DNN Plugins Overview
The DNN Plugins module enables DNN models that are composed of layers that are not supported by TensorRT to benefit from the efficiency of TensorRT.
Integrating such models to DriveWorks can be divided into the following steps:
- Implement custom layers as dwDNNPlugin and compile as a dynamic library
- Generate TensorRT model with plugins using tensorRT_optimization tool
- Load the model and the corresponding plugins at initialization
Implementing Custom DNN Layers as Plugins
- Note
- Dynamic libraries representing DNN layers must depend on the same TensorRT, CuDNN and CUDA version as DriveWorks if applicable.
A DNN plugin in DriveWorks requires implementing a set of pre-defined functions. The declarations of these functions are located in dw/dnn/plugins/DNNPlugin.h.
These functions have _dwDNNPluginHandle_t in common. This is a custom variable that can be constructed at initialization and used or modified during the lifetime of the plugin.
In this tutorial, we are going to implement and integrate a pooling layer (PoolPlugin) for an MNIST UFF model. See DNN Plugin Sample for the corresponding sample.
In PoolPlugin example, we shall implement a class to store the members that must be available throughout the lifetime of the network model as well as to provide the methods that are required by dwDNNPlugin. One of these members is CuDNN handle, which we shall use to perform the inference. This class will be the custom variable _dwDNNPluginHandle_t that will be passed to each function.
class PoolPlugin
{
PoolPlugin() = default;
PoolPlugin(const PoolPlugin&) = default;
virtual ~PoolPlugin() = default;
int initialize();
void terminate();
size_t getWorkspaceSize(int) const;
void deserializeFromFieldCollections(
const char8_t* name,
void deserializeFromBuffer(
const char8_t* name,
const void* data,
size_t length);
int32_t getNbOutputs() const;
int32_t numInputs, int32_t numOutputs) const;
int enqueue(int batchSize, const void* const* inputs, void** outputs, void*, cudaStream_t stream);
size_t getSerializationSize();
void serialize(void* buffer);
static const char* getPluginType()
{
return "MaxPool";
}
static const char* getPluginVersion()
{
return "2";
}
void setPluginNamespace(const char* libNamespace);
const char* getPluginNamespace() const;
private:
template<typename T> void write(char*& buffer, const T& val);
template<typename T> T read(const char* data, size_t totalLength, const char*& itr);
std::shared_ptr<int8_t[]> m_tensorInputIntermediateHostINT8;
std::shared_ptr<float32_t[]> m_tensorInputIntermediateHostFP32;
float32_t* m_tensorInputIntermediateDevice =
nullptr;
std::shared_ptr<float32_t[]> m_tensorOutputIntermediateHostFP32;
std::shared_ptr<int8_t[]> m_tensorOutputIntermediateHostINT8;
float32_t* m_tensorOutputIntermediateDevice =
nullptr;
PoolingParams m_poolingParams;
std::map<dwPrecision, cudnnDataType_t> m_typeMap = {{
DW_PRECISION_FP32, CUDNN_DATA_FLOAT},
cudnnHandle_t m_cudnn;
cudnnTensorDescriptor_t m_srcDescriptor, m_dstDescriptor;
cudnnPoolingDescriptor_t m_poolingDescriptor;
std::string m_namespace;
};
Creation
A plugin will be created via the following function:
dwStatus _dwDNNPlugin_create(_dwDNNPluginHandle_t* handle);
In this example, we shall construct the PoolPlugin and store it in the _dwDNNPluginHandle_t:
{
std::unique_ptr<PoolPlugin> plugin(new PoolPlugin());
return DW_SUCCESS;
}
Initialization
The actual initialization of the member variables of PoolPlugin is triggered by the following function:
As you can see above, the same plugin handle is passed to the function and the initialize method of this handle can be called as the following:
{
auto plugin = reinterpret_cast<PoolPlugin*>(handle);
plugin->initialize();
return DW_SUCCESS;
}
In PoolPlugin example, we shall initialize CuDNN, Pooling descriptor and source and destination tensor:
int initialize()
{
CHECK_CUDA_ERROR(cudnnCreate(&m_cudnn));
CHECK_CUDA_ERROR(cudnnCreateTensorDescriptor(&m_srcDescriptor));
CHECK_CUDA_ERROR(cudnnCreateTensorDescriptor(&m_dstDescriptor));
CHECK_CUDA_ERROR(cudnnCreatePoolingDescriptor(&m_poolingDescriptor));
CHECK_CUDA_ERROR(cudnnSetPooling2dDescriptor(m_poolingDescriptor,
m_poolingParams.poolingMode, CUDNN_NOT_PROPAGATE_NAN,
m_poolingParams.kernelHeight,
m_poolingParams.kernelWidth,
m_poolingParams.paddingY, m_poolingParams.paddingX,
m_poolingParams.strideY, m_poolingParams.strideX));
return 0;
}
TensorRT requires plugins to provide serialization and deserialization functions. Following APIs are needed to be implemented in order to meet this requirement:
An example of serializing to / deserializing from buffer:
size_t getSerializationSize()
{
size_t serializationSize = 0U;
serializationSize += sizeof(m_poolingParams);
serializationSize += sizeof(m_inputBlobSize);
serializationSize += sizeof(m_outputBlobSize);
serializationSize += sizeof(m_precision);
{
}
return serializationSize;
}
void serialize(void* buffer)
{
char* d = static_cast<char*>(buffer);
write(d, m_poolingParams);
write(d, m_inputBlobSize);
write(d, m_outputBlobSize);
write(d, m_precision);
{
write(d, m_inHostScale);
write(d, m_outHostScale);
}
}
void deserializeFromBuffer(
const char8_t* name,
const void* data,
size_t length)
{
const char* dataBegin = reinterpret_cast<const char*>(data);
const char* dataItr = dataBegin;
m_poolingParams = read<PoolingParams>(dataBegin, length, dataItr);
m_inputBlobSize = read<dwBlobSize>(dataBegin, length, dataItr);
m_outputBlobSize = read<dwBlobSize>(dataBegin, length, dataItr);
m_precision = read<dwPrecision>(dataBegin, length, dataItr);
{
m_inHostScale = read<float32_t>(dataBegin, length, dataItr);
m_outHostScale = read<float32_t>(dataBegin, length, dataItr);
}
}
Destroying
The created plugin shall be destroyed by the following function:
For more information on how to implement plugin, please see DNN Plugin Sample.
Plugin Lifecycle
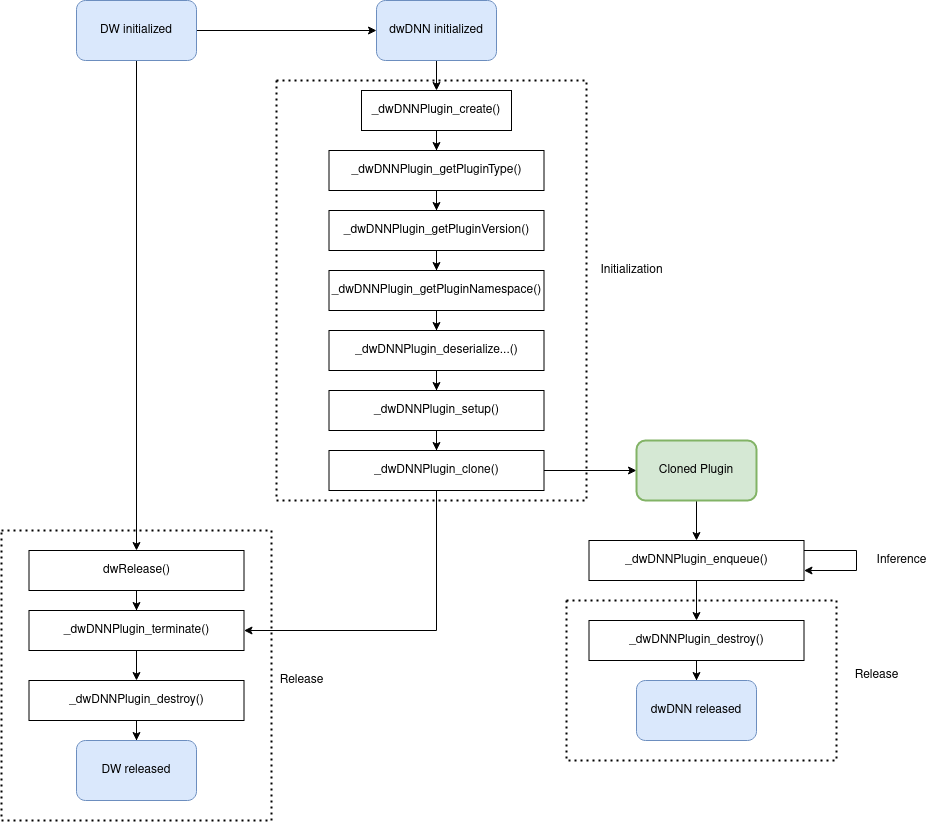
Plugin Lifecycle
Generating TensorRT Model with Plugins
In PoolPlugin example, we have only one custom layer that requires a plugin. The path of the plugin is libdnn_pool_plugin.so, assuming that it is located in the same folder as TensorRT Optimizer Tool. Since this is a UFF model, the layer names do not need to be specified. Therefore, we can create a plugin.json file as follows:
{
"libdnn_pool_plugin.so" : [""]
}
Finally, we can generate the model by:
./tensorRT_optimization --modelType=uff --uffFile=mnist_custom_pool.uff --inputBlobs=in --outputBlobs=out --inputDims=1x28x28 --pluginConfig=plugin.json --out=mnist_with_plugin.dnn
Loading TensorRT Model with Plugins
Loading a TensorRT model with plugin generated via TensorRT Optimizer Tool requires plugin configuration to be defined at initialization of dwDNNHandle_t.
The plugin configuration structures look like this:
typedef struct
{
size_t numCustomLayers;
typedef struct
{
const char* pluginLibraryPath;
const char* layerName;
Just like the json file used at model generation (see plugin json), for each layer, the layer name and path to the plugin that implements the layer must be provided.
In PoolPlugin example:
std::string pluginPath = "libdnn_pool_plugin.so";
pluginConf.customLayers = &customLayer;
See DNN Plugin Sample for more details.