API usage#
Note
The CUDALibrarySamples repository on Github contains
several examples showing how to use cuFFTMp in various situations.
The reader is encouraged to explore those while reading this document.
Similarly to the cuFFT’s single-process, multi-GPU API, input and output arrays in cuFFTMp are distributed across multiple GPUs. This is done using descriptors, which hold both a pointer to the local data and an enum describing how the data is distributed across multiple GPUs. Note that in cuFFTMp every descriptor only holds a pointer to the data local to its GPU, and not to other GPUs.
cuFFTMp supports two kinds of data distributions.
Built-in slabs
This is done using CUFFT_XT_FORMAT_INPLACE and CUFFT_XT_FORMAT_INPLACE_SHUFFLED.
This is the default, optimized data distribution and is identical to the single process API.
Consider an array of size X*Y*Z distributed over n GPUs.
With
CUFFT_XT_FORMAT_INPLACE, the firstX % nGPUs each own(X/n+1)*Y*Zelements and the remaining GPUs each own(X/n)*Y*Zelements.With
CUFFT_XT_FORMAT_INPLACE_SHUFFLED, the firstY % nGPUs each ownX*(Y/n+1)*Zelements and the remaining GPUs each ownX*(Y/n)*Zelements.
Note that this data distribution does not allow strides between elements and assumes in-place transforms with an in-place data layout. This means a real dimension of length Z need to be padded to 2(Z/2+1) elements.
Flexible slabs and pencils
Using CUFFT_XT_FORMAT_DISTRIBUTED_INPUT and CUFFT_XT_FORMAT_DISTRIBUTED_OUTPUT.
This lets the user use any Slab or Pencil data distribution (with arbitrary strides between elements).
While efficient, this distribution is less optimized than the previous one.
Usage with built-in slab data decompositions#
When using the default and optimized data distribution, cuFFTMp’s API usage is similar to the single-process, multi-GPU cuFFT API usage. The following outlines the sequence of required API calls.
// Initialize MPI, create some distribute data
MPI_Init(...)
MPI_Comm comm = MPI_COMM_WORLD;
// Initialize a cuFFT handle
cufftHandle plan = 0;
cufftCreate(&plan);
// Create a plan with MPI communicator attached
size_t workspace;
cufftMpMakePlan3d(plan, nx, ny, nz, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &workspace);
// Allocate a multi-GPU descriptor
cudaLibXtDesc *desc;
cufftXtMalloc(plan, &desc, CUFFT_XT_FORMAT_INPLACE);
// Copy data from the CPU to the GPU.
// The CPU data is distributed according to CUFFT_XT_FORMAT_INPLACE
cufftXtMemcpy(plan, desc, cpu_data, CUFFT_COPY_HOST_TO_DEVICE);
// Compute a forward FFT
cufftXtExecDescriptor(plan, desc, desc, CUFFT_FORWARD);
// Copy memory back to the CPU. Data is now distributed according to CUFFT_XT_FORMAT_INPLACE_SHUFFLED
cufftXtMemcpy(plan, cpu_data, desc, CUFFT_COPY_DEVICE_TO_HOST);
// Free the multi-GPU descriptor and the plan and finalize MPI
cufftXtFree(desc);
cufftDestroy(plan);
MPI_Finalize();
This code snippet does the following:
Initialize MPI using
MPI_Init, create a distributed 2D or 3D array (in natural or permuted order) on CPU.(Optional) On multi-GPU systems, select a GPU using
cudaSetDevice.Create an empty plan
cufftCreate(&plan).(Optional) Attach a stream
cufftSetStream(plan, stream).Make the multi-process plan and attach the MPI communicator
commto the plan. This creates a plan for a 3D complex-to-complex transform of sizenx*ny*nzcufftMpMakePlan3d(plan, nx, ny, nz, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &workspace)
and this creates a plan for a 2D complex-to-complex transform of size
nx*nycufftMpMakePlan2d(plan, nx, ny, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &workspace)
Since cuFFTMp only supports in-place transforms without strides,
cufftMakePlanManyshould not be used. Note that this is a collective call that should be called by all processes within the MPI communicator.Allocate GPU memory to hold the data using
cufftXtMalloc(plan, desc, CUFFT_XT_FORMAT_INPLACE).CUFFT_XT_FORMAT_INPLACEindicates that the data is distributed according to the natural order.CUFFT_XT_FORMAT_INPLACE_SHUFFLEDcan be used to allocate data in permuted order. The memory is allocated indesc->descriptor->data[0].Copy data from the CPU to the GPU using
cufftXtMemcpy(plan, desc, cpu_data, CUFFT_COPY_HOST_TO_DEVICE). Note that the data can also be initialized on GPU from the beginning, and usingcufftXtMemcpyis merely a convenience function. GPU data can be directly accessed through the descriptor by using the device memory pointerdesc->descriptor->data[0].Run the transform
cufftXtExecDescriptor(plan, desc, desc, CUFFT_FORWARD)
At this point, data is distributed in the permuted order. If required, element-wise operations, filtering, a backward transform, etc. can be performed.
Copy data back from the GPU to the CPU using
cufftXtMemcpy(plan, cpu_data, desc, CUFFT_COPY_DEVICE_TO_HOST)This does not change the data distribution. If the GPU data is distributed according toCUFFT_XT_FORMAT_INPLACE(orCUFFT_XT_FORMAT_INPLACE_SHUFFLED), the same holds for the CPU data.Free the descriptor
cufftXtFree(desc).Destroy the plan
cufftDestroy(plan).Finalize MPI using
MPI_Finalize.
Warning
cufftMakePlanMany and cufftXtMakePlanMany should not be used with cuFFTMp.
If they are used, any stride information will be ignored.
Finally, you can build and run as follows:
Include the
cufftMp.hheaderCompile the application and link to cuFFTMp (
libcufftMp.so), NVSHMEM host (libnvshmem_host.so) and the CUDA driver (libcuda.so). Note that statically linking to NVSHMEM (libnvshmem.a) is not allowed. Also note thatlibcufftMp.socontains both the single and multi-process cuFFT functionalities and it is not necessary to link tolibcufft.soas well. Assuming${CUFFTMP_HOME}and${NVSHMEM_HOME}are the installation directories of cuFFTMp and NVSHMEM, respectively:mpicxx app.cpp -I${CUFFTMP_HOME}/include -L${CUFFTMP_HOME}/lib -L${NVSHMEM_HOME}/lib -lcufftMp -lnvshmem_host -lcuda -o app
At runtime, ensure that the NVSHMEM bootstrap (
nvshmem_bootstrap_mpi.so) is present inLD_LIBRARY_PATHexport LD_LIBRARY_PATH=${NVSHMEM_HOME}/lib:$LD_LIBRARY_PATH
If necessary, increase the amount of memory reserved for NVSHMEM by setting the
NVSHMEM_SYMMETRIC_SIZEenvironment variable to, e.g., 10GB:export NVSHMEM_SYMMETRIC_SIZE=10G
Run the application using MPI, e.g.,
mpirun -n 2 ./app
Usage with custom slabs and pencils data decompositions#
cuFFTMp also supports arbitrary data distributions in the form of 3D boxes.
Consider a X*Y*Z global array.
3D boxes are used to describe a subsection of this global array by indicating the lower and upper corner of the subsection.
By associating boxes to processes one can then describe a data distribution where every process owns a contiguous rectangular subsection of the global array.
For instance, consider a 2D case with a global array of size X*Y = 4*4 and three boxes, described as box = {lower, upper}
Box 0 = { {0,0}, {2,2} }(in green)Box 1 = { {2,0}, {4,2} }(in blue)Box 2 = { {0,2}, {4,4} }(in purple)
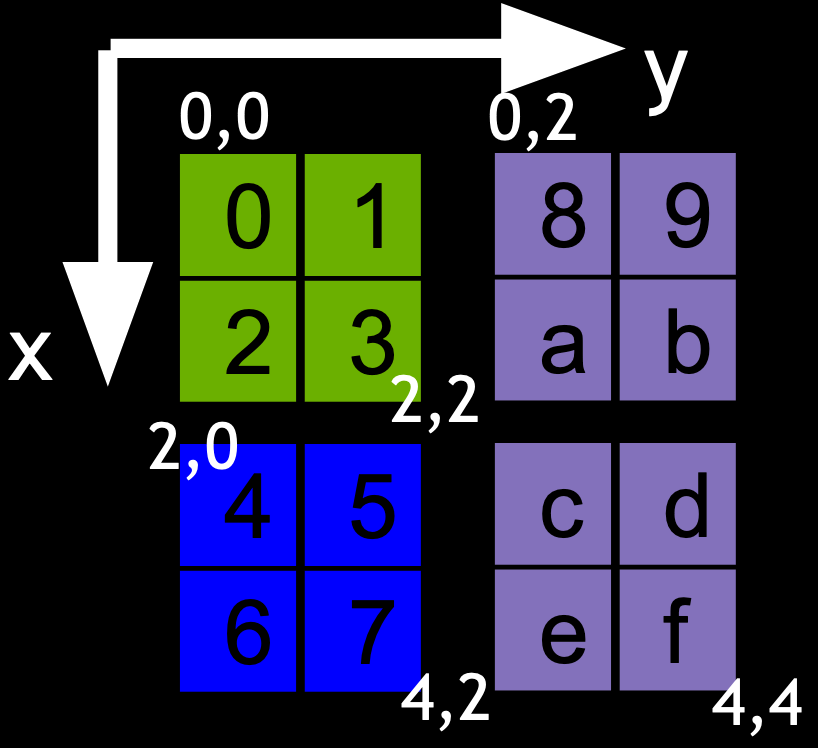
By associating box 0 to process 0, box 1 to process 1 and box 2 to process 2, this creates a data distribution of the global 4*4 array across three processes.
The same process can be generalized to a 3D array.
This logic can be used to generalize the usage from the previous section and use any data distribution.
This requires the use of the cufftMpMakePlanDecomposition(plan, rank, size, lower_input, upper_input, strides_input, lower_output, upper_output, strides_output, type, comm_ptr, comm_type, workSize) function.
With this function, cufftXtExecDescriptor(plan, ...) can accept descriptors with a data distribution of type CUFFT_XT_FORMAT_DISTRIBUTED_INPUT or
CUFFT_XT_FORMAT_DISTRIBUTED_OUTPUT.
For a given plan,
CUFFT_XT_FORMAT_DISTRIBUTED_INPUTindicates that the data in the descriptor is distributed according to(lower_input, upper_input)and that the data layout in memory is described bystrides_input;CUFFT_XT_FORMAT_DISTRIBUTED_OUTPUTindicates that the data in the descriptor is distributed according to(lower_output, upper_output)and that the data layout in memory is described bystrides_output.
Note that, in addition,
R2Cplans only supportCUFFT_XT_FORMAT_DISTRIBUTED_INPUT, i.e.,(lower_input, upper_input)should describe the real data distribution and(lower_output, upper_output)the complex data distribution;C2Rplans only supportCUFFT_XT_FORMAT_DISTRIBUTED_OUTPUT, i.e.,(lower_input, upper_input)should describe the real data distribution and(lower_output, upper_output)the complex data distribution.
This implies that the proper usage for a R2C followed-by C2R plan is
int n[3] = {nx, ny, nz}; // For R2C plan cufftMpMakePlanDecomposition(plan_r2c, 3, n, real_lower, real_upper, real_strides, complex_lower, complex_upper, complex_strides, CUFFT_R2C, &comm, CUFFT_COMM_MPI, &scratch); // For C2R plan cufftMpMakePlanDecomposition(plan_c2r, 3, n, complex_lower, complex_upper, complex_strides, real_lower, real_upper, real_strides, CUFFT_C2R, &comm, CUFFT_COMM_MPI, &scratch); ... cufftXtExecDescriptor(plan_r2c, desc, desc, CUFFT_FORWARD); ... cufftXtExecDescriptor(plan_c2r, desc, desc, CUFFT_INVERSE);
Overall, for a C2C plan, this leads to the following:
// Initialize MPI, create some distribute data MPI_Init(...) MPI_Comm comm = MPI_COMM_WORLD; // Create plan cufftHandle plan = 0; cufftCreate(&plan); // Initialize input and output data distribution descriptors long long int lower_input[3], upper_input[3], lower_output[3], upper_output[3], strides_input[3], strides_output[3]; int n[3] = {nx, ny, nz}; size_t scratch; ... // initialize above arrays // Create the plan with distribution and attach the communicator for multi-process support. cufftMpMakePlanDecomposition(plan, 3, n, lower_input, upper_input, strides_input, lower_output, upper_output, strides_output, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &scratch); // Allocate a multi-GPU descriptor cudaLibXtDesc *desc; cufftXtMalloc(plan, &desc, CUFFT_XT_FORMAT_INPLACE); // Copy data from the CPU to the GPU. // The CPU data is distributed according to CUFFT_XT_FORMAT_DISTRIBUTED_INPUT cufftXtMemcpy(plan, desc, cpu_data, CUFFT_COPY_HOST_TO_DEVICE); // Compute a forward FFT cufftXtExecDescriptor(plan, desc, desc, CUFFT_FORWARD); // Copy memory back to the CPU. Data is now distributed according to CUFFT_XT_FORMAT_DISTRIBUTED_OUTPUT cufftXtMemcpy(plan, cpu_data, desc, CUFFT_COPY_DEVICE_TO_HOST); // Free the multi-GPU descriptor and the plan and finalize MPI cufftXtFree(desc); cufftDestroy(plan); MPI_Finalize();
Create an empty plan
cufftCreate(&plan)(Optional) Attach a stream
cufftSetStream(plan, stream)Create the plan with specified decomposition and attach the communicator for multi-process plan. First define the input and output boxes, describing the subsection of the global array owned by this process. Then, call
cufftMpMakePlanDecompositionto set up the decomposition and create the plan in one step:long long int lower_input[3], upper_input[3], lower_output[3], upper_output[3], strides_input[3], strides_output[3]; int n[3] = {nx, ny, nz}; size_t scratch; ... // initialize above arrays // Create the plan with specified decomposition and attach the communicator for multi-process plan. cufftMpMakePlanDecomposition(plan, 3, n, lower_input, upper_input, strides_input, lower_output, upper_output, strides_output, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &scratch);
This creates a plan for a 3D transform of (global) size
nx*ny*nzand sets up the custom data decomposition.
Allocate GPU memory to hold the data.
CUFFT_XT_FORMAT_DISTRIBUTED_INPUTindicates that the data is distributed according toinput_boxcufftXtMalloc(plan, desc, CUFFT_XT_FORMAT_DISTRIBUTED_INPUT)
Copy data from the CPU to the GPU using
cufftXtMemcpy(plan, desc, cpu_data, CUFFT_COPY_HOST_TO_DEVICE)
Note that using
cufftXtMemcpyis optional. Instead, data can be initialized and manipulated on the device directly. Also not thatcufftXtMemcpycopies the entire CPU buffer, effectively ignoring the all but the first-dimension strides.Run the transform
cufftXtExecDescriptor(plan, desc, desc, CUFFT_FORWARD)
Copy data back from the GPU to the CPU. At this point, data is distributed according to
CUFFT_XT_FORMAT_DISTRIBUTED_OUTPUT, i.e.,output_box.cufftXtMemcpy(plan, cpu_data, desc, CUFFT_COPY_DEVICE_TO_HOST)
Free the descriptor with
cufftXtFree(desc)Destroy the plan with
cufftDestroy(plan)
Usage with NVSHMEM#
To use cuFFTMp with NVSHMEM-allocated buffers, users need to
Initialize and finalize NVSHMEM;
Allocate and free memory using
nvshmem_mallocandnvshmem_free;Call
cufftXtSetSubformatDefault(plan, subformat_forward, subformat_inverse)on the plan to indicate the data decomposition expected bycufftExecC2Cor similar APIs.subformat_forwardwill be the input data decomposition of a forward transform, andsubformat_inversethe data decomposition of an inverse transform.
Compare this code snippet with the previous example using descriptors in Usage with built-in slab data decompositions.
Code calling NVSHMEM APIs directly need to link to both libnvshmem_host.so and libnvshmem_device.a.
// Initialize MPI, create some distribute data
MPI_Init(...)
MPI_Comm comm = MPI_COMM_WORLD;
// Initialize NVSHMEM
nvshmemx_init_attr_t attr;
attr.mpi_comm = (void*)&comm;
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_MPI_COMM, &attr);
// Initialize a cuFFT handle
cufftHandle plan = 0;
cufftCreate(&plan);
// Create a plan with MPI communicator attached.
size_t workspace;
cufftMpMakePlan3d(plan, nx, ny, nz, CUFFT_C2C, &comm, CUFFT_COMM_MPI, &workspace);
// Allocate NVSHMEM memory
cuComplex* gpu_data = (cuComplex*)nvshmem_malloc(...);
// Indicate default data distribution expected by cufftExecC2C
cufftXtSetSubformatDefault(plan, CUFFT_XT_FORMAT_INPLACE, CUFFT_XT_FORMAT_INPLACE_SHUFFLED);
// Copy data from the CPU to the GPU.
// The CPU data is distributed according to CUFFT_XT_FORMAT_INPLACE
cudaMemcpy(gpu_data, cpu_data, ..., cudaMemcpyDefault);
// Compute a forward FFT
// CUFFT_FORWARD means the input is CUFFT_XT_FORMAT_INPLACE and the output is CUFFT_XT_FORMAT_INPLACE_SHUFFLED
// CUFFT_INVERSE would mean that the input is CUFFT_XT_FORMAT_INPLACE_SHUFFLED and the output is CUFFT_XT_FORMAT_INPLACE
cufftExecC2C(plan, gpu_data, gpu_data, CUFFT_FORWARD);
// Copy memory back to the CPU. Data is now distributed according to CUFFT_XT_FORMAT_INPLACE_SHUFFLED
cudaMemcpy(cpu_data, gpu_data, ..., cudaMemcpyDefault);
// Free the NVSHMEM memory and the plan and finalize NVSHMEM and MPI
nvshmem_free(gpu_data);
cufftDestroy(plan);
nvshmem_finalize();
MPI_Finalize();
Reshape API#
cuFFT exposes a distributed reshape API which enables redistributing data described using 3D boxes without using a cuFFT plan, descriptors or cufftXtMemcpy.
Its usage follows the general cuFFT usage but with a new handle type.
// Initialize MPI MPI_Init(...); MPI_Comm comm = MPI_COMM_WORLD; // Initialize input and output data distribution descriptors long long int lower_input[3], upper_input[3], lower_output[3], upper_output[3], strides_input[3], strides_output[3]; ... // initialize above arrays // Allocate reshape, attach MPI communicator cufftReshapeHandle handle; cufftMpCreateReshape(&handle); // Build reshape with communicator parameters cufftMpMakeReshape(handle, sizeof(int), 3, lower_input, upper_input, strides_input, lower_output, upper_output, strides_output, &comm, CUFFT_COMM_MPI); // Create a stream cudaStream_t stream; cudaStreamCreate(&stream); // Retreive workspace size size_t workspace; cufftMpGetReshapeSize(handle, &workspace); // Allocate NVSHMEM memory void *src = nvshmem_malloc(input_size * sizeof(int)); void *dst = nvshmem_malloc(output_size * sizeof(int)); void *scratch = nvshmem_malloc(workspace); // Apply reshape CUFFT_CHECK(cufftMpExecReshapeAsync(handle, dst, src, scratch, stream)); // Cleanup nvshmem_free(src); nvshmem_free(dst); nvshmem_free(scratch); cufftMpDestroyReshape(handle); cudaStreamDestroy(stream); MPI_Finalize();
Create an empty reshape handle,
cufftMpCreateReshape(handle)Make the reshape with communicator parameters directly
cufftMpMakeReshape(handle, sizeof(int), 3, lower_input, upper_input, strides_input, lower_output, upper_output, strides_output, &comm, CUFFT_COMM_MPI);
(lower_input, upper_input, strides_input)(one on each process) describes the input distribution, and(lower_output, upper_output, strides_output)describes the output distribution.element_sizeis the size, in bytes, of a single element. This is a collective call.Retrieve the workspace size, in bytes using
cufftMpGetReshapeSize(handle, workspace).Allocate workspace using NVSHMEM
Execute the reshape with
cufftMpExecReshapeAsync(handle, dst, src, workspace, stream)
This is a stream-ordered, collective call.
dst, src, workspaceshould all be pointers to a symmetric-heap, NVSHMEM-allocated memory buffer. Note that this differs from MPI, wheredst, src, workspacewould be regular pointers to cudaMalloc’ed memory. See also NVSHMEM’s documentation on the symmetric heap here. In addition, when one GPU starts to executecufftMpExecReshapeAsyncin a stream, the destination memory bufferdstand scratch bufferworkspaceshould be ready on all other GPUs to prevent race conditions. This can be achieved by, for instance, placing synchronization points likenvshmemx_sync_all_on_stream(stream)before the API.Cleanup and destroy the reshape with
cufftMpDestroyReshape(handle).
Note
Those functions require the use of NVSHMEM to allocate memory.
nvshmem_malloc and nvshmem_free can be used for this.
For more information, see the NVSHMEM documentation and NVSHMEM memory buffer in cuFFTMp.
Note that symmetric-heap NVSHMEM-allocated buffers have a different semantic as local buffers
In particular, dst, src, workspace should all refer to the same symmetric object allocated on all GPUs.
This is different than when passing pointers to a message-passing based library like MPI, where pointers refer only to local objects.
Helper functions#
Similarly to the cuFFT’s single-process, multi-GPU API, cuFFTMp provides helper functions to help with managing multiple GPUs memory. Their usage is similar to the single-process case.
cufftXtMallocis used to allocate memory on multiple GPUs in multiple processes. It takes an argument indicating which data decomposition.cufftXtMemcpyis used to copy memory between CPU and GPU or between GPUs. Its usage depends on the source and destination of the data transfer:cufftXtMemcpy(plan, dst, src, CUFFT_COPY_HOST_TO_DEVICE)copies distributed CPU data to GPU, keeping the distribution unchanged. This means the CPU data has to be distributed in the same way as the GPU data.cufftXtMemcpy(plan, dst, src, CUFFT_COPY_DEVICE_TO_HOST)copies distributed GPU data to CPU, keeping the distribution unchanged. This means the CPU data will be distributed in the same way as the GPU data.cufftXtMemcpy(plan, dst, src, CUFFT_COPY_DEVICE_TO_DEVICE)can be used to re-distribute GPU data fromCUFFT_XT_FORMAT_INPUT_SHUFFLEDtoCUFFT_XT_FORMAT_INPUT(or vice-versa). This can be useful to transform permuted data back to natural order for easier post-processing.
cufftXtFreeis used to free a descriptor