Streaming
Combining the buffer and synchronization functions from the previous chapters allows you to develop applications that stream sequences of data from one rendering component to another, building an efficient processing pipeline. For developers who wish to have complete control over the process, no additional functionality is required.
However, use cases for streaming can become quite complex, making the details difficult to manage. This is particularly true when portions of the pipeline are provided by independent developers who must coordinate the stream management. NVIDIA therefore provides an additional NvSciStream library layered on NvSciBuf and NvSciSync with utilities for constructing streaming application suites.
Terminology
The following section describes basic memory buffer terminology.
• Block: A modular portion of a stream that resides in a single process and manages one aspect of the stream's behavior. Blocks are connected together in a tree to form arbitrary streams.
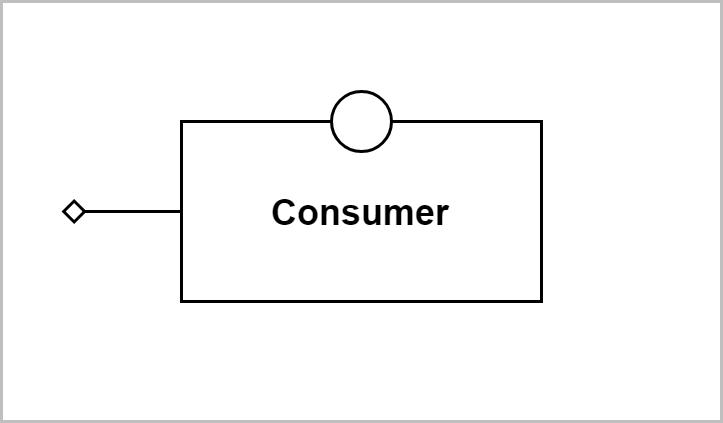
• Consumer: An application component responsible for processing data received from a stream, or the stream block with which it communicates.
• Element: A single buffer within a packet.
• Frame: A simple payload consisting of a single image.
• Packet: A set of buffers that contain stream data. A stream may make use of one or more packets.
• Payload: The contents of a packet and associated fences at a given point in the stream sequence.
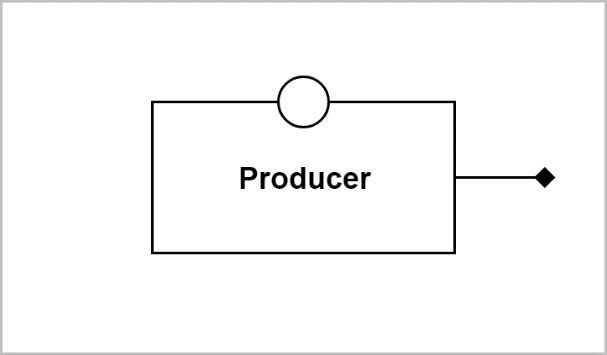
• Producer: An application component responsible for generating data to insert in a stream, or the stream block with which it communicates.
• Stream: A mechanism to pass a sequence of measured or computed data from one application component responsible for generating it to one or more other application components responsible for processing it.
A Simple Stream
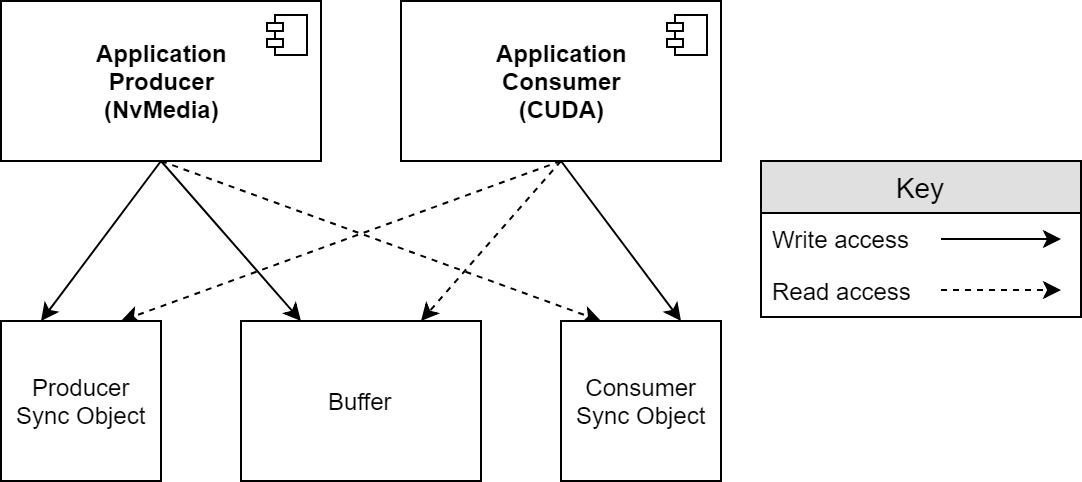
This section illustrates how streaming works with an example application that directly uses NvSciBuf and NvSciSync to take images from a camera controlled by NvMedia, and sends the images to CUDA for processing. This application is so simple that there is no need to involve the added NvSciStream layer. It uses a single buffer that NvMedia can write to and CUDA can read from, and a pair of sync objects. One sync object is for NvMedia to write and CUDA to read, and the other is for CUDA to write and NvMedia to read.
Setup
The initial setup for the application is shown below. Much of this should already be familiar from the earlier chapters on buffers and synchronization objects. (For brevity, we assume everything succeeds and omit error checking.)
Simple Stream Setup
/* Initialize NvMedia (not all steps are shown) */
NvMediaDevice* nvmediaDevice = NvMediaDeviceCreate();
NvMedia2D* nvmedia2D = NvMedia2DCreate(nvmediaDevice);
/* Initialize CUDA (not all steps are shown) */
CUdevice cudaDevice;
cuDeviceGet(&cudaDevice, IGPU);
CUcontext cudaContext;
cuCtxCreate(&cudaContext, CU_CTX_MAP_HOST, dev);
cuCtxPushCurrent(&cudaContext);
CUstream cudaStream;
cuStreamCreate(&cudaStream, CU_STREAM_DEFAULT);
/* Initialize NvSci buffer and sync modules */
NvSciBufModule bufModule;
NvSciBufModuleOpen(&bufModule);
NvSciSyncModule syncModule;
NvSciSyncModuleOpen(&syncModule);
/* Obtain NvMedia buffer requirements */
NvSciBufAttrList nvmediaBufAttrs;
NvSciBufAttrListCreate(bufModule, &nvmediaBufAttrs);
NvMediaImageFillNvSciBufAttrs(nvmediaDevice, <...NvMedia settings ...>, nvmediaBufAttrs);
/* Obtain NvMedia sync requirements */
NvSciSyncAttrList nvmediaWriteSyncAttrs, nvmediaReadSyncAttrs;
NvSciSyncAttrListCreate(syncModule, &nvmediaWriteSyncAttrs);
NvMedia2DFillNvSciSyncAttrList(nvmediaWriteSyncAttrs, NVMEDIA_SIGNALER)
NvSciSyncAttrListCreate(syncModule, &nvmediaReadSyncAttrs);
NvMedia2DFillNvSciSyncAttrList(nvmediaReadSyncAttrs, NVMEDIA_WAITER)
/* Obtain CUDA buffer requirements */
NvSciBufAttrList cudaBufAttrs;
NvSciBufAttrListCreate(bufModule, &cudaBufAttrs);
<Fill in with CUDA raw buffer attributes>
/* Obtain CUDA sync requirements */
NvSciSyncAttrList cudaWriteSyncAttrs, cudaReadSyncAttrs;
NvSciSyncAttrListCreate(syncModule, &cudaWriteSyncAttrs);
cuDeviceGetNvSciSyncAttributes(cudaWriteSyncAttrs, cudaDevice, CUDA_NVSCISYNC_ATTR_SIGNAL);
NvSciSyncAttrListCreate(syncModule, &cudaReadSyncAttrs);
cuDeviceGetNvSciSyncAttributes(cudaReadSyncAttrs, cudaDevice, CUDA_NVSCISYNC_ATTR_WAIT);
/* Combine buffer requirements and allocate buffer */
NvSciBufAttrList allBufAttrs[2], conflictBufAttrs;
NvSciBufAttrList combinedBufAttrs;
allBufAttrs[0] = nvmediaBufAttrs;
allBufAttrs[1] = cudaBufAttrs;
NvSciBufAttrListReconcile(allBufAttrs, 2, &combinedBufAttrs, &conflictBufAttrs);
NvSciBufObj buffer;
NvSciBufObjAlloc(combinedBufAttrs, &buffer);
/* Combine sync requirements and allocate nvmedia to cuda sync object */
NvSciSyncAttrList allSyncAttrs[2], conflictSyncAttrs;
allSyncAttrs[0] = nvmediaWriteSyncAttrs;
allSyncAttrs[1] = cudaReadSyncAttrs;
NvSciSyncAttrList nvmediaToCudaSyncAttrs;
NvSciSyncAttrListReconcile(allSyncAttrs, 2, &nvmediaToCudaSyncAttrs, &confictSyncAttrs);
NvSciSyncObj nvmediaToCudaSync;
NvSciSyncObjAlloc(nvmediaToCudaSyncAttrs, &nvmediaToCudaSync);
/* Combine sync requirements and allocate cuda to nvmedia sync object */
allSyncAttrs[0] = cudaWriteSyncAttrs;
allSyncAttrs[1] = nvmediaReadSyncAttrs;
NvSciSyncAttrList cudaToNvmediaSyncAttrs;
NvSciSyncAttrListReconcile(allSyncAttrs, 2, &cudaToNvmediaSyncAttrs, &confictSyncAttrs);
NvSciSyncObj cudaToNvmediaSync;
NvSciSyncObjAlloc(cudaToNvmediaSyncAttrs, &cudaToNvmediaSync);
/* Map objects into NvMedia */
NvMediaImage nvmediaBuffer;
NvMediaImageCreateFromNvSciBuf(nvmediaDevice, buffer, &nvmediaBuffer);
NvMedia2DRegisterNvSciSyncObj(nvmedia2D, NVMEDIA_EOFSYNCOBJ, nvmediaToCudaSync);
NvMedia2DRegisterNvSciSyncObj(nvmedia2D, NVMEDIA_PRESYNCOBJ, cudaToNvmediaSync);
/* Map objects into CUDA */
cudaExternalMemoryHandleDesc cudaMemHandleDesc;
memset(&cudaMemHandleDesc, 0, sizeof(cudaMemHandleDesc));
cudaMemHandleDesc.type = cudaExternalMemoryHandleTypeNvSciBuf;
cudaMemHandleDesc.handle.nvSciBufObject = buffer;
cudaMemHandleDesc.size = <allocated size>;
cudaImportExternalMemory(&cudaBuffer, &cudaMemHandleDesc);
CUDA_EXTERNAL_SEMAPHORE_HANDLE_DESC cudaSemDec;
CUexternalSemaphore nvmediaToCudaSem, cudaToNvmediaSem;
cudaSemDesc.type = CU_EXTERNAL_SEMAPHORE_HANDLE_TYPE_NVSCISYNC;
cudaSemDesc.handle.nvSciSyncObj = (void*)nvmediaToCudaSync;
cuImportExternalSemaphore(&nvmediaToCudaSem, &cudaSemDesc);
cudaSemDesc.type = CU_EXTERNAL_SEMAPHORE_HANDLE_TYPE_NVSCISYNC;
cudaSemDesc.handle.nvSciSyncObj = (void*)cudaToNvmediaSync;
cuImportExternalSemaphore(&cudaToNvmediaSem, &cudaSemDesc);
First, the buffer and sync object requirements are queried from NvMedia, the producer of the stream, and from CUDA, the consumer. These requirements are combined and used to allocate the objects, which are then mapped into NvMedia and CUDA so that they can be used for processing.
Two sync objects are required instead of one because synchronization is required in both directions. It is important that the CUDA consumer does not begin reading from the buffer until the NvMedia producer is done writing to it. It is equally as important that the NvMedia producer does not begin writing a new image to the buffer until the CUDA consumer is done reading the previous image. Otherwise, it overwrites data that is still in use.
Streaming
Once initialized, the streaming loop looks like this:
Simple Stream Loop
/* Initialize empty fences for each direction*/
NvSciSyncFence nvmediaToCudaFence = NV_SCI_SYNC_FENCE_INITIALIZER;
NvSciSyncFence cudaToNvmediaFence = NV_SCI_SYNC_FENCE_INITIALIZER;
/* Main rendering loop */
while (!done) {
/* Instruct NvMedia pipeline to wait for the fence from CUDA */
NvMedia2DInsertPreNvSciSyncFence(nvmedia2D, cudaToNvmediaFence)
/* Generate NvMedia image */
NvMedia2DSomeRenderingOperation(..., nvmediaBuffer, ...);
/* Generate a fence when rendering finishes */
NvMedia2DSetNvSciSyncObjforEOF(nvmedia2D, nvmediaToCudaSync);
NvMedia2DGetEOFNvSciSyncFence(nvmedia2D, nvmediaToCudaSync, &nvmediaToCudaFence);
/* Instruct CUDA pipeline to wait for fence from NvMedia */
CUDA_EXTERNAL_SEMAPHORE_WAIT_PARAMS cudaWaitParams;
cudaWaitParams.params.nvSciSync.fence = (void*)&nvmediaToCudaFence;
cudaWaitParams.flags = 0;
cudaWaitExternalSemaphoresAsync(&nvmediaToCudaSem, &cudaWaitParams, 1, cudaStream);
/* Process the frame in CUDA */
cudaSomeProcessingOperation(..., cudaBuffer, ...);
/* Generate a fence when processing finishes */
CUDA_EXTERNAL_SEMAPHORE_SIGNAL_PARAMS cudaSignalParams;
cudaSignalParams.params.nvSciSync.fence = (void*)&cudaToNvmediaFence;
cudaSignalParams.flags = 0;
cudaSignalExternalSemaphoresAsync(&cudaToNvmediaSem, &cudaSignalParams, 1, cudaStream);
}
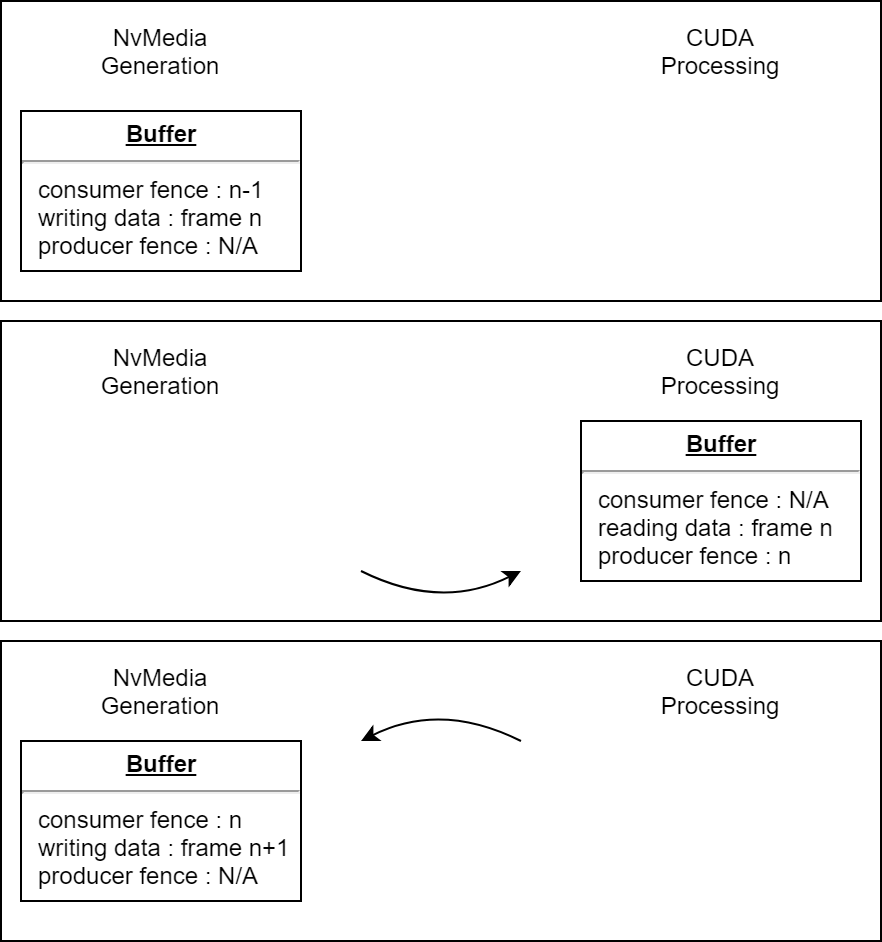
For each frame of data, the application instructs NvMedia to write the image to the buffer, and then issues a fence that indicates when writing finishes. CUDA is instructed to wait for that fence before it proceeds with any subsequent operations, then the commands to process the frame are issued to CUDA. Lastly, CUDA is told to generate a fence of its own, which indicates when all its operations finish. This fence is fed back to NvMedia, which waits for it before starting to write the next image to the buffer. "Ownership" of the buffer cycles back and forth between producer and consumer.
More Complex Streams
All of the basic steps in the previous example to set up buffers and sync objects, and to generate and wait for fences must be performed for all streaming applications, regardless of whether they use NvSciStream. For a simple situation like that, there is no need for anything more.
What NvSciStream provides is the ability to manage more complex cases, such as cycling between multiple buffers, streaming to multiple consumers at once, and streaming between applications. It also provides a uniform set of interfaces for setting up streams for which independent developers can design modular producers and consumers without needing to directly coordinate and then plug their products together. This section describes some of those use cases Adding NvSciStreams for these use cases relieves the developer of many burdensome details.
Multiple Buffers
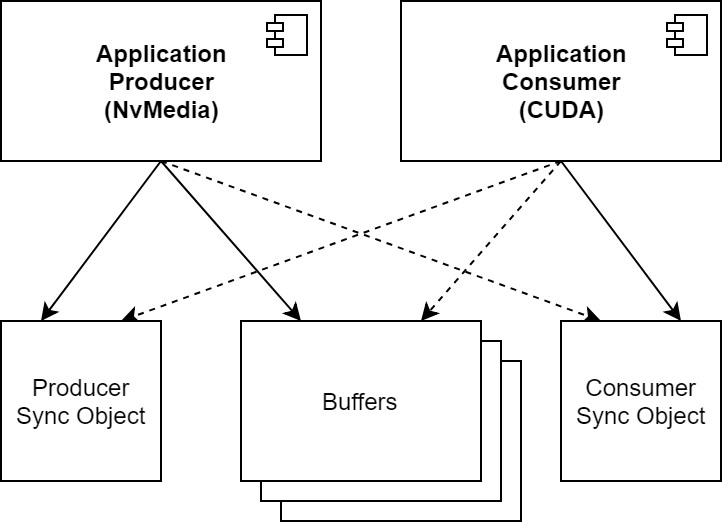
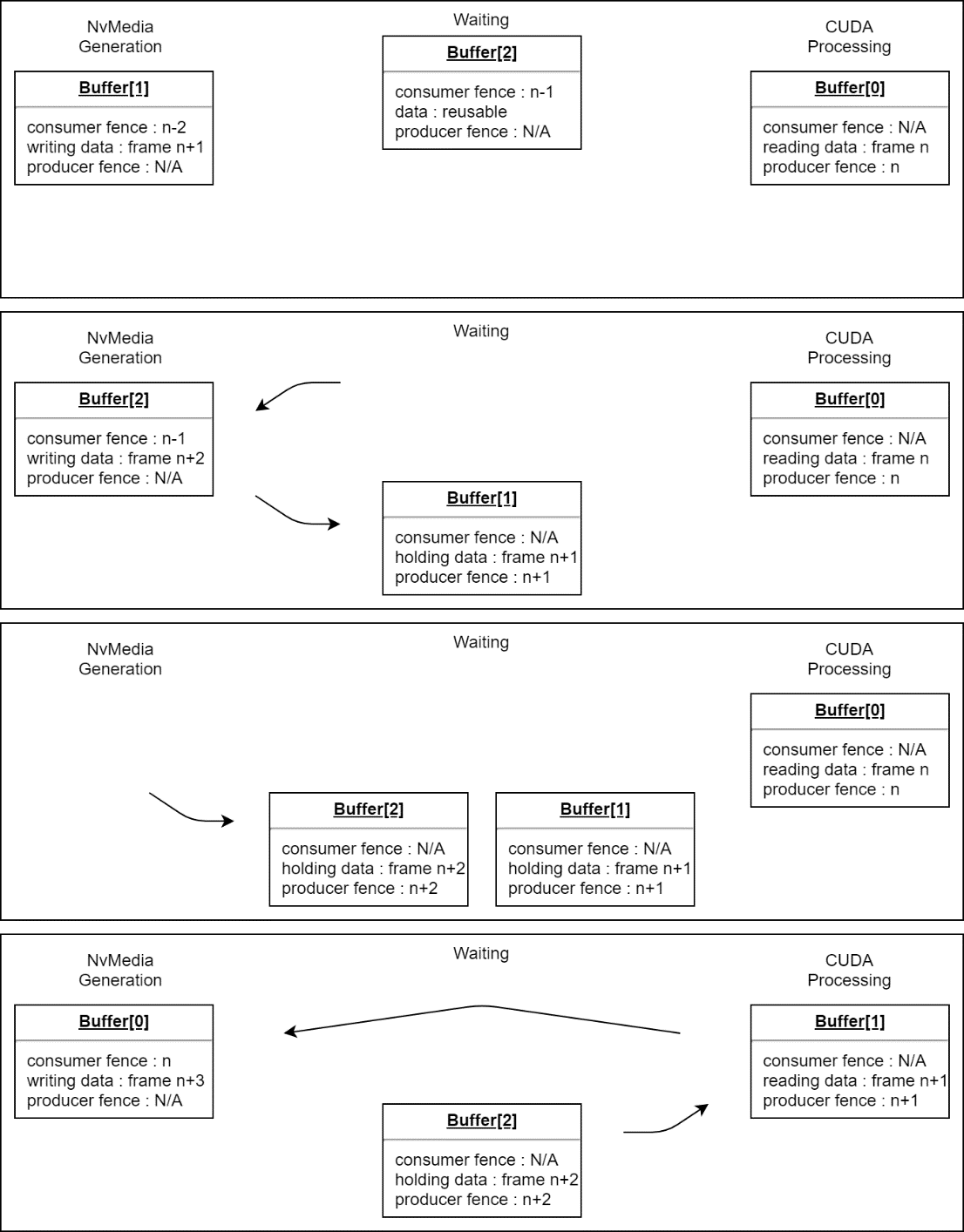
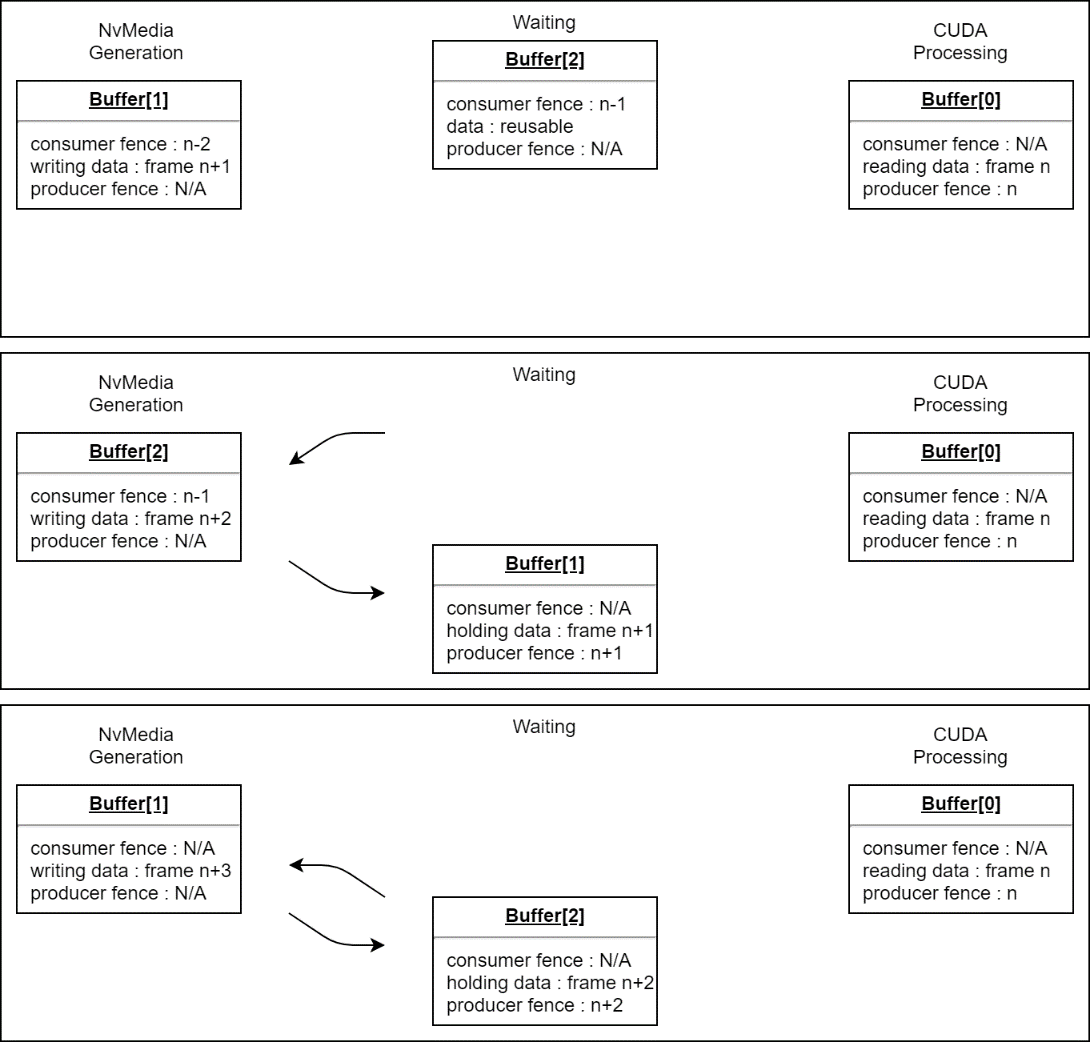
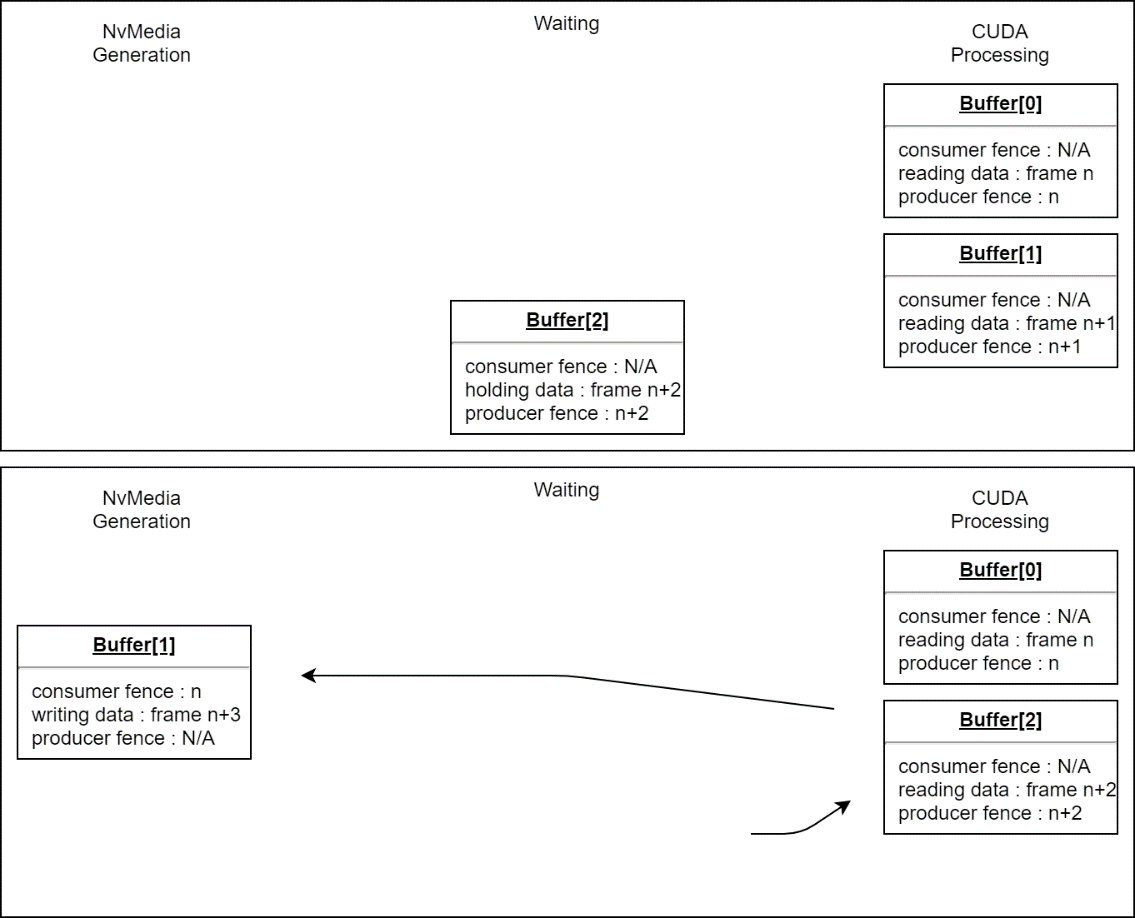
NvMedia and CUDA use different portions of the NVIDIA hardware. In the example above, the compute hardware is idle during 2D processing, and the 2D hardware is idle during compute processing. The pipeline can be made more efficient by allocating one (1) or more additional buffers and cycling between them, creating a queue of frames. This way, CUDA can process one image while NvMedia prepares the next one. No additional sync objects are needed, but it is necessary to generate a fence for each frame, and therefore you must keep track of which fence is associated with the current contents of each buffer. Once a stream has multiple buffers available, there are several different possible modes of operation to consider.
FIFO Mode
If the use case requires that all data in the sequence be processed, the stream application operates in FIFO mode. When the producer fills a buffer with new data, it must wait for the consumer to process it. If the consumer requires more time than the producer, the producer is slowed to the consumer's speed to wait for buffers to become available for reuse.
Mailbox Mode
In other use cases, it is more important that the consumer always have the most recent input available. In this case, the stream application operates in mailbox mode. If the consumer has not started processing a previous frame when a new one becomes available, it is skipped, and its buffer immediately returned to the producer for reuse. This means that the order in which the producer and consumer cycle through buffers is subject to change at any time, and the streaming system must manage this.
Multiple Acquired Frames
Some processing algorithms must compare data from multiple frames in a sequence. In this case, the consumer may hold multiple buffers at once. These buffers may be released for reuse in an order other than they arrive. The streaming system must manage this.
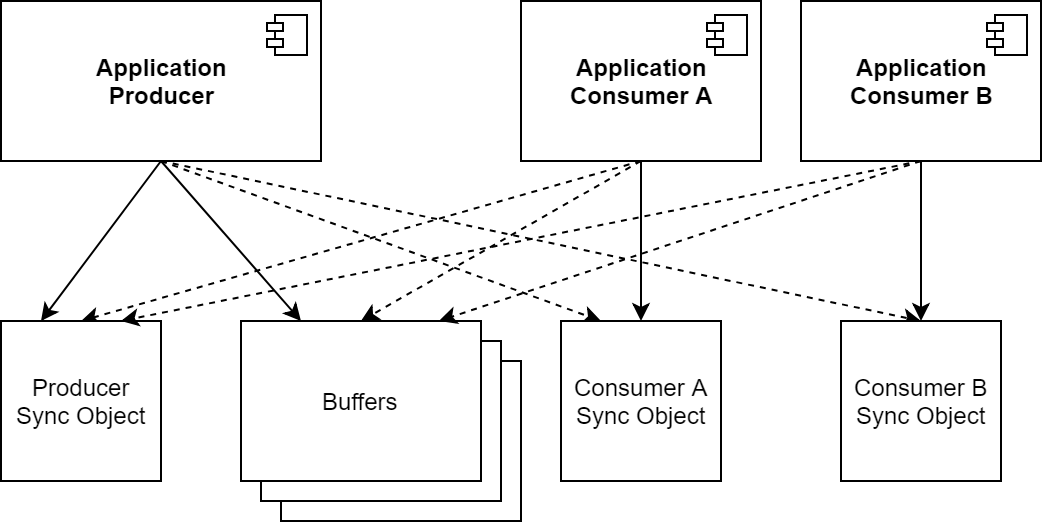
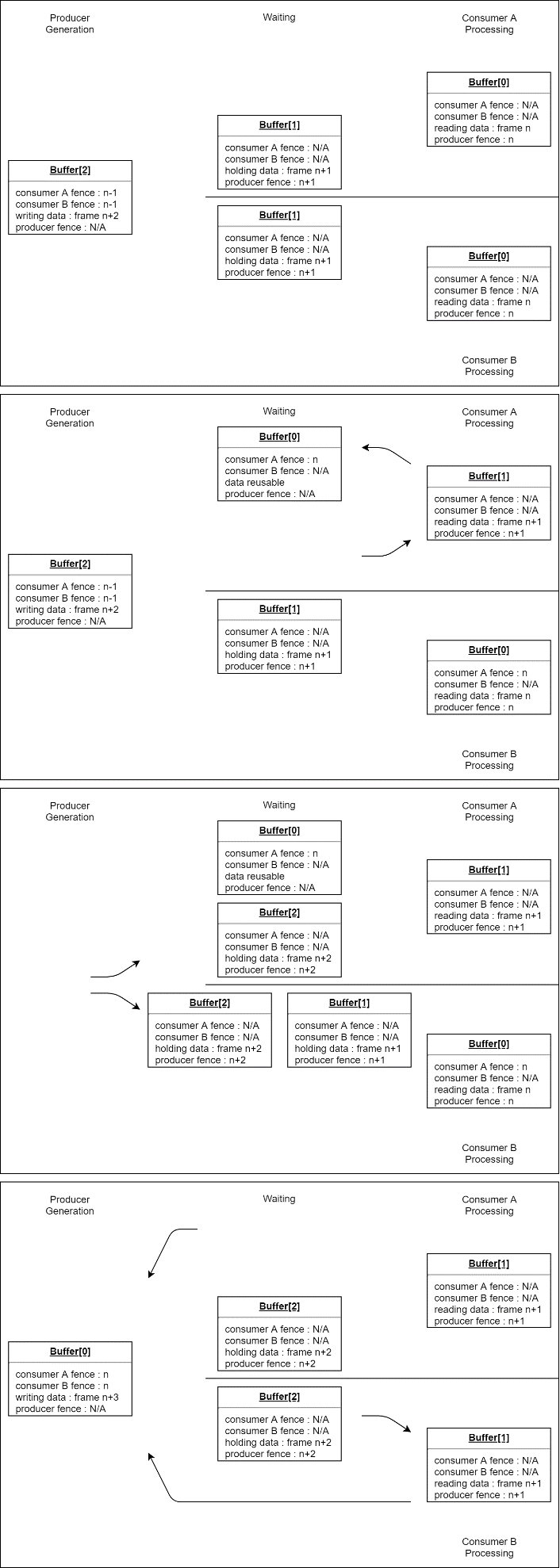
Multiple Consumers
In some cases, the output of a single producer must be sent to multiple consumers. This means that during initialization, the requirements from all of the consumers must be gathered, and sync objects from all of the consumers must be mapped into the producer.
During streaming, the system must track each buffer's state with regards to all the consumers and wait for fences from all of them to complete before the producer can reuse it. This can be further complicated if one consumer requires FIFO behavior and another requires mailbox. They might return buffers in different orders.
Cross-Application
Having producers and consumers in separate applications requires inter-process communication during every step of the process. At setup, all the requirements must be transmitted between the endpoints, and then the allocated objects must be shared between the processes. During streaming, every time the producer generates a frame, a message letting the consumer know it is ready, which includes the fence, must be sent to the other side. When the consumer is done reading from the frame, a similar message must be sent back in the other direction. Each application must be prepared to read and process these messages so streaming can occur in a timely fashion.
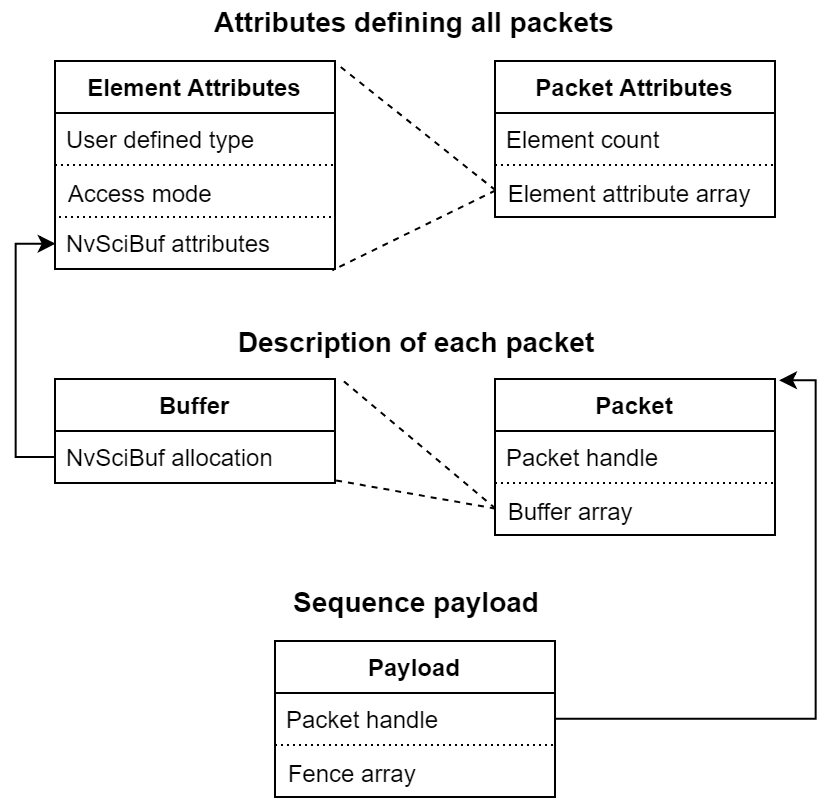
Data Packets
In the examples above, only 2D buffers containing single frames of image data are considered. For many use cases, that is all that is required. However, NvSciStream supports more arbitrary data. In the sections below, “buffers” are generalized to "packets", and "frames" to "payloads".
A packet is a set of indexed buffers that contains images, tensors, metadata, or other information. These buffers are referred to as the "elements" of a packet. Each stream may use one or more packets. For a given stream, all packets have the same number of elements, and the ith element of all packets is allocated with the same NvSciBuf attributes. As a result, all packets have uniform memory requirements and signatures. Producers and consumers send and receive entire packets at a time, along with associated fences to indicate when the payloads they contain are ready.
In addition to the NvSciBuf attributes used to allocate them, the elements of each packet also have a type and mode associated with them, which help applications coordinate how the elements are used. These are described in the next sections.
Element Type
In a complex modular application suite, a given producer may know how to produce many different types of data, and the various consumers may only require a subset of them. NvSciStream provides mechanisms to help applications negotiate the data that is actually required for a given stream. The top-level system integrator must define a set of integer values to associate with each type of data that the application suite supports. Any non-zero value may be used for these types, and developers are advised to plan for future types and backwards compatibility.
As an example, the following table is a subset of the types that are available in an automotive system. These may not all be supplied by a single producer. For instance, one producer might be responsible for front-facing sensors, and another for rear-facing sensors. Different consumers make use of different sets of sensors to generate their output. The types listed in the table below all correspond to raw inputs, but a pipe-lined application may have a series of producers and consumers with additional types to represent intermediate processed data. The following table describes the sample data packet types:
Data Type | Assigned Enum |
Front left camera | 0x1101 |
Front-center camera | 0x1102 |
Front-right camera | 0x1103 |
Rear-left camera | 0x1201 |
Rear-center camera | 0x1202 |
Rear-right camera | 0x1203 |
Front radar | 0x2110 |
Front lidar | 0x2120 |
Rear radar | 0x2210 |
Rear lidar | 0x2220 |
GPS | 0x3010 |
IMU | 0x3020 |
At initialization, a producer declares all the types of data it is able to provide. Consumers indicate the types of data they are interested in. The part of the application responsible for allocating the buffers takes this information and collates it to determine the packet layout and passes the packet attributes back to the producer and consumers. The producer checks this layout to see what elements it actually needs to provide. The consumers check it to determine where in the packets to find the elements they care about. Any element that a given consumer doesn't require can be ignored.
In simple applications that only deal with a single type of data such as images, producers and consumers can simply specify a value of 1 for the type. These type exchange mechanisms are only intended to aid integration of larger suites.
Element Mode
Payload data generated and processed by NVIDIA hardware is usually written and read asynchronously, and requires waiting for a fence before it can be accessed. But in some use cases, auxiliary data may be generated synchronously by the CPU and must be read before the commands to process the rest of the data are issued. An example is a camera producer that generates images asynchronously, but also includes a synchronously generated metadata field that contains the camera's focal length, exposure time, and other settings. A consumer synchronously reads in the metadata first, and uses the values it contains when issuing the commands to asynchronously process the image.
To support these use cases, NvSciStream allows each element of a packet to be marked as immediate or asynchronous mode. Immediate mode elements are read as soon as a packet is received by the consumer. Asynchronous mode elements are only read after waiting for the fence(s) associated with the payload. Similarly, the producer can write new data to an immediate mode element as soon as the consumer releases the packet, while reusing asynchronous mode elements requires waiting for the fence(s) returned by the consumer.
Building Block Model
NvSciStream is designed to make implementing complex stream use cases easier by providing a uniform set of interfaces for exchanging requirements, and sending and receiving frames. At the top level, an application suite determines the overall structure of the stream. At the lower application component level, each producer and consumer performs its own function, without needing to know the details of the full stream. They can be developed independently in a modular fashion and plugged together as needed.
In order to support this wide variety of use cases, NvSciStream itself takes a modular approach. It defines a set of building blocks, each with a specific purpose, which applications create and connect together to suit their needs. This section describes the available building blocks and their behavior.
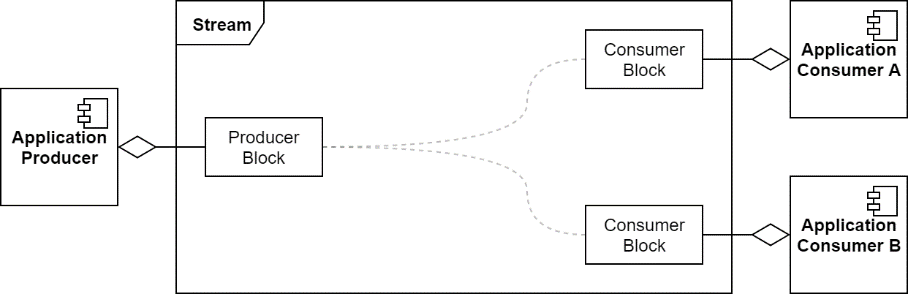
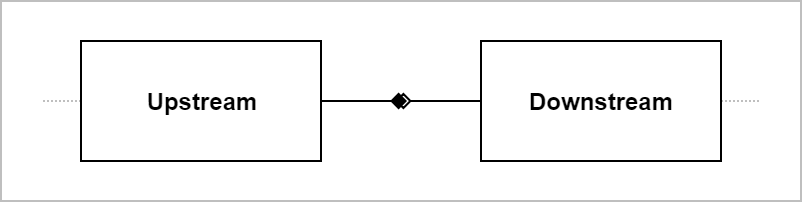
Endpoints
Each stream begins with a producer block and ends with one or more consumer blocks. These are referred to as the "endpoints" of the stream, with the producer being the "upstream" end and the consumers being the "downstream" end. For each stream endpoint, there is an application component responsible for interacting with it. The endpoints and their corresponding application components may all reside in a single process or be distributed across multiple processes, partitions, or systems.
Producer
A producer block provides the following interactions with the application producer component:
• During setup phase:
• Synchronization:
• Accepts producer synchronization requirements.
• Reports consumer synchronization requirements.
• Accepts producer allocated sync objects.
• Reports consumer allocated sync objects.
• Buffers:
• Accepts list of element attributes producer can generate.
• Reports consolidated packet attribute list.
• Reports all allocated packets.
• During streaming phase:
• Signals availability of packets for reuse.
• Retrieves next packet to reuse with fence to wait for before writing.
• Accepts filled packet with fence to wait for before consumer should read.
• In non-safety builds, during streaming phase:
• Accepts limited changes to requested element attributes (e.g., to modify the image size).
• Reports updated packet attributes.
• Reports removal of buffers allocated for old attributes and addition of new ones.
Note: | Reallocation of buffers in non-safety builds are not supported in this release. |
Consumer
A consumer block provides the following interactions with its corresponding application consumer component:
• During setup phase:
• Synchronization:
• Accepts consumer synchronization requirements.
• Reports producer synchronization requirements.
• Accepts consumer allocated sync objects.
• Reports producer allocated sync objects.
• Buffers:
• Accepts list of element attributes consumer requires.
• Reports consolidated packet attribute list.
• Reports all allocated packets.
• During streaming phase:
• Signals availability of packets for reading.
• Retrieves next payload with fence to wait for before reading.
• Accepts packet, which can be reused with fence to wait for before the produce writes new data.
• In non-safety builds, during streaming phase:
• Reports updated packet attributes.
• Reports removal of buffers allocated for old attributes and addition of new ones.
Note: | Reallocation of buffers in non-safety builds are not supported in this release. |
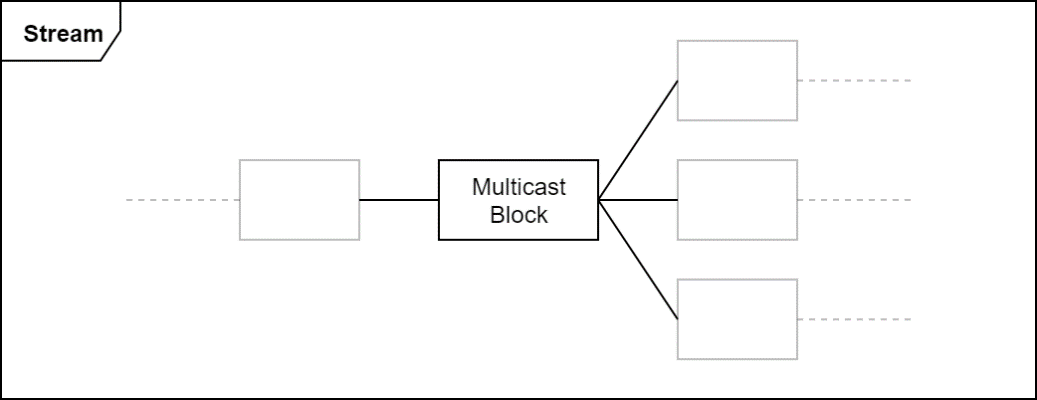
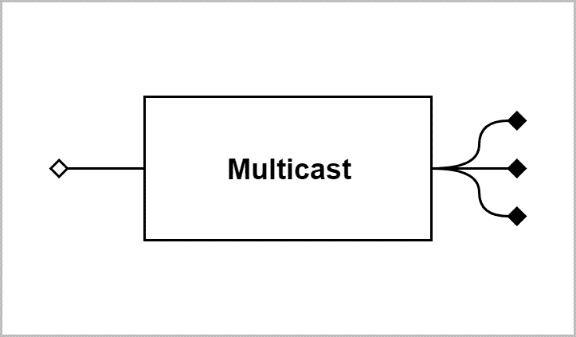
Multicast
When a stream has more than one consumer, a multicast block is used to connect the separate pipelines. This block distributes the producer's resources and actions to the consumers, who are unaware that each other exist. It combines the consumers' resources and actions, making them appear to the producer as a single virtual consumer. The block does not directly provide any mechanisms to safeguard any of its consumers against faulty or malicious behavior in its other consumers. Additional blocks can be used to isolate individual consumer pipelines from others when there are safety or security concerns.
Once created and connected, no direct interaction by the application with a multicast block is required. It automatically performs the following operations as events arrive from up and downstream:
• During setup phase:
• Synchronization:
• Passes producer synchronization requirements to all consumers.
• Combines consumer synchronization requirements and passes to producer.
• Passes producer allocated sync objects to all consumers.
• Passes sync objects allocated by all consumers to producer.
• Buffers:
• Combines lists of element attributes from all consumers into a single list and passes upstream.
• Passes consolidated packet attribute list to all consumers.
• Passes allocated packets to all consumers.
• During streaming phase:
• Passes available payloads to all consumers.
• Tracks packets returned for reuse by the consumers and returns them to the producer when all consumers are done with them. All fences are combined into one list.
• In non-safety builds, during streaming phase:
• Distributes changes in packet attributes and buffers to all consumers.
Note: | Multicast blocks are not supported in this release. |
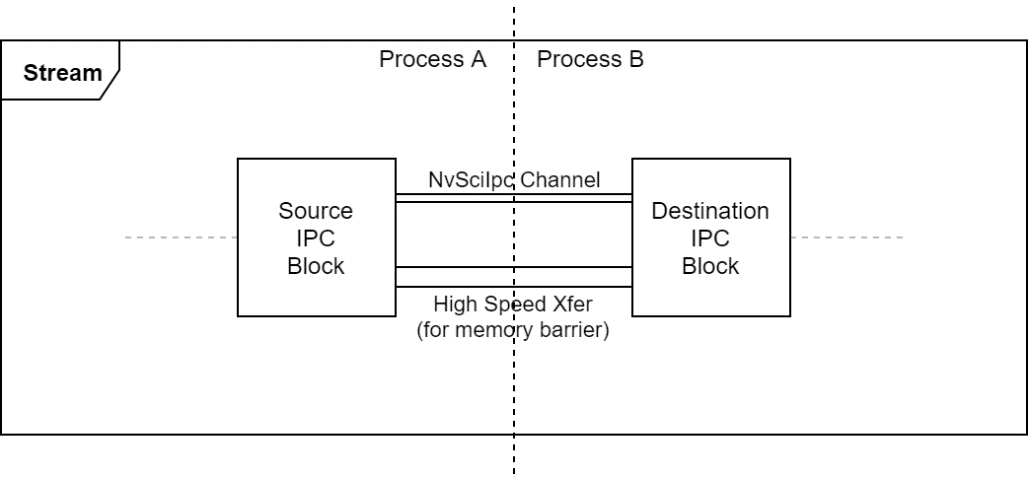
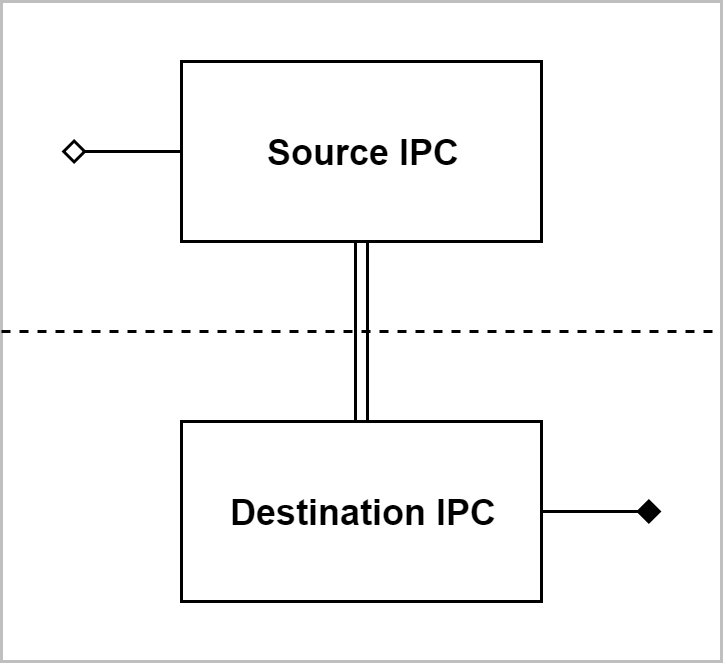
IPC
When the endpoints of a stream reside in separate processes, IPC blocks are used to bridge the gaps. They are created in pairs, with a source IPC block in the upstream process and a destination IPC block in the downstream process. The communication must first be established by the application using NvSciIpc, and then the channel endpoints are passed to the two IPC blocks. They take ownership of the channel and use it to coordinate the exchange of requirements and resources, and signal the availability of packets.
There are two types of IPC pairs available, depending on whether the upstream and downstream portions share memory.
Memory Sharing IPC
When the two halves of the stream access the same physical memory, memory sharing IPC blocks can be used. These coordinate the sharing of resources between the two ends but do not need to access the payload data. They perform the following actions when events arrive from up and downstream:
• During setup phase:
• Synchronization:
• Exports synchronization requirements from the producer and consumer(s) and imports them on the other side.
• Exports sync objects from the producer and consumer(s) and imports them on the other side.
• Buffers:
• Exports consumer element attributes from downstream and imports them upstream.
• Exports consolidated packet attribute list and packets from upstream and imports them downstream.
• During streaming phase:
• Source IPC block signals availability of new payloads to destination block, passing the fence.
• Destination IPC block signals availability of packets for reuse to source block, passing the fence.
• In non-safety builds, during streaming phase:
• Signals changes in packet attributes and buffers from source to destination.
Note: | Reallocation of buffers in non-safety builds are not supported in this release. |
Memory Boundary IPC
When the two processes do not share memory, memory boundary IPC blocks must be used. Each half of the stream must provide a separate set of packets. When new payloads arrive, the source block transmits all the data to the destination block, where it is copied into a new packet. Auxiliary communication channels may be set up for this purpose. Once transmission is done, the original packet is returned upstream for reuse, without waiting for the consumer to finish reading the data, since it accesses a different set of buffers.
These IPC blocks can also be used to create virtual memory boundaries between portions of a stream. If one consumer operates at a lower level of safety and/or security than the rest of the stream, then even if it can share memory with the rest of the stream, it may not be desirable to do so. Requiring this consumer to use its own set of buffers ensures that if it fails, it won't prevent the rest of the stream from continuing, and if it falls prey to a security issue, it won't be able to modify the buffer data seen by the other consumers.
• During setup phase:
• Synchronization:
• Synchronization objects are not exchanged across the memory boundary.
• Source and destination blocks provide their synchronization requirements for the producer and consumer, respectively.
• If necessary, creates sync objects to be used to coordinate the data copy, and passes to the local endpoint .
• Accesses sync objects from the local endpoint to coordinate data copy.
• Buffers:
• Exports a subset of the consumer element attributes from downstream and imports them upstream, replacing attributes related to memory access with those needed for the data transfer mechanism to access the memory.
• Exports a subset of the consolidated packet attribute list from upstream and imports them downstream, again replacing attributes related to memory access with those needed for the copy engine.
• On destination side, receives and maps buffers used for copy from downstream.
• During streaming phase:
• Source IPC block transmits payload data to the destination block.
• Destination IPC block reads the payload data into an available packet and passes it downstream.
• In non-safety builds, during streaming phase:
• Signals changes in packet attributes and buffers from source to destination.
Note: | Memory boundary IPC blocks are not supported in this release. |
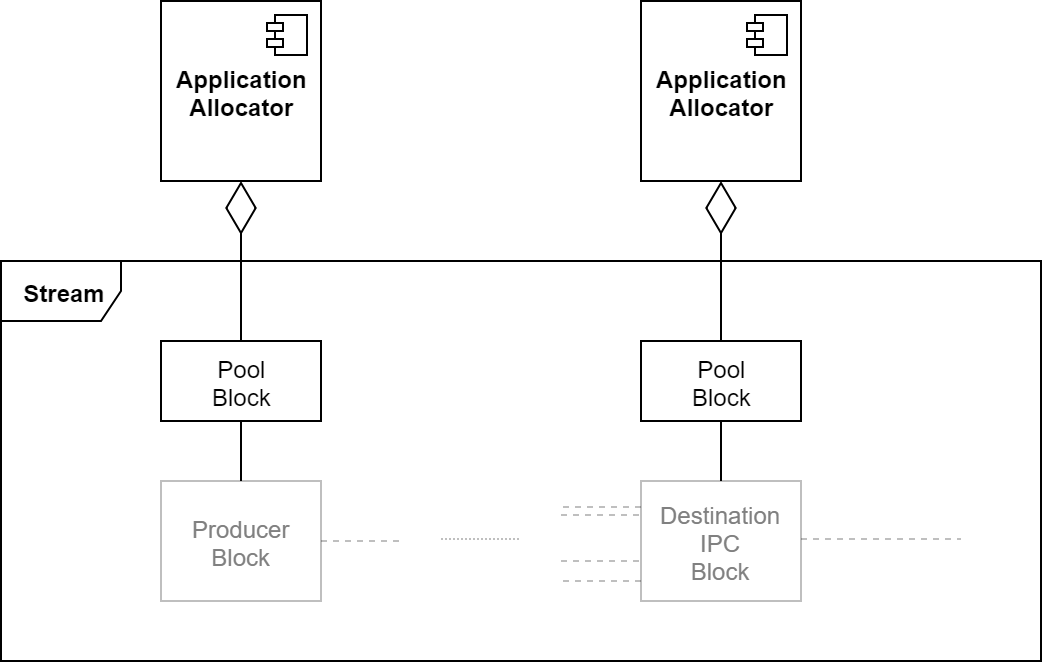
Pool
Pool blocks are used to introduce packets to the stream and track packets available for reuse. All streams must have at least one pool attached to the producer block. If a stream contains memory boundaries, then additional pools are needed for each section of the stream that uses its own set of packets, attached to the IPC block. For each pool block, there is an application component responsible for deciding the packet layout based on the requirements and allocating the buffers.
NvSciStream supports two kinds of pools: static and dynamic.
Static Pool
Static pools provide a set of packets that remain fixed for the life of the stream. The number of buffers must be specified at creation time, and the buffers are added during the setup phase. A static pool provides the following interactions with the application component that manages it:
• During setup phase:
• Buffers:
• Reports list of element attributes producer can generate.
• Reports list of element attributes consumers require.
• Accepts consolidated packet attribute list, and sends to producer and consumers.
• Accepts allocated packets and sends to producer and consumers.
• During streaming phase:
• Receives and queues packets returned to the producer for reuse.
• Provides an available packet to the producer or IPC block it supports when requested.
Dynamic Pool
Dynamic pools are only available in non-safety builds. They allow buffers to be added and removed at any time. This supports use cases where the producer may need to change some of the buffer attributes, such as the size or pixel format of the data. Video playback is a typical example where such changes may occur. A dynamic pool provides all the interactions of a static pool, plus the following:
• In non-safety builds, during streaming phase:
• Reports requested element attribute changes from the producer.
• Accepts updated element attributes and sends it to the producer and consumers.
• Accepts instructions to remove packets from the stream and sends it to the producer and consumers.
• Accepts new allocated packets and sends it to the producer and consumers.
Note: | Dynamic blocks are not supported in this release. |
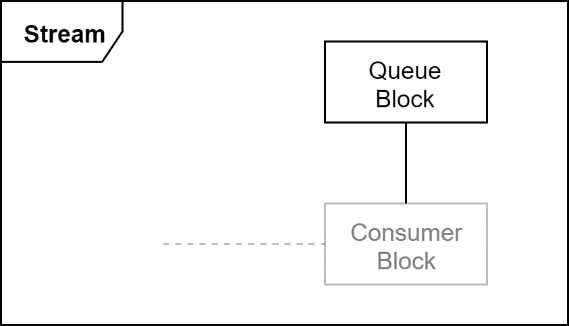
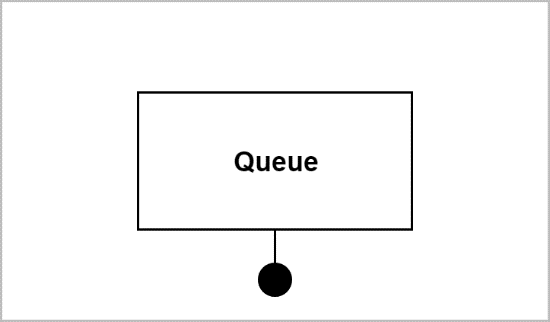
Queue
Queue blocks keep track of payloads that are waiting to be acquired by the consumer. Each consumer block must have an attached queue block to manage available packets.
NvSciStream supports two types of queue blocks: FIFOs and mailboxes. A FIFO block is used when all data must be processed. Payloads always wait in FIFO until the consumer acquires them. Mailboxes are used when the consumer always acts on the most recent data. If a new payload arrives in the mailbox when one is already waiting, the previous one is skipped and immediately returned to the producer for reuse.
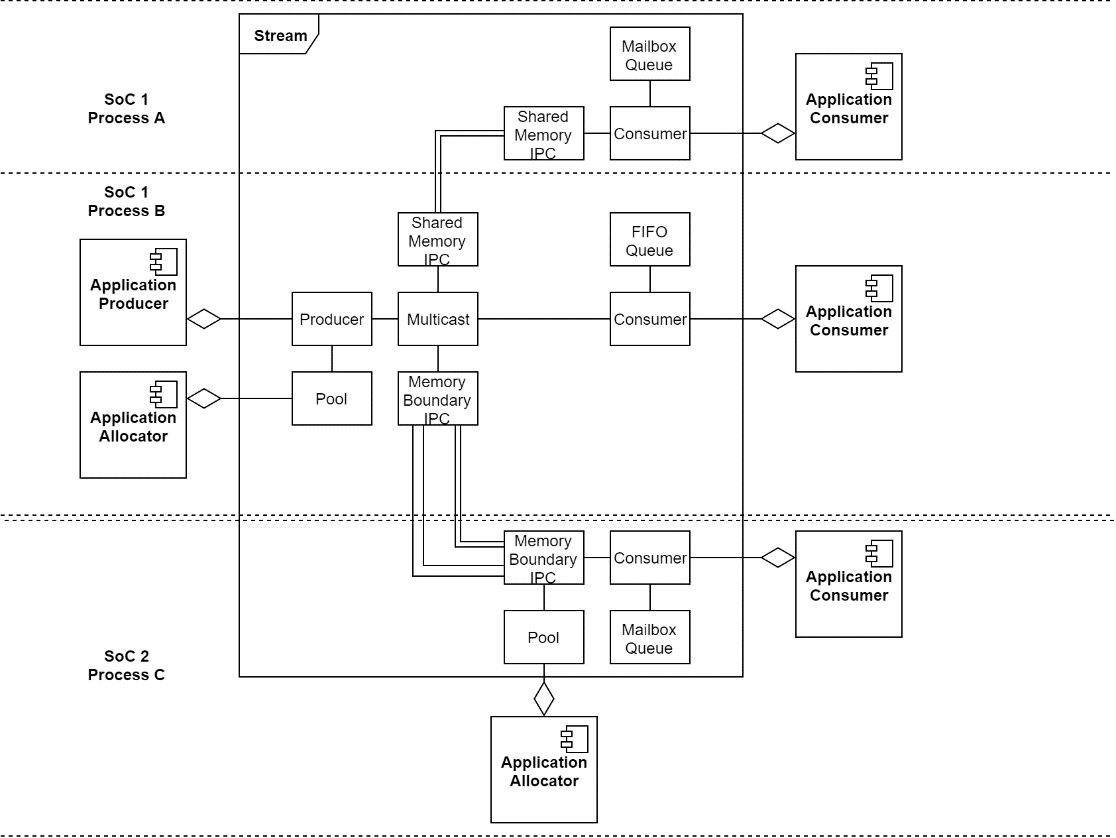
Example
The following diagram shows a complete stream. It has three (3) consumers. One resides in the same process as the producer, the second resides in another process on the same system and shares memory with the producer process, and the third resides on another system and uses its own set of packets. The first uses a FIFO queue and the other two use mailbox queues.
Stream Creation
The modular nature of NvSciStream allows producer and consumer components, or entire applications, to be developed independently by different providers, but some planning is required to ensure proper inter-operation. System integrators must make several decisions before assembling a stream.
• Determine which consumers reside in the same process as the producer and which are separated in other processes, partitions, or systems. Factors that influence this decision include modularity of development, management of computational resources, and freedom from interference.
• Determine which consumers require physical or virtual memory boundaries to safeguard critical consumers from less robust or secure consumers.
• Determine which consumers must process every payload and which only require the most recent data.
• Determine how communication between the processes is established.
• Provide a uniform set of packet element types with associated data layout definitions for designing all endpoints.
• Based on the complexity of the stream, determine how many packets are required to keep the pipeline operating at desired efficiency.
Once these decisions are made, use NvSciStream to assemble the desired stream(s).
NvSciBuf and NvSciSync Initialization
All NvSci buffer and sync object handles are associated with a particular NvSciBufModule and NvSciSyncModule, respectively. Any streaming application must begin by creating one of each of these modules. In general, an application may create more than one of each type of module, but there is rarely any reason to do so. However, all buffer and sync objects used with a given stream within a single process must be associated with the same modules. Different streams may use different modules.
NvSciIpc Initialization
For cross-process streams, the applications must first establish communication with each other using NvSciIpc. This is outside the scope of this document. However, NvSciStream does impose some minimum requirements on the IPC channels to be able to transmit the required messages. The NvSciIpc channel must be created with at least 24K (24576) bytes per frame. NVIDIA recommends the channel be created with at least 16 frames. See the
NvSciIpc documentation for more information on how to set up the connections.
Once an NvSciIpc channel is created, the applications may use it to do any initial validation and coordination required. Once that is complete, ensure that there are no unprocessed messages remaining in the channel, and pass it off to NvSciStream. NvSciStream then uses it to coordinate stream operations between the two processes. From this point on, the application must not directly operate on the channel. Doing so leads to unpredictable behavior and almost certainly cause the stream to fail.
Block Creation
Each application is responsible for creating the NvSciStream blocks that reside in that process. The block creation functions all take a pointer parameter in. When successful, a block handle of type NvSciStreamBlock is returned. This handle is used for all further operations on the block. Some require additional parameters. For those that require a NvSciBufModule and/or NvSciSyncModule, the same module must be provided as those used to access the buffers and sync objects. Blocks may be created in any order.
Pool
NvSciError
NvSciStreamStaticPoolCreate(
uint32_t numPackets,
NvSciStreamBlock* pool)
• Pool blocks have no inputs and outputs used with the connection function.
• Pools are attached directly to a producer or IPC block during that block's creation.
• For static pools, the number of packets the pool provides must be specified at creation.
Producer
NvSciError
NvSciStreamProducerCreate(
NvSciStreamBlock pool,
NvSciStreamBlock* producer)
• A pool block must be provided for each producer block at creation.
• Producer blocks have a single output connection and no input connections.
Multicast
NvSciError
NvSciStreamMulticastCreate(
uint32_t numOutputs,
NvSciStreamBlock* multicast)
• Multicast blocks have a single input connection and a fixed number of output connections specified at creation.
• During the connection process (below), the order in which outputs are connected doesn't matter.
Queues
NvSciError
NvSciStreamFifoQueueCreate(
NvSciStreamBlock* queue)
NvSciError
NvSciStreamMailboxQueueCreate(
NvSciStreamBlock* queue)
• Queue blocks have no inputs and outputs used with the connection function.
• Queues are attached directly to a consumer block during that block's creation.
Consumer
NvSciError
NvSciStreamConsumerCreate(
NvSciStreamBlock queue,
NvSciStreamBlock* consumer)
• A queue block must be provided for each consumer block at creation.
• Consumer blocks have a single input connection and no output connections.
IPC
NvSciError
NvSciStreamIpcSrcCreate(
NvSciIpcEndpoint ipcEndpoint,
NvSciSyncModule syncModule,
NvSciBufModule bufModule,
NvSciStreamBlock* ipc)
NvSciError
NvSciStreamIpcDstCreate(
NvSciIpcEndpoint ipcEndpoint,
NvSciSyncModule syncModule,
NvSciBufModule bufModule,
NvSciStreamBlock* ipc)
• IPC blocks are created in pairs, each using one end of an NvIpc channel.
• The caller must complete any of its own communication over the channel before passing it to NvSciStream, and must not subsequently read from or write to it.
• The buffer and sync modules must be those used for all buffer and sync object associated with the stream in the calling process. The block uses them when importing objects from the other endpoint.
• The source (upstream) block has one input connection, and the destination (downstream) block has one output connection. Together with the channel between them, they are viewed as a single virtual block with one input and one output, spanning the two processes.
Block Connection
Once blocks are created, they can be connected in pairs. The connection can be done in any order, and can be intermingled with creation of the blocks.
NvSciError
NvSciStreamBlockConnect(
NvSciStreamBlock upstream,
NvSciStreamBlock downstream)
An available output of the upstream block is connected to an available input of the downstream block. If there is no available output or input, the function fails. Each input and output block can be connected only once. A new block cannot be connected in place of an old one, even if the old one is destroyed.
Comparison with EGL
Those familiar with EGL will notice that this process is more involved than the creation of an EGLStream. For an EGLStream, all the desired features are encoded into an array of attributes, and then a single stream object (or two in the case of cross-process) is created. The details of setting up all the stream management are left to the EGL implementation. But a simple attribute array cannot convey all the possible stream feature permutations and use cases that an application may desire. In fact, multicasting to more than one consumer cannot be handled by EGLStream at all without additional extensions defining new objects.
The modular approach used by NvSciStream requires applications to perform separate creation calls for each feature of the desired stream, and then connect them together. This is more effort, but affords greater control over the stream's behavior, and allows for features not originally anticipated or readily supported by EGLStreams, such as multicasting. It allows the development of new block types to support new features in the future, which are harder to add to a monolithic stream object.
Simple Example
The following example assembles a simple cross-process stream with a producer and pool in one process, and a FIFO and consumer in another process. The cross-process communication channel is assumed to be established before this code executes.
Sample Producer Creation
// We'll use triple buffering for this stream
const uint32_t numPackets = 3;
// Stream variables
NvSciIpcEndpoint srcIpc;
NvSciBufModule bufModule = 0;
NvSciSyncModule syncModule = 0;
NvSciStreamBlock producerBlock = 0;
NvSciStreamBlock poolBlock = 0;
NvSciStreamBlock srcIpcBlock = 0;
NvSciError err;
// Setting up communication is outside the scope of this guide
srcIpc = <something>;
// Set up buffer and sync modules
// (If using multiple streams, or doing other non-stream NvSci
// operations, these might be passed in from some global setup.)
err = NvSciBufModuleOpen(&bufModule);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciSyncModuleOpen(&syncModule);
if (NvSciError_Success != err) {
<handle failure>
}
// Create all the stream blocks
err = NvSciStreamStaticPoolCreate(numPackets, &poolBlock);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciStreamProducerCreate(poolBlock, &producerBlock);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciStreamIpcSrcCreate(srcIpc, syncModule, bufModule, &srcIpcBlock);
if (NvSciError_Success != err) {
<handle failure>
}
// Connect the blocks
err = NvSciStreamBlockConnect(producerBlock, srcIpcBlock);
if (NvSciError_Success != err) {
<handle failure>
}
Sample Consumer Creation
// Stream variables
NvSciIpcEndpoint dstIpc;
NvSciBufModule bufModule = 0;
NvSciSyncModule syncModule = 0;
NvSciStreamBlock consumerBlock = 0;
NvSciStreamBlock fifoBlock = 0;
NvSciStreamBlock dstIpcBlock = 0;
NvSciError err;
// Setting up communication is outside the scope of this guide
dstIpc = <something>;
// Set up buffer and sync modules
// (If using multiple streams, or doing other non-stream NvSci
// operations, these might be passed in from some global setup.)
err = NvSciBufModuleOpen(&bufModule);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciSyncModuleOpen(&syncModule);
if (NvSciError_Success != err) {
<handle failure>
}
// Create all the stream blocks
err = NvSciStreamFifoQueueCreate(&fifoBlock);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciStreamConsumerCreate(fifoBlock, &consumerBlock);
if (NvSciError_Success != err) {
<handle failure>
}
err = NvSciStreamIpcDstCreate(dstIpc, syncModule, bufModule, &dstIpcBlock);
if (NvSciError_Success != err) {
<handle failure>
}
// Connect the blocks
err = NvSciStreamBlockConnect(dstIpcBlock, consumerBlock);
if (NvSciError_Success != err) {
<handle failure>
}
Event Handling
NvSciStream is designed so that, once a stream is created and connected, applications can follow an event-driven model. Operations on one block in a stream trigger events in other blocks. These events are dequeued by the applications, which act in response, performing new block operations that trigger new events, and so on. Every block supports an event queue, although some types of blocks may only generate events during the initial setup phase.
Event Query
Events can be queried from each block:
NvSciError
NvSciStreamBlockEventQuery(
NvSciStreamBlock block,
int64_t timeout_usec,
NvSciStreamEvent *event)
• If no events are currently pending in the block's queue, a non-zero timeout causes it to wait the specified number of microseconds for one to arrive. If a negative value is used, the call waits forever.
• The event parameter must point to an event structure the function fills in. Any previous contents of the structure are ignored and may be overwritten.
On success, a pending event is removed from the block's queue, the provided event structure is filled with event information, and NvSciError_Success is returned. If no event is available before the timeout period ends, an NvSciError_Timeout error is returned. Additional errors may be found in the reference manual.
The event structure contains several fields. The type is always be set and indicates what kind of event occurred. Only some of the other fields are set, depending on the type of event. These are described in the sections on specific events, later in this document.
typedef struct {
NvSciStreamEvent type;
NvSciStreamSyncAttr syncAttr;
NvSciStreamSyncDesc syncDesc;
NvSciStreamElementAttr packetAttr;
NvSciStreamPacket packetCreate;
NvSciStreamElementDesc packetElement;
NvSciStreamCookie packetCookie;
NvSciError error;
uint32_t index;
uint32_t count;
} NvSciStreamEvent
Note: | Some of the fields in this data structure are substructures that match the structures used to initiate the event. This results in some types of information (e.g., packet handles and cookies) that are duplicated in multiple locations. In a future release, this structure will be flattened so that there is only one of each type of field. |
Event Notification
Note: | You can easily set up event loops for each block in separate threads using the event query function in the previous section. However, having a single thread with an event loop that handles multiple blocks is less convenient. Either the thread must continuously poll each block to check for events, which is wasteful when no events are pending, or it must have some knowledge of which block receives an event next, in order to wait for it. An event notification mechanism is under development, which allows a single thread to wait on multiple blocks simultaneously. It wakes when any block receives an event. This mechanism is compatible with NvSciIpc events and operating system specific event mechanisms, allowing the thread to wait for more than just NvSciStream events at the same time. This mechanism is not supported in the current release. |
Connection Events
Assuming no failures occur during setup, the first event type each block receives is NvSciStreamEventType_Connected. This indicates that the block has a complete connection path to the producer and consumers, respectively. None of the event data fields are used with this event type. After connecting, no operations are allowed on any block until this event is received. Applications must wait for it before proceeding with the resource setup described in the next section.
If a block is destroyed or, in the cross-process case, communication with a process is lost, NvSciStreamEventType_Disconnected event is sent to any connected blocks. If there are other events pending, such as available payloads, they are processed first. Disconnect event does not use any data fields in the event structure. Once this event is received, no further events arrive, and operations to send events fail.
Note: | In safety-certified systems, failures and teardown are never supposed to occur. Although disconnect events are currently supported in the current safety release, they will be removed in later safety releases, and only supported for non-safety platforms. |
Resource Creation
Once the stream blocks are fully created, the next step is to create synchronization and buffer resources. The process of determining resource requirements and allocating them is much like that described in the simple single-buffer example at the beginning of this chapter. But all coordination between the producer and consumers is done through the stream, which automatically deals with any translations required to share the resources between processes, partitions, or systems.
Creation of synchronization and buffer resources can be done in either order, or can be intermingled. The two are similar, but the process for synchronizing objects is a little simpler.
Synchronization Resources
Before reading this section, be sure to read the full chapter on
Synchronization to understand how synchronization requirements are specified and synchronization objects are created. This section assumes familiarity with the commands used there and does not explain them in detail. The following sections cover how to coordinate synchronization objects through a stream.
Synchronization Requirements
Setting up synchronization resources begins by determining the requirements of each endpoint. The producer and consumers must query the NVIDIA drivers they are going to use with the appropriate APIs to obtain separate NvSciSyncAttrList handles representing the requirements for signaling (writing to) and waiting for (reading from) synchronization objects.
If an endpoint directly writes to or reads from the stream packets with the CPU instead of using an NVIDIA API, it does not generate any fences, and therefore does not need synchronization signaling requirements. It needs to perform CPU waits for fences from the other endpoint, and therefore must create a waiting requirement attribute list with the NeedCpuAccess flag set.
In some use cases, an application endpoint may require that packets it receives be available immediately, without waiting for any fence. In this case, it does not need to provide any synchronization waiting requirement attributes. Instead, it indicates to the other endpoint that it must do a CPU wait before sending the packets. This is not common but is provided to support these cases when they arise.
Once an endpoint has determined its signal and wait requirements for synchronization objects, it stores the signal requirements locally, and passes the wait requirements to the other endpoint through the stream. It fills in an NvSciStreamSyncAttr structure with the wait requirement attribute list and a boolean flag indicating the rare case where fences are not supported at all. This structure is then passed into the endpoint block by calling NvSciStreamBlockSyncRequirements(). The function call is the same for both producer and consumer endpoints.
typedef struct {
// Flag indicating fences are not supported
bool synchronousOnly;
// The read requirements for sync objects
NvSciSyncAttrList waiterSyncAttr;
} NvSciStreamSyncAttr
NvSciError
NvSciStreamBlockSyncRequirements(
NvSciStreamBlock block,
const NvSciStreamSyncAttr* attr)
Receiving Requirements
When the producer and consumer(s) specify their synchronization requirements, the other endpoint(s) receive(s) an NvSciStreamEventType_SyncAttr event. The syncAttr field is filled with the wait requirements to use in allocating synchronization objects.
If the synchronousOnly field in the structure is set in the event's syncAttr structure, then synchronization objects cannot be used to coordinate with the other endpoint. This case is rare, but producer and consumer application components that are designed to be fully modular must recognize and handle this situation. More focused applications do not need to deal with it. If set, the application must not allocate any synchronization objects, and signal a count of zero as described in the next subsection. It should also make note of the fact that it must behave synchronously, which comes into play during the streaming phase, described later.
If the synchronousOnly field is not set, then the waiterSyncAttr field of the stream's syncAttr structure is set to a synchronization attribute list handle. Ownership of this handle belongs to the application receiving the event, and it must free the handle when it is no longer needed. The attributes in this list may not exactly match those specified by the originating endpoint(s). If there is more than one consumer, then the stream combines their requirements into a single attribute list. The stream itself may also perform transformations on the attributes to handle cross-process or cross-system cases.
The application must merge these wait requirements with its own signal requirements to form the final reconciled synchronization attribute list. It can then use the final list to allocate one or more synchronization objects from NvSciSync. More than one synchronization object may be required in the case where multiple NVIDIA driver channels operate on the data at the same time, each requiring separate synchronization. The application must map these synchronization objects into the drivers and use them to generate fences passed into the stream.
Synchronization Objects
This section describes synchronization objects.
Sending Objects
After allocating the synchronization objects, the application must inform the stream. First, it can indicate the number of objects it provides with NvSciStreamBlockSyncObjCount(). In the common case where there is a single synchronization object, omit this call. A value of 1 is assumed when the object itself is specified. It must be called if there are zero or more than one synchronization objects.
For each synchronization object, it must fill in a NvSciStreamSyncDesc structure and call NvSciStreamBlockSyncObject(). Each index from 0 to the count-1 must be used exactly once. The index ordering chosen defines the order in which the endpoint passes fence arrays during the streaming phase. Ownership of the synchronization object's handle remains with the caller. The stream creates a duplicate before the function returns.
typedef struct {
// The index of the sync object
uint32_t index;
// Handle of the sync object
NvSciSyncObj sync;
} NvSciStreamSyncDesc
NvSciError
NvSciStreamBlockSyncObjCount(
NvSciStreamBlock block,
uint32_t count
)
NvSciError
NvSciStreamBlockSyncObject(
NvSciStreamBlock block,
const NvSciStreamSyncDesc* sync
)
Receiving Objects
On the other endpoint, a NvSciStreamEventType_SyncCount event is received, followed by a NvSciStreamEventType_SyncDesc event for each of the synchronization objects. For the SyncCount event, the count field in the event structure contains the number of synchronization objects that are provided. For the SyncDesc events, the syncDesc field in the event structure contains the index and handle of each synchronization object. Ownership of the handle belongs to the application receiving the event, and it must free the sync object when it is no longer required. The application must map these into the drivers, and use them to interpret fences received from the stream.
As with the requirements, the synchronization objects received may not exactly match those sent. If there is more than one consumer, the stream combines their synchronization objects into a single list before passing it to the producer. The stream may also replace the synchronization objects with its own if it must perform intermediate copy operations to pass the data from one endpoint to the other.
Comparison with EGL
When using EGLStreams, there is never any need to explicitly deal with synchronization objects. They are present in the NVIDIA EGL implementation, but require no action on the application's part. This is possible because the producer and consumer rendering libraries connect directly to an EGLStream, and are able to coordinate synchronization setup themselves through the stream without the user being aware of it. In the NvSciStream model, the rendering libraries do not access the stream. Resources must be transferred between them and the stream. Therefore, these additional steps are required to initialize synchronization.
Buffer Resources
The process of creating buffers is similar to that of creating synchronization objects. However, instead of allocating buffers themselves, the producer and consumer blocks communicate their requirements to a third block, the pool. The application component that owns this block is responsible for performing the allocations. For many use cases, this is the same application that manages the producer. But keeping this functionality in a separate block from the producer serves several purposes.
It allows NvSciStream to provide different types of pools for different use cases while sharing a common set of interfaces. For instance, you may choose a static pool with a fixed set of buffers for safety-certified builds, a dynamic pool that allows buffers to be added and removed in cases where the producers may change the data layout over time, or a remote pool managed by a central server process that doles out buffers to all streams in the application suite.
Furthermore, a stream may require additional pools beyond the one which feeds buffers to the producer. For instance, in cross-system use cases where memory is not shared between the producer and consumer, the IPC block on the consumer side also requires a pool to provide buffers into which data is copied. Keeping the pool as a separate block allows generic application components to be written that do not need to know whether the pool is used with a producer or another block.
Before reading this section, be sure to read the full chapter on
Buffers to understand how buffer requirements are specified and how buffers are created. This section assumes familiarity with the commands used there and does not explain them in detail. This section covers how to coordinate buffers through a stream.
Buffer Requirements
This section describes the buffer requirements.
Specifying Requirements
With synchronization objects, fences are generated at both endpoints and flow in both directions, so it was necessary for producer and consumer(s) to determine and exchange both write and read requirements. Buffer data, on the other hand, flows in only one direction, from the producer to the consumer(s). So the producer must query the NVIDIA drivers they use for buffer attribute lists that provide write capability, while consumers must query for buffer attributes that provide read capability. If the buffer memory is written or read directly with the CPU, attribute lists can be manually created, requesting CPU access.
A packet may consist of multiple buffer elements containing different types of data. The producer must obtain a buffer attribute list for each type of data it can generate, and consumers must obtain attribute lists for each type of data they require.
Once a producer knows all the elements it can provide, or a consumer knows all the elements it requires, it can inform the stream by calling NvSciStreamBlockPacketElementCount(). In the common case where the number of elements is one, this call can be omitted. Otherwise, the count must be provided. Although not common, a count of zero is allowed, and may be used if the stream is only required to provide synchronization between the endpoints, with no exchange of data.
After providing the count, the endpoint must call NvSciStreamBlockPacketAttr() once for each element with a NvSciStreamElementAttr structure containing the element details. The index field of the structure specifies the index of the element within the list of elements the endpoint provides or requires. The type field specifies a user-defined type value understood by both the producer and consumer(s). This is used to align the producer and consumer element lists, since they may be specified in different orders. The bufAttr field contains a handle for the element's attribute list. Ownership of this handle remains with the caller, and it deletes it when it is no longer needed after the function returns. NvSciStream creates a duplicate.
The mode field may be set to NvSciStreamElementMode_Asynchronous or NvSciStreamElementMode_Immediate, and describes the relationship between the data written to a packet's element and the fence sent with the data. Asynchronous elements data is not available to the consumer until the fences complete. This generally indicates data written using NVIDIA hardware. Immediate elements data is available to be read as soon as the packet is acquired by the consumer, without waiting for any fence. This generally indicates data written directly with the CPU.
The producer must specify which mode is appropriate for the data it generates. The consumer must specify asynchronous mode for all elements unless it has a requirement that the data be immediately available. A typical use case for this is a packet containing a large primary data element accompanied by a smaller metadata element containing information required to program the hardware for processing the primary element. Upon acquiring the packet, the metadata must be read immediately by the CPU, so that instructions for the NVIDIA drivers can be issued, but the primary data is read later once the fence has been reached.
typedef struct {
uint32_t index;
uint32_t type;
NvSciStreamElementMode mode;
NvSciBufAttrList bufAttr;
} NvSciStreamElementAttr
NvSciError
NvSciStreamBlockPacketElementCount(
NvSciStreamBlock block,
uint32_t count
)
NvSciError
NvSciStreamBlockPacketAttr(
NvSciStreamBlock block,
const NvSciStreamElementAttr* attr
)
Receiving Requirements
The primary pool connected to the producer block receives the number of elements the producer can provide in a PacketElementCountProducer event. Only the count field in the event structure is used. This is followed by one PacketAttrProducer event for each element the producer provides. The packetAttr field within the event structure contains the element information. The buffer attribute list handle within this field is owned by the application receiving the event, and it must free it when it is no longer required. Similarly, the pool receives PacketElementCountConsumer and PacketAttrConsumer events for the consumer buffer requirements.
As with synchronization requirements, the attributes received by the pool may not exactly match those sent by the producer and consumer endpoints. For the multicast case, the pool receives a combined list with one element for each type of attribute the consumers requested. Elements with the same type arrive as a single event with their attribute lists merged. The stream may also transform attributes to handle cross-process or cross-system cases.
Any secondary pools connected to IPC blocks also receive events for the producer and consumer elements. However, the producer events are delayed until the primary pool determines the final packet layout (discussed below). The producer element attributes the secondary pools receive are those sent by the primary pool.
Reconciling Requirements
The application managing the pool must take the capabilities provided by the producer and the requirements provided by the consumer(s) and determine the final packet layout. For each element type provided by the producer and required by a consumer, it should merge their attribute lists to obtain the attribute list to use in allocating the buffer. If there is an element type provided by the producer but not required by any of the consumers, omit it from the packets. If there is a type required by a consumer that the producer cannot provide, the application can trigger an error. However, there may be cases understood by the application suite where the consumer requirements actually represent several options, and only one of the requested element types is needed. If the producer can provide one of them, streaming can proceed. It is to support possible complex situations like this that the reconciliation process is left to applications, rather than being done automatically by the stream.
Once the application has determined the final layout, it calls the same NvSciStreamBlockPacketElementCount() and NvSciStreamBlockPacketAttr() functions used by the producer and consumer, this time with the pool block, to indicate the number and list of elements. This results in PacketElementCount and PacketAttr events at the producer and consumer blocks. The fields used are the same as those in the corresponding events received by the pool, as described above. The application(s) controlling these blocks use this information to interpret the data layout, and prepare to receive the actual packets.
Some care must be taken with the mode specified for each element. If a consumer requires access to data be immediate but the producer normally generates this data with asynchronous mode, then an extra burden is placed on the producer application. The pool must indicate to the producer that immediate mode is required. The producer takes note of this, and during streaming it waits for that element to finish being generated before it inserts the payload into the stream.
Buffer Exchange
This section describes buffer exchange.
Specifying Buffers
Once the element attributes have been specified, the application can now proceed to allocate buffers from NvSciBuf using the attribute lists. It creates packets using the pool object, allocates a buffer for each element of each packet, and then assigns them to their proper places in the packets.
To create a new packet, the application calls NvSciStreamPoolPacketCreate(). The cookie is a value that the application uses to look up its own data structures for the packet. It can be any non-zero value that the application chooses. Typically, it is either a 1-based index into an array of structures, or a pointer directly to the structure. Any events received on the pool object related to the packet references this cookie. On success, the function returns a new handle. The application stores this handle in its data structure for the packet and uses it whenever it needs to tell the stream to operate on the packet.
After creating a packet, the application assigns a buffer to each element by calling NvSciStreamPoolPacketInsertBuffer(). The desc structure contains the packet handle returned at packet creation, the index of the element being assigned, and the buffer handle. NvSciStream duplicates the buffer handle. Ownership of the original remains with the caller, and once the function returns, it may safely free the buffer.
For static pools, the number of packets expected is specified when the pool is created. Streaming cannot begin until this number of packets is created. If the application tries to create more than this number of packets, an error occurs.
typedef struct {
uint32_t index;
NvSciStreamPacket handle;
NvSciBufObj buffer;
} NvSciStreamElementDesc
NvSciError
NvSciStreamPoolPacketCreate(
NvSciStreamBlock pool,
NvSciStreamCookie cookie,
NvSciStreamPacket* handle
)
NvSciError
NvSciStreamPoolPacketInsertBuffer(
NvSciStreamBlock pool,
const NvSciStreamElementDesc* desc
)
Receiving Buffers
When a packet is added to a pool, any producer or consumers that pool serves is notified with a packetCreate event. The packetCreate field in the event structure is set with the handle of the new packet. The packet handles seen by the producer and consumer(s) may or may not be identical to those seen by the pool, or each other. Applications should not count on these handles matching.
Upon receiving this event, the endpoint prepares a new packet data structure to manage the buffers, and stores the handle in it. It then calls NvSciStreamBlockPacketAccept(). The err parameter indicates whether the application was successful in setting up the new packet. If so, the value is NvSciError_Success. Otherwise, it can be any value the application chooses. NvSciStream does not interpret the value except to check for success, and passes it back to the pool. If successful, the cookie parameter provides the endpoint's cookie for the packet. Each endpoint can provide its own cookie for each packet, which is used in subsequent events. The producer and/or consumers may assign the same cookies as the pool but are not required to do so.
If an endpoint successfully accepts a packet, it then receives packetElement events for each element in the packet. The packetCookie field in the event structure identifies the packet, and the packetElement field is filled in with the index of the element and its buffer handle. The buffer handle is owned by the application receiving the event, and it frees it when it is no longer needed.
Upon receiving each buffer, the application maps it into any NVIDIA drivers that are used to operate on the buffer. It then calls NvSciStreamBlockElementAccept() to indicate success or failure of mapping the buffer. As with the packet acceptance, NvSciStream does not interpret the error value except to check for success, and passes it back to the pool.
NvSciError
NvSciStreamBlockPacketAccept(
NvSciStreamBlock block,
NvSciStreamPacket handle,
NvSciStreamCookie cookie,
NvSciError err
)
NvSciError
NvSciStreamBlockElementAccept(
NvSciStreamBlock block,
NvSciStreamPacket handle,
uint32_t index,
NvSciError err
)
Completing Buffer Setup
When the producer successfully or unsuccessfully accepts a packet or element, a PacketStatusProducer or ElementStatusProducer event is received by the pool. Similarly, PacketStatusConsumer or ElementStatusConsumer events are received from the consumer. The error field in the event structure contains the error code provided by the endpoint. The packetCookie field identifies the packet using the pool's cookie, and for elements, the index field indicates the element. For multicast, success is indicated only if all consumers succeed. If any of them fail, the error code reported by the first one to fail is used.
Once all packet and element acceptance events are processed, the packets become available for the producer to render into. If setup of synchronization objects has also completed, streaming may begin.
Comparison with EGL
When using EGLStreams, this back and forth coordination of buffer attributes between the endpoints is not required. Buffers are created through the producer rendering interface and are communicated to the consumer when inserted in the stream. The downside of this is that, in most cases, the producer has no awareness of the consumer for which the buffers are intended. There is no way to ensure that the buffers the producer allocates are compatible with the consumer at the time they are created. If they aren't, then either streaming fails when the consumer receives the buffers, or a costly conversion process, of which the user is unaware, must be undertaken for every frame. The NvSciStream model puts more burden on the application when establishing the buffers but ensures that the optimal allocation settings are used for compatibility between producer and consumers.
Additionally, EGLStreams are far more restricted in the kinds of buffers they support. They allow two-dimensional image buffers rendered by the GPU and video, along with a limited set of metadata buffers generated by the CPU. NvSciStream allows multiple buffers of data rendered by either source. These buffers can contain images, arrays, tensors, or anything else the user requires.
Frame Production
Once setup is complete, the producer application enters a cycle of receiving empty packets for reuse, writing to them, and inserting them back into the stream to be send to the consumer(s).
Note: | Resizing or otherwise replacing buffers during streaming is supported for non-safety builds, and is described in a later section when it becomes available. It is not supported in the current release. |
Obtaining Packets
When setup completes, the pool begins releasing the packets to the producer block for rendering. Subsequently, as payloads are returned from downstream because they were skipped or the consumer no longer needs them, they become available to the producer again. The order in which packets are received by the producer depends on various stream settings and is not deterministic, but the pool tries to optimize so that buffers with the least wait time until it is safe to write to them are available first.
When a packet becomes available for writing, a PacketReady event is received by the producer block. None of the extra data fields in the event structure are used for this type of event. The packet info is retrieved by a subsequent call. If multiple packets are available, the producer receives separate events for each of them.
After a packet becomes available, a producer application may call NvSciStreamProducerPacketGet() to obtain it. It provides an NvSciStreamPayload structure that NvSciStream populates with the packet information. The cookie field is filled in with the cookie the producer assigned to the packet. The prefences field points to an array with space for one fence for each of the sync objects provided by the consumer. If the consumer provides zero sync objects, this field can be NULL. The function fills in the array with the fences that indicate when the consumer is no longer using the data in the packet's buffers.
typedef struct {
NvSciStreamCookie cookie;
NvSciSyncFence* prefences;
} NvSciStreamPayload
NvSciError
NvSciStreamProducerPacketGet(
NvSciStreamBlock producer,
NvSciStreamPayload* payload
)
Writing Packets
Upon obtaining a packet, the producer application must ensure that the consumers are done reading from it before modifying their contents. If it is writing to the buffers using NVIDIA API, it must use the appropriate API-specific operation to insert a wait for each of the fences into the hardware command sequence. Then it looks up the API-specific buffer handle(s) for the packet and makes those buffers the current rendering targets. It may then proceed to issue rendering commands.
If instead the application writes directly to the buffer memory, it performs a CPU wait for all of the fences in the array. Then it can begin writing the new data.
A producer application may retrieve multiple packets at once from the pool. It may operate on them at the same time and may insert the completed packets into the stream in any order, not necessarily in which they were retrieved.
Presenting Packets
When it has finished issuing its rendering instructions, the producer application must provide synchronization for their completion. If the consumer sets the synchronousOnly flag during setup of the synchronization objects, then the producer must perform a CPU wait for rendering to finish before inserting the packet in the stream. Otherwise, it instructs the APIs it used to generate fences to trigger when rendering finishes. It fills in an array of fences, one for each of the sync objects the producer created. If some of the sync objects aren't relevant for the new payload, the application can clear their entries in the fence array to empty but must not leave the array contents undefined.
The application can now insert the packet back into the stream along with the fences by calling NvSciStreamProducerPacketPresent() with the handle of the packet and the array of post-fences. The stream makes the packet available to the consumer(s), performing any necessary copy or translations steps along the way to make the data and fences accessible. Once a packet has been presented, the application must not attempt to modify its contents until it is again returned for reuse.
NvSciError
NvSciStreamProducerPacketPresent(
NvSciStreamBlock producer,
NvSciStreamPacket handle,
NvSciSyncFence* postfences
)
Comparison with EGL
With EGLStreams, the process for rendering and presenting frames varies depending on the rendering API chosen. For EGLSurface producers, the application never directly interacts with the individual image buffers. It simply issues rendering instructions for the surface and a swap command when it is done with each frame. The NvSciStream process therefore requires more hands on interaction.
By contrast, use of CUDA and NvMedia producers for EGLStreams follows a very similar pattern to NvSciStream. After the first time a buffer is used, it is obtained from the stream when the consumer returns it. The application renders to the buffer, and then once again inserts it into the stream. The only real difference in buffer access is that with EGLStreams, the API’s buffer handles are returned directly, whereas with NvSciStream the application receives a cookie and must look up the corresponding API handle.
For all EGLStream producers, a key difference in NvSciStream is the need to manage fences. In EGLStreams, the act of presenting a frame triggers automatic fence generation based on internal tracking of the last instructions issued for the buffer. Similarly, when buffers are returned, a fence from the consumer is internally associated with the buffer and the API waits for it the next time that buffer is used. In NvSciStream, the application must take control of requesting fences from the APIs to be inserted in the stream and waiting for fences received from the stream. This is necessary in order to support the more general variety of usage models that NvSciStream can handle that EGLStream cannot.
Frame Consumption
The consumer side cycle mirrors that of the producer, receiving packets full of data, reading from them, and returning them to the producer to be reused.
Acquiring Packets
Just as the producer block receives a PacketReady event when a packet is available for reuse, the consumer block receives one when a packet containing new data arrives. Again, none of the extra data fields in the event structure are used for this type of event, and the packet info is retrieved by a subsequent call. If multiple packets are available, the consumer receives separate events for each of them.
After a packet becomes available, a consumer application may call NvSciStreamConsumerPacketAcquire() to obtain it. It provides an NvSciStreamPayload structure that NvSciStream populates with the packet information. The cookie field is filled in with the cookie the consumer assigned to the packet. The prefences field points to an array with space for one fence for each of the sync objects provided by the producer. If the producer provides zero sync objects, this field can be NULL. The function fills in the array with the fences that indicate when the producer is finished writing data to the buffers.
Consumer packets are always received in the order that the producer sends them, but depending on the stream settings (e.g., if a mailbox queue is used) some packets may be skipped. The consumer may acquire and hold multiple packets at once.
NvSciError
NvSciStreamConsumerPacketAcquire(
NvSciStreamBlock consumer,
NvSciStreamPayload* payload
)
Reading Packets
Upon obtaining a packet, the consumer must wait until the contents are ready before reading from it. Any elements that are set up with immediate mode can be accessed right away. For all other elements, it must wait for the fences provided.
If it reads from the buffers using NVIDIA API, it must use the appropriate API-specific operation to insert a wait for each of the fences into the hardware command sequence. Then it can look up the API-specific buffer handle(s) for the packet and make those buffers the current read sources. It can then proceed to issue commands that use the data.
If instead the application reads directly from the buffer memory, it must perform a CPU wait for all of the fences in the array. Then it can begin reading the new data.
Releasing Packets
When it finishes issuing instructions to read from a packet, the consumer must return the packet to the producer for reuse. Packets may be returned in any order, regardless of the order they were acquired.
Before sending the frame back, the consumer provides synchronization to indicate when its operations complete. If the producer set the synchronousOnly flag during setup of the synchronization objects, then the consumer must perform a CPU wait for reading to finish before inserting the packet in the stream. Otherwise, it must instruct the APIs it used to generate fences, which triggers when rendering finishes. It fills in an array of fences, one for each of the sync objects the consumer created. If some of the sync objects aren't relevant for how a given packet was used, the application can clear their entries in the fence array to empty but must not leave the array contents undefined.
The application can now insert the packet back into the stream along with the fences by calling NvSciStreamConsumerPacketRelease() with the handle of the packet and the array of post-fences. The stream returns the packet to the producer, performing any necessary copy or translations steps along the way to make the fences accessible. Once a packet is released, the application must not attempt to read its contents until a new payload using the packet arrives.
NvSciError
NvSciStreamConsumerPacketPresent(
NvSciStreamBlock consumer,
NvSciStreamPacket handle,
NvSciSyncFence* postfences
)
Comparison with EGL
As with the producer, consumer similarities between EGLStreams and NvSciStream depend on the rendering API chosen. For GL texture consumers, acquired buffers are bound directly to a selected texture, without the application knowing their details. CUDA and NvMedia consumers are closer to NvSciStream. The application receives individual buffers to read from and returns those to the stream when they are no longer required.
Again, the key difference in NvSciStream is the need to manage fences. Just as with the producer, EGLStreams handles all synchronization on behalf of the application, while with NvSciStream, the application is responsible for generating and waiting for fences.
Teardown
In safety-certified builds, destruction of NvSciStream blocks and packets is not supported. Once created, all objects persist until the application shuts down. In non-safety builds, streams can be dynamically torn down at any time, and new streams can be created.
Packet Destruction
Packets can be destroyed one by one with the function:
NvSciError NvSciStreamPoolPacketDelete(
NvSciStreamBlock pool,
NvSciStreamPacket handle)
This API schedules an existing packet to be removed from the pool. If the packet is currently in the pool, it is removed right away. Otherwise this is deferred until the packet returns to the pool. When the specified packet is returned to the pool, the pool releases resources associated with it and sends a PacketDelete event to the producer and consumer. Once deleted, the packet may no longer be used for pool operations.
Block Destruction
Regardless of type, all blocks are destroyed with the same function:
NvSciError
NvSciStreamBlockDelete(
NvSciStreamBlock block)
When called, the block handle immediately becomes invalid, making it an error to use in any function call unless it is reused for a new block. Any blocks connected to this one are informed that the stream has disconnected, if they haven't already, so that they may do an orderly cleanup. (It is not possible to connect a new block in place of a destroyed one.) Any resources associated with the block are scheduled for deletion, although this may not happen immediately if they are still in use by some part of the pipeline.