TLT Integration with DeepStream
NVIDIA Transfer Learning Toolkit (TLT) is a simple, easy-to-use training toolkit that requires minimal to zero coding to create vision AI models using the user's own data. Using TLT, users can transfer learn from NVIDIA pre-trained models to create their own model. Users can add new classes to an existing pre-trained model, or they can re-train the model to adapt to their use case. Users can use model pruning capability to reduce the overall size of the model.
Pre-trained models
There are 2 types of pre-trained models that users can start with. One is the purpose-built pre-trained models. These are highly accurate models that are trained on millions of objects for a specific task. The other type of models are meta-architecture vision models. The pre-trained weights for these models merely act as a starting point to build more complex models. These pre-trained weights are trained on Open image dataset and they provide a much better starting point for training versus starting from scratch or starting from random weights. With the latter choice, users can choose from 80+ permutations of model architecture and backbone. See the illustration below.
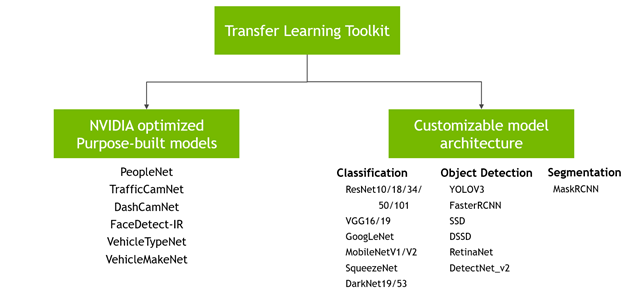
The purpose-built models are built for high accuracy and performance. These models can be deployed out of the box for applications in smart city or smart places or can also be used to re-train with user’s own data. All 6 models are trained on millions of objects and can achieve more than 80% accuracy on our test data. More information about each of these models is available in Chapter 4 of TLT documentation – Purpose built models or in the individual model cards. Typical use cases and some model KPIs are provided in the table below. PeopleNet can be used for detecting and counting people in smart buildings, retail, hospitals, etc. For smart traffic applications, TrafficCamNet and DashCamNet can be used to detect and track vehicles on the road.
Model Name | Network Architecture | Number of classes | Accuracy | Use case |
|---|---|---|---|---|
DetectNet_v2-ResNet18 | 4 | 83.5% | Detect and track cars | |
DetectNet_v2-ResNet18/34 | 3 | 84% | People counting, heatmap generation, social distancing. | |
DetectNet_v2-ResNet18 | 4 | 80% | Identify objects from a moving object | |
DetectNet_v2-ResNet18 | 1 | 96% | Detect face in a dark environment with IR camera | |
ResNet18 | 20 | 91% | Classifying car models | |
ResNet18 | 6 | 96% | Classifying type of cars as coupe, sedan, truck, etc |
Models trained with TLT are natively integrated for inference with DeepStream. So, any pre-trained models mentioned above or any meta-architecture models such as YoloV3, FasterRCNN, SSD, MaskRCNN, etc will work with DeepStream. To make it easier to deploy, we have provided sample config files for each of the networks. The sample config files are available in the ‘samples/configs/tlt_pretrained_models’. This can be used with the ‘deepstream-app’ reference application. Here is what is included:
• deepstream_app_source1_dashcamnet_vehiclemakenet_vehicletypenet.txt - Demonstrates object detection using DashCamNet model with VehicleMakeNet and VehicleTypeNet as secondary classification models on one source.
• deepstream_app_source1_faceirnet.txt - Demonstrates face detection for IR camera using FaceDetectIR object detection model on one source
• deepstream_app_source1_peoplenet.txt - Demonstrates object detection using PeopleNet object detection model on one source
• deepstream_app_source1_trafficcamnet.txt - Demonstrates object detection using TrafficCamNet object detection model on one source
• deepstream_app_source1_detection_models.txt - Demonstrates object detection using multiple TLT meta-architecture models located at https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps. Models can be switched using one of the nvinfer configuration files below. This config can also be used for user’s own custom models trained with TLT.
• config_infer_primary_dashcamnet.txt, labels_dashcamnet.txt - DashCamNet – Resnet18 based object detection model for Vehicle, Bicycle, Person, Roadsign
• config_infer_secondary_vehiclemakenet.txt, labels_vehiclemakenet.txt - VehicleMakeNet – Resnet18 based classification model for make of the vehicle
• config_infer_secondary_vehicletypenet.txt, labels_vehicletypenet.txt - VehicleTypeNet – Resnet18 based classification model for type of the vehicle
• config_infer_primary_faceirnet.txt, labels_faceirnet.txt - FaceIRNet – Resnet18 based face detection model for IR images
• config_infer_primary_peoplenet.txt, labels_peoplenet.txt -PeopleNet – Resnet18 based object detection model for Person, Bag, Face
• config_infer_primary_trafficcamnet.txt, labels_trafficnet.txt - TrafficCamNet – Resnet18 based object detection model for Vehicle, Bicycle, Person, Roadsign for traffic camera viewpoint
• config_infer_primary_detectnet_v2.txt, detectnet_v2_labels.txt - DetectNetv2 – Object detection model for Bicycle, Car, Person, Roadsign
• config_infer_primary_dssd.txt, dssd_labels.txt - DSSD – Object detection model for Bicycle, Car, Person, Roadsign
• config_infer_primary_frcnn.txt, frcnn_labels.txt - FasterRCNN – Object detection model for Bicycle, Car, Person, Roadsign, Background
• config_infer_primary_retinanet.txt, retinanet_labels.txt - RetinaNet – Object detection model for Bicycle, Car, Person, Roadsign
• config_infer_primary_ssd.txt, ssd_labels.txt - SSD – Object detection model for Bicycle, Car, Person, Roadsign
• config_infer_primary_yolov3.txt, yolov3_labels.txt - YoloV3 – Object detection model for Bicycle, Car, Person, Roadsign
For more information about TLT and how to deploy TLT models with DeepStream, refer to Deploying to DeepStream chapter of TLT user guide.
For more information about deployment of architecture specific models, refer to https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps GitHub repo.