KServe Support on NIM Operator#
About KServe Support#
The NIM Operator supports both raw deployment and serverless deployment of NIM through KServe on Kubernetes clusters, including Red Hat OpenShift Container Platform.
NIM Operator with KServe provides two additional benefits:
Intelligent Caching with NIMCache to reduce initial inference time and autoscaling latency, resulting in faster and more responsive deployments.
NeMo Microservices support to evaluate, guardrail, and enhance AI systems across key metrics such as latency, accuracy, cost, and compliance.
The Operator configures KServe deployments using InferenceService to manage deployment, upgrade, ingress, and autoscaling of NIM.
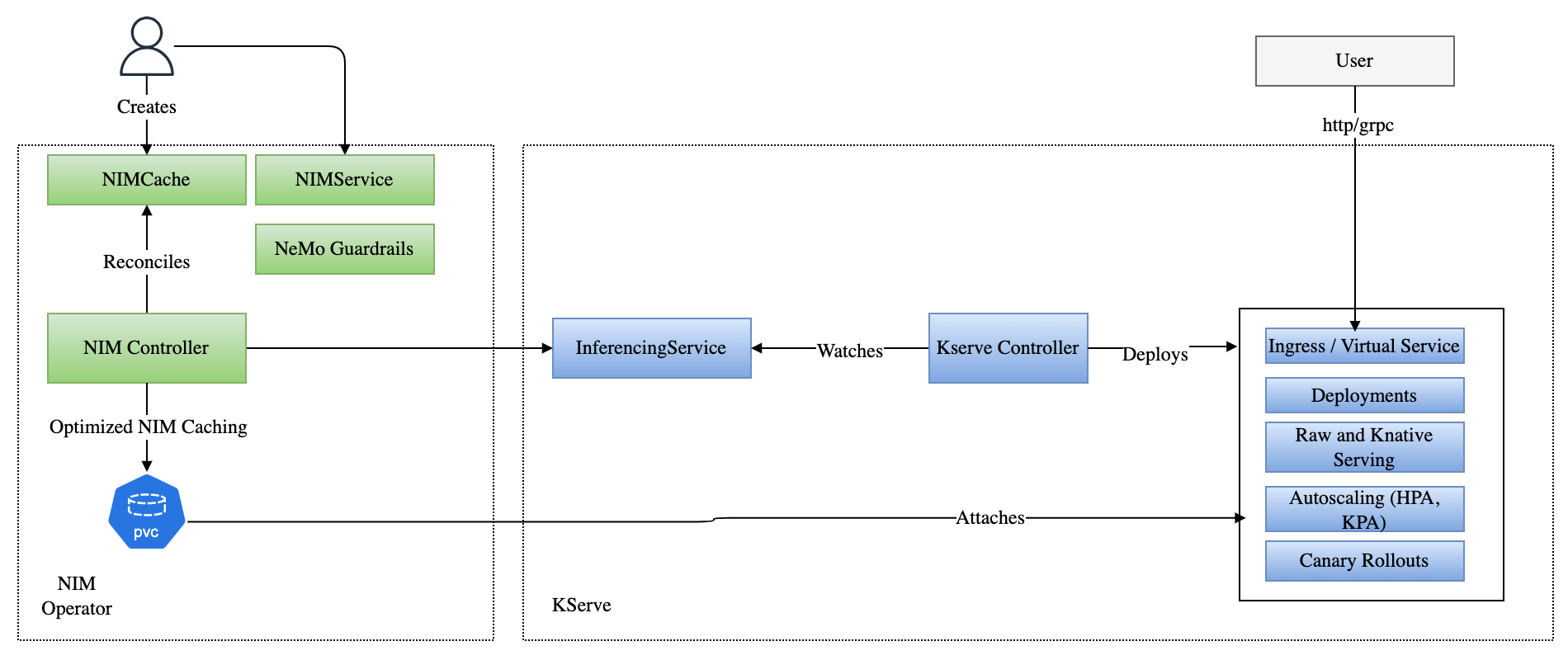
Diagram 1. NIM Operator and KServe interaction
KServe Deployment Modes Comparison#
Category |
KServe serverless (with Knative) |
Raw Deployment |
|---|---|---|
Autoscaling |
Scales pods automatically based on request load (speed and traffic). Can scale all the way to zero when unused. These are configured by providing Knative annotations
in the NIMService |
Uses Horizontal/Vertical Pod Autoscalers with custom NIM metrics. Cannot scale to zero by default. These are configured by providing |
Upgrades |
Every new model version creates a new revision. Can send only a portion of traffic to test new versions. Easy rollback by shifting traffic. This is automatically managed by KServe. No special parameters required in the NIMService API. Refer to the Knative documentation on gradual rollouts and traffic management for configuring canary rollouts. |
Uses rolling updates. Rollback is manual if something goes wrong. This is not configurable. Only RollingUpdate of native Kubernetes deployment is supported. |
Ingress |
Uses Knative Gateway (such as Istio). Gives each model revision a stable domain/URL. Built-in secure connections. Has a queue system to handle overload. This is automatically managed by KServe. No special parameters are added. The domain name has to be configured during KServe install (default example.com). |
Exposed using Kubernetes Service + Ingress/LoadBalancer (NGINX, Istio, etc.) Security (mTLS, certificates) must be set up manually. This is automatically managed by KServe. No special parameters are added. The domain name has to be configured during KServe install (default example.com). |
NIM Metrics |
Metrics and tracing are built in through Knative, KServe, and service mesh. No extra config in the NIMService is required. |
Must build your own stack. For example, Prometheus, Grafana, OpenTelemetry, etc. ServiceMonitor needs to be enabled through the NIMService |
GPU Resources |
Passed using the |
Passed using the |
Multi-Node |
Not supported. |
Not supported. |
Dynamic Resource Allocation (DRA) |
Not supported. |
Not supported. |
Tolerations |
Passed through Feature gates must be enabled with the Knative config. |
Passed through |
RuntimeClassName |
Passed through Feature gates must be enabled with the Knative config. |
Passed through |
NodeSelectors |
Passed through Feature gates must be enabled with the Knative config. |
Passed through |
Custom Scheduler Name |
Passed through Feature gates must be enabled with the Knative config. |
Passed through |
Select Your Deployment Environment and Type#
Raw Deployment
on Standard Kubernetes
Raw Deployment
on Red Hat OpenShift
Serverless Deployment
on Standard Kubernetes
Note
This documentation uses kubectl for Kubernetes examples and oc for OpenShift examples. Both tools provide similar functionality for their respective platforms.
Raw Deployment Example on Standard Kubernetes#
Summary#
For raw deployment of NIM through KServe on a standard Kubernetes installation, follow these steps:
Optional: Create NIM Cache.
1. Install KServe in Raw Deployment Mode#
Note
For security, consider downloading and reviewing the script before execution in production environments.
Run the following command to execute the KServe quick install script:
$ curl -s "https://raw.githubusercontent.com/kserve/kserve/release-0.16/hack/quick_install.sh" | bash -s - -r
For more information, refer to Getting Started with KServe.
The following components are deployed by the KServe quick install script:
Component |
Description |
|---|---|
KServe |
|
Gateway API CRDs |
|
Istio (Service Mesh) |
Deployed into the
|
Cert-Manager |
|
Verify the installation by checking each component:
KServe
$ kubectl get pods -n kserve
Example output
NAME READY STATUS RESTARTS AGE kserve-controller-manager-85768d7b78-lrmss 2/2 Running 0 2m56s
Istio System
$ kubectl get pods -n istio-system
Example output
NAME READY STATUS RESTARTS AGE istio-ingressgateway-74949b4866-hk5nf 1/1 Running 0 3m50s istiod-77bbc7c8bb-qkwdt 1/1 Running 0 4m1s
Cert Manager
$ kubectl get pods -n cert-manager
Example output
NAME READY STATUS RESTARTS AGE cert-manager-74b7f6cbbc-7mrrw 1/1 Running 0 4m18s cert-manager-cainjector-58c9d76cb8-t8bxb 1/1 Running 0 4m18s cert-manager-webhook-5875b545cf-dhhfb 1/1 Running 0 4m18s
Note
To uninstall KServe, follow the instructions in Uninstalling KServe.
2. Optional: Create NIM Cache#
Note
Refer to prerequisites for more information on using NIM Cache.
Create a file, such as
nimcache.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMCache metadata: name: meta-llama-3-2-1b-instruct namespace: nim-service spec: source: ngc: modelPuller: nvcr.io/nim/meta/llama-3.2-1b-instruct:1.8 pullSecret: ngc-secret authSecret: ngc-api-secret model: engine: "tensorrt" tensorParallelism: "1" storage: pvc: create: true storageClass: size: "50Gi" volumeAccessMode: ReadWriteOnce
Apply the manifest:
$ kubectl apply -n nim-service -f nimcache.yaml
Create a file, such as
nimcache.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMCache metadata: name: nim-cache-multi-llm namespace: nim-service spec: source: hf: endpoint: "https://huggingface.co" namespace: "nvidia" authSecret: hf-api-secret modelPuller: nvcr.io/nim/nvidia/llm-nim:1.12 pullSecret: ngc-secret modelName: "Llama-3.1-Nemotron-Nano-8B-v1" storage: pvc: create: true storageClass: '' size: "50Gi" volumeAccessMode: ReadWriteOnce
Apply the manifest:
$ kubectl apply -n nim-service -f nimcache.yaml
3. Deploy NIM through KServe as a Raw Deployment#
Create a file, such as
nimservice.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMService metadata: name: meta-llama-3-2-1b-instruct namespace: nim-service spec: inferencePlatform: kserve annotations: serving.kserve.io/deploymentMode: 'Standard' labels: networking.kserve.io/visibility: "exposed" scale: enabled: true hpa: minReplicas: 1 maxReplicas: 3 metrics: - type: "Resource" resource: name: "cpu" target: type: "Utilization" averageUtilization: 80 image: repository: nvcr.io/nim/meta/llama-3.2-1b-instruct tag: "1.8" pullPolicy: IfNotPresent pullSecrets: - ngc-secret authSecret: ngc-api-secret storage: nimCache: name: meta-llama-3-2-1b-instruct replicas: 1 resources: limits: nvidia.com/gpu: 1 cpu: "12" memory: 32Gi requests: nvidia.com/gpu: 1 cpu: "4" memory: 6Gi expose: service: type: ClusterIP port: 8000
Apply the manifest for raw deployment:
$ kubectl create -f nimservice.yaml -n nim-service
Verify that the inference service has been created:
View inference service details:
$ kubectl get inferenceservice -n nim-service -o yaml
Example output
apiVersion: v1 items: - apiVersion: serving.kserve.io/v1beta1 kind: InferenceService metadata: annotations: nvidia.com/last-applied-hash: 757475558b nvidia.com/parent-spec-hash: b978f49f7 openshift.io/required-scc: nonroot serving.kserve.io/autoscalerClass: hpa serving.kserve.io/deploymentMode: RawDeployment serving.kserve.io/enable-metric-aggregation: "true" serving.kserve.io/enable-prometheus-scraping: "true" temp: temp-1 creationTimestamp: "2025-07-25T14:58:06Z" finalizers: - inferenceservice.finalizers generation: 1 labels: app.kubernetes.io/instance: meta-llama-3-2-1b-instruct app.kubernetes.io/managed-by: k8s-nim-operator app.kubernetes.io/name: meta-llama-3-2-1b-instruct app.kubernetes.io/operator-version: "" app.kubernetes.io/part-of: nim-service networking.kserve.io/visibility: cluster-local temp2: temp-2 name: meta-llama-3-2-1b-instruct namespace: nim-service ownerReferences: - apiVersion: apps.nvidia.com/v1alpha1 blockOwnerDeletion: true controller: true kind: NIMService name: meta-llama-3-2-1b-instruct uid: aaa7e95a-81e4-404a-a1de-6dce898f9937 resourceVersion: "43983337" uid: c92a7aa9-4954-4959-86b3-ad8aa6c39ca8 spec: predictor: annotations: openshift.io/required-scc: nonroot serving.kserve.io/deploymentMode: RawDeployment temp: temp-1 containers: - env: - name: MY_ENV value: my-value - name: NIM_CACHE_PATH value: /model-store - name: NGC_API_KEY valueFrom: secretKeyRef: key: NGC_API_KEY name: ngc-api-secret - name: OUTLINES_CACHE_DIR value: /tmp/outlines - name: NIM_SERVER_PORT value: "8000" - name: NIM_HTTP_API_PORT value: "8000" - name: NIM_JSONL_LOGGING value: "1" - name: NIM_LOG_LEVEL value: INFO image: nvcr.io/nim/meta/llama-3.2-1b-instruct:1.8 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /v1/health/live port: api initialDelaySeconds: 15 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 name: kserve-container ports: - containerPort: 8000 name: api protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /v1/health/ready port: api initialDelaySeconds: 15 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 resources: limits: cpu: "12" memory: 32Gi nvidia.com/gpu: "1" requests: cpu: "12" memory: 32Gi nvidia.com/gpu: "1" startupProbe: failureThreshold: 30 httpGet: path: /v1/health/ready port: api initialDelaySeconds: 30 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 volumeMounts: - mountPath: /model-store name: model-store - mountPath: /dev/shm name: dshm deploymentStrategy: rollingUpdate: maxSurge: 0 maxUnavailable: 25% type: RollingUpdate imagePullSecrets: - name: ngc-secret labels: app: meta-llama-3-2-1b-instruct maxReplicas: 3 minReplicas: 1 scaleMetric: cpu scaleMetricType: Utilization scaleTarget: 80 securityContext: fsGroup: 2500 runAsGroup: 2500 runAsUser: 2500 serviceAccountName: meta-llama-3-2-1b-instruct volumes: - emptyDir: medium: Memory name: dshm - name: model-store persistentVolumeClaim: claimName: meta-llama-3-2-1b-instruct-pvc status: address: url: http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local components: predictor: url: http://meta-llama-3-2-1b-instruct-predictor-nim-service.example.com conditions: - lastTransitionTime: "2025-07-25T14:58:06Z" status: "True" type: IngressReady - lastTransitionTime: "2025-07-25T14:58:06Z" status: "True" type: PredictorReady - lastTransitionTime: "2025-07-25T14:58:06Z" status: "True" type: Ready deploymentMode: RawDeployment modelStatus: copies: failedCopies: 0 totalCopies: 1 states: activeModelState: Loaded targetModelState: Loaded transitionStatus: UpToDate observedGeneration: 1 url: http://meta-llama-3-2-1b-instruct-nim-service.example.com kind: List metadata: resourceVersion: ""
View inference service status:
$ kubectl get inferenceservice -n nim-service
Example output
NAME URL READY AGE meta-llama-3-2-1b-instruct http://meta-llama-3-2-1b-instruct-nim-service.example.com True 100s
View NIM Service status:
$ kubectl get nimservice -n nim-service -o json | jq .items[0].status
Example output
{ "conditions": [ { "lastTransitionTime": "2025-07-25T15:02:09Z", "message": "", "reason": "Ready", "status": "True", "type": "Ready" }, { "lastTransitionTime": "2025-07-25T14:58:06Z", "message": "", "reason": "Ready", "status": "False", "type": "Failed" } ], "model": { "clusterEndpoint": "http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local", "externalEndpoint": "http://meta-llama-3-2-1b-instruct-nim-service.example.com", "name": "meta/llama-3.2-1b-instruct" }, "state": "Ready" }
Verify that the HPA has been created:
$ kubectl get hpa -n nim-service meta-llama-3-2-1b-instruct-predictor -o yaml
Create a file, such as
nimservice.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMService metadata: name: nim-service-multi-llm namespace: nim-service spec: inferencePlatform: kserve annotations: serving.kserve.io/deploymentMode: 'Standard' labels: networking.kserve.io/visibility: "exposed" image: repository: nvcr.io/nim/nvidia/llm-nim tag: "1.12" pullPolicy: IfNotPresent pullSecrets: - ngc-secret authSecret: ngc-api-secret replicas: 1 storage: nimCache: name: nim-cache-multi-llm profile: 'tensorrt_llm' resources: limits: nvidia.com/gpu: 1 cpu: "12" memory: 32Gi requests: nvidia.com/gpu: 1 cpu: "4" memory: 6Gi expose: service: type: ClusterIP port: 8000
Apply the manifest for raw deployment:
$ kubectl create -f nimservice.yaml -n nim-service
Verify that the inference service has been created:
$ kubectl get inferenceservice -n nim-service nim-service-multi-llm -o yaml
Raw Deployment Example on Red Hat OpenShift#
Summary#
For raw deployment of NIM through KServe using Red Hat OpenShift, follow these steps:
1. Install KServe in Raw Deployment Mode Using OpenShift#
Follow the instructions on the Red Hat website for installing the single-model serving platform to install the OpenShift AI Operator.
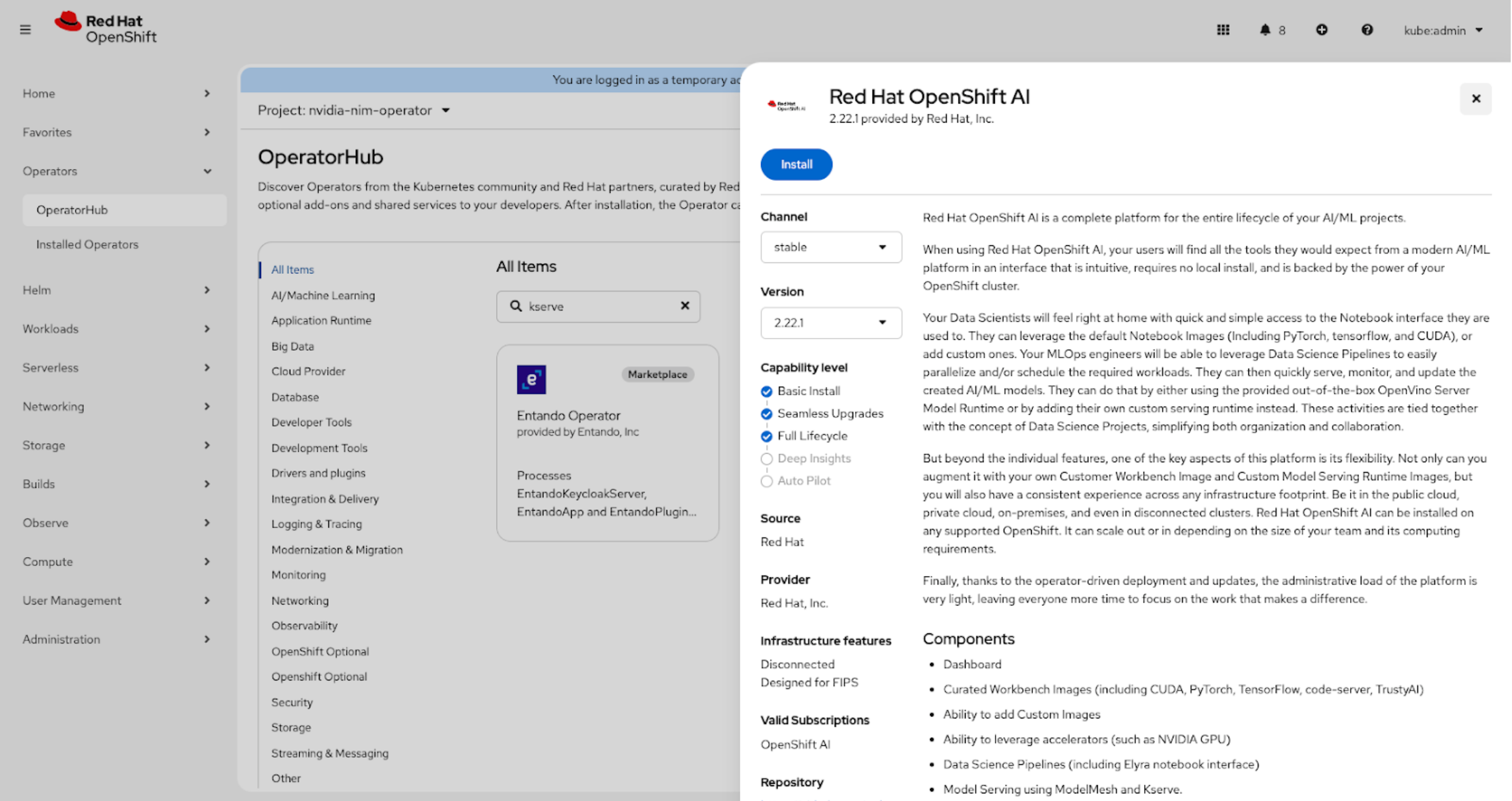
Figure 1. OpenShift web console
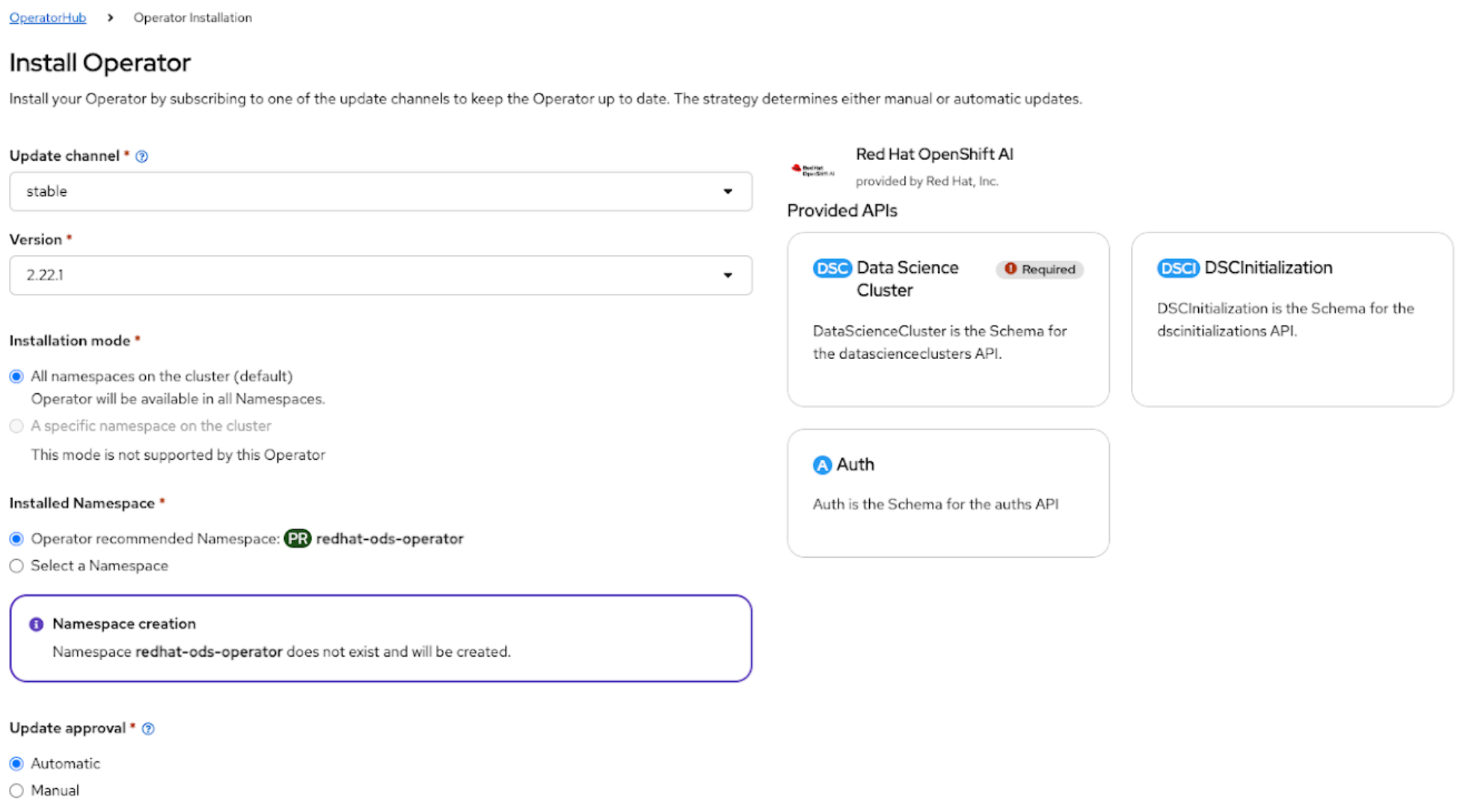
Figure 2. Interface to install OpenShift AI Operator
Follow the steps for
standarddeployment (OpenShift’s term for raw deployment mode). Select the following settings:Update channel: stable
Version: 2.22.1
Operator recommended namespace: redhat-ods-operator
Note
There is also an
advancedmode, which is equivalent to serverless; however, the NIM Operator does not support it in this release.Create an instance of Data Science Cluster (DSC)
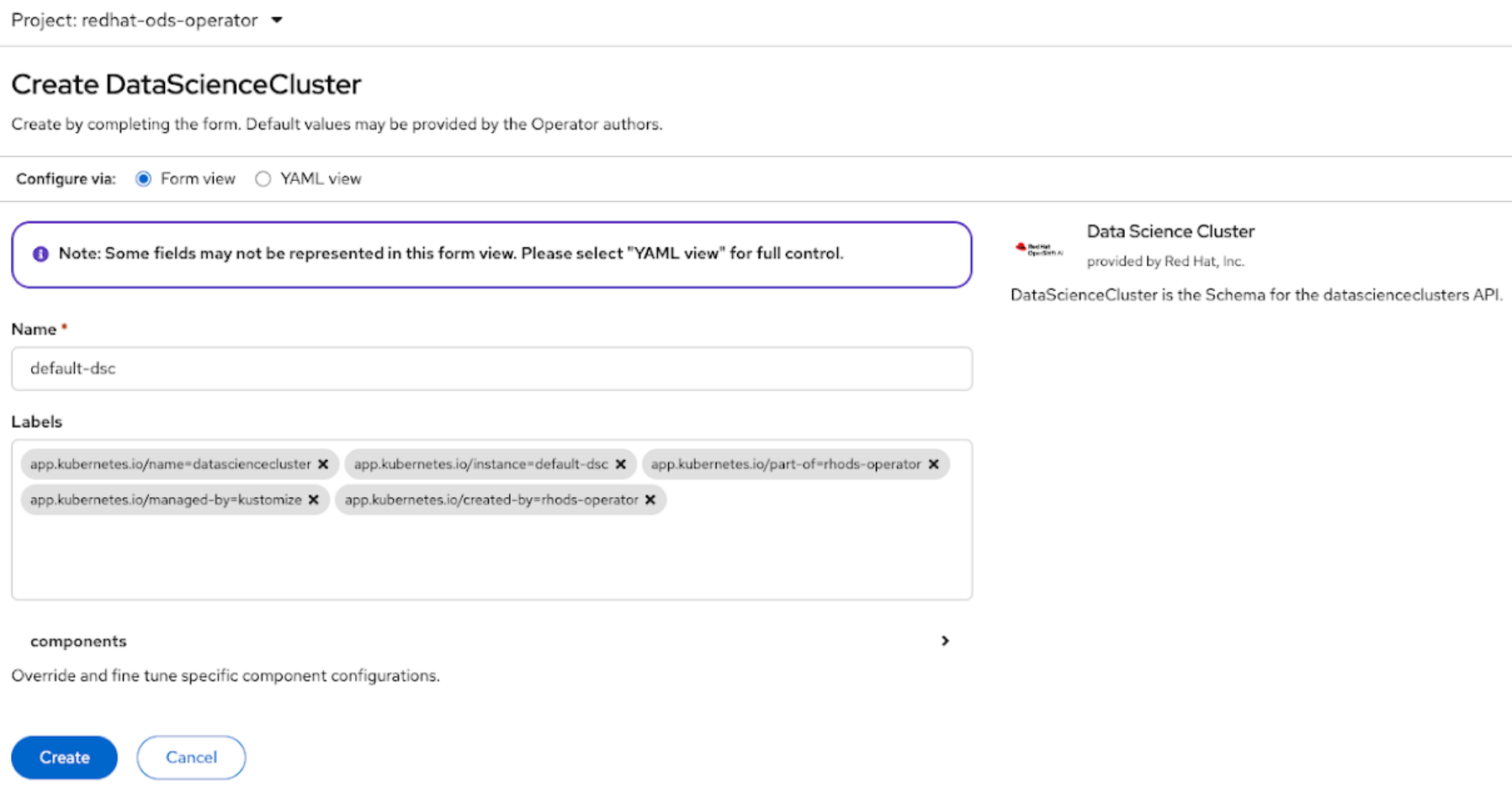
Figure 3. Interface to create instance of DSC
Use the following YAML to create the DSC:
kind: DataScienceCluster metadata: labels: app.kubernetes.io/created-by: rhods-operator app.kubernetes.io/instance: default-dsc app.kubernetes.io/managed-by: kustomize app.kubernetes.io/name: datasciencecluster app.kubernetes.io/part-of: rhods-operator name: default-dsc spec: components: codeflare: managementState: Managed kserve: defaultDeploymentMode: RawDeployment managementState: Managed nim: managementState: Managed rawDeploymentServiceConfig: Headed serving: ingressGateway: certificate: type: OpenshiftDefaultIngress managementState: Removed name: knative-serving modelregistry: registriesNamespace: rhoai-model-registries feastoperator: {} trustyai: {} ray: {} kueue: {} workbenches: workbenchNamespace: rhods-notebooks dashboard: {} modelmeshserving: {} llamastackoperator: {} datasciencepipelines: {} trainingoperator: {}
Create an instance of DSCInitialization (DSI):
Figure 4. Interface to create instance of DSI
Use the following YAML to create the DSI:
apiVersion: dscinitialization.opendatahub.io/v1 kind: DSCInitialization metadata: name: default-dsci spec: applicationsNamespace: redhat-ods-applications serviceMesh: controlPlane: metricsCollection: Istio name: data-science-smcp namespace: istio-system managementState: Removed
Verify the KServe controller is running:
Click on Workloads > Pods > redhat-ods-applications project.
2. Create NIM Cache Using OpenShift#
Note
Refer to prerequisites for more information on using NIM Cache.
Create a file, such as
nimcache.yaml, with contents like the following example:# NIM Cache for OpenShift apiVersion: apps.nvidia.com/v1alpha1 kind: NIMCache metadata: name: meta-llama3-1b-instruct namespace: nim-service spec: source: ngc: authSecret: ngc-api-secret model: engine: tensorrt_llm tensorParallelism: '1' modelPuller: 'nvcr.io/nim/meta/llama-3.2-1b-instruct:1.8.3' pullSecret: ngc-secret storage: pvc: create: true size: 50Gi volumeAccessMode: ReadWriteOnce
Apply the manifest:
$ oc apply -n nim-service -f nimcache.yaml
3. Deploy NIM Through KServe as a Raw Deployment Using OpenShift#
Create a file, such as
nimservice.yaml, with contents like the following example:# NIM Service Raw Deployment Using OpenShift apiVersion: apps.nvidia.com/v1alpha1 kind: NIMService metadata: name: meta-llama-3-2-1b-instruct namespace: nim-service spec: annotations: serving.kserve.io/deploymentMode: RawDeployment expose: service: port: 8000 type: ClusterIP scale: enabled: true hpa: maxReplicas: 3 metrics: - resource: name: cpu target: averageUtilization: 80 type: Utilization type: Resource minReplicas: 1 inferencePlatform: kserve authSecret: ngc-api-secret image: pullPolicy: IfNotPresent pullSecrets: - ngc-secret repository: nvcr.io/nim/meta/llama-3.2-1b-instruct tag: 1.8.3 storage: nimCache: name: meta-llama3-1b-instruct resources: limits: nvidia.com/gpu: 1 cpu: "12" memory: 32Gi requests: nvidia.com/gpu: 1 cpu: "4" memory: 6Gi replicas: 1
Apply the manifest for raw deployment:
$ oc create -f nimservice.yaml -n nim-service
Verify that the inference service has been created:
View inference service details:
$ oc get inferenceservice -n nim-service -o json | jq .items[0].status
Example output
{ "address": { "url": "http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local" }, "components": { "predictor": {} }, "conditions": [ { "lastTransitionTime": "2025-08-15T05:59:00Z", "status": "True", "type": "IngressReady" }, { "lastTransitionTime": "2025-08-15T05:59:00Z", "status": "True", "type": "PredictorReady" }, { "lastTransitionTime": "2025-08-15T05:59:00Z", "status": "True", "type": "Ready" }, { "lastTransitionTime": "2025-08-15T05:58:59Z", "severity": "Info", "status": "False", "type": "Stopped" } ], "deploymentMode": "RawDeployment", "modelStatus": { "copies": { "failedCopies": 0, "totalCopies": 1 }, "states": { "activeModelState": "Loaded", "targetModelState": "Loaded" }, "transitionStatus": "UpToDate" }, "observedGeneration": 1, "url": "http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local" }
View NIM Service status:
$ oc get nimservice -n nim-service meta-llama-3-2-1b-instruct -o json | jq .status
Example output
{ "conditions": [ { "lastTransitionTime": "2025-08-15T05:59:50Z", "message": "", "reason": "Ready", "status": "True", "type": "Ready" }, { "lastTransitionTime": "2025-08-15T05:58:59Z", "message": "", "reason": "Ready", "status": "False", "type": "Failed" } ], "model": { "clusterEndpoint": "http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local", "externalEndpoint": "http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local", "name": "meta/llama-3.2-1b-instruct" }, "state": "Ready" }
Run inference:
$ oc -n nim-service run curltest --rm -i --image=curlimages/curl --restart=Never -- \ curl -s http://meta-llama-3-2-1b-instruct-predictor.nim-service.svc.cluster.local/v1/chat/completions \ -H 'Content-Type: application/json' \ -d '{"model":"meta/llama-3.2-1b-instruct","messages":[{"role":"user","content":"Hello!"}]}'
Example output
{"id":"chat-2d3c821536514598b931783033a7e7e7","object":"chat.completion","created":1755239534,"model":"meta/llama-3.2-1b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"Hello! How can I help you today?"},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":12,"total_tokens":21,"completion_tokens":9},"prompt_logprobs":null}
Serverless Deployment Example on Standard Kubernetes#
Summary#
For serverless deployment of NIM through KServe on a standard Kubernetes installation, follow these steps:
1. Install KServe in Serverless Mode#
Note
For security, consider downloading and reviewing the script before execution in production environments.
Run the following command to execute the KServe quick install script:
$ curl -s "https://raw.githubusercontent.com/kserve/kserve/release-0.16/hack/quick_install.sh" | bash
For more information, refer to Getting Started with KServe.
The following components are deployed by the KServe quick install script:
Component |
Description |
|---|---|
KServe |
|
Gateway API CRDs |
|
Istio (Service Mesh) |
Deployed into the
|
Cert-Manager |
|
Knative |
|
Note
To uninstall KServe, follow the instructions in Uninstalling KServe.
2. Enable PVC Support#
Run the following command to enable persistent volume support:
$ kubectl patch --namespace knative-serving configmap/config-features \
--type merge \
--patch '{"data":{"kubernetes.podspec-persistent-volume-claim": "enabled", "kubernetes.podspec-persistent-volume-write": "enabled"}}'
These extensions enable persistent volume support:
kubernetes.podspec-persistent-volume-claim: Enables persistent volumes (PVs) with Knative Servingkubernetes.podspec-persistent-volume-write: Provides write access to those PVs
3. Optional: Create NIM Cache With Serverless Deployment#
Note
Refer to prerequisites for more information on using NIM Cache.
Create a file, such as
nimcache.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMCache metadata: labels: app.kubernetes.io/name: k8s-nim-operator name: meta-llama-3-2-1b-instruct namespace: nim-service spec: source: ngc: modelPuller: nvcr.io/nim/meta/llama-3.2-1b-instruct:1.8 pullSecret: ngc-secret authSecret: ngc-api-secret model: engine: "tensorrt" tensorParallelism: "1" storage: pvc: create: true size: "50Gi" volumeAccessMode: ReadWriteOnce
Apply the manifest:
$ kubectl apply -n nim-service -f nimcache.yaml
4. Deploy NIM through KServe as a Serverless Deployment#
Note
Autoscaling and ingress are handled directly by KServe, not through NIMService configuration.
Create a file, such as
nimservice.yaml, with contents like the following sample manifest:apiVersion: apps.nvidia.com/v1alpha1 kind: NIMService metadata: name: meta-llama-3-2-1b-instruct namespace: nim-service spec: inferencePlatform: kserve annotations: # Knative concurrency-based autoscaling (default). autoscaling.knative.dev/class: kpa.autoscaling.knative.dev autoscaling.knative.dev/metric: concurrency # Target 10 requests in-flight per pod. autoscaling.knative.dev/target: "10" # Disable scale to zero with a min scale of 1. autoscaling.knative.dev/min-scale: "1" # Limit scaling to 100 pods. autoscaling.knative.dev/max-scale: "10" image: repository: nvcr.io/nim/meta/llama-3.2-1b-instruct tag: "1.8" pullPolicy: IfNotPresent pullSecrets: - ngc-secret authSecret: ngc-api-secret storage: nimCache: name: meta-llama-3-2-1b-instruct profile: '' resources: limits: nvidia.com/gpu: 1 cpu: "12" memory: 32Gi requests: nvidia.com/gpu: 1 cpu: "4" memory: 6Gi replicas: 1 expose: service: type: ClusterIP port: 8000
Apply the manifest for serverless deployment:
$ kubectl create -f nimservice.yaml -n nim-service
Verify that the inference service has been created:
$ kubectl get inferenceservice -n nim-service meta-llama-3-2-1b-instruct-serverless -o yaml
Uninstalling KServe#
If you installed KServe using the https://raw.githubusercontent.com/kserve/kserve/release-0.16/hack/quick_install.sh quick install script, use the following commands to uninstall it:
helm uninstall --ignore-not-found istio-ingressgateway -n istio-system
helm uninstall --ignore-not-found istiod -n istio-system
helm uninstall --ignore-not-found istio-base -n istio-system
echo "😀 Successfully uninstalled Istio"
helm uninstall --ignore-not-found cert-manager -n cert-manager
echo "😀 Successfully uninstalled Cert Manager"
helm uninstall --ignore-not-found keda -n keda
echo "😀 Successfully uninstalled KEDA"
kubectl delete --ignore-not-found=true KnativeServing knative-serving -n knative-serving --wait=True --timeout=300s || true
helm uninstall --ignore-not-found knative-operator -n knative-serving
echo "😀 Successfully uninstalled Knative"
helm uninstall --ignore-not-found kserve -n kserve
helm uninstall --ignore-not-found kserve-crd -n kserve
echo "😀 Successfully uninstalled KServe"
kubectl delete --ignore-not-found=true namespace istio-system
kubectl delete --ignore-not-found=true namespace cert-manager
kubectl delete --ignore-not-found=true namespace kserve