NVIDIA DRIVE OS 5.1 Linux Developer Guide 5.1.0.2 Release |
NVIDIA DRIVE OS 5.1 Linux Developer Guide 5.1.0.2 Release |
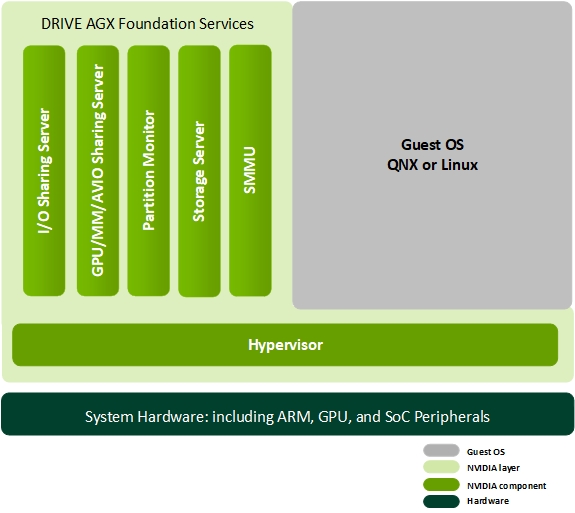
Component | Description |
Hypervisor | Trusted RM server that separates the system into partitions. Each partition can contain an operating system or a bare-metal application. The Hypervisor manages: • Guest OS partitions and the isolation between them. • Partitions’ virtual views of the CPU and memory resources. • Hardware interactions • Run-lists • Channel recovery Hypervisor is optimized to run on the ARM Cortex-A15 MPCore. |
Early Boot Partition | Provides early display of video images. |
I/O Sharing Server | Allocates peripherals that Guest OS need to control. |
GPU/MM/AVIO Sharing Server | Components that manage isolated hardware services for: • Graphics and computation (GPU) • Codecs (MM) • Display, video capture and audio I/O (AVIO) |
Partition Monitor | Monitors partitions, including: • Dynamically loads/unloads and starts/stops partitions and virtual memory allocations. • Logs partition use. • Provides interactive debugging of guest operating systems. |
Component | Description |
cuDNN | The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks. cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN is part of the NVIDIA Deep Learning SDK. For more information consult: https://developer.nvidia.com/cudnn |
TensorRT | NVIDIA TensorRT™ is a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for deep learning applications. For more information consult: https://developer.nvidia.com/tensorrt |
CUDA | CUDA® is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers are able to dramatically speed up computing applications by harnessing the power of GPUs. For more information consult: https://developer.nvidia.com/cuda-zone |