ASR Overview
Contents
ASR Overview#
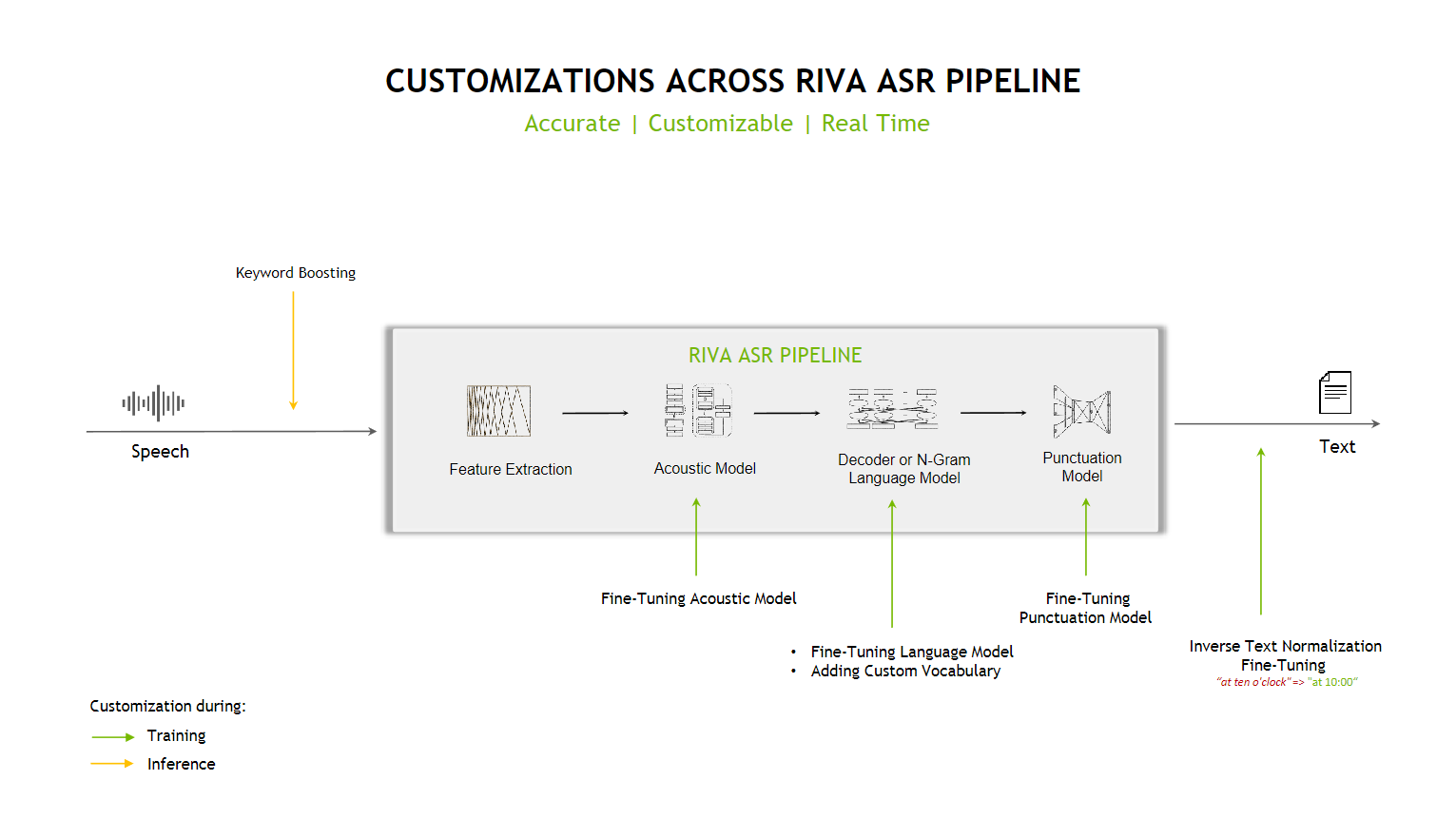
Automatic Speech Recognition (ASR) takes an audio stream or audio buffer as input and returns one or more text transcripts, along with additional optional metadata. Speech recognition in Riva is a GPU-accelerated compute pipeline, with optimized performance and accuracy. Riva supports offline/batch and streaming recognition modes.
Try It Out#
Experience Riva ASR on our demo platform: https://build.nvidia.com/explore/speech
Pretrained ASR Models#
The .riva model, language model, lexicon vocabulary, and WFST files used to generate the RMIRs in the Quick Start scripts can be found at the following NGC locations.
Language |
Acoustic Model (AM) |
Language Model (LM) and Lexicon |
Punctuation |
Inverse Text Norm (ITN) |
|---|---|---|---|---|
English (en-US) |
Parakeet-0.6B Parakeet-0.6B-Unified Parakeet-1.1B Parakeet-1.1B Channel Robust (Beta Model) Parakeet-1.1B-RNNT Conformer Conformer-XL Distil-Whisper |
n-gram LM
(files |
||
Spanish-US (es-US) |
||||
Spanish (es-ES) |
||||
German (de-DE) |
||||
Hindi (hi-IN) |
n/a |
|||
Russian (ru-RU) |
n/a |
|||
French (fr-FR) |
||||
English (en-GB) |
n/a |
|||
Portuguese-Brazilian (pt-BR) |
n/a |
|||
Korean (ko-KR) |
n/a |
|||
Japanese (ja-JP) |
n/a |
|||
Arabic (ar-AR) |
||||
Italian (it-IT) |
n/a |
|||
Mandarin (zh-CN) |
n/a |
|||
Dutch (nl-NL) |
||||
Dutch-Belgian (nl-BE) |
||||
Spanish-English Multilingual Code Switch (es-en-US) |
n/a |
|||
Japanese-English Multilingual Code Switch (ja-en-JP) |
n/a |
n/a |
||
Multilingual Code Switch (em-ea) |
n/a |
n/a |
||
Multilingual (multi) |
Parakeet-1.1B-Unified-Universal-CTC Parakeet-1.1B-Unified-Universal-RNNT Parakeet-1.1B-Unified-Concat-CTC |
n/a |
n/a |
n/a |
Multilingual with AST (multi) |
n/a |
n/a |
n/a |
Language and Model Support#
Riva Speech AI Skills provides high-quality pretrained models across a variety of languages that are listed in above section. Upgraded models and new languages are released regularly.
To select which language and model to deploy, simply change the variables asr_acoustic_model and asr_language_code in the config.sh file within the quickstart directory of the Quick Start scripts.
Currently, Speech hints is supported only with English(en-US).
Multilingual Models#
Below are the languages supported for various multilingual ASR models. With the Multilingual (universal-rnnt), Multilingual (universal), Multilingual (concat), and Multilingual (whisper) models, you can also pass multi in the language_code field while configuring a request from the client, as these models support automatic language identification.
Multilingual (universal-rnnt):
ASR:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-IN,he-IL,nb-NO,nl-NL,cs-CZ,da-DK,fr-CA,pl-PL,sv-SE,th-TH,tr-TR,pt-PT,nn-NO
Recommended languages:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-IN
Recommended model for streaming multilingual ASRMultilingual (universal):
ASR:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-IN,he-IL,nb-NO,nl-NL,cs-CZ,da-DK,fr-CA,pl-PL,sv-SE,th-TH,tr-TR,pt-PT,nn-NO
Recommended languages:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,hi-INMultilingual (concat):
ASR:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-IN,he-IL,nb-NO,nl-NL,cs-CZ,da-DK,fr-CA,pl-PL,sv-SE,th-TH,tr-TR,pt-PT,nn-NO
Recommended languages:en-US,ar-AR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-INMultilingual (whisper):
ASR:en,zh,de,es,ru,ko,fr,ja,pt,tr,pl,ca,nl,ar,sv,it,id,hi,fi,vi,he,uk,el,ms,cs,ro,da,hu,ta,no,th,ur,hr,bg,lt,la,mi,ml,cy,sk,te,fa,lv,bn,sr,az,sl,kn,et,mk,br,eu,is,hy,ne,mn,bs,kk,sq,sw,gl,mr,pa,si,km,sn,yo,so,af,oc,ka,be,tg,sd,gu,am,yi,lo,uz,fo,ht,ps,tk,nn,mt,sa,lb,my,bo,tl,mg,as,tt,haw,ln,ha,ba,jw,su,yue
AST: translation toenfrom all ASR languages in above list is supported.Multilingual (canary-1b and canary-0.6b-turbo):
ASR:en-US,en-GB,es-ES,ar-AR,es-US,pt-BR,fr-FR,de-DE,it-IT,ja-JP,ko-KR,ru-RU,hi-IN
AST: translation between all non-english and english ASR languages in above list is supported in both directions. Additionally, translation from english to mandarinzh-CN, and translation between any two languages fromar-AR,es-ES,fr-FR,de-DEis also supported. Translation fromja-JP,ko-KR,es-ES,es-UStoen-USis of beta quality.Multilingual Code Switch (em-ea):
ASR:en-GB,es-ES,fr-FR,it-IT,de-DE,ar-AR
Features#
Riva ASR features include:
Support for offline and streaming use cases
A streaming mode that returns intermediate transcripts with low latency
GPU-accelerated feature extraction
Multiple (and growing) acoustic model architecture options accelerated by NVIDIA TensorRT
Beam search decoder based on n-gram language models
Voice activity detection algorithms (CTC-based)
Automatic punctuation
Ability to return top-N transcripts from beam decoder
Word-level timestamps
Word-level confidences
Inverse Text Normalization (ITN)
Offline non-overlapping Speaker Diarization
Streaming Speaker Diarization
Speech hints
Support for Opus-encoded streams
Two-Pass End of Utterance
VAD based End of Utterance
Automatic Speech Translation (AST)
Offline Recognition#
In offline or batch mode, the full audio signal is first read from a file or captured from a microphone. Following the capture of the entire signal, the client makes a request to the Riva Speech AI server to transcribe it. The client then waits for the response from the server.
Tip
This method can have long latency because the processing of the audio signal begins only after the full audio signal has been captured or read from the file.
Streaming Recognition#
In streaming recognition mode, as soon as an audio segment of a specified length is captured or read, a request is made to the server to process that segment. On the server side, a response is returned as soon as an intermediate transcript is available.
Note
You can select the length of the audio segments based on speed and memory requirements.
Refer to the protobuf-docs-asr documentation and ASR example command-line clients for more details on running speech recognition with file or microphone input.
Offline Recognition with Non-Overlapping Speaker Diarization#
When the ASR offline client is run with speaker diarization enabled, the audio data is sent as input to the Riva Speech AI server. The server then returns an ASR transcript to the client as output, along with a speaker tag for each word in the transcript.
The following table contains the NGC locations of the neural VAD and embedding extractor .riva models that were used to generate the speaker diarization RMIR in the Quick Start scripts.
Pipeline |
Neural VAD |
Embedding extractor |
|---|---|---|
Diarizer Offline |
Note
You can easily deploy the offline speaker diarization model by setting the deploy_offline_diarizer field to true in the config.sh file found in the Riva Quick Start scripts.
Streaming Recognition with Speaker Diarization#
Riva ASR uses a streaming speaker diarization algorithm that identifies the Speaker ID in real-time. For every final transcript generated at end-of-utterance detection, speaker tags are provided for all words in the transcript. When using streaming ASR client with --speaker-diarization enabled, the server invokes the Speaker Diarization model in parallel to the ASR and returns final ASR transcripts on end-of-utterance detection along with speaker tags for each word.
Note
Streaming speaker diarization is currently a beta release.
Below are the Streaming Speaker Diarization (SD) models supported with Riva ASR, along with the NGC locations of their .riva models.
Note
For convenience, NGC provides a pre-built RMIR that combines the en-US Parakeet 1.1b ASR model with Sortformer speaker diarization. You can easily deploy this model by setting the
asr_accessory_modelfield todiarizerin theconfig.shfile found in the Riva Quick Start scripts.Currently, Sortformer speaker diarization is supported only with the Parakeet-CTC and Conformer-CTC ASR models in streaming mode.
Refer to the pipeline configuration section for details on how to build and deploy a custom streaming ASR model with speaker diarization enabled.
Neural-Based Voice Activity Detection#
It is possible to use a neural-based Voice Activity Detection (VAD) algorithm in Riva ASR. This can help to filter out noise in the audio, and can help reduce spurious words from appearing in the ASR transcripts.
Below are the neural-based Voice Activity Detection (VAD) models supported with Riva ASR, along with the NGC locations of their .riva models.
Silero VAD (recommended)
Note
For convenience, NGC provides a pre-built RMIR that combines the en-US Parakeet 1.1b ASR model with Silero VAD. You can easily deploy this model by setting the asr_accessory_model field to silero in the config.sh file found in the Riva Quick Start scripts.
Refer to the pipeline configuration section for details on how to build and deploy ASR models with neural-based VAD enabled.
Two-Pass End of Utterance#
The Two-Pass End of Utterance (EOU) feature enables users to receive transcripts earlier for downstream tasks (such as feeding them to LLMs) while maintaining accuracy. By default, RIVA performs end-of-utterance detection using the stop_history(ms) parameter to produce the final transcript. When Two-Pass EOU is enabled, RIVA performs an additional early EOU detection using the stop_history_eou(ms) parameter.
The process works as follows:
Early EOU Detection (when enabled): Riva detects an early EOU based on the
stop_history_eou(ms) parameter, producing an intermediate transcript.Final EOU Detection (always enabled): Riva confirms the final EOU based on the
stop_history(ms) parameter, producing the final transcript.
To enable early EOU detection, use --stop_history_eou=<silence duration> from the RIVA client. Based on our experiments, we suggest setting this value to 240 ms for optimal performance.
This feature is particularly useful for applications that need quick access to transcripts while still getting the benefit of more accurate final transcripts. Since RIVA ASR retains the utterance state until the final transcript is delivered, the latency improvement is equal to the time difference between early and final EOU detection. Refer to this reference from the ASR gRPC documentation for more details on configuring these parameters.
Note
Two-pass EOU is currently supported only for Parakeet CTC and Conformer CTC models.
The intermediate transcript is available earlier but may have slightly lower accuracy compared to the final transcript.
VAD based End of Utterance (EOU)#
This is an optional configuration for ASR to use VAD probabilities to detect end of utterance. You can pass enable_vad_endpointing:true in the custom_configuration field to enable this feature (VAD should be enabled in the ASR pipeline). Refer to the pipeline configuration section for details on how to build and deploy ASR models with neural-based VAD enabled. End of utterance detection using VAD probabilities is more accurate compared to Acoustic model-based end of utterance detection. When using VAD-based end of utterance, the recommended value for stop_history is 500 (ms).
Automatic Speech Translation (AST)#
Automatic Speech Translation (AST) translates audio signals from the source language directly into text in the target language. In Riva, this is supported using the Whisper model through the custom_configuration field mentioned in the protobuf-docs-asr documentation. For example, you can pass fr-FR in the language_code field and target_language:en-US,task:translate in the custom_configuration field while configuring a request from the client to perform AST from French to English.
Multiple Deployed Models#
The Riva server supports multiple speech recognition models deployed simultaneously, up to the limit of your GPU’s memory. As such, a single-server process can host models tailored for streaming or batch, various languages, accents, or channel characteristics.
When receiving requests from the client application, the Riva server selects the deployed ASR model
to use based on the RecognitionConfig of the client request. If no models are available to fulfill
the request, an error is returned. In the case where multiple models might be able to fulfill the
client request, one model is selected at random. You can also explicitly select which ASR model
to use by setting the model field of the RecognitionConfig protobuf object to the value of
<pipeline_name> which was used with the riva-build command. This enables you to deploy
multiple ASR pipelines concurrently and select which one to use at runtime.
Checking deployed models#
Once a server is running retrieving the available models can be done via the GetRivaSpeechRecognitionConfig rpc.
For each model available to make inference request, the rpc returns the parameters used when the model was deployed.