Abstract
This NVIDIA NVSHMEM Developer Guide version 1.0.1 describes NVSHMEM, a programming interface that implements the OpenSHMEM programming model for clusters of NVIDIA GPUs. OpenSHMEM provides a partitioned global address space and an easy-to-use one-sided communication interface.
1. Introduction
NVIDIA® NVSHMEM™ is a software library that implements the OpenSHMEM application programming interface (API) for clusters of NVIDIA GPUs. OpenSHMEM is a community standard, one-sided communication API that provides a partitioned global address space (PGAS) parallel programming model. A key goal of the OpenSHMEM specification -- and also of NVSHMEM -- is to provide an interface that is convenient to use, while also providing high performance with minimal software overheads.
The OpenSHMEM specification is under active development, with regular releases that expand its feature set and extend its ability to utilize emerging node and cluster architectures. The current version of NVSHMEM is based upon the OpenSHMEM version 1.3 APIs and also includes many features from OpenSHMEM 1.4. While NVSHMEM is based on OpenSHMEM, there are important differences that are detailed in this document.
NVSHMEM provides an easy-to-use host-side interface for allocating symmetric memory, which can be distributed across a cluster of NVIDIA GPUs interconnected with NVLink, PCIe, and InfiniBand. Device-side APIs can be called by CUDA kernel threads to efficiently access locations in symmetric memory through one-sided read (get), write (put), and atomic update API calls. In addition, symmetric memory that is directly accessible to a given GPU (for example, a memory region that is located on the local GPU or a peer GPU connected via NVLink) can be queried and accessed directly via a pointer provided by the NVSHMEM library.
More information on the OpenSHMEM specification can be found at openshmem.org.
1.1. Partitioned Global Address Space
NVSHMEM aggregates the memory of multiple GPUs in a cluster into a Partitioned Global Address Space (PGAS) that enables fine-grained GPU-to-GPU data movement and synchronization from within a CUDA kernel.
Using NVSHMEM, developers can write long running kernels that include both communication and computation, reducing the need for synchronization with the CPU. These composite kernels also allow for fine-grain overlap of computation with communication as a result of thread warp scheduling on the GPU. NVSHMEM GPU-initiated communication can reduce overheads resulting from kernel launches, calls to CUDA API, and CPU-GPU synchronization. Reducing these overheads can enable significant gains in strong scaling of application workloads. When necessary, NVSHMEM also provides the flexibility of CPU-side calls for inter-GPU communication outside of CUDA kernels.
The Message Passing Interface (MPI) is one of the most commonly used communication libraries for scalable, high performance computing. A key design principle of NVSHMEM is support for fine-grain, highly-concurrent GPU-to-GPU communication from within CUDA kernels. Utilizing conventional MPI send and receive operations in such a communication regime can lead to significant efficiency challenges. Because of the need to match send and receive operations, MPI implementations can incur high locking (or atomics) overheads for shared data structures involved in messaging, serialization overheads that result from the MPI message ordering requirements, and protocol overheads that result from messages arriving at the receiver before they have posted the corresponding receive operation.
While there have been efforts to reduce the overhead of critical sections using fine-grained locking and multiple network end-points per process, matching between send and receive operations is inherent to the send-receive model of communication in MPI and is challenging to scale to highly threaded environments presented by GPUs. In contrast, one-sided communication primitives avoid these bottlenecks by enabling the initiating thread to specify all the information required to complete a data transfer. They can be directly translated to RDMA primitives exposed by the network hardware or to load/store operations on the NVLink fabric. Using asynchronous APIs, one-sided primitives also make it programmatically easier to interleave computation and communication, thereby having the potential for better overlap.
1.2. GPU-Initiated Communication And Strong Scaling
NVSHMEM support for GPU-initiated communication can significantly reduce communication and synchronization overheads, leading to improvements in strong scaling.
Strong scaling refers to how the solution time of a fixed problem changes as the number of processors is increased. In other words, strong scaling is the ability to solve a fixed problem faster by increasing the number of processors. This is a critical metric for many scientific, engineering, and data analytics applications as increasingly large clusters and more powerful GPUs become available.
Current state-of-the-art applications running on GPU clusters typically offload computation phases onto the GPU and rely on the CPU to manage communication between cluster nodes, using the Message Passing Interface (MPI) or OpenSHMEM. Dependency on the CPU for communication limits strong scalability, owing to the overhead of repeated kernel launches, CPU-GPU synchronization, underutilization of the GPU during communication phases, and underutilization of the network during compute phases. Some of these issues can be addressed by restructuring application code to overlap independent compute and communication phases using CUDA streams. These optimizations can lead to complex application code and their benefits usually diminish as the problem size per GPU becomes smaller.
As a problem is strong-scaled, the Amdahl’s fraction of the execution corresponding to CPU-GPU synchronization and communication increases. Thus, minimizing these overheads is critical for strong scaling of applications on GPU clusters. Furthermore, GPUs are designed for throughput and have enough state and parallelism to hide long latencies to global memory, which can allow them to be efficient at hiding data movement overheads. Following the CUDA programming model and best practices and utilizing NVSHMEM for GPU-initiated communication enables developers to take advantage of these latency hiding capabilities.
1.3. Key Features
NVSHMEM extends the OpenSHMEM APIs to support clusters of NVIDIA GPUs. The following provides a brief summary of several key extensions:
-
Support for symmetric allocation of GPU memory.
-
Support for GPU-initiated communication, including support for CUDA types.
-
A new API call to collectively launch CUDA kernels across a set of GPUs.
-
Stream-based APIs that allow data movement operations initiated from the CPU to be offloaded onto the GPU and ordered with regard to a CUDA stream.
-
Threadgroup communication where threads from whole warps or whole thread blocks in a CUDA kernel can collectively participate in a single communication operation.
-
Differentiation between synchronizing and non-synchronizing operations to benefit from strengths (weak or strong) of operations in the GPU memory model.
-
API names are prefixed with “nv” to enable hybrid usage of NVSHMEM with an existing OpenSHMEM library.
-
All buffer arguments to NVSHMEM communication routines must be symmetric.
-
NVSHMEM provides weak ordering for data returned by blocking operations that fetch data. Ordering can be enforced via the nvshmem_fence operation.
2. The NVSHMEM Programming Model
An NVSHMEMjob consists of several operating system processes, referred to as processing elements (PEs), executing on one or more nodes in a GPU cluster. NVSHMEM jobs are launched by a process manager. Each process in an NVSHMEM job runs a copy of the same executable program.
Thus, an NVSHMEM job represents a single program, multiple data (SPMD) parallel execution. Each PE is assigned an integer identifier (ID), ranging from zero to one less than the total number of PEs. PE IDs are used to identify the source or destination process in OpenSHMEM operations, and are also used by application developers to assign work to specific processes in an NVSHMEM job.
All PEs in an NVSHMEM job must simultaneously, i.e. collectively, call the NVSHMEM initialization routine before any NVSHMEM operations can be performed. Similarly, prior to exiting, PEs must also collectively call the NVSHMEM finalization function. After initialization, a PE’s ID and the total number of running PEs can be queried. PEs communicate with each other and share data through symmetric memory that is allocated from a symmetric heap located in GPU memory. This memory is allocated using the CPU-side NVSHMEM allocation API. Memory allocated using any other method is considered private to the allocating PE and is not accessible by other PEs.
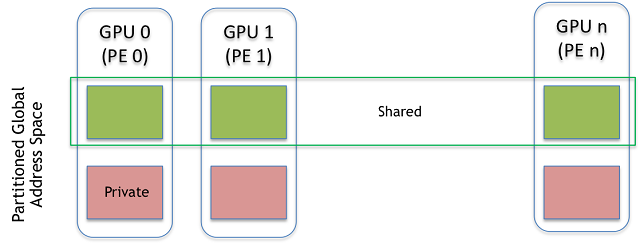
Symmetric memory allocation in NVSHMEM is a collective operation that requires each PE to pass the same value in the size argument for a given allocation. The resulting memory allocation is symmetric; a linear region of memory of the specified size is allocated from the symmetric heap of each PE and can subsequently be accessed using a combination of the PE ID and the symmetric address returned by the NVSHMEM allocation routine. Symmetric memory is accessible to all other PEs in the job using NVSHMEM APIs from inside CUDA kernels as well as on the CPU. In addition, the symmetric address returned by an NVSHMEM allocation routine is also a valid pointer to local GPU memory on the calling PE and can be used by that PE to access its piece of a symmetric allocation directly via CUDA APIs and load/store operations on the GPU.
Like all PGAS models, the location of data in the global address space is an inherent part of the NVSHMEM addressing model. NVSHMEM operations access symmetric objects in terms of the tuple <symmetric_address, destination_PE>. The symmetric address can be generated by performing pointer arithmetic on the address returned by an NVSHMEM allocation routine, e.g. &X[10] or &ptr->x. Symmetric addresses are only valid at the PE where they were returned by the NVSHMEM allocation routine and cannot be shared with other PEs. Within the NVSHMEM runtime, symmetric addresses are translated to the actual remote address, and advanced CUDA memory mapping techniques are used to ensure this can be done with little or no overhead.
2.1. Example NVSHMEM Program
The code snippet below shows a simple example of NVSHMEM usage within a CUDA kernel where PEs form a communication ring.
#include <stdio.h>
#include <cuda.h>
#include <nvshmem.h>
#include <nvshmemx.h>
__global__ void simple_shift(int *destination) {
int mype = nvshmem_my_pe();
int npes = nvshmem_n_pes();
int peer = (mype + 1) % npes;
nvshmem_int_p(destination, mype, peer);
}
int main(void) {
int mype_node, msg;
cudaStream_t stream;
nvshmem_init();
mype_node = nvshmemx_my_pe(NVSHMEMX_TEAM_NODE);
cudaSetDevice(mype_node);
cudaStreamCreate(&stream);
int *destination = (int *) nvshmem_malloc(sizeof(int));
simple_shift<<<1, 1, 0, stream>>>(destination);
nvshmemx_barrier_all_on_stream(stream);
cudaMemcpyAsync(&msg, destination, sizeof(int), cudaMemcpyDeviceToHost, stream);
cudaStreamSynchronize(stream);
printf("%d: received message %d\n", nvshmem_my_pe(), msg);
nvshmem_free(destination);
nvshmem_finalize();
return 0;
}
This example begins in main by initializing the NVSHMEM library, querying the PE’s ID in the on-node team, and using the on-node ID to set the CUDA device. The device must be set prior to allocating memory or launching any kernels. Next, a stream is created and a symmetric integer called destination is allocated on every PE. After this, the simple_shift kernel is launched on a single thread with a pointer to this symmetric object as its argument.
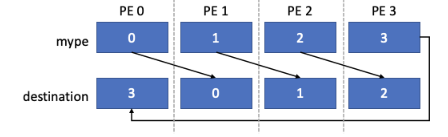
This kernel queries the global PE ID and the number of executing PEs. It then performs a single-element integer put operation to write the calling PE’s ID into destination at the PE with the next highest ID, or 0 in the case of the PE with the highest ID. The kernel is launched asynchronously on stream, followed by an NVSHMEM barrier on the stream to ensure that all updates have completed, and an asynchronous copy to copy the updated destination value to the host. The stream is then synchronized and the result is printed. Example output with 8 PEs is shown below.
0: received message 7 1: received message 0 2: received message 1 4: received message 3 6: received message 5 7: received message 6 3: received message 2 5: received message 4
Finally, the destination buffer is freed and the NVSHMEM library is finalized prior to the program exiting.
2.4. Usage Of NVSHMEM With MPI And OpenSHMEM
NVSHMEM can be used in conjunction with OpenSHMEM or MPI, making it easier for existing OpenSHMEM and MPI applications to be incrementally ported to use NVSHMEM. The code snippet below shows how NVSHMEM can be initialized within an MPI program. In this program, we assume that each MPI process is also an NVSHMEM PE -- that is, that each process has both an MPI rank as well as an NVSHMEM rank.
int main(int argc, char *argv[]) {
int rank, ndevices;
nvshmemx_init_attr_t attr;
MPI_Comm comm = MPI_COMM_WORLD;
attr.mpi_comm = &comm;
MPI_Init(&argc, &argv);
MPI_Comm_rank(&rank, MPI_COMM_WORLD));
cudaGetDeviceCount(&ndevices);
cudaSetDevice(rank % ndevices);
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_MPI_COMM, &attr);
...
nvshmem_finalize();
MPI_Finalize();
return 0;
}
As shown in this example, the MPI (or OpenSHMEM) library should be initialized first. After MPI has been initialized, the MPI rank can be queried and used to set the CUDA device. An nvshmemx_init_attr_t structure is created and the mpi_comm field is assigned a reference to an MPI communicator handle. The nvshmemx_init_attr operation is used instead of nvshmem_init to enable MPI compatibility mode. For additional details, see .
2.3. Communication Model
NVSHMEM provides get and put APIs, which copy data from and to symmetric objects, respectively. Bulk transfer, scalar transfer, and interleaved versions of these APIs are provided. In addition, Atomic Memory Operations (AMOs) are also provided and can be used to perform atomic updates to symmetric variables. Using these APIs, NVSHMEM provides fine-grained and low-overhead to data stored in the partitioned global address space (PGAS) from inside CUDA kernels. By performing communication from within kernels, NVSHMEM also enables applications to benefit from the intrinsic latency-hiding capabilities of the GPU warp scheduling hardware.
In addition to put, get, and AMO library routines, applications can also use the nvshmem_ptr routine to query a direct pointer to data located in partitions of the PGAS located on other PEs. When the given memory at the specified PE is directly accessible, this function returns a valid pointer. Otherwise, it returns a null pointer. This allows applications to issue direct loads and stores to global memory. NVSHMEM APIs (and loads/stores when allowed by the hardware) can be used to access both local and remote data, allowing a single code path to handle both local and remote data.
-
All symmetric memory that is allocated using the NVSHMEM allocation APIs is pinned GPU device memory.
-
NVSHMEM supports both GPU- and CPU-side communication and synchronization APIs, provided that the memory involved is GPU device memory allocated by NVSHMEM. In other OpenSHMEM implementations, these APIs can only be called from the CPU.
NVSHMEM is a stateful library. It detects which GPU a PE is using when the PE calls into an NVSHMEM initialization routine. This information is stored inside the NVSHMEM runtime. All symmetric allocation calls made by the PE return device memory of the selected GPU. All NVSHMEM calls made by the PE are assumed to be made with respect to the selected GPU or from inside kernels launched on this GPU. This requires certain restrictions on PE-to-GPU mappings in applications using NVSHMEM.
-
The PE selects its GPU (with cudaSetDevice, for example), before the first allocation, synchronization, communication, collective kernel API launch call, or NVSHMEM API call on the device.
-
An NVSHMEM allocation or synchronization must be performed on the host prior to the first NVSHMEM API call on the device.
-
The PE uses one and only one GPU throughout the lifetime of an NVSHMEM job.
-
A GPU may not be used by more than one PE.
NVSHMEM relies on data coalescing features in GPU hardware to achieve efficiency over the network when the data access API is used. It is important that application developers follow CUDA programming best practices that promote data coalescing when using fine-grained communication APIs in NVSHMEM.
CUDA kernels that do not use the NVSHMEM synchronization or collective APIs but use other NVSHMEM communication APIs can be launched with either the normal CUDA launch interfaces or the collective launch API. These kernels can still use other NVSHMEM device side APIs such as the one-sided data movement API.
-
Multiple PEs should not share the same GPU.
-
NVSHMEM PEs should have exclusive access to the GPU. The GPU cannot be used to drive a display or for another compute job.
Memory Model
NVSHMEM follows the OpenSHMEM memory model; however several important exceptions are made to adapt OpenSHMEM to the weakly consistent memory model provided by the GPU architecture, as noted in Modifications Of The OpenSHMEM Memory Model.
-
Remote memory access (RMA: PUT/GET)
-
Atomic memory operations (AMO)
-
Signal operations
-
Direct load and store operations (e.g., using a pointer returned by nvshmem_ptr)
-
Collective functions (broadcast, reductions, and others)
-
Wait and test functions (local symmetric memory only)
Two operations, either issued by the same PE or different PEs, that access the same memory location in parallel are in conflict when one or more of the operations performs a write. Such conflicts result in undefined behavior in the OpenSHMEM memory model. An exception is made when the operations are a combination of AMOs or AMOs and wait/test operations. A second exception is made when the operations are a combination of signal updates and wait/test operations.
Updates to globally accessible objects are unordered. A PE can enforce ordering of its updates with respect to accesses performed by the target PE using the nvshmem_fence operation. When updates performed by a PE must be ordered or made visible to PEs other than the target PE, the nvshmem_quiet operation should be used. While updates are unordered, updates made using NVSHMEM APIs are guaranteed to eventually complete without any additional actions performed by either the source or the target PE. As a result, NVSHMEM guarantees that updates will eventually become visible to other PEs through the NVSHMEM API. Updates are also stable in the sense once the update is visible to another API call, the update remains until replaced by another update. This guarantees that synchronization as described above completes in a finite amount of time.
-
The accesses are the result of different collective function calls that happen in program order.
-
The first access is a wait or test call, followed by a read operation, both of which target local symmetric memory.
2.4.1. Modifications Of The OpenSHMEM Memory Model
Blocking operations in OpenSHMEM that read data (for example, get or atomic fetch-and-add) are expected to return data according to the order in which the operations are performed. For example, consider a program that performs atomic fetch-and-add of the value 1 to the symmetric variable x on PE 0.
a = shmem_int_fadd(x, 1, 0);
b = shmem_int_fadd(x, 1, 0);
In this example, the OpenSHMEM specification guarantees that b > a. However, this strong ordering can incur significant overheads on weakly ordered architectures by requiring memory barriers to be performed before any such operation returns. NVSHMEM relaxes this requirement in order to provide a more efficient implementation on NVIDIA GPUs. Thus, NVSHMEM does not guarantee b > a.
Where such ordering is required, programmers can use an nvshmem_fence operation to enforce ordering for blocking operations (for example, between the two statements above). Non-blocking operations are not ordered by calls to nvshmem_fence. Instead, they must be completed using the nvshmem_quiet operation. The completion semantics of fetching operations remain unchanged from the specification: the result of the get or AMO is available for any dependent operation that appears after it, in program order.
2.4.2. Quiet And Fence Semantics
The nvshmem_quiet operation is used to complete pending operations, and provides the following guarantees:
-
All non-blocking operations issued by the calling PE have completed.
-
Access to all PEs (i.e. to any location in the PGAS) are ordered, such that accesses that occurred prior to the quiet operation can be observed by all PEs as having occurred before accesses after the quiet operation. PEs must use appropriate synchronization operations, for example, wait/test operations, to observe the ordering enforced at the PE that performed the quiet operation.
-
Ordering is guaranteed for all OpenSHMEM APIs, as well as for direct store operations.
-
Access to each PE (i.e. to a single partition of the PGAS) are ordered, such that accesses that occurred prior to the fence operation can be observed by the PE that is local to the corresponding partition of the PGAS as having occurred before accesses after the fence operation. PEs must use appropriate synchronization operations, for example, wait/test operations, to observe the ordering enforced at the PE that performed the quiet operation.
-
Ordering is guaranteed for all OpenSHMEM APIs, as well as for direct store operations.
3. NVSHMEM API
NVSHMEM includes the OpenSHMEM 1.3 API, as well as several APIs defined in OpenSHMEM 1.4 and 1.5. For complete details, refer to the NVSHMEM API documentation.
For a complete list of API descriptions, refer to the corresponding OpenSHMEM specification document, available at openshmem.org.
NVSHMEM functions are classified according to where they can be invoked: on the host, on the GPU, or on both the host and the GPU.
- Initialization and termination, for example, nvshmem_init and nvshmem_finalize.
- Memory management, for example, nvshmem_malloc and nvshmem_free.
- Collective kernel launch, for example, nvshmemx_collective_launch.
- Stream-based operations.
- Thread block scoped operations, for example, nvshmem_putmem_block.
- Thread warp scoped operations, for example, nvshmem_putmem_warp.
The remaining operations, including one-sided remote memory access, one-sided remote atomic memory access, memory ordering, point-to-point synchronization, collectives, pointer query, and PE information query operations are supported from both the host and the device.
4.2. OpenSHMEM 1.3 APIs Not Supported
The following OpenSHMEM 1.3 APIs are not supported in NVSHMEM:
- OpenSHMEM Fortran API
- shmem_global_exit
- shmem_pe_accessible
- shmem_addr_accessible
- shmem_realloc
- shmem_fcollect
- shmem_alltoalls
- shmem_lock
- _SHMEM_* constants (deprecated)
- CUDA supports only a subset of the atomic operations included in the OpenSHMEM specification. The long long, int64_t, ptrdiff_t types are currently unsupported for add, fetch_add, inc, and fetch_inc atomic operations in NVSHMEM.
OpenSHMEM 1.3 APIs Not Supported Over InfiniBand
The following OpenSHMEM 1.3 APIs are not supported over InfiniBand in NVSHMEM:
- shmem_iput
- shmem_iget
- shmem_atomic_<all operations>
3.3. Additional Supported OpenSHMEM APIs
For a complete list of API descriptions, refer to the OpenSHMEM 1.4 specification document, available at openshmem.org.
For a complete list of API descriptions, refer to the NVSHMEM API documentation.
OpenSHMEM 1.4 APIs
- Threading support, with functions nvshmemx_init_thread and
nvshmemx_query_thread, and constants
NVSHMEM_THREAD_SINGLE,
NVSHMEM_THREAD_FUNNELED,
NVSHMEM_THREAD_SERIALIZED, and
NVSHMEM_THREAD_MULTIPLE.
Note: These functions will be renamed to nvshmem_init_thread and nvshmem_query_thread in a future release.
- NVSHMEM_SYNC_SIZE constant
- nvshmem_calloc (host)
- Bitwise atomic memory operations and, fetch_and, or, fetch_or, xor, and fetch_xor are supported with the names nvshmem_<TYPE>_atomic_<OP> where TYPE is the name of the datatype and OP is the name of the operation (for example, shmem_int_atomic_fetch_and). These APIs are supported on both the host and device.
- nvshmem_sync and nvshmem_sync_all (host and device)
4. NVSHMEM API Extensions
The following sections summarize the NVSHMEM extension APIs and their functionality. For a complete list of API descriptions, refer to the NVSHMEM API documentation.
4.1. NVSHMEM API Extensions For CPU Threads
| Description | NVSHMEM (nvshmemx_*) | Notes |
|---|---|---|
| Initialization | *_init_attr | |
| CUDA kernel launch | *_collective_launch | CUDA kernels that invoke synchronizing NVSHMEM APIs such as nvshmem_barrier, nvshmem_wait, collective operations, and others, must be launched using this API; otherwise behavior is undefined. |
| Collective launch grid size | *_collective_launch_query_gridsize | Used to query the largest grid size that can be used for the given kernel with CUDA cooperative launch on the current GPU. |
| Remote memory access | *_put_<all_variants>_on_stream, *_get_<all_variants>_on_stream | Asynchronous with respect to the calling CPU thread; takes a cudaStream_t as argument and is ordered on that CUDA stream. |
| Memory ordering | *_quiet_on_stream | |
| Collective communication | *_broadcast_<all_variants>_on_stream, *_collect__<all_variants>_on_stream, *_alltoall_<all_variants>_on_stream, *_to_all_<all_variants>_on_stream (reductions) | |
| Collective synchronization | *_barrier_all_on_stream, *_barrier_on_stream, *_sync_all_on_stream, *_sync_on_stream |
NVSHMEM extends the remote memory access (get and put), memory ordering, collective communication, and collective synchronization APIs with support for CUDA streams. Each steam-based function performs the same operation as described by the OpenSHMEM specification. An additional argument of type cudaStream_t is added as the last argument to each function and indicates the stream on which the operation is enqueued.
Ordering APIs (fence, quiet and barrier) issued on the CPU and the GPU only order communication operations that were issued from the CPU and the GPU, respectively. To ensure completion of GPU-side operations from the CPU, the developer must ensure completion of the CUDA kernel from which the GPU-side operations were issued, using operations like cudaStreamSynchronize or cudaDeviceSynchronize. Stream-based quiet or barrier operations have the effect of a barrier being executed on the GPU in stream order, ensuring completion and ordering of only GPU-side operations.
NVSHMEM Extension APIs Invoked By GPU Threads
| Description | NVSHMEM (nvshmem_*) | Notes |
|---|---|---|
| RMA Write | *_put_block, *_put_warp | New APIs for GPU-side invocation are provided that can be called collectively by a threadblock or a warp. |
| RMA Read | *_get_block, *_get_warp | |
| Asynchronous RMA write | *_put_nbi_block, *_put_nbi_warp | |
| Asynchronous RMA read | *_get_nbi_block, *_get_nbi_warp | |
| Collective communication | *_broadcast_<all_variants>_block, *_broadcast_<all_variants>_warp, *_collect__<all_variants>_block, *_collect__<all_variants>_warp, *_alltoall_<all_variants>_block, *_alltoall_<all_variants>_warp, *_to_all_<all_variants>_block, *_to_all_<all_variants>_warp (reductions) | |
| Collective synchronization | *_barrier_all_block, *_barrier_all_warp, *_barrier_block, *_barrier_warp, *_sync_all_block, *_sync_all_warp, *_sync_block, *_sync_warp |
The above table lists the NVSHMEM extension APIs that can be invoked by GPU threads. Each of the APIs corresponding to the entries in the description column have two variants each – one with the suffix _block and the other with the suffix _warp. For example, the OpenSHMEM API shmem_float_put has two extension APIs in NVSHMEM: nvshmemx_float_put_block and nvshmemx_float_put_warp.
These extension APIs are collective calls that must be called by every thread in the scope of the API and with exactly the same arguments. The scope of the *_block extension APIs is the block in which the thread resides. Similarly, the scope of the *_warp extension API is the warp in which the thread resides. For example, if thread 0 calls nvshmem_float_put_block, then every other thread that is in the same block as thread 0 must also call nvshmem_float_put_block with exactly the same arguments. Otherwise, the call will result in erroneous behavior or deadlock in the program. The NVSHMEM runtime may or may not leverage the multiple threads in the scope of the API to execute the API call.
- Converting nvshmem_float_put to nvshmemx_float_put_block enables the NVSHMEM runtime to leverage all the threads in the block to concurrently copy the data to the destination PE if the destination GPU of the put call is p2p connected. If the destination GPU is connected via InfiniBand, then a single thread in the block can issue an RMA write operation to the destination GPU.
- *_block and *_warp extensions of the collective APIs can make use of multiple threads to perform collective operations, such as parallel reduction operations in case of a collective reduction operation or sending data in parallel.
5.1. Examples
Source code for the examples described in this section is available in the examples folder of the NVIDIA® NVSHMEM™ package.
Attribute-Based Initialization Example
The following code shows an MPI version of the simple shift program that was explained in The NVSHMEM Programming Model. It shows the use of the NVSHMEM attribute-based initialization API where the MPI communicator can be used to set up NVSHMEM.
#include <stdio.h>
#include "mpi.h"
#include "nvshmem.h"
#include "nvshmemx.h"
#define CUDA_CHECK(stmt) \
do { \
cudaError_t result = (stmt); \
if (cudaSuccess != result) { \
fprintf(stderr, "[%s:%d] CUDA failed with %s \n", \
__FILE__, __LINE__, cudaGetErrorString(result)); \
exit(-1); \
} \
} while (0)
__global__ void simple_shift(int *destination) {
int mype = nvshmem_my_pe();
int npes = nvshmem_n_pes();
int peer = (mype + 1) % npes;
nvshmem_int_p(destination, mype, peer);
}
int main (int argc, char *argv[]) {
int mype_node, msg;
cudaStream_t stream;
int rank, nranks;
MPI_Comm mpi_comm = MPI_COMM_WORLD;
nvshmemx_init_attr_t attr;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &nranks);
attr.mpi_comm = &mpi_comm;
nvshmemx_init_attr(NVSHMEMX_INIT_WITH_MPI_COMM, &attr);
mype_node = nvshmem_team_my_pe(NVSHMEMX_TEAM_NODE);
CUDA_CHECK(cudaSetDevice(mype_node));
CUDA_CHECK(cudaStreamCreate(&stream));
int *destination = (int *) nvshmem_malloc (sizeof(int));
simple_shift<<<1, 1, 0, stream>>>(destination);
CUDA_CHECK(cudaMemcpyAsync(&msg, destination, sizeof(int),
cudaMemcpyDeviceToHost, stream));
CUDA_CHECK(cudaStreamSynchronize(stream));
printf("%d: received message %d\n", nvshmem_my_pe(), msg);
nvshmem_free(destination);
nvshmem_finalize();
MPI_Finalize();
return 0;
}
5.2. Collective Launch Example
The following code shows an example implementation of a single ring-based reduction where multiple iterations of the code, including computation, communication and synchronization are expressed as a single kernel.
This example also demonstrates the use of NVSHMEM collective launch, required when the NVSHMEM synchronization API is used from inside the CUDA kernel.
There is no MPI dependency for the example. NVSHMEM can be used to port existing MPI applications and develop new applications.
#include <stdio.h>
#include "nvshmem.h"
#include "nvshmemx.h"
#define CUDA_CHECK(stmt) \
do { \
cudaError_t result = (stmt); \
if (cudaSuccess != result) { \
fprintf(stderr, "[%s:%d] cuda failed with %s \n",\
__FILE__, __LINE__, cudaGetErrorString(result));\
exit(-1); \
} \
} while (0)
#define NVSHMEM_CHECK(stmt) \
do { \
int result = (stmt); \
if (NVSHMEM_SUCCESS != result) { \
fprintf(stderr, "[%s:%d] nvshmem failed with error %d \n",\
__FILE__, __LINE__, result); \
exit(-1); \
} \
} while (0)
__global__ void reduce_ring (int *target, int mype, int npes) {
int peer = (mype + 1)%npes;
int lvalue = mype;
for (int i=1; i<npes; i++) {
nvshmem_int_p(target, lvalue, peer);
nvshmem_barrier_all();
lvalue = *target + mype;
}
}
int main (int c, char *v[])
{
int mype, npes;
nvshmem_init();
mype = nvshmem_my_pe();
npes = nvshmem_n_pes();
//application picks the device each PE will use
CUDA_CHECK(cudaSetDevice(mype));
double *u = (double *) nvshmem_malloc(sizeof(double));
void *args[] = {&u, &mype, &npes};
dim3 dimBlock(1);
dim3 dimGrid(1);
NVSHMEM_CHECK(nvshmemx_collective_launch ((const void *)reduce_ring, dimGrid, dimBlock, args, 0 , 0));
CUDA_CHECK(cudaDeviceSynchronize());
printf("[%d of %d] run complete \n", mype, npes);
nvshmem_free(u);
nvshmem_finalize();
return 0;
}
5.3. On-Stream Example
The following example shows how nvshmemx_*_on_stream functions can be used to enqueue a SHMEM operation onto a CUDA stream for execution in stream order. Specifically, the example shows the following:
- How a collective SHMEM reduction operation can be made to wait on a preceding kernel in the stream.
- How a kernel can be made to wait for a communication result from a previous collective SHMEM reduction operation.
The example shows one use case for relieving CPU control over GPU compute and communication.
#include <stdio.h>
#include "nvshmem.h"
#include "nvshmemx.h"
#define THRESHOLD 42
#define CORRECTION 7
#define CUDA_CHECK(stmt) \
do { \
cudaError_t result = (stmt); \
if (cudaSuccess != result) { \
fprintf(stderr, "[%s:%d] cuda failed with %s \n",\
__FILE__, __LINE__, cudaGetErrorString(result));\
exit(-1); \
} \
} while (0)
__global__ void accumulate(int *input, int *partial_sum)
{
int index = threadIdx.x;
if (0 == index) *partial_sum = 0;
__syncthreads();
atomicAdd(partial_sum, input[index]);
}
__global__ void correct_accumulate(int *input, int *partial_sum, int *full_sum)
{
int index = threadIdx.x;
if (*full_sum > THRESHOLD) {
input[index] = input[index] - CORRECTION;
}
if (0 == index) *partial_sum = 0;
__syncthreads();
atomicAdd(partial_sum, input[index]);
}
int main (int c, char *v[])
{
int mype, npes;
int *input;
int *partial_sum;
int *full_sum;
int input_nelems = 512;
int to_all_nelems = 1;
int PE_start = 0;
int PE_size = 0;
int logPE_stride = 0;
long *pSync;
int *pWrk;
cudaStream_t stream;
nvshmem_init ();
PE_size = nvshmem_n_pes();
mype = nvshmem_my_pe();
npes = nvshmem_n_pes();
CUDA_CHECK(cudaSetDevice(mype));
CUDA_CHECK(cudaStreamCreate(&stream));
input = (int *) nvshmem_malloc(sizeof(int) * input_nelems);
partial_sum = (int *) nvshmem_malloc(sizeof(int));
full_sum = (int *) nvshmem_malloc(sizeof(int));
pWrk = (int *) nvshmem_malloc(sizeof(int) * NVSHMEM_REDUCE_MIN_WRKDATA_SIZE);
pSync = (long *) nvshmem_malloc(sizeof(long) * NVSHMEM_REDUCE_SYNC_SIZE);
accumulate <<<1, input_nelems, 0, stream>>> (input, partial_sum);
nvshmemx_int_sum_to_all_on_stream(full_sum, partial_sum, to_all_nelems, PE_start, logPE_stride, PE_size, pWrk, pSync, stream);
correct_accumulate <<<1, input_nelems, 0, stream>>> (input, partial_sum, full_sum);
CUDA_CHECK(cudaStreamSynchronize(stream));
printf("[%d of %d] run complete \n", mype, npes);
CUDA_CHECK(cudaStreamDestroy(stream));
nvshmem_free(input);
nvshmem_free(partial_sum);
nvshmem_free(full_sum);
nvshmem_free(pWrk);
nvshmem_free(pSync);
nvshmem_finalize();
return 0;
}
5.4. Threadgroup Example
The example in this section shows how nvshmemx_collect32_block can be used to leverage threads to accelerate a SHMEM collect operation when all threads in the block depend on the result of a preceding communication operation. For this instance, partial vector sums are computed across different PEs and have a SHMEM collect operation to obtain the complete sum across PEs.
#include <stdio.h>
#include "nvshmem.h"
#include "nvshmemx.h"
#define NTHREADS 512
#define CUDA_CHECK(stmt) \
do { \
cudaError_t result = (stmt); \
if (cudaSuccess != result) { \
fprintf(stderr, "[%s:%d] cuda failed with %s \n",\
__FILE__, __LINE__, cudaGetErrorString(result));\
exit(-1); \
} \
} while (0)
__global__ void distributed_vector_sum(int *x, int *y, int *partial_sum, int *sum, long *pSync, int use_threadgroup, int mype, int npes)
{
int index = threadIdx.x;
int nelems = blockDim.x;
int PE_start = 0;
int logPE_stride = 0;
partial_sum[index] = x[index] + y[index];
if (use_threadgroup) {
/* all threads realize the entire collect operation */
nvshmemx_collect32_block(sum, partial_sum, nelems, PE_start, logPE_stride, npes, pSync);
} else {
/* thread 0 realizes the entire collect operation */
if (0 == index) {
nvshmem_collect32(sum, partial_sum, nelems, PE_start, logPE_stride, npes, pSync);
}
}
}
int main (int c, char *v[])
{
int mype, npes;
int *x;
int *y;
int *partial_sum;
int *sum;
int use_threadgroup = 1;
long *pSync;
int nthreads = NTHREADS;
nvshmem_init ();
npes = nvshmem_n_pes();
mype = nvshmem_my_pe();
CUDA_CHECK(cudaSetDevice(mype));
x = (int *) nvshmem_malloc(sizeof(int) * nthreads);
y = (int *) nvshmem_malloc(sizeof(int) * nthreads);
partial_sum = (int *) nvshmem_malloc(sizeof(int) * nthreads);
sum = (int *) nvshmem_malloc(sizeof(int) * nthreads * npes);
pSync = (long *) nvshmem_malloc(sizeof(long) * NVSHMEM_COLLECT_SYNC_SIZE);
void *args[] = {&x, &y, &partial_sum, &sum, &pSync, &use_threadgroup, &mype, &npes};
dim3 dimBlock(nthreads);
dim3 dimGrid(1);
nvshmemx_collective_launch ((const void *)distributed_vector_sum, dimGrid, dimBlock, args, 0, 0);
CUDA_CHECK(cudaDeviceSynchronize());
printf("[%d of %d] run complete \n", mype, npes);
nvshmem_free(x);
nvshmem_free(y);
nvshmem_free(partial_sum);
nvshmem_free(sum);
nvshmem_free(pSync);
nvshmem_finalize();
return 0;
}
5.5. put_block Example
In the example below, every thread in block 0 calls nvshmemx_float_put_block. Alternatively, every thread can call nvshmem_float_p, but nvshmem_float_p has a disadvantage that when the destination GPU is connected via InfiniBand, there is one RMA message for every single element, which can be detrimental to performance.
The disadvantage with using nvshmem_float_put in this case is that when the destination GPU is P2P-connected, a single thread will copy the entire data to the destination GPU. While nvshmemx_float_put_block can leverage all the threads in the block to copy the data in parallel to the destination GPU.
#include <stdio.h>
#include <assert.h>
#include "mpi.h"
#include "nvshmem.h"
#include "nvshmemx.h"
#define CUDA_CHECK(stmt) \
do { \
cudaError_t result = (stmt); \
if (cudaSuccess != result) { \
fprintf(stderr, "[%s:%d] cuda failed with %s \n",\
__FILE__, __LINE__, cudaGetErrorString(result));\
exit(-1); \
} \
} while (0)
#define THREADS_PER_BLOCK 1024
__global__ void set_and_shift_kernel (float *send_data, float *recv_data, int num_elems, int mype, int npes) {
int thread_idx = blockIdx.x * blockDim.x + threadIdx.x;
/* set the corresponding element of send_data */
if (thread_idx < num_elems)
send_data[thread_idx] = mype;
int peer = (mype + 1) % npes;
int block_offset = blockIdx.x * blockDim.x;
/* All threads in the block call API with same arguments */
nvshmemx_float_put_block(recv_data + block_offset, send_data + block_offset, min(blockDim.x, num_elems, - block_offset), peer);
}
int main (int c, char *v[])
{
int mype, npes;
float *send_data, *recv_data;
int num_elems = 8192;
int num_blocks;
nvshmem_init ();
mype = nvshmem_my_pe();
npes = nvshmem_n_pes();
//application picks the device each PE will use
CUDA_CHECK(cudaSetDevice(mype));
send_data = (float *) nvshmem_malloc(sizeof(float) * num_elems);
recv_data = (float *) nvshmem_malloc(sizeof(float) * num_elems);
assert(num_elems % THREADS_PER_BLOCK == 0); /* for simplicity */
num_blocks = num_elems / THREADS_PER_BLOCK;
set_and_shift_kernel<<<num_blocks, THREADS_PER_BLOCK>>>
(send_data, recv_data, num_elems, mype, npes);
CUDA_CHECK(cudaDeviceSynchronize());
printf("[%d of %d] run complete \n", mype, npes);
nvshmem_free(send_data);
nvshmem_free(recv_data);
nvshmem_finalize();
return 0;
}
6. Troubleshooting And FAQs
6.1. General FAQs
Q: What does the following runtime warning imply?
WARN: IB HCA and GPU are not connected to a PCIe switch so InfiniBand performance can be
limited depending on the CPU generationA: This warning is related to the HCA to GPU mapping of the platform. For more information, refer to the SHMEM_HCA_PE_MAPPING variable in the section.
Q: What does the following runtime error indicate?
NULL value could not find mpi library in environment.
A: This occurs if libmpi.so or libmpi_ibm.so is not present in the environment. For more information, refer to the NVSHMEM_MPI_LIB_NAME variable in the section to specify the name of the MPI library installed.
Q: What does the following runtime error indicate?
src/comm/transports/ibrc/ibrc.cpp:: NULL value mem registration
failed.~$ lsmod | grep nv_peer_mem nv_peer_mem 20480 0 ib_core 241664 11 rdma_cm,ib_cm,iw_cm,nv_peer_mem,mlx4_ib,mlx5_ib,ib_ucm,ib_umad,ib_uverbs,rdma_ucm,ib_ipoib nvidia 17596416 226 nv_peer_mem,gdrdrv,nvidia_modeset,nvidia_uvm nv_peer_mem is available here https://github.com/Mellanox/nv_peer_memory
Q: My application uses the CMake build system. Adding NVSHMEM to the build system breaks for a CMake version below 3.11. Why?
A: Device linking support was added in version 3.11 which NVSHMEM requires.
Q: Why does a CMake build of my NVSHMEM application fail with version 3.12 but does not with an earlier version?
cmake_policy(SET CMP0074 OLD)” to CMakeLists.txt
Q: What CMake settings needed to build CUDA or NVSHMEM applications?
A: Add the following to the CMake file string(APPEND CMAKE_CUDA_FLAGS "-gencode arch=compute_70,code=sm_70") or whichever GPU architecture you are compiling for.
Q: Why does my NVSHMEM Hydra job become non-responsive on Summit?
A: Summit requires the additional option --launcher ssh to be passed to nvshmrun at the command-line.
6.2. Prerequisite FAQs
Q: Does NVSHMEM require CUDA?
A: Yes. CUDA 9.0 or later must be installed to use NVSHMEM. NVSHMEM is a communication library intended to be used for efficient data movement and synchronization between two or more GPUs. It is currently not intended for data movement that does not involve GPUs.
6.3. Running NVSHMEM Programs FAQs
Q: Are there environment variables, configuration files, or parameters that need to be set for mpirun?
mpirun -n 4 -ppn 2 -hosts hostname1,hostname2 /path/to/nvshmem/app/binary
mpirun -n 2 /path/to/nvshmem/app/binary
Q: Why does NVSHMEM package provide installation script for Hydra Process Manager?
A: NVSHMEM packages the installation script for the Hydra Process Manager to enable standalone NVSHMEM application development. Specifically, you can write an NVSHMEM program and run a multi-process job using the Hydra Process Manager. This eliminates any dependency on installing MPI to use NVSHMEM. The Hydra launcher is called mpiexec.hydra and the default Hydra build system installs two symbolic links, mpiexec and mpirun. Run mpiexec.hydra -h for help information.
6.4. Interoperability With Other Programming Models FAQs
Q: Can NVSHMEM be used in MPI applications?
A: Yes. NVSHMEM provides an initialization API that takes an MPI communicator as an attribute. Each MPI rank in the communicator becomes an OpenSHMEM PE. Currently, NVSHMEM has been tested with OpenMPI 4.0.0. In principle, other OpenMPI derivatives such as SpectrumMPI (available on Summit and Sierra) are also expected to work.
Q: Can NVSHMEM be used in OpenSHMEM applications?
A: Yes. NVSHMEM provides an initialization API that supports running NVSHMEM on top of an OpenMPI/OSHMEM job. Each OSHMEM PE maps 1:1 to an NVSHMEM PE. NVSHMEM has been tested with OpenMPI 4.0.0/OSHMEM and OpenMPI3+/OSHMEM depends on UCX (NVSHMEM has been tested with UCX 1.4.0). The OpenMPI-4.0.0 installation must be configured with the --with-ucx flag to enable OpenSHMEM + NVSHMEM interoperability.
6.5. GPU-GPU Interconnection FAQs
Q: Can I use NVSHMEM to transfer data across GPUs on different sockets?
A: Yes, if there is an InfiniBand NIC accessible to GPUs on both the sockets. Otherwise, NVSHMEM requires that all GPUs are P2P accessible.
Q: Can I use NVSHMEM to transfer data between P2P-accessible GPUs that are connected by PCIE?
A: Yes, NVSHMEM supports both PCIE and NVLink. Atomic memory operations are only supported between NVLink-connected GPUs.
Q: Can I use NVSHMEM to transfer data between GPUs on different hosts connected by InfiniBand?
A: Yes. NVSHMEM supports InfiniBand. Strided-RMA (shmem_put/get), and atomic memory operations are not supported over InfiniBand.
6.6. NVSHMEM API Usage FAQs
Q: What's the difference between, say, nvshmemx_putmem_on_stream and nvshmemx_putmem_nbi_on_stream? It seems both are asynchronous to the host thread and ordered with respect to a given stream.
A: The function putmem_nbi_on_stream is implemented in a more deferred way by not issuing the transfer immediately but making it wait on an event at the end of the stream. If there is another transfer in process at the same time (on another stream), bandwidth could be shared. If the application can avoid this, nbi_on_stream gives the flexibility to express this intent to NVSHMEM. But NVSHMEM currently does not track activity on all CUDA streams. The current implementation records an event on the user provided stream, makes an NVSHMEM internal stream wait on the event, and then issues a put on the internal stream. If all nbi puts land on the same internal stream, they are serialized so that the bandwidth is used exclusively.
Q: Can I issue multiple barrier_all_on_stream on multiple streams concurrently and then cudaStreamSynchronize on each stream?
A: Multiple concurrent barrier_all_on_stream / barrier_all calls are not valid. Only one barrier (or any other collective) among the same set of PEs can be in-flight at any given time. To use concurrent barriers among partially overlapping active sets, syncneighborhood_kernel can be used as a template to implement a custom barrier. See the following for an example of a custom barrier (multi-gpu-programming-models).
Q: Suppose there are in-flight putmem_on_stream. Does nvshmem_barrier_all() ensure completion of the pending shmem operations on streams?
A: The StreamSynchronize function needs to be called before calling nvshmem_barrier_all. barrier_all_on_stream appears to hang non-deterministically.
Q: Why is nvshmem_quiet necessary in the syncneighborhood_kernel?
A: It is required by shmem_barrier semantics. As stated in multi-gpu-programming-models, “…shmem_barrier ensures that all previously issued stores and remote memory updates, including AMO and RMA operations, done by any of the PEs in the active set on the default context are complete before returning.”
Q: If a kernel uses nvshmem_put_block instead of nvshmem_p, is nvshmem_quiet still required?
A: It is required per OpenSHMEM's requirement to put semantics which do not guarantee delivery of data to the destination array on the remote PE. For more information, see multi-gpu-programming-models.
Q: I use the host-side blocking API, nvshmem_putmem_on_stream, on the same CUDA stream that I want to be delivered at the target in order. Is nvshmem_quiet required even though there is no non-blocking call and they are issued in separate kernels?
A: In the current implementation, nvshmem_putmem_on_stream includes quiet. However, it is only required to release the local buffer and not necessarily deliver at the target by the OpenSHMEM spec.
Q: Is it sufficient to use a nvshmem_fence (instead of a nvshmem_quiet) in the above case if the target is the same PE?
A: In the current implementation, all messages to the same PE are delivered in the order they are received by the HCA, which follows the stream order. So, even nvshmem_fence is not required. These are not the semantics provided by the OpenSHMEM specification, however. The putmem_on_stream function on the same CUDA stream only ensures that the local buffers for the transfers will be released in the same order.
Q: When nvshmem_quiet is used inside a device kernel, is the quiet operation scoped within the stream the kernel is running on? In other words, does it ensure completion of all operations or only those issued to the same stream?
A: It ensures all operations that are GPU-initiated. A nvshmem_quiet() call on the device does not quiet in-flight operations from the host.
6.7. Debugging FAQs
Q: Is there any hint to diagnose the hang?
A: Check if there are stream 0 blocking CUDA calls from the application, like cudaDeviceSynchronize or cudaMemcpy, especially in the iterative phase of the application. Stream 0 blocking calls in the initialization and finalization phases are usually safe. Check if the priority of the user stream used for NVSHMEM _on_stream calls is explicitly set with cudaStreamCreateWithPriority. Check that the determinism of the hang changes with single-node (all pairs of GPUs connected by NVLink or PCI-E only) compared to single-node (GPUs on different sockets connected by InfiniBand loopback) or multi-node (GPUs connected by InfiniBand).
Q: How do I dump debugging information?
A: A: Refer to the runtime environment variables - NVSHMEM_DEBUG and NVSHMEM_DEBUG_FILE in .
Q: Why is the receive buffer not updated with remote data even after synchronization with a flag?
A: For synchronization with flag, the application must use nvshmem_wait_until/test API. A plain while loop or if condition to check flag value is not sufficient. NVSHMEM needs to perform consistency operation to ensure that the data is visible to the GPU after synchronization using flag value.
6.8. Miscellaneous FAQs
Q: Does pointer arithmetic work with shmem pointers? For example, int* outmsg = (int *) shmem_malloc(2* sizeof(int)); shmem_int_p(target + 1, mype, peer)?
A: Yes.
Q: Can I avoid cudaDeviceSynchronize + MPI_Barrier to synchronize across multiple GPUs?
A: Yes, nvshmem_barrier_all_on_stream with cudaStreamSynchronize can be called from the host thread. If multiple barrier synchronization events can happen before synchronizing with the host thread, this gives better performance. Calling nvshmem_barrier_all from inside the CUDA kernel can be used for collective synchronization if there are other things that can be done by the same CUDA kernel after a barrier synchronization event. For synchronizing some pairs of PEs and not all, pair-wise nvshmem_atomic_set calls by the initiator and nvshmem_wait_until or nvshmem_test calls by the target can be used.
Q: How should I allocate memory for NVSHMEM?
A: NVSHMEM supports nvshmem_malloc and nvshmem_align memory allocation APIs. Per the OpenSHMEM specification v1.3, these APIs only require the remote pointer to be from the symmetric heap (SHEAP). However, NVSHMEM also requires the local pointer to be from SHEAP for communication with a remote peer connected by InfiniBand. If the remote peer is P2P accessible (PCI-E or NVLink), the local pointer can be obtained using cudaMalloc and is not required to be from the SHEAP.
Q: Is there any example of a mini-application written using NVSHMEM?
A. Yes. The programming models GitHub repository contains examples of Jacobi mini-application written using NVSHMEM.
Notices
Notice
This document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.
NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice.
Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.
NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.
NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk.
NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.
No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.
Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.
THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.
VESA DisplayPort
DisplayPort and DisplayPort Compliance Logo, DisplayPort Compliance Logo for Dual-mode Sources, and DisplayPort Compliance Logo for Active Cables are trademarks owned by the Video Electronics Standards Association in the United States and other countries.
HDMI
HDMI, the HDMI logo, and High-Definition Multimedia Interface are trademarks or registered trademarks of HDMI Licensing LLC.
Trademarks
NVIDIA, the NVIDIA logo, and CUDA, CUDA Toolkit, GPU, Kepler, Mellanox, NVLink, NVSHMEM, and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.