Communication Libraries#
This section describes Unified Collective Communication (UCC), Open Unified Communication X (UCX), and Open Message Passing Interface (MPI).
UCX#
UCX is a core NVIDIA communications library. Refer to NVIDIA HPC-X and OpenUCX for more information about UCX. This guide identifies and documents UCX performance tunings and considerations in the GB200 platform with multi-node NVLink (MNNVL).
UCX offers multiple communication primitives such as get/put, send/receive and active messages (RPC) between various endpoints (CPUs, GPUs) in a distributed compute cluster. In a GB200 environment, such as 36x1, 72x1, and 36x2, there can be multiple communication paths between a pair of endpoints. Multi-node NVLink offers the highest bandwidth (NVL5, 900GB/s unidirectional theoretical maximum) with the lowest latency for large messages (for smaller sizes such as 1-byte message, IB over CX-7 has lower latency). A secondary East-West network using CX-7 Infiniband NICs is available, primarily for inter-rack connectivity but also to transport smaller messages.
Here is some additional information:
There are a variety of performance tests available to sanity check the setup. These tests measure bandwidth and latency by performing transfers over a range of data sizes. If MNNVL is enabled, UCX will use this network for transfers higher than a particular size.
UCX supports source and destination buffers obtained through a variety of APIs such as
cudaMalloc(),cudaHostAlloc(),cudaMallocManaged(),cuMemCreate(),malloc(), and so on and attempts to realize transfers between the source and the destination without intermediate copies through RDMA, DMA-based copies, and so on. When this is not possible because of system-dependent reasons or because of resource constraints, UCX resorts to pipelining mechanisms over internal buffers. For example, when source and destination buffers come fromcuMemCreate()allocations with fabric capability and reside on two different GPUs interconnected by MNNVL, UCX performs a zero-copy DMA-based read or write between the buffers. On the other hand, if the source and the destination buffers come fromcudaMallocManaged()allocations, UCX uses a pipeline protocol over internal device buffers because DMA-based copies cannot be used for inter-GPU communication on these buffers. The size of these internal buffers is fixed but can be changed through environment variables.When MNNVL is enabled, UCX uses the MNNVL fabric for host-to-host transfers. The MNNVL fabric provides higher bandwidth but consumes chip-to-chip bandwidth. To conserve chip-to-chip bandwidth, disable NVVL by setting the
UCX_CUDA_IPC_ENABLE_MNNVL=0environment variable.
Tip
Starting in UCX 1.18.1, UCX defaults to using the MNNVL fabric.
UCC#
The UCC library is available directly from the UCC github repository or as part of the HPC-X package.
Refer to the following for more information:
Using UCC from Open MPI#
To check whether the Open MPI build supports UCC accelerated collectives run the following command:
the MCA coll: ucc component:
$ ompi_info | grep ucc
MCA coll: ucc (MCA v2.1.0, API v2.0.0, Component v4.1.4)
To execute the MPI program with UCC accelerated collectives, enable the
uccMCA component by settingexport OMPI_MCA_coll_ucc_enable=1.To work around the open-mpi/ompi#9885 known issue, set
export OMPI_MCA_coll_ucc_priority=100.
UCC heuristics select the highest performing implementation for a collective. UCC supports execution scales from one node to a full supercomputer. Depending on specific system setup, the UCC heuristics might not be optimal. This section only describes basic UCC tuning.
Team Layers and Collective Layers#
UCC collective implementations are composed of at least one Team Layer (TL) that are designed as thin, composable abstraction layers with no dependencies between
different TLs. To fulfill the semantic requirements of programming models like MPI, and because not all TLs cover the full functionality required by a collective, TLs are composed of Collective Layers (CLs). To review the list of CLs and TLs supported by the available UCC installation, run the ucc_info -s command.
$ ucc_info -s
Default CLs scores: basic=10 hier=50
Default TLs scores: cuda=40 nccl=20 self=50 ucp=10
Tuning Team Layers and Collective Layers#
UCC exposes environment variables to tune CL and TL selection and behavior. To list all
UCC environmental variables, run the ucc_info -caf command:
$ ucc_info -caf | head -15
# UCX library configuration file
# Uncomment to modify values
#
# UCC configuration
#
#
# Comma separated list of CL components to be used
#
# syntax: comma-separated list of: [basic|hier|all]
#
UCC_CLS=basic
UCC selects CLs/TLs based on a score. Each time UCC needs to select a CL/TL, the score with the highest score is selected as long as the CL/TL configuration satisfies:
The collective type
The message size
The memory type
The team size (number of ranks participating in the collective)
To override the default scores following this syntax, users can set the UCC_<CL/TL>_<NAME>_TUNE environment variables:
UCC_<CL/TL>_<NAME>_TUNE=token_1#token_2#...#token_N
The syntax uses the delimiter # to include a list of tokens to the environment variable, and each token is a : separated list of qualifiers:
token=coll_type:msg_range:mem_type:team_size:score:alg
The only mandatory qualifier is to provide the score or specify the alogrithm with the alg option, and all other qualifiers are optional. Here is a list of qualifiers:
coll_type = coll_type_1,coll_type_2,...,coll_type_n- a comma (,) separated list of collective types.msg_range = m_start_1-m_end_1,m_start_2-m_end_2,..,m_start_n-m_end_n- a comma (,) separated list of msg ranges in byte, where each range is represented bystartandendvalues separated by-. Values can be integers using optional letter suffixes. Supported suffixes areK=1<<10,M=1<<20,G=1<<30and,T=1<<40. Parsing is case independent and abcan be optionally added. The special valueinfmeans MAX msg size. For example,128,256b,4K,1Mare valid sizes.mem_type = m1,m2,..,mN- a,separated list of memory typesteam_size = [t_start_1-t_end_1,t_start_2-t_end_2,...,t_start_N-t_end_N]- a,separated list of team size ranges enclosed with[].score =, anintvalue from0toinf.infmaps to INT_MAX (2147483647).alg = @<value|str>- character@followed by either theintor string representing the collective algorithm.
Here is a list of the supported memory types:
host: for CPU memory.cuda: for pinned CUDA Device memory (cudaMalloc).cuda_managed: for CUDA Managed Memory (cudaMallocManaged).
Here is a list of the sample configurations:
UCC_TL_NCCL_TUNE=0. This disables all the NCCL collectives. A score of 0 is applied toAll collectives because the
coll_typequalifier is not specified.All memory types because mem_type` qualifier is not used.
The default (
[0-inf]) message range.The default (
[0-inf]) team size.
UCC_TL_NCCL_TUNE=allreduce:cuda:inf#alltoall:0. This forces NCCL allreduce forcudabuffers and disables alltoall.UCC_TL_UCP_TUNE=bcast:0-4K:cuda:0#bcast:65k-1M:[25-100]:cuda:inf. This disables UCP bcast on CUDA buffers for message sizes0-4Kand forces UCP bcast on CUDA buffers for message sizes65K-1Monly for teams with25-100processes (or ranks).UCC_TL_UCP_TUNE=allreduce:0-4K:@0#allreduce:4K-inf:@sra_knomial. This sets the algorithm@0(called rab) for TL_UCP for message range 0-4K bytes and to the algorithmsra_knomialfor 4k-inf bytes message range. The output ofucc_info -Aprovides more information about UCC algorithms.UCC_CLS="hier,basic"andUCC_TLS="cuda,ucp". - The first variable selects the hier and basic CLs. - The second variable selects the cuda and ucp TLs. Individual algorithms are selected based on their scores that can be viewed withucc_info -s.UCC_CLS="basic",UCC_TLS="cuda,ucp",UCC_TL_UCP_TUNE="allgather:0-inf:cuda:90:@0", andUCC_TL_CUDA_TUNE="allgather:512-64K:cuda:[4-8]:100:@0". These sets of variables select basic CL and cuda and ucp TLs. The@0allgather algorithm for ucp is given a score of90. However, for team sizes of[4-8]and message sizes of5`2-64K, allgather from cuda TL will be preferred since it has a higher score of100.UCC_TL_UCP_ALLREDUCE_KN_RADIX=0-8k:host:8,8k-inf:host:2. This option sets the radix of the recursive knomial allreduce algorithm (@0andknomial) to 8 (for message ranges of0-8k) and 2 (for message range of8k-inf). This is done forhostmemory.
The UCC_COLL_TRACE=INFO variable reports all selected CLs and TLs by the UCC library.
UCC Configuration File and Priority#
The ucc.conf UCC configuration file provides a unified way of tailoring the behavior of
UCC components including CLs and TLs. It can contain any UCC variable in the VAR=VALUE format. If a UCC user sets the UCC variable value in the command line and in the configuration file, the value provided in the command line takes precedence.
To query the supported collective types and algorithms, run the following command:
$ ucc_info -A
cl/hier algorithms:
Allreduce
0 : rab : intra-node reduce, followed by inter-node allreduce, followed by innode broadcast
1 : split_rail : intra-node reduce_scatter, followed by PPN concurrent inter-node allreduces, followed by intra-node allgather
Alltoall
0 : node_split : splitting alltoall into two concurrent a2av calls withing the node and outside of it
Alltoallv
0 : node_split : splitting alltoallv into two concurrent a2av calls withing the node and outside of it
[...] snip
The output for ucc_info -A shows that the cl/hier collective layer supports
two Allreduce algorithms. The first algorithm, called rab, can be referenced in the environment variables
or configuration file with the 0 value (@0) or string (rab).
The UCC implementation currently supports the following CLs:
basic: Basic CL available for all supported algorithms.hier: Hierarchical CL exploiting the hierarchy on a system.
The hier CL exposes the following hierarchy levels:
NODEcontaining all ranks running on the same node.NETcontaining one rank from each node.
NODE and NET support a FULL subgroup.
An example of a hierarchical CL is a pipeline of CUDA reduce with inter-node SHARP and UCP broadcast.
The basic CL can leverage the same TLs but will execute in a non-pipelined, less efficient, fashion.
UCC supports the following TLs:
cuda: TL supports CUDA device memory by exploiting the NVLINK connections between GPUs.nccl: TL leverages NCCL for collectives on CUDA device memory. In many cases, UCC collectives are directly mapped to NCCL collectives. If that is not possible, a combination of NCCL collectives might be used.self: TL supports collectives with only one participant.ucp: TL builds on the UCP point to point communication routines from UCX. This is the most general TL that supports all memory types. If required, computation happens local to the memory (for example, for CUDA device memory CUDA kernels are used for computation).sharp: TL leverages the NVIDIA Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) in-network computing features to accelerate inter-node collectives.
Open MPI#
The Message Passing Interface (MPI) is a popular process management and inter-process communication specification. Open MPI is optimized for NVIDIA systems with binary packages and containers available through HPCX and the HPC SDK.
For support with cuMemCreate() or cudaMallocAsync() memory, you need one of the following minimum
versions:
Open MPI 4.1.7 or 5.0.6 with UCX 1.18
HPCX 2.21
Process Placement, Affinity, and Basic Tuning#
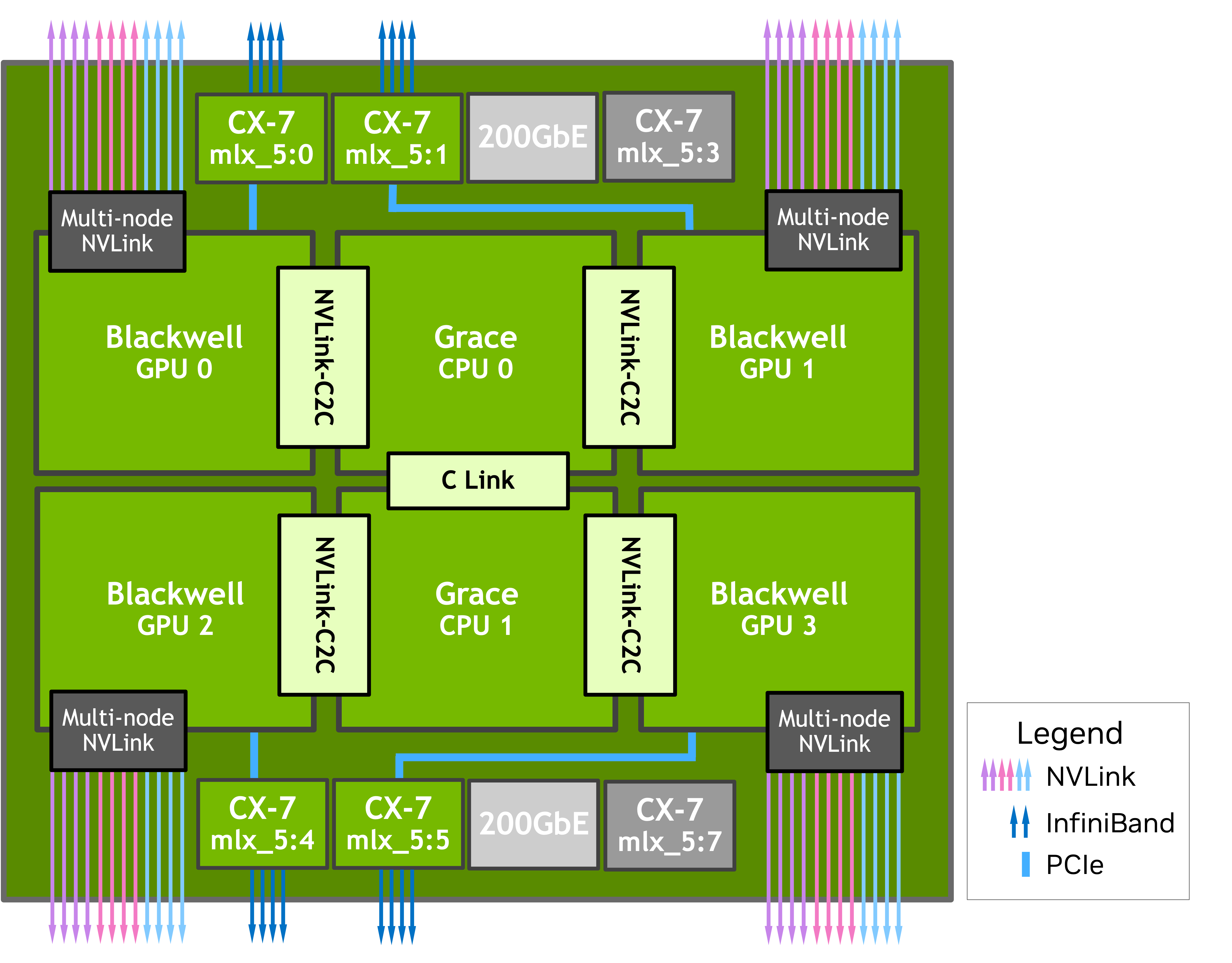
Figure 1 Simplified logical view of the compute node. Some connections are not shown.#
Figure 1 shows the logical view of one GB200 Oberon compute node OS instance, and there are two Grace CPUs per node. Each CPU has two Blackwell GPUs internally connected by an NVLink C2C bus, and each GPU has a multi-node NVLink 5 network connection.
Each node has eight network adaptors, and there is one Mellanox CX-7 InfiniBand network adaptor for each GPU. To get the best MPI performance on the GB200 Oberon system, during the application launch ensure that you are using the correct process, thread, GPU, and InfiniBand adaptor affinities because an incorrect affinity can negatively impact performance.
Affinities are controlled through a combination of the process launcher (mpirun
or srun) command-line arguments and environment variables. A common use case
in parallel high-performance computing applications is to assign one process
per GPU. When running with one process per GPU on the GB200 Oberon system, there
will be four MPI processes per node with two processes assigned to each of the
two 72 core Grace CPUs. Once bound to a specific CPU, the processes are additionally
restricted to 36 of the 72 available physical cores.
For applications that use OpenMP, each thread should be bound to
a unique physical core.
1 #!/bin/bash
2
3 source ~/luster_fsw/installs/modulefiles/cuda-12.8.sh
4 source ~/luster_fsw/installs/modulefiles/hpcx-v2.22.sh
5 source ~/luster_fsw/installs/modulefiles/omb-7.3.sh
6
7 # GB200 Oberon Node Specs
8 gpus_per_node=4
9 cores_per_socket=72
10 sockets_per_node=2
11
12 # use 1 MPI process per GPU
13 n_nodes=${SLURM_JOB_NUM_NODES}
14 let n_procs=n_nodes*gpus_per_node
15
16 procs_per_socket=$(( gpus_per_node / sockets_per_node ))
17 cores_per_proc=$(( cores_per_socket / procs_per_socket ))
18
19 # set OpenMP thread affinity
20 export OMP_NUM_THREADS=${cores_per_proc} OMP_PROC_BIND=true
21
22 # UCX tuning
23 export UCX_TLS=rc,cuda # select protocol
24 export UCX_CUDA_IPC_ENABLE_MNNVL=y # enable multi-node NVL
25 export UCX_IB_AR_ENABLE=y # enable adaptive routing
26 export UCX_IB_SL=1 # enable adaptive routing
27
28 # Open MPI tuning
29 export OMPI_MCA_pml=ucx # use UCX for point-to-point
30 export OMPI_MCA_coll_ucc_enable=1 # enable UCC component
31 export OMPI_MCA_coll_ucc_priority=100 # enable UCC component
32
33 # OSU command line
34 units=1000000 # 1 MB
35 min_msg_size_B=$(( 1 * units ))
36 max_msg_size_B=$(( 2048 * units ))
37
38 srun --nodes ${n_nodes} --ntasks ${n_procs} --ntasks-per-node ${gpus_per_node} \
39 -c ${cores_per_proc} --cpu-bind=cores --mpi=pmix \
40 proc_launch.sh osu_alltoall -i 100 -x 10 -d cuda_fabric \
41 -m ${min_msg_size_B}:${max_msg_size_B}
An example SLURM batch script for the one MPI process per GPU scenario is shown in Listing 1. The script launches the OSU all-to-all benchmark. This benchmark can be used to evaluate performance improvements obtained by changing Open MPI, UCX, and UCC tuning parameters.
The script first calculates the number of MPI processes for the run
by multiplying the number of assigned nodes, as reported by SLURM, by the
number of GPUs per-node (line 14). The number of processes to assign to each CPU
is two and is determined by the number of processes per-node divided by the
number of sockets per-node (line 16). The number of physical cores to assign
to each process is thirty six, which is determined by taking the number of cores
per CPU, divided by the number of processes assigned to the socket
(line 17). If OpenMP is used for multi-threading it must be informed of the
settings by environment variables (line 20). The process and thread affinity
values are combined and passed to srun on the command line (lines 38-39).
Refer to SLURM multi-core support
for more information about assigning process and thread affinity when using srun.
The UCX tuning parameters that are used to restrict the transport protocol, enable multi-node NVLink, and enable adaptive routing are specified by environment variable (lines 23-26). Similarly, the MPI tuning parameters that are used to enable UCX and UCC are specified by environment variables (line 29-31). Refer to UCX and UCC for more information about tuning UCX and UCC. Open MPI’s tuning parameters are discussed below in Tuning Open MPI
The benchmark is started using a launch script called proc_launch.sh (line 40).
The purpose of this script is to apply settings that need to be different for
each process, for example setting GPU and network adaptor affinity.
1 #!/bin/bash
2
3 if [ -n "${SLURM_PROCID}" ]
4 then
5 rank=${SLURM_PROCID}
6 local_rank=${SLURM_LOCALID}
7 else
8 echo "ERROR: failed to determine local rank!"
9 exit -1
10 fi
11
12 # map GPU to compute network fabric
13 nics=( mlx5_0:1 mlx5_1:1 mlx5_4:1 mlx5_5:1 )
14 gpus=( 0 1 2 3 )
15
16 export CUDA_VISIBLE_DEVICES=${gpus[${local_rank}]}
17 export UCX_NET_DEVICES=${nics[${local_rank}]}
18
19 $*
Listing 2 shows the per-process launch script that is used to
configure settings that need to be different for each process. When the script
is run, SLURM’s srun process launcher provides environment variables that
identify the process’s local and global rank in the run. These environment
variables are used to assign the process a GPU and InfiniBand adaptor on the
system’s compute fabric. Other settings that should vary between processes can also
be made here. This example uses the SLURM srun environment variables SLURM_PROCID and
SLURM_LOCALID (lines 5-6) to determine the process’s MPI global and node
local rank. Other MPI process launchers, such as Open MPI’s mpirun, provide
this information through variables with different names.
The per-node device mapping that contains the GPU to network adaptor affinity
is used (lines 13-14). The node local rank provided by the srun process launcher (line 6)
is used to assign this process a unique GPU using the CUDA_VISIBLE_DEVICES
environment variable (line 16). The specific compute fabric network adaptor
associated with the selected GPU is assigned (line 17).
Command-line arguments are forwarded to the application as it
is launched (line 19).
1 // initialize the CUDA driver and assign a GPU
2 void initCuda()
3 {
4 int numDev = 0;
5 const char *localRankStr = nullptr;
6
7 if ((localRankStr = getenv("SLURM_LOCALID")) &&
8 (cudaSuccess == cudaGetDeviceCount(&numDev)) &&
9 (numDev > 0))
10 {
11 int localRank = atoi(localRankStr);
12 cudaSetDevice( localRank % numDev );
13 }
14 }
15
16 int main(int argc, char **argv)
17 {
18 // initialize the CUDA driver and assign a GPU
19 initCuda();
20
21 // initialize MPI
22 int provided = 0;
23 MPI_Init_thread(&argc, &argv, MPI_THREAD_MULTIPLE, &provided);
24
25 // the rest of the application code goes here ...
26
27 return 0;
28 }
Applications should initialize the CUDA driver before initializing MPI. This
ensures that all CUDA-related features in UCC and UCX are activated and used.
Assigning a GPU by using the CUDA_VISIBLE_DEVICES environment variable before
launching the application, as shown in Listing 3, is the best
practice. The function in Listing 3 illustrates how to
initialize the CUDA driver and assign a GPU. The function is compatible with
the CUDA_VISIBLE_DEVICES environment variable and will assign the
available GPUs to the processes on the node using a round-robin strategy when
the CUDA_VISIBLE_DEVICES environment variable is not set.
This function should be called before initializing MPI. This example makes use
of the SLURM srun-specific environment variable SLURM_LOCALID to determine the process’s MPI
rank before MPI is initialized. Other MPI process launchers,
such as Open MPI’s mpirun, provide this information through a variable with
a different name.
Coordinating Access with the Multi-Process Service#
In some applications, one process is not capable of saturating the GPU. In these cases, it can be beneficial to provide multiple processes simultaneous access to the same GPU. However, the driver is designed to isolate processes from each other. This prevents concurrent access to the same GPU, even when the processes are part of the same parallel application. The NVIDIA Multi-Process Service (MPS) enables several processes in an MPI job to concurrently access the same GPU reducing or eliminating the associated overheads such as context switching. To use MPS, the MPS daemon needs to be started on each node before the application starts. This is typically handled by a per-process launch script, as shown in Listing 4.
1 #!/bin/bash
2
3 if [ -n "${SLURM_PROCID}" ]
4 then
5 rank=${SLURM_PROCID}
6 local_rank=${SLURM_LOCALID}
7 else
8 echo "ERROR: failed to determine local rank!"
9 exit -1
10 fi
11
12 # map GPU to compute network fabric
13 nics=( mlx5_0:1 mlx5_1:1 mlx5_4:1 mlx5_5:1 )
14 gpus=( 0 1 2 3 )
15
16 export CUDA_VISIBLE_DEVICES=${gpus[${local_rank}]}
17 export UCX_NET_DEVICES=${nics[${local_rank}]}
18
19 # start the MPS daemon on each node
20 if [[ ${local_rank} -eq 0 ]]
21 then
22 nvidia-cuda-mps-control -d
23 fi
24
25 $*
This script is similar to the script shown in Listing 2.
The script is used passed to srun along with the executable to run and all its command-
line arguments. The SLURM_LOCALID
environment variable provides the processes rank on the node. This is used to set the
process’s GPU affinity (line 16), network adaptor affinity (line 17), and to filter processes such that only one
process per node starts the MPS daemon (line 20). The MPS daemon is launched
(line 22) before the application is started (line 25). Refer to Listing 1
for an example of how the script is called.
Refer to MPS documentation for more information about MPS.
Tuning Open MPI#
This section describes Open MPI’s tuning mechanisms. When tuning MPI applications there are several factors to consider including the scale at which the application is run, the amount of data being moved, the application’s internal organization, and the specific communication bottlenecks. Successful tuning will require careful measurement and profiling of the application using tools such as NVIDIA NSight Systems and the OSU Micro Benchmarks.
How Tuning Works in Open MPI#
Open MPI supports tuning by swapping purpose specific modular components at run time as well as tuning within the selected components. Multiple components implementing collective and point-to-point operations are provided. The individual components contain implementations of different algorithms as well as hardware accelerated optimizations. During the communicator construction phase the Open MPI runtime queries the available components for a self-assigned a priority. Priorities are based on several runtime factors such as the size of the process group and/or the hardware features available. The runtime then selects the component with the highest priority for use. The components additionally expose detailed tuning parameters which can be set through environment variables, command line arguments, and configuration files.
Open MPI organizes components into frameworks. Frameworks are collections of
components that implement the part of the internal system and hence the same
APIs. Examples of frameworks include pml, the point-to-point messaging
layer and coll which handles the implementation of collective operations.
When setting tuning parameters the name of the framework and component are
specified along with tuning parameter name and its intended value. For example
to set the priority of the point-to-point messaging layer’s ucx component
to one hundred.
mpirun --mca pml_ucx_priority 100 ...
MCA variables can be also be set using environment variables of the same
name prefixed with OMPI_MCA_. For example, OMPI_MCA_pml_ucx_priority
can be used to set the pml ucx priority. When using the SLURM process
launcher srun, environment variables must be used.
Discovering Tuning Parameters#
To show the complete list of tuning parameters along with their descriptions, use the
ompi_info command.
$ ompi_info --all | less
The output of this command is piped into a pager (here less) because it fills
many screens worth of output. For the GB200 Oberon system, focus on the ucx
component in the pml framework when tuning point-to-point operations, and
the ucc, hcoll, and tuned components in the coll framework when
tuning collective operations.
To display the list of tuning parameters exposed to Open MPI for a component, use the ompi_info command with its --param option.
For example, the following command illustrates how to display the tuning
parameters exposed by the ucc component
$ ompi_info --param coll ucc --level 9
Note that the ucc and ucx components provide several environment
variables for tuning that are not exposed through Open MPI MCA variables.
Therefor, the ucx and ucc components will often need to be tuned using
these implementation specific environment variables rather than Open MPI’s
tuning infrastructure. More information can be found in UCX and UCC.
In addition to ucc, hcoll it’s predecessor, has CUDA-aware
implementations of Allreduce, Bcast, and Allgather. Open MPI’s tuned
component has high-quality non CUDA-aware implementations that none the less
deliver high performance on NVIDIA systems when paired with a CUDA-aware point-to-point
framework component such as ucx. The coll tuned component implements
multiple algorithms for many of MPI’s collective operations. Several of these
algorithms expose detailed tuning parameters. The tuned component also
provides a file based tuning mechanism that supports tuning each collective
operation for several communicator and message sizes using a table of rules
stored in an ASCII text file.
For more information on the collectives and algorithms implemented by the coll tuned component,
their associated tuning parameters, and for details of the tuning file format see the
MPI User’s Guide
Tuning Point-to-Point Operations#
Open MPI’s ucx component should be used for point-to-point operations on
NVIDIA systems. The ucx component has built-in tuning heuristics based on
runtime conditions such as message size and whether the data to be moved
is allocated on device or host memory. Refer to UCX for more
information about tuning UCX.
Tuning Collective Communication#
In this section an illustrative example of tuning a collective operation is shown. The example runs the OSU all-to-all benchmark which reports the average time per all-to-all on a sweep over per-process message sizes. See the OSU benchmark site for more information on the benchmark code.
1 #!/bin/bash
2
3 source ~/luster_fsw/installs/modulefiles/cuda-12.8.sh
4 source ~/luster_fsw/installs/modulefiles/hpcx-v2.22.sh
5 source ~/luster_fsw/installs/modulefiles/omb-7.3.sh
6
7 # GB200 Oberon Node Specs
8 gpus_per_node=4
9 cores_per_socket=72
10 sockets_per_node=2
11
12 # use 1 MPI process per GPU
13 n_nodes=${SLURM_JOB_NUM_NODES}
14 let n_procs=n_nodes*gpus_per_node
15
16 procs_per_socket=$(( gpus_per_node / sockets_per_node ))
17 cores_per_proc=$(( cores_per_socket / procs_per_socket ))
18
19 # set OpenMP thread affinity
20 export OMP_NUM_THREADS=${cores_per_proc} OMP_PROC_BIND=true
21
22 # UCX tuning
23 export UCX_TLS=rc,cuda # select UCX protocol
24 export UCX_CUDA_IPC_ENABLE_MNNVL=y # enable multi-node NVL
25 export UCX_IB_AR_ENABLE=y # enable adaptive routing
26 export UCX_IB_SL=1 # enable adaptive routing
27
28 # Open MPI tuning
29 export OMPI_MCA_pml=ucx # use UCX for point-to-point
30 export OMPI_MCA_coll_ucc_priority=0 # disable UCC component
31 export OMPI_MCA_coll_tuned_priority=100 # enable tuned component
32 export OMPI_MCA_coll_tuned_use_dynamic_rules=1 # enable runtime tuning in tuned comp
33 export OMPI_MCA_coll_tuned_alltoall_algorithm=4 # select the linear sync algorithm
34
35 # OSU command line
36 units=1000000 # 1 MB
37 min_msg_size_B=$(( 1 * units ))
38 max_msg_size_B=$(( 2048 * units ))
39
40 # sweep varying the number of requests
41 for n_reqs in 0 1 2 4 8 16
42 do
43
44 if [ ${n_reqs} -ge ${n_procs} ]
45 then
46 break
47 fi
48
49 # tune the linear sync number of requests
50 export OMPI_MCA_coll_tuned_alltoall_algorithm_max_requests=${n_reqs}
51
52 srun --nodes ${n_nodes} --ntasks ${n_procs} --ntasks-per-node ${gpus_per_node} \
53 -c ${cores_per_proc} --cpu-bind=cores --mpi=pmix \
54 proc_launch.sh osu_alltoall -i 100 -x 10 -d cuda_fabric \
55 -m ${min_msg_size_B}:${max_msg_size_B}
56
57 done
The all-to-all tuning script is shown in Listing 5. The example
starts by setting process and thread affinity as well as UCX transport selection,
enabling multi-node NVLink, and enabling adaptive routing.
The script then selects Open MPI’s
tuned component (line 31). The tuned component’s linear sync
all-to-all algorithm is selected (line 32) and run time tuning is enabled (line 33).
A loop (line 41) evaluates several
vales of the algorithm’s max_requests tuning parameter (line 50).
The max_requests parameter controls the number of concurrently
communicating pairs of processes.
- A max_requests of 1 fully serializes the
exchanges mimicking an implementation commonly known as “pairwise” exchange.
- A setting equal to the number of processes floods the system with
all exchanges concurrently, mimicking a strategy commonly known as “fan out” exchange.
- A setting of 0 is used as a proxy for the number of processes.
Finding the best value of max_requests can improve the performance of this
algorithm. The best value depends on the per-process message size as well as
which fabric (MNNVL or InfiniBand) is being used.
The average time per all-to-all as reported in the benchmark output can be used
to compare different tunings.