Appendix C#
NVIDIA Enterprise Reference Architecture: NVIDIA HGX H100/H200/B200 and NVIDIA Spectrum-X Networking Platform#
The NVIDIA HGX H100/H200/B200 and NVIDIA Spectrum-X Networking Enterprise RA is optimized for multi-node AI or hybrid applications. This modular architecture is based on NVIDIA-Certified HGX H100/H200/B200 systems, each equipped with eight H100 or H200 or B200 SXM GPUs. Using a four-node scalable unit (SU), this can scale up to 32 NVIDIA-Certified HGX 8-GPU systems, totaling 256 GPUs. Fully tested systems can scale to thirty-two SUs, with the potential for larger clusters based on customer requirements. The flexible rail-optimized end-of-row network architecture accommodates modifications in rack layout and the number of servers per rack. Hardware support is provided through the fulfilling system partner, while software support from NVIDIA is available via a per GPU paid subscription to NVIDIA AI Enterprise.
Use Cases#
- AI Inference: Large (per node) and medium (per GPU) model parameter inference workloads
- AI Training: Large to small model training and fine-tuning based on cluster sizing
NVIDIA HGX H100/H200/B200 Reference Configurations#
The HGX 8-GPU baseboard is an AI powerhouse that enables enterprises to expand the frontiers of business innovation and optimization. The HGX H100/H200 baseboard combines H100/H200 Tensor Core GPUs with high-speed interconnects to form the world’s most powerful systems. With eight H100/H200 GPUs, the baseboard has up to 640 GB (1,128 GB for H200) of GPU memory for unprecedented acceleration.
The HGX B200 baseboard is a Blackwell x86 platform, based on eight B200 GPUs, that has up to 1.44 TB of GPU memory and can deliver up to 144 petaFLOPs of AI performance. The HGX B200 baseboard delivers the best performance (15 times more than the HGX H100 baseboard) and TCO (12 times more than the HGX H100 baseboard) for x86 scale-up platforms and infrastructure. Each GPU is configurable up to 1 kW per GPU.
NVIDIA-Certified HGX H100/H200/B200 8-GPU systems are based on a common system design with flexibility for optimizing the configuration to match cluster requirements. This was built using the 8-GPU design pattern (2-8-9-400 CPU-GPU-NIC-Bandwidth), but the 4-GPU design can also be utilized based on specific needs. An example of this design is shown in Figure 7.
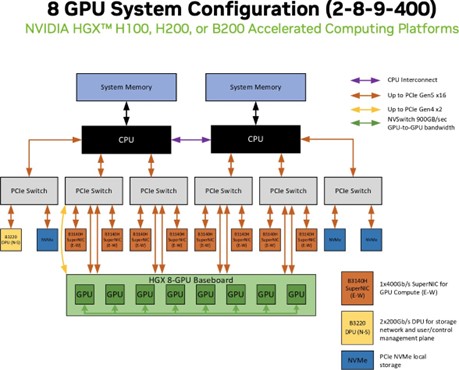
Figure 8 Example of a HGX H100, H200 or B200 8 GPU system configuration.#