RDMA over Converged Ethernet (RoCE)
Remote Direct Memory Access (RDMA) is the remote memory management capability that allows server-to-server data movement directly between application memory without any CPU
involvement. RDMA over Converged Ethernet (RoCE) is a mechanism to provide this efficient data transfer with very low latencies on lossless Ethernet networks. With advances in data center convergence over reliable Ethernet, ConnectX® Ethernet adapter cards family with RoCE uses the proven and efficient RDMA transport to provide the platform for deploying RDMA technology in mainstream data center application at 10GigE and 40GigE link-speed. ConnectX® Ethernet adapter cards family with its hardware offload support takes advantage of this efficient RDMA transport (InfiniBand) services over Ethernet to deliver ultra-low latency for performance-critical and transaction-intensive applications such as financial, database, storage, and content delivery networks.
When working with RDMA applications over Ethernet link layer the following points should be noted:
The presence of a Subnet Manager (SM) is not required in the fabric. Thus, operations that require communication with the SM are managed in a different way in RoCE. This does not affect the API but only the actions such as joining the multicast group, that need to be taken when using the API
Since LID is a layer 2 attribute of the InfiniBand protocol stack, it is not set for a port and is displayed as zero when querying the port
With RoCE, the alternate path is not set for RC QP. Therefore, APM (another type of High Availability and part of the InfiniBand protocol) is not supported
Since the SM is not present, querying a path is impossible. Therefore, the path record structure must be filled with relevant values before establishing a connection. Hence, it is recommended working with RDMA-CM to establish a connection as it takes care of filling the path record structure
VLAN tagged Ethernet frames carry a 3-bit priority field. The value of this field is derived from the IB SL field by taking the 3 least significant bits of the SL field
RoCE traffic is not shown in the associated Ethernet device's counters since it is offloaded by the hardware and does not go through Ethernet network driver. RoCE traffic is counted in the same place where InfiniBand traffic is counted; /sys/class/infiniband/<device>/ports/<port number>/counters/
RoCE encapsulates IB transport in one of the following Ethernet packets:
RoCEv1 - dedicated ether type (0x8915)
RoCEv2 - UDP and dedicated UDP port (4791)
RoCEv1 and RoCEv2 Protocol Stack
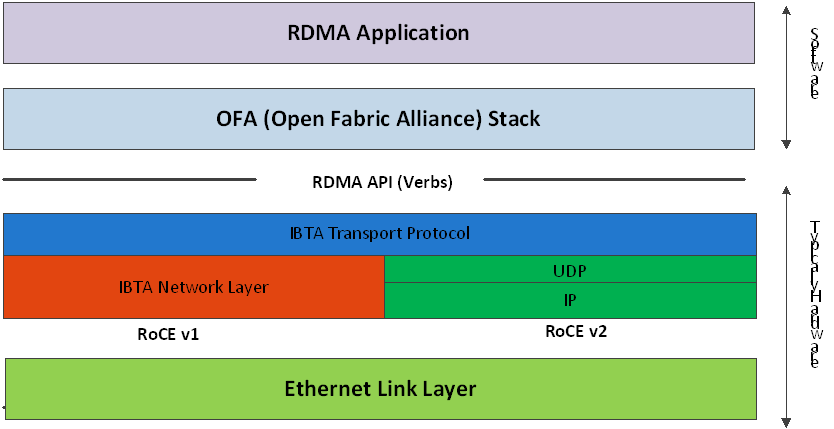
RoCEv1
RoCE v1 protocol is defined as RDMA over Ethernet header (as shown in the figure above). It uses ethertype 0x8915 and can be used with or without the VLAN tag. The regular Ethernet MTU applies on the RoCE frame.
RoCEv2
RoCE v2 is supported on ConnectX®-3 Pro and above adapter cards.
A straightforward extension of the RoCE protocol enables traffic to operate in IP layer 3 environments. This capability is obtained via a simple modification of the RoCE packet format. Instead of the GRH used in RoCE, IP routable RoCE packets carry an IP header which allows traversal of IP L3 Routers and a UDP header (RoCEv2 only) that serves as a stateless encapsulation layer for the RDMA Transport Protocol Packets over IP.
The proposed RoCEv2 packets use a well-known UDP destination port value that unequivocally distinguishes the datagram. Similar to other protocols that use UDP encapsulation, the UDP source port field is used to carry an opaque flow-identifier that allows network devices to implement packet forwarding optimizations (e.g. ECMP) while staying agnostic to the specifics of the protocol header format.
Furthermore, since this change exclusively affects the packet format on the wire, and due to the fact that with RDMA semantics packets are generated and consumed below the AP, applications can seamlessly operate over any form of RDMA service, in a completely transparent way.
RoCE Modes Parameters
While ConnectX®-3 supports only RoCEv1, ConnectX®-3 Pro supports both RoCEv1 and RoCEv2. The RoCE mode can be set using the 'roce_mode' parameter in the /etc/modprobe.d/mlx4_core.conf file.
The following are the possible RoCE mode values:
If set to '0', the driver associates all GID indexes to RoCEv1
If set to '2', the driver associates all GID indexes to RoCEv2 (supported in ConnectX-3 Pro as of firmware v2.32.5100)
If set to '4', the driver associates all GID indexes to RoCEv1 and RoCEv2, a single entry for each RoCE version (supported in ConnectX-3 Pro as of firmware v2.34.5000)
RoCE mode values example in ConnectX-3 Pro:
options mlx4_core roce_mode=2
ConnectX®-4 supports both RoCEv1 and RoCEv2. By default, the driver associates all GID indexes to RoCEv1 and RoCEv2, thus, a single entry for each RoCE version.
For further information, please refer to HowTo Configure RoCEv2 Community post.
GID table entries are created whenever an IP address is configured on one of the Ethernet devices of the NIC's ports. Each entry in the GID table for RoCE ports has the following fields:
GID value
GID type
Network device
For ports on devices that support two RoCE modes (ConnectX®3 Pro), the table will be occupied with two GIDs, both with the same GID value but with different types. The network device in an entry is the Ethernet device with the IP address that GID is associated with. The GID format can be of 2 types; IPv4 and IPv6. IPv4 GID is an IPv4-mapped IPv6 address, while IPv6 GID is the IPv6 address itself. Layer 3 header for packets associated with IPv4 GIDs will be IPv4 (for RoCEv2) and IPv6/GRH for packets associated with IPv6 GIDs and IPv4 GIDs for RoCEv1.
The number of entries in the GID table is equal to N1,2(K+1), where N is the number of IP addresses that are assigned to all network devices associated with the port, including VLAN devices, alias devices and bonding masters (for active slaves only). Link-local IPv6 addresses are excluded from this count since the GID for them is always pre-set (the default GIDs) at the beginning of each table. K is the number of supported RoCE types. Since the number of entries in the hardware is limited to 128 for each port, it is important to understand the limitations on N. MLNX_OFED provides a script called show_gids to view the GID table conveniently.
When the mode of the device is RoCEv1/RoCEv2, each entry in the GID table occupies 2 entries in the hardware. In other modes, each entry in the GID table occupies a single entry in the hardware.
In a multifunction configuration, the PF gets 16 entries in the hardware while each VF gets 112/F where F is the number of virtual functions on the port. If 112/F is not an integer, some functions will have 1 less entry than others. Note that when F is larger than 56, some VFs will get only one entry in the GID table.
RoCEv1(Layer2) Compatibility
This feature is not supported in MLNX_OFED v4.0.
For a node running MLNX_OFED to connect to a node running RoCE with Layer 2 GID format (RoCE v1), it is required to work in RoCE v1 compatibility mode.
In order to enable compatibility:
Change default value of the ib_core module parameter "roce_v1_noncompat_gid" to "no".
Restart the driver.
Run the compat_gid_gen script for configuration of the GID table:
compat_gid_gen <-d netdev> \[-v|V vlan\] \[-D\] \[-n\]
where:
<netdev>: The network device that is associated with the port or a bonding master of such device.
<vlan>: VLAN ID of the remote interface. Note that the local interface (netdev) does not have to be a VLAN interface if the machine is virtual and tagging is done in the hypervisor (VST).
<-n>: Running the script with -n switch will only print the commands for configuration but will not execute them.
The GID will be displayed in the GID table in following format:
ip\[0..7\] = fe80000000000000
ip\[8\] = mac\[0\] ^ 2 ip\[9\] = mac\[1\]
ip\[10\] = mac\[2\] ip\[11\] = ff ip\[12\] = fe ip\[13\] = mac\[3\]
ip\[14\] = mac\[4\]
ip\[15\] = mac\[5\]
Note: If the script is used with the -v/-V option, the GID will be displayed in the GID table in fol- lowing format:
ip\[0..7\] = fe80000000000000
ip\[8\] = mac\[0\] ^ 2 ip\[9\] = mac\[1\]
ip\[10\] = mac\[2\]
ip\[11\] = VLAN ID high byte (4 MS bits). ip\[12\] = VLAN ID low byte
ip\[13\] = mac\[3\]
ip\[14\] = mac\[4\]
ip\[15\] = mac\[5\]
The configuration is non-persistent, but can be made persistent by editing the network configuration files and adding the proper addresses to them.
GID Table in sysfs
GID table is exposed to userspace via sysfs
GID values can be read from:
/sys/
class/infiniband/{device}/ports/{port}/gids/{index}
GID type can be read from:
/sys/
class/infiniband/{device}/ports/{port}/gid_attrs/types/{index}
GID net_device can be read from:
/sys/
class/infiniband/{device}/ports/{port}/gid_attrs/ndevs/{index}
Setting the RoCE Mode for a Queue Pair (QP)
Setting RoCE mode for devices that support two RoCE modes is different for RC/UC QPs (connected QP types) and UD QP.
To modify an RC/UC QP (connected QP) from INIT to RTR, an Address Vector (AV) must be given. The AV, among other attributes, should specify the index of the port's GID table for the source GID of the QP. The GID type in that index will be used to set the RoCE type of the QP.
To modify UD QPs, the value of the mlx4_core module parameter 'ud_gid_type' must be used to set the RoCE mode for all UD QPs on the device. The allowed values are:
|
RoCE Mode |
Allowed Value |
|
RoCE v1 |
0 (Default) |
|
RoCE v2 |
2 |
Setting RoCE Mode of RDMA_CM Applications
RDMA_CM interface requires only the active side of the peer to pass the IP address of the passive side. The RDMA_CM decides upon the source GID to be used and obtains it from the GID table. Since more than one instance of the GID value is possible, the lookup should be also according to the GID type. The type to use for the lookup is defined as a global value of the
RDMA_CM module. Changing the value of the GID type for the GID table lookups is done using the cma_roce_mode script.
To print the current RoCE mode for a device port:
cma_roce_mode -d <dev> -p <port>
To set the RoCE mode for a device port:
cma_roce_mode -d <dev> -p <port> -m <1|2>
GID Table Example
The following is an example of the GID table.
|
DEV |
PORT |
INDEX |
GID |
IPv4 |
Type |
Netdev |
|
mlx4_0 |
1 |
0 |
fe80:0000:0000:0000:0202:c9ff:feb6:7c70 |
RoCE V2 |
eth1 |
|
|
mlx4_0 |
1 |
1 |
fe80:0000:0000:0000:0202:c9ff:feb6:7c70 |
RoCE V1 |
eth1 |
|
|
mlx4_0 |
1 |
2 |
0000:0000:0000:0000:0000:ffff:c0a8:0146 |
192.168.1.70 |
RoCE V2 |
eth1 |
|
mlx4_0 |
1 |
3 |
0000:0000:0000:0000:0000:ffff:c0a8:0146 |
192.168.1.70 |
RoCE V1 |
eth1 |
|
mlx4_0 |
1 |
4 |
0000:0000:0000:0000:0000:ffff:c1a8:0146 |
193.168.1.70 |
RoCE V2 |
eth1.100 |
|
mlx4_0 |
1 |
5 |
0000:0000:0000:0000:0000:ffff:c1a8:0146 |
193.168.1.70 |
RoCE V1 |
eth1.100 |
|
mlx4_0 |
1 |
6 |
1234:0000:0000:0000:0000:0000:0000:0070 |
RoCE V2 |
eth1 |
|
|
mlx4_0 |
1 |
7 |
1234:0000:0000:0000:0000:0000:0000:0070 |
RoCE V1 |
eth1 |
|
|
mlx4_0 |
2 |
0 |
fe80:0000:0000:0000:0202:c9ff:feb6:7c71 |
RoCE V2 |
eth2 |
|
|
mlx4_0 |
2 |
1 |
fe80:0000:0000:0000:0202:c9ff:feb6:7c71 |
RoCE V1 |
eth2 |
where:
Entries on port 1 index 0/1 are the default GIDs, one for each supported RoCE type
Entries on port 1 index 2/3 belong to IP address 192.168.1.70 on eth1.
Entries on port 1 index 4/5 belong to IP address 193.168.1.70 on eth1.100.
Packets from a QP that is associated with these GID indexes will have a VLAN header (VID=100)
Entries on port 1 index 6/7 are IPv6 GID. Packets from a QP that is associated with these GID indexes will have an IPv6 header
In order to function reliably, RoCE requires a form of flow control. While it is possible to use global flow control, this is normally undesirable, for performance reasons.
The normal and optimal way to use RoCE is to use Priority Flow Control (PFC). To use PFC, it must be enabled on all endpoints and switches in the flow path.
For further information, please refer to RoCE Over L2 Network Enabled with PFC User Guide:
Prerequisites
The following are the driver's prerequisites in order to set or configure RoCE:
ConnectX®-3 firmware version 2.32.5000 or higher
ConnectX®-3 Pro firmware version 2.32.5000 or higher
For OEM adapters, the required firmware version is 2.11.1250
All InfiniBand verbs applications which run over InfiniBand verbs should work on RoCE links if they use GRH headers.
Set HCA to use Ethernet protocol:
Display the Device Manager and expand "System Devices". Please refer to ConnectX-3/ConnectX-3 Pro Port Type Management section.
Configuring SwitchX® Based Switch System
To enable RoCE, the SwitchX should be configured as follows:
Ports facing the host should be configured as access ports, and either use global pause or Port Control Protocol (PCP) for priority flow control
Ports facing the network should be configured as trunk ports, and use Port Control Protocol (PCP) for priority flow control
For further information on how to configure SwitchX, please refer to SwitchX User Manual.
Configuring DAPL over RoCE
The default dat.conf file that contains entries for the DAPL devices does not contain entries for the DAPL over RDMA_CM over RoCE devices.
To add the missing entries:
Run the ibdev2netdev utility to see all the associations between the Ethernet devices and the IB devices/ports.
Add a new entry line according to the format below to the dat.conf file for each output line of the ibdev2netdev utility.
<IA Name> u2.0 nonthreadsafe default libdaplofa.so.2 dapl.2.0 "<ethX> <port>" ""Parameter
Description
Example
<IA Name>
The device's IA name. The name must be unique.
ofa-v2-ethx
<ethX>
The associated Ethernet device used by RoCE.
eth3
<port>
The port number.
1
The following is an example of the ibdev2netdev utility's output and the entries added per output line:
sw419:~ # ibdev2netdev mlx4_0 port
2<===> eth2 mlx4_0 port1<===> eth3 ofa-v2-eth2 u2.0nonthreadsafedefaultlibdaplofa.so.2dapl.2.0"eth2 2"""ofa-v2-eth3 u2.0nonthreadsafedefaultlibdaplofa.so.2dapl.2.0"eth3 1"""
The next section provides information on how to use InfiniBand over Ethernet (RoCE).
To install and load the driver:
Install MLNX_OFED (See Installation section for further details).
RoCE is installed as part of mlx4 and mlx4_en and other modules upon driver's installation.WarningThe list of the modules that will be loaded automatically upon boot can be found in the configuration file /etc/infiniband/openib.conf.
Query for the device's information. Example:
ofed_info -s MLNX_OFED_LINUX-
3.2-1.0.0:Display the existing MLNX_OFED version.
ibv_devinfo hca_id: mlx5_0 transport: InfiniBand (
0) fw_ver:10.14.0114node_guid: f452:1403:0035:9050sys_image_guid: f452:1403:0035:9050vendor_id:0x02c9vendor_part_id:4113hw_ver:0x0board_id: MT_1240110019 phys_port_cnt:2Device ports: port:1state: PORT_ACTIVE (4) max_mtu:4096(5) active_mtu:4096(5) sm_lid:1port_lid:1port_lmc:0x00link_layer: InfiniBand port:2state: PORT_INIT (2) max_mtu4096(5) active_mtu:4096(5) sm_lid:0port_lid:65535port_lmc:0x00link_layer: InfiniBand
Output Notes:
|
The ports' states are:
|
The port state can also be obtained by running the following commands: # cat /sys/class/infiniband/mlx4_0/ports/ 1/state 2: INIT # cat /sys/class/infiniband/mlx4_0/ports/ 2/state 4: ACTIVE |
|
link_layer parameter shows that:
|
The link_layer of the two ports can also be obtained by running the following commands: # cat /sys/class/infiniband/mlx4_0/ports/ 1/link_layer InfiniBand # cat /sys/class/infiniband/mlx4_0/ports/ 2/link_layer Ethernet |
|
The fw_ver parameter shows that the firmware version is 2.31.5050. |
The firmware version can also be obtained by running the following commands: # cat /sys/class/infiniband/mlx4_0/fw_ver 2.31.5050 |
|
Although the InfiniBand over Ethernet's Port MTU is 2K byte at maximum, the actual MTU cannot exceed the mlx4_en interface's MTU. Since the mlx4_en interface's MTU is typically 1560, port 2 will run with MTU of 1K. Please note that RoCE's MTU is subject to InfiniBand MTU restrictions. The RoCE's MTU values are 256 byte, 512 byte, 1024 byte, and 2K. In general RoCE MTU is the largest power of 2 that is still lower than mlx4_en interface MTU. |
- |
Associating InfiniBand Ports to Ethernet Ports
Since both RoCE and mlx4_en use the Ethernet port of the adapter, one of the drivers must control the port state. In the example above, the mlx4_en driver controls the port's state. The mlx4_ib driver holds a reference to the mlx4_en net device for getting notifications about the state of the port, as well as using the mlx4_en driver to resolve IP addresses to MAC that are required for
address vector creation. However, RoCE traffic does not go through the mlx4_en driver, it is completely offloaded by the hardware.
# ibdev2netdev
mlx4_0 port 2 <===> eth2
mlx4_0 port 1 <===> ib0
#
Configuring an IP Address to the mlx4_en Interface
To configure an IP address to the mlx4_en interface:
Configure an IP address to the mlx4_en interface on both sides of the link.
# ifconfig eth2
20.4.3.220# ifconfig eth2 eth2 Link encap:Ethernet HWaddr00:02:C9:08:E8:11inet addr:20.4.3.220Bcast:20.255.255.255Mask:255.0.0.0UP BROADCAST MULTICAST MTU:1500Metric:1RX packets:0errors:0dropped:0overruns:0frame:0TX packets:0errors:0dropped:0overruns:0carrier:0collisions:0txqueuelen:1000RX bytes:0(0.0b) TX bytes:0(0.0b)Make sure that ping is working.
ping
20.4.3.219PING20.4.3.219(20.4.3.219)56(84) bytes of data.64bytes from20.4.3.219: icmp_seq=1ttl=64time=0.873ms64bytes from20.4.3.219: icmp_seq=2ttl=64time=0.198ms64bytes from20.4.3.219: icmp_seq=3ttl=64time=0.167ms20.4.3.219ping statistics —3packets transmitted,3received,0% packet loss, time 2000ms rtt min/avg/max/mdev =0.167/0.412/0.873/0.326ms
Adding VLANs
Make sure that the 8021.q module is loaded.
modprobe 8021q
Add VLAN.
# vconfig add eth2
7Added VLAN with VID ==7to IF -:eth2:- #Configure an IP address.
ifconfig eth2.
77.4.3.220
Defining Ethernet Priority (PCP in 802.1q Headers)
Define Ethernet priority on the server.
# ibv_rc_pingpong -g
1-i2-l4local address: LID0x0000, QPN0x1c004f, PSN0x9daf6c, GID fe80::202:c900:708:e799 remote address: LID0x0000, QPN0x1c004f, PSN0xb0a49b, GID fe80::202:c900:708:e8118192000bytes in0.01seconds =4840.89Mbit/sec1000iters in0.01seconds =13.54usec/iterDefine Ethernet priority on the client.
# ibv_rc_pingpong -g
1-i2-l4sw419 local address: LID0x0000, QPN0x1c004f, PSN0xb0a49b, GID fe80::202:c900:708:e811 remote address: LID0x0000, QPN0x1c004f, PSN0x9daf6c, GID fe80::202:c900:708:e7998192000bytes in0.01seconds =4855.96Mbit/sec1000iters in0.01seconds =13.50usec/iter
Using rdma_cm Tests
Use rdma_cm test on the server.
# ucmatose cmatose: starting server initiating data transfers completing sends receiving data transfers data transfers complete cmatose: disconnecting disconnected test complete
returnstatus0#Use rdma_cm test on the client.
# ucmatose -s
20.4.3.219cmatose: starting client cmatose: connecting receiving data transfers sending replies data transfers complete test completereturnstatus0#
This server-client run is without PCP or VLAN because the IP address used does not belong to a VLAN interface. If you specify a VLAN IP address, then the traffic should go over VLAN.
Overview
The TOS field for rdma_cm sockets can be set using the rdma_set_option() API, just as it is set for regular sockets. If a TOS is not set, the default value (0) is used. Within the rdma_cm kernel driver, the TOS field is converted into an SL field. The conversion formula is as follows:
SL = TOS >> 5 (e.g., take the 3 most significant bits of the TOS field)
In the hardware driver, the SL field is converted into PCP by the following formula:
PCP = SL & 7 (take the 3 least significant bits of the TOS field)
SL affects the PCP only when the traffic goes over tagged VLAN frames.
DSCP
A new entry has been added to the RDMA-CM configfs that allows users to select default TOS for RDMA-CM QPs. This is useful for users that want to control the TOS field without changing their code. Other applications that set the TOS explicitly using the rdma_set_option API will continue to work as expected to override the configfs value.
For further information about DSCP marking, refer to
HowTo
Set
Egress
ToS/DSCP
on
RDMA-
CM
QPs
Community post.
RoCE Link Aggregation (RoCE LAG) provides failover and link aggregation capabilities for mlx4 device physical ports. In this mode, only one IB port, that represents the two physical ports, is exposed to the application layer. Kernel 4.0 is a requirement for this feature to properly function.
Enabling RoCE Link Aggregation
To enter the Link Aggregation mode, a bonding master that enslaves the two net devices on the mlx4 ports is required. Then, the mlx4 device re-registers itself in the IB stack with a single port. If the requirement is not met, the device re-registers itself again with two ports.
For the device to enter the Link Aggregation mode, the following prerequisites must exist:
Exactly 2 slaves must be under the bonding master
The bonding master has to be in one of the following modes:
(1) active-backup mode
(2) static active-active mode
(4) dynamic active-active mode
Restarting the device when entering or leaving Link Aggregation mode, invalidates the open resources (QPs, MRs, etc.) on the device.
Link Aggregation in Active-Backup Mode
When the bonding master works in active-backup mode, RoCE packets are transmitted and received from the active port that the bonding master reports. The logic of failover is done solely in the bonding driver and the mlx4 driver only polls it.
Link Aggregation in Active-Active Mode
In this mode, RoCE packets are transmitted and received from both physical ports. While the mlx4 driver has no influence on the port on which packets are being received from, it can determine the port packets are transmitted to.
If user application does not set a preference, the mlx4 driver chooses a port in a round robin fashion when QP is modified from RESET to INIT. This is necessary because application sees only one port to use so it will always state port_num 1 in the QP attributes. With that, the theoretical bandwidth of the system will be kept as the sum of the two ports.
An application that prefers to send packets on the specific port for a specific QP should set flow_entropy when modifying a QP from RESET to INIT. Values for the flow_entropy parameter are interpreted by the mlx4 driver as a hint to associate the SQ of the QP to "1" while odd values associate the SQ with port 2.
The code example below shows how to set flow_entropy for a QP.
struct ibv_exp_qp_attr attr = {
.comp_mask = IBV_EXP_QP_ATTR_FLOW_ENTROPY,
.qp_state = IBV_QPS_INIT,
.pkey_index = 0,
.port_num = port,
.qp_access_flags = 0,
.flow_entropy = 1
};
if (ibv_exp_modify_qp(ctx->qp, &attr,
IBV_QP_STATE |
IBV_QP_PKEY_INDEX |
IBV_QP_PORT |
IBV_EXP_QP_FLOW_ENTROPY |
IBV_QP_ACCESS_FLAGS)) {
fprintf(stderr, "Failed to modify QP to INIT\n"); goto clean_qp;
}
Link Aggregation for Virtual Functions
When ConnectX®-3 Virtual Functions are present, High Availability behaves differently. Nonetheless, its configuration process remain the same and is performed in the Hypervisor. However, since the mlx4 device in the Hypervisor does not re-register, the two ports remain exposed to the upper layer. Therefore, entering the LAG mode does not invalidate the open resources although applications that run in the Hypervisor are still protected from a port failure.
When Virtual Functions are present and RoCE Link Aggregation is configured in the Hypervisor, a VM with an attached ConnectX-3 Virtual Function is protected from a Virtual Function port failure. For example, if the Virtual Function is bounded to port #1 and this port fails, the Virtual Function will be redirected to port #2. Once port #1 comes up, the Virtual Function is redirected back to port #1.
When the Hypervisor enters the LAG mode, it checks for the requirements below. If they are met, the Hypervisor enables High Availability also for the Virtual Functions.
The requirements are:
Only single port VFs are configured, on either port (See “Configuring SR-IOV for ConnectX-3/ConnectX-3 Pro”)
Flow steering is enabled (See “Enable/Disable Flow Steering”)
Total number of VFs is smaller than 64
RoCE LAG is a feature meant for mimicking Ethernet bonding for IB devices and is available for dual port cards only.
This feature is supported on the following operating systems:
RHEL 6.9
RHEL 7.2
RHEL 7.4
RHEL 7.5
SLES 15
RoCE LAG mode is entered when both Ethernet interfaces are configured as a bond in one of the following modes:
active-backup (mode 1)
balance-xor (mode 2)
802.3ad (LACP) (mode 4)
Any change of bonding configuration that negates one of the above rules (i.e, bonding mode is not 1, 2 or 4, or both Ethernet interfaces that belong to the same card are not the only slaves
of the bond interface), will result in exiting RoCE LAG mode and the return to normal IB device per port configuration.
Enabling RoCE LAG can be controlled using sysfs: /sys/bus/pci/drivers/mlx5_core/<bdf>/ roce_lag_enable (1 will enable RoCE LAG (default value) and 0 will disable it). However, note that enablement and disablement through sysfs is non-persistent after driver restart.
Once RoCE LAG is enabled, instead of having two IB devices; mlx5_0 and mlx5_1, there will be one device named mlx5_bond_0.
For information on how to configure RoCE LAG over ConnectX-4, ConnectX-4 Lx and ConnectX-5 HCAs, refer to HowTo Configure RoCE over LAG (ConnectX-4/ConnectX-5/ConnectX-6)Community post.
RoCE LAG ECMP
RoCE LAG ECMP enables entering RoCE LAG mode without bonding.
In RoCE LAG ECMP, unlike in regular RoCE LAG, the source MAC address for RoCE traffic is determined by the MAC address of the port that the QP is assigned to. Therefore, a QP that moves from one port to the other alters its source MAC address to that port’s address.
RoCE LAG ECMP mode is entered by writing the name of the parent device to sysfs:
echo ndev > /sys/class/net/eth1/device/roce_lag_ecmp_dev
The driver would treat ndev in the same manner the bond device is treated in non-ECMP RoCE LAG mode; its IP addresses and state will be used for the RoCE bond device.
To exit this mode, write an empty string to the sysfs entry:
echo '' > /sys/class/net/eth1/device/roce_lag_ecmp_dev
In this mode, the size of the GID table for the RoCE bond device becomes half its normal size, since the driver implicitly uses half of the table for duplicate entries with the MAC address of the second Ethernet port.
Soft RoCE is a software implementation that allows RoCE to run on any Ethernet network adapter whether it offers hardware acceleration or not. It leverages the same efficiency characteristics as RoCE, providing a complete RDMA stack implementation over any NIC.
Soft RoCE driver implements the InfiniBand RDMA transport over the Linux network stack. It enables a system with standard Ethernet adapter to inter-operate with hardware RoCE adapter or with another system running Soft-RoCE.
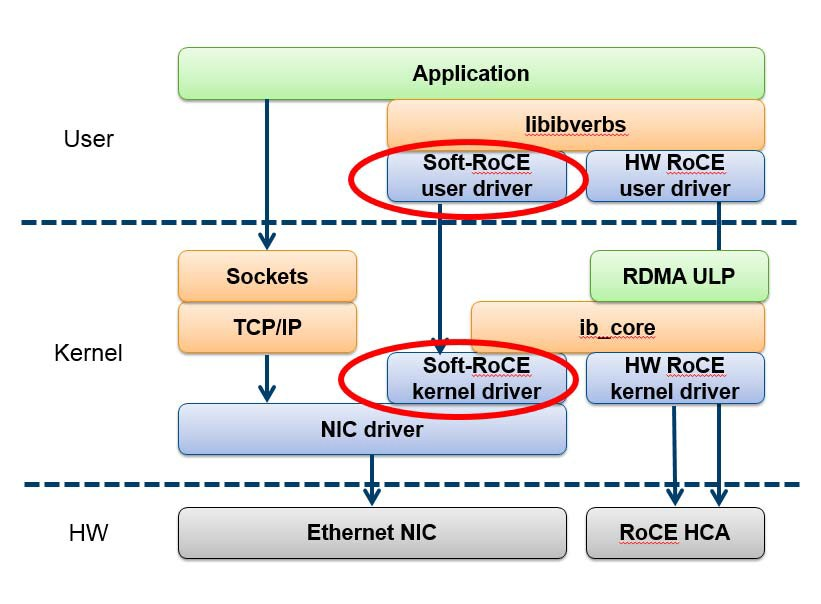
For details on how to configure Soft RoCE, refer to HowTo Configure Soft-RoCE Community post.
By default, RoCE is enabled on all mlx5 devices. When RoCE is enabled, all traffic to UDP port 4791 is treated as RoCE traffic by the device.
In case you are only interested in Ethernet (no RDMA) and wish to enable forwarding of traffic to this port, you can disable RoCE through sysfs:
echo <0|1> > /sys/devices/{pci-bus-address}/roce_enable
Once RoCE is disabled, only Ethernet traffic will be supported. Therefore, there will be no GID tables and only Raw Ethernet QPs will be supported.
The current RoCE state can be queried by sysfs:
cat /sys/devices/{pci-bus-address}/roce_enable
Enabling/Disabling RoCE on VFs (ConnectX-4)
By default, when configuring several VFs on the hypervisor, all VFs will be enabled with RoCE. This means that they require more OS memory comparing to Ethernet only VFs. In case you are only interested in Ethernet (no RDMA) on the VF, and you wish to save the hypervisor memory, you can disable RoCE on the VF from the hypervisor. By doing this, the VF will request less host memory from the hypervisor.
For details on how to enable/disable RoCE on a VF, refer to HowTo Enable/Disable RoCE on VFs Community post.
This feature enables setting a global traffic_class value for all RC QPs, or setting a specific traffic class based on several matching criteria.
Usage
To set a single global traffic class to be applied to all QPs, write the desired global traf- fic_class value to /sys/class/infiniband/<dev>/tc/<port>/traffic_class.
Note the following:Negative values indicate that the feature is disabled. traffic_class value can be set using ibv_modify_qp()
Valid values range between 0 - 255
The ToS field is 8 bits, while the DSCP field is 6 bits. To set a DSCP value of X, you need to multiply this value by 4 (SHIFT 2). For example, to set DSCP value of 24, set the ToS bit to 96 (24x4=96).
To set multiple traffic class values based on source and/or destination IPs, write the desired rule to /sys/class/infiniband/<dev>/tc/<port>/traffic_class. For example:
echo
"tclass=16,src_ip=1.1.1.2,dst_ip=1.1.1.0/24"> /sys/class/infiniband/mlx5_0/tc/1/ traffic_classNote: Adding "tclass" prefix to tclass value is optional.
In the example above, traffic class 16 will be set to any QP with source IP 1.1.1.2 and destination IP 1.1.1.0/24.
Note that when setting a specific traffic class, the following rule precedence will apply:
If a global traffic class value is set, it will be applied to all QPs
If no global traffic class value is set, and there is a rule with matching source and destina- tion IPs applicable to at least one QP, it will be applied
Rules only with matching source and/or destination IPs have no defined precedence over other rules with matching source and/or destination IPs
Notes:
A mask can be provided when using destination IPv4 addresses
The rule precedence is not affected by the order in which rules are inserted
Overlapping rules are entirely up to the administrator.
"tclass=-1" will remove the rule from the database
This feature enables setting a global TTL value for all RC QPs.
Write the desired TTL value to /sys/class/infiniband/<dev>/tc/<port>/ttl. Valid values range between 0 - 255