Getting Started¶
In this section, we show how to implement quantum computing simulation using cuStateVec. Firstly, We describe how to install the library and how to compile it. Then, we present an example code to perform common steps in cuStateVec.
Installation and Compilation¶
Download the cuQuantum package (which cuStateVec is part of) from https://developer.nvidia.com/cuQuantum-downloads.
Linux¶
Assuming cuQuantum has been extracted in CUQUANTUM_ROOT, we update the library path accordingly:
export LD_LIBRARY_PATH=${CUQUANTUM_ROOT}/lib64:${LD_LIBRARY_PATH}
We can compile the sample code we will discuss below (statevec_example.cu) via the following command:
nvcc statevec_example.cu -I${CUQUANTUM_ROOT}/include -L${CUQUANTUM_ROOT}/lib64 -lcustatevec -o statevec_example
Code Example¶
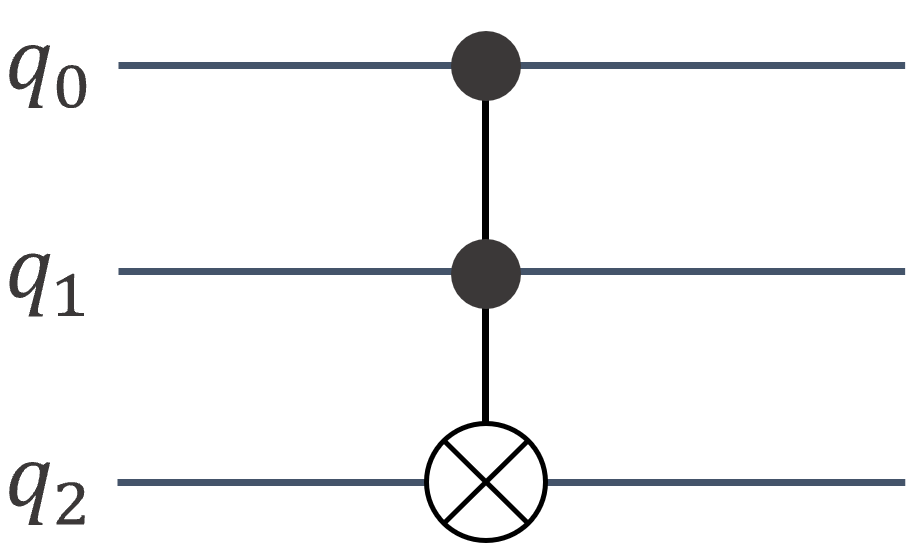
The following code example shows the common steps to use cuStateVec. Here we apply a Toffoli gate, which inverts the third bit when the first two bits are both 1.
#include <cuda_runtime_api.h> // cudaMalloc, cudaMemcpy, etc.
#include <cuComplex.h> // cuDoubleComplex
#include <custatevec.h> // custatevecApplyMatrix
#include <stdio.h> // printf
#include <stdlib.h> // EXIT_FAILURE
int main(void) {
const int nIndexBits = 3;
const int nSvSize = (1 << nIndexBits);
const int nTargets = 1;
const int nControls = 2;
const int adjoint = 0;
int targets[] = {2};
int controls[] = {0, 1};
cuDoubleComplex h_sv[] = {{ 0.0, 0.0}, { 0.0, 0.1}, { 0.1, 0.1},
{ 0.1, 0.2}, { 0.2, 0.2}, { 0.3, 0.3},
{ 0.3, 0.4}, { 0.4, 0.5}};
cuDoubleComplex h_sv_result[] = {{ 0.0, 0.0}, { 0.0, 0.1}, { 0.1, 0.1},
{ 0.4, 0.5}, { 0.2, 0.2}, { 0.3, 0.3},
{ 0.3, 0.4}, { 0.1, 0.2}};
cuDoubleComplex matrix[] = {{0.0, 0.0}, {1.0, 0.0},
{1.0, 0.0}, {0.0, 0.0}};
cuDoubleComplex *d_sv;
cudaMalloc((void**)&d_sv, nSvSize * sizeof(cuDoubleComplex));
cudaMemcpy(d_sv, h_sv, nSvSize * sizeof(cuDoubleComplex),
cudaMemcpyHostToDevice);
//--------------------------------------------------------------------------
// custatevec handle initialization
custatevecHandle_t handle;
custatevecCreate(&handle);
void* extraWorkspace = nullptr;
size_t extraWorkspaceSizeInBytes = 0;
// check the size of external workspace
custatevecApplyMatrix_bufferSize(
handle, CUDA_C_64F, nIndexBits, matrix, CUDA_C_64F,
CUSTATEVEC_MATRIX_LAYOUT_ROW, adjoint, nTargets, nControls,
CUSTATEVEC_COMPUTE_64F, &extraWorkspaceSizeInBytes);
// allocate external workspace if necessary
if (extraWorkspaceSizeInBytes > 0)
cudaMalloc(&extraWorkspace, extraWorkspaceSizeInBytes);
// apply gate
custatevecApplyMatrix(
handle, d_sv, CUDA_C_64F, nIndexBits, matrix, CUDA_C_64F,
CUSTATEVEC_MATRIX_LAYOUT_ROW, adjoint, targets, nTargets, controls,
nControls, nullptr, CUSTATEVEC_COMPUTE_64F,
extraWorkspace, extraWorkspaceSizeInBytes);
// destroy handle
custatevecDestroy(handle);
//--------------------------------------------------------------------------
cudaMemcpy(h_sv, d_sv, nSvSize * sizeof(cuDoubleComplex),
cudaMemcpyDeviceToHost);
bool correct = true;
for (int i = 0; i < nSvSize; i++) {
if ((h_sv[i].x != h_sv_result[i].x) ||
(h_sv[i].y != h_sv_result[i].y)) {
correct = false;
break;
}
}
if (correct)
printf("example PASSED\n");
else
printf("example FAILED: wrong result\n");
cudaFree(d_sv);
if (extraWorkspaceSizeInBytes)
cudaFree(extraWorkspace);
return EXIT_SUCCESS;
}
More samples can be found in the NVIDIA/cuQuantum repository.