Migrate Slurm Scripts to DGX Cloud Lepton Jobs
Migrate Slurm scripts to DGX Cloud Lepton jobs, including job creation, resource allocation, and environment configuration.
Slurm to DGX Cloud Lepton Terminology
The following table outlines the key terminology mapping between Slurm and DGX Cloud Lepton for job migration.
| Slurm | DGX Cloud Lepton |
|---|---|
--job-name | Job Name |
--partition, --cluster, --qos | Node Group and Queue Priority |
--nodes (-N), --ntasks (-n) | Workers |
--gres=gpu:X, --cpus-per-task, --mem | Resource Shape |
--time | Job Timeout |
--constraint, --nodelist | Node Group / Node ID |
srun, mpirun command | Run Command (DGX Cloud Lepton will auto wrap with /bin/bash -c) |
--export, environment | Environment Variables and Secrets |
| Singularity / Docker Image | Container Image |
squeue, scancel | Jobs List and Stop Job |
| Job array, dependencies | Not Supported Yet |
Example
This example demonstrates how to migrate a Slurm script to a DGX Cloud Lepton job.
The following Slurm script launches an interactive job:
- Requests 1 node with 8 GPUs
- Uses a specific partition
- Runs a container from a Singularity image file
- Exports all current environment variables to the container
- Opens an interactive bash shell inside the container
Now, convert this to a batch job on DGX Cloud Lepton.
Create the Job on DGX Cloud Lepton
Navigate to the Create a Job page, and configure the following fields:
- Name:
test-jobas the job name configured in the Slurm script. - Resource:
- Select a node group with available GPUs. If you don't have one, refer to this guide to request a node group. For this example, we request 1 node with 8 GPUs, so we can select a GPU type like
H100-80GB-HBM3and specifyx8for the GPU count. - To specify the priority, click on the dropdown in the Resource section and select one of the priorities. Refer to this guide for more details.
- Set workers to
1. You can also specify a higher number of workers to accelerate the training process.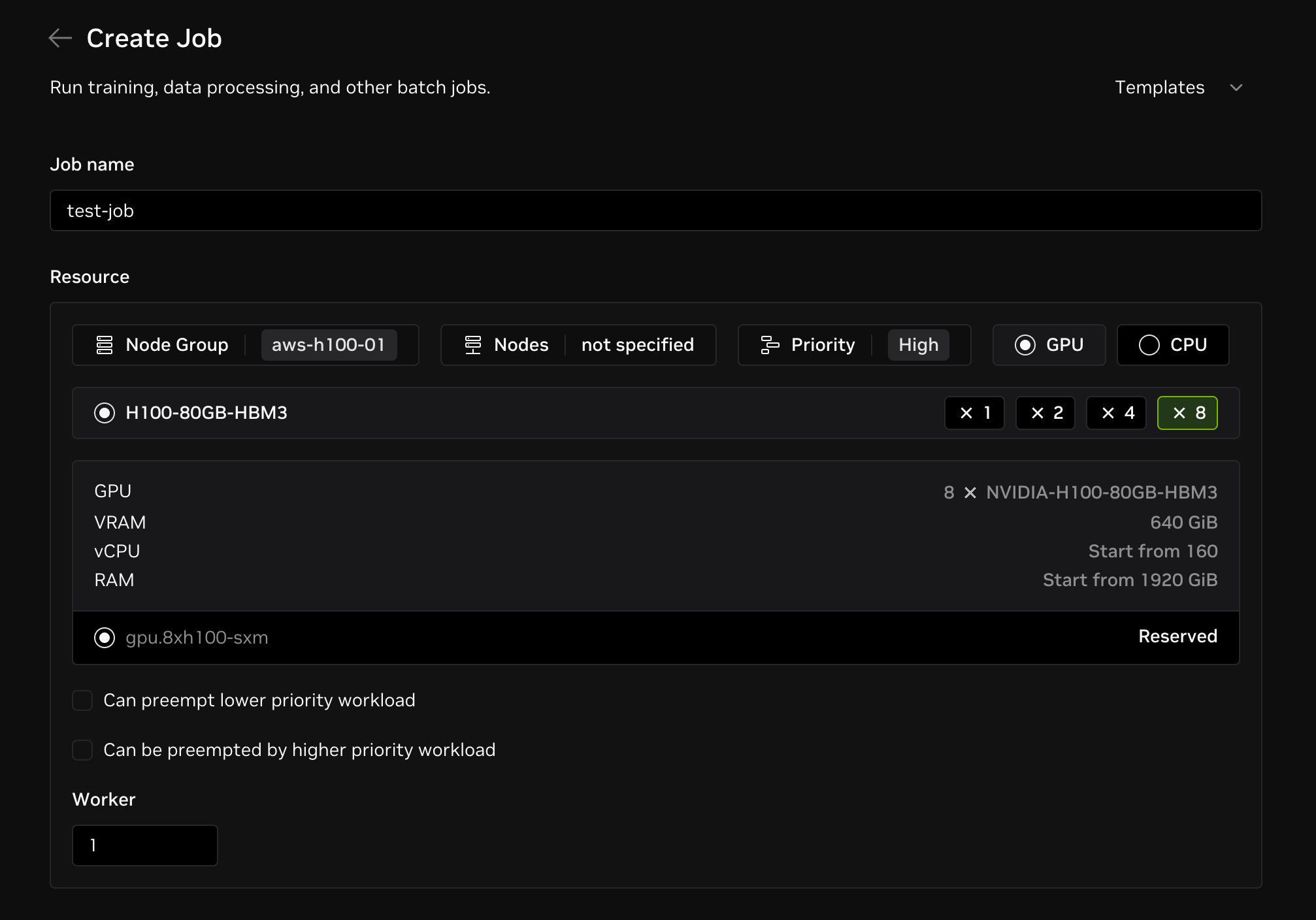
- Select a node group with available GPUs. If you don't have one, refer to this guide to request a node group. For this example, we request 1 node with 8 GPUs, so we can select a GPU type like
- Container Image: Specify the private container image in the Container section. For this example, use the default image.
- Advanced Settings: Configure advanced settings in the Advanced Settings section.
- Add environment variables and secrets under Environment Variables. For example, you can add
HUGGING_FACE_HUB_TOKENas a securely stored secret on DGX Cloud Lepton, which you can then reference as an environment variable within the container.
- Add environment variables and secrets under Environment Variables. For example, you can add
Create the job using the DGX Cloud Lepton CLI
Jobs can also be submitted using the Lepton CLI. Install the latest version of the CLI with the following command:
Once installed, the CLI can be invoked with lep. To see the list of available commands, run:
Taking the example srun command above, this can be invoked with the CLI as follows:
Breaking down each of the flags:
--name: This is the name of the job and is analogous to the--job-namecommand.--resource-shape: This describes what resources should be allocated in the container. For multi-GPU workloads, this comes in the formatgpu.Nx<gpu-type>whereNis the number of GPUs to allocate in the job and<gpu-type>is the name of the GPU to run on, such ash100-80gb. For single-GPU workloads, this would begpu.h100-80gb. The list of available resource shapes can be viewed withlep job create -hand viewing the--resource-shapeoption. This is analogous to the--gpus-per-nodeflag for Slurm.--node-group: This specifies which node group to run the job in. The list of available node groups can be found in the Nodes section of the DGX Cloud Lepton UI. This most closely resembles partitions in Slurm, but it goes further as different node groups could span different NVIDIA Cloud Providers (NCPs).--container-image: This is the container image to use for the job from a container registry, such asnvcr.io/nvidia/pytorch:YY.MM-py3. This is analogous to the--container-imagecommand in Slurm.--env: This is a key:value pair to add as an environment variable. Multiple environment variables can be set with multiple--envflags.--secret: You can specify a secret that is added to DGX Cloud Lepton to be usable in the job. Set theNAMEto the name that the secret will be set to inside the container, andSECRET_NAMEto the name of the secret in DGX Cloud Lepton.--command: This is the actual command to run inside the job. This can either be something likesleep infinityto let the job run indefinitely in the background and allow users to connect remotely to the container, or one or multiple commands strung together to be run on container start.
List Jobs
To list all jobs, run:
To list all jobs in some specific states, run:
Stop a Job
To stop a job, run:
Create 10 jobs