SDK Getting Started¶
DirectX12¶
NVIDIA HairWorks 1.2 for DirectX12 is under active development, and is NOT AVAILABLE within this public release. The documentation on DirectX12 usage and the Sdk headers are for illustrative purposes only and may be subject to change. Early access to HairWorks 1.2 for DirectX12 is available to developers on request at visualfx-licensing@nvidia.com
Directory structure¶
- bin : Executables and DLL files
- docs : Documentations for DCC Plugin and Viewer
- src : Header files and source for HairWorks library integration
- media : Sample art resources
- samples : Sample projects for HairWorks library integration
- include : Just the header files from the src directory (generally better to just include Src in your project)
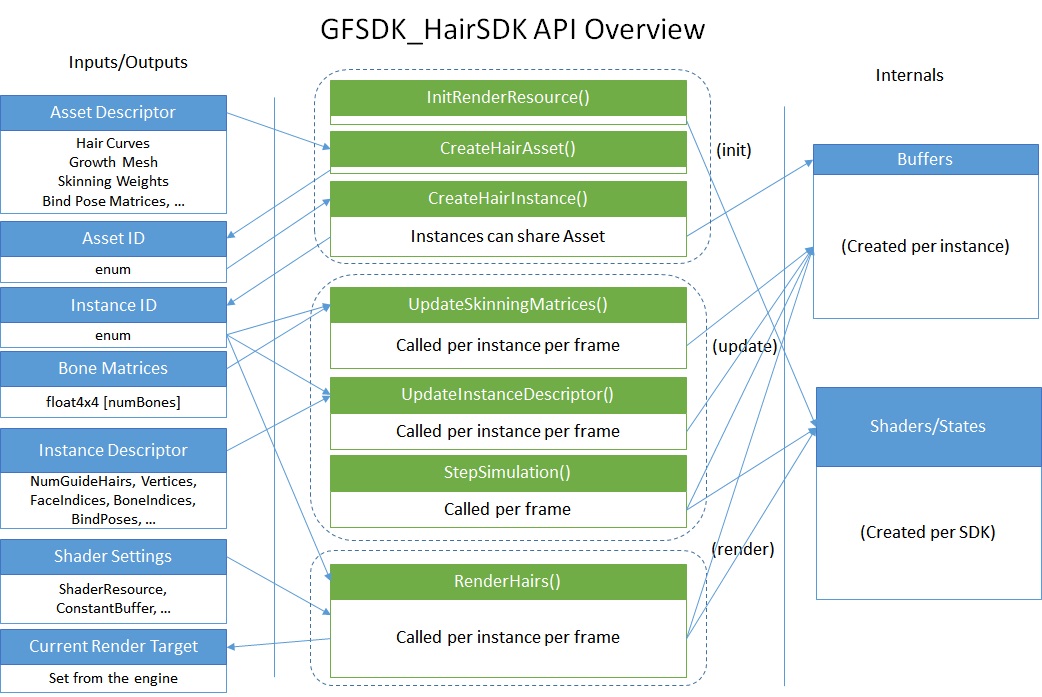
API Overview¶
HairWorks SDK provides various API functions to manage assets and GPU resources, render and simulate hairs. Above diagram summarizes how each API calls relates to user inputs (left) and internal resources (right). Main header file is located in src/Nv/HairWorks/NvHairSdk.h and must be included to use HairWorks data structures and runtime APIs. All the API functions are encapsuled by an abstract API class NvHair::Sdk.
HairWorks runs on any DirectX11 and DirectX12 capable GPU devices and requires dx11 and/or dx12 runtime.
Note that whilst Dx11 is available on a wide selection of Windows operating systems, and can be compiled with many different versions of Visual Studio, currently DirectX12 is only available on Windows 10 and can only be built with Visual Studio 2015.
Initialization¶
Loading the library¶
The first step is to locate and load the HairWorks dll (located in bin\win32 and bin\win64). Make sure your runtime path points to the directory or copy the dll to your bin path.
For Dx11 to load the library:
#include <Nv/HairWorks/NvHairSdk.h> // hairworks main header file
#include <Nv/HairWorks/Platform/Win/NvHairWinLoadSdk.h> // Only needed to load the Dll on windows
// Provides mechanisms to wrap Dx11 types such that they can be passed to HairWorks Sdk
#include <Nv/Common/Platform/Dx11/NvCoDx11Handle.h>
NvHair::Sdk* hairSdk = NvHair::loadSdk("NvHairWorksDx11.win64.dll", NV_HAIR_VERSION);
For Dx12 to load the library:
#include <Nv/HairWorks/NvHairSdk.h> // hairworks main header file
#include <Nv/HairWorks/Platform/Win/NvHairWinLoadSdk.h> // Only needed to load the Dll on windows
// Provides mechanisms to wrap Dx12 types such that they can be passed to HairWorks Sdk
#include <Nv/Common/Platform/Dx12/NvCoDx12Handle.h>
// Provides types and mechanisms for custom Dx12 types needed to work with HairWorks and Dx12
#include <Nv/HairWorks/Platform/Dx12/NvHairDx12SdkHandle.h>
NvHair::Sdk* hairSdk = NvHair::loadSdk("NvHairWorksDx12.win64.dll", NV_HAIR_VERSION);
A custom memory allocator may be supplied as an optional argument. See the header file.
Hair Assets and Instances¶
HairWorks defines two different types of hair data - asset (NvHair::AssetDescriptor) and instance (NvHair::InstanceDescriptor).
A hair asset stores all the geometry data such as hair curves, skinning weights, etc., which are authored outside of HairWorks runtime and do not change during runtime. All the asset data reside in CPU memory once loaded and do not consume any GPU memory, thus do not require DirectX runtime to exist.
From each asset, users can instantiate multiple hair instances and its runtime behavior is controlled by the instance descriptor. Creation of each instance requires GPU buffers to be allocated and managed, thus requires DirectX runtime to be initialized beforehand. Separation of assets from instances allows users to share the same hair asset to create multiple characters, and efficiently manage GPU resources when hairs are not needed in certain parts of game.
Loading the hair asset¶
HairWorks provides multiple ways to load hair asset data.
Files prefixed with NvCo and which live in Nv/Common make up the NvCommon library which provides support functionality to HairWorks. All types in library are in the nvidia::Common namespace. You can load a hair asset from the .apx/.apb file (generated by DCC tool or FurViewer) using:
#include <Nv/Common/Platform/StdC/NvCoStdCFileReadStream.h> // For reading from a file // Create a ReadStream that in this case will allow reading from a file "test.apx" NvCo::StdCFileReadStream stream("test.apx"); // The id for the read hair asset will be stored in NvHair::AssetId assetId; // Functions that can return errors do so through Nv::Result type that is similar to a COM HRESULT. Test for // success or failure using the macros NV_SUCCEEDED() or NV_FAILED(). NvResult res = hairSdk->loadAsset(&stream, assetId, NV_NULL, NV_NULL); if (NV_FAILED(res)) { // Hit a problem return; }
, or you can directly load it from memory buffer (e.g. when custom file system is used) using:
void* buffer = ...; // user pointer that stores the entire apx file in memory NvSizeT bufferSize = ...; // size of the user memory buffer NvCo::MemoryReadStream(buffer, bufferSize); NvResult res = hairSdk->loadHairAsset(&stream, assetId, NV_NULL, NV_NULL);
, or you can manually fill in the asset descriptor (GFSDK_HairAssetDescriptor) and create a hair asset from it:
NvHair::AssetDescriptor desc; desc.m_numGuideHairs = 4; // number of guide hairs desc.m_numVertices = 20; // number of total hair cvs desc.m_vertices = vertices; // cv position data desc.m_endIndices = endIndices; // index to last cv for each guide curve ... NvHair::AssetId assetId; NvResult res = hairSdk->create(desc, assetId);
All above APIs output a unique hair asset ID (NvHair::AssetId) that can be later used to identify the hair asset for further modification and instance creation, so save this ID somewhere.
Initializing D3D runtime¶
When D3D device is created and intialized, initialize HairWorks runtime using the method initRenderResources. This will initialize all the global GPU resources used by HairWorks runtime such as shaders, etc.
For Dx11 use:
#include <Nv/Common/Platform/Dx11/NvCoDx11Handle.h> /// Needed to wrap Dx11 handles
ID3D11Device* device = ...;
ID3D11DeviceContext* deviceContext = ...;
// Initialize DirectX settings for HairWorks runtime
m_hairSdk->initRenderResources(NvCo::Dx11Type::getHandle(device), NvCo::Dx11Type::getHandle(deviceContext));
For Dx12 use:
#include <Nv/Common/Platform/Dx12/NvCoDx12Handle.h> /// Needed to wrap Dx12 handle
ID3D12GraphicsCommandList* commandList = ...;
ID3D12Device* device = ...;
// Initialize this structure define the render target being rendered to
NvHair::Dx12InitInfo initInfo;
initInfo.m_targetInfo = ...;
// Initialize DirectX settings for HairWorks runtime
m_hairSdk->initRenderResources(NvCo::Dx12Type::wrap(device), NvCo::Dx12Type::wrap(commandList), NvHair::Dx12SdkType::wrapPtr(&initInfo));
An important difference between Dx11 and Dx12 is with Dx12 HairWorks has to manage the lifetime of transient resources. To do this it is the responsibility of the app to inform HairWorks when work is submitted to the GPU, such that hairworks can track the GPU state and know when resources are no longer needed. Use:
ID3D12CommandQueue* commandQueue = ...;
// The command list that is being used for HairWorks work
ID3D12GraphicsCommandList* commandList = ...;
// Close the command list so it can be executed.
NV_RETURN_VOID_ON_FAIL(commandList->Close());
// Submit it
ID3D12CommandList* commandLists[] = { commandList };
commandQueue->ExecuteCommandLists(NV_COUNT_OF(commandLists), commandLists);
// Inform hair works - doing so will add a fence to the queue, and also do other work to release resources
m_hairSdk->onGpuWorkSubmitted(Dx12Type::wrap(commandQueue));
NOTE! If onGpuWorkSubmitted is not called HairWorks will leak both GPU and CPU resources. If called in an inappropriate location, or which the wrong queue the behavior is undefined.
Creating and deleting hair instances¶
Once the DirectX runtime was initialized, we can start creating hair instances using:
NvHair::InstanceId instanceId;
NvResult res = hairSdk->createInstance(assetId, instanceId);
When hair instances are no longer needed, delete the resource using:
hairSdk->freeInstance(instanceId);
Runtime Controls¶
To simulate and render hairs, use the API functions described in this section. In many situations, users may want to separate code path for animation/simulation from rendering control flow. For each such code path, one needs to set the followings.
Setting context and camera¶
Set render context for HairWorks:
// For Dx11 ID3D11DeviceContext* deviceContext = ...; hairSdk->setCurrentContext(NvCo::Dx11Type::getHandle(deviceContext)); // For Dx12 ID3D12GraphicsCommandList* commandList = ...; m_hairSdk->setCurrentContext(Dx12Type::wrap(commandList));
Set view matrix and projection matrix:
XMMATRIX projection; // ... get projection matrix from your camera definition XMMATRIX view; // ... get model view matrix from your camera definition hairSdk->setViewProjection((const gfsdk_float4x4*)&view,(const gfsdk_float4x4*)&projection);
A hint about handedness of the camera may be supplied (used for backface culling feature). It is important to provide correct camera information as many features such as LOD rely on camera info. If your application has multiple windows with different camera settings, make sure to provide each camera info properly before calling the APIs below.
Updating control parameters¶
By default, HairWorks use control parameters stored in the asset. By updating instance descriptor, users can change all the control parameters anytime during runtime:
NvHair::InstanceDescriptor desc;
desc.m_width = 0.2;
desc.m_density = 1.0;
desc.m_lengthNoise = 0.0f;
desc.m_simulate = true;
...
hairSdk->updateInstanceDescriptor(instanceId, desc);
Animating Hairs¶
To move and animate hairs, a typical process is to give it an animation first, by updating bones used to skin animated hair shapes. Once skinning data are set, we call StepSimulation() to simulate motion of hairs for each frame.
Updating skinning data¶
A skinning matrix is defined as inverse(bind pose) * world space bone matrix. This is exactly the same matrix you would use to skin underlying character mesh vertices.
Note that number of bones and bone orders must match the ones defined in the asset descriptor. (see the setBoneRemapping() API to deal with bone number/order mismatch issue).
HairWorks provide the following options to update skinning.
Updating the skinning with linear matrix:
hairSdk->updateSkinningMatrices(instanceId, numBones, skinningMatrices);
Updating the skinning with dual quaternion:
hairSdk->updateSkinningDqs(instanceId, numBones, dualQuats);
Note: If skinning update APIs are not used, HairWorks uses identity transform for all the skinning data.
Simulating/Animating Hair¶
To activate simulation, m_simulate member of NvHair::InstanceDescriptor must be set to true:
// Stored elsewhere... // NvHair::InstanceDescriptor hairDesc; hairDesc.m_simulate = true; g_hairSdk->updateInstanceDescriptor(instanceId, hairDesc);
To simulate hairs use:
hairSdk->stepSimulation();
This function simulates all active hair instances in a batch call. Note that if m_simulate is set to false, hairs will be animated due to the skinning data. So it is important to use this function even if you only want skinning based animation.
Rendering¶
To render hairs, users need to set device context and camera info as above. Then users would set pixel shader and other rendering resources if needed. Then calling renderHairs() API will draw hairs onto current render target buffers.
m_hairSdk->renderHairs(m_instanceId);
NOTE There must have been at least one simulation step before rendering will work correctly. The step doesn’t have to actually simulate (m_simulate can be false on the InstanceDescriptor), but the function must be called to initialize the instance before rendering. The method stepInstanceSimulation can be used to step the simulation on a single instance, if it’s not possible to call stepSimulation before first render.
There are two other optional parameters to the renderHairs method - the first provides extra general rendering options, whilst the final parameter is rendering API specific and can be used for custom shaders, custom buffers for example on Dx12.
To provide maximum flexibility in hair rendering, HairWorks allows the replacement of the pixel shader stage of rendering.
Customizing shader resources and constant buffers¶
HairWorks provide the following APIs for customized shader resource managment.
- NvHair::ShaderSettings
In renderHairs() call, users can provide additional shader settings to indicate what part of shader pipeline will be customized by the users.
- prepareShaderConstantBuffer()
HairWorks shaders need some global info such as camera projection, hair materials to be defined in a constant buffer. This API facilitate preparation of such constant buffers.
See sample codes for more details of how these APIs and hair shaders work.
Custom hair shaders on Dx11¶
We also provide example hair pixel shaders in the included sample code.
Users can use such hair shaders or modified version of them to best suit their needs. It is user’s responsibility to create and manage such shaders.
Set your hair pixel shader before rendering hairs:
d3dContext->PSSetShader(myCustomHairWorksShader, NULL, 0);
Custom hair shaders on Dx12¶
Unlike in Dx11 because Dx12 is ‘closer to the metal’ there has to be far more coordination between the app and HairWorks to use shaders. First it is necessary to register shaders with HairWorks:
// Create custom pixel shader for HairWorks rendering
{
ComPtr<ID3DBlob> pixelBlob;
NV_RETURN_ON_FAIL(DxUtil::findAndReadShader(m_app, SMP_HAIR_SAMPLE_ROOT "/Dx/Shader/ShadingHairShader.hlsl", "ps_main", "ps_5_0", D3DCOMPILE_ENABLE_STRICTNESS, 0, pixelBlob));
NvHair::Dx12PixelShaderInfo pixelInfo;
pixelInfo.m_pixelBlob = (const UInt8*)pixelBlob->GetBufferPointer();
pixelInfo.m_pixelBlobSize = pixelBlob->GetBufferSize();
pixelInfo.m_targetInfo = ...;
pixelInfo.m_hasDynamicConstantBuffer = true;
pixelInfo.m_numSrvs = NvHair::ShaderResourceType::COUNT_OF + 2;
// Okay try setting it
m_hairSdk->setPixelShader(0, NvHair::Dx12SdkType::wrapPtr(&pixelInfo));
}
Here the NvHair::Dx12PixelShaderInfo structure is filled in with the information about the shader. The targetInfo describes the render target that will be rendered to. This shader uses two custom shader resource views over the standard ones. The m_hasDynamicConstantBuffer enables a feature where hairworks will handle management of constant buffer upload, and it’s contents can just be passed as a pointer to memory on rendering. The last line sets the shader index 0 to be this shader if successful.
This can then be rendered as follows:
{
D3D12_CPU_DESCRIPTOR_HANDLE srvs[NvHair::ShaderResourceType::COUNT_OF + 2];
// Get shader resources (these may change each render/simulate)
m_hairSdk->getShaderResources(m_instanceId, NV_NULL, NvHair::ShaderResourceType::COUNT_OF, Dx12Type::wrapPtr(srvs));
// Get the additional textures
const NvHair::ETextureType types[] = { NvHair::TextureType::ROOT_COLOR, NvHair::TextureType::TIP_COLOR };
m_hairSdk->getTextures(m_instanceId, types, NV_COUNT_OF(types), Dx12Type::wrapPtr(srvs + NvHair::ShaderResourceType::COUNT_OF));
NvHair::Dx12RenderInfo renderInfo;
renderInfo.init();
renderInfo.m_srvs = srvs;
m_hairSdk->renderHairs(m_instanceId, NV_NULL, NvHair::Dx12SdkType::wrapPtr(&renderInfo));
}
NOTE that the default hairworks shader on Dx12 is shader index 0. If you wanted to use a shader set on another slot, it would be necessary to pass ShaderSettings as the second parameter and set m_shaderIndex to the shader slot required.
Frame Rate Independent Rendering¶
HairWorks consists of simulation and rendering systems, with the rendering typically being driven by the results of the simulation. The most simple coupling of simulation with rendering would be to step the simulation and then render the hair. In practice the rate of rendering is often dynamic with the complexity of a scene or other loads on a system causing the frame rate to vary significantly. Whilst in principal it is possible to have one simulation step coupled with a render - by varying the timeStep passed to the method stepSimulation, in practice this is problematic.
The problem in principal is that the simulation is most stable and deterministic if it operates at a suitably high fixed timeStep. Doing a simulation timeStep of 1/30 sec does not produce the same results of two steps of 1/60 sec - the results could be dramatically different. This difference depending on the hair and the simulation rate could be such that the hair simulation looks incorrect.
Thus in situations where you have a variable rendering frame rate, there are many important advantages to running the simulation with a fixed time step.
HairWorks 1.2 introduces Frame rate Independent Rendering (FIR). Using the feature it is possible to step the simulation at a fixed rate, and to render at an arbitrary frame rate. When hairworks renders using FIR it will interpolate between two simulation results such that the rendering motion remains smooth.
The API changes to support FIR are small - the main change is the introduction of preRender method, which takes ‘simulationInterp’ and stepSimulation which now has a ‘simulateOnly’ parameter. In previous versions of HairWorks stepSimulation did both simulation work, and the work performed by preRender. Splitting the functionality gives control to where simulation is turned into render data, potentially improving performance. More importantly for FIR it gives the application control on how simulation data is turned into render data - as preRender takes into account the current bones, the modelToWorldMatrix and the simulationInterp. NOTE! It is important that preRender is called before any rendering takes place - either by doing it as part of the simulationStep, or explicitly. The implementation does track if something has changed, and will only do the preRender work if it is needed. If a render related call before preRender is performed no action will be taken and an error written to the log. A render related call includes renderHairs, renderVisualization and somewhat less obviously getShaderResources. This is because what ‘getShaderResources’ returns can change with calls to preRender.
For FIR to work the ‘simulationInterp’ value needs to be >=0 and < 1. This controls how HairWorks renders the hair by interpolating between the last simulation state and the current state. If the value is set to 1, HairWorks will render the current simulation state which is the same behavior as with previous versions of HairWorks. If the value is less than 1 there will be an interpolation between positions of the last simulation step and the current one taking into account the currently set skinning bones and the current worldToModel matrix set on the instance descriptor. The taking into account of skin means that the interpolation is corrected such that hairs are always connected to the skin as defined by the bones.
In practice this means
- For a single game engine cycle, may cause 0, 1, or many fixed simulations to run
- Simulation steps should be run with simulationOnly = true
- The simulation should always be ahead (by some fraction of the simulation timestep) of the rendering. Thus the bones when set for the simulation are generally set ‘in the future’ of the current animation time
- preRender should be called with the correct interpolation between the last two simulation steps
- There must have been at least TWO simulation steps for FIR to work correctly
- preRender can be called many times inbetween simulation steps
- Pixel velocity is calcuated as the viewspace distance moved between the last preRender and the current preRender
- This means there can be many simulation steps inbetween preRender calls, and pixel velocity will be correct
- One preRender call can be used for multiple render calls (shadow, backbuffer etc)
- If the bones are incorrectly set for the simulation (say due to change in animation), the hair may still look correct because it remains bound to the skin
On the last point, if there is a significant amount of rotation, and motion during the FIR interpolation, the hair could penetrate the skin. This is because the bones correction does not take into account rotation, so hair (especially long hair pulled close to the head) may intersect. It is therefore important in general to set the simulation bones correctly.
In terms of the actual calculation FIR performs, it is an interpolation between the last two frames simulation values, with a correction for the currently set bones matrices, followed finally with the modelToWorld matrix transform.
A typical simulation step might look something like the following:
// The FrameCalculator is a help class (in NvCommon) that can calculate the interpolation, and number
// of simulation steps
NvCo::FrameCalculator& simCalc = ...;
const int numSimSteps = simCalc.addTime(timeStep);
if (numSimSteps > 0)
{
// The scale converts seconds into the value to drive the animation
const float animScale = m_animationSpeed * m_animationFps;
// Works out the amount of time from now to the previous simulation step
float simTimeElapsed = numSimSteps * simCalc.getTimeStep() + simCalc.getRemainingTime();
// Calculate how much animation time passes per step of simulation
const float animTimeStep = simCalc.getTimeStep() * animScale;
// Calculate initially the animation time for the next simulation step
float animTime = currentAnimTime + animTimeStep * 2 - animScale * simTimeElapsed;
// Do multiple simulation steps
for (int i = 0; i < numSimSteps; i++, animTime += animTimeStep)
{
// Update the skinning on all the hair instances for the current simulation steps
for (int j = 0; j < instances.getSize(); j++)
{
const NvHair::InstanceId instanceId = instances[i];
// Uses game engine to calculate the bones at the specified animation time
// and sets it on the instance
calcAnimationBones(hairSdk, instanceId, animTime);
}
// Step the simulation only (we don't want to do preRender to)
hairSdk->stepSimulation(simCalc.getTimeStep(), NV_NULL, false);
}
}
For rendering:
NvCo::FrameCalculator& simCalc = ...;
// Uses game engine to calculate the bones at the specified animation time
// and sets it on the instance
calcAnimationBones(hairSdk, instanceId, currentAnimTime);
hairSdk->preRender(simCalc.getInterp());
hairSdk->renderHairs(instanceId, &settings);
Note that
- Doing frame rate independent rendering adds some extra cost - as skinning, and interpolation is additionally needed
- Setting renderInterpolation = 1.0 leads to no interpolation and no cost
- HairWorks only interpolates position, not lighting so simulation rate needs to be high enough for that to be unnoticable
If FIR is used and it is possible that the animation bones set on the simulation can differ from the animation bones when that point in time is reached, renderInterpolation must always be < 1. The value can be effectively 1 (say 0.999999), but it cannot be >= 1 as if it is FIR will not be engaged, and hair will be incorrectly rendered with the bones that were set when the simulation step took place.
FIR and Simulation¶
Most of the HairWorks API returns results based on the last simulation step. FIR modifies HairWorks rendering by interpolating between two simulation steps and correcting with the currently set bones and model position. This means to make items not rendered by HairWorks but based on HairWorks simulation data (for example the hair pins position) render in sync with the hairworks rendering additional interpolation is needed. For example if there is a need to render a mesh at a hair pins position, and FIR is being used, then something like the following will be needed:
struct Instance
{
// Stored in some structure
NvHair::InstanceId m_instanceId;
gfsdk_float4x4 m_prevPinPosition;
gfsdk_float4x4x m_pinPosition;
};
Array<Instance> instances;
Do the simulation:
if (numSimSteps > 0)
{
// The scale converts seconds into the value to drive the animation
const float animScale = m_animationSpeed * m_animationFps;
// Works out the amount of time from now to the previous simulation step
float simTimeElapsed = numSimSteps * simCalc.getTimeStep() + simCalc.getRemainingTime();
// Calculate how much animation time passes per step of simulation
const float animTimeStep = simCalc.getTimeStep() * animScale;
// Calculate initially the animation time for the next simulation step
float animTime = currentAnimTime + animTimeStep * 2 - animScale * simTimeElapsed;
// Do multiple simulation steps
for (int i = 0; i < numSimSteps; i++, animTime += animTimeStep)
{
// Update the skinning on all the hair instances for the current simulation steps
for (int j = 0; j < instances.getSize(); j++)
{
Instance& instance = instances[i];
// Uses game engine to calculate the bones at the specified animation time
// and sets it on the instance
calcAnimationBones(hairSdk, instance.m_instanceId, animTime);
}
hairSdk->stepSimulation(simCalc.getTimeStep());
// Save off pin positions
for (int j = 0; j < instances.getSize(); j++)
{
Instance& instance = instances[i];
instance.m_prevPinPosition = instance.m_pinPosition;
// Blocking async call
hairSdk->getPinMatrix(NV_NULL, true, instance.m_instanceId, 0, &instance.m_pinPosition);
}
}
}
Do the rendering of the pins:
float renderInterp = ...; // The render interpolation
for (int i = 0; i < instances.getSize(); i++)
{
const Instance& instance = instances[i];
gfsdk_float4x4 pos = gfsdk_lerp(instance.m_prevPinPosition, instance.m_pinPosition, renderInterp);
// Apply the modelToWorld matrix here if needed..
/// Render the pin mesh at interpolated position
renderPinMesh(pos);
}
This is a somewhat simplified scenario, because it’s using the blocking style of getPinMatrix call (it’s being called with NV_NULL passed as the AsyncHandle pointer). This will only work if the rendering API version of HairWorks supports blocking, and then it may not be very efficient.
Dx12 currently doesn’t support the blocking option. It can be simulated though in client code by after doing the async fetch storing the AsyncHandles. Then submit to the GPU and wait on a fence. Then call updateCompleted on the HairWorks the simulation call adding a fence and waiting until its hit. Now the Async results can be fetched via the handles.
As this blocks it is also not very efficient. Gaining more concurrency would requiring doing other work, and calling updateCompleted and checking regularly if the async work has completed or not.
Clean up and shutdown¶
To release the instance, asset, render resource and library, call the following APIs:
hairSdk->freeInstance(hairInstanceId); // deletes a hair instance
hairSdk->freeAsset(hairAssetId); // deletes a hair asset (NOTE - any instances referencing must be deleted first!)
hairSdk->freeRenderResources(); // shut down global GPU resources
hairSdk->release(); // deletes the SDK