Moving Data from S3 Using s5cmd
Learn how to download data from S3 using s5cmd in a DGX Cloud Lepton batch job.
This example demonstrates how to create a batch job to download data from a private S3 bucket. A batch job workload is used due to the non-interactive nature of this task. The workload is configured with private information to access the S3 bucket and execute the commands necessary to install and run the s5cmd tool to download the data from that bucket to a mounted filestore.
Prerequisites
The following are required before running the data download workload:
- Storage associated with your node group
- A private S3 bucket with data you want to download
- AWS access credentials (access key ID and secret access key) with permissions to read from the S3 bucket
Create AWS Credentials
To securely provide AWS credentials to your workload, you'll need to create secrets in DGX Cloud Lepton.
- Navigate to the Settings page in your workspace and click Secrets on the left side.
- Click + New Secret and select Custom Secret.
- Configure the secret:
- Give it a descriptive name like
AWS_SECRET_ACCESS_KEY. - Set the value to your AWS secret access key.
- Set the visibility to Private if you do not want the secret to be used by other users in the workspace.
- Give it a descriptive name like
- Click Add to save.
- Repeat steps 2-4 for your AWS access key ID.
Create the Batch Job
Navigate to the create job page to configure your data download job.
Job Name: Set a descriptive name like s3-data-download.
Resource: Select the desired node group and resource shape. You can use a CPU-only resource for this workload.
Image: Use the built-in image.
Run Command: Copy the following script and replace your-s3-bucket-name-here with your actual S3 bucket name:
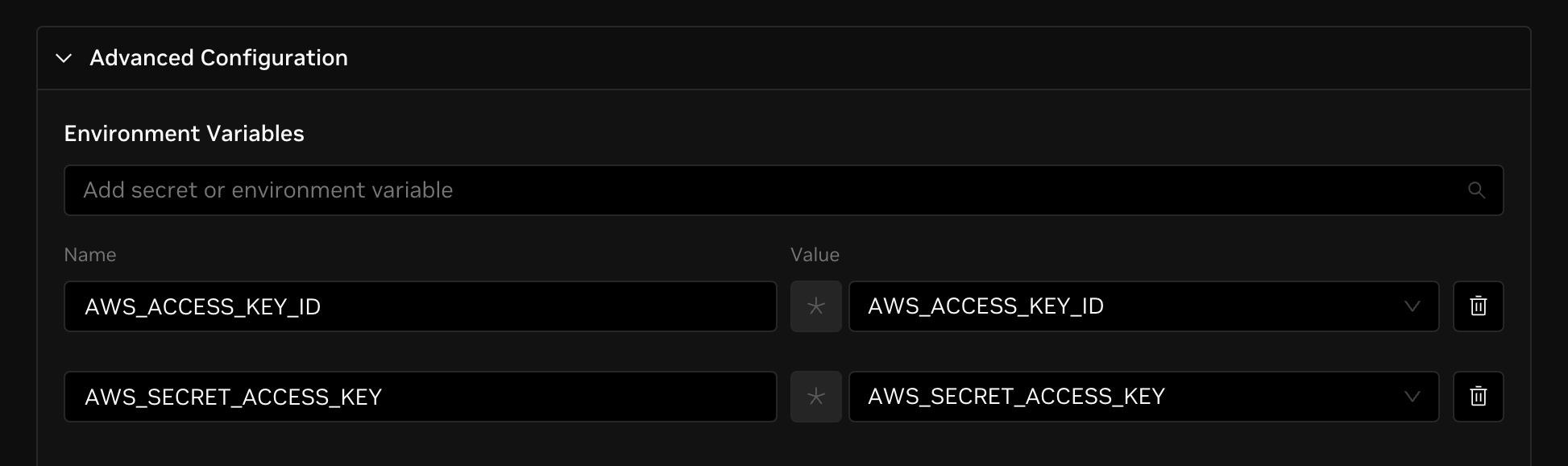
Select Advanced Configuration, go to Environment Variables, and click Add Secret. Add your AWS Access Key ID and secret access key as secrets. This should look like the image below.
In the Storage section, click + Mount Storage. Select the storage volume where you want to download the data. Input your desired from path and /dataset as the mount path.
Click CREATE to submit your job to the queue. The job will automatically start when cluster resources become available.
Monitor Progress
After creating the job, you will be redirected to the job overview page. Monitor the job status until the status shows "Completed".
Once the status shows "Completed", click on the job name and go to the LOGS tab to verify the data transfer was successful. The logs should show the s5cmd output indicating successful data transfer from your S3 bucket to the mounted storage.