Attention
This toolkit supports only Quantization Aware Training (QAT) as a quantization method.
Subclassed models are not supported in the current version of this toolkit. Original Keras layers are wrapped into quantized layers using TensorFlow's clone_model method, which doesn't support subclassed models.
Basics¶
Quantization Function¶
quantize_model is the only function the user needs to quantize any Keras model. It has the following signature:
(function) quantize_model:
(
model: tf.keras.Model,
quantization_mode: str = "full",
quantization_spec: QuantizationSpec = None,
custom_qdq_cases : List['CustomQDQInsertionCase'] = None
) -> tf.keras.Model
Note
Refer to the Python API for more details.
Example
import tensorflow as tf
from tensorflow_quantization import quantize_model, utils
assets = utils.CreateAssetsFolders("toolkit_basics")
assets.add_folder("example")
# 1. Create a simple model (baseline)
input_img = tf.keras.layers.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(filters=2, kernel_size=(3, 3))(input_img)
x = tf.keras.layers.ReLU()(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(10)(x)
model = tf.keras.Model(input_img, x)
# 2. Train model
model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 3. Save model and then convert it to ONNX
tf.keras.models.save_model(model, assets.example.fp32_saved_model)
utils.convert_saved_model_to_onnx(assets.example.fp32_saved_model, assets.example.fp32_onnx_model)
# 4. Quantize the model
q_model = quantize_model(model)
# 5. Train quantized model again for a few epochs to recover accuracy (fine-tuning).
q_model.fit(train_images, train_labels, batch_size=32, epochs=2, validation_split=0.1)
# 6. Save the quantized model with QDQ nodes inserted and then convert it to ONNX
tf.keras.models.save_model(q_model, assets.example.int8_saved_model)
utils.convert_saved_model_to_onnx(assets.example.int8_saved_model, assets.example.int8_onnx_model)
Note
The quantized model q_model behaves similar to the original Keras model, meaning that the compile() and fit() functions can also be used to easily fine-tune the model.
Refer to Getting Started: End to End for more details.
Saved ONNX files can be visualized with Netron. Figure 1, below, shows a snapshot of the original FP32 baseline model.
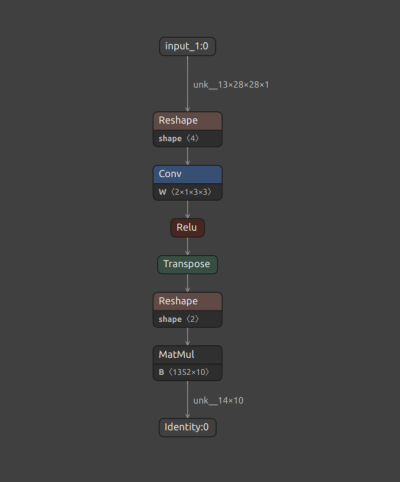
Figure 1. Original FP32 model.
The quantization process inserts Q/DQ
nodes at the inputs and weights (if layer is weighted) of all supported layers, according to the TensorRT™ quantization
policy.
The presence of a Quantize node (QuantizeLinear ONNX op), followed by a Dequantize node (DequantizeLinear ONNX op),
for each supported layer, can be verified in the Netron visualization in Figure 2 below.
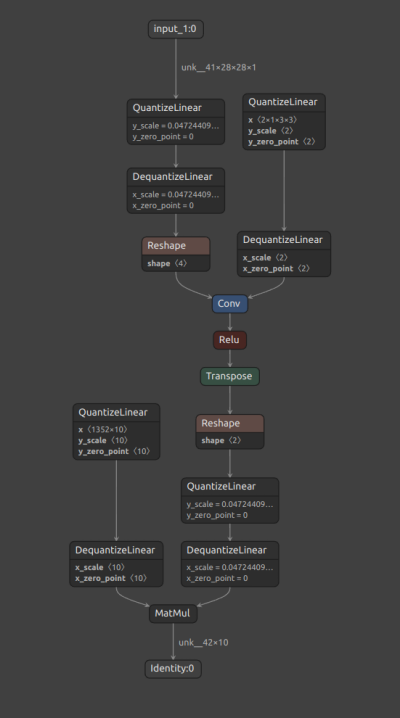
Figure 2. Quantized INT8 model.
TensorRT™ converts ONNX models with Q/DQ nodes into an INT8 engine, which can take advantage of Tensor Cores and other hardware accelerations in the latest NVIDIA® GPUs.
Quantization Modes¶
There are a few scenarios where one might need to customize the default quantization scheme.
We broadly categorize quantization (i.e. the process of adding Q/DQ nodes) into Full and Partial modes, depending on the set of layers that are quantized.
Additionally, Full quantization can be Default or Custom, while Partial quantization is always Custom.
- Full Default Quantization
All supported layers of a given model are quantized as per default toolkit behavior.
- Full Custom Quantization
Toolkit behavior can be programmed to quantize specific layers differentely by passing an object of
QuantizationSpecclass and/orCustomQDQInsertionCaseclass. The remaining supported layers are quantized as per default behavior.
- Partial Quantization
Only layers passed using
QuantizationSpecand/orCustomQDQInsertionCaseclass object are quantized.
Note
Refer to the Tutorials for examples on each mode.
Terminologies¶
Layer Name¶
Name of the Keras layer either assigned by the user or Keras. These are unique by default.
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
Here ‘my_dense’ is a layer name assigned by the user.
Tip
For a given layer l, the layer name can be found using l.name.
Layer Class¶
Name of the Keras layer class.
import tensorflow as tf
l = tf.keras.layers.Dense(units=100, name='my_dense')
Here ‘Dense’ is the layer class.
Tip
For a given layer l, the layer class can be found using l.__class__.__name__ or l.__class__.__module__.
NVIDIA® vs TensorFlow Toolkit¶
TFMOT is TensorFlow’s official quantization toolkit. The quantization recipe used by TFMOT is different to NVIDIA®’s in terms of Q/DQ nodes placement, and it is optimized for TFLite inference. The NVIDIA® quantization recipe, on the other hand, is optimized for TensorRT™, which leads to optimal model acceleration on NVIDIA® GPUs and hardware accelerators.
Other differences:
Feature |
TensorFlow Model Optimization Toolkit (TFMOT) |
NVIDIA® Toolkit |
|---|---|---|
QDQ node placements |
Outputs and Weights |
Inputs and Weights |
Quantization support |
Whole model (full) and of some layers (partial by layer class) |
Extends TF quantization support: partial quantization by layer name and pattern-base quantization by extending |
Quantization scheme |
|
|
Additional Resources¶
About this toolkit
GTC 2022 Tech Talk (NVIDIA)
Blogs
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware Training with NVIDIA TensorRT (NVIDIA)
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and NVIDIA TensorRT (NVIDIA)
Videos
Generate per-tensor dynamic range
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Quantizing Deep Convolutional Networks for Efficient Inference: A Whitepaper
8-bit Inference with TensorRT (NVIDIA)
Documentation (NVIDIA)