The 3D Sample
NOTE: With the 1.3.0 release, the NVIGI 3D Sample has been moved into the main SDK itself for ease of use. The name has changed from
NVIGISample.exetonvigi.3d.exeto reflect this change. The sample is now built as part of the SDK build, and is available in the<SDK_ROOT>/bin/x64directory. The source code for the sample is in the<SDK_ROOT>/source/samples/nvigi.3ddirectory.
The 3D sample, nvigi.3d combines NVIGI and Donut https://github.com/NVIDIAGameWorks/donut to create a sample app demonstrating an NVIGI AI integration. Using NVIGI, it’s possible to support multiple backends within single application. Sample app shows one such usecase using GGML CPU, CUDA, Vulkan and D3D12-based backends. Support for multiple backends ensures application developer can create wide variety of inference pipelines. In the sample, based on user selection, particular type of backend is instantiated and used for inferencing.
The Donut-based NVIDIA NVIGI (In-Game Inference) 3D Sample is an interactive 3D application that is designed to show how one might integrate such AI features as speech recognition (ASR) and chatbots (GPT/LLM) into a UI-based workflow. The focus in the sample is showing how to present the options to the user and run AI workflows without blocking the 3D interaction or rendering. The sample defaults to rendering with Direct3D 12, but via a command-line option can switch to rendering via Vulkan.
IMPORTANT: For important changes and bug fixes included in the current release, please see the release notes for the SDK BEFORE use.
Requirements
Hardware:
Same as overall SDK.
Software:
Same as overall SDK.
Etc:
An NVIDIA Integrate API key, needed to use the GPT cloud plugin. Contact your NVIDIA NVIGI developer relations representative for details if you have not been provided one.
If you wish to use OpenAI cloud models, an OpenAI account API key is needed.
Setting up and Launching the Sample
There are several steps that are required in order to be able to use all of the NVIGI features shown in the sample:
Downloading the models as noted above. These represent models that an application would bundle with their installer. NOTE if you manually download a model while the sample is running, you will need to exit and restart the sample application in order for the model to be shown as an option in the UI.
Setting up the NVIDIA Cloud API key. The enables the use of the example cloud GPT plugin.
Setting up the GPT Cloud Plugin
The NVIGI Cloud GPT plugin that is supported by this sample uses a setup based upon an API key from a developer account on https://build.nvidia.com/explore/discover. The basic steps to set this up are:
Navigate your browser to https://build.nvidia.com/explore/discover
Sign up or sign on to a developer account
Navigate to the model that the sample currently supports: https://build.nvidia.com/meta/llama-3_1-405b-instruct
Next to the Python code example, click the “Get API Key” button and save the key for reference
Set this key into your environment as the value of
NVIDIA_INTEGRATE_KEY
If you wish to use the OpenAI cloud models, you will need to generate an OpenAI API key as per their instructions and set it as the value of the environment variable OPENAI_KEY
IMPORTANT: After setting an API Key as an environment variable in the system properties, Visual Studio (if used) or the command prompt used to launch the Sample must be restarted to read the new environment variable.
Launching the Sample
For those using a prebuilt NVIGI binary pack, the sample executable is available immediately and can be run. For those building from source, building the SDK tree will also build the 3D Sample.
To launch the sample, run <SDK_ROOT>/bin/x64/nvigi.3d.exe, either by double-clicking the executable in Windows Explorer or by running it from a command prompt. The sample will launch a window with a 3D scene and a UI on the left side of the window.
The sample requires and looks for AI models and rendering media relative to the executable path. Specifically, it looks for:
The models directory, which it finds by starting at the executable directory, looking for
<dir>/data/nvigi.modelssuch that it containsnvigi.plugin.gpt.ggml. The code will check upward from the executable directory several times to find this. This is done so that pre-built binary and GitHub source layouts are trivially supported with no user effort.The media directory, which it finds by starting at the executable directory, looking for
<dir>/data/nvigi.test/nvigi.3d. The code will check upward from the executable directory several times to find this. This is done so that pre-built binary and GitHub source layouts are trivially supported with no user effort.
If required, the models directory may be specified explicitly via the command line argument -pathToModels <path>. This is recommended if you have a non-standard layout.
To run the rebuilt sample from within the debugger, simply set nvigi.3d as the startup project in Visual Studio and launch with debugging.
The LLM System Prompt
By default, the LLM model uses the following system prompt:
“You are a helpful AI agent. Your goal is to provide information about queries. Generate only medium size answers and avoid describing what you are doing physically.
Avoid using specific words that are not part of the dictionary.”
You can customize this prompt using the -systemPromptGPT parameter.
Example:
.\nvigi.3d.exe -systemPromptGPT "You are a helpful AI assistant answering user questions."
Using the Sample
Main UI
On launch, the sample will show a UI box on the left side of the window as shown above, and will show a 3D rendered scene at the same time. This is the main UI:
At the top is the UI Header
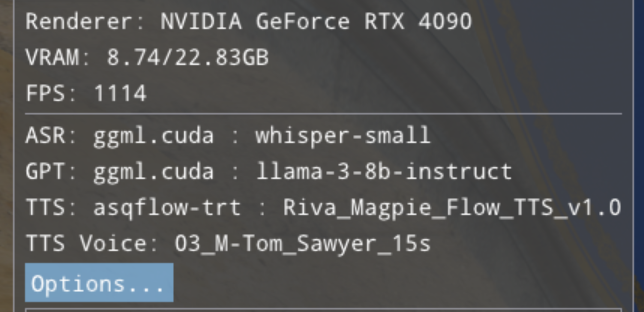
The top is GPU, system and performance info.
Directly below is a listing of the current models/backends in use
Next is the “Options…” button that launches the tabbed dialog with all settings (Details below)
Then, the large chat text window, which shows the results of GPT (and of ASR when used).
Finally, we have the interaction area:
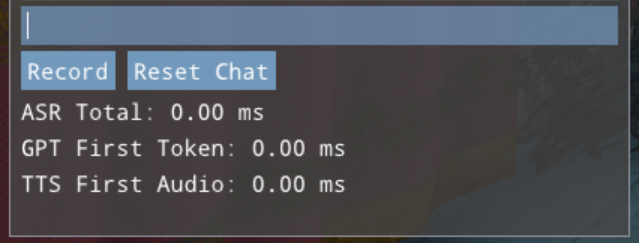
The interaction controls for ASR, GPT and TTS. Details of their use are below.
Three performance numbers:
End-to-end audio-to-text inference time for ASR
Time from start of inference to first text response for GPT
Time from first text input to first audio for TTS
The main UI’s interaction area includes controls that allow the user to type in queries to the LLM or record a spoken query to be converted to text by ASR, then passed to the LLM and finally passed to TTS. In addition, the “Reset Chat” button clears the chat window and resets the LLM’s history context, “forgetting” previous discussion. Typed and spoken input is handled as follows:
Speech. Click the “Record” button to start recording (the “Record” button will be replaced by a “Stop” button. Then, speak a question, and conclude by pressing the “Stop” button. The ASR plugin will compute speech recognition and print the recognized text, which will then be sent to the LLM for a response that will be printed in the UI. In the case of the GPT plugin being deactivated, the text will be sent directly to TTS. If the text returned from ASR is a form of “[BLANK AUDIO]”, then check you Windows microphone settings, as the audio may not be getting routed correctly in Windows. To test different microphones, user should select microphone from Windows settings. The model shipping with this release is the Whisper Small Multi-lingual, which supports a wide range of languages, with varying levels of quality/coverage.
Typing. Click in the small, blank text line at the bottom of the UI, type your query and press the Enter or Return key. The text will be sent to the LLM and the result printed to the UI. If the GPT plugin is deactivated, the text will be sent directly to TTS.
Text To Speech By default, no TTS model is selected. Please choose one in the model settings to use TTS. The target voice can be changed through the UI.
The Options Dialog
By clicking the “Options…” button, the user can launch the tabbed options dialog:
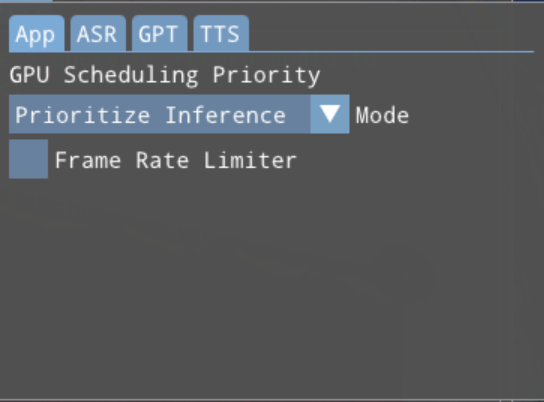
This dialog contains four tabs, each of which contains the options for a different functionality:
App: Top-level/global application settings
ASR: Speech Recognition settings
GPT: LLM/Chatbot settings
TTS: Text-to-Speech settings
App Settings Tab
This tab contains global application settings that affect rendering and performance:
A drop-down to set the 3D-vs-compute/inference prioritization to one of the following:
Prioritize Graphics: Give more GPU priority to 3D rendering, at the expensive of inference latency
Prioritize Inference: Give more GPU priority to compute, improving inference latency at the potential expense of rendering time (Does not currently affect Vulkan backend plugins)
Balanced: A more even split between the two
An option frame-rate limiter. If the “Frame Rate Limiter” box is checked, a typein allows the user to specify the max frame rate for rendering to avoid the sample (and its minimal 3D load) running at many hundreds of FPS.
ASR Settings Tab
This tab contains settings specific to the ASR feature:
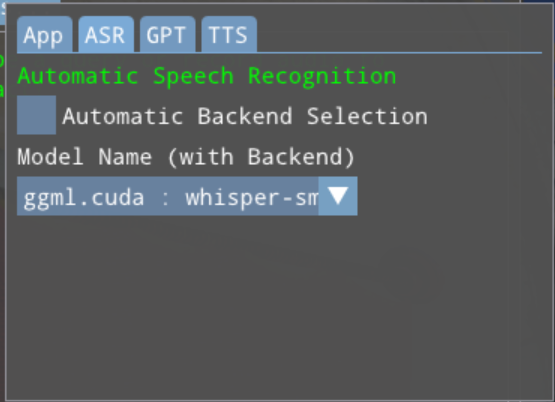
To change the selected models, the UI provides two modes: Manual and Automatic. Each feature tab (ASR, GPT and TTS) has this option, which initially defaults to the Manual Settings panel.
The ASR tab (as well as the GPT and TTS tabs) contains:
A checkbox to switch between the Manual and Automatic backend selection modes
The currently-selected model/backend pairs for the feature
Drop-downs to select a model/backend pairing for the feature
In Manual mode, the drop-downs show all model/backend pairings available, grouped by model.
Note that both local CUDA and remote cloud backends are shown for the model “llama-3.2-3b-instruct”. There may be multiple available backends for some models.
Selecting each type of model behaves slightly differently:
Selecting locally-available models will immediately load the model from disk. This will disable the feature until the new model is loaded, as the sample shuts down the previous model before loading the new one.
Selecting a cloud model will make a connection to the cloud. Generally, the UI will be immediately available again, as there is no local loading to be done.
Clicking the “Automatic Backend Selection” checkbox will switch to the Automatic Settings controls for that feature:
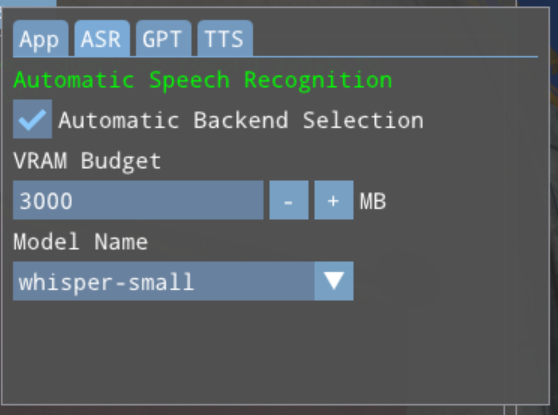
This panel is similar to the Manual Settings UI with some important differences:
Each feature dropdown only shows models, not backends. Each model will appear once
Each feature has an integer VRAM budget adjustment that sets the amount of VRAM that the model may use.
Unlike Manual mode, the user only selects a model in Automatic mode. The backend is selected automatically by code in the sample. Currently, that code selects in the following order:
If an NVIDIA GPU is present and a CUDA-based backend that is within the VRAM budget exists, select it
If a GPU is present and a GPU-based backend that is within the VRAM budget exists, select it
If a cloud API key is set for the domain (via the environment variables) and a matching cloud backend exists, select it
Select a CPU backend if available.
Adjusting the VRAM budget for a given feature can cause a new backend to be selected as the user is interacting.
This selection metric can be changed by changing the behavior of the function SelectAutoPlugin in NVIGIContext.cpp.
GPT Settings Tab
The GPT settings tab is analogous to the ASR tab.
TTS Settings Tab
The TTS settings tab is analogous to the ASR tab with the addition of a drop-down to select the target voice for TTS synthesis.
Logging from the Sample
By default, the pre-built sample will use Development plugins and core, and will launch a log window that shows the NVIGI log messages during init, creation, runtime and shutdown. In addition, logging to file may be enabled by specifying a path (directory-only) to where logs should be written:
nvigi.3d.exe -logToFile ..\logs <...>
With this option example a log file would be written to ..\logs\nvigi-log.txt
Logs can be useful when debugging issues or sending support questions.
In addition, if the GGML LLM/GPT plugin is used, the plugin may write a llama.log to the runtime directory. This file is written by the GGML code itself, and contains model-specific debugging output as per https://github.com/ggerganov/ggml
(Re)Building the Sample
The 3D Sample is automatically rebuilt along with the SDK. However, the default build uses a pre-built version of the Donut rendering framework, pulled from packman. It is also possible to rebuild the Sample against a locally-built version of Donut, which is useful for debugging or testing changes to the Sample itself. To do this, you will need CMake installed on the development system and in the PATH. Then, follow these steps:
Open a VS2022 Developer Command Prompt to
<SDK_ROOT>/source/samples/nvigi.3d/opt-local-donutDownload the Donut source code by running the script
01_pull.bat. By default, this will checkout the commit that was used to generate the pre-built version of Donut used in the sample.NOTE: This script has git use the SSH protocol to clone the repositories from GitHub; therefore, it expects you to have your git client set up with the proper SSH keys for your GitHub account. You can modify this script to use git with the HTTPS protocol instead if you would prefer not to worry about SSH keys.
If desired, checkout a newer commit of Donut from within the new
<SDK_ROOT>/source/samples/nvigi.3d/opt-local-donut/Donutdirectory, or edit the Donut code as desired.Run the script
02_setup.batrun CMake to create the build files.Run the script
03_build.batto build all three configurations of Donut. This will create a prebuilt pack of Donut in the<SDK_ROOT>/source/samples/nvigi.3d/opt-local-donut/_packagedirectory.NOTE: If this script fails with the following error:
cl : command line error D8040: error creating or communicating with child process, please simply re-run it and it should succeed.
Edit the Premake file for the sample
<SDK_ROOT>/source/samples/nvigi.3d/premake.luato:Comment out
donut_dir = externaldir.."donut"Uncomment
donut_dir = ROOT.."source/samples/nvigi.3d/opt-local-donut/_package/donut"
Re-run the top-level
<SDK_ROOT>/setup.batRebuild the SDK
Rerun the top-level copy/packaging (
package.bat -<cfg>if provided,copy_sdk_binaries.bat <cfg>if not)
This will build the sample against the locally-built Donut code, which can then be debugged or tested as needed.
Command-line Options
A subset including the most interesting options to the most common users:
Arguments |
Effect |
|---|---|
|
Required for just about any use - documented above, should point to the downloaded and unzipped models tree. Defaults to |
|
Sets the destination directory for logging. The log will be written to |
|
Sets system prompt for the LLM model. Default : See the “Launching the Sample” section. |
More Useful Command Line Arguments:
Arguments |
Effect |
|---|---|
|
Use Vulkan for rendering and show only vulkan-compatible NVIGI plugins |
|
Sets width |
|
Sets height |
|
Allows vebose info level logging logging |
|
Enables NVRHI and Graphics API validation Layer |
|
Does not do NVIGI dll signiture check |
|
Enables Vsync |
|
Sets number of frames to render before the app shuts down |
|
Disable the use of CUDA in Graphics optimization (for debugging/testing purposes) |
Notes:
The Vulkan rendering mode and its associated inference are experimental at this time
The sample is designed for use with local systems - use of the sample on remote desktop is not recommended. Support for remote desktop is being investigated for an upcoming release.