User Guide#
Pipecat Overview#
NVIDIA ACE uses the open-source Python framework pipecat to handle and customize the overall data and control flow of your ACE application. Pipecat enables you to create your ACE application with great flexibility while reducing iteration times for developers. Pipecat was created to simplify building voice-enabled, real-time, multimodal AI applications and is expanded with additional services by the nvidia-pipecat extension. For more information, refer to the NVIDIA Pipecat Services section.
Pipecat provides a flexible pipeline architecture for connecting various AI services, audio processing, and transport layers. Together with the nvidia-pipecat extension, Pipecat supports various applications including:
Pipecat Application |
Description |
|---|---|
Voice Assistants |
|
Interactive Avatars |
|
Interactive Agents |
|
Multimodal Applications |
|
Business Solutions |
|
Creative Tools |
|
Pipecat Terminology#
Term |
Description |
|---|---|
Frames |
Frames can represent discrete chunks of data; for instance, a chunk of text, a chunk of audio, or an image. They can also be used to control flow; for instance, a frame that indicates that there is no more data available or that a user started or stopped talking. They can also represent more complex data structures, such as a message array used for an LLM completion. |
FrameProcessors |
Frame processors operate on frames. Every frame processor implements a process_frame method that consumes one frame and produces zero or more frames. Frame processors can do simple transforms, such as concatenating text fragments into sentences, or they can treat frames as input for an AI Service, and emit chat completions based on message arrays or transform text into audio or images. Frames that the processor doesn’t process should be immediately yielded. |
Pipelines |
Pipelines are lists of frame processors linked together. Frame processors can push frames upstream or downstream to their peers. A very simple pipeline might chain an LLM frame processor to a text-to-speech frame processor, with a transport as an output. |
Transports |
Transports provide input and output frame processors to receive or send frames, respectively. |
AI Services |
These are specialized frame processors that interact with external AI services, such as STT (Speech to Text), TTS (Text to Speech), and LLMs. |
Building and Customizing Pipelines#
Pipecat pipelines are built by connecting different frame processors together. The best way to get started building your own custom pipelines is to read the Pipecat documentation. There you will find a plethora of examples and the full API documentation. We recommend that you familiarize yourself with those docs before starting to build any pipeline yourself:
NVIDIA Pipecat Services#
NVIDIA Pipecat offers a variety of services that help you develop multimodal interactive experiences utilizing NVIDIA technology. These services enable the creation of new Pipecat pipelines to drive full interactive avatar experiences that incorporate NVIDIA technologies such as Automatic Speech Recognition (ASR), Text-to-Speech (TTS), Audio2Face-3D, character animations, different renderers, and more.
By leveraging the Pipecat framework, these services allow you to customize your application’s controller to meet your specific requirements. They are designed to be compatible with the Pipecat framework and can generally be integrated into any Pipecat pipeline.
Note
There are exceptions for more advanced concepts, such as speculative speech processing. In these cases, careful integration with existing Pipecat pipelines is necessary. You may need to adapt and upgrade your implementation of existing frame processors to ensure compatibility with these advanced concepts and frame processors.
Here, we give a brief overview of the processors available in the nvidia-pipecat library and provide a link to the corresponding documentation.
Pipecat Service |
Description |
|---|---|
This service provides streaming speech recognition using NVIDIA’s Riva ASR models. It supports real-time transcription with interim results and interruption handling. |
|
This service provides high-quality speech synthesis using NVIDIA’s Riva TTS models. It supports multiple voices, languages, and custom dictionaries for pronunciation. |
|
This service can be used for text translation between different languages. It uses NVIDIA Riva Neural Machine Translation APIs. |
Pipecat Service |
Description |
|---|---|
This service extends the functionality of LLMService and serves as base class for all the services that connect with NVIDIA NIM LLMs using the ChatNvidia client. |
|
This service can be used if we want to have the NVIDIA RAG as the dialog management component in the pipeline. |
Pipecat Service |
Description |
|---|---|
Manages NVIDIA-specific user context for speculative speech processing, tracking interim and final transcriptions to enable real-time response generation. |
|
Specializes the base LLM assistant context aggregator for NVIDIA, handling assistant responses and maintaining conversation context during speculative speech processing. |
|
A matched pair of user and assistant context aggregators that collaboratively maintain bidirectional conversation state. |
|
Manages speculative speech TTS response timing by buffering during user input, coordinating playback with speech state, and queuing to prevent overlap and ensure natural turn-taking. |
Pipecat Service |
Description |
|---|---|
Generates predefined FacialGestures based on the interaction state to provide non-verbal feedback to the user. |
|
Change the avatar’s posture depending on the state of the conversation such as listening, talking or attentiveness. |
|
Converts streamed audio to facial blend-shapes for real-time lip-syncing and facial performances. |
|
Controls avatar animations (body, face, lips), configured to consume the output of the Audio2Face3DService to drive the avatar’s lips. |
Pipecat Service |
Description |
|---|---|
Synchronizes user speech transcripts with the received speech. |
|
Synchronizes bot speech transcripts with audio bot speech playback (TTS playback). |
Pipecat Service |
Description |
|---|---|
Reacts to user presence with a configurable greeting and farewell message and blocks input frames if no user is present. |
|
Generates a configurable bot message when long pauses in the interaction occur to keep the conversation going. |
|
Sends random acknowledgement words when a user stops speaking to provide conversational feedback while waiting for a slow RAG/LLM to respond |
Pipecat Service |
Description |
|---|---|
Extended ElevenLabs TTS service that supports end-of-speech events for usage in avatar interactions. |
ACE Controller Scaling#
A single instance of the Pipecat pipeline can only serve a single user stream. ACE Controller supports both horizontal and vertical scaling for multiple pipeline instances.
ACE Controller microservice introduces the following components to manage scaling:
FastAPI Server
The FastAPI Server exposes a WebSocket endpoint that users can connect to with a unique stream_id to spin up a new Pipecat pipeline instance. The websocket instance can be passed directly to ACETransport or FastAPIWebsocketTransport at pipeline creation and will be utilized for communication with external components, such as UI for inputs and outputs.
Optionally, FastAPI Server exposes add_stream and remove_stream HTTP endpoints, which can help manage the lifecycle of the pipeline creation and removal irrespective of the WebSocket connection. This can help to reconnect the WebSocket to the existing pipeline in case of a disconnection due to the network.
ACETransport
ACETransport is specifically designed to support integration with existing ACE microservices. It uses a FastAPI websocket instance similar to FastAPIWebsocketTransport for input and output communication with external components such as UI, but in addition, it has the option to use an RTSP URL for user audio frames in InputTransport.
ACEPipelineRunner
ACEPipelineRunner replaces Pipecat’s PipelineRunner and allows creating multiple instances of pipelines. There are a few differences from how Pipecat’s PipelineRunner works:
ACEPipelineRunner expects a method for creating a PipelineTask instance at runtime, but Pipecat’s PipelineRunner expects an existing instance of the PipelineTask at startup.
async def create_pipeline_task(pipeline_metadata: PipelineMetadata): # method to create a pipeline task transport = ACETransport( websocket=pipeline_metadata.websocket, ) pipeline = Pipeline( [ transport.input(), ..., transport.output(), ] ) task = PipelineTask( pipeline, params=PipelineParams( start_metadata={"stream_id": pipeline_metadata.stream_id}, ), ) return task app = FastAPI() app.include_router(websocket_router) runner = ACEPipelineRunner(pipeline_callback=create_pipeline_task)
Optionally, you can utilize
add_pipelineandremove_pipelinealong with FastAPI HTTP endpoints to better manage pipeline instances.from nvidia_pipecat.transports.services.ace_controller.routers.register_apis_router import router as register_apis_router from nvidia_pipecat.transports.services.ace_controller.routers.websocket_router import router as websocket_router app = FastAPI() app.include_router(websocket_router) # Register websocket endpoint app.include_router(register_apis_router) # Register stream add / remove apis runner = ACEPipelineRunner(pipeline_callback=create_pipeline_task, enable_rtsp=True) # Make sure to use enable_rtsp=True flag with HTTP apis
ACEPipelineRunner allows you to update the WebSocket instance at runtime to reconnect to the existing pipeline if using HTTP endpoints.
ACEPipelineRunner only supports WebSocket client-based Transport, but you can easily modify it to support your own transport class.
Stream Routing and Distribution (SDR)
ACE Controller is a stateful microservice, as we need to route all requests to the same pipeline instance only. For creating multiple replicas of ACE Controller, we need to use a load balancer for routing the request with a specific stream_id to the respective ACE Controller pod. NVIDIA Tokkio workflow uses the SDR microservices for managing streams across the ACE Controller pods using exposed HTTP add and remove APIs as part of the FastAPI Server.
Speculative Speech Processing#
Speculative speech processing enables real-time, natural conversational AI by processing interim transcripts and generating early responses while maintaining conversation coherence. This implementation uses NVIDIA’s specialized frame processors and context aggregators.
Component |
Description |
Processing Steps |
|---|---|---|
Handles user speech processing. |
|
|
Manages assistant responses. |
|
|
Controls TTS responses. |
|
For more information, refer to the NVIDIA Riva ASR documentation regarding how speculative speech processing is enabled using the Two-Pass End of Utterance. Interim transcripts are a result of Riva ASR’s tentative hypotheses that may change. The estimate of the likelihood that the recognizer will not change its guess about this interim result is reflected by the interim’s stability parameter. Interims with stability of 1.0 are considered stable and interims with stability less than 1.0 are considered unstable and also referred to as partials. Final transcripts are the last hypotheses transcript returned by Riva ASR which is considered to be the most stable and is recognised by the is_final flag set to True.
Workflow#
As the user speaks, the system receives interim transcripts from the speech-to-text engine as RivaInterimTranscriptionFrames. Each RivaInterimTranscriptionFrame includes a stability score indicating the likelihood of the transcription remaining unchanged.
The NvidiaUserContextAggregator processes only stable interim transcripts (stability=1.0) to prevent processing unstable or rapidly changing transcriptions. When a final transcript arrives, it replaces any interim transcripts for that utterance if the content of the final transcript is different from the received interims before it.
In addition, the NvidiaUserContextAggregator maintains conversation history using a dynamic update mechanism. Instead of always appending new messages, it updates existing messages when appropriate. This approach helps maintain conversation coherence while enabling early response generation for speculative speech scenarios. The system enforces strict user-assistant turn-taking to ensure natural conversation flow where each user query is strictly followed by an assistant response entry.
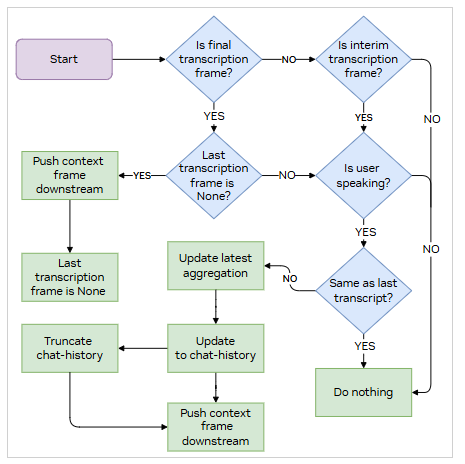
After transcript filtration and conversation history management from NvidiaUserContextAggregator, transcriptions are sent downstream to LLM and TTS services as OpenAILLMContextFrame.
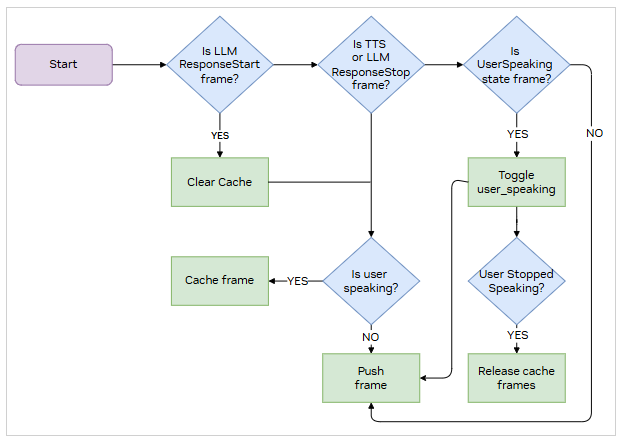
After responses are generated from TTS service, NvidiaTTSResponseCacher manages their delivery timing. While the user is speaking, TTS responses are cached rather than immediately played. This caching mechanism prevents response overlap and maintains natural turn-taking. When the user stops speaking, cached responses are released in the appropriate order, creating a more natural conversational experience.
# Example Pipeline Configuration
nvidia_tts_response_cacher = NvidiaTTSResponseCacher()
## Configuration Options
nvidia_context_aggregator = create_nvidia_context_aggregator(
context,
send_interims=True, # Enable interim processing
chat_history_limit=20, # Conversation turn limit
)
pipeline = Pipeline(
[
transport.input(), # Input from client
stt, # Speech-to-Text [ RivaASRService ]
nvidia_context_aggregator.user(), # Handle interim/final transcripts
llm, # Language Model
tts, # Text-to-Speech [TTS service ]
nvidia_tts_response_cacher, # Response timing control
transport.output(),
nvidia_context_aggregator.assistant(), # Response management
]
)
Enabling Speculative Speech Processing#
Speculative speech processing is enabled through configuration settings in the pipeline setup. When enabled, the system processes the final as well as the stable interim transcripts and follow a strict turn-taking approach where responses are generated even before the user completes their utterance based on hypothesised transcripts from Riva ASR Service, that is, the interim transcripts.
To enable speculative speech processing, modify the context aggregator configuration in your pipeline setup. The primary control is through the send_interims parameter when creating NvidiaContextAggregators. If using a context aggregation pair from the NvidiaLLM service, swap the same with the NvidiaContextAggregators pair as follows.
# Enable speculative processing by setting send_interims=True
nvidia_context_aggregator = create_nvidia_context_aggregator(
context,
send_interims=True # Enables interim transcript processing
)
# Swap context aggregator from LLM service with nvidia_context_aggregators
Add the NvidiaTTSResponseCacher frame processor to your pipeline if you are enabling speculative speech processing.
# Example Pipeline with Speculative Speech Processing Enabled
nvidia_tts_response_cacher = NvidiaTTSResponseCacher()
nvidia_context_aggregator = create_nvidia_context_aggregator(context, send_interims=True)
pipeline = Pipeline([
transport.input(), # Input from client
stt, # Speech-to-Text [ RivaASRService ]
nvidia_context_aggregator.user(), # Handle interim/final transcripts
llm, # Language Model
tts, # Text-to-Speech [TTS service ]
nvidia_tts_response_cacher, # Response timing control
transport.output(),
nvidia_context_aggregator.assistant() # Response management
])
For pipelines with speculative speech processing disabled, refer to Building a Basic Pipeline section.
After enabling speculative speech processing:
Interim transcripts will be processed
Response generation starts after the first stable interim transcript is received
TTS responses are speculatively cached until the user stops speaking
Early response generation takes place on the basis of interim transcripts decreasing overall pipeline latency by parallelizing LLM, RAG, and TTS services. You should expect an approximately 300 ms reduction in end-to-end latency.
Improved context management with support for interim updates
Potentially decreased response latency; however, it slightly increases processing overhead.
Building Speculative Speech Processing Specific Frame Processors#
When developing features that work with speculative speech processing, it’s crucial to design components that can handle both interim and final transcripts while maintaining conversation coherence. The system needs to manage early responses and potential updates.
The following guidelines are useful when building frame processors that lie between the RivaASR service and the NvidiaTTSResponseCacher frame processor in the pipeline.
Handle Interim States:
Design frames to carry stability information
Include mechanisms to update or replace interim content.
Implement clear state transitions from interim to final
Implement Versioning
Support content updates without creating new entries
Design for Incremental Updates
Support partial response processing
Design considering TTSRawAudio frames are cached by the response caching mechanism until the release conditions are triggered.
Handle response cancellation
Handle transitions between interim and final states
Support rollback capabilities
Observing Logs for Debugging and Best Practices#
Log |
Symptom |
Steps to Debug |
|---|---|---|
No LLM/TTS response generated |
No chat or TTS is generated; logs a user transcript. |
|
TTS response generated but not played |
Generated TTS, |
|
Repeated LLM/TTS responses |
Bot repeats its response as if it is generating two responses for the same query; one after the other. |
|
How to Debug the Pipeline#
Logging#
By default, the logging level is on DEBUG, capturing information about the main pipeline processing steps. If you need a more detailed insight into the pipeline and see all the pushed frames and their processing path, you can change this to TRACE.
setup_default_ace_logging(level="TRACE")
You can add additional log statements:
from loguru import logger
logger.debug("Your log info")
Observers#
Observers (introduced in Pipecat 0.0.56) can view all the frames that go through the pipeline without the need to inject processors in the pipeline. Custom observers can be created for different use cases.
A custom observer (for example, NvidiaObserver) can be added to the pipeline as shown below. For the details on how to implement an observer, refer to GitHub: pipecat-ai / pipecat.
task = PipelineTask(
pipeline,
params=PipelineParams(
observers=[NvidiaObserver()],
),
)
Any debugging related code (or something similar) can be added by overriding the method on_push_frame() of the Observer. It is an abstract method that can trigger events and print debug logs when a frame is pushed from one frame processor to another in the pipeline.
Audio#
Since audio issues are difficult to debug with logging messages alone, we provide a helper frame processor called AudioRecorder to record audio frames (AudioRawFrame, TTSAudioRawFrame) to a file. The processor will not consume those frames and can therefore be inserted anywhere in the pipeline without changing its functionality.
from pipecat_nvidia.processors.audio_util import AudioRecorder
recorder = AudioRecorder(
output_file=str(TMP_FILE),
params=TransportParams(audio_out_sample_rate=SAMPLE_RATE)
)
Measure Bot Response Latency#
The bot response latency refers to the time delay between the end of a user’s speech and the response from a bot. Several components contribute to latency in conversational AI systems. To diagnose higher latencies in the pipeline, it is essential to understand the contribution of each component, including network latency, processing time, and model inference delays.
The framework provides metrics for Time to First Byte (TTFB) and total processing time for several components. Currently, we have metrics for the LLM and TTS components. To enable these metrics in the workflow, you can use multiple types of flags in the parameters of the PipelineTask, as shown in the following example.
task = PipelineTask(
pipeline,
params=PipelineParams(
enable_metrics=True,
enable_usage_metrics=True,
send_initial_empty_metrics=True,
report_only_initial_ttfb=True,
start_metadata={"stream_id": pipeline_metadata.stream_id},
),
)
Some example metric logs are included below:
2025-03-13 17:53:40.286 | DEBUG | pipecat.processors.metrics.frame_processor_metrics:stop_ttfb_metrics:50 | streamId=43fcc4b0-7ab3-4b07-ab99-56851842e2a0 - NvidiaLLMService#0 TTFB: 0.03784751892089844
2025-03-13 17:54:14.952 | DEBUG | pipecat.processors.metrics.frame_processor_metrics:start_tts_usage_metrics:85 | streamId=43fcc4b0-7ab3-4b07-ab99-56851842e2a0 - RivaTTSService#0 usage characters: 34
2025-03-13 17:54:14.953 | DEBUG | pipecat.processors.metrics.frame_processor_metrics:stop_processing_metrics:65 | streamId=43fcc4b0-7ab3-4b07-ab99-56851842e2a0 - RivaTTSService#0 processing time: 0.050315141677856445