

Benchmark Planner Decisions with DynoSim
This tutorial runs the Dynamo Planner inside DynoSim so you can compare aggregated and disaggregated topologies, tune SLA targets, and test sensitivity to worker startup time without a live cluster.
The production Planner scales Kubernetes or Global Planner deployments; it does not autoscale a
local CLI deployment. Although python -m dynamo.replay executes on your local machine, this
tutorial evaluates Planner decisions for a Kubernetes deployment through the virtual simulation
environment.
For the general replay workflow, see Run a DynoSim Simulation. For Planner field types and defaults, see the Planner Configuration reference. For how the simulation supplies metrics to the Planner, see DynoSim Architecture.
Prerequisites
Build the Rust runtime bindings and install the Python components from the repository root. Activate
the project virtual environment so the remaining commands use its python executable:
Use a release build because repeated simulation runs are CPU-bound.
The commands below use AIConfigurator-backed engine timing. The relevant fields are documented in the DynoSim Replay CLI Reference.
Set prefill_engine_num_gpu and decode_engine_num_gpu explicitly in every simulated Planner run.
The simulation adapter cannot auto-detect a deployment GPU count, and leaving both values unset
causes cumulative GPU-hours to report as zero.
Compare aggregated and disaggregated deployments
Download the trace:
Run agg (2 workers, TP=1):
Run disagg (1P1D, TP=1):
Each run prints the AIPerf summary table to stdout and writes an HTML diagnostics report to ./planner_reports/<report_filename>. For this trace with a long ISL and short OSL, agg is better than disagg, which gets slightly better ITL at the cost noticeably more GPU-hours.
Sweep cold-start time
How sensitive is SLA attainment to engine startup time? Sweep startup_time from 0 to 300 seconds in 10-second steps and record TTFT/ITL/GPU-hours per run.
Each run emits the AIPerf metrics table (parse TTFT / ITL avg / p90) and its HTML report (grep GPU hours: <float>). Plotting those against startup_time gives:
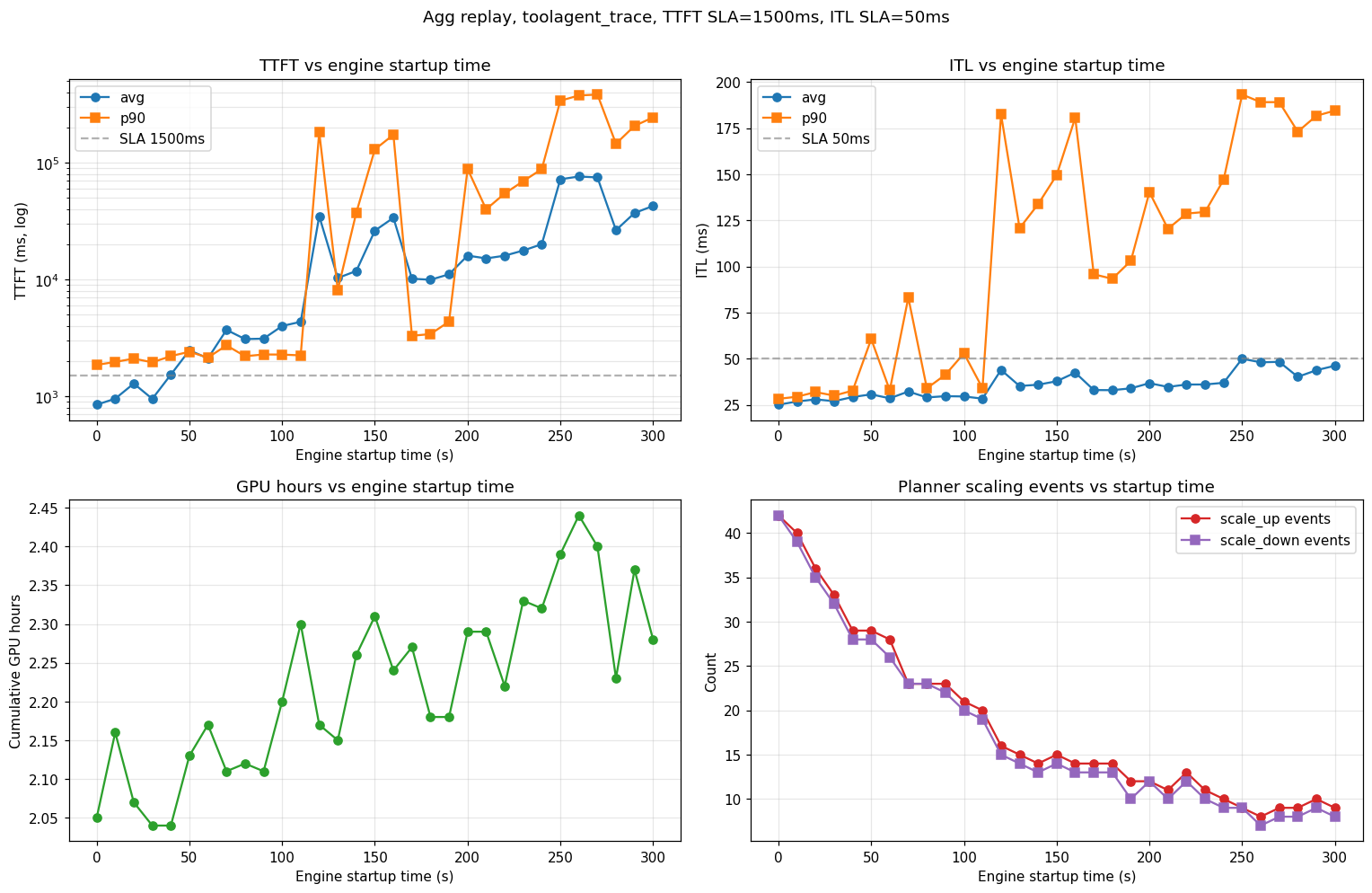
Observations from this sweep (agg, TTFT SLA 1,500 ms, ITL SLA 50 ms, H200-SXM, Llama-3.1-8B-FP8, TP=1):
- SLA cliff near 100–120 s. Below that, the planner scales up fast enough to hold TTFT; above it, p99 TTFT diverges and the system stays perpetually backlogged.
- Scaling-event count drops monotonically (42 → 8) as startup grows — long-startup runs require load planner to wait for stabilization before the next scaling decision.
- ITL is less sensitive than TTFT until the queue saturates. Below the cliff, ITL rises modestly (25 → 30 ms avg); above it, p90 ITL jumps to ~200 ms as decode requests starve.