

NVIDIA Requirements for AI Clouds
Purpose and Intent
This document serves three main purposes:
- Setting requirements for NVIDIA Cloud Partners (NCPs) delivering GPU capacity to NVIDIA
This is the primary requirements document from NVIDIA to any NCP providing NVIDIA GPU/AI compute and software services. These requirements cover the full stack of AI cloud infrastructure services and operations needed to run NVIDIA DGX Cloud, expanding on the NVIDIA hardware reference design. - Providing a reference set of requirements for the industry
NVIDIA is publishing this document openly so that NCPs, GPU datacenter operators, and AI practitioners can use it as a reference for the capabilities a large GPU consumer requires. - Defining NVIDIA’s service delivery expectations
NVIDIA expects services to be delivered as generally available services, not as bespoke implementations built for NVIDIA alone. NVIDIA also expects operational excellence, transparent communication, and proactive engagement from all partners.
NVIDIA will consider additional services that an NCP offers or plans to offer beyond what is described here.
Service Delivery SLAs
NCPs should be able to demonstrate their ability to meet the SLAs and operational requirements below, by category, to be considered for offtake.
Service Delivery Timelines
The NCP must demonstrate API readiness and transport establishment at least 12 weeks ahead of GPU delivery. Additionally, the NCP must provide development capacity (ancillary CPU nodes only) and high-performance storage capacity with the API integrated 8 weeks before GPU and cluster delivery. At this T-minus-8-week milestone, the Data Movement Systems Requirements must be met.
SLAs and SLOs
Managed K8s
- Control Plane SLA target: Financially-backed 99.95%+ uptime for production.
Storage
- Performance (QoS): Must provision the requested minimum throughput and IOPS.
- Home Directory Storage:
- Availability: Over 99.99% availability for unplanned incidents, exclusive of scheduled maintenance.
- Durability: Over 99.99% for any FS less than 1 PB.
- High-Speed Storage Service Requirements:
- Availability (SLO): Must meet 99.99% availability in a 30-day rolling SLO exclusive of maintenance.
- High-Speed Storage Filesystem Requirements:
- End-to-end Availability: Over 99.5% uptime per PB.
- Durability: Over 99.999% durability per PB annually.
Operational Requirements
- Dedicated technical specialist or engineer available to NVIDIA.
- Slack channel monitored by a technical specialist or engineer.
- 24x7 support available per the partner’s standard incident severity procedures, including emergency access recovery.
- Service-impacting incidents and planned and unplanned maintenance events are communicated to NVIDIA.
- For planned maintenance, NVIDIA can schedule maintenance windows through APIs or console tools, avoid unexpected outages, and provide feedback.
- NCP must remediate critical vulnerabilities in a timely manner while providing transparent disclosure of any issues.
Telemetry
NCP shall deliver all required telemetry, including metrics and logs, with a latency of no longer than 120 seconds.
Testing Compliance
The requirements described in this document can largely be validated using the tests in the AI Cloud Ready test suite. See the AI Cloud Ready documentation for details on how to run the tests. Tests are added regularly, so review the Requirements Test Matrix to find which tests validate which requirements.
Exemplar Cloud Workload Performance
NVIDIA Exemplar Cloud seeks to improve performance per TCO with hardware and software recipes, references, tools, and capabilities. Run the latest publicly available release from https://github.com/NVIDIA/dgxc-benchmarking and always select the latest release version from the GitHub repository. The release must be completed successfully on one uniform hardware cluster type. Run all workloads for a given release and share the results in the template below.
Compute and Network Provisioning
This section outlines the requirements for provisioning compute and network resources. Compute instances can be provided as either bare-metal instances (through BMaaS) or virtual machines (through VMaaS) to support the NVIDIA DGX Cloud engagement. All operations must be controlled through a fully documented and secure API; gRPC or REST is preferred. All systems are expected to scale and perform at scale.
General, Compute, and Lifecycle Management
Boot Process and Disks
SDN and Virtual Networking
This section covers the virtual networking requirements. Physical transport and networking requirements are discussed later in this document.
Kubernetes as a Service (KaaS) Requirements
Kubernetes Conformance, Versioning, and Compliance
Kubernetes Operational Excellence
Robust Kubernetes Security
Kubernetes Component and Extension Requirements
Kubernetes Functionality
Security and Identity Management
Identity and Access Management (IAM)
The platform must provide a centralized system for authentication, identity federation, authorization, and lifecycle provisioning across all platform services. It must integrate with a trusted external or platform-hosted identity provider and consume OIDC-based identity tokens for user authentication. Upstream identity sources and protocols, such as enterprise directories, may be used through federation with the identity provider.
Cryptography and Key Management
Network Isolation and Encryption
Edge Network Security
Hardware Security and Compliance
Breakfix Requirements
The NCP must provide a specific Breakfix API to support fleet reliability. Any node-level remediation must not impact other parts of the tenancy. Specifically, NVLink must be reconfigured properly to take a node out of the tenancy.
The API must enable the following actions:
Telemetry Requirements
The telemetry requirements comprise two core components that require alignment between DGX Cloud and the NCP:
- Delivery Method: How telemetry will be delivered by the NCP to DGX Cloud for ingestion.
- Telemetry Scope: What telemetry the NCP will deliver to DGX Cloud.
Delivery Method
NCPs must deliver all required telemetry, including metrics and logs, in a manner that allows ingestion into DGX Cloud systems with a latency of no longer than 120 seconds. Native OpenTelemetry Protocol delivery is preferred.
Telemetry Scope
DGX Cloud will provide the NCP with a specification document with the required metrics and logs. Upon receipt, the NCP must provide a formal written response detailing:
- Confirmation of its ability to deliver the specified metrics and logs.
- Projected timelines for delivery.
- Specific technical details, including metric names, label names, and label values.
Network Telemetry
The NCP must provide network telemetry across the following domains:
- North-South (front-end) network, including client-facing and external interconnects.
- East-West (back-end) network, including GPU/GPU interconnects.
- Management network, including control-plane and orchestration traffic.
- NVSwitch fabric, including intra-node GPU switching, applicable only for GB200 and later clusters.
- Host network, including NIC-level and server connectivity.
Logs
DGX Cloud will require the NCP to provide logs from various network technologies, including, but not limited to:
- Fabric Manager logs for the NVLink domain, where applicable.
- Subnet Manager logs for the NVLink domain, where applicable.
- VPC Flow logs for all ingress and egress traffic.
- UFM event logs.
- General switch logs.
- Switch syslogs.
- Switch kernel logs.
- BMC SEL logs.
- Syslogs.
- Management logs.
Storage Requirements
NCPs must provide shared storage solutions, where applicable, that are manageable through standard APIs and UIs, including auditing rights for NVIDIA access.
Home Directory Storage
- Quota Feature: Configurable filesystem-wide limit, default user/gid quota settings, and per-uid/gid overrides.
- Accounting: Usage accounting for uid/gids must be available when the feature is enabled.
High-Speed Storage Service Requirements
These are the requirements for provisioning and interacting with the provider’s service offering.
High-Speed Storage Filesystem Requirements
These capabilities are required for the high-speed filesystem.
Data Movement Systems Requirements
The Data Movement system copies data from an external data source, such as NVIDIA or another cloud, to the NCP data center. These requirements must be met eight weeks before the first tranche of GPU delivery.
DGXC-Managed Storage System Deployment
For scenarios where DGXC, rather than the NCP, deploys and manages the storage-system software, the following requirements apply. These requirements enable DGXC to operate storage systems, such as high-speed parallel filesystems, capacity object storage, or block storage, using NCP-provided infrastructure while maintaining operational control. For storage systems provided by the NCP, disregard this section.
Host Provisioning and Lifecycle
Network Transport and Fabric Visibility
Backend Switch Fabric API
The purpose of this API is to expose sufficient information about the cluster network topology to enable efficient scheduling, placement, and optimization of multi-node GPU workloads. Understanding the network hierarchy between compute instances and switches, as well as intra- and inter-node NVLink domains, is essential for minimizing communication latency and maximizing throughput. This applies to north-south, east-west, and NVLink networks, but not to management networks. See the appendix for a DGXC-recommended reference implementation.
Transport and Networking Requirements
Non-Conflicting IP Space Allocation for the DGXC Cluster
Purpose: Ensure DGXC GPU clusters deployed in an NCP can access the NVIDIA DGXC/CorpIT network directly through routing exchange. DGXC cluster IP address space must not conflict with existing NVIDIA private IP space.
Connection to NVIDIA CorpIT Network
Purpose: Provide a connection from DGXC GPU clusters within the NCP to NVIDIA CorpIT for internal command, control, and administrative access.
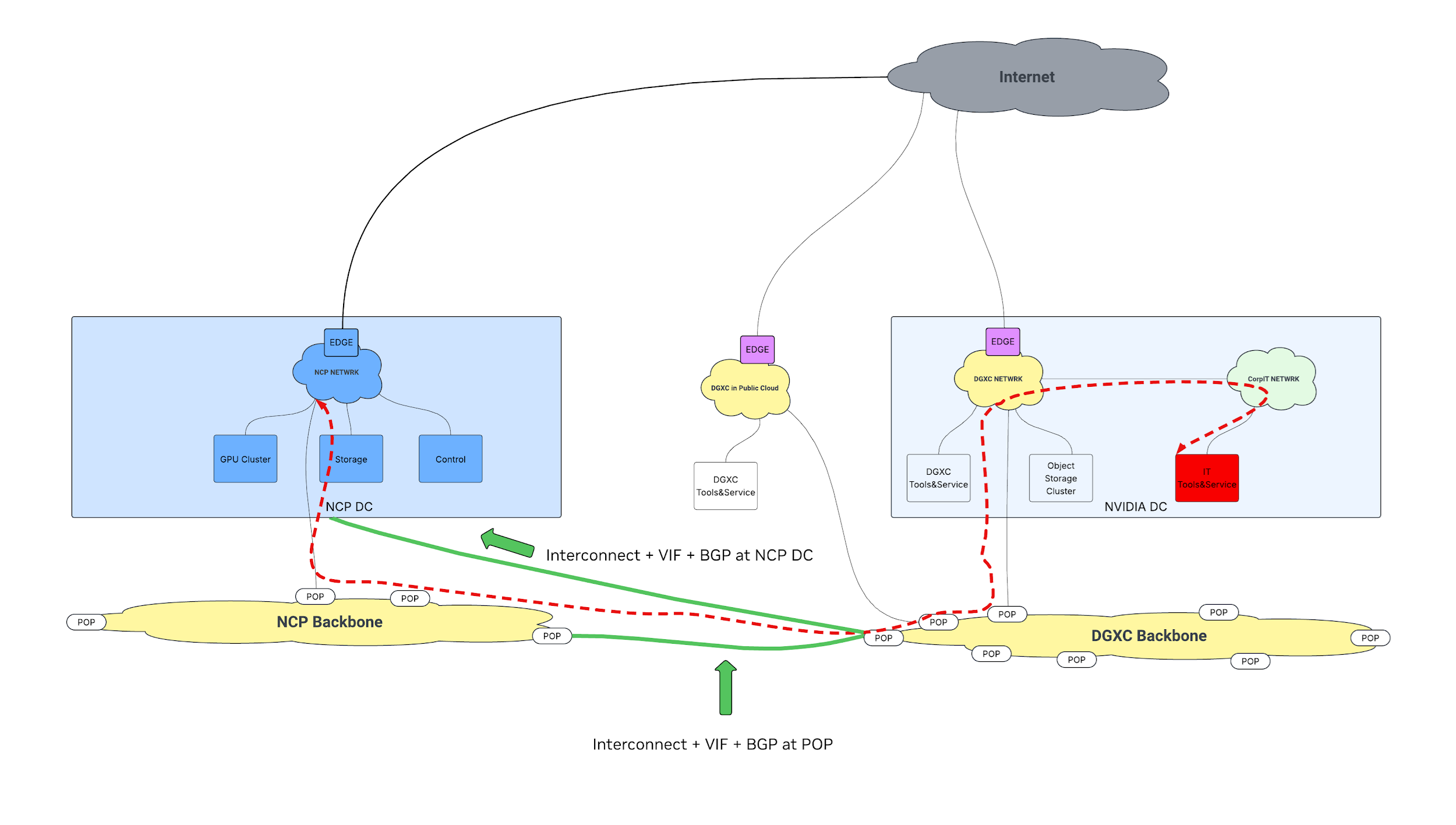
Figure: Private Cloud Interconnect + VIF + BGP for CorpIT access
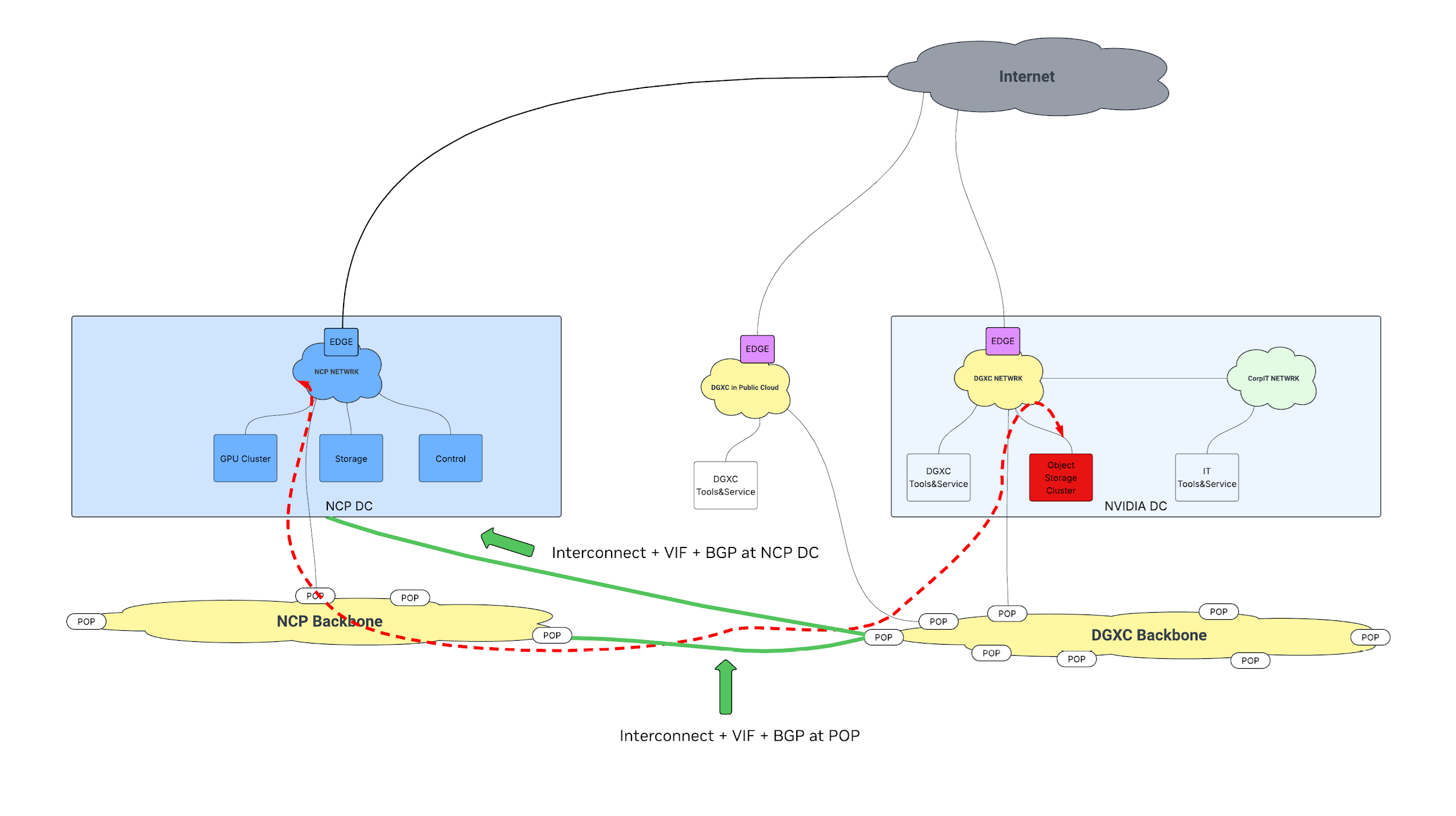
Connection to DGXC Storage
Purpose: Enable high-bandwidth, end-to-end MACsec-encrypted, fail-closed access between DGXC GPU clusters within the NCP and NVIDIA DGXC on-premises object storage for large-scale data movement.
Cluster Local Internet Access
Purpose: Provide general internet access from DGXC GPU clusters within the NCP to the internet, including NVIDIA DGXC hosted services on third-party public-cloud services.
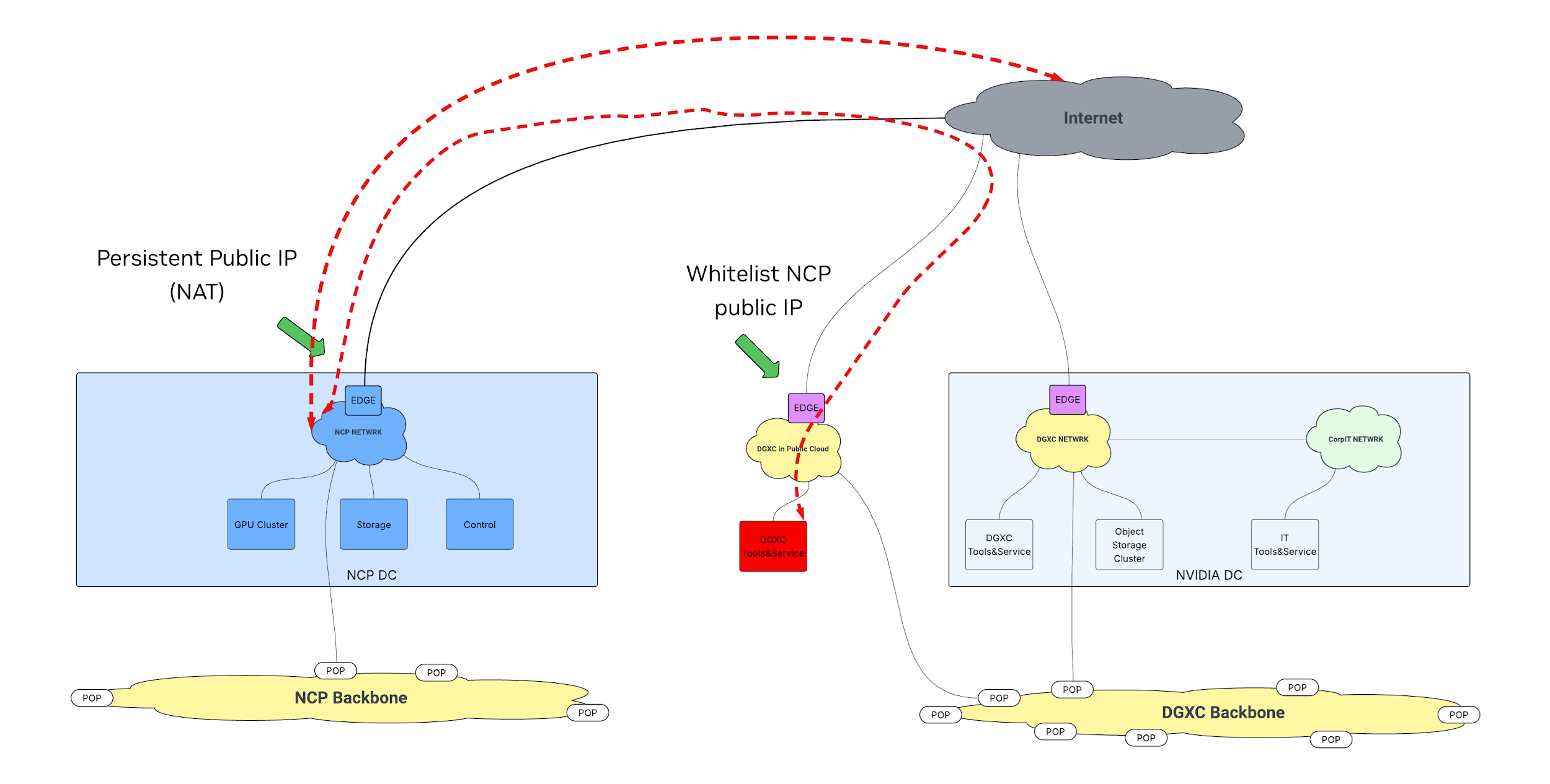
Figure: Public internet access for DGXC-hosted services
Capacity and Fleet Management
This section defines the essential metrics required for standardized monitoring and reporting of fleet health in partner engagements, supporting operations and contractual SLAs.
Appendix
This section contains links to reference documents and implementation guidance that provide additional details for NCPs.
Implementation Guidance
The following reference documents provide additional information on implementing some of the requirements in this guide.
- Network Topology Discovery: NVIDIA/topograph. Aligning with this YAML format may be useful. Topograph currently provides in-cluster topology.
- Breakfix B200: B200 DGXC Lazarus BreakFix Requirements.
- Breakfix GB300: GB300 DGXC Lazarus BreakFix Requirements.
- Breakfix scenarios: DGXC Breakfix Maintenance Events.
- Networking: Revised GNI - NCP - Cluster Connection Requirements for DGX Cloud.
- Exemplar Cloud: NVIDIA Exemplar Cloud and the DGXC benchmarking repository.
- Kubernetes security guidance: Kubernetes Security Response Committee.
Other Feature Considerations (Not Minimum Requirements)
- Disk Cloning: Disk-cloning capability for network-attached block devices. It should be possible to clone a disk even on a running instance.
- Managed Control Plane Autoscaling: Strong preference for the control plane to automatically add capacity when load increases.
- Threat Detection: Control planes, management planes, and hosts under the service provider’s control should deploy threat- and anomaly-detection solutions, for example HIDS and NIDS, that can identify active threats.
- Break-Glass Administrative Access: The platform should support a limited break-glass access mechanism for designated NVIDIA administrative users when federated SSO is unavailable, misconfigured, compromised, or otherwise prevents authorized access to the tenant. Break-glass accounts should use local platform credentials independent of the external identity provider, be explicitly excluded from SSO enforcement, and be protected by strong authentication controls including MFA. Their use should be auditable, generate security-relevant logs and alerts, and support periodic review, rotation, disablement, and testing.