The NVIDIA Grace Blackwell Superchip#
The Blackwell architecture introduces groundbreaking advancements for generative AI and accelerated computing. The incorporation of the second-generation Transformer Engine with the faster and wider NVIDIA® NVLink® interconnect propels the data center into a new era, with orders of magnitude more performance as compared to the previous architecture generation. Additional advances in NVIDIA Confidential Computing raise the level of security for real-time LLM inference at scale without compromising performance. When the Blackwell’s new Decompression Engine is combined with Spark RAPIDS™, the libraries deliver unparalleled database performance to fuel data analytics applications. Blackwell’s multiple advancements are build on generations of accelerated computing technologies to define the next chapter of generative AI with unparalleled performance, efficiency, and scale.
The NVIDIA GB200 NVL72 connects 36 Grace CPUs and 72 Blackwell GPUs in a rack-scale design, supercharging generative AI, data processing, and high-performance computing. The GB200 NVL72 is a liquid-cooled, rack-scale solution that boasts a 72-GPU NVLink domain that acts as a massive GPU and delivers 30 times faster real-time trillion-parameter LLM inference.
The GB200 Grace Blackwell Superchip is a key component of the NVIDIA GB200 NVL72, connecting two high-performance NVIDIA Blackwell GPUs and an NVIDIA Grace CPU, using the 900 GB/s NVIDIA® NVLink®-C2C interconnect to the two Blackwell GPUs.
A New Class of AI Superchip#
Blackwell-architecture GPUs pack 208 billion transistors and are manufactured using a custom-built TSMC 4NP process. All Blackwell products feature two reticle-limited dies connected by a 10 terabytes per second (TB/s) chip-to-chip interconnect in one GPU.
The Blackwell architecture is much more than a chip with high theoretical, floating-point operations per second (FLOPS). It continues to build upon and benefit from NVIDIA’s rich ecosystem of development tools, CUDA-X™ libraries, over four million developers, and over 3,000 applications scaling performance across thousands of nodes.
Second Generation Transformer Engine#
Blackwell introduces the new second-generation Transformer Engine. The second-generation Transformer Engine uses custom Blackwell Tensor Core technology combined with TensorRT-LLM and Nemo Framework innovations to accelerate inference and training for LLMs and Mixture-of-Experts (MoE) models. To supercharge inference of large MoE models, Blackwell Tensor Cores add new precisions, including new community-defined microscaling formats, giving high accuracy and greater throughput. The Blackwell Transformer Engine utilizes advanced dynamic range management algorithms and fine-grain scaling techniques, called micro-tensor scaling, to optimize performance and accuracy and enable FP4 AI. This doubles the performance with Blackwell’s FP4 Tensor Core, doubles the parameter bandwidth to the HBM memory, and doubles the size of next-generation models per GPU.
Performant Confidential Computing and Secure AI#
NVIDIA has a tradition of being first to deliver new ideas and technologies in non-traditional ways, which is why Confidential Computing capabilities extended the Trusted Execution Environment (TEE) beyond CPUs to GPUs. Confidential Computing on NVIDIA Blackwell was architected to be the fastest, most secure, and attestable (evidence-based) protections for LLMs and other sensitive data. Blackwell introduces the first TEE-I/O capable GPU in the industry and provides the most performant confidential compute solution with TEE-I/O capable hosts and inline protection over NVLink, which provides confidentiality and integrity. Blackwell Confidential Computing delivers nearly identical throughput performance as compared to unencrypted modes. Customers can now secure even the largest models in a performant way, in addition to protecting AI intellectual property (IP) and securely enable confidential AI training, inference, and federated learning.
Fifth-Generation NVLink#
Unlocking the full potential of exascale computing and trillion-parameter AI models hinges on the need for swift, seamless communication among every GPU in a server cluster. Before NVIDIA GB200 NVL72 was introduced, the maximum number of GPUs that could be connected in one NVLink domain was limited to eight on an HGX H200 baseboard, with a communication speed of 900 GB/s per GPU. The introduction of the GB200 NVL72 design and fifth-generation NVLINK dramatically expanded these capabilities because the NVLink domain can now support up to 72 NVIDIA Blackwell GPUs, with a communication speed of 1.8 TB/s per GPU, and 36 times faster than state-of-the-art 400 Gbps Ethernet standards. This leap in NVLink domain size and speed can accelerate training and inference of trillion-parameter models, such as GPT-MoE-1.8T, by up to four and 30 times respectively.
The NVIDIA NVLink Switch Chip enables 130TB/s of GPU bandwidth in one 72-GPU NVLink domain (NVL72) for model parallelism and delivers four times the bandwidth efficiency with new NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ FP8 support. NVLink and NVLink Switch can be used together to support clusters beyond a server at the same impressive 1.8TB/s interconnect. Multi-server clusters with NVLink scale GPU communications in balance with the increased computing, so NVL72 can support 9X the GPU throughput of a single eight-GPU system.
Decompression Engine#
Data analytics and database workflows have traditionally been slow and cumbersome, relying on CPUs for compute. Accelerated data science can dramatically boost the performance of end-to-end analytics, speeding up value generation and time to insights while reducing cost. Databases, including Apache Spark, play critical roles in handling, processing, and analyzing large volumes of data for data analytics. Blackwell’s new dedicated Decompression Engine, in combination with the 8TB/s of high memory bandwidth and the Grace CPU’s high-speed NVLink-C2C, accelerates the full pipeline of database queries for the highest performance in data analytics and data science. With support for the latest compression formats, such as LZ4, Snappy, and Deflate, Blackwell performs 18X faster than CPUs and 6X faster than NVIDIA H100 Tensor Core GPUs for query benchmarks.
Use Cases and Workloads#
The field of AI has long been defined by the idea that more compute, more training data, and more parameters makes a better AI model.
However, AI has grown to require three laws that describe how applying compute resources in different ways impacts model performance. Together, these AI scaling laws reflect how the field has evolved with techniques to use additional compute in a wide variety of increasingly complex AI use cases:
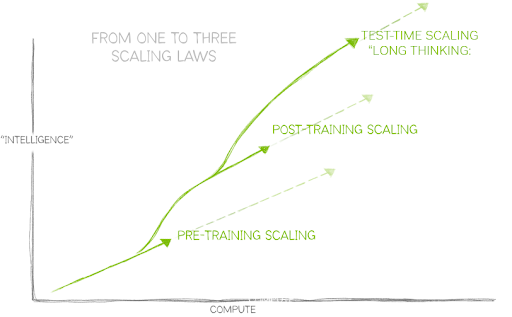
Pre-Training Scaling: Scaling up datasets and model parameters has consistently led to intelligence gains in AI, resulting in groundbreaking capabilities from billion- and trillion-parameter models.
This scaling law continues to drive innovation in model architecture and distributed training techniques, with future AI models poised to leverage the growing trove of multimodal data including text, images, audio, video, and sensor information.
Post-Training Scaling: Fine-tuning AI models for specific real-world applications requires 30x more compute during AI inference than pre-training.
As organizations adapt existing models for their unique needs, cumulative demand for AI infrastructure skyrockets.
Test-Time Scaling (“Long Thinking”): Advanced AI applications such as agentic AI or physical AI require iterative reasoning, where models explore multiple possible responses before selecting the best one, which consumes up to 100x more compute than traditional inference.
The NVIDIA GB200 NVL72 connects 36 Grace CPUs and 72 Blackwell GPUs in a rack-scale design, with a 72-GPU NVLink domain that acts as a massive GPU that unlocks the full potential of massive AI models across the three scaling laws.