NVIDIA DGX SuperPOD FAQ#
Introduction#
Where can the latest information on NVIDIA DGX SuperPOD be found?
The NVIDIA DGX SuperPOD landing page provides a datasheet and high-level reference to what makes a DGX SuperPOD great. Additional details can be found in the NVIDIA DGX SuperPOD documentation. Most customers find the NVIDIA DGX SuperPOD Reference Architecture - DGX H100 and the NVIDIA DGX SuperPOD: Data Center Design - DGX H100 documents especially useful.
Important
These documents are updated frequently, so please always check the latest versions on the website mentioned above!
What is an NVIDIA DGX SuperPOD Solution (Product)?
NVIDIA DGX SuperPOD Solution (Product) is a turnkey hardware, software, services, and support offering that removes the guesswork from building and deploying AI infrastructure. For customers needing a trusted and proven approach to AI innovation at scale, we’ve wrapped our internal deployment system, “Eos”, into a comprehensive solution, services, and support offering. NVIDIA DGX SuperPOD solution delivers a full-service experience that delivers industry-proven results in weeks instead of months to every organization that needs leadership-class infrastructure, with a white-glove implementation that’s intelligently integrated with your business so your team can deliver results sooner. DGX SuperPOD scales from 31 to 1,023 nodes of DGX Systems.
What DGX systems are supported in an NVIDIA DGX SuperPOD?
DGX H100 systems are supported in the NVIDIA DGX SuperPOD. The SuperPOD featuring DGX H100 is based on NVIDIA Quantum 2 networking with compute fabric speeds up to 400 Gb/s with NDR400.
Datacenter Architecture#
What is NVIDIA’s suggested Reference Architecture for DGX SuperPOD?
DGX SuperPOD design introduces compute building blocks called Scalable Units (SU). The SU size for SuperPOD H100 designs is 32 DGX H100 nodes per SU. The DGX SuperPOD design includes NVIDIA networking switches and software, DGX SuperPOD-certified storage, and NVIDIA NGC™ optimized software. The reference architecture documentation enumerates all of the components and configurations for the NVIDIA DGX SuperPOD.
What are some Data Center Colocation provider considerations for DGX SuperPOD?
DGX SuperPOD integrates many DGX systems, high-speed networking, storage, and management servers into a single solution. This integrated solution has complex power and thermal requirements. These requirements are discussed in the Data Center Design Guide. Refer to this document to understand the DC requirements and planning details for a DGX SuperPOD.
Hardware#
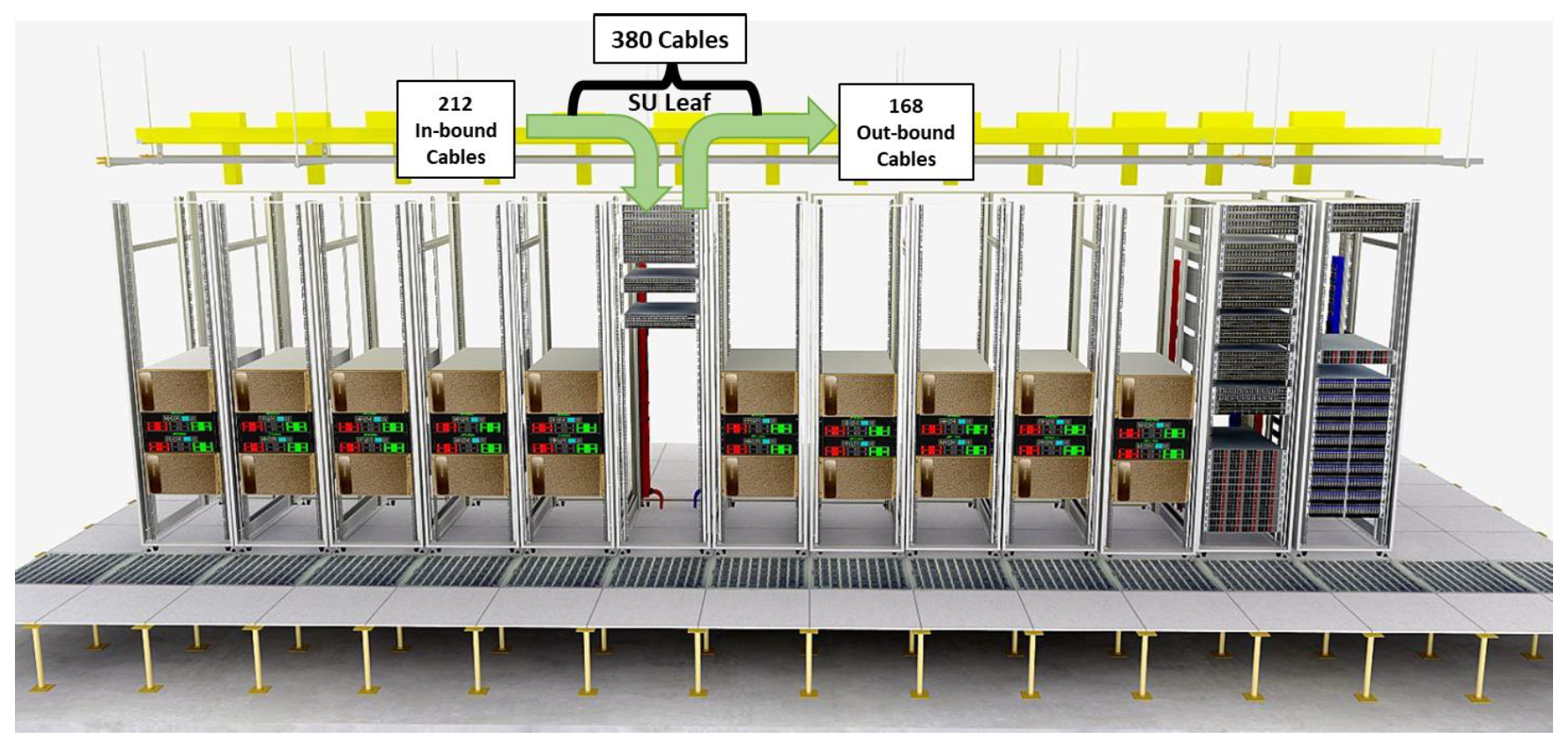
What does a single SU look like?
Below is an example figure of a single SU. Depending on the data center the racks may be configured differently depending on local data center requirements, including maximum power per rack and cooling infrastructure.

What is the difference between an NVIDIA DGX BasePOD and an NVIDIA DGX SuperPOD?
DGX SuperPOD is the product that NVIDIA provides to the market. The DGX SuperPOD is a complete turnkey solution with specific BOM, Installation services, support services, and guaranteed performance. The DGX BasePOD is a more flexible solution primarily driven by NVIDIA-certified storage vendors. NVIDIA provides reference architectures and prescriptions for a DGX BasePOD, but storage vendors can customize it for their customer needs. An NVIDIA DGX BasePOD is anything that fundamentally contains NVIDIA DGX, NVIDIA Networking, and NVIDIA Software, including Base Command Manager (BCM) and certified 3rd party storage. While using reference architectures is recommended, it is not required to be considered a DGX BasePOD.
What is the difference between NVIDIA DGX SuperPOD/DGX BasePOD and a large cluster of DGX Nodes?
The DGX SuperPOD is a complete turnkey solution with specific BOM, Installation services, support services, and guaranteed performance. A large cluster deployment is when one of the core components of DGX SuperPOD or DGX BasePOD is not used. For example, if a customer has their cluster management solution or if the customer wants to use NON-certified storage or other vendor networking gear. This would NOT be considered a SuperPOD or BasePOD.
What changes to the DGX SuperPOD design are permitted?
The NVIDIA DGX SuperPOD is a solution that mirrors what NVIDIA operates internally, which allows NVIDIA to offer the best customer experience possible. Minor adjustments to integrate with specific environments are allowed, such as adjusting the number of DGX systems per rack, changing cable lengths, or selecting alternative racks or PDUs to align with the standards at the intended data center.
Changes that have the potential to impact the performance or functionality of the NVIDIA DGX SuperPOD, such as using an alternate cluster manager or job scheduler (e.g., Kubernetes instead of Slurm), running a different operating system on the cluster (e.g., Red Hat instead of Ubuntu/DGX OS), use of non-DGX SuperPOD certified storage, or changing the compute, storage, or in-band management fabric topology generally disqualify the system from being an NVIDIA DGX SuperPOD. In many cases, the system is still an NVIDIA DGX BasePOD and would be installed, supported, and operated as such.
Can a SuperPOD be logically split between SU’s with VLANs?
No, a SuperPOD can only physically be split into completely separate compute fabrics
How many DGX systems must be installed to be an NVIDIA DGX SuperPOD?
Size is not what determines whether something is an NVIDIA DGX SuperPOD.
As described in earlier questions, an NVIDIA DGX SuperPOD is about deploying and operating a solution that mirrors what NVIDIA has so that it’s easiest to take advantage of the experience and ongoing improvements that NVIDIA makes to its own DGX SuperPOD deployments - not about number of systems. While a 1SU DGX SuperPOD configuration is the starting point, even if all of the DGX systems in that SU are not initially installed, it may still be an NVIDIA DGX SuperPOD. Conversely, a cluster may have hundreds of DGX systems installed and not be an NVIDIA DGX SuperPOD because it includes variations that make it an NVIDIA DGX BasePOD or a large custom DGX cluster.
What networking is used in the DGX SuperPOD?
Multiple networks are required for the DGX SuperPOD as defined in the NVIDIA DGX SuperPOD H100 Reference Architecture. These include well-defined compute, storage, in-band, and out–of–band fabrics. Only NVIDIA networking is supported with DGX SuperPOD. All supported switches are defined in the RAs.
What high-performance (inner-ring) storage is used with the DGX SuperPOD?
Currently, the only certified storage is the DDN AI400X, Dell PowerScale, IBM Storage Scale, NetApp E-Series (BeeGFS), NetApp A90 (ONTAP), Pure Storage FlashBlade, WEKA, and VAST.
What other storage is required but not included for the DGX SuperPOD?
NFS-based storage system for $HOME and an object store/data lake as outer ring storage. Also, cloud-bursting capability should be considered. The customer is responsible for scoping and procuring this storage independent of the DGX SuperPOD.
Is the NVIDIA SuperPOD always front-to-back cooling?
Yes. The NVIDIA SuperPOD components are selected for pulling cool air from the DGX H100 bezel side.
What is the largest number of DGX systems per rack you’ve seen deployed in an air-cooled center? One that doesn’t have liquid on the rack?
For DGX H100, two is the practical maximum unless the data center is specifically designed for significantly more power and cooling density. Then, three to four H100 nodes per rack may be possible. The issue is with the air-cooled data center and the power available per rack. Note that the scalability of a DGX deployment is in the ability to create multiple SUs, all of which are attached back to that common Infiniband spine and core, depending on the total size of the system. It’s less about how many DGX systems you can put into a rack and more about how many SUs you can bring about in your data center.
What should be the operating temperature ranges for a DGX system at full GPU load?
DGX H100’s operating temperature is 5–30 ºC (41–86 ºF).
Does a rear door change my airflow requirement?
A rear door heat exchanger can provide a higher cooling density in your data center if the plumbing can accommodate a water solution into that rear door. This allows you to augment the cooling capacity of your data center by bringing chilled water closer to the IT cabinets. Ensure you are cognizant of any limits with adding a rear door - your back of cabinet space, cabling deployments, and rack PDUs (rPDUs) must also be accommodated with a rear door.
Don’t you have to worry about back pressure from cooled rear doors?
If you are concerned about backpressure, consider an active rear door with a fan pack that assists with the airflow. Active rear doors typically have pressure and temperature monitors that control the door fans, so you have an optimum airflow to avoid back pressure issues. If you are running high-density, high-performance workloads all the time, active rear doors would be an option that can be engineered to meet cooling requirements.
Is it a requirement that these electrical circuits be three-phase?
To reach the power density using a single utility circuit and its redundant partner, it would be necessary to have three-phase power if we were trying to support multiple DGX H100 systems per rack. It is possible to accommodate that using multiple single-phase 208V circuits, but it would require many circuits to be brought into each rack. The NVIDIA DGX SuperPOD: Data Center Design - DGX H100 document provides various examples of recommended data center power configurations for optimal NVIDIA DGX SuperPOD operation.
What is the power consumption and physical size of the DGX H100 system?
The DGX H100 system is 10.2 kW, 8U.
Does NVIDIA specify certain cabinet dimensions or parameters?
Yes. While NVIDIA does not specify a particular brand or model of the rack to be used, it does specify that Racks must conform to EIA-310 standards for enclosed racks with 19” EIA mounting. Cabinets must be at least 24” x 44” (600 mm × 1100 mm) in size, and at least 42 RU tall. NVIDIA recommends 30” x 48” x 52 RU (700 mm × 1200 mm) racks.
Can InfiniBand cable length limitations be extended using patch panels or top-of-rack switches? Do you have any advice on cabling?
No. InfiniBand is an extremely high-performance architecture, and its cable length limitations are based on signal attenuation and latency of the entire signal path, not just a segment of cable. Patch panels exacerbate signal attenuation, and intermediary top-of-rack switches add latency.
We furthermore recommend bundling cables together in groups of relevance (i.e., Inter-Switch Link, uplinks to core devices) to ease the management and troubleshooting. Also, please use the correct cable length. Leave only a little slack at each end. Keep cables running under 90% of the max distances supported for Active Optical Cables (AOC). Install and space cables in advance for future replacement of damaged cables. Finally, use color coding of the cable ties to indicate the endpoints and put proper labels at both ends and along the run.
Does NVIDIA specify certain rPDU types?
Since rPDUs must conform to the power provisioning available in each data center and the brands available in each market region, NVIDIA does not specify a particular brand or model. However, we recommend the SuperPOD design include rPDUs, which have an Integrated smart module, network interface, SNMP interface, RestAPI interface, ports for temperature and sensor probes, locking receptacles, PDU level metering, remote outlet switching per receptacle, and optionally red and blue exterior colors.
How many SUs can I deploy?
A SuperPOD can contain up to four SUs (tested configuration).
What if I want to deploy more than four SUs?
The standard SuperPOD size is 4SUs and can be configured in The DGX SuperPOD and BasePOD BOM Configurator. The DGX SuperPOD H100 RA lists support for up to 64SUs. Please utilize the SuperPOD ARB and send your inquiries for greater than 4SUs to the ARB.
Contact your NVIDIA representative to discuss larger system options.
Can I utilize empty space in DGX (SU) racks for other IT equipment?
No. A DGX SU is an engineered solution that should not cohabitate with unrelated equipment in a shared rack.
Software#
What software is included with the DGX SuperPOD?
Every DGX is shipped with DGX OS preinstalled. NVIDIA DGX OS provides a customized installation of Ubuntu Linux with system-specific optimizations and configurations, additional drivers, and diagnostic and monitoring tools. It provides a stable, fully tested, and supported OS to run AI, machine learning, and analytics applications on DGX Supercomputers.
NVIDIA Base Command Manager offers comprehensive management for DGX SuperPOD. It’s essential to the DGX SuperPOD experience, providing the tools and prescriptive configuration information needed to maximize performance and utilization. Base Command Manager is the same technology NVIDIA uses to manage thousands of systems for our award-winning data scientists and provides an immediate path to a TOP500 supercomputer for organizations that need the best. Full Data Sheet
Scheduling/Management/ML Ops (have the SuperPOD deployments gone with DGX-Ready SW or a combination of Slurm/K8s/Singularity?
DGX SuperPOD is optimized for multi-user, large DL/AI training, and HPC workflows. SLURM is the designated schedule and resource management tool. SLURM is an enterprise-proven, highly effective workload scheduler that handles multi-GPU multi-node batch processing. The SuperPOD uses two NVIDIA-developed open-source tools, enroot and pyxis, to support root-less containerized multi-GPU and multi-node workload management with SLURM.
An alternative resource manager such as Kubernetes would be possible but is outside the scope of the current DGX SuperPOD product. An NVIDIA DGX SuperPOD deployment and performance validation will always be performed in the SLURM environment, even if the ultimate use cases are meant to be with different software. Once the software stack is changed, NVIDIA cannot support the entire solution as a DGX SuperPOD. Still, instead, it will be treated like a DGX BasePOD as described in prior questions.
Operations - Staffing#
Governance best practices for a shared environment?
Shared environments are a shared responsibility of the host facility, operations team, and leaders of the key research and scientific teams. The SuperPOD reference architecture does not explicitly cover remote access solutions because they are site-dependent. The SuperPOD operates as a unified system that exposes only management nodes to the outside environment. This architecture creates controlled access to the SuperPOD resources. It matches well with remote access solutions compliant with GDPR and other privacy standards that are important considerations for any shared environment.
DGX SuperPOD and BasePOD are explicitly not designed for multi-tenant environments.
Business - Budget and Strategy#
Are the Standard three-Year Enterprise Support Services mandatory for individual systems of the DGX SuperPOD?
Yes, the Standard three-Year Enterprise Support Services are mandatory for individual systems of the DGX SuperPOD.
Is a Premium TAM required with every NVIDIA DGX SuperPOD deployment?
As part of the DGX SuperPOD, a Premium Technical Account Manager is mandatory for each deployment.
What are the key benefits of Premium TAM Services?
The Premium TAM Services are targeted at DGX SuperPOD customers who have to manage various hardware & software systems supplied by multiple vendors, including NVIDIA. Premium TAM will begin engaging with customers after the delivery of SuperPOD. The deliverables of a Premium
TAM include:
Develop and maintain a joint support plan for the DGX SuperPOD with defined goals and success metrics
Route and manage technical support cases for DGX SuperPOD within NVIDIA and coordinate with third-party vendors
As part of managing the technical support cases, the Premium TAM will coordinate software updates and multi-vendor issues, including work to identify a root cause and work with the vendor to facilitate the resolution of an issue.
What other services are available with the DGX SuperPOD?
NVIDIA Professional Services Installation and deployment are required for the DGX SuperPOD.
What does the deployment engagement look like?
For each DGX SuperPOD deployment, NVIDIA will provide Technical Project management to support the successful delivery, installation, testing, and operational handoff. A dedicated Program Manager will engage with the customer once a sale is booked to start working on the Statement of Work for each customer deployment.
Support#
What support terms are included for DGX SuperPOD?
The support term or the length of the support period for DGX SuperPOD is equal to the terms of PTAM and DGX H100 Enterprise Support Services, the NVIDIA Networking support terms, and the NVIDIA AI Enterprise Terms and Conditions. The third-party products must have their respective vendor support services coverage to ensure non-NVIDIA technical issues can be addressed and resolved promptly.
Does NVIDIA support/advise on customer applications (e.g, issues with scaling deep learning models)
DGX SuperPOD includes NVIDIA AI Enterprise as they are built on top of NVIDIA DGX H100 systems. Issues with NVIDIA AI Enterprise deep learning containers and frameworks can be addressed through NVIDIA Enterprise support.
DGXperts program allows preferred connection with the NVIDIA Solution Architecture and Engineering team for education and extended, best-effort support on top of the regular business support services.
What support services are included with the key products, DGX H100 systems, of the DGX SuperPOD?
DGX H100 system support services deliverables include:
HW Support Services – Remote hardware support; onsite hardware support and replacement, including advanced RMA for next business day
Software Support Services – Remote software support for NGC and issues related to the base OS (Ubuntu), SBIOS, BMC and firmware on DGX system
Cases accepted for remote support 24/7 (email, phone or Enterprise Support Portal)
Escalation support during customer’s local business hours (9 a.m.–5 p.m., M–F)
Direct communication with NVIDIA Enterprise Support (backed by engineering)
Access to the latest software updates and upgrades
Access to Enterprise Support Portal (case initiation, case status, software/firmware repository and knowledgebase)
Access to private NGC registry
For workloads that contain sensitive information, what option is available that doesn’t require letting drives outside of the data center?
In situations where it’s not feasible to return the failed SSDs, the purchase of SSD Media Retention Service (SDMR) service can be used. This allows retention of physical media in the case of a failure and RMA. The term of the SDMR must match the DGX H100 Support Services.
How are air-gapped environments accommodated during installation and maintenance?
Deployment of NVIDIA DGX SuperPODs in an air-gapped environment presents a significant challenge that requires close coordination and preparation well before deployment and at every maintenance window. Although the NVIDIA DGX SuperPOD does not require Internet connectivity during operation, it can be challenging for deployment and ongoing maintenance if there is no connectivity during those periods. Before purchasing an NVIDIA DGX SuperPOD, work with the NVIDIA DGX team to ensure the deployment is suitable for the intended environment.