Layer-wise distributed optimizer#
This document introduces a new type of distributed optimizer designed for preconditioner based optimizers like Muon.
Element-wise distributed optimizer#
In traditional Data Parallelism, every GPU keeps a full copy of the optimizer states and weights. An element-wise distributed optimizer breaks this redundancy by:
Partitioning states: Instead of every GPU storing everything, the optimizer states are evenly sliced up across all available GPUs.
Reduce-Scatter gradient: A reduce-scatter is performed over all gradients and each GPU gets portion of gradients corresponding to the parameters it “owns”.
Local Updates: Each GPU only updates the specific portion of the model parameters it “owns.”
All-Gather parameters: After the update, GPUs communicate to ensure everyone has the updated version of the full model for the next forward pass.
A more advanced version breaks down operations and overlaps communication with computations, e.g. the Megatron-Core version.
Emerging optimizers#
There are many emerging optimizers that require gradient of the entire layer to calculate update to each individual weight. For example, the popular Muon optimizer does:

If weights and optimizer states are evenly distributed among DP ranks, update can’t be calculated based on the data available on each GPU. Additional communication will be needed to collect data for calculating the full update.
Layer-wise sharding#
In a layer-wise distributed optimizer, parameters of different layers are distributed to different DP ranks. Each GPU has full layers worth of parameters so that preconditioner can be calculated.
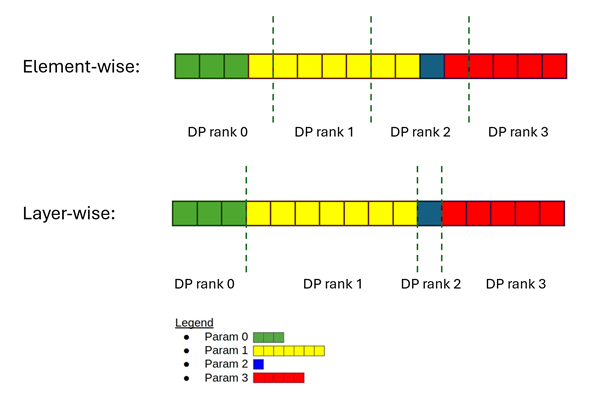
One change comes with layer-wise is variable size communication, e.g. each GPU now needs to collect different size of updated parameters from different GPUs, aka all_gatherv. The full Megatron-Core integration can be found in layer_wise_optimizer.py.
There are further optimizations possible for the layer-wise distributed optimizers as well as different parallel strategy for preconditioner based optimizer in general. They’ll be introduced in future documents.
Toy example#
Here is an example demonstrating the layer-wise sharding idea.
# torchrun --nproc-per-node 4 example.py
import torch
from torch import nn
class DummyModel(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.ModuleList([
nn.Linear(16, 32, bias=False),
nn.Linear(32, 64, bias=False),
nn.Linear(64, 128, bias=False),
nn.Linear(128, 256, bias=False),
])
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
def main():
model = DummyModel().cuda()
# Assign dummy gradients
for param in model.parameters():
param.grad = torch.randn_like(param)
# Variable size reduce-scatter is difficult, use all-reduce to reduce gradient to all ranks
# regardless whether the rank owns the parameter
all_gather_buffer = []
for param in model.parameters():
torch.distributed.all_reduce(param.grad, op=torch.distributed.ReduceOp.AVG)
all_gather_buffer.append(torch.empty_like(param))
# Mimic local update
rank = torch.distributed.get_rank()
model.layers[rank].weight.data += model.layers[rank].weight.grad * 0.01
# All-gatherv parameters to all ranks
torch.distributed.all_gather(all_gather_buffer, model.layers[rank].weight.data)
if __name__ == "__main__":
torch.distributed.init_process_group(backend="nccl")
assert torch.distributed.get_world_size() == 4, "This toy example only works on 4 ranks"
torch.cuda.set_device(torch.distributed.get_rank())
main()
torch.distributed.destroy_process_group()
Try it today#
Kimi-K2 recipe with Muon support is now available in NeMo Megatron-bridge, kimi_k2.py