FAQ#
General FAQ#
Where can I find cuOpt container images?
There are two options: - NVIDIA Docker Hub (https://hub.docker.com/r/nvidia/cuopt) - NVIDIA NGC registry (https://catalog.ngc.nvidia.com/orgs/nvidia/teams/cuopt/containers/cuopt/tags) with NVAIE license.
How to get a NVAIE license?
Please refer to NVIDIA NVAIE for more information.
How to access NGC registry?
Once you have a NVAIE license, you can access the NGC registry for cuOpt container images.
How to pull cuOpt container images from NGC registry?
Log into NGC using the invite and choose the appropriate NGC org.
Generate an NGC API key from settings. If you have not generated an API Key, you can generate it by going to the Setup option in your profile and choose Get API Key. Store this or generate a new one next time.
- Go to the container section for cuOpt and copy the pull tag for the latest image.
Within the Select a tag dropdown, locate the container image release that you want to run.
Click the Copy Image Path button to copy the container image path.
Log into the nvcr.io container registry in your cluster setup, using the NGC API key as shown below.
docker login nvcr.io
Username: $oauthtoken
Password: <my-api-key>
Pull the cuOpt container image.
docker pull <COPIED_IMAGE_TAG>
Do I need a GPU to use cuOpt?
Yes, please refer to system requirements for GPU specifications. You can acquire a cloud instance with a supported GPU and launch cuOpt; alternatively, you can launch it in your local machine if it meets the requirements.
Does cuOpt use multiple GPUs/multi-GPUs/multi GPUs?
Yes, in cuOpt self-hosted server, a solver process per GPU can be configured to run multiple solvers. Requests are accepted in a round-robin queue. More details are available in server api.
There is no support for leveraging multiple GPUs to solve a single problem or oversubscribing a single GPU for multiple solvers.
The cuOpt Service is not starting: Issue with port?
Check the logs for the container (see cuOpt service monitoring below).
Is port 5000 already in use?
If port 5000 is unavailable, the logs will contain an error like this
ERROR: [Errno 98] error while attempting to bind on address ('0.0.0.0', 5000): address already in use”
Try to locate the process that is using port 5000 and stop it if possible. A tool like
netstatrun as the root user can help identify ports mapped to processes, anddocker ps -awill show running containers.Alternatively, use port mapping to launch cuOpt on a different port such as 5001 (note the omission of
–network=hostflag):If running locally, you can also use
ps -aux | grep cuopt_serverto find the process and kill it.
docker run -d --rm --gpus all -p 5001:5000 <CUOPT_IMAGE>
Why is NVIDIA cuOpt running longer than the supplied time limit?
The time limit supplied governs the run time of the solver only, but there are other overheads such as network delay, ETL, validation or the solver being busy with other requests.
The complete round-trip solve time might be more than what was set.
Why am I getting “libssl.so.3: cannot open shared object file” or “libcrypto.so.3: cannot open shared object file” when importing cuOpt?
The cuOpt wheel links against OpenSSL 3 and intentionally does not bundle libssl.so.3 / libcrypto.so.3; the host must provide them. This keeps libcrypto and any FIPS provider (system or mounted) byte-version-matched at runtime.
Most modern Linux distributions provide OpenSSL 3 out of the box: Ubuntu 22.04+, Debian 12+, RHEL/Rocky/Alma 9+, and Fedora 36+. For older distributions:
RHEL / Rocky / Alma / CentOS 8: install the
openssl3runtime package from EPEL:dnf install -y epel-release dnf install -y openssl3 # Verify ldconfig -p | grep -E 'libssl\.so\.3|libcrypto\.so\.3'
Ubuntu 20.04: install OpenSSL 3 from a PPA or backport, or use the cuOpt container image (Ubuntu 22.04 base) instead.
Other distributions: install your distribution’s OpenSSL 3 development/runtime package, or use the cuOpt container.
After installing, re-run pip install (or restart the Python process) and the import should succeed.
Why am I getting “libcuopt.so: cannot open shared object file: No such file or directory” error?
This error indicates that the cuOpt shared library is not found. Please check the following:
The cuOpt is installed
Use
find / -name libcuopt.soto search for the library path from root directory. You might need to run this command as root user.If the library is found, please add it to the
LD_LIBRARY_PATHenvironment variable as shown below:
export LD_LIBRARY_PATH=/path/to/cuopt/lib:$LD_LIBRARY_PATH
If the library is not found, it means it is not yet installed. Please check the cuOpt installation guide for more details.
Is there a way to make cuOpt also account for other overheads in the same time limit provided?
We currently don’t account for it, since many such overheads are relative and cannot be tracked properly.
cuOpt is not running: Issue with GPU memory availability?
If there are errors pertaining to
rmmor errors that the service couldn’t acquire GPU memory, there is a possibility that GPU memory is being consumed by another process.This can be observed using the command
nvidia-smi.
The cuOpt service is not responding: What to check?
cuOpt microservice health check on the cuOpt host.
Perform a health-check locally on the host running cuOpt:
curl -s -o /dev/null -w '%{http_code}\\n' localhost:5000/cuopt/health 200If this command returns 200, cuOpt is running and listening on the specified port.
If this command returns something other than 200, check the following:
Check that a cuOpt container is running with
docker -ps.Examine the cuOpt container log for errors.
Did you include the
–network=hostor a-pport-mapping flag to docker when you launched cuOpt? If you used port mapping, did you perform the health check using the correct port?Restart cuOpt and see if that corrects the problem.
cuOpt microservice health-check from a remote host.
If you are trying to reach cuOpt from a remote host, run the health check from the remote host and specify the IP address of the cuOpt host, for example:
1 curl -s -o /dev/null -w '%{http_code}\\n' <ip>::5000/cuopt/health 2 200If this command does not return 200, but a health check locally on the cuOpt host does return 200, the problem is a network configuration or firewall issue. The host is not reachable, or the cuOpt port is not open to incoming traffic.
Certificate Validation Errors from Python client?
This might happen mostly with cuOpt running in a cloud instance.
It could be that you are behind a proxy that is generating a certificate chain and you need additional certificate authorities installed on your machine.
You can examine the certificate chain returned on a connection with the following commands or something similar. If it looks like there are certificates in the chain that are issued by your own organization, contact your local IT admin, and ask them for the proper certificates to install on your machine.
In this example, we will check the certificate chain being returned from a connection to NVCF at NVIDIA, but you can substitute a different address if you are trying to connect to an instance of cuOpt deployed in the cloud:
1export MY_SERVER_ADDRESS=”api.nvcf.nvidia.com:443”
2openssl s_client -showcerts -connect $MY_SERVER_ADDRESS </dev/null 2>/dev/null | sed -n -e '/BEGIN\ CERTIFICATE/,/END CERTIFICATE/ p' > test.pem
3
4while openssl x509 -noout -text; do :; done < test.pem.txt
gRPC remote execution (cuopt_grpc_server)#
Where are log files for the gRPC server / StreamLogs?
Workers write per-job solver logs under /tmp/cuopt_logs/job_<job_id>.log. The StreamLogs RPC tails that file. Operational limits and behavior are summarized in gRPC server behavior.
What happens if a cuopt_grpc_server worker crashes?
Jobs that worker was running are marked FAILED. The server monitor can detect the crash and spawn a replacement worker; other workers keep running. For more detail, see gRPC server behavior and the contributor reference cpp/docs/grpc-server-architecture.md in the repository.
Does CancelJob stop a solve immediately?
Cancellation is honored before the solver starts. If the solve has already begun, it runs to completion; there is no mid-solve cancellation path. See gRPC server behavior.
Routing FAQ#
What is a Waypoint Graph?
A waypoint graph is a weighted, directed graph where the weights symbolize cost. Unlike the cost matrix, this graph often represents more than just target locations, including intermediate decision points along a route (locations merely passed through). This method is commonly used for custom environments and indoor spaces, such as warehouses and factories, where the cost between target locations is dynamic or not easily quantifiable. A basic waypoint graph with four nodes is illustrated below:
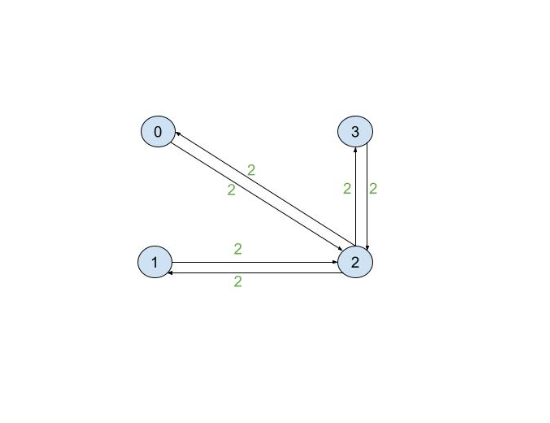
1{
2"cost_waypoint_graph_data":{
3 "waypoint_graph": {
4 "0": {
5 "offsets": [0, 1, 2, 5, 6],
6 "edges": [2, 2, 0, 1, 3, 2],
7 "weights": [2, 2, 2, 2, 2, 2]
8 }
9 }
10}
Graphs intended for input into cuOpt are shown in Compressed Sparse Row (CSR) format for efficiency. The translation from a more conventional (and human-readable) graph format, such as a weighted edge list, to CSR can be accomplished quickly, as depicted below:
1graph = { 2 0:{ 3 "edges":[2], 4 "weights":[2]}, 5 1:{ 6 "edges":[2], 7 "weights":[2]}, 8 2:{ 9 "edges":[0, 1, 3], 10 "weights":[2, 2, 2]}, 11 3:{ 12 "edges":[2], 13 "weights":[2]} 14 } 15 16def convert_to_csr(graph): 17 num_nodes = len(graph) 18 19 offsets = [] 20 edges = [] 21 weights = [] 22 23 cur_offset = 0 24 for node in range(num_nodes): 25 offsets.append(cur_offset) 26 cur_offset += len(graph[node]["edges"]) 27 28 edges = edges + graph[node]["edges"] 29 weights = weights + graph[node]["weights"] 30 31 offsets.append(cur_offset) 32 33 return offsets, edges, weights 34 35offsets, edges, weights = convert_to_csr(graph) 36print(f"offsets = {offsets}") 37print(f"edges = {edges}") 38print(f"weights = {weights}")
What is a mixed fleet?
In some cases, not all vehicles within a fleet are identical. Some might travel faster, while others might incur unaffordable costs when traveling through certain areas. For example, we could have a fleet consisting of planes and trucks.
vehicle_typescan be used along with data such as cost/time matrix for each of the vehicles. Given the example above, planes would have one cost/time matrix, while trucks would have a different cost/time matrix.
How to get partially feasible solutions to infeasible problems?
Use Prize collection, which associates each task with a prize and the solver will maximize the prize collected. This allows cuOpt to prioritize some tasks over others.
What is a dimension mismatch error?
Some of the metrics need to be equal in size; for example, the number of tasks and their demand. If they don’t match, it means the problem is partially defined or there is an issue with the data.
cuOpt resource estimates; how large a problem can I run with a given set of constraints?
For the standard CVRPTW (Capacitated Vehicle Routing Problem with Time Windows) problem with real-world constraints, cuOpt can easily solve for 15K locations with the NVIDIA GPU A100/H100.
Not getting the same solution in every run: Determinism?
cuOpt routing solver is not deterministic, so the results might vary across multiple runs. Increasing the time limit set for the solver will increase the likelihood of getting identical results across multiple runs.
Also, there might be several different solutions with the same cost.
How do we account for dynamic changing constraints?
cuOpt is stateless and cannot handle dynamic constraints directly, but this can be resolved with modeling.
Dynamic reoptimization is used when there is a change in the conditions of the operation such as a vehicle getting broken, a driver calling in sick, a road block, traffic, or a high-priority order coming in.
The problem is prepped in such a way that the packages that are already en route are assigned to only those vehicles, and new and old deliveries will be added to this problem. Please refer to example notebooks in cuOpt Resources to understand more about how to tackle this problem.
Does cuOpt take an initial solution?
Currently, cuOpt doesn’t accept the initial solution.
Do we need to normalize the data when creating a time window matrix?
The units can be whatever the customer wants them to be: minutes, seconds, milliseconds, hours, and so on. It is the user’s responsibility to normalize the data across the complete problem, so all time-related constraints use the same unit. For example, if the travel time matrix is given in minutes, we want to make sure time windows and service times are also given in minutes.
Is there a way to prevent vehicles from traveling along the same path in a waypoint graph, or is there a way to prevent more than one vehicle from visiting a location, or even that a location is only visited one time by a single vehicle?
Currently, we do not have such restrictions, and cuOpt tries to optimize for the fewest number of vehicles as the primary default objective.
Travel time deviation: When using the same dataset, the travel time varies by a couple of seconds in different runs, but the distance remains the same. How can travel time deviate in multiple runs on the same data and distance remains constant?
This is because travel time is not part of the objective, so we could have two solutions that are equivalent when picking the best solution. You can include total travel time (includes wait time) as part of the objective.
There is no path between two locations, how do I input this information to the solver?
Set high values compared to other actual values, not max of float type.
This will ensure this path would not be traversed since it will incur a huge cost.
Floating point vs. integers for specifying task locations?
The documentation says task_locations should be integers. But in the real world, latitude and longitude coordinates are floating point values. To explain this, read the following section.
cuOpt expects that a user provides either:
A cost matrix and corresponding location indices.
A waypoint graph and locations corresponding to waypoints as integers.
So in either case, task locations are actually integer indices into another structure.
If you have (lat, long) values, then you can generate a cost matrix using a map API. cuOpt does not directly connect to a third-party map engine, but that can be done outside of cuOpt and the resulting cost matrix passed in.
Is it possible to define constraints such as refrigerated vehicles required for certain orders?
Yes, you can define constraints to match vehicles to order type using vehicle_order_match. Frozen goods are a great example.
How do we model the following scenario: Pick up from multiple different locations and deliver to a single customer?
This can be observed as a pickup and delivery problem.
I know that the problem has a feasible solution, but cuOpt returns an infeasible solution. How do I avoid this?
The time limit could be too short.
An infeasible solution always provides information about what constraints caused it and which constraint can be relaxed, which might give more hints.
How to set prize collection to deliver as many orders as possible ?
Set all prize values = 1 with a very high prize objective (like 10^6), and then set the other objective values for cost, travel_time, and route_variance proportional to each other for cuOpt to always return the best possible solution.
What are the limitations of the routing solver?
The routing solver capabilities are based on few factors:
The available GPU memory
- The size of the problem
Number of locations
Number of vehicles
Number of tasks
- The complexity of the problem
Number of demand and capacity constraints
Number of time windows
Number of vehicle types
Number of breaks
The time limit
Depending on these factors, the problems that can be solved can vary, for example:
On a H100 SXM with 80GB memory, the maximum number of locations that routing solver can handle is 10,000.
At the same time, depending on complexity, the solver might be able to handle more or less than 10,000 locations.
Linear Programming FAQs#
How small and how many problems can I give when using the batch mode?
LP batch mode is deprecated; see Batch Mode in Convex Optimization Features.
The batch mode allows solving many LPs in parallel to try to fully utilize the GPU when LP problems are too small. Using H100 SXM, the problem should be of at least 1K elements, and giving more than 100 LPs will usually not increase performance.
Can the solver run on dense problems?
Yes, but we usually see great results on very large and sparse problems.
How large can the problem be?
If run on a H100 SXM 80GB (hardware used when using NVIDIA Cloud Functions), you can run the following sizes:
4.5M rows/constraints; 4.5M columns/variables; and 900M non-zeros in the constraint matrix
36M rows/constraints; 36M columns/variables; and 720M non-zeros in the constraint matrix
How can I get the best performance?
There are several ways to tune the solver to get the best possible performance:
Hardware: If using self-hosted, you should use a recent server-grade GPU. We recommend H100 SXM (not the PCIE version).
Tolerance: The set tolerance usually has a massive impact on performance. Try the lowest possible value using
set_optimality_toleranceuntil you have reached your lowest possible acceptable accuracy.PDLP Solver mode: PDLP solver mode will change the way PDLP internally optimizes the problem. The mode choice can drastically impact how fast a specific problem will be solved. You should test the different modes to see which one fits your problem best.
Batch mode: Deprecated for LP; prefer sequential
cuopt.linear_programming.Solvecalls (see Batch Mode). While available, batch mode can solve multiple LPs in parallel.Presolve: Presolve can reduce problem size and improve solve time.
What solver mode should I choose?
We cannot predict up-front which solver mode will work best for a particular problem. The only way to know is to test. Once you know a solver mode is good on a class of problems, it should also be good on other similar problems.
What tolerance should I use?
The choice entirely depends on the level of accuracy you need for your problem. A looser tolerance will always result in a faster result. For PDLP, 1e-2 relative tolerance is low accuracy, 1e-4 is regular, 1e-6 is high, and 1e-8 is very high.
What are the limitations of the LP solver?
There is no inherit limit imposed on the number of variables, number of constraints, or number of non-zeros you can have in a MILP or LP, except the restrictions due to the number of bits in an integer and the amount of memory in the CPU and GPU.
Depending on these factors, the problems that can be solved can vary, for example:
- On a H100 SXM with 80GB memory, here are few examples of the problems that can be solved:
10M rows/constraints, 10M columns/variables, and 2B non-zeros in the constraint matrix.
74.5M rows/constraints, 74.5M columns/variables, and 1.49B non-zeros in the constraint matrix.
Does cuOpt implement presolve reductions?
cuOpt supports presolve reductions using PSLP or Papilo for linear programming (LP) problems, and Papilo for mixed-integer programming (MIP) problems. For MIP problems, Papilo presolve is always enabled by default. For LP problems, PSLP presolve is always enabled by default. Presolve is controlled by the CUOPT_PRESOLVE setting.
How do I use warm start with PDLP?
To use warm start functionality with PDLP, you must explicitly disable presolve by setting CUOPT_PRESOLVE=0 in solver_config.
This is required because presolve transforms the problem, and the warm start solution from the original problem
cannot be applied to the presolved problem.
Mixed Integer Linear Programming FAQs#
How do I run the MIP solver with cuOpt?
You can run the cuOpt MIP solver through the Python, C, CLI, or server APIs by providing a model with integer or binary variables. The cuOpt MIP solver is in beta and under active development. The solver currently excels at finding high-quality feasible solutions quickly with GPU-accelerated primal heuristics. Proving feasible solutions optimal remains under active development.
What are the limitations of the MILP solver?
There is no inherit limit imposed on the number of variables, number of constraints, or number of non-zeros you can have in a MILP or LP, except the restrictions due to the number of bits in integer and the amount of memory in the CPU and GPU.
Depending on these factors, the problems that can be solved can vary, for example:
- On a H100 SXM with 80GB memory, this is the biggest dataset that was tested:
27 million non-zeros coefficients on a problem from MIPLIB2017.
Container FAQs#
How do I share only selected GPUs in a container?
You can share only selected GPUs in a container by using the --gpus flag. For example, to share only the first GPU, you can use the following command:
docker run --gpus '"device=0,1"' <image>
How do I run cuOpt container with options set as environment variables?
You can run cuOpt container with options set as environment variables by using the --env flag. For example, to set the time limit to 1000 seconds, you can use the following command:
mkdir data
mkdir result
docker run -v `pwd`/data:/cuopt_data \
-v `pwd`/results:/cuopt_results \
-e "CUOPT_DATA_DIR=/cuopt_data" \
-e "CUOPT_RESULT_DIR=/cuopt_result" \
-e CUOPT_MAX_RESULT=0 \
-e CUOPT_SERVER_PORT=8081 \
-p 8081:8081 \
<image> \
/bin/bash -c "python -m cuopt_server.cuopt_server"