Odds and Ends
This section includes a random set of topics and concepts.
Thread Safety
The cuDNN library is thread-safe. Its functions can be called from multiple host threads, so long as the threads do not share the same cuDNN handle simultaneously.
When creating a per-thread cuDNN handle, it is recommended that a single synchronous call of cudnnCreate() be made first before each thread creates its own handle asynchronously.
Per cudnnCreate(), for multi-threaded applications that use the same device from different threads, the recommended programming model is to create one (or a few, as is convenient) cuDNN handles per thread and use that cuDNN handle for the entire life of the thread.
Reproducibility (Determinism)
By design, most of cuDNN’s routines from a given version generate the same bit-wise results across runs when executed on GPUs with the same architecture. There are some exceptions. For example, the following routines do not guarantee reproducibility across runs, even on the same architecture, because they use atomic operations in a way that introduces truly random floating point rounding errors:
cudnnConvolutionBackwardFilterwhenCUDNN_CONVOLUTION_BWD_FILTER_ALGO_0orCUDNN_CONVOLUTION_BWD_FILTER_ALGO_3is used
cudnnConvolutionBackwardDatawhenCUDNN_CONVOLUTION_BWD_DATA_ALGO_0is used
cudnnPoolingBackwardwhenCUDNN_POOLING_MAXis used
cudnnSpatialTfSamplerBackward
cudnnCTCLossandcudnnCTCLoss_v8whenCUDNN_CTC_LOSS_ALGO_NON_DETERMINSTICis used
Across different architectures, no cuDNN routines guarantee bitwise reproducibility. For example, there is no guarantee of bitwise reproducibility when comparing the same routine run on NVIDIA Volta and NVIDIA Turing architecture.
Scaling Parameters
Many cuDNN routines like cudnnConvolutionForward() accept pointers in host memory to scaling factors alpha and beta. These scaling factors are used to blend the computed values with the prior values in the destination tensor as follows:
dstValue = alpha*computedValue + beta*priorDstValue
The dstValue is written to after being read.
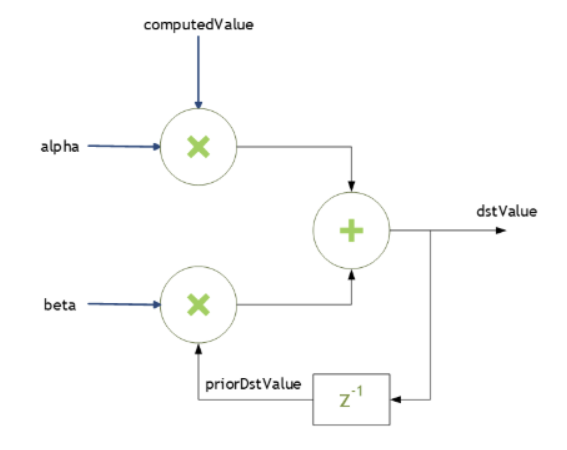
When beta is zero, the output is not read and may contain uninitialized data (including NaN).
These parameters are passed using a host memory pointer. The storage data types for alpha and beta are:
floatforHALFandFLOATtensors, and
doubleforDOUBLEtensors.
For improved performance use beta = 0.0. Use a non-zero value for beta only when you need to blend the current output tensor values with the prior values of the output tensor.
Type Conversion
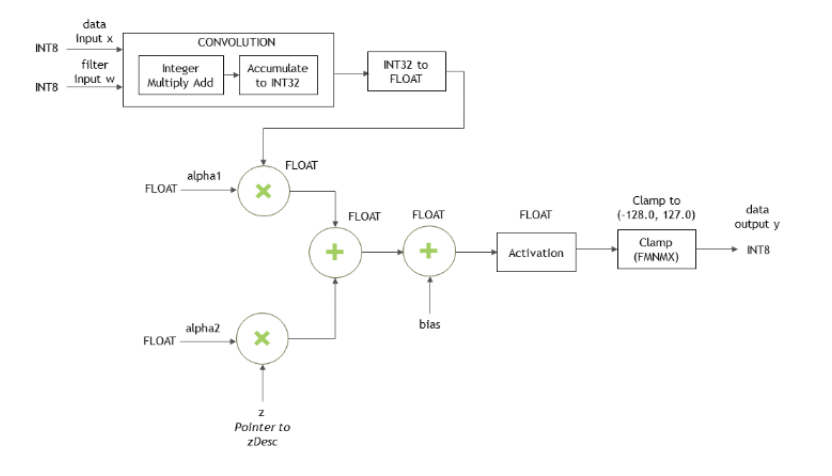
When the data input x, the filter input w, and the output y are all in INT8 data type, the function cudnnConvolutionBiasActivationForward() will perform the type conversion. Accumulators are 32-bit integers that wrap on overflow.
cuDNN API Compatibility
Beginning in cuDNN 7, the binary compatibility of a patch and minor releases is maintained as follows:
Any patch release x.y.z is forward or backward-compatible with applications built against another cuDNN patch release x.y.w (meaning, of the same major and minor version number, but having w!=z).
cuDNN minor releases are binary backward-compatible with applications built against the same or earlier minor release (meaning, cuDNN x.y is binary compatible with an app built against cuDNN x.z, where z<=y).
Applications compiled with a cuDNN version x.z are not guaranteed to work with x.y release when z>y.
Deprecation Policy
- cuDNN uses a streamlined, two-step, deprecation policy for all API and enum changes to enable a fast pace of innovation:
- Step 1: Label for deprecation
The current major version marks an API function or enum as deprecated without changing its behavior.
A deprecated enum value is marked with the
CUDNN_DEPRECATED_ENUMmacro.If it is simply renamed, the old name will map to the new name, and the old name will be marked with the
CUDNN_DEPRECATED_ENUMmacro.
A deprecated API function is marked with the CUDNN_DEPRECATED macro.
- Step 2: Removal
The next major version removes the deprecated API function or enum value and its name is never reused.
This depreciation scheme allows us to retire the deprecated API in just one major release. Functionality that is deprecated in the current major release can be compiled without any changes.The backward compatibility ends when another major cuDNN release is introduced.
Prototypes of deprecated functions will be prepended in cuDNNs headers using the CUDNN_DEPRECATED macro. When the -DCUDNN_WARN_DEPRECATED switch is passed to the compiler, any deprecated function call in your code will emit a compiler warning, for example:
warning: 'cudnnStatus_t cudnnRNNSetClip_v8(cudnnRNNDescriptor_t, cudnnRNNClipMode_t, ...)' is deprecated [-Wdeprecated-declarations]
or
warning C4996: 'cudnnRNNSetClip_v8': was declared deprecated
The above warnings are disabled by default to avoid potential build breaks in software setups where compiler warnings are treated as errors.
Similarly, for deprecated enum values, the compiler emits a warning when attempting to use a deprecated value:
warning: 'EXAMPLE_VAL' is deprecated: value not allowed [-Wdeprecated-declarations]
or
warning C4996: 'EXAMPLE_VAL': was declared deprecated
Special Case: API Behavior Change
To help ease the transition and avoid any surprises to developers, a behavior change between two major versions of a specific API function is accommodated by suffixing the function with a _v tag followed by the current, major cuDNN version. In the next major release, the deprecated function is removed, and its name is never reused. (Brand-new APIs are first introduced without the _v tag).
Updating a function’s behavior in this way uses the APIs name to embed the cuDNN version where the API call was modified. As a result, the API changes will be easier to track and document.
Let us explain this process through an example using two subsequent, major cuDNN releases, version 8 and 9. In this example, an API function foo() changes its behavior from cuDNN v7 to cuDNN v8.
Major Release 8
The updated API is introduced as foo_v8(). The deprecated API foo() is kept unchanged to maintain backward compatibility until the next major release.
Major Release 9
The deprecated API foo() is permanently removed and its name is not reused. The foo_v8() function supersedes the retired call foo().
GPU And Driver Requirements
For the latest compatibility software versions of the OS, CUDA, the CUDA driver, and the NVIDIA hardware, refer to the cuDNN Support Matrix.
Conventions And Features For Convolutions
The convolution functions are:
Convolution Formulas
This section describes the various convolution formulas implemented in cuDNN convolution functions for the cudnnConvolutionForward() path.
The convolution terms described in the table below apply to all the convolution formulas that follow.
Term |
Description |
|---|---|
|
Input (image) Tensor |
|
Weight Tensor |
|
Output Tensor |
|
Current Batch Size |
|
Current Input Channel |
|
Total Input Channels |
|
Input Image Height |
|
Input Image Width |
|
Current Output Channel |
|
Total Output Channels |
|
Current Output Height Position |
|
Current Output Width Position |
|
Group Count |
|
Padding Value |
|
Vertical Subsample Stride (along Height) |
|
Horizontal Subsample Stride (along Width) |
dil h |
Vertical Dilation (along Height) |
dil w |
Horizontal Dilation (along Width) |
|
Current Filter Height |
|
Total Filter Height |
|
Current Filter Width |
|
Total Filter Width |
C g |
\(\frac{C}{G}\) |
K g |
\(\frac{K}{G}\) |
- Convolution (convolution mode set to
CUDNN_CROSS_CORRELATION) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r,q+s}\times W_{k,c,r,s}\)
- Convolution with Padding
\(x_{\lt 0,\lt 0}=0\) \(x_{\gt H,\gt W}=0\) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r-pad,q+s-pad}\times W_{k,c,r,s}\)
- Convolution with Subsample-Striding
\(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,\left( p\ast u \right)+r,\left( q\ast v \right)+s}\times W_{k,c,r,s}\)
- Convolution with Dilation
\(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+\left( r\ast dil_{h} \right),q+\left( s\ast dil_{w} \right)}\times W_{k,c,r,s}\)
- Convolution (convolution mode set to
CUDNN_CONVOLUTION) \(y_{n,k,p,q}=\sum_{c}^{C}\sum_{r}^{R}\sum_{s}^{S} x_{n,c,p+r,q+s}\times W_{k,c,R-r-1,S-s-1}\)
- Convolution using Grouped Convolution
\(C_{g}=\frac{C}{G}\) \(K_{g}=\frac{K}{G}\) \(y_{n,k,p,q}=\sum_{c}^{C_{g}}\sum_{r}^{R}\sum_{s}^{S} x_{n,C_{g}\ast floor\left( k/K_{g} \right)+c,p+r,q+s}\times W_{k,c,r,s}\)
Grouped Convolutions
cuDNN supports grouped convolutions by setting groupCount > 1 for the convolution descriptor convDesc, using cudnnSetConvolutionGroupCount(). By default, the convolution descriptor convDesc is set to groupCount of 1.
Basic Idea
Conceptually, in grouped convolutions, the input channels and the filter channels are split into a groupCount number of independent groups, with each group having a reduced number of channels. The convolution operation is then performed separately on these input and filter groups. For example, consider the following: if the number of input channels is 4, and the number of filter channels is 12. For a normal, ungrouped convolution, the number of computation operations performed are 12*4.
If the groupCount is set to 2, then there are now two input channel groups of two input channels each, and two filter channel groups of six filter channels each. As a result, each grouped convolution will now perform 2*6 computation operations, and two such grouped convolutions are performed. Hence the computation savings are 2x: (12*4)/(2*(2*6)).
cuDNN Grouped Convolution
When using groupCount for grouped convolutions, you must still define all tensor descriptors so that they describe the size of the entire convolution, instead of specifying the sizes per group.
Grouped convolutions are supported for all formats that are currently supported by the functions cudnnConvolutionForward(), cudnnConvolutionBackwardData(), and cudnnConvolutionBackwardFilter().
The tensor stridings that are set for groupCount of 1 are also valid for any group count.
By default, the convolution descriptor convDesc is set to groupCount of 1. Refer to Convolution Formulas for the math behind the cuDNN grouped convolution.
Example
Below is an example showing the dimensions and strides for grouped convolutions for NCHW format, for 2D convolution. The symbols * and / are used to indicate multiplication and division.
xDesc or dxDesc
Dimensions:
[batch_size, input_channel, x_height, x_width]Strides:
[input_channels*x_height*x_width, x_height*x_width, x_width, 1]
wDesc or dwDesc
Dimensions:
[output_channels, input_channels/groupCount, w_height, w_width]Format:
NCHW
convDesc
Group Count:
groupCount
yDesc or dyDesc
Dimensions:
[batch_size, output_channels, y_height, y_width]Strides:
[output_channels*y_height*y_width, y_height*y_width, y_width, 1]
Best Practices for 3D Convolutions
Attention
These guidelines are applicable to 3D convolution and deconvolution functions starting in NVIDIA cuDNN v7.6.3.
The following guidelines are for setting the cuDNN library parameters to enhance the performance of 3D convolutions. Specifically, these guidelines are focused on settings such as filter sizes, padding and dilation settings. Additionally, an application-specific use-case, namely, medical imaging, is presented to demonstrate the performance enhancement of 3D convolutions with these recommended settings.
Specifically, these guidelines are applicable to the following functions and their associated data types:
For more information, refer to the cuDNN API Reference.
Recommended Settings
The following table shows the recommended settings while performing 3D convolutions for cuDNN.
Recommended Setting |
|
|---|---|
Platform |
|
Convolution (3D or 2D) |
3D and 2D |
Convolution or deconvolution ( |
|
Grouped convolution size |
|
Data layout format (NHWC/NCHW). NHWC/NCHW corresponds to NDHWC/NCDHW in 3D convolution. |
NDHWC |
I/O precision (FP16, FP32, INT8, or FP64) |
|
Accumulator (compute) precision (FP16, FP32, INT32 or FP64) |
|
Filter (kernel) sizes |
No limitation |
Padding |
No limitation |
Image sizes |
2 GB limitation for a tensor |
Number of |
|
Number of |
|
Convolution mode |
Cross-correlation and convolution |
Strides |
No limitation |
Dilation |
No limitation |
Data pointer alignment |
All data pointers are 16-bytes aligned. |
Limitations
Your application will be functional but could be less performant if the model has channel counts lower than 32 (gets worse the lower it is). If the above is in the network, use cuDNNFind* to get the best option.
Environment Variables
cuDNNs behavior can be influenced through a set of environment variables. The following environment variables are officially supported by cuDNN:
NVIDIA_TF32_OVERRIDE
CUDNN_LOGDEST_DBG
CUDNN_LOGLEVEL_DBG
CUDNN_LOGINFO_DBG(deprecated)
CUDNN_LOGWARN_DBG(deprecated)
CUDNN_LOGERR_DBG(deprecated)
CUDNN_FORWARD_COMPAT_DISABLE
For more information about these variables, refer to the cuDNN API Reference.
Note
Except for the environment variables listed above, we provide no support or guarantee on the use of any other environment variables prefixed by
CUDNN_.
SM Carveout
Starting in cuDNN 8.9.5, SM carveout is supported on NVIDIA Hopper GPUs, allowing expert users to reserve SMs for concurrent execution on a separate CUDA stream. Users can set a target SM count to cuDNN heuristics, and get a list of engine configs that will use that number of SMs during execution. For advanced use cases without cuDNN heuristics, users can also create the engine config from scratch with the SM carveout configured (the engines that support this feature are listed in the table below).
The following code snippet is a sample for heuristics use cases.
// Create heuristics descriptor cudnnBackendDescriptor_t engHeur; cudnnBackendCreateDescriptor(CUDNN_BACKEND_ENGINEHEUR_DESCRIPTOR, &engHeur); cudnnBackendSetAttribute(engHeur, CUDNN_ATTR_ENGINEHEUR_OPERATION_GRAPH, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &opGraph); cudnnBackendSetAttribute(engHeur, CUDNN_ATTR_ENGINEHEUR_MODE, CUDNN_TYPE_HEUR_MODE, 1, &heurMode); // SM carveout int32_t targetSMCount = 66; cudnnBackendSetAttribute(engHeur, CUDNN_ATTR_ENGINEHEUR_SM_COUNT_TARGET, CUDNN_TYPE_INT32, 1, &targetSMCount); cudnnBackendFinalize(engHeur); // Create engine config descriptor cudnnBackendDescriptor_t engConfig; cudnnBackendCreateDescriptor(CUDNN_BACKEND_ENGINECFG_DESCRIPTOR, &engConfig); // Retrieve optimal engine config(s) from heuristics cudnnBackendGetAttribute(engHeur, CUDNN_ATTR_ENGINEHEUR_RESULTS, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &returnedCount, engConfig); // "engConfig" should now be ready with target SM count as 66
This feature is currently supported by normal convolutions (Fprop, Dgrad, and Wgrad) as well as the Conv-Bias-Act fusions.
Convolution Forward |
Convolution Backward Data |
Convolution Backward Filter |
|
|---|---|---|---|
|
|
|
|
Version Checking Against CUDNN_VERSION
The definition of CUDNN_VERSION is:
CUDNN_MAJOR * 10000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL
from
CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL
Therefore, any version checking using CUDNN_VERSION should be updated accordingly. For example, if users want to exercise a code path only if cuDNN is greater or equal to 9.0.0, they will have to use the macro conditionals such as CUDNN_VERSION >= 90000 rather than CUDNN_VERSION >= 9000.
cuDNN Symbol Server
Obfuscated symbols for cuDNN libraries that are being debugged or profiled in your application can be downloaded from a repository of symbols for Linux. The repository hosts symbol files (.sym) that contain obscured symbol names (debug data is not distributed).
When an issue appears with a cuDNN API, using the symbol server to symbolize its stack trace can help speed up the debug process.
There are two recommended ways to use obfuscated symbols for each cuDNN library with the GNU Debugger (GDB):
By unstripping the library
By deploying the
.symfile as a separate debug information file
The following code illustrates the recommended ways to use obfuscated symbols on x86_64 Ubuntu 22.04:
# Determine the Build ID of the library $ readelf -n /usr/lib/x86_64-linux-gnu/libcudnn_graph.so # ... Build ID: 457c8f5dea095b0f90af2abddfcb69946df61b76 # Browse to https://cudatoolkit-symbols.nvidia.com/libcudnn_graph.so/457c8f5dea095b0f90af2abddfcb69946df61b76/index.html to determine .sym filename to download $ wget https://cudatoolkit-symbols.nvidia.com/libcudnn_graph.so/457c8f5dea095b0f90af2abddfcb69946df61b76/libcudnn_graph.so.9.0.0.sym # Then with appropriate permissions, either unstrip, $ eu-unstrip /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9.0.0 libcudnn_graph.so.9.0.0.sym -o /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9.0.0 # Or, with appropriate permissions, deploy as a separate debug info file # By splitting the Build ID into two parts, with the first two characters as the directory # And the remaining characters as the filename with the ".debug" extension $ cp libcudnn_graph.so.9.0.0.sym /usr/lib/debug/.build-id/45/7c8f5dea095b0f90af2abddfcb69946df61b76.debug
Example: Symbolizing
Here is a simplified example to show the uses of symbolizing. A sample application named test_shared calls the cuDNN API cudnnDestroy() which leads to a segmentation fault. With a default install of cuDNN and no obscured symbols, the output in GDB might look like the following:
Thread 1 "test_shared" received signal SIGSEGV, Segmentation fault. 0x00007ffff7a4ac01 in ?? () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 (gdb) bt #0 0x00007ffff7a4ac01 in ?? () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #1 0x00007ffff7a4c919 in cudnnDestroy () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #2 0x00000000004007b7 in main ()
After applying the obscured symbols in one of the ways described earlier, the stack trace will look like the following:
Thread 1 "test_shared" received signal SIGSEGV, Segmentation fault. 0x00007ffff7a4ac01 in libcudnn_graph_148ced18265f5231d89551dcbdcf5cf3fe6d77d1 () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 (gdb) bt #0 0x00007ffff7a4ac01 in libcudnn_graph_148ced18265f5231d89551dcbdcf5cf3fe6d77d1 () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #1 0x00007ffff7a4c919 in cudnnDestroy () from /usr/lib/x86_64-linux-gnu/libcudnn_graph.so.9 #2 0x00000000004007b7 in main ()
The symbolized call stack can then be documented as part of a bug description provided to NVIDIA for analysis.