Key building blocks of Enterprise Reference Architectures#
Each NVIDIA Enterprise Reference Architecture includes deployment guidelines for multiple workloads, supporting flexible cluster sizing, networking, and expansion needs. Our Enterprise RAs encompass infrastructure and optimized server networking configurations based on common design patterns for CPU, GPU, and networking. The key components of an Enterprise RA include the accelerated computing clusters, East-West networking, North-South networking, and switches.
Accelerated Computing Clusters#
NVIDIA Enterprise RAs include design recommendations for building accelerated computing clusters using NVIDIA-Certified servers with balanced CPU to GPU to NIC patterns to avoid potential bottlenecks and sub-optimal performance. NVIDIA delivers design patterns for both GPU scale-up and scale-out configurations leveraging NVIDIA® NVLink® and for high-speed, multi-GPU communication facilitating all-to-all GPU communication.
PCIe-Optimized Reference Configurations: Enterprise RAs based upon PCIe-Optimized Reference Configurations utilize NVLink technology within individual servers (when supported, ex: NVIDIA H100/H200 NVL) while providing guidelines for scaling out the cluster with additional servers to enhance overall capacity and performance. This approach is ideal for workloads demanding high performance from each server within the cluster.
These scale-out systems employ optimized PCIe technology, allowing for flexible expansion of GPUs and networking capabilities as needed for each node. The NVIDIA Enterprise RAs follow Reference Configuration recommendations for balancing CPU, GPU, and Network Interface Card (NIC) configurations to prevent potential bottlenecks and ensure optimal performance. This balanced approach enables organizations to scale their computational resources efficiently, meeting the demands of complex, distributed workloads while maintaining high performance across the entire cluster.
PCIe-Optimized 2-4-3-200 (CPU-GPU-NIC-Bandwidth) Reference Configurations are for 2U NVIDIA-Certified compute nodes using PCIe allowing you to deploy 2 CPUs balanced with up to 4 GPUs plus 3 NICs with East-West traffic of 200 GbE per GPU. This pattern can scale from 8 up to 32 nodes in a cluster.
Eligible GPU: NVIDIA H100 NVL and L40S
Eligible CPU: AMD EPYC™ Processors: Milan, Genoa, Turin; Intel® Xeon® Scalable Processors: Sapphire Rapids, Emerald Rapids, Granite Rapids
East-West Networking: NVIDIA BlueField-3 B3140H or NVIDIA ConnectX-7
North-South Networking: NVIDIA BlueField-3 B3220
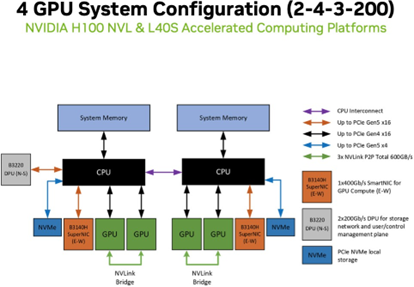
Figure 1 Above is an example of pattern 2-4-3-200 from the NVIDIA H100 NVL and NVIDIA Spectrum Platforms Enterprise RA which is designed for a variety of use cases, including visual computing for 3D graphics and rendering, AI inference for medium model parameter workloads, and AI training for small model training and fine-tuning. Refer to Appendix A for more details.#
PCIe-Optimized 2-8-5-200 (CPU-GPU-NIC-Bandwidth) Reference Configuration are for 4U NVIDIA-Certified compute nodes using PCIe allowing you to deploy 2 CPUs balanced with up to 8 GPUs plus 5 NICs with East-West traffic of 200 GbE per GPU. This pattern scales from 4 up to 32 nodes in a cluster.
Eligible GPU: NVIDIA Blackwell RTX PRO™ 6000 Blackwell Server Edition and H200 NVL
Eligible CPU: AMD EPYC™ Processors: Milan, Genoa, Turin; Intel® Xeon® Scalable Processors: Sapphire Rapids, Emerald Rapids, Granite Rapids
East-West Networking: NVIDIA BlueField-3 B3140H or NVIDIA ConnectX-7
North-South Networking: NVIDIA BlueField-3 B3220
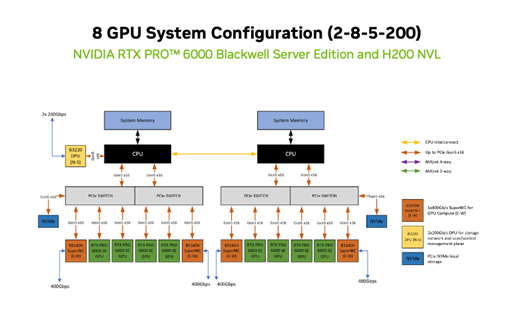
Figure 2 Above is an example of a PCIe-Optimized 2-8-5-200 Reference Configuration based upon the NVIDIA H200 NVL or RTX PRO 6000 Blackwell Server Edition and NVIDIA Spectrum Platforms Enterprise RA which is designed for AI inference for large to medium model parameter workloads and AI training and fine-tuning. Refer to Appendices B and D for more details.#
HGX Reference Configurations: With Enterprise RAs based upon HGX Reference Configurations, NVLink connections can be extended to create seamless, high-bandwidth, multi-node GPU clusters. Deploying compute clusters with these scale-up systems effectively transforms a data center into a single, massive GPU, capable of handling workloads distributed across multiple servers. The fifth-generation NVLink technology addresses the escalating need for high-speed scale-up interconnects in GPU clusters, supporting up to 576 GPUs. This advanced interconnect is essential for rapidly feeding extensive datasets into models and facilitating swift data exchange between GPUs.
These NVIDIA Enterprise RAs are specifically designed for NVIDIA SXM baseboard architectures, offering predefined configurations for 4-GPU and 8-GPU systems, such as HGX and Grace class offerings. These systems can scale up to their maximum corresponding NVLink capability. For example, the GB200 NVL72 can scale up to 72 GPUs, functioning as a single, cohesive unit, providing unprecedented computational power for complex AI and HPC workloads.
HGX 2-8-9-400 (CPU-GPU-NIC-Bandwidth) Reference Configuration is for scale-up NVIDIA 8-GPU HGX NVIDIA Certified servers with 2 CPUs balanced with 8 GPUs plus 9 NICs with East-West traffic of 400 GbE per GPU. This pattern scales from 4 to 32 nodes in a cluster.
Eligible GPU: NVIDIA HGX™ H100, H200, or B200
Eligible CPU: AMD EPYC™ Processors: Milan, Genoa, Turin; Intel® Xeon® Scalable Processors: Sapphire Rapids, Emerald Rapids, Granite Rapids
East-West Networking: NVIDIA BlueField-3 B3140H/L or NVIDIA ConnectX-7
North-South Networking: NVIDIA BlueField-3 B3220
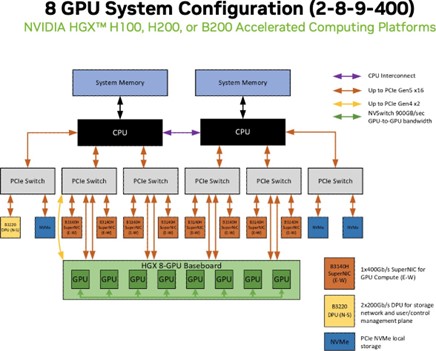
Figure 3 Above is an example of the HGX 2-8-9-400 Reference Configuration from the NVIDIA HGX H100/H200/B200 and NVIDIA Spectrum-X Networking Platform Enterprise RA which is designed for AI inference with large (per node) and medium (per GPU) model parameter workloads, as well as AI training for large-to-small model training and fine-tuning based on cluster sizing. Refer to Appendix C for more details.#
Scale-out NVIDIA Grace Configurations: These scale-out Enterprise RAs leverage NVIDIA’s Grace CPU technology instead of the x86 variants above, bringing together the groundbreaking performance of NVIDIA GPUs with the versatility of the NVIDIA Grace™ CPU. At the heart of the Grace Hopper Superchip is NVIDIA’s memory-coherent NVLink-C2C interconnect, enabling applications to oversubscribe the GPU’s memory and directly utilize the Grace CPU’s memory at high bandwidth. This makes it ideal for compute- and memory-intensive workloads like single-node LLM inference, retrieval-augmented generation (RAG), recommenders, graph neural networks (GNNs), high-performance computing (HPC), and data processing.
Scale-out Grace 2-2-3-400 reference configuration is for scale-out NVIDIA superchips with 2 CPUs balanced with 2 GPUs plus 3 NICs with East-West traffic of 400 GbE per GPU. This pattern scales from 4 to 32 nodes in a cluster.
Eligible GPU: NVIDIA GH200 NVL2 Superchip
Eligible CPU: NVIDIA Grace
East-West Networking: NVIDIA BlueField-3 B3140H or NVIDIA ConnectX-7
North-South Networking: NVIDIA BlueField-3 B3220
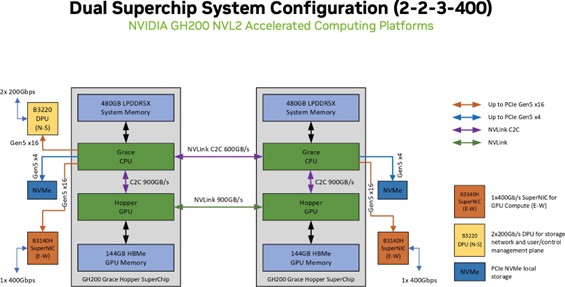
Figure 4 Above is an example from the NVIDIA GH200 NVL2 and NVIDIA Spectrum-X Networking Platform Enterprise RA and is optimized for workloads of multi-node AI, HPC, or hybrid applications.#
Enterprise RA networking leverages NVIDIA expertise in Al cloud data centers and optimizes network traffic flow, enabling the highest Al performance and scale while ensuring cloud manageability and security. Each Enterprise RA includes design recommendations based on the NVIDIA Spectrum-X Ethernet platform — combining Spectrum-4 Ethernet switches and NVIDIA BlueField-3 SuperNICs for optimal performance. Additionally, each Enterprise RA includes guidance on the appropriate network topology at multiple design points based on scale and use case.
- East-West Networking: These recommendations are critical for AI processing, handling internal data transfers that affect model training and scaling, requiring high bandwidth and low latency solutions. These are tailored for AI clusters to improve communication between GPUs and other components, ensuring seamless data flow within the data center. This is critical for scaling as data is processed and passed between various layers in AI models (across GPUs, CPUs, and storage). Poorly managed east-west traffic can lead to bottlenecks, slowing down training times and reducing the overall efficiency of the AI pipeline.
- North-South Networking: Supports external communication and is especially important for storage connectivity for data ingestion and result delivery. Presently, NVIDIA recommends NVIDIA BlueField Data Processing Units (DPUs) for all North-South traffic to offload and ensure secure, efficient handling of requests from outside the network.
- Switching: For all Enterprise RAs, NVIDIA provides configuration recommendations for Ethernet, which is the preferred switching for enterprise workloads.
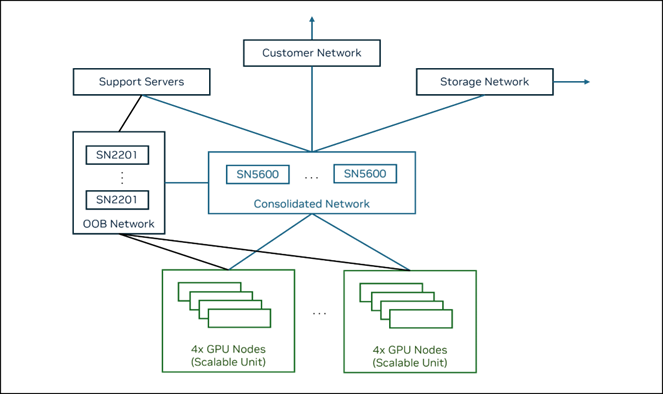
Figure 5 Shows the simplified networking topology for building clusters with 4 node scalable units.#
Storage#
As enterprises build AI factories the importance of this data cannot be overstated: access to high quality data directly impacts the performance and reliability of AI models. Data is essential for developing and optimizing AI applications, and it must be fed across all stages of the AI pipeline, from model building to training, tuning, and inference, with varied storage requirements at each stage. It’s the fuel for the AI factory.
The NVIDIA-Certified Storage program is designed to support the massive data demands of enterprise AI factories by offering a comprehensive storage certification that complements the Enterprise RA programs. This empowers partners and customers to deploy to build AI factories that efficiently leverage massive amounts of data for faster, more accurate, and reliable AI models. NVIDIA Enterprise RAs have designated network end points to attach NVIDIA-Certified storage solutions.
The NVIDIA-Certified Storage program offers two levels of certification: Foundation and Enterprise. These storage certifications integrate seamlessly with corresponding NVIDIA Enterprise RAs to ensure the storage systems have the performance to support the needs of the North-South networking and feed the compute nodes with data. The Foundation level storage certification certifies storage partners for the 2-4-3-200 and 2-8-5-200 reference configurations. The larger scale Enterprise level storage certification certifies storage partners for 2-8-9-400 reference configuration.
This is important for organizations looking to build robust, high-performance systems that leverage NVIDIA accelerated computing with optimal storage performance. It’s also important to ensure that the storage is fully compatible with NVIDIA’s GPU and networking technologies, reducing integration risks and deployment complexity.
Software#
NVIDIA Enterprise RAs provide a bare-metal foundation optimized for performance and reliability across AI workloads. The RAs can be used with industry-standard orchestration tools, such as Kubernetes and Slurm. NVIDIA Enterprise RAs also provide the foundation for enterprise-grade AI software and models across a wide range of AI workloads. For example, NVIDIA AI Enterprise (including NVIDIA NIM microservices) and NVIDIA Omniverse software can be deployed on system configurations designed using an Enterprise RA to provide a full-stack solution.
Going forward, NVIDIA Enterprise RAs will provide specific software configuration recommendations to optimize performance for various AI workloads, including sizing and deployment guidelines. By following Enterprise RA recommendations, NVIDIA partners and our joint enterprise customers can simplify AI adoption and ensure optimal performance with faster time to value.
Why This Matters#
NVIDIA Enterprise Reference Architectures provide guidance for building high-performance, scalable data center infrastructure. The transformation of traditional data centers into AI Factories is revolutionizing how enterprises process and analyze data by integrating advanced computing and networking technologies to meet the substantial computational demands of AI applications. To address these challenges, NVIDIA has introduced NVIDIA Enterprise Reference Architectures, offering clear and consolidated recommendations for our partners and joint enterprise customers building AI Factories based on NVIDIA-Certified systems with NVIDIA Certifed storage partners. Informed by years of expertise in designing and building large-scale computing systems, these NVIDIA Enterprise RAs streamline the deployment process, providing flexible and cost-effective configurations that eliminate much of the guesswork and risk.
Business Benefits#
- Accelerate Time to Token: By leveraging NVIDIA’s structured approach and recommended designs, enterprises can deploy AI solutions faster, reducing the time to achieve business value.
- Resource and Cost Efficiency: Optimized configurations ensure efficient use of resources, minimizing waste and reducing overall costs.
- Risk Mitigation: Recommending proven and tested design pattern increases customer confidence and helps mitigate deployment risks, ensuring consistent and predictable outcomes.
IT Benefits#
- Performance: High-performance computing capabilities meet the demanding requirements of AI workloads, ensuring optimal performance.
- Scale and Manageability: Flexible scaling options and manageable configurations allow enterprises to grow their AI infrastructure seamlessly.
- Reduced Complexity and TCO: Simplified deployment processes and efficient designs reduce complexity and total cost of ownership (TCO).
- Supportability: Following specific standardized design patterns allows for consistent operation from installation-to-installation, reduces the need for frequent support, and enables faster resolution times.
By following NVIDIA’s structured approach to introducing new technologies and leveraging the NVIDIA Enterprise RA recommendations, our system partners and joint enterprise customers can confidently build and scale AI Factories. This enables them to focus on running their business and delivering innovative AI solutions, ultimately maximizing their return on investment and achieving significant business value.
For more information please visit the Qualified System Catalog page and filter the list for any of the NVIDIA-Certified System categories. View the NVIDIA-Certified Systems documentation for additional information.