Introduction#
NVIDIA Mission Control is an integrated software platform designed for managing and orchestrating large-scale GPU computing clusters. It provides comprehensive deployment, management, and monitoring capabilities for high-performance computing (HPC) and AI workloads across different system configurations.
Platform Overview#
Mission Control delivers a unified control plane that simplifies the complexity of managing GPU-accelerated infrastructure. The platform combines cluster orchestration, workload scheduling, and system monitoring into a cohesive management framework built on Kubernetes and industry-standard tools.
Key capabilities include:
Automated Deployment: Streamlined provisioning and configuration of compute resources
Workload Orchestration: Advanced scheduling and resource allocation for AI/ML and HPC jobs
System Monitoring: Real-time observability and health tracking across the infrastructure
Slurm Integration: Native support for Slurm workload manager with BCM-provisioned clusters
Supported System Configurations#
Mission Control supports multiple system architectures, each optimized for different scale and performance requirements:
DGX B200/B300 Systems#
Architecture Version: v2.2
Mission Control Software Architecture – DGX B200/B300 Systems (v2.2)
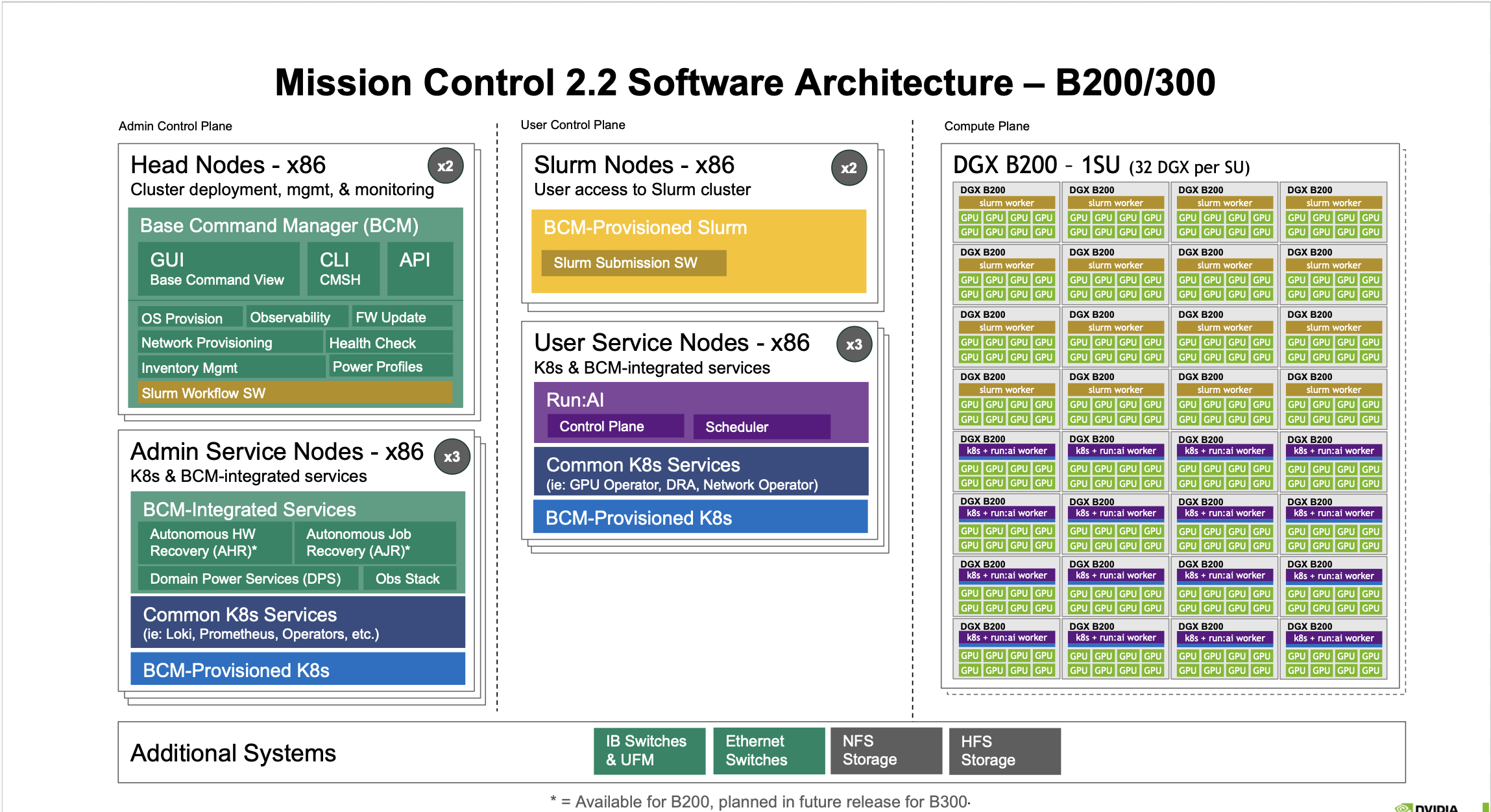
Figure 1 Mission Control 2.2 Software Architecture – B200/300#
The DGX B200/B300 configuration represents NVIDIA’s high-density GPU computing platform with unified architecture supporting both B200 and B300 systems.
Admin Control Plane#
Head Nodes - x86 (x2)
Cluster deployment, management, and monitoring functionality with Base Command Manager (BCM):
GUI: Base Command View for visual cluster management
CLI: CMSH command-line interface
API: RESTful API for programmatic automation
Core BCM Functions:
OS Provision and Observability
Network Provisioning and FW Update
Rack & Inventory Management and Health Check
Leak Monitoring & Control and Power Profiles
Slurm Workflow SW integration
Admin Service Nodes - x86 (x3)
Kubernetes and BCM-integrated services providing:
BCM-Integrated Services:
Mission Control-autonomous hardware recovery: Automated hardware fault detection and recovery
Mission Control-autonomous job recovery: Automatic job restart and fault tolerance
Domain Power Services (DPS)- Early Preview: Power management and optimization
Observability Stack: Comprehensive observability and monitoring
Common K8s Services:
Loki, Prometheus, Operators, and other Kubernetes ecosystem tools
BCM-Provisioned K8s cluster management
User Control Plane#
Slurm Nodes - x86 (x2)
User access to Slurm cluster with BCM-Provisioned Slurm and Slurm Submission SW.
User Service Nodes - x86 (x3)
Run:ai and other User K8s code execution platform featuring:
Run:ai: AI workload orchestration with Control Plane and Scheduler
Common K8s Services: GPU Operator, DRA, Network Operator
BCM-Provisioned K8s: Kubernetes cluster provisioned by BCM
Compute Plane#
DGX B200 - 1SU (32 DGX per SU)
The compute plane consists of DGX systems organized in superunits (SU), each containing 32 DGX units. Each DGX node runs:
Slurm worker: HPC job execution
k8s + run:ai worker: AI/ML workload execution with Run:ai orchestration
Multiple CPU and GPU units per DGX system
Additional Systems#
IB Switches & UFM: InfiniBand networking and Unified Fabric Manager
Ethernet Switches: Standard Ethernet connectivity
NFS Storage: Network File System for shared storage
HFS Storage: High-performance file system
Key Features (B200/B300)#
Unified architecture supporting both DGX B200 and DGX B300 systems*
Separated Admin and User Control Planes for enhanced security
Mission Control-autonomous hardware recovery and Mission Control-autonomous job recovery
Run:ai integration with dedicated Control Plane and Scheduler
Domain Power Services (DPS)- Early Preview feature capability for power management
Comprehensive observability stack with Loki and Prometheus
Note: Some features available for B200, planned in future release for B300
GB200/GB300 NVL72 Systems#
Architecture Version: v2.2
Mission Control Software Architecture – GB200/GB300 NVL72 Systems (v2.2)
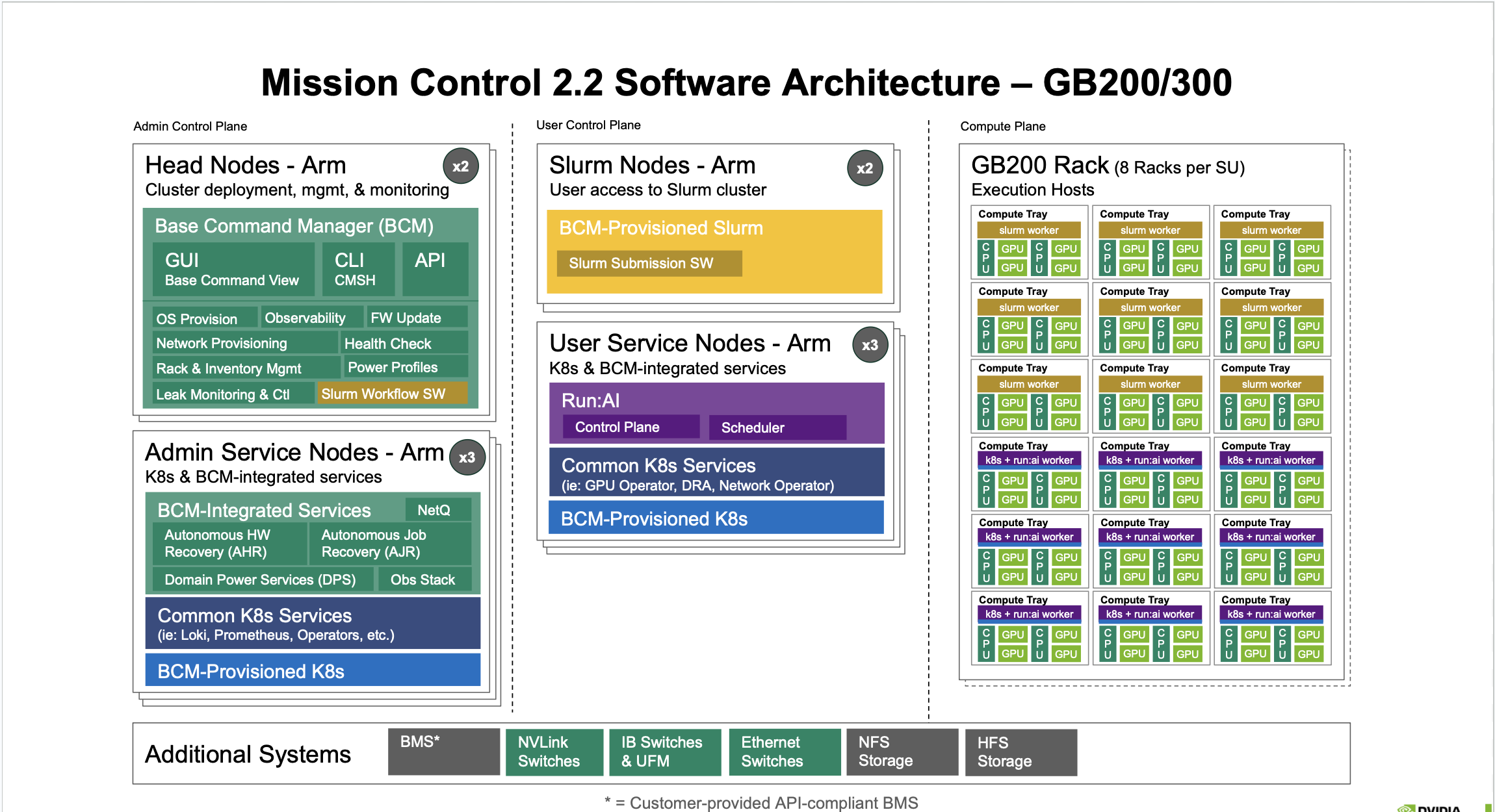
Figure 2 Mission Control 2.2 Software Architecture – GB200/300#
The GB200/GB300 configuration delivers advanced capabilities with separated admin and user control planes, featuring ARM64-based architecture for next-generation systems.
Admin Control Plane#
Head Nodes - Arm (x2)
Cluster deployment, management, and monitoring with Base Command Manager (BCM):
GUI: Base Command View
CLI: CMSH for ARM64 systems
API: RESTful API
Core Functions:
OS Provision and Observability
Network Provisioning and FW Update
Rack & Inventory Management and Health Check
Leak Monitoring & Control and Power Profiles
Slurm Workflow SW
Admin Service Nodes - Arm (x3)
Kubernetes and BCM-integrated services:
BCM-Integrated Services:
NetQ: Network monitoring and observability
Mission Control-autonomous hardware recovery: Hardware fault management
Mission Control-autonomous job recovery: Job fault tolerance
Domain Power Services (DPS)- Early Preview: Power management and optimization
Observability Stack: Comprehensive observability and monitoring
Common K8s Services:
Loki, Prometheus, Operators, etc.
BCM-Provisioned K8s infrastructure
User Control Plane#
Slurm Nodes - Arm (x2)
User access to Slurm cluster with BCM-Provisioned Slurm and Slurm Submission SW.
User Service Nodes - Arm (x3)
Kubernetes and BCM-integrated services for user workloads:
Run:ai: Control Plane and Scheduler for AI workload orchestration (New in Mission Control 2.2)
Common K8s Services: GPU Operator, DRA, Network Operator
BCM-Provisioned K8s: User-space Kubernetes cluster
Compute Plane#
GB200 Rack (8 Racks per SU)
The compute plane consists of GB200/300 racks organized in compute trays, with 8 racks per superunit (SU). Each compute tray contains:
Slurm worker: HPC job execution
k8s + runai worker: AI/ML workload execution
CPU and GPU units: Combined CPU and GPU compute resources
Execution Hosts are organized in compute trays for optimal resource allocation.
Additional Systems#
BMS*: Customer-provided API-compliant Building Management System
NVLink Switches: High-speed GPU interconnect
IB Switches & UFM: InfiniBand networking
Ethernet Switches: Standard networking
NFS Storage: Network file storage
HFS Storage: High-performance storage
* = Customer-provided API-compliant BMS
Key Features (GB200/GB300)#
Native ARM64 architecture for head nodes and service nodes
Separated admin and user control planes for enhanced security and isolation
NetQ network monitoring and observability
Run:ai with dedicated control plane and scheduler
Mission Control-utonomous hardware recovery and Mission Control-autonomous job recovery
Customer-provided BMS integration support
NVLink switches for high-speed GPU interconnect
Compute tray organization for optimal resource management
Architecture Components#
Base Command Manager (BCM)#
The Base Command Manager serves as the central management interface for Mission Control, providing:
GUI: Web-based Base Command View for visual cluster management
CLI: Command-line interface (CMSH for x86 systems, CMSH for Arm64 systems)
API: RESTful API for programmatic automation
Core Functions#
OS provisioning and firmware updates
Network provisioning and health checks
Inventory management and power profiles
Observability and monitoring integration
Leak monitoring and control
Slurm workflow software integration
Run:ai Orchestration#
Run:ai provides advanced AI workload management with:
Intelligent scheduling and resource allocation
GPU sharing and fractionalization
Workload prioritization and fairness policies
Integration with common machine learning frameworks
Dedicated control plane and scheduler (v2.2)
Kubernetes Infrastructure#
Mission Control leverages Kubernetes for:
Container orchestration across control and compute planes
Service discovery and load balancing
Declarative configuration management
BCM-provisioned and common Kubernetes services (Loki, Prometheus, network operators)
Slurm Workload Manager#
BCM-provisioned Slurm integration enables:
Traditional HPC job scheduling
Resource allocation and queue management
Integration with existing HPC workflows
Slurm submission software for user access
Network and Storage Systems#
Mission Control integrates with enterprise infrastructure:
Networking:
InfiniBand switches and UFM for high-performance interconnect
Ethernet switches for standard networking
NVLink switches (GB300/GB200) for GPU-to-GPU communication
Storage:
NFS storage for shared filesystems
HFS storage for high-performance workloads
Autonomous Resiliency Engine (ARE)#
Mission Control-autonomous hardware recovery#
Automated detection and recovery from hardware failures:
Continuous health monitoring
Automatic fault isolation
Self-healing infrastructure capabilities
Mission Control-autonomous job recovery#
Intelligent job fault tolerance:
Automatic checkpoint and restart
Job state preservation
Minimal user intervention required
Observability Stack#
Comprehensive monitoring and observability:
Prometheus: Metrics collection and alerting
Loki: Log aggregation and querying
NetQ: Network monitoring and observability (GB200/GB300)
Real-time health tracking across infrastructure
Performance analytics and troubleshooting
Version Information#
This documentation covers Mission Control version 2.2, supporting the latest DGX B200/B300 and NVIDIA GB200/GB300 NVL72 system architectures.
Getting Started#
To begin using Mission Control:
Review the system requirements for your target architecture (B200/B300 or GB200/GB300)
Follow the installation procedures specific to your configuration
Configure the Base Command Manager for your cluster topology
Provision compute nodes and verify system health
Set up user access through Slurm or Kubernetes interfaces
The following chapters provide detailed instructions for installation, configuration, and operation of Mission Control across all supported system architectures.
Important Notes#
GB200/GB300 systems require customer-provided API-compliant BMS
All systems support both Slurm and Kubernetes-based workload submission
ARM64 architecture is native for GB200/GB300 control planes
Some features for B300 are planned for future releases