Just-In-Time Link-Time Optimizations¶
What is JIT LTO?¶
Link-Time Optimization (LTO) is a powerful tool that brings whole-program optimization to applications that are built with separate compilation. For CUDA applications, LTO was introduced for the first time in CUDA 11.2. When LTO is applied as part of the application building process using the nvcc compiler, we call it offline LTO.
We can also apply LTO optimizations at runtime, when the application is executed. We call this process Just-In-Time (JIT) LTO. JIT LTO allows libraries to finalize at runtime only the kernels requested by the user, instead of all possible kernels.
JIT LTO is implemented using the nvJitLink library, which was introduced in CUDA 12.0.
JIT LTO in cuFFT LTO EA¶
In this preview, we decided to apply JIT LTO to the callback kernels that have been part of cuFFT since CUDA 6.5. There are currently two main benefits of LTO-enabled callbacks in cuFFT, when compared to non-LTO callbacks.
First, JIT LTO allows us to inline the user callback code inside the cuFFT kernel. Once the callback has been inlined, the optimization process takes place with full kernel visibility. Without JIT LTO, user callbacks were compiled separately and indirectly called from within the cuFFT kernel using function pointers. The result of using LTO is a noticeable improvement in performance for some callback use cases due to the removal of the overhead of indirect function calls to the callback.
In other words, JIT LTO allows us to seamlessly combine user code with library code at runtime.
Secondly, the runtime aspect of JIT LTO means we do not need to build all possible kernels beforehand to be shipped with the library; only the kernels requested by the user at plan time need to be finalized. cuFFT will expand on this idea in future releases to bring additional functioanlity and Speed-of-Light performance that were previously impossible to ship without compromising binary size.
cuFFT LTO EA includes a sample of this additional performance for LTO callback kernels:
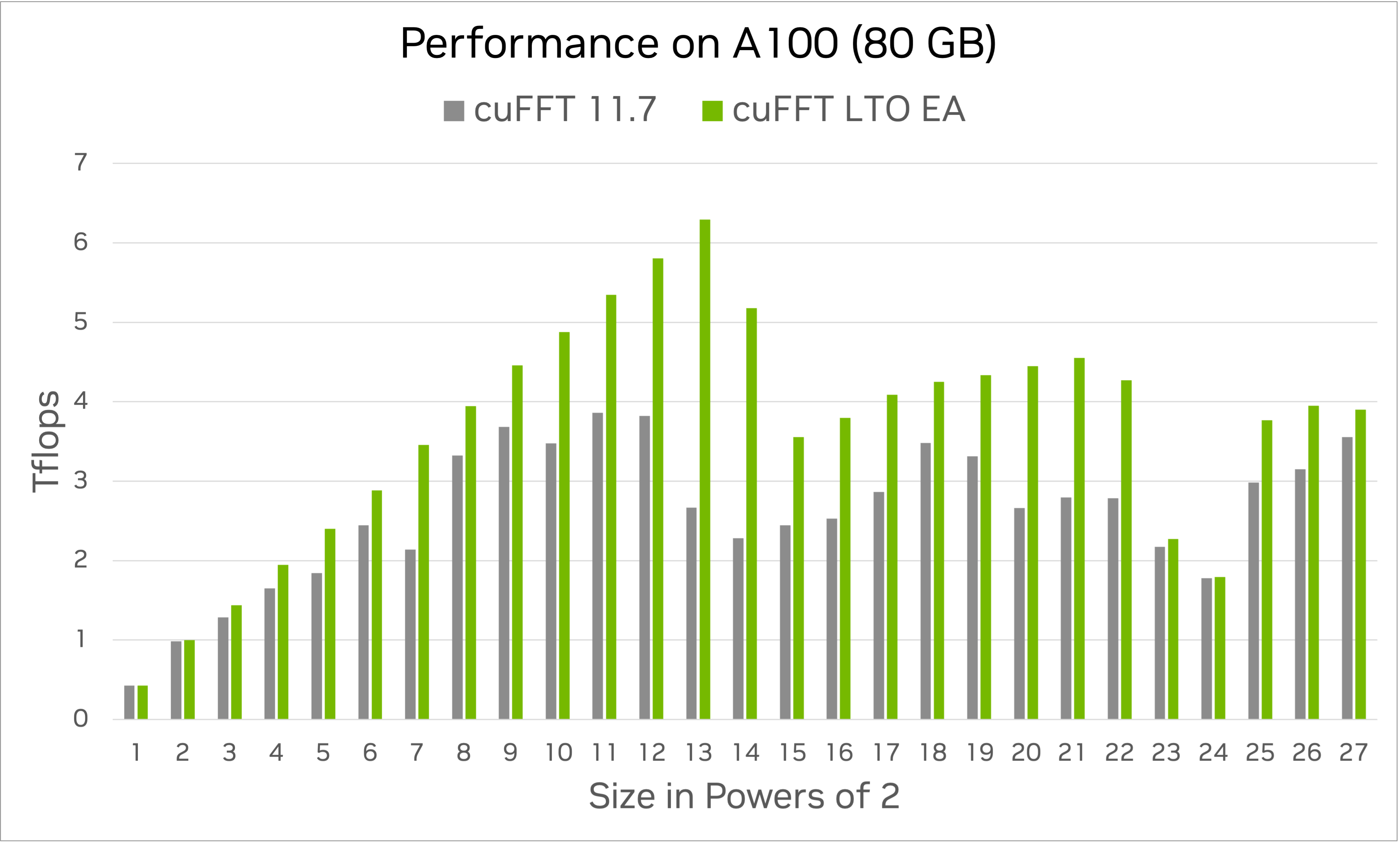
The chart above illustrates the performance gains of using LTO callbacks when compared to non-LTO callbacks in cuFFT distributed in the CUDA Toolkit 11.7. The benchmark runs Complex-to-Complex (C2C) FFTs in single precision, with minimal load and store callbacks, on an Ampere GPU (A100 with 80 GB).
The cost of JIT LTO¶
When using JIT LTO, kernel finalization happens at runtime, rather than when the library is built. This runtime component is a great advantage over offline LTO: since with offline LTO we do not know which kernels are going to be run, we need to link the whole library with the user callback code, which is a slow and delicate process.
The drawback of finalizing the kernel at runtime is the overhead of kernel finalization at plan time. We have measured most cases to be between 50 and 500 ms of overhead at plan time per kernel. This compares to about 250 ms of library initialization in older versions of cuFFT shipped in CUDA 10.X, and less than 200 ms per kernel in CUDA 11.X and newer versions, due to PTX JIT.
Please keep in mind that these times are an estimation and actual times vary with the characteristics of the system used to run the application, i.e. CPU power. Also note that starting from CUDA 12.1, nvJitLink uses a cache to greatly reduce the overhead of runtime linking for kernels across multiple runs.