Multi-LLM NIM Deployment
Learn how to deploy a multi-LLM compatible NIM on DGX Cloud Lepton.
Multi-LLM compatible NIM is a single container that supports a broad range of models for flexible deployment. The multi-LLM NIM container is recommended for models that NVIDIA has not yet created a specific container for. Models can be loaded from local storage, Hugging Face, or NGC. Refer to the official documentation for more information about NVIDIA NIM for LLMs.
Prerequisites
To run the Multi-LLM NIM, you need:
- Access to your NIM Container Registry and NGC API Key. For more information, refer to the setup information.
- Access to at least one NVIDIA A100 GPU or higher on DGX Cloud Lepton (actual GPU requirements depend on the model being deployed).
- A Hugging Face access token.
Create Endpoint from NVIDIA NIM
Navigate to the create endpoint page on the dashboard.
Specify a name for the endpoint in the Endpoint Name field.
Select the model to deploy by either loading the model from Hugging Face or from storage attached to your node group. To load a model hosted on Hugging Face, click the Load from Hugging Face button and enter or select the model repo, such as meta-llama/Llama-3.1-8B-Instruct. If deploying a gated model, select your Hugging Face token from the UI or add one using the + Add token button.
To load a model from storage, click the Load from Storage button and specify the volume to mount and the path to the model in the mounted storage, such as /path/to/my/model.
Select the node group and resource shape to use for the deployment in the Resource section. The number of GPUs will vary depending on the model, but a general rule of thumb is to have at least 2 GB of GPU memory for every billion parameters for a model in BF16 precision. For example, an 8 billion parameter model will need approximately 16 GB of GPU memory to deploy.
In the NIM Configuration section, specify the registry authentication and your NGC API key.
- Registry Auth: Select one of the existing registry auth configurations you created in your workspace or create a new one with access to NGC.
- NGC API key: Select one of the existing NGC API keys you saved in your workspace as a secret or create a new one.
Very large models can take a long time to download if not already available in storage. To prevent the endpoint from failing before the model is downloaded, go to Advanced Configuration and set Healthcheck Initial Delay Seconds to Custom with a value of 7200 seconds or higher as necessary.
Saving Model in Cache
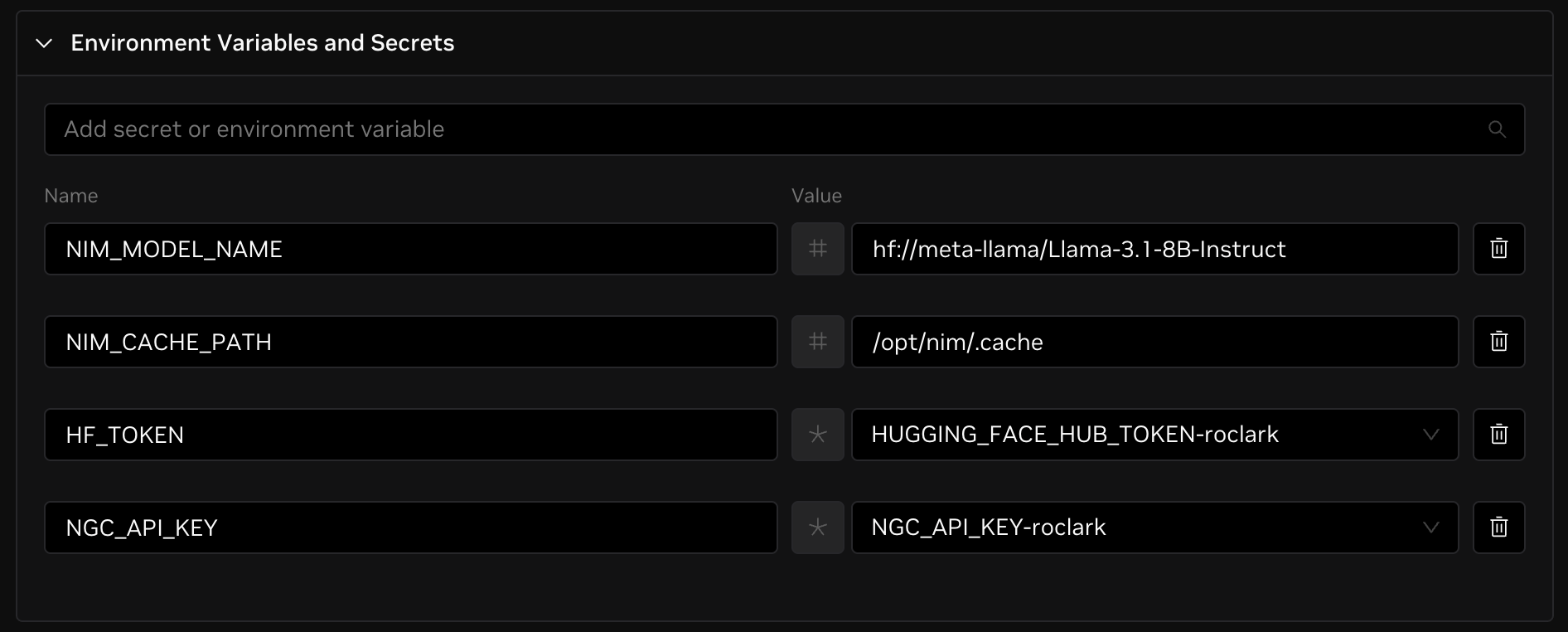
Since models can take hours to download depending on their size, you may want to store the model in a persistent cache. To do this, set an environment variable with a new cache path in persistent storage and mount that storage path.
Go to Environment Variables and Secrets and click Add Variable. Set the variable name to NIM_CACHE_PATH and the variable value to /opt/nim/.cache. Then go to Storage and click + Mount Storage. Select your desired volume, set the from path to /opt/nim/.cache or another location for storing cache on storage, and set the to path to /opt/nim/.cache.
This should now look like the image below.
For other endpoint configurations, refer to the Endpoints documentation.
Access Token
By default, endpoints require authentication with requests. This can be changed in the Access Tokens section. A random token will be generated for requests if access tokens are enabled. This will be shown in the UI alongside the deployed endpoint once ready.
Endpoints can also be made publicly available without authentication. Please note that anyone with the endpoint URL can access the model and send requests without authentication if made public.
Testing Endpoint
Once your endpoint is ready, you can use the playground to send requests directly from the UI, or you can send requests to the endpoint URL by running a command like the following:
If you set your endpoint to be publicly accessible, you do not need to set the authorization token.
LLMs follow the OpenAI API standard. For more information, refer to the official documentation.