Deep Learning Accelerator Programming
The NVIDIA® Deep Learning Accelerator (DLA) component provides a set of APIs that run interference on a provided network on the NVIDIA SoC DLA.
Sequence of Tasks
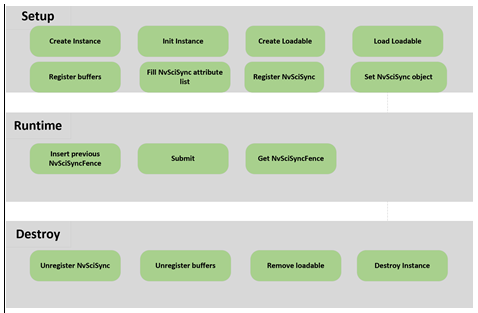
The following diagram illustrates the sequence of tasks that applications follow when using NvMedia DLA.
The following sections describe the sequence of tasks in the flow diagram above.
Setup
Allocate, configure, and set up all resources before attempting any runtime calls. Due to safety requirements, NVIDIA does not recommend calling these setup APIs during runtime.
1. Create instance.
2. Initialize the instance.
Initialize the instance with the instance ID and number of tasks with API NvMediaDlaInit().
3. Create the loadable.
Create a loadable opaque handle with NvMediaDlaLoadableCreate(). The handle is populated when the loadable is loaded into the instance.
4. Load the loadable.
Load a binary loadable into a DLA instance with the provided APIs in the following order:
NvMediaDlaAppendLoadable
NvMediaDlaLoadLoadable
Only one loadable can be appended to the instance. Clients must call NvMediaSetCurrentLoadable to specify which loadable to work on.
The binary loadable is created by the TensorRT builder. One example test app to create a binary loadable is located
here:
5. Register buffers.
Register all buffers that will be used with the instance. Registration API is NvMediaDlaDataRegister.
6. Fill the NvSciSync attribute list.
The DLA instance fills in the NvSciSync attributes to provided memory with NvMediaDlaFillNvSciSyncAttrList.
7. Register NvSciSync.
Register all NvSciSync objects that will be used with the instance. Registration API is NvMediaDlaRegisterNvSciSyncObj.
8. Set the NvSciSync object.
Set end-of-frame (EOF) NvSciSync object or start-of-frame (SOF) NvSciSync object to the instance, if needed. The related APIs are NvMediaSetNvSciSyncObjforSOF and NvMediaSetNvSciSyncObjforEOF.
Runtime
Run the inference with input data on the provided loadable.
1. Insert the previous NvSciFence.
Insert the previous NvSciFence to the instance. The operation is blocked until the expiration of the previous NvSciFence. The related API is NvMediaDlaInsertPreNvSciSyncFence.
2. Submit.
Submit a task with specified inputs and outputs to the hardware engine with NvMediaDlaSubmit.
This is a non-block call. Applications can choose to block and wait for an operation on a particular buffer to complete. To do so, use the following NvMediaTensorGetStatus function, as applicable.
3. Get NvSciFence.
Get the end-of-frame(EOF) or start-of-frame(SOF) from the instance. The expiration of EOF indicates the completion of the operation and the expiration of SOF indicates the start of the operation. The related APIs are NvMediaDlaGetEOFNvSciSyncFence and NvMediaDlaGetSOFNvSciSyncFence.
Destroy
Free all resources.
1. Unregister NvSciSync objects.
Unregister all registered NvSciSync objects using NvMediaDlaUnregisterNvSciSyncObj.
2. Unregister data.
Unregister all registered buffers using NvMediaDlaDataUnregister.
3. Remove the loadable.
Remove the loaded loadable from the instance with NvMediaDlaRemoveLoadable.
4. Destroy the loadable handle.
Destroy the created loadable handle with NvMediaDlaLoadableDestroy.
5. Destroy the instance.
Destroy the hardware engine instance using NvMediaDlaDestroy to free all resources.
Supported Tensor Formats
The following table describes DLA support for NvMediaTensor format types.
Input Tensor Ordering and Precision | Output Tensor Ordering and Precision |
|
NHWC with INT8 | NC/xHWx with INT8 |
NC/xHWx INT8 | NC/xHWx INT8 |
NHWC with FP16 | NC/xHWx with FP16 |
NC/xHWx FP16 | NC/xHWx FP16 |