VSS Warehouse Blueprint - 2D Vision AI with Agents Profile#
Overview#
Introduction#
The VSS Warehouse Blueprint’s 2D Vision AI with Agents Profile is a comprehensive guide to building a 2D intelligent video analytics system. It provides a detailed overview of the system architecture, data flow, and key components.
Deployment Architecture#
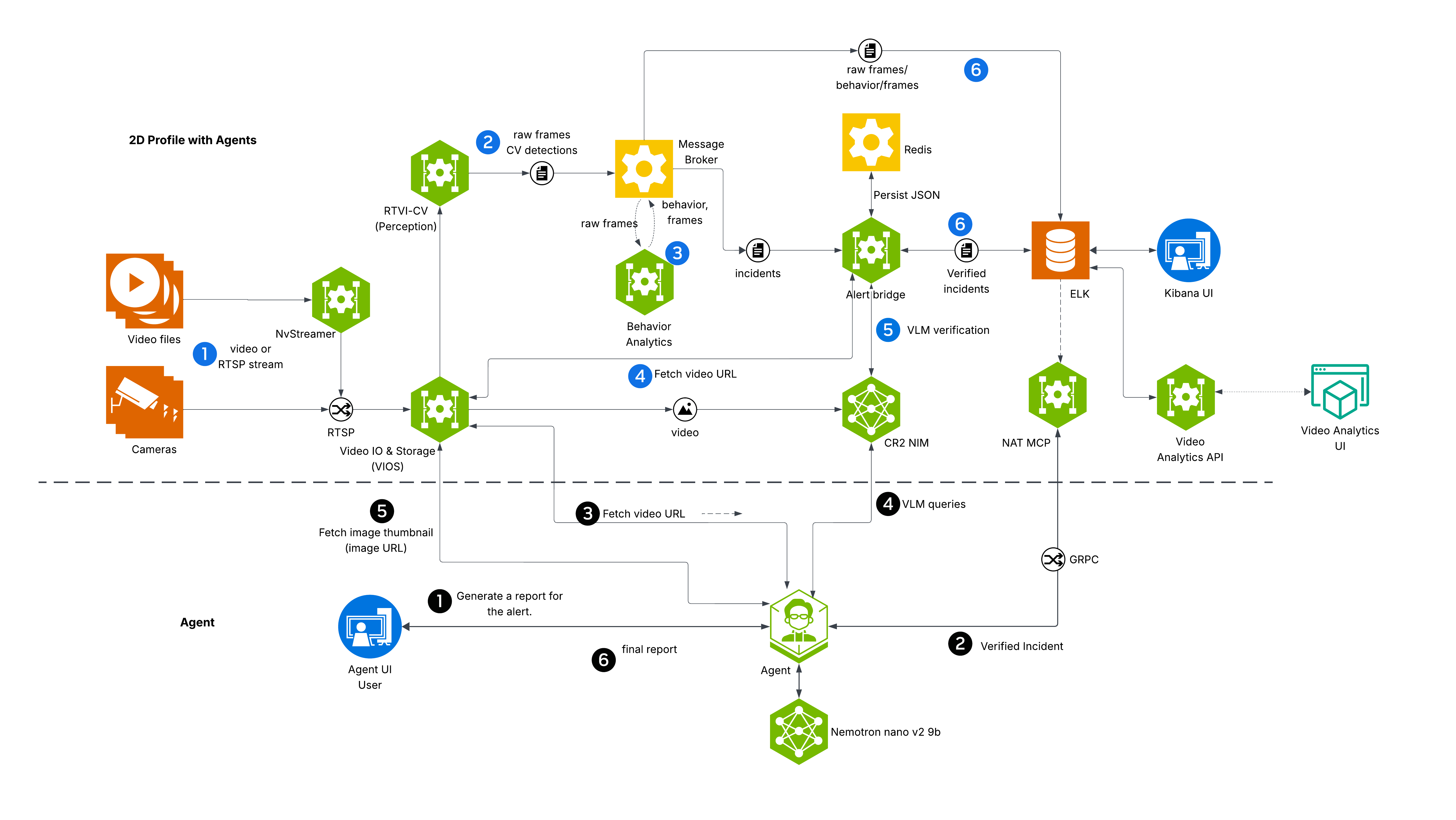
Components and Interactions#
The diagram depicts VSS Warehouse 2D Vision AI with Agents Profile, emphasizing 2D single-camera detection, tracking, and behavior analytics for safety events and metrics. Below is a breakdown of the components and their interactions.
Input Source
Videos: Raw video data stored in a filesystem, serving as input for processing.
NvStreamer (link): A microservice that streams videos via RTSP (Real-Time Streaming Protocol) to the VIOS (Video IO & Storage). NvStreamer can be swapped with real-world cameras.
Video IO & Storage (VIOS) (link):
VIOS ingests video streams from NvStreamer via RTSP.
It records the streams and forwards them (via RTSP) to the DeepStream microservice for further processing.
DeepStream (link):
DeepStream processes RTSP streams for 2D single-camera detection and tracking, utilizing the RT-DETR (Real-Time Detection Transformer) model (link) to generate precise 2D bounding boxes for diverse objects including people, humanoid robots, autonomous vehicles, and warehouse equipment.
RT-DETR features an EfficientViT/L2 backbone, pretrained on warehouse scene datasets for accurate 2D object detection in industrial environments.
It sends frame data, including detected and tracked object IDs, in Protobuf format to the Kafka messaging system via the
mdx-rawtopic.
Kafka (Messaging System) (link):
Kafka serves as the central hub for data distribution, using Protobuf for all data exchanges.
It also functions as a control bus, managing notifications (in JSON, via
mdx-notification) for calibration updates, such as new ROI or tripwire definitions.
Behavior Analytics (link):
This microservice consumes
mdx-rawdata (Protobuf) from Kafka.It processes the data to generate behavior analytics, safety insights, and metrics.
The resulting data, in Protobuf format, is sent back to Kafka for indexing into Elasticsearch.
Storage
ELK (Elasticsearch, Logstash, Kibana) (link): Logstash retrieves mdx-raw outputs and safety violation frames from Kafka, converts Protobuf to JSON, stores the data in Elasticsearch, and supports querying and visualization.
Visualization
Kibana UI (link): A user interface for visualizing analytics data stored in Elasticsearch.
VIOS UI (link): A separate interface for interacting with the VIOS system, receiving JSON notifications from Kafka.
Video Analytics UI (link): A browser based user interface for visualizing the moving objects, live camera feeds along with events and metrics. This is a sample UI to interact with the underneath data through Video Analytics API.
External Interfaces
API Gateway and MCP (link): Enables external systems to interact with the events data through API calls.
Agents
Agentic Reference UI (link): The Warehouse Blueprint incorporates an agentic AI system that provides natural language interaction capabilities for querying warehouse safety incidents, generating reports, and retrieving visual information from warehouse cameras.
Key Technologies#
Microservices: Components like NvStreamer, VIOS, DeepStream, and Behavior Analytics are modular microservices.
RTSP: Facilitates real-time video streaming.
Protobuf: Ensures efficient, compact data exchange.
Kafka: Manages data distribution and control messaging.
ELK Stack: Supports storage, logging, and visualization.
JSON: Used for notifications and calibration data.
Setup and Configuration#
Testing and Validation#
Kibana UI#
Note
In the new Kibana UI (versions 8.0 and later), “Index Patterns” have been renamed to “Data Views”.
Check for Events, Frames and Behavior Data Views in Kibana
Launch Chrome browser
In the address bar enter
http://<IP_address>:5601
In the user interface, navigate to the Management -> Stack Management section and select Data Views under Kibana. If the data views are not visible, create new data view (via “Create data view” button on the top right corner) for mdx-raw, mdx-frames and mdx-behavior.
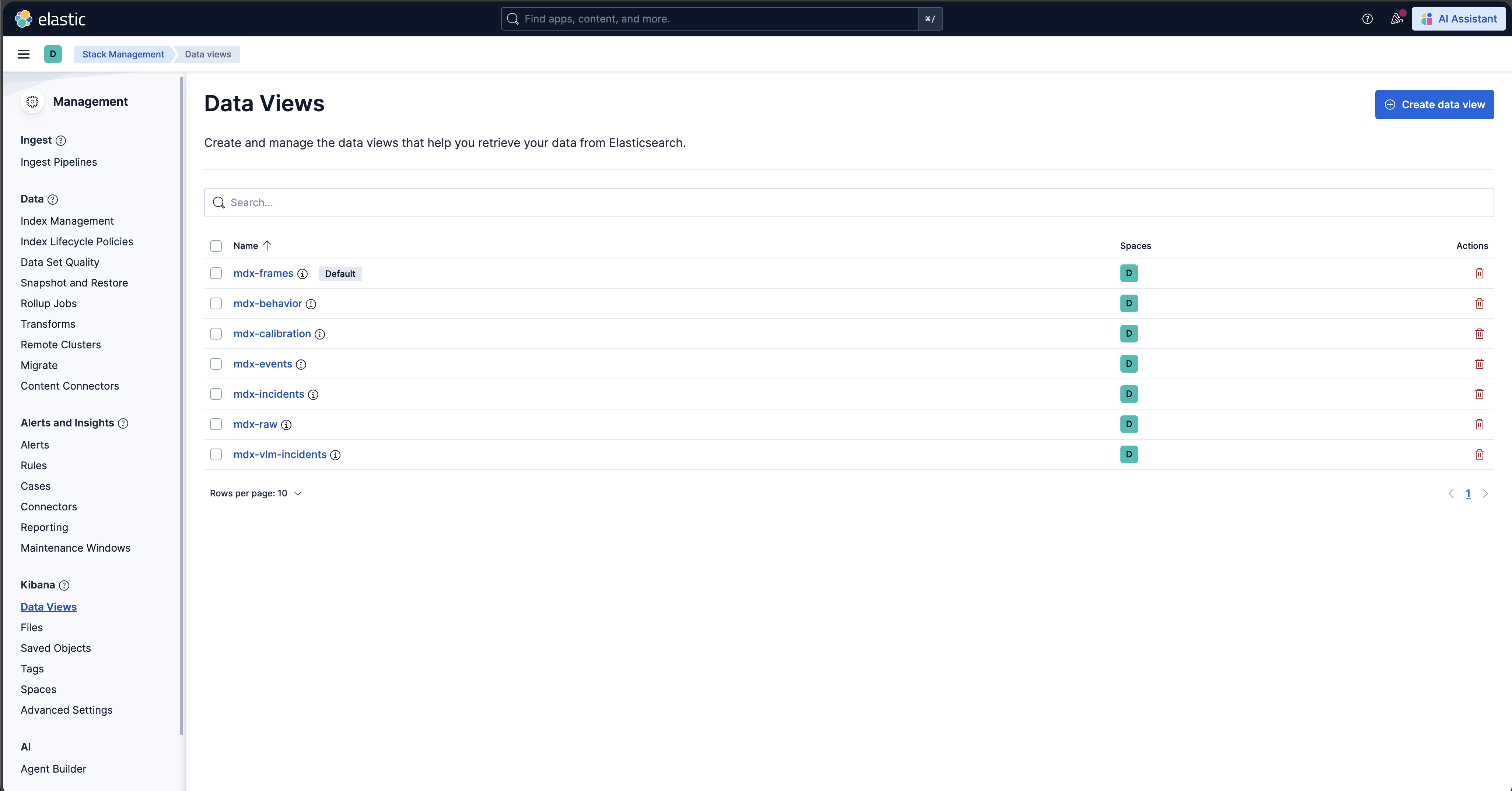
Browse the Kibana UI, discover the data views and visualize the data.
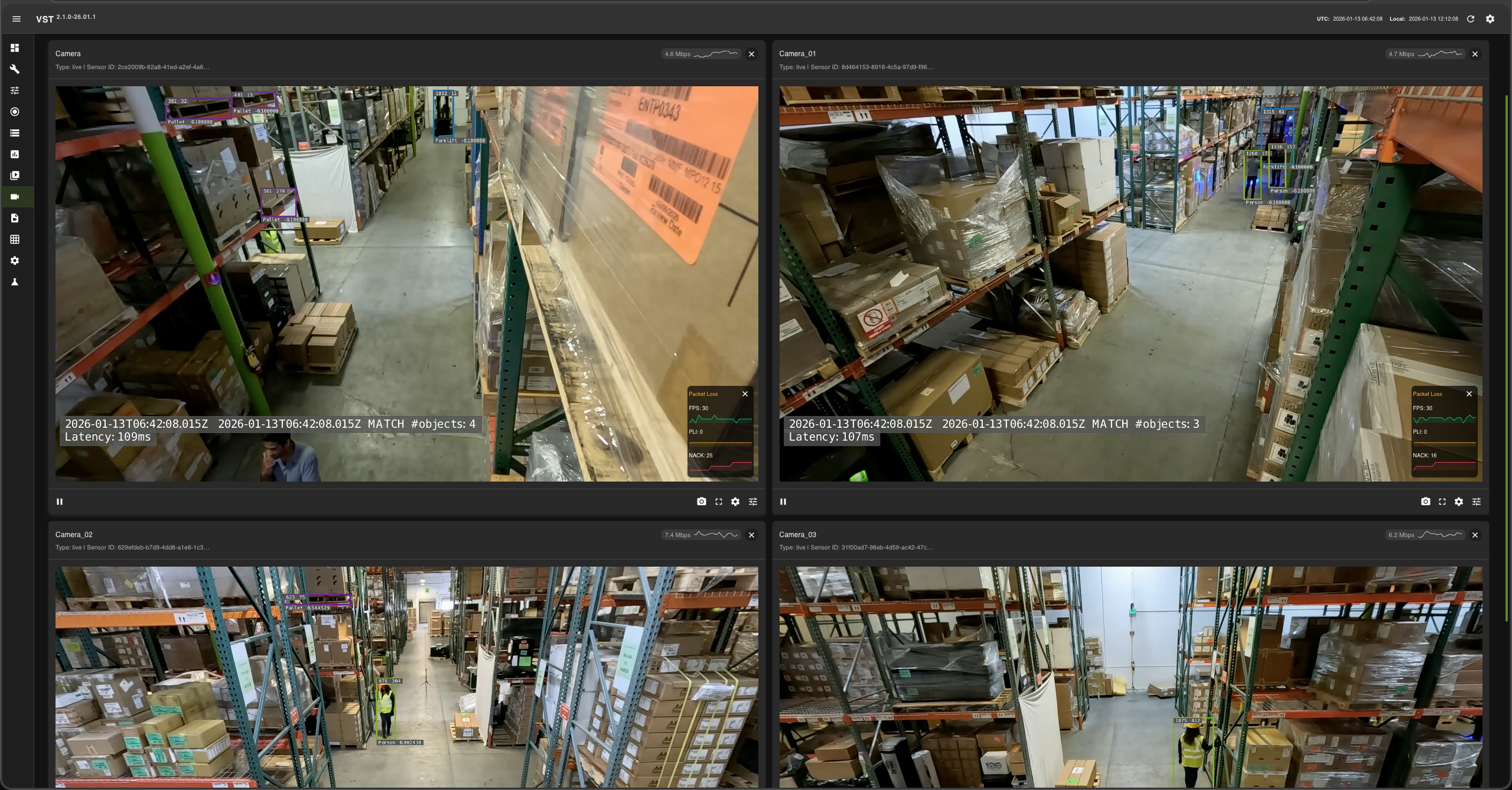
VIOS UI#
Please note: At this point the web-based application is only available for Chrome browser running on Linux, Windows or MacOS, details can be found in VIOS docs.
Launch Chrome browser
In the address bar enter
http://<IP_address>:30888/vst/
Configure and View
Reference Video Analytics UI#
We provide a sample browser-based user interface for visualizing the moving objects, live camera feeds along with events and metrics. Details can be found in Reference Video Analytics UI.
Launch Chrome browser
In the address bar enter
http://<IP_address>:3002
Configure and View
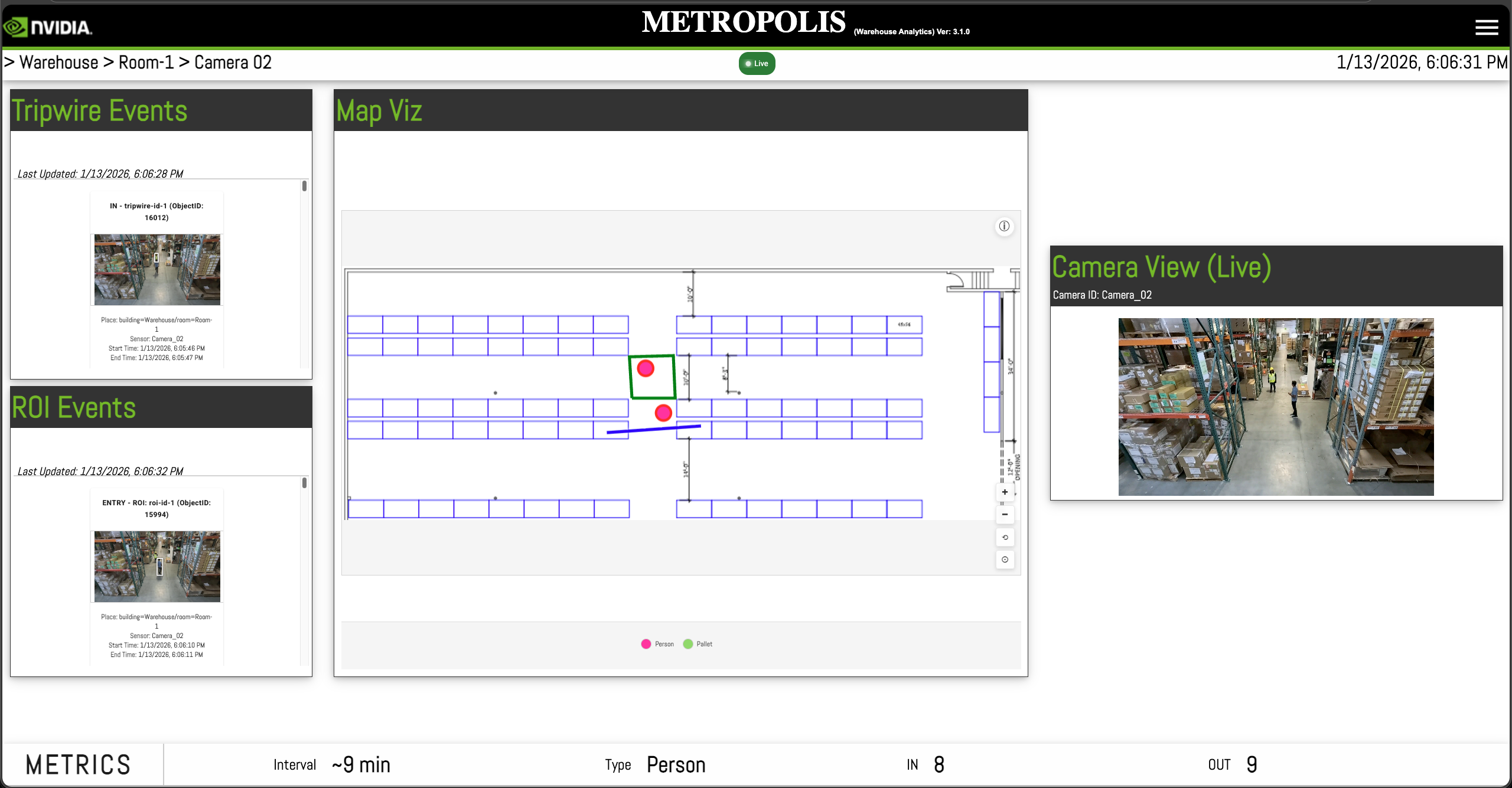
Reference Agentic UI#
The browser-based interface supports Chat, Alerts, Dashboard, and Video Management modes. Details can be found in Reference Agentic UI.
Launch Chrome browser
In the address bar enter
http://<IP_address>:3000
Configure and View
KPI & Metrics#
Performance#
System |
Model |
No. of streams |
Fps |
(NvStreamer + VIOS + DeepStream) latency |
Behavior-analytics latency |
E2E latency |
|---|---|---|---|---|---|---|
NVIDIA DGX Spark + ARM Cortex-X925/A725 20-Core (4.0GHz) |
RT-DETR |
4 |
30 |
86 ms |
16 ms |
102 ms |
NVIDIA IGX Thor + ARM 14-Core (2.6GHz) |
RT-DETR |
4 |
30 |
183 ms |
39 ms |
222 ms |
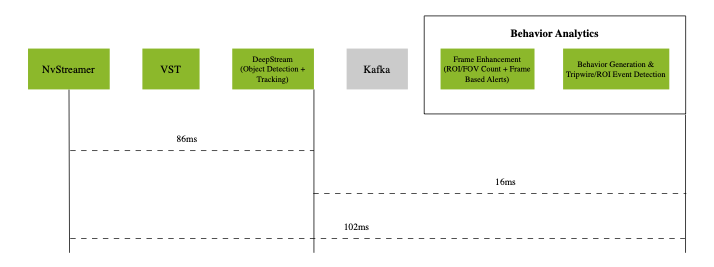
Latency Measurements on DGX Spark (p50)
The above diagram shows the p50 latency of the VSS Warehouse 2D Blueprint, measured using an NVIDIA DGX Spark + ARM Cortex-X925/A725 20-Core (4.0GHz) with 4 streams at 30 fps for RT-DETR model.
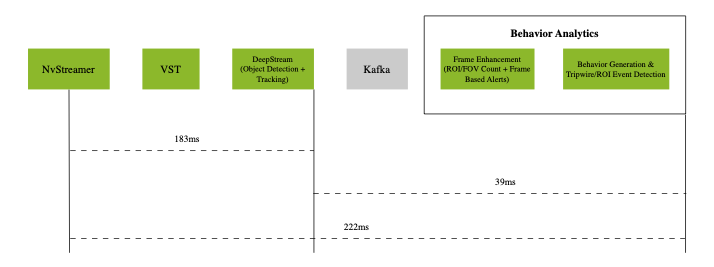
Latency Measurements on IGX Thor (p50)
The above diagram shows the p50 latency of the VSS Warehouse 2D Blueprint, measured using an NVIDIA IGX Thor + ARM 14-Core (2.6GHz) with 4 streams at 30 fps for RT-DETR model.
The system demonstrates the following p50 latency breakdown:
Video pipeline (nvStreamer + VIOS + DeepStream): 86ms with DGX Spark, 183ms with IGX Thor for RT-DETR model
Behavior analytics pipeline: 16ms with DGX Spark, 39ms with IGX Thor
The end-to-end system latency is 102ms with DGX Spark, 222ms with IGX Thor at p50.
Note
The latency may vary based on the hardware, the number of objects in a scene, the number of ROIs and tripwires, and the machine’s load.
Customization#
The Blueprint supports several levels of customization:
Data Level: Add, remove, or replace cameras while maintaining the existing workflow
Model Level: Fine-tune perception models or integrate different LLM models to better suit your use cases
Application Level: Build new microservices or applications using the provided APIs and components
Microservice Level: Modify existing microservices from source code to extend functionality
Adding New Cameras#
Prepare and Calibrate New Cameras#
Before integrating a camera into the VSS Warehouse 2D Vision AI with Agents Profile workflow, you must generate a proper calibration file.
The 2D Vision AI with Agents Profile supports both live RTSP feeds and recorded video files from real cameras. Both require proper calibration files.
For detailed instructions on calibrating real cameras for 2D use case, see Manual Calibration Guide.
As an easier alternative, you can use the VSS Auto Calibration microservice to automatically calibrate cameras through a simple, web-based workflow and generate a calibration file from archived videos, without manual steps or downtime. For details, see VSS Auto Calibration.
Integrating New Cameras#
There are two approaches to integrate new cameras into the 2D Warehouse Blueprint:
Option 1: NvStreamer/VIOS (Recorded Videos)
Use this approach for recorded videos or when managing cameras using NvStreamer/VIOS.
Configure NvStreamer/VIOS:
For recorded videos:
First upload videos to NvStreamer (see uploading videos section)
Then add RTSP links to VIOS (see add camera section)
For live feeds: Directly add RTSP links to VIOS (see add camera section)
Update DeepStream Configuration:
Modify the source-list in the DeepStream configuration
Update sensor count and batch size settings
See source config section for details
Update Calibration File:
Maintain a single calibration.json file per deployment
Add new camera information following the schema defined in Schema Documentation
Reference Prepare and Calibrate New Cameras for guidance
Option 2: Live RTSP Feeds
Use this approach for realtime RTSP streams when you want to define camera configurations declaratively via a JSON file.
Create a Sensor Info File (
camera_info.json):{ "sensors": [ { "camera_name": "camera-01", "rtsp_url": "rtsp://192.168.1.100:554/stream1", "group_id": "entrance-group", "region": "building-A" }, { "camera_name": "camera-02", "rtsp_url": "rtsp://192.168.1.101:554/stream1", "group_id": "entrance-group", "region": "building-A" } ] }
Required fields:
camera_name,rtsp_urlOptional fields:
group_id,region(can also be obtained from calibration data)Configure Blueprint Configurator Environment Variables:
SENSOR_INFO_SOURCE=file SENSOR_FILE_PATH=<path_to_camera_info.json>
Update Calibration File:
Ensure your
calibration.jsonincludes calibration data for all cameras defined in the sensor info file.Refer to Prepare and Calibrate New Cameras for guidance.
Configuring Number of Streams
For both approaches, the number of streams/sensors to be processed can be configured in two ways:
Static Configuration: Set the
NUM_STREAMSenvironment variable to specify the desired number of streams.NUM_STREAMS=4
The configured number of streams should be less than or equal to the maximum streams supported by your hardware profile and deployment mode. Blueprint Configurator can be used to automatically cap the stream count using the formula:
final_stream_count = min(NUM_STREAMS, max_streams_supported). For more details, refer to the How to Count Files Dynamically (Prerequisites) section in Blueprint Configurator Documentation.Dynamic Configuration: Use the Blueprint Configurator’s prerequisite operations to automatically count the number of video files in the recorded videos directory and use that count for configuration updates. Please note that this approach cannot be used for live RTSP feeds.
Example: Automatically determine stream count from video files in dataset directory:
# In blueprint_config.yml commons: # Step 1: Count video files BEFORE variable processing prerequisites: 2d: - operation_type: "file_management" target_directories: - "${MDX_DATA_DIR}/videos/warehouse-2d-app" file_management: action: "file_count" parameters: pattern: "*.mp4" output_variable: "available_video_count" # Stores count (e.g., 6) # Step 2: Use the count to compute final stream count variables: 2d: # Cap to minimum of: available videos, GPU limit - final_stream_count: "min(${available_video_count}, ${max_streams_supported})" # Step 3: Use computed variable in config file updates file_operations: 2d: - operation_type: "yaml_update" target_file: "${DS_CONFIG_DIR}/config.yaml" updates: num_sensors: ${final_stream_count}
How it works: If your dataset directory has 6 video files, and GPU supports max 4 streams, the configurator computes:
final_stream_count = min(6, 4) = 4. For more details, refer to the How to Count Files Dynamically (Prerequisites) section in Blueprint Configurator Documentation.
Model Customization#
Perception Model Fine-tuning#
The Blueprint uses RT-DETR (Real-Time Detection Transformer) as its primary perception model. RT-DETR features an EfficientViT/L2 backbone and is pretrained on warehouse scene datasets for precise 2D object detection in industrial environments. For details, see: 2D Single Camera Detection and Tracking.
For fine-tuning the RT-DETR model via TAO Toolkit on custom datasets, refer to: TAO RT-DETR Finetuning.
LLM Integration#
Integrate different LLM services or locally deployed models in the agent.
VLM Custom Weights#
The Warehouse Blueprint supports using VLM custom weights for specialized use cases. You can download custom weights from two sources:
From NGC
# Set your NGC API key if not already set
export NGC_CLI_API_KEY='your_ngc_api_key'
# Download custom weights from NGC
ngc registry model download-version <org>/<team>/<model>:<version>
# Move downloaded custom weights to desired path/folder
mv </downloaded/path/in/ngc/output> </path/to/custom/weights>
From Hugging Face
You can download from Hugging Face using either the Hugging Face CLI or Git LFS:
Option 1: Using Hugging Face CLI
# Install Hugging Face CLI if not already installed
pip install -U "huggingface_hub[cli]"
# Login to Hugging Face (required for gated models)
hf auth login
# Create a base directory where the custom weights can be downloaded
mkdir -p </path/to/custom/weights>
# Download a model
hf download <model-id> --local-dir </path/to/custom/weights>
Option 2: Using Git LFS
# Install Git LFS if not already installed
sudo apt install git-lfs
git lfs install
# Clone the model repository
git clone https://huggingface.co/<model-id> </path/to/custom/weights>
Note
Some Hugging Face models may be gated and require access approval. Visit the model page on Hugging Face and request access if needed.
Verify Downloads
After downloading custom weights, verify the directory structure and contents:
# List the contents of the weights directory
ls -lrh </path/to/custom/weights>
Typical VLM weight directories contain:
Model configuration files (e.g.,
config.json)Model weights (e.g.,
pytorch_model.bin,model.safetensors, or sharded weights)Tokenizer files (e.g.,
tokenizer.json,tokenizer_config.json)Other metadata files
Configure Custom Weights
After downloading custom weights, update the .env file to use them:
# Set the path to custom weights
export VLM_CUSTOM_WEIGHTS="</path/to/custom/weights>"
# Update the .env file
sed -i \
-e "s|^# VLM_CUSTOM_WEIGHTS.*|VLM_CUSTOM_WEIGHTS=\"${VLM_CUSTOM_WEIGHTS}\"|" \
warehouse/.env
OR Update the .env file manually Set VLM_CUSTOM_WEIGHTS to the path where your custom weights are located.
VLM_CUSTOM_WEIGHTS="/path/to/custom/weights"
Application Customization#
The Blueprint uses a modular microservices architecture with the following communication channels:
Kafka message broker
Elasticsearch database
REST APIs
User can build their own microservices by consuming data from above channels.
For complete API documentation, see API Reference Page.
Available Service Ports#
The following ports are used during the deployment, and users can leverage for any potential integration:
Service |
Port |
|---|---|
Calibration-Toolkit |
8003 |
Kafka |
9092 |
ZooKeeper |
2181 |
Elasticsearch |
9200 |
Kibana |
5601 |
NvStreamer |
31000 |
VIOS |
30888/vst |
Video Analytics API |
8081 |
Reference Video Analytics UI |
3002 |
Reference Agentic UI |
3000 |
Nemotron |
30081 |
CR2 |
30082 |
Phoenix UI |
6006 |
Analytics Microservices Customization (Advanced)#
For detailed information about customizing specific analytics microservices, refer to:
Hardware Config Customization#
The 2D Warehouse Blueprint requires several configuration files to be properly tuned based on your GPU hardware and deployment requirements. When changing hardware (e.g., switching from H100 to L4 GPU) or adjusting the number of video streams, multiple configuration files must be updated to ensure optimal performance and prevent GPU overload.
Configuration Files Requiring Hardware-Based Updates#
The following table lists the configuration files that typically require updates when hardware changes:
Configuration File |
Parameters to Update |
Why Update is Needed |
|---|---|---|
|
|
Batch sizes must match stream count for optimal GPU utilization |
|
|
Same as above for Redis-based deployments |
|
|
Sync file count must align with stream count |
|
|
Device limits must match GPU capacity |
|
|
Same as above for Redis-based deployments |
There are two approaches to customize these configuration files:
Approach 1: Manual Configuration#
Manually update all required configuration files before deploying the blueprint. This is time consuming, error prone and often not suitable for production deployments.
# Update DeepStream main config
vi <PATH_TO_DS_CONFIG_DIR>/ds-main-config.txt
# Set: num-source-bins=0, max-batch-size=<stream_count>, batch-size=<stream_count>
# Update DeepStream Redis main config
vi <PATH_TO_DS_CONFIG_DIR>/ds-main-redis-config.txt
# Set: num-source-bins=0, max-batch-size=<stream_count>, batch-size=<stream_count>
# Update NvStreamer config
vi <PATH_TO_NVSTREAMER_CONFIG_DIR>/vst-config.json
# Set: "nv_streamer_sync_file_count": <stream_count>
# Update VST Kafka config
vi <PATH_TO_VST_CONFIG_DIR>/vst_config_kafka.json
# Set: "max_devices_supported": <max_streams>, "always_recording": true
# Update VST Redis config
vi <PATH_TO_VST_CONFIG_DIR>/vst_config_redis.json
# Set: "max_devices_supported": <max_streams>, "always_recording": true
Approach 2: Automatic Config Management using Blueprint Configurator#
The Blueprint Configurator provides a declarative approach to automatically update all required configuration files based on your hardware profile and deployment mode. This is the recommended approach for production deployments and simplifies the configuration management process.
To enable the Blueprint Configurator, in Blueprint Configurator’s environment variables you must set:
ENABLE_PROFILE_CONFIGURATOR=true
By default, the Blueprint Configurator is disabled (ENABLE_PROFILE_CONFIGURATOR=false).
When enabled, it runs before the Blueprint Deployment starts and adjusts configuration files based on the hardware profile and deployment mode as defined in the HARDWARE_PROFILE and MODE environment variables.
The Blueprint Configurator provides a comprehensive set of features for automated profile configuration management:
Feature |
Description |
|---|---|
Configuration File Updates |
Automatically update configuration files in multiple formats:
|
Environment Variable Validation |
Validate environment variables before deployment to catch configuration errors early:
|
Prerequisite Operations |
Run operations before variable processing to dynamically determine values:
|
Variable Computations |
Create computed variables for intermediate calculations and condition checking. Use case: Automatically cap stream count to GPU limits using
|
Execution Order: Prerequisite Operations → Environment Variable Validation → Variable Computations → Configuration File Updates
For detailed information on how to create custom hardware profiles and advanced configuration options, refer to the Profile Configuration Manager section in Blueprint Configurator Documentation.