Tegra GPU Scheduling Improvements
Warning: | There is a conflict in environment variables when using the same terminal to build and flash the tools. Unset the TEGRA_TOP environmental variable before trying to flash, or use different terminals to build and flash. |
NVIDIA® Tegra® GPU scheduling architecture addresses the quality of service (QoS) for several classes of work. The following table summarizes these classes of work.
Priority | Description | Workload |
|---|---|---|
HIGH | Critical applications that must meet their rendering deadlines | Small workloads (executable within a display refresh cycle), typically 60 frames/second (fps) |
MEDIUM | Well-behaved applications that are not known to cause channel reset | Small-to-medium workloads (may be spread across several refresh cycles) |
LOW | Long-running or potentially rogue applications (e.g., WebGL contexts) | Small-to-large workloads |
Scheduling Parameters
Applications can achieve the desired QoS by tweaking the following scheduling parameters:
• timeslice: Specifies the maximum time a channel can use an engine uninterrupted.
• runlist interleave frequency: Specifies the number of times a channel can appear on a runlist.
• preemption type: Defines the preemption boundary and how a context is saved.
Previous Limitations
In the previous implementation, applications could set the timeslice (via a sysfs interface) and the preemption type, but the runlist interleave frequency was fixed at 1. This resulted in high-priority applications receiving only one scheduling point per iteration of all channels on the runlist. (For more information, see Runlist Interleave Frequency in this chapter). This implementation was insufficient to let high-priority applications reach their target frame rate.
Setting the Timeslice
Use the following guidelines when setting the timeslice, depending on the priority of the application.
Low-Priority Applications
For low-priority applications, set the timeslice both:
• Large enough that an application can make progress, but
• Not so large that it affects the scheduling latency of high- or medium-priority applications.
The recommended upper bound for timeslice in low-priority applications is 1.5 milliseconds (ms).
Medium-Priority Applications
For medium-priority applications, set the timeslice both:
• Large enough that an application can make progress, but
• Not so large that it affects the scheduling latency of high-priority applications.
The recommended upper bound for timeslice in medium-priority applications is 2 ms.
High-Priority Applications
For high priority applications, set the timeslice large enough so that all work can be completed within one timeslice.
The recommended upper bound for timeslice in single, high-priority applications is:
16.6 ms − lpt − cst – crt = 11.6 ms
Where:
• lpt is the low-priority timeslice, set to 1.5 ms
• cst is the context-switch timeout, equal to 2.0 ms
• crt is the channel reset time, equal to 1.5 ms
For multiple, high-priority applications, use the timeslice for each high-priority application to determine a reasonable bound. The recommended combined workload of all high-priority applications must not exceed 50% of a display refresh cycle.
High-priority applications must avoid flushing work prematurely, whether by calling glFlush or glFinish or by other means. This ensures all rendering for a frame completes without any context switches.
Reserve Time for Lower-Priority Applications
To ensure lower-priority applications make reasonable progress, you must ensure that high- and medium-priority applications do not use 100% of the GPU by:
• Lowering your application frame rate targets and/or
• Reducing complexity of rendered frames.
The proportion of time to reserve for low-priority applications depends on the number and nature of the applications.
Setting the Preemption Type
High-Priority Applications
For high-priority applications, set the timeslice large enough that all work can complete. The recommeded Compute-Instruction-Level-Preemption (CILP) setting for graphics and for compute is a preemption type of Wait-For-Idle (WFI). This ensures CILP will not be hit because NVIDIA® CUDA® kernels will have completed.
Medium-Priority Applications
The recommended setting for medium-priority applications is a preemption type enabled for graphics (GFXP) and compute (CILP). For applications that can complete in their timeslice, context-switch overhead is minimal because the GPU is in an idled state.
Low-Priority Applications
For low-priority applications, always enable graphics and compute preemption because workloads are unpredictable.
Runlist Interleave Frequency
The runlist is an ordered list of channels that the GPU HOST reads to find work for the downstream engines to complete. To enable the GPU HOST to schedule a given channel more often, include the channel multiple times on a runlist. For each priority level, the runlist interleave frequency must be set to match the priority.
For example, if a system has one high-priority application, one medium-priority application, and two low-priority applications, the GPU scheduler constructs the runlist as follows:
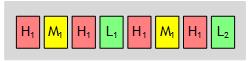
The scheduling latency for when a high-priority application will be able to run is governed by:
worst-case latency(high) = (h-1) × timeslice(high) + execution time(low) + channel reset
Where:
• h is the total number of high priority applications, and
• execution time(low) = timeslice(low) + context-switch timeout(low)

Setting Parameters
Use the following guidelines when setting scheduling parameters.
• Identify the relevant use cases before setting scheduling parameters.
• Associate a priority with each application.
• Determine appropriate timeslices.
Then using the environment variables listed below, specify the runlist interleave frequency, timeslice, and preemption type.
Environment Variable | Role | Values |
|---|---|---|
NVRM_GPU_CHANNEL_ INTERLEAVE | Sets runlist frequency for a context | 1: LOW 2: MEDIUM 3: HIGH |
NVRM_GPU_CHANNEL_ TIMESLICE | Sets timeslice for a context | Non-zero value in microseconds (minimum 1000 for 1 ms) |
NVRM_GPU_NVGPU_FORCE_ GFX_ PREEMPTION | Enables GFXP | 0: off 1: on |
Note: | The environment variables apply to all contexts belonging to a process. |
Setting Parameters on Behalf of Other Applications
A privileged application can set scheduling parameters (timeslice and interleave) on behalf of other applications based on their PID.
The libnvrm_gpusched library provides a way to:
• Get a list of all TSGs
• Get a list of recent TSGs (i.e., a list of TSGs opened since the last query)
• Get a list of TSGs opened by a given process
• Get notifications when a TSG is allocated
• Get current scheduling parameters for a TSG
• Set runlist interleave for a TSG
• Set timeslice for a TSG
• Lock control (i.e., prevent other applications from changing their own scheduling parameters such as timeslice and interleave)
Library API is defined in nvrm_gpusched.h and sample code implements command line to control GPU scheduling parameters.
Building GPU Scheduling Sample Applications
Enter:
cd <top>/drive-t186ref-linux/samples/nvrm/gpusched
make clean
make
Running the GPU Scheduling Sample Application
Here is a step-by-step example that shows how to tweak the GPU scheduling parameters on behalf of other applications based on their PID.
To schedule a high-priority app to render at the desired frame rate
1. Boot native Linux or a single Linux VM with a 4K HDMI display supporting 60 Hz refresh rate attached to a DRIVE OS 5.2 Linux platform, and start X.
sudo ./nvrm_gpusched set interleave 3
sudo ./nvrm_gpusched set timeslice 11600
sudo –b X –ac –noreset –nolisten tcp
2. Start 16 instances of bubble by entering this command:
export DISPLAY=:0
export NVRM_GPU_NVGPU_FORCE_GFX_PREEMPTION=1
export NVRM_GPU_CHANNEL_INTERLEAVE=1
export NVRM_GPU_CHANNEL_TIMESLICE=1000
export NV_SWAPINTERVAL=1
export WIDTH=960
export HEIGHT=540
let Y=2160-HEIGHT
while [ $Y -ge 0 ]; do
let X=3840-WIDTH
while [ $X -ge 0 ]; do
<top>/drive-t186ref-linux/samples/opengles2/bubble/x11/bubble -windowsize $WIDTH $HEIGHT -windowoffset $X $Y -msaa 8 -fps &
sleep 1
let X=X-WIDTH
done
let Y=Y-HEIGHT
done
3. Wait about 10 seconds and record the frame rate of the bubble instances. All instances should have a similar frame rate, and lower than 60 fps.
4. Check scheduling parameters using:
sudo ./nvrm_gpusched get params
5. Change the timeslice and runlist interleave of the last instance by entering:
sudo ./nvrm_gpusched set timeslice -p <pid> 3000
sudo ./nvrm_gpusched set interleave -p <pid> 2
6. Wait about 10 seconds and record the frame rate of the last instance of bubble. It should be fixed around 60 fps, and the other instances should be running lower.
Note that NV_SWAPINTERVAL=1 limits the frame rate to the monitor’s refresh rate.
7. Restore timeslice to its previous value for the last bubble instance:
sudo ./nvrm_gpusched set timeslice -p <pid> 1000
sudo ./nvrm_gpusched set interleave -p <pid> 1
8. Wait about 10 seconds and check that all bubble instances have about the same fps.