Blackwell Cluster Launch Control#
Overview#
A GEMM workload usually consists of three phases: prologue, mainloop and epilogue. Each SM will process multiple output tiles in series if the number of output tiles are much more than the number of SMs, completely exposing the overhead of prologue and epilogue.
Consider a GEMM that has 20x20x1 output tiles, running on a GPU with 100 SMs. There is another kernel occupying all the resources of 20 SMs so only 80 SMs can be used. Assume cluster shape is 1x1x1. The following diagram shows how the schedule would look like for such a kernel.
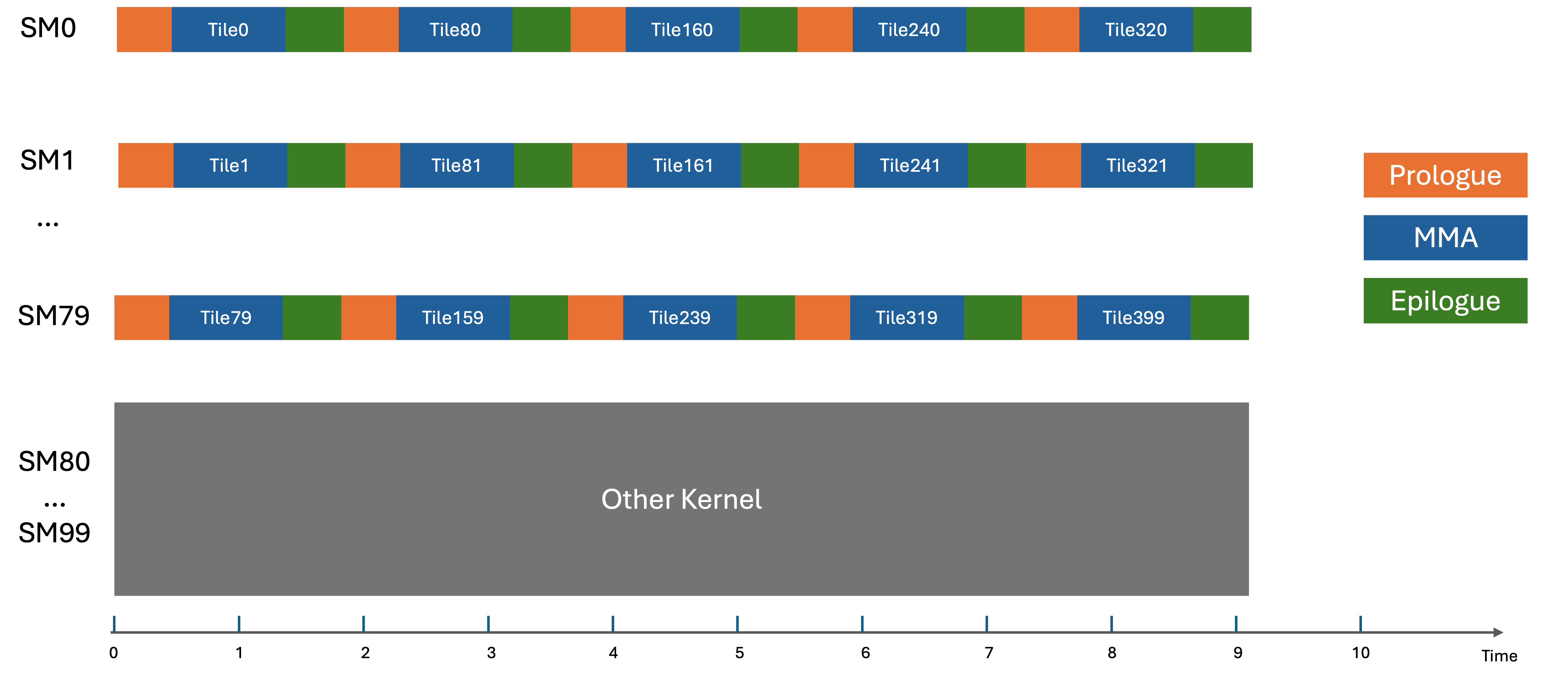
Static Scheduler#
CUTLASS has adopted a software technique named persistent kernels. Persistent clusters, or Workers, can stay on the GPU throughout kernel execution and process multiple tiles, hiding prologue and epilogue costs. The tile scheduler statically determines the next output tile to process with zero overhead.
However, static scheduler is susceptible to workload imbalance if the resources of some SMs are unavailable. The following diagram illustrates this issue.
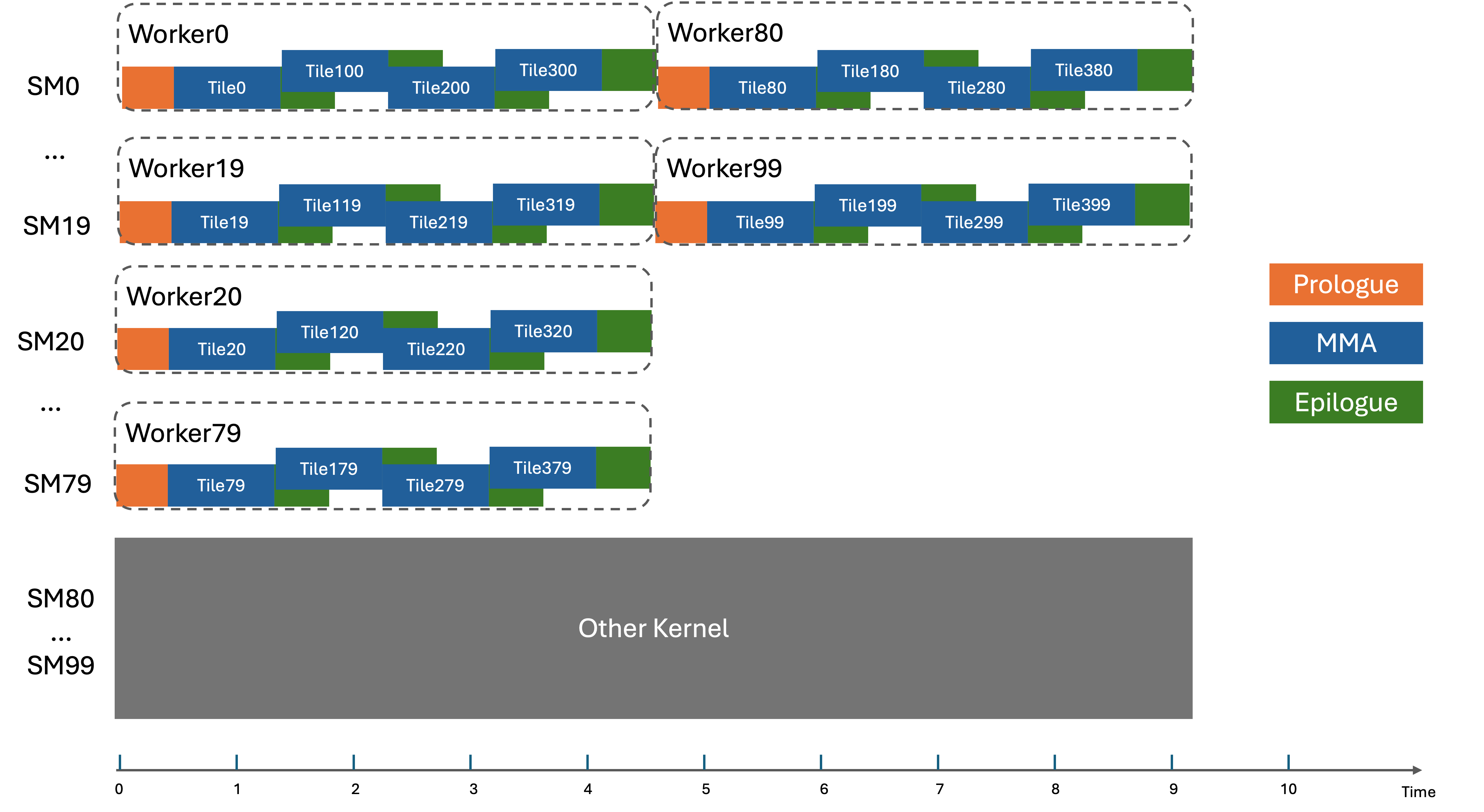
Dynamic Scheduler with Cluster Launch Control#
A fundamental limitation of persistent scheduling is that the number of SMs this kernel can utilize is unknown in real time. Some SMs might be occupied by another kernel and thus their resources are unavailable. This makes it challenging to load-balance work across SMs.
Blackwell introduces cluster launch control (CLC) for dynamic scheduling. (See https://docs.nvidia.com/cuda/parallel-thread-execution). With this feature, the kernel launches a grid containing as many threadblocks as there are output tiles to compute in the kernel – just like one would in a non-persistent kernel. Here we define ClcID to be a coordinate from the 3D grid launched on GPU.
Cluster launch control follows the below rules:
A
ClcIDwill be launched as a Worker when there are available resources.A
ClcIDcan be queried by an existing Worker viaclusterlaunchcontrol.try_cancelinstruction.Every
ClcIDis guaranteed to be processed by either (1) or (2).Each worker uses the
{blockIdx.x, blockIdx.y, blockIdx.z}coordinate as the first output tile to process and uses the CLC query for subsequent processing of output tiles.clusterlaunchcontrol.try_cancelinstruction returns either a success signal with aClcIDor a decline signal. The most common reason of a decline is that allClcIDs have been processed.Cluster launch control works on the granularity of clusters. For example, a 2x2 persistent worker cluster’s query will consume 2x2
ClcIDs at once.
The following diagram shows how the schedule would look like with cluster launch control.
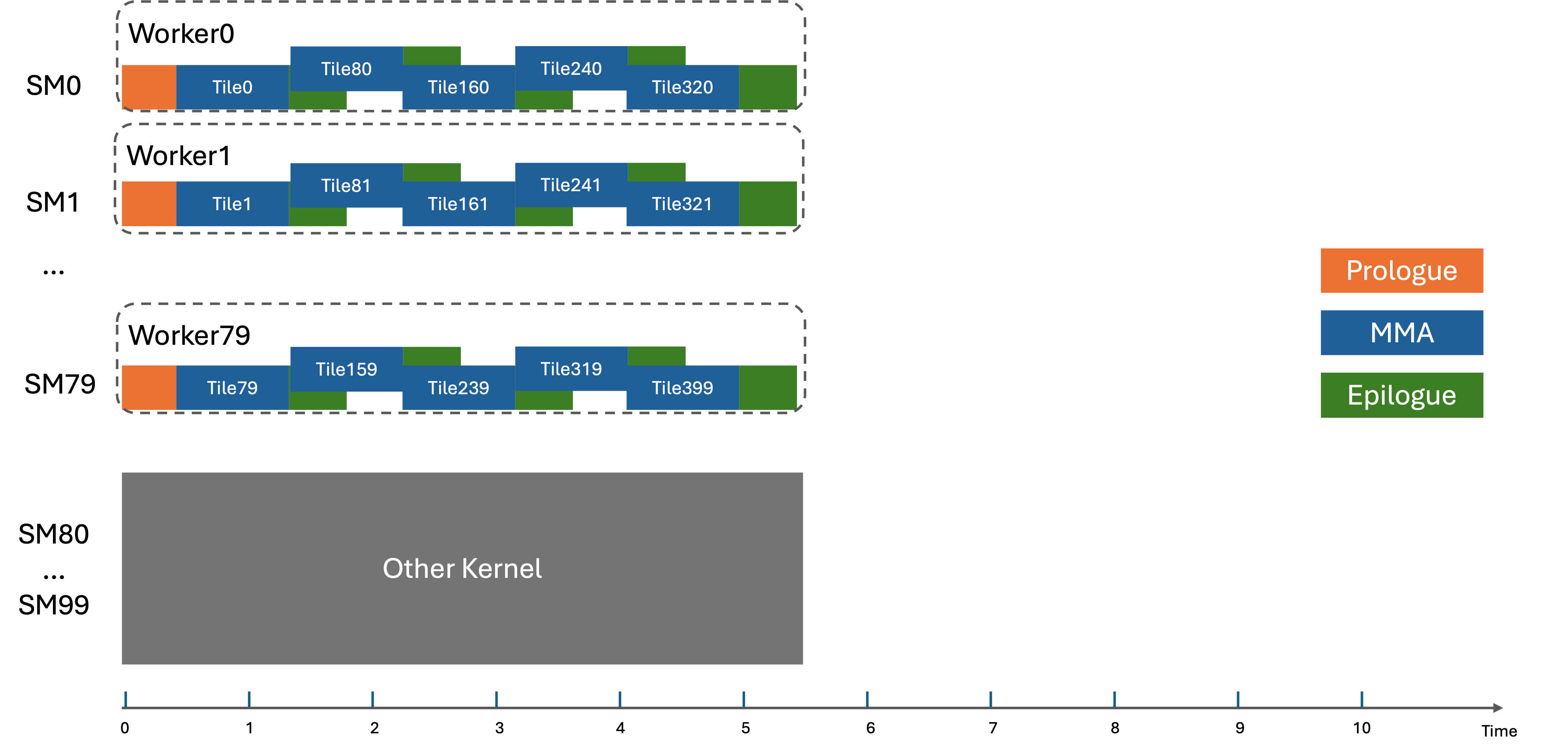
Programming Model#
Pseudo Code#
Non-persistent kernel#
// Non-persistent kernel
__device__ non_persistent_kernel(...) {
setup_common_data_structures();
dim3 workCoordinates = blockIdx;
coordinate_specific_compute(workCoordinates);
}
Static Persistent Kernel#
// Static Persistent Kernel
__device__ static_persistent_kernel(...) {
setup_common_data_structures(...);
dim3 workCoordinates = blockIdx;
bool isValidId;
do {
coordinate_specific_compute(workCoordinates);
std::tie(isValidId, workCoordinates) = staticTileScheduler.fetch_next_work();
} while (isValidId);
}
Blackwell Dynamic Persistent Kernel#
// Dynamic Persistent Kernel
__device__ clc_dynamic_persistent_kernel(...) {
setup_common_data_structures(...);
dim3 workCoordinates = blockIdx;
dim3 newClcID;
bool isValidId;
do {
coordinate_specific_compute(workCoordinates);
std::tie(isValidId, newClcID) = clcTileScheduler.fetch_next_work();
workCoordinates = newClcID;
} while (isValidId);
}
Cluster Launch Control Pipeline Class#
Please refer to the PipelineCLCFetchAsync pipeline class defined in Cluster launch control pipeline class. Cluster launch control queries can be pipelined and managed by an asynchronous pipeline with producer-consumer relationship (See
pipeline document). The producer is the scheduler warp of the 0th CTA in the cluster and the consumers are all warps that need ClcIDs.
To setup a CLC pipeline correctly, we need to make sure the params are set to the right values:
transaction_bytesis16as CLC will return a 16B response and store it in the specified shared memory address.consumer_arv_countis the thread count of all the consumer warps in the cluster.producer_arv_countis1because only one thread from scheduler warp will be elected to issueclusterlaunchcontrol.try_cancel.producer_blockidis0to denote that the first CTA in the cluster is producing.
Dynamic tile scheduler class#
Please refer to PersistentTileSchedulerSm100 class defined in sm100 dynamic persistent tile scheduler.
There are two important methods of the CLC scheduler class. The first is advance_to_next_work, which is intended to be executed by one elected thread from the scheduler warp. It effectively sends out the CLC query to the CLC. A CLC query response will be broadcast to the same shared memory address of all CTAs in the cluster.
The other method is named get_current_work. It simply loads the CLC response from the shared memory buffer indexed by a pipeline state.
The CLC pipeline and scheduler classes are used together to ensure correct functionality and necessary synchronization of CLC feature. Please refer to cluster launch control pipeline unit test.
Blackwell Warp-specialized Persistent Kernel#
Now, let’s take a look at how CLC feature is used in our Blackwell dense GEMM kernel.
This particular warp-specialized kernel has the following warp assignment:
Warp Role |
Warp |
|---|---|
MMA |
0 |
Scheduler |
1 |
Mainloop Load |
2 |
Epilogue Load |
3 |
Epilogue |
4, 5, 6, 7 |
Scheduler warp is the producer of the CLC pipeline. The consumers are the MMA, Mainloop Load, Epilogue Load and Epilogue warps. In addition, the scheduler warp is its own consumer! This is because it needs the success information from the query to terminate the persistent loop on end-of-grid.
The CLC pipeline has a depth of 3 to overlap the CLC operations of multiple waves for latency hiding. The first ClcID is the preloaded blockIdx, which does not require CLC query and is fully static.
Copyright#
Copyright (c) 2025 - 2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved. SPDX-License-Identifier: BSD-3-Clause
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.