Networking Logical Architecture#
This Enterprise RA uses a converged spine-leaf network providing physical fabrics for the use cases such as inferencing and fine-tuning. Deeper explanations of each of the fabric roles are below:
GPU Compute (E/W) Network
The GPU Compute (E/W) network is an RDMA based fabric in a spine-leaf architecture where the GPUs are connected using a rail-optimized network topology through their respective SuperNICs. This design allows the most efficient communication for multi-GPU applications within and across the compute nodes. In the architectures below for smaller design points the Compute Fabric has been merged with the Converged Fabric. This is to lower cost and to simplify the network architecture.
For larger network design points, due to the high number of endpoints required, it is recommended the Compute Fabric utilizes a super-spine, spine and leaf networking architecture. This is principally to support the required design points but also to allow extensibility in the architecture.
CPU Converged (N/S) Network
The CPU Converged (N/S) network connects the nodes using two 200 GbE ports to two separate switches to provide redundancy and high storage throughput. This network is used for node communications with compute along with storage, in-band management, and end-user connections as outlined below.
Storage (N/S) connectivity
This network specifically provides converged connectivity for storage infrastructure. Principally storage is attached on this network and then can be provided to the nodes via the CPU network as required.
Customer (N/S) Network Connectivity
Typically, this is upstream connectivity to connect the cluster into the rest of an enterprise customers networking infrastructure. This is provisioned to provide ample bandwidth for typical user communications.
Support Server (N/S) Network
This is dedicated networking for the respective support servers. These servers generally provide management, provisioning, monitoring, and control services to the rest of the cluster. High performance networking is used here due to requirements such as cluster deployment and imaging.
Out-of-band Management Networking for the infrastructure
All infrastructure requires management. This network provides bulk management 1Gb RJ45 connectivity for all the Nodes. This network uses low-cost bulk management switches. These switches have upstream connections to the Core networking infrastructure to allow flexibility and wider consolidation of services such as management and monitoring.
Note
VLAN isolation is used to provide logical separation of the networks above over the single physical fabric.
For cluster layouts larger than 4 SUs, an exception to the standard architecture is made. In these cases, a dedicated network is configured and implemented using a collapsed Spine-Leaf design for the GPU Compute (E/W) Network.
Enterprise RA Scalable Unit (SU)#
This Enterprise RA is built on scalable units (SU) based on 4 compute nodes. Each SU is a discrete entity of computation that is tied to the port availability size of the network devices. SUs can be replicated to adjust the scale of the deployment with more ease.
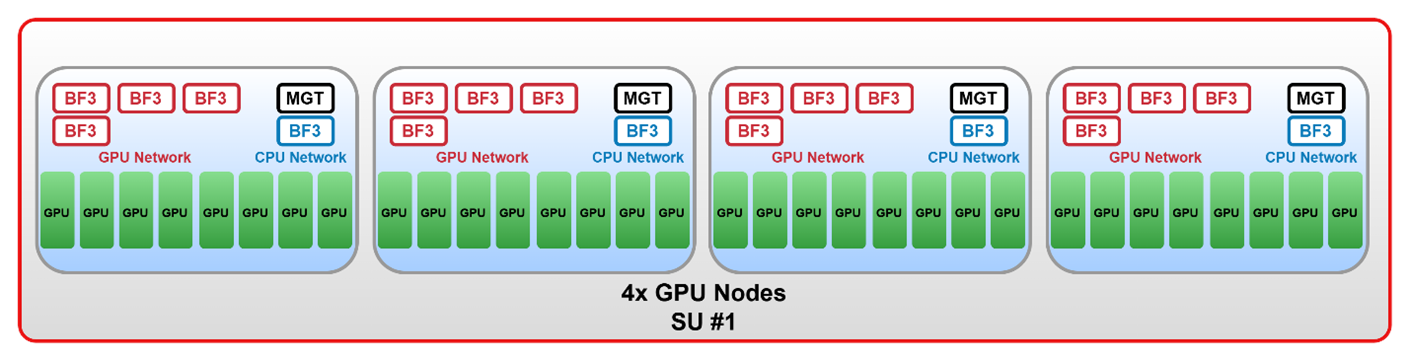
Figure 8 Example diagram of 4-Node SU.#
The 4-Node scalable unit provides the following connectivity building blocks:
For the Compute (E/W) fabric: 4 servers, each with 4x B3140H SuperNICs, providing 16x 400Gb/s connections and a total aggregate bandwidth of 6.4Tb/s under optimal conditions
For the Converged (N/S) fabric: 4 servers, each with 1x B3220 DPU providing 8x 200Gb/s connections and a total aggregate bandwidth of 1.6Tb/s under optimal conditions
For the Out-of-band Management fabric, 4 servers, each with 6x 1Gb/s connections providing 24x 1Gb/s for management under optimal conditions
Spine-Leaf Networking#
The network fabrics are built using switches with NVIDIA Spectrum-X Ethernet technology in a full nonblocking fat tree topology to provide the highest level of performance for the application running over the Enterprise RA configuration. The networks are RDMA-compliant, Ethernet-based fabrics in a spine-leaf architecture where the GPUs are connected using a rail-optimized network topology through their respective SuperNICs. This design allows the most efficient communication for multi-GPU applications within and across the nodes.
The leaf and spine architecture allows for a scalable and reliable network that can fit varied sizes of clusters using the same architecture. The compute network is designed to maximize bandwidth and minimize network latency required to connect GPUs within a server and within a rail.
In addition to the supported compute fabrics, the converged spine-leaf network also supports the following attributes:
Provides high bandwidth to high performance storage and connects to the data center network.
Each compute and management node is connected with two 200 GbE ports to two separate switches to provide redundancy and high storage throughput.
Out-of-Band (OOB) Management Network#
The OOB management network connects the following components:
Baseboard management controller (BMC) ports of the server nodes
BMC ports of the Bluefield-3 DPU and SuperNICs
OOB management ports of switches
This OOB network can also connect other devices that should have management connectivity physically isolated for security purposes. The SN2201 is used to connect to the BMC/OOB 1 Gbps ports of these components. Scale out this network using a 25 Gbps or 100 Gbps spine layer to connect the SN2201 uplink switches.
Optimized Use Case#
This architecture is optimized for both inference and fine-tuning use cases. Deployment of this single architecture will enable both types of workloads.
Architecture Details#
The NVIDIA 2-8-5-200 node architecture with NVIDIA Spectrum-X Networking utilizes 400 Gbps/interface for the East/West compute fabric. These components are detailed in Table 5 below.
Table 5: 2-8-5-200 Server Ethernet components with Spectrum-X fabric
Component |
Technology |
|---|---|
Compute node servers (4-32) |
2-8-5-200 node architected servers with 8 RTX™ PRO 6000 Blackwell Server Edition GPUs, configured with |
Compute (E/W) Spine-Leaf Fabric |
NVIDIA SN5610 128-port 400 GbE switches |
Converged (N/S) Spine-Leaf Fabric |
NVIDIA SN5610 128-port 400 GbE switches |
OOB management fabric |
NVIDIA SN2201 48-port 1 Gb plus 4-port 100 GbE |
Table 6 below shows the number of cables and switches required for the Compute (Node East/West) Fabric for different SU sizes.
Table 6: Compute (Node East/West) and switch component count
Compute Counts |
Switch Counts |
Transceiver Counts |
Cable Counts |
||||||
|---|---|---|---|---|---|---|---|---|---|
Nodes |
GPUs |
SUs |
Leaf |
Spine |
Node-to-Leaf (Node) |
Node-to-Leaf (Switch) |
Switch-to-Switch |
Compute-to-Leaf |
Switch-to-Switch |
16 |
128 |
4 |
2 |
N/A |
64 |
32 |
32 |
64 |
32 |
32 |
256 |
8 |
2 |
N/A |
128 |
64 |
64 |
128 |
64 |
Converged (Node North/South) Fabric Table#
Table 7 below shows the number of cables and switches required for the Converged (Node North/South) Fabric for different SU sizes. For lower node counts such as 16 nodes where the Converged Network has been consolidated with the Compute Network, the transceiver and cables are additional to the quantities in Table 7 used for the East/West fabric.
Table 7: Converged (Node North/South) and switch component count
Compute Counts |
Switch Counts |
Converged Network Allocated Ports |
Transceiver Counts |
Cable Counts |
|||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Nodes |
GPUs |
SUs |
Leaf |
Spine |
CPU (Node N-S) |
Storage |
Mgmt. Uplinks |
Customer |
Support |
ISL Ports (both ends) |
Node-to-Leaf (Node) |
Node-to-Leaf (Switch) |
Switch-to-Switch |
Node-to-Leaf |
Switch-to-Switch |
16 |
128 |
4 |
Converged in E-W Network |
8 |
4 |
4 |
8 |
4 |
N/A |
104 |
25 |
N/A |
104 |
N/A |
|
32 |
256 |
8 |
2 |
N/A |
16 |
8 |
4 |
16 |
4 |
18 |
200 |
46 |
18 |
200 |
18 |
16 Nodes with 128 GPUs#
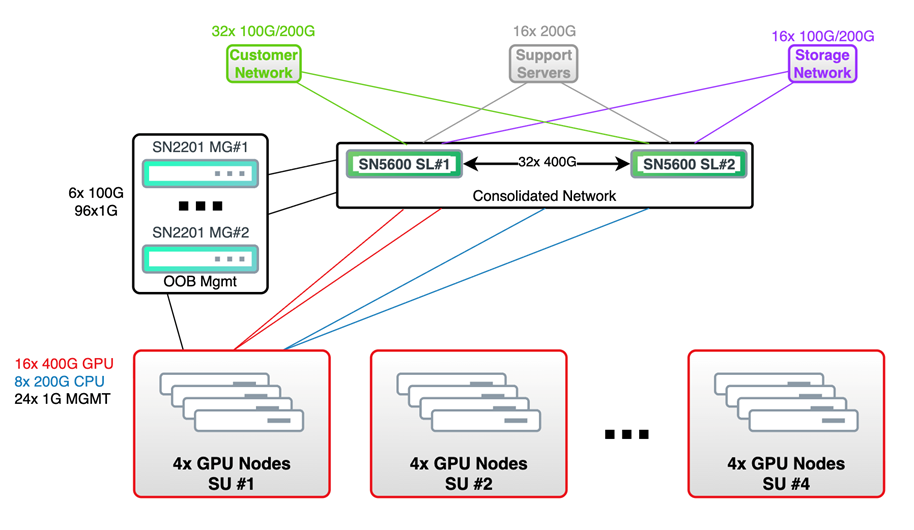
Figure 9 2-8-5-200 Spectrum-X Enterprise RA with 16 RTX PRO Servers (128 GPUs).#
Architecture Overview
16 RTX PRO Servers (128 GPUs) in 2-8-5-200 configuration with Spectrum-X consolidated fabric
4 scalable units (SUs) with 4 server nodes per unit
Network Design
Cost-efficient collapsed converged spine-leaf design for all fabrics
Spectrum fabric is rail-optimized and non-blocking using 64-port switches
Port breakout functionality consolidates ports while maintaining resiliency
Connectivity (Under Optimal Conditions)
16x 400G uplinks per SU for GPU Compute traffic
8x 200G uplinks per SU for CPU traffic
Up to 8 support servers, dual-connected at 200Gb
32x 100G/200G customer network connections (minimum 25Gb bandwidth per GPU)
16x 100G/200G storage connections (minimum 12.5Gb bandwidth per GPU)
Management
200 GbE management fabric with HA using two 100GbE core connections
All nodes connected to 1Gb management switches uplinked to the core network
Additional Considerations
VLAN isolation separates North-South and East-West fabrics collapsed into the physical infrastructure
Rack layout must provide power supply redundancy; otherwise, consider an alternative rack layout
The number of GPU servers per rack depends on available rack power
32 Nodes with 256 GPUs#
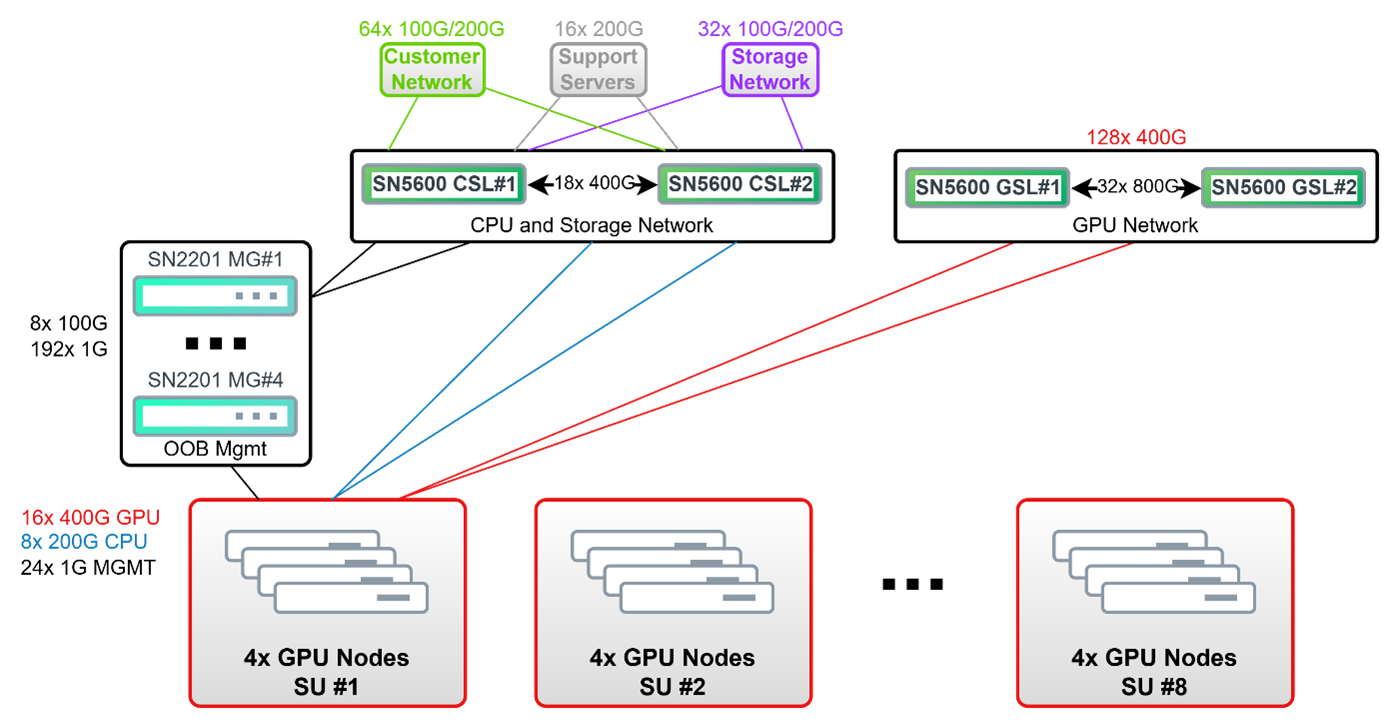
Figure 10 Figure: 10 2-8-5-200 Spectrum-X Enterprise RA with 32 RTX PRO Servers (256 GPUs).#
Architecture Overview
32 RTX PRO Servers (256 GPUs) in 2-8-5-200 configuration with Spectrum-X compute fabric
8 scalable units (SUs) with 4 server nodes per unit
Network Design
Cost-efficient collapsed spine-leaf design for all fabrics except GPU Compute (East-West)
GPU Compute (East-West) Network uses isolated converged spine-leaf for high-bandwidth, low-latency communication
Rail-optimized, non-blocking Spectrum fabric with 64-port switches in full spine-leaf design
Port breakout functionality consolidates ports while maintaining resiliency
Connectivity (Under Optimal Conditions)
16x 400G uplinks per SU for GPU Compute traffic
8x 200G uplinks per SU for CPU traffic
Up to 8 support servers, dual-connected at 200Gb
64x 100G/200G connections to customer network (minimum 25Gb bandwidth per GPU)
32x 100G/200G connections for storage (minimum 12.5Gb bandwidth per GPU)
Management
SN2201 switch for every 2 SUs (minimum 2 switches recommended)
Each SN2201 uplinked to core via 2x 100G links
200 GbE management fabric with HA using two 100GbE core connections
All nodes connected to 1Gb management switches
Additional Considerations
VLAN isolation separates fabrics on Converged (North/-South) Network
Rack layout must provide power supply redundancy
GPU servers per rack depends on available rack power