Overview
Contents
Overview#
About Riva#
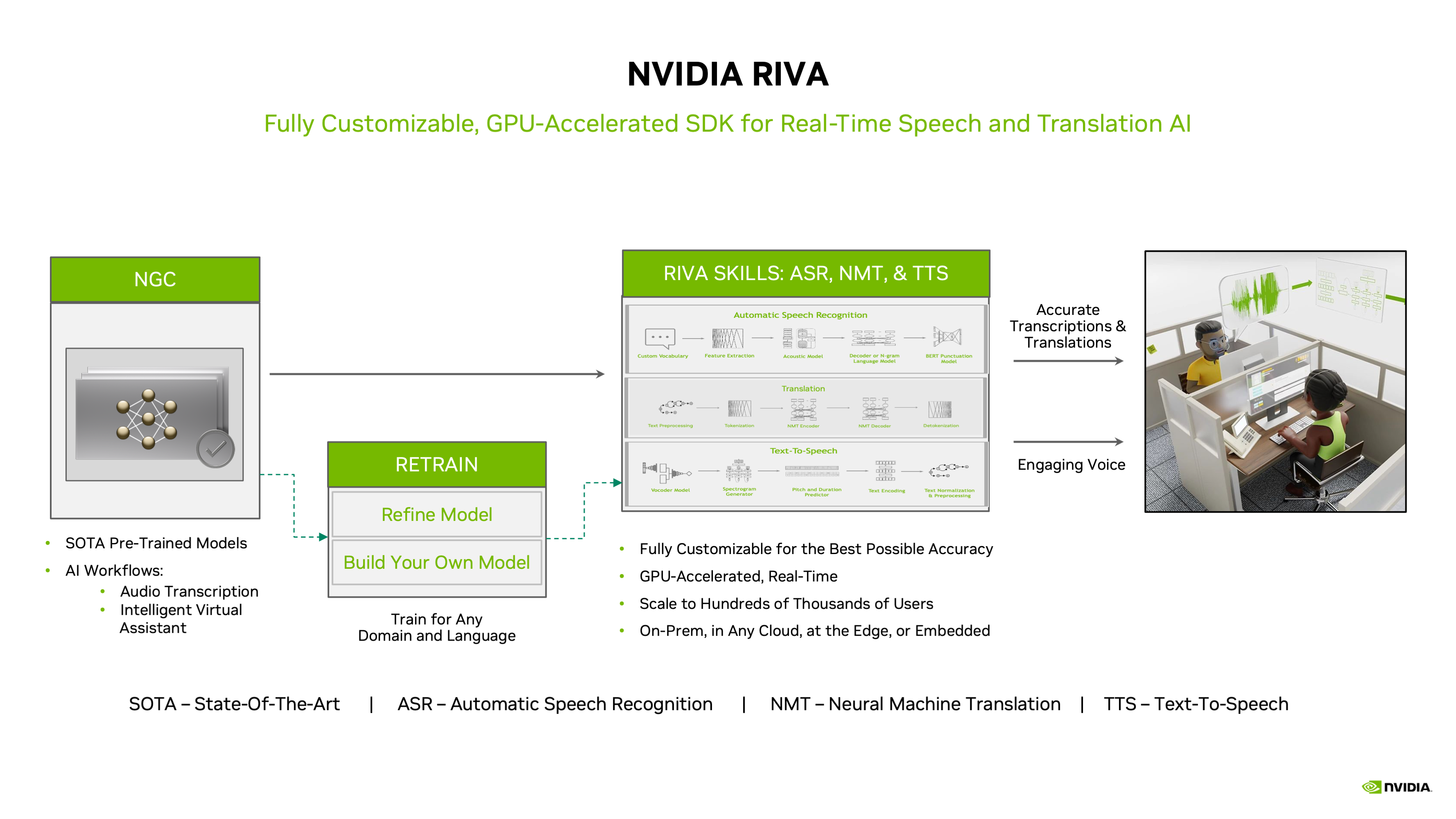
NVIDIA Riva is a GPU-accelerated SDK for building Speech AI applications that are customized for your use case and deliver real-time performance.
Riva offers pretrained speech models in NVIDIA NGC™ that can be fine-tuned with the NVIDIA NeMo on a custom data set, accelerating the development of domain-specific models by 10x.
Models can be easily exported, optimized, and deployed as a speech service on premises or in the cloud with a single command using Helm charts.
Riva’s high-performance inference is powered by NVIDIA TensorRT™ optimizations and served using the NVIDIA Triton™ Inference Server, which are both part of the NVIDIA AI platform.
Riva services are available as gRPC-based microservices for low-latency streaming, as well as high-throughput offline use cases.
Riva is fully containerized and can easily scale to hundreds and thousands of parallel streams.
Some of the major benefits that Riva provides are:
State-of-the-Art AI#
Riva is part of the NVIDIA AI platform - built on a decade of AI innovations by NVIDIA across hardware, model architectures, training techniques, inference optimizations, and deployment solutions.
Fully Customizable#
Flexibility at every step, from modifying model architectures to fine-tuning models on your data and customizing pipelines, as well as the ability to deploy on any platform.
Leading Performance#
Continued optimizations across the entire stack from models to software to hardware delivered 12X the gain versus the previous generation.
What Can You Do with Riva?#
With a few commands, you can access the high-performance services through API operations and try demos. Using Riva, you can easily fine-tune state-of-art models on your data to achieve a deeper understanding of their specific contexts. You can also optimize for inference to offer real-time services that run in 150 milliseconds (ms) compared to the 25 seconds required on CPU-only platforms.
You can use Riva to access highly optimized Automatic Speech Recognition (ASR) and speech synthesis services for use cases like real-time transcription and virtual assistants. The ASR skill is available in multiple languages. It is trained and evaluated on a wide variety of real-world, domain-specific datasets. With telecommunications, podcasting, and healthcare vocabulary, it delivers world-class production accuracy.
You can use Riva’s text-to-speech (TTS) or speech synthesis skills to generate human-like speech. Riva uses nonautoregressive models to deliver 12x higher performance on NVIDIA A100 GPUs compared to Tacotron 2 and WaveGlow models on NVIDIA V100 GPUs. Furthermore, with TTS, you can create a natural custom voice for every brand and virtual assistant with only 30 minutes of an actor’s voice data.
Some of the major tasks that you can perform using Riva are:
Customizing a model with your data Using the NVIDIA NeMo, you can use a custom-trained model in Riva.
Deploying a model in Riva Riva is designed for speech AI at scale. To help you efficiently serve models across different servers robustly, NVIDIA provides push-button model deployment using Helm charts.