Basics of Speech Recognition and Customization of Riva ASR
Contents
Basics of Speech Recognition and Customization of Riva ASR#
Even with the best ASR solution, there is a likelihood that the performance of the system for a use case does not meet requirements. Human level accuracy typically is estimated at > 95% (which is < 5% word error rate (WER)). However, there may be domains that require accuracies closer to 99%. Furthermore, there is an assumption of domain expertise on the human transcriber. An expert in transcribing legal documents would do poorly on medical documents and vice versa. The same applies to automated speech recognition solutions as well.
To adapt an existing solution to your domain, it requires a basic understanding of how speech recognition works. Without this understanding one would find it difficult to understand which components of the speech recognition system needs to be customized.
Basics of Automatic Speech Recognition#
Speech recognition is the process of converting a sequence of sound units (phones) uttered by a person into a sequence of words of a language. Without a language in context, the sequence of phones have no meaning. For example, to a person who does not understand Mandarin, listening to Mandarin speech makes no sense. Even when there is a language in context, we still have issues when we have limited textual context. For example:
I need you to recognize speech
I need you to wreck a nice beach
I need you to wreck a nice peach
There’s a town of happy people
Theirs a town of happy people
Speech Recognition by Humans#
The speech recognition problem, as far as humans are concerned, is the problem of identifying the sequence of \(m\) words (\(\mathbf{W}=w_1,w_2\ldots w_m\)) having listened to a sequence of \(n\) phones (\(\mathbf{P}=p_1,p_2\ldots p_n\)), \(n \geq m\). Mathematically, this can be represented as W
that is, choose the sequence of words for the sequence of phones that is more probable. Using Bayes rule, this can be expanded as
where:
\(P(\mathbf{P}|\mathbf{W})\) is a Markov model derived from a lexicon/dictionary, and
\(P(\mathbf{W})\) is the language model.
Speech Recognition by Machines#
The speech signal does not have a \(1:1\) correspondence with phones. There is however some degree of correlation between the speech signal and the sequence of phones. Phones refer to the perceived/mental form of speech sounds. The written representation is phoneme. There is no unique acoustic or time series representation of a phoneme. All that a computer can utilize is the speech signal, therefore, features are extracted from the speech signal. Now, the problem of automatic speech recognition is that of identifying the sequence of \(m\) words (\(\mathbf{W}=w_1,w_2\ldots w_m\)) having observed a sequence of \(t\) features (\(\mathbf{O}=o_1,o_2\ldots o_t\)). Mathematically, this can be represented as
where:
\(P(\mathbf{W})\) is the language model,
\(P(\mathbf{O})\) is assumed to be \(1\) (that is, all feature sequences are equally possible)
\(P(\mathbf{O}|\mathbf{W})\) is the acoustic model trained using speech data.
To develop a automatic speech recognition system, we need the following:
A lexicon (pronunciation dictionary mapping words to sequence of phonemes or letters or other units)
Language model (given possible sequences of words corresponding to utterance, this provides the most likely sequences of words)
Acoustic model (given speech signal, this provides the most likely sequences of phonemes/letters/other units)
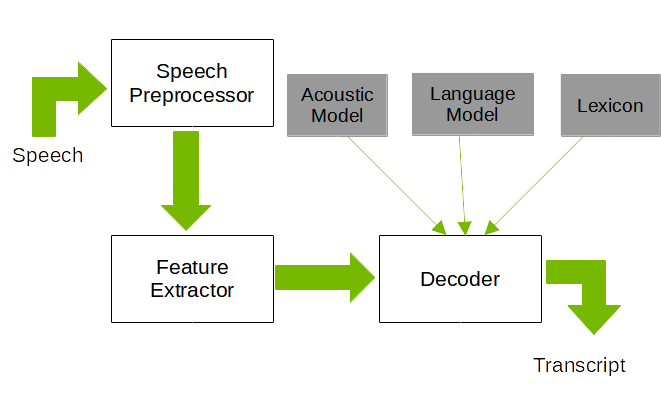 Architecture of an Automatic Speech Recognition
System
Architecture of an Automatic Speech Recognition
System
Figure 1 shows the architecture of a generic speech recognition system. The main components of the system are the speech processor, feature extractor, and the decoder. The speech preprocessor implements a number of algorithms depending on the task. Some typical speech preprocessor tasks include speech segmentation, speech enhancement, speaker diarization, and so on. The feature extractor extracts a sequence of feature (typically spectral features) from the processed speech signal. The decoder uses the pretrained acoustic and language models along with a lexicon to find the best possible sequence of words for the speech signal (features).
Speech Data preferably recorded in the environment in which the system will be deployed, and of the best possible quality.
Orthographic transcriptions for the speech data. This can range from a simple chain of words per recording item (based on the script that was used during the recording) to an extensive labeling of several different semantic layers. The choice about what is to be included in the transcript is dependent on the type of speech corpus and the intended usage. For example, a corpus of read speech items over the telephone network with the aim to train automatic speech recognition algorithms does not need any elaborated labeling of discourse events. A corpus containing dialog speech between two or more persons specific to a particular domain requires a bit more effort.
Lexicon containing list of words that define the vocabulary of the domain with all possible pronunciations for those words.
Evaluation of ASR Accuracy#
Evaluation of ASR systems depends on the task at hand. For most cases where simple transcription accuracy is concerned, the traditional evaluation metric is the Word Error Rate (WER). This requires that actual (reference) transcription (verified by humans) is available for the speech data being evaluated. The predicted and reference transcriptions could be of different length and hence they need to be aligned first before WER is computed. Once aligned, the WER can be computed as follows:
where:
\(N\) is the total number of words present in the reference transcription.
\(S\) is the number of words substituted
\(D\) is the number of words deleted
\(I\) is the number of words wrongly inserted
Popular tools for calculating the WER include asr_evaluation and jiwer.
An alternative evaluation metric for ASR is the Character Error Rate (CER). CER is calculated similar to WER with alignments of the two transcripts being at character level instead of words. CER is a more useful metric for languages that are character based (for example, Mandarin) and those that do not use white-spaces to separate words (for example, Thai, Lao, and Khmer).
WER evaluation might be too simplistic for specific use cases. For example, consider a dictation system that records clinical information. If a patient’s name, address, as well as specific medical terms are wrongly transcribed, the error is significantly higher for those words and matters a lot more than if verbs/adjectives or other phrases were wrongly transcribed. One technique to better evaluate in these scenarios would be to have a list of most common words that are ignored while evaluating WER. Alternatively, it is possible to provide more weight to some words to better estimate the ASR accuracy for the task. One mechanism to do this is to use Term Frequency-Inverse Document Frequency (TF-IDF) to determine the importance of the word.
For slot-filling applications like voice assistants, WER is a less useful metric. The goal in slot-filling is to identify the intent and any relevant entities associated with that intent. Unlike a generic vocabulary, slot-filling utilizes specific sets of grammars/phrases associated with the various intents and an exhaustive list of entities which may be present in a database. The evaluation metrics associated with these applications primarily use the Intent Classification Error Rate (ICER) and the Entity Error Rate (EER). ICER and EER are typically measured using Precision/Recall or F1/F2 scores.
Riva ASR#
Riva ASR supports models that use the Connectionist Temporal Classification algorithm (CTC). Understanding how CTC decoders work greatly helps in root-causing accuracy issues.
The Alignment Problem#
ASR is a sequence discriminative task. A discriminative task is one that requires labels to be assigned to a given data. However since speech is a sequence of acoustic sounds, this requires labels to be assigned to portions of the speech signal and there is no 1:1 mapping between the speech signal and the label. Labeling speech signals is difficult even for the most trained human expert since no two people are likely to agree on the boundary. Traditionally, speech recognition systems rely on a technique called force-alignment to align two sequences, in this case text and speech.
CTC decoders overcome this problem by computing the output distribution over all possible alignments of the labels with the input sequence. For example, given an observation sequence (\(\mathbf{O}=o_1,o_2\ldots o_7\)) and say the transcript “heart” for a speech signal, some of the possible alignments are:
h,e,e,a,a,r,t
h,e,a,a,a,r,t
h,e,a,a,r,t,t
h,h,e,a,r,t,t
Collapsing the text results in the string “heart”. However, this can cause problems with words having repeating letters, for example the word “harry”. Additionally, there can also be silences present in the utterance. To deal with this issue, an additional token called the blank token (\(\epsilon\)) is used. The algorithm is modified so that it only repeats characters between the blank token. For example, one of the alignment for “harry” would be “h,a,a,r,\(\epsilon\),r,y”.
The CTC alignments give a distribution over the output labels for each time step. Various techniques exist to extract the text sequence corresponding to the speech signal. The two most commonly used techniques are:
Greedy decoder
Beam search decoder
Lexicon search decoder (using a word language model and lexicon)
Lexicon free decoder (using a character language model)
The Greedy Search Decoder#
The greedy (search) decoder is the simplest and the least computationally intensive algorithm to get a sequence of text. This algorithm assumes that the best path obtained by concatenating the character with the highest value (logit) at each time step with the previously selected character sequence is the most probable text sequence.
The Beam Search Decoder#
The beam search decoder is a more computationally intensive algorithm that is more likely to generate the most probable text sequence. This is especially useful since the CTC algorithm does not consider the outputs at the previous time-steps when estimating the logits at the current timestamp. The idea here is that the sum of paths corresponding to the most probable text sequence can be iteratively computed from the prefix paths corresponding to the text sequence. Since this can result in exponential growth in number of paths at each time step, some of these are pruned by ignoring all paths with probabilities less than a particular value. Alternatively, additional restrictions on the number of possible paths could be placed. One could simply select the most likely sequence from the multiple paths or alternatively use a language model to rescore the beams.
Riva Speech Recognition Pipeline#
The following flow diagram shows the Riva speech recognition pipeline along with the possible customizations.
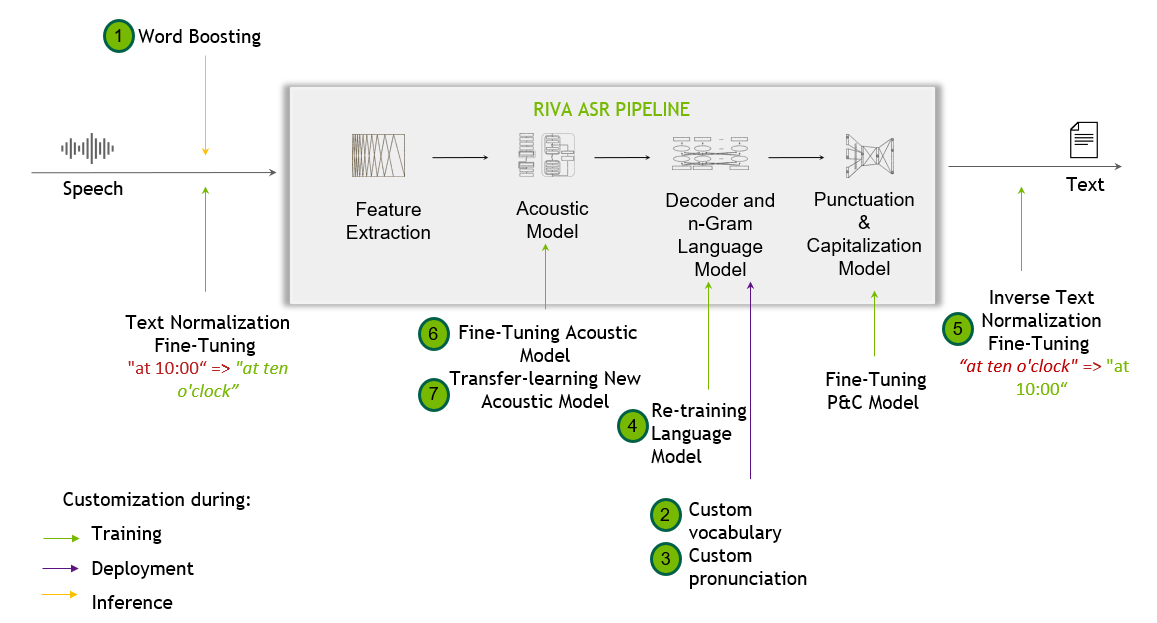
Summary of Riva ASR Customizations#
In the following table, the corresponding customizations are listed in increasing order of difficulty and efforts:
Techniques |
Difficulty |
What it Does |
When to Use |
How to Use |
|---|---|---|---|---|
|
Quick and easy |
Extends the vocabulary while increasing the chance of recognition for a provided list of keywords. This strategy enables you to easily improve recognition of specific words at request time. |
When certain words or phrases are important in a particular context. For example, attendee names in a meeting. |
|
|
Easy |
Extends the default vocabulary to cover new words of interest. |
When the default model vocabulary does not sufficiently cover the domain of interest. |
|
|
Easy |
Explicitly guides the decoder to map pronunciations (that is, token sequences) to specific words. The lexicon decoder emits words that are present in the decoder lexicon. It is possible to modify the lexicon used by the decoder to improve recognition. |
When a word can have one or more possible pronunciations. |
|
|
Moderate |
Trains a new language model for the application domain to improve the recognition of domain specific terms. The Riva ASR pipeline supports the use of n-gram language models. Using a language model that is tailored to your use case can greatly help in improving the accuracy of transcripts. |
When domain text data is available. |
|
|
Moderately hard |
Maps the sequence of transcribed spoken words into a desired written format. |
When a particular written format is required. |
|
|
Moderately hard |
Fine-tunes an existing acoustic model using a small amount of domain data to better suit the domain. |
When transcribed domain audio data (10h-100h) is available, other easier approaches fall short. |
|
|
Hard |
Trains a brand new acoustic model from scratch or with cross-language transfer learning, using thousands of hours of audio data. |
Only recommended when adapting Riva to a new language or dialect. |
Basic Customization of Riva ASR#
Word Boosting#
Word boosting provides a quick and temporary adaptation for the model to cope with new scenarios, such as recognizing proper names, products, and new or domain specific terminologies. For OOV (Out Of Vocabulary) words, the word boosting functionality extends the vocabulary at inference time. You will have to explicitly specify the list of boosted words at every request. Other adaptation methods such as custom vocabulary and lexicon mapping provide a more permanent solution, which affects every subsequent request.
Of all the adaptation techniques, word boosting is the easiest and quickest to implement. Word boosting allows you to bias the ASR engine to recognize particular words of interest at request time, by giving them a higher score when decoding the output of the acoustic model. All you need to do is pass a list of words of importance to the model along with a weight as extra context to the API call, as shown in the following example.
# Word Boosting
boosted_lm_words = ["BMW", "Ashgard"]
boosted_lm_score = 20.0
speech_context = rasr.SpeechContext()
speech_context.phrases.extend(boosted_lm_words)
speech_context.boost = boosted_lm_score
config.speech_contexts.append(speech_context)
# Creating StreamingRecognitionConfig instance with config
streaming_config = rasr.StreamingRecognitionConfig(config=config, interim_results=True)
Make note of the following while implementing word boosting:
There is no limit to the number of words that can be boosted. You should see minimal impact on latency for all requests, even for tens of boosted words, except for the first request, which is expected.
By default, no words are boosted on the server side. Only words passed by the client are boosted.
Out-of-vocabulary word boosting is supported.
Boosting phrases or combination of words is not yet fully supported (but do work). We will revisit finalizing this support in an upcoming release.
Word boosting can improve the chance of recognition of the desired words, but at the same time, can increase false positives. As such, start with a small positive weight and gradually increase till you see positive effects. Start with a boosted score of 20 and increase up to 100 if needed.
Word boosting is most suitable as a temporary fix. For best output, you can attempt a binary search for the boosted weights while monitoring the accuracy metrics on a test set. The accuracy metrics should include both the word error rate (WER) and possibly a form of terms error rate (TER) focusing on the terms of interest.
Word boosting examples - Examples demonstrating how to use word boosting can be found in the /opt/riva/examples/transcribe_file_offline.py and /opt/riva/examples/transcribe_file.py Python scripts in the Riva client image. The following sample command shows how to run these scripts (and the outputs they generate) from within the Riva client container:
/opt/riva/examples# python3 transcribe_file.py --server <Riva API endpoint hostname>:<Riva API endpoint port number> --input-file <audio file path>/audiofile.wav
Final transcript: I had a meeting today with Muhammad Oscar and Katherine Rutherford about the future of Riva at NVIDIA.
/opt/riva/examples# python3 transcribe_file.py --server <Riva API endpoint hostname>:<Riva API endpoint port number> --input-file <audio file path>/audiofile.wav --boosted-lm-words "asghar"
Final transcript: I had a meeting today with Muhammad Asghar and Katherine Rutherford about the future of Riva at NVIDIA.
These scripts show how to add the boosted words to RecognitionConfig, with SpeechContext (look for the "# Append boosted words/score" comment). For more information about SpeechContext, refer to the riva/proto/riva_asr.proto description.
We recommend using boosting score values between 20. and 100. A higher score increases the likelihood that the boosted words appear in the transcript if the words occurred in the audio. However, it can also increase the likelihood that the boosted words appear in the transcription even though they did not occur in the audio. Try experimenting with the boosting score values until you get accurate transcription results. Also, revisit the boosting score value if you switch to a different acoustic model.
The following word boosting code snippets are included in these example
scripts and
tutorial:
import riva.client
uri = "localhost:50051" # Default value
auth = riva.client.Auth(uri=uri)
asr_service = riva.client.ASRService(auth)
config = riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
max_alternatives=1,
profanity_filter=False,
enable_automatic_punctuation=True,
verbatim_transcripts=False,
)
my_wav_file=PATH_TO_YOUR_WAV_FILE
boosted_lm_words = ["first", "second", "third"]
boosted_lm_score = 10.0
riva.client.add_audio_file_specs_to_config(config, my_wav_file)
riva.client.add_word_boosting_to_config(config, boosted_lm_words, boosted_lm_score)
You can also have different boost values for different words. For example, here first is boosted by 10 and
second is boosted by 20:
riva.client.add_word_boosting_to_config(config, ['first'], 10.)
riva.client.add_word_boosting_to_config(config, ['second'], 20.)
Custom Vocabulary#
The Flashlight decoder, deployed by default in Riva, is a lexicon-based decoder and only emits words that are present in the provided vocabulary file. That means, domain specific words that are not present in the vocabulary file have no chance of being generated.
There are two ways to expand the decoder vocabulary:
At Riva build time - When building a custom model, pass the extended vocabulary file to the
--decoding_vocab=<vocabulary_file>parameter of the build command. Out of the box vocabulary files for Riva languages can be found on NGC, for example, for English, the vocabulary file namedflashlight_decoder_vocab.txtcan be found in the Riva ASR English(en-US) LM model.After deployment - For a production Riva system, the lexicon file can be modified, extended, and take effect after a server restart. Refer to the next section.
Note that the greedy decoder (available during the riva-build process under the flag --decoder_type=greedy) is not vocabulary-based and therefore, can produce any character sequence.
Custom Pronunciation (Lexicon Mapping)#
When using the Flashlight decoder, the lexicon file provides a mapping between vocabulary dictionary words and its tokenized form, for example, sentence piece tokens for many Riva models.
Modifying the lexicon file serves two purposes:
Extends the vocabulary.
Provides one or more explicit custom pronunciations for a specific word. For example:
manu ▁ma n u manu ▁man n n ew manu ▁man n ew
Training Language Models#
Introducing a language model to an ASR pipeline is an easy way to improve accuracy for natural language
and can be fine-tuned for niche settings. In short, an n-gram language model estimates the probability
distribution over groups of n or less consecutive words, P (word-1, …, word-n). By altering or biasing
the data on which a language model is trained on, and thus the distribution it is estimating, it can be
used to predict different transcriptions as more likely, and thus alter the prediction without changing
the acoustic model. Riva supports n-gram models trained and exported from KenLM.
Custom language models can provide a permanent solution to improve the recognition of domain specific terms and phrases. A domain specific custom LM can be mixed with a general domain LM via a process called interpolation.
KenLM Setup#
KenLM is the recommended tool for building language models. This toolkit supports estimating, filtering, and querying n-gram language models. To begin, first make sure you have Boost and zlib installed. Depending on your requirements, you may require additional dependencies. Double check by referencing the dependencies list.
After all dependencies are met, create a separate directory to build KenLM.
wget -O - https://kheafield.com/code/kenlm.tar.gz | tar xz
mkdir kenlm/build
cd kenlm/build
cmake ..
make -j2
Estimating#
The next step is to gather and process data. In most cases, KenLM expects data to be natural language (suiting your use case). Common preprocessing steps include replacing numerics and removing umlauts, punctuation, or special characters. However, it is most important that your preprocessing steps are consistent between both your language and acoustic model.
Assuming your current working directory is the build subdirectory of KenLM, bin/lmplz performs
estimation on the corpus provided through stdin and writes the ARPA (a human readable from of the
language model) to stdout. Running bin/lmplz documents the command-line arguments, however, here are
a few important ones:
-o: Required. The order of the language model. Depends on use case, but generally 3-8.-S: Memory to use. Number followed by%for percentage,bfor bytes,Kfor kilobytes, and so on. Default is80%.-T: Temporary file location--text arg: Read text from a file instead ofstdin.--arpa arg: Write ARPA to a file instead ofstdout.--prune arg: Prune n-grams with count less than or equal to the given threshold, with one value specified for each order. For example, to prune singleton trigrams,--prune 0 0 1. The sequence of values must be nondecreasing and the last value applies to all remaining orders. Default is not to prune. Unigram pruning is not supported, so the first number must be0.--limit_vocab_file arg: Read allowed vocabulary separated by whitespace from file in argument and prune all n-grams containing vocabulary items not from the list. Can be combined with pruning.
Pruning and limiting vocabulary help to get rid of typos, uncommon words, and general outliers from the dataset, making the resulting ARPA smaller and generally less overfit, but potentially at the cost of losing some jargon or colloquial language.
With the appropriate options, the language model can be estimated.
bin/lmplz -o 4 < text > text.arpa
Querying and Evaluation#
For faster loading, convert the arpa file to binary.
bin/build_binary text.arpa text.binary
The binary or ARPA can be queried via the command-line.
bin/query text.binary < data
>>>>>>> release/22.06
Training from Scratch#
When a substantial amount of raw text is available, a custom LM can be trained from scratch. Riva supports n-gram models trained and exported from KenLM.
For Riva ASR models in production, we aggregate all the transcribed text in the training data for training the language models.
Limit the vocabulary size if using scraped text. Many online sources contain typos or ancillary pronouns and uncommon words. Removing these can improve the language model.
When the text belongs to a narrow, niche domain, there might be an impact to the overall ASR pipeline in recognizing general domain language, as a trade-off. Therefore, experiment with mixing domain text with general text for a balanced representation.
LM Interpolation#
An alternative approach to mixing data is to mix two or more pretrained n-gram language models in .ARPA format. This can be carried out with a 3rd party tool, such as the SRI ngram tool. For example:
./ngram -order 4 -lm <lm1.arpa> -mix-lm <lm2.arpa> -lambda 0.4 -write-lm <output_lm.arpa>
This command interpolates lm1.arpa and lm2.arpa with weights [0.6, 0.4] while writing to output_lm.arpa.
Deploying a Custom Language Model#
A custom n-gram language model file in binary format can be deployed as part of an ASR pipeline by passing the binary language model file to riva-build using the flag --decoding_language_model_binary=<lm_binary>.
Advanced Customization of Riva ASR#
Inverse Text Normalization#
Riva implements inverse text normalization (ITN) for ASR requests. It uses weight finite state transducers (WFST) based models to convert spoken domain output from an ASR model into a written domain text to improve readability of the ASR systems output.
Text normalization converts text from written form into its verbalized form. It is used as a preprocessing step before TTS. It could also be used for preprocessing ASR training transcripts.
ITN is a part of the ASR post-processing pipeline. ITN is the task of converting the raw spoken output of the ASR model into its written form to improve text readability.
Riva implements NeMo ITN, which is based on WFST grammars. The tool uses Pynini to construct WFSTs. The created grammars can be exported and integrated into Sparrowhawk (an open-source version of the Kestrel TTS text normalization system) for production.
With a functional NeMo installation, the German ITN grammars for example, can be exported with the pynini_export.py tool as follows:
python3 pynini_export.py --output_dir . --grammars itn_grammars --input_case cased --language de
This exports the tokenizer_and_classify and verbalize FSTs as OpenFst finite state archive (FAR) files, ready to be deployed with Riva.
[NeMo I 2022-04-12 14:43:17 tokenize_and_classify:80] Creating ClassifyFst grammars.
Created ./de/classify/tokenize_and_classify.far
Created ./de/verbalize/verbalize.far
To deploy these ITN rules with Riva, pass the FAR files to the riva-build command under these options:
riva-build speech_recognition
[--wfst_tokenizer_model WFST_TOKENIZER_MODEL]
[--wfst_verbalizer_model WFST_VERBALIZER_MODEL]
Additionally, riva-build also supports --wfst_pre_process_model and --wfst_post_process_model arguments to pass the pre and post processing FAR files for inverse text normalization.
To learn more on how to build grammars from the ground-up, consult the NeMo Weighted Finite State Transducers (WSFT) tutorial.
Details on the model architecture can be found in the paper NeMo Inverse Text Normalization: From Development To Production.
Speech Hints#
Speech hints apply an out-of-vision (OOV) class as a part of ASR post-processing pipeline. It uses finite state transducers (FST) to improve readability based on the expected OOV class applied to normalize the output in a more readable format.
Speech hints are applied on the spoken domain output of ASR before passing the generated text through the ITN. The phrases which need to be applied are added to RecognitionConfig using SpeechContext.
import riva.client
uri = "localhost:50051" # Default value
auth = riva.client.Auth(uri=uri)
asr_service = riva.client.ASRService(auth)
config = riva.client.RecognitionConfig(
encoding=riva.client.AudioEncoding.LINEAR_PCM,
max_alternatives=1,
profanity_filter=False,
enable_automatic_punctuation=True,
verbatim_transcripts=False,
)
my_wav_file=PATH_TO_YOUR_WAV_FILE
speech_hints = ["$OOV_ALPHA_SEQUENCE", "i worked at the $OOV_ALPHA_SEQUENCE"]
boost_lm_score = 4.0
riva.client.add_audio_file_specs_to_config(config, my_wav_file)
riva.client.add_word_boosting_to_config(config, speech_hints, boost_lm_score)
The following classes and phrases are supported:
$OOV_NUMERIC_SEQUENCE$OOV_ALPHA_SEQUENCE$OOV_ALPHA_NUMERIC_SEQUENCE$ADDRESSNUM$FULLPHONENUM$POSTALCODE$OOV_CLASS_ORDINAL$MONTH
Training or Fine-Tuning an Acoustic Model#
Model fine-tuning is a set of techniques that makes fine adjustments to a pre-existing model using new data, so as to make it adapt to new situations while also retaining its original capabilities.
Model training refers to training a new model either from scratch (that is, starting from random weights), or with weights initialized from an existing model, but with the goal of having the model acquire totally new skills without necessarily retaining the original capabilities (such as in cross-language transfer learning).
Many use cases require training new models or fine-tuning existing ones with new data. In these cases, there are a few best practices to follow. Many of these best practices also apply to inputs at inference time.
Use lossless audio formats if possible. The use of lossy codecs such as MP3 can reduce quality.
Augment training data. Adding background noise to audio training data can initially decrease accuracy, but increase robustness.
Limit vocabulary size if using scraped text. Many online sources contain typos or ancillary pronouns and uncommon words. Removing these can improve the language model.
Use a minimum sampling rate of 16kHz if possible, but do not resample.
If using NeMo to fine-tune ASR models, refer to the Finetuning CTC models on other languages tutorial. We recommend fine-tuning ASR models only with sufficient data approximately on the order of several hundred hours of speech. If such data is not available, it may be more useful to simply adapt the LM on in-domain text corpus than to train the ASR model.
There is no formal guarantee that the ASR model will or will not be streamable after training. We recommend fine-tuning the Conformer acoustic model if doing streaming recognition. In our experience, it provides better streaming WER after fine-tuning compared to Citrinet.
Training New Models#
Train models from scratch - End-to-end training of ASR models requires large datasets and heavy compute resources. There are more than 5,000 languages around the world, but very few languages have datasets large enough to train high quality ASR models. For this reason, we only recommend training models from scratch where several thousands of hours of transcribed speech data is available.
Cross-language transfer learning - Cross-language transfer learning is especially helpful when training new models for low-resource languages. But even when a substantial amount of data is available, cross-language transfer learning can help boost the performance further.
It is based on the idea that phoneme representation can be shared across different languages. Experiments by the NeMo team showed that on as little as 16h of target language audio data, transfer learning works substantially better than training from scratch. In the GTC 2020 talk, NVIDIA data scientists demonstrate cross-language transfer learning for a low resource language with <30h of speech data.
Fine-Tuning Existing Models#
When other easier approaches have failed to address accuracy issues in challenging situations brought about by significant acoustic factors, such as different accents, noisy environments or poor audio quality, fine-tuning acoustic models should be attempted.
We recommend fine-tuning ASR models with sufficient data approximately, on the order of 100 hours of speech or more. The minimal number of hours which we used for NeMo transfer learning was ~100 hours for CORAAL dataset, as shown in this Cross-Language Transfer Learning, Continuous Learning, and Domain Adaptation for End-to-End Automatic Speech Recognition paper. Our experiments demonstrate that in all three cases of cross-language transfer learning, continuous learning and domain adaptation, transfer learning from a good base model has higher accuracy than a model trained from scratch. It is also preferred to finetune large models than training small models from scratch, even if the dataset for fine-tuning is small.
Low-resource domain adaptation - In case of smaller datasets, such as ~10 hours, appropriate precautions should be taken to avoid overfitting to the domain and hence sacrificing significant accuracy in the general domains, also known as catastrophic forgetting. If fine-tuning will be done on this small dataset, mix with other larger datasets (“base”). For English for example, NeMo has a list of public datasets that it can be mixed with.
In transfer learning, continual learning is a sub-problem wherein models that are trained with new domain data should still retain good performance on the original source domain.
If using NeMo to fine-tune ASR models, refer to this Finetuning CTC models on other languages tutorial.
Data quality and augmentation - Use lossless audio formats if possible. The use of lossy codecs such as MP3 can reduce quality. As a regular practice, use a minimum sampling rate of 16kHz. You can also use Opus-encoded sources with 8K, 16K, 24K or 48K sampling rate.
Augment training data with noise can improve the model’s ability to cope with noisy environments. Adding background noise to audio training data can initially decrease accuracy, but increase robustness.
Punctuation and Capitalization Model#
ASR systems typically generate text with no punctuation and capitalization of the words. In Riva, the punctuation and capitalization model is responsible for formatting the text, enhanced with both punctuation and capitalization.
The punctuation and capitalization model should be customized when an out-of-the-box model does not perform well in the application context, such as when applying to a new language variant.
To either train or fine-tune, and then deploy a custom punctuation and capitalization model, refer to RIVA Punctuation and NeMo Punctuation and Capitalization.
Deploying a Custom Acoustic Model#
If using NVIDIA NeMo, the model must first be exported from a .nemo format to a .riva format using the nemo2riva tool that is available as part of the Riva distribution. Next, use the Riva container and tools (riva-build and riva-deploy) for deployment. For more information, refer to the Deploying Your Custom Model into Riva section.
WFST Decoding#
Language models are used in speech recognition tasks to help disambiguate which word is more likely to occur given it is preceded by a sequence of words. Conventional n-gram models, model the probability of a word occurring given it is preceded by a sequence of (n-1) words.
However, in many domains, there is a likelihood of a having a sequence of words that may be similar in nature.
Consider for example the phrases “I would like to fly from New York to Seattle” and “I would like to fly from London to Paris”, the probabilities of these two sentences are generally only dependent on how often people fly between these places. Otherwise, the probabilities of occurrence of these two sentences in a domain involving booking of flights is equally probable.
This then requires support for building ngram models that consider word classes. Word classes can also be considered as entities or entity types (as in NER), but are more generic in nature.
Support for word classes with ngrams is not trivial. One alternative could be to generate using BNF grammars all possible such sequences. However, this could easily increase the size of the LM and could still cause issues with multi-word word classes.
An alternative approach is to use Weighted-finite state transducers (WFSTs). WFSTs as used in speech recognition consists of three main components:
Grammar WFST (
G.fst) - A grammar WFST encodes word sequences in a language/domain. In general this is basically a language model represented as a weighted finite state acceptor.Lexicon WFST (
L.fst) - A lexicon WFST encodes the mapping between a sequence of tokens (phonemes/BPE/WPE or other CTC units) to the corresponding word.Token WFST (
T.fst) - The token WFST maps a sequence of frame-level CTC labels to a single lexicon unit (phonemes/BPE/WPE or other CTC units).
These three WFSTs are composed together with other operations to form TLG.fst.
The sequence of operations are T ◦ min ( det ( L ◦ G ) ) where
◦refers to the composition operationminrefers to minimizationdetrefers to determinization
For more information, see “Speech Recognition with Weighted Finite-State Transducers” by Mohri, Pereira and Riley (in Springer Handbook on SpeechProcessing and Speech Communication, 2008).
Supporting Class Language models in the WFST framework#
Support for class language models in the WFST framework can be summarized as
modifying G.fst to support paths in the acceptor that refers to word classes.
This requires that
The lexicon has all entries from both the language model and the entries in each of word classes. This is important as otherwise the words in the word classes will not be recognized.
The n-gram model should have the relevant phrases build from word class grammars. For example in the above example the word class grammar would be “I would like to fly from #entity:city to #entity:city” with #entity:city being the label for the word class corresponding to cities with airports. This can be achieved in the following two ways:
Build the language model from text containing standard text as well as word class labels
n-gram LM interpolation/mixing of two LMs, one from standard text and other from domain specific grammars.
The latter option provides for better weighting between in-domain and out of domain LMs. Please refer to the tutorial “How To Train, Evaluate, and Fine-Tune an n-gram Language Model” for LM model interpolation using kenlm. Alternatively SRILM (license required) can also be used here
The process for supporting word classes in the WFST framework basically involves
replacement of the arcs representing the class labels, with FSTs created from
the entities present in the word classes. Given a G.fst containing
word class labels (#entity:<class>), and the files (filenames <class>.txt)
containing the list of entities for the class. The list of entities is not
restricted to words and could be phrases
For example, in the above example cities.txt would contain at the very least the
following
$> cat city.txt
london
new york
paris
seattle
Creating the TLG.fst supporting word classes#
Checkout the class_lm branch from https://github.com/anand-nv/riva-asrlib-decoder/tree/class_lm.
All the below scripts are available in src/riva/decoder/scripts/prepare_TLG_fst path.
Generate the lexicon, list of Tokens/units and list of entities from the arpa file. This is accomplished using
lexicon_from_arpa.pyscript. The syntax for the command is as follows:
lexicon_from_arpa.py --asr_model <path_to_nemo_model> --lm_path <path_to_arpa_file> --grammars <path_to_folder_containing_grammars> <units_txt_path:output> <lexicon_path:output> <classlabels_path:output>
This generates the list of units(tokens), the lexicon and the list of word classes (to be used as disambiguation symbols)
Generate the FSTs,
T.fst,L.fstandG.fst, extend and compose to formTLG.fst
mkgraph_ctc_classlm.sh --units <units_txt_path> --extra_word_disamb <classlabels_path> <lexicon_path> <path_to_arpa_file> <lang_folder_path:output>
When run successfully, the above command will generate a graph folder in
<lang_folder_path> with the name graph_CTC_<lm_name> which contains
all the files relevant for decoding with WFST
Evaluation#
The evaluate_nemo_wfst.py script can help evaluate the WFST decoder before
being used in the Riva service maker build. This would be useful to
debug any issues with TLG.fst
The script can be run as follows
./evaluate_nemo_wfst.py <model_path> <graph_path> <path_containing_audio_files:input> <results_txt_file:output>
Deploying in Riva#
The generated TLG.fst can be used with the kaldi decoder in riva. To build the riva ASR service using the generated
TLG.fst the following command can be used
# Syntax: riva-build <task-name> output-dir-for-rmir/model.rmir:key dir-for-riva/model.riva:key
! docker run --rm --gpus 0 -v $MODEL_LOC:/data $RIVA_SM_CONTAINER -- \
riva-build speech_recognition \
/data/rmir/asr_offline_conformer_ctc.rmir:$KEY \
/data/$MODEL_NAME:$KEY \
--offline \
--name=asr_offline_conformer_wfst_pipeline \
--ms_per_timestep=40 \
--chunk_size=4.8 \
--left_padding_size=1.6 \
--right_padding_size=1.6 \
--nn.fp16_needs_obey_precision_pass \
--featurizer.use_utterance_norm_params=False \
--featurizer.precalc_norm_time_steps=0 \
--featurizer.precalc_norm_params=False \
--featurizer.max_batch_size=512 \
--featurizer.max_execution_batch_size=512 \
--decoder_type=kaldi \
--decoding_language_model_fst=/data/graph/TLG.fst \
--decoding_language_model_words=/data/graph/words.txt \
--kaldi_decoder.asr_model_delay=5 \
--kaldi_decoder.default_beam=17.0 \
--kaldi_decoder.max_active=7000 \
--kaldi_decoder.determinize_lattice=true \
--kaldi_decoder.max_batch_size=1 \
--language_code=en-US \
--wfst_tokenizer_model=<far_tokenizer_file> \
--wfst_verbalizer_model=<far_verbalizer_file> \
--speech_hints_model=<far_speech_hints_file>