Performance
Contents
Performance#
Evaluation Process#
This section presents latency and throughput numbers of the Riva text-to-speech (TTS) service on different GPUs. Performance of the TTS service was measured for a different number of parallel streams. Each parallel stream performed 20 iterations over 10 input strings from the LJSpeech dataset. Each stream sends a request to the Riva server and waits for all audio chunks to have been received before sending another request. Latency to first audio chunk, latency between successive audio chunks, and throughput were measured. The following diagram shows how the latencies are measured.
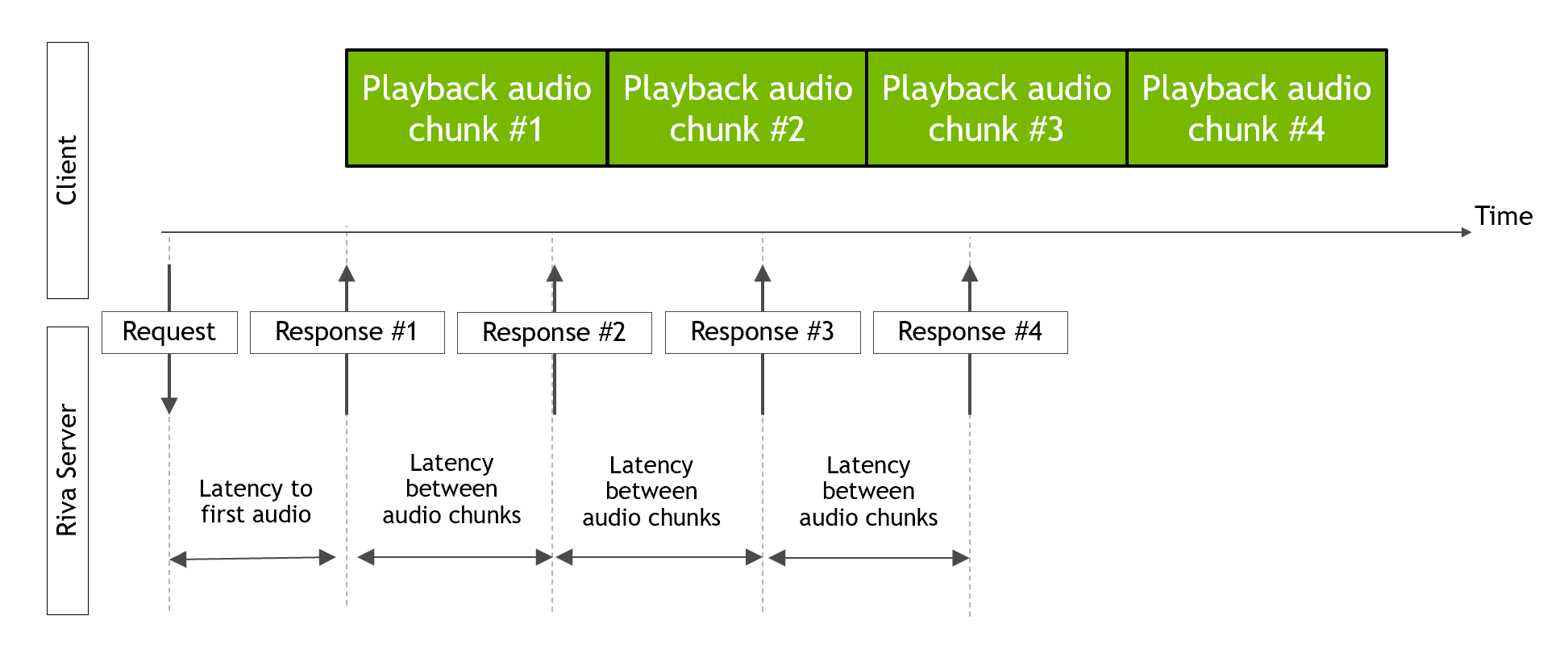
The FastPitch and HiFi-GAN models were tested.
The Riva TTS perf client riva_tts_perf_client,
provided in the Riva image, was used to measure performance. The source code of the client can be obtained from https://github.com/nvidia-riva/cpp-clients.
The following command was used to generate the tables below:
riva_tts_perf_client \
--num_parallel_requests=<num_streams> \
--voice_name=English-US.Female-1 \
--num_iterations=<20*num_streams> \
--online=true \
--text_file=$test_file \
--write_output_audio=false
Where test_file is a path to the
ljs_audio_text_test_filelist_small.txt file.
Results#
Latencies to first audio chunk, latencies between audio chunks, and throughput are reported in the following tables. Throughput is measured in RTFX (duration of audio generated / computation time).
Note
--num_iterations equals 100 for Xavier AGX, Xavier NX, and Orin AGX and 20 for all other measurements.
Note
The values in the tables are average values over 3 trials. The values in the table are rounded to the last significant digit according to standard deviation calculated on 3 trials. If a standard deviation is less than 0.001 of the average, then the corresponding value is rounded as if standard deviation equals 0.001 of the value.
For specifications of the hardware on which these measurements were collected, refer to the Hardware Specifications section. Please notice, that
results on AWS and GCP are computed using Riva 2.4.0
results On-Prem are computed using Riva 2.15.0.
Cloud instance descriptions for AWS and GCP.
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
22 |
24.2 |
25 |
25.3 |
2.84 |
3.1 |
3.15 |
4.02 |
150.8 |
4 |
40 |
50 |
60 |
70 |
5 |
8 |
9 |
12 |
340 |
8 |
63 |
84 |
90 |
100 |
8 |
12 |
14 |
18 |
420 |
16 |
120 |
143 |
154 |
200 |
14.3 |
17.8 |
19.4 |
23 |
460 |
32 |
323 |
340 |
355 |
390 |
14.5 |
17.9 |
19.9 |
23.9 |
440 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
300.9 |
305.5 |
309.4 |
380.6 |
95.2 |
109.8 |
112.3 |
116.1 |
1.43 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
22.35 |
25 |
25 |
26.15 |
3.75 |
4.1 |
4.5 |
5 |
130.5 |
4 |
47 |
64 |
70 |
80 |
7 |
12.6 |
15 |
17.4 |
200 |
8 |
90 |
116 |
120 |
140 |
10 |
17 |
20 |
27 |
300 |
16 |
200 |
200 |
220 |
2000 |
15.8 |
26 |
30.4 |
38 |
300 |
32 |
360 |
425 |
440 |
500 |
17 |
27 |
32 |
40.4 |
400 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
300.2 |
309 |
310 |
313.3 |
97.2 |
112.9 |
116 |
121.7 |
1.40 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
24 |
27 |
28 |
30 |
3.71 |
4.94 |
5.05 |
5.3 |
126 |
4 |
50 |
67 |
74 |
90 |
6.8 |
12 |
14.4 |
18 |
260 |
8 |
100 |
120 |
130 |
500 |
10 |
20 |
22 |
28 |
300 |
16 |
182 |
220 |
240 |
1100 |
17.34 |
28 |
33 |
44 |
286 |
32 |
398.5 |
480 |
500 |
540 |
18.7 |
30 |
35.5 |
45 |
365 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
303.8 |
312.3 |
312.9 |
316.8 |
97.5 |
118.2 |
121.9 |
128.8 |
1.40 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
22.8 |
25 |
25.8 |
26.6 |
3.5 |
4.13 |
4.26 |
5 |
134 |
4 |
48.3 |
65.3 |
70.7 |
80 |
7.26 |
13.5 |
16 |
19.2 |
254 |
8 |
100 |
130 |
139 |
300 |
10.8 |
19 |
22 |
28 |
280 |
16 |
194 |
256 |
280 |
500 |
19.8 |
33 |
38 |
49 |
300 |
32 |
480 |
564 |
593 |
700 |
22.4 |
36 |
41.3 |
53 |
300 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
287.8 |
295.7 |
296.9 |
298.3 |
88.1 |
99.6 |
101.9 |
105.7 |
1.54 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
17 |
19 |
19.3 |
20 |
2.5 |
3.035 |
3.08 |
3.16 |
185 |
4 |
30 |
42 |
50 |
60 |
4 |
6 |
7 |
9 |
430 |
8 |
60 |
80 |
80 |
90 |
6 |
10 |
11 |
14 |
500 |
16 |
100 |
120 |
130 |
2000 |
7.7 |
13 |
14.6 |
18.2 |
500 |
32 |
200 |
230 |
242 |
500 |
9.5 |
13 |
14.6 |
18.63 |
700 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
207.3 |
209.8 |
210.2 |
211.4 |
68 |
77.9 |
79.4 |
81.6 |
2.01 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
27.6 |
31 |
32 |
33 |
4.95 |
5.25 |
6 |
6.1 |
102.8 |
4 |
70 |
84 |
90 |
1000 |
8.43 |
15.4 |
18 |
21 |
200 |
8 |
130 |
163 |
174 |
300 |
11.75 |
19.5 |
22 |
28 |
230 |
16 |
207 |
260 |
290 |
500 |
21 |
32 |
36.5 |
45 |
280 |
32 |
500 |
580 |
600 |
700 |
23.3 |
35.76 |
41 |
50 |
290 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
34 |
38.4 |
39.3 |
50 |
6.92 |
8.2 |
9.2 |
12 |
78.2 |
4 |
100 |
140 |
150 |
200 |
16.8 |
33 |
37 |
43.6 |
114 |
8 |
220 |
285 |
304 |
900 |
28.4 |
45 |
50 |
64 |
120 |
16 |
430 |
568 |
620 |
1000 |
48.5 |
79 |
90 |
110 |
130 |
32 |
1100 |
1300 |
1340 |
2000 |
52 |
87 |
100.6 |
124 |
130 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
341.9 |
352.6 |
353.3 |
356.8 |
120.9 |
144.6 |
149.5 |
156 |
1.13 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
22.6 |
25.1 |
26 |
27 |
3.5 |
4.09 |
4.19 |
5 |
135 |
4 |
50 |
66 |
70 |
83 |
7.5 |
14.3 |
17.33 |
20.07 |
250 |
8 |
98 |
129 |
138 |
154 |
12 |
22 |
26 |
33 |
274 |
16 |
200 |
280 |
300 |
700 |
21.6 |
37.8 |
44 |
56.7 |
270 |
32 |
520 |
610 |
650 |
800 |
24 |
41 |
47.7 |
62 |
280 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
302 |
310.7 |
311.6 |
313.8 |
96.3 |
111.8 |
114.9 |
120.2 |
1.41 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
21.5 |
24.3 |
24.7 |
25.5 |
2.4 |
3.3 |
3.5 |
4 |
162 |
4 |
40 |
55 |
60 |
70 |
5 |
7 |
8 |
10 |
300 |
8 |
60 |
80 |
86 |
100 |
6.8 |
10 |
11 |
13 |
440 |
16 |
100 |
122 |
133 |
170 |
9.7 |
14.4 |
16.4 |
21 |
600 |
32 |
300 |
310 |
320 |
2000 |
12 |
17 |
19.4 |
24 |
500 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
252.4 |
260.8 |
262.4 |
266.7 |
76.2 |
87.9 |
90 |
92.6 |
1.78 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
32.6 |
32.95 |
33.1 |
134.8 |
4.86 |
5.72 |
5.74 |
6.72 |
38.25 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
98.45 |
103.52 |
103.52 |
103.52 |
20.85 |
27.54 |
28.21 |
31.05 |
2.18 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
31 |
40 |
60 |
6.9 |
7.2 |
7.5 |
9 |
80 |
4 |
94 |
125 |
140 |
200 |
17.5 |
30 |
36 |
44 |
118 |
6 |
150 |
200 |
220 |
300 |
25 |
42 |
50 |
63 |
117 |
8 |
190 |
260 |
290 |
350 |
34.4 |
55 |
64 |
79.7 |
119 |
10 |
216 |
300 |
330 |
400 |
38 |
61 |
70 |
87 |
119.2 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
76 |
77 |
78 |
90 |
44 |
48 |
48 |
50 |
18 |
4 |
690 |
940 |
1000 |
1100 |
70 |
115 |
148 |
200 |
22.6 |
6 |
1130 |
1510 |
1590 |
1750 |
91 |
170 |
210 |
296 |
22.5 |
8 |
1637 |
2100 |
2200 |
2400 |
101 |
186 |
230 |
320 |
22.53 |
10 |
2050 |
2500 |
2610 |
2900 |
110 |
200 |
246 |
340 |
22.9 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
27 |
40 |
40 |
5.05 |
6.2 |
7 |
8 |
100 |
4 |
53 |
70 |
80 |
100 |
9.4 |
16.1 |
18.2 |
24 |
215 |
6 |
77 |
108.4 |
120 |
150 |
12.25 |
20.8 |
23.8 |
30 |
233 |
8 |
100 |
140 |
150 |
180 |
15.5 |
25.6 |
30 |
40 |
240 |
10 |
113 |
157 |
170 |
200 |
17.2 |
28 |
32 |
42 |
245 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
60 |
54.8 |
55 |
56 |
27.4 |
29.6 |
30.2 |
31 |
28 |
4 |
330 |
444 |
470 |
530 |
30.8 |
47 |
56 |
77 |
48.9 |
6 |
500 |
650 |
690 |
770 |
35 |
57 |
70 |
100 |
53.4 |
8 |
670 |
860 |
900 |
990 |
39 |
68 |
83 |
120 |
55.9 |
10 |
840 |
1050 |
1140 |
1350 |
43 |
76 |
94 |
130 |
56.5 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
30 |
50 |
60 |
5.6 |
6.17 |
6.24 |
6.4 |
90 |
4 |
57 |
80 |
90 |
100 |
9.3 |
16 |
17.5 |
26 |
210 |
6 |
82 |
120 |
130 |
150 |
12 |
19.2 |
22 |
28 |
230 |
8 |
113 |
158 |
170 |
200 |
15 |
24 |
27 |
33 |
230 |
10 |
122 |
170 |
184 |
200 |
17 |
26.8 |
30 |
37 |
236 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
66 |
67.6 |
68.4 |
70 |
33.1 |
35.8 |
36 |
37 |
23 |
4 |
356 |
480 |
510 |
564 |
32 |
50 |
57 |
76 |
45.5 |
6 |
530 |
700 |
740 |
800 |
37 |
60 |
70 |
100 |
50.4 |
8 |
710 |
930 |
980 |
1060 |
40 |
66 |
80 |
110 |
53.2 |
10 |
870 |
1070 |
1160 |
1360 |
43 |
73 |
90 |
130 |
55 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
25.1 |
40 |
50 |
3.8 |
4.7 |
5.1 |
5.4 |
120 |
4 |
38 |
50 |
60 |
90 |
5.9 |
9.97 |
11.7 |
15 |
320 |
6 |
51 |
70 |
76 |
100 |
7.2 |
12.4 |
14.6 |
19 |
370 |
8 |
63 |
85 |
90 |
100 |
8.5 |
15 |
17 |
23 |
400 |
10 |
68 |
94 |
102 |
120 |
9.3 |
17 |
20 |
26 |
420 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
40 |
42.3 |
42.7 |
45 |
19.9 |
21.8 |
22.4 |
23 |
38 |
4 |
194 |
268 |
285 |
310 |
18 |
27 |
30 |
36 |
83 |
6 |
270 |
350 |
370 |
410 |
20 |
30 |
36 |
47 |
97 |
8 |
350 |
450 |
470 |
510 |
21 |
34 |
40 |
50 |
105 |
10 |
430 |
525 |
560 |
680 |
22.4 |
35 |
41 |
56 |
109 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
26 |
40 |
50 |
3.4 |
4.04 |
4.14 |
4.6 |
120 |
4 |
40 |
55 |
60 |
90 |
5.3 |
9 |
10 |
13 |
320 |
6 |
54 |
75 |
80 |
100 |
6.7 |
11.1 |
13.02 |
17 |
370 |
8 |
64 |
87 |
95 |
100 |
8.2 |
14.07 |
16.4 |
21.5 |
410 |
10 |
68 |
94 |
100 |
120 |
9 |
16 |
19 |
25 |
430 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
45 |
45.1 |
45.8 |
50 |
21.33 |
24 |
24.1 |
24.6 |
36 |
4 |
197 |
280 |
296 |
320 |
18 |
27 |
31 |
37 |
83 |
6 |
267 |
345 |
360 |
394 |
19 |
30 |
34 |
42 |
99 |
8 |
336 |
430 |
450 |
500 |
21.6 |
34 |
39 |
50 |
108 |
10 |
414 |
496 |
526 |
660 |
22.3 |
35 |
40 |
53 |
113 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
34.4 |
50 |
70 |
7.7 |
8.2 |
8.4 |
10 |
70 |
4 |
98 |
135 |
150 |
200 |
18.4 |
31 |
36 |
46 |
113 |
6 |
156 |
225 |
240 |
300 |
25 |
40.5 |
45 |
57 |
114 |
8 |
205 |
290 |
310 |
360 |
33 |
52 |
60 |
72 |
116 |
10 |
230 |
320 |
340 |
400 |
37 |
56 |
63 |
80 |
118 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
80 |
83 |
84 |
100 |
44.6 |
48.6 |
49.2 |
50.4 |
17.6 |
4 |
650 |
900 |
950 |
1050 |
69 |
116 |
144 |
190 |
23.4 |
6 |
1056 |
1390 |
1470 |
1600 |
85 |
157 |
190 |
270 |
23.97 |
8 |
1520 |
2000 |
2100 |
2270 |
95 |
174 |
220 |
300 |
24.25 |
10 |
1890 |
2350 |
2500 |
3000 |
105 |
200 |
240 |
350 |
24.45 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
30 |
27.6 |
40 |
50 |
5.6 |
6.16 |
6.24 |
6.5 |
100 |
4 |
58 |
80.5 |
90 |
100 |
9.8 |
16 |
18.5 |
28 |
200 |
6 |
83 |
120 |
130 |
150 |
13 |
20.6 |
24 |
32 |
220 |
8 |
112.3 |
157 |
170 |
200 |
16 |
26 |
30 |
37 |
223 |
10 |
124 |
172 |
183 |
200 |
18.3 |
28.4 |
32 |
40 |
227 |
# of streams |
Latency to first audio (ms) |
Latency between audio chunks (ms) |
Throughput (RTFX) |
||||||
|---|---|---|---|---|---|---|---|---|---|
avg |
p90 |
p95 |
p99 |
avg |
p90 |
p95 |
p99 |
||
1 |
63 |
65 |
66 |
67 |
32.5 |
35.1 |
35.7 |
36.4 |
24 |
4 |
366 |
500 |
520 |
600 |
32.7 |
50 |
60 |
80 |
44.7 |
6 |
540 |
710 |
754 |
820 |
37 |
60 |
75 |
106 |
49.5 |
8 |
720 |
930 |
980 |
1080 |
40.5 |
68 |
83 |
115 |
52.7 |
10 |
900 |
1100 |
1200 |
1400 |
43.4 |
76 |
95 |
130 |
53.5 |
On-Prem Hardware Specifications#
GPU |
|
|---|---|
NVIDIA DGX A100 40 GB |
|
CPU |
|
Model |
AMD EPYC 7742 64-Core Processor |
Thread(s) per core |
2 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
8 |
Frequency boost |
enabled |
CPU max MHz |
2250 |
CPU min MHz |
1500 |
RAM |
|
Model |
Micron DDR4 36ASF8G72PZ-3G2B2 3200MHz |
Configured Memory Speed |
2933 MT/s |
RAM Size |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA A40 |
|
CPU |
|
Model |
AMD EPYC 7763 64-Core Processor |
Thread(s) per core |
1 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
8 |
Frequency boost |
enabled |
CPU max MHz |
3529 |
CPU min MHz |
1500 |
RAM |
|
Model |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
Configured Memory Speed |
3200 MT/s |
RAM Size |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA A30 |
|
CPU |
|
Model |
AMD EPYC 7742 64-Core Processor |
Thread(s) per core |
1 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
2 |
Frequency boost |
disabled |
CPU max MHz |
2250.0000 |
CPU min MHz |
1500.0000 |
RAM |
|
Model |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
Configured Memory Speed |
3200 MT/s |
RAM Size |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA A10 |
|
CPU |
|
Model |
AMD EPYC 7763 64-Core Processor |
Thread(s) per core |
1 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
8 |
Frequency boost |
enabled |
CPU max MHz |
2450 |
CPU min MHz |
1500 |
RAM |
|
Model |
Samsung DDR4 M393A4K40DB3-CWE 3200 MHz |
Configured Memory Speed |
3200 MT/s |
RAM Size |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA H100 80GB HBM3 |
|
CPU |
|
Model |
Intel(R) Xeon(R) Platinum 8480CL |
Thread(s) per core |
2 |
Socket(s) |
2 |
Core(s) per socket |
56 |
NUMA node(s) |
2 |
CPU max MHz |
3800 |
CPU min MHz |
800 |
RAM |
|
Model |
Micron DDR5 MTC40F2046S1RC48BA1 4800MHz |
Configured Memory Speed |
4400 MT/s |
RAM Size |
32x64GB (2048GB Total) |
GPU |
|
|---|---|
NVIDIA V100 SXM2 16 GB |
|
CPU |
|
Model |
Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz |
Thread(s) per core |
2 |
Socket(s) |
2 |
Core(s) per socket |
20 |
NUMA node(s) |
2 |
CPU max MHz |
3600 |
CPU min MHz |
1200 |
RAM |
|
Model |
Micron DDR4 36ASF4G72PZ-2G6D1 2667MHz |
Configured Memory Speed |
2133 MT/s |
RAM Size |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA T4 |
|
CPU |
|
Model |
Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz |
Thread(s) per core |
2 |
Socket(s) |
2 |
Core(s) per socket |
18 |
NUMA node(s) |
2 |
CPU max MHz |
3900 |
CPU min MHz |
1000 |
RAM |
|
Model |
Samsung DDR4 M393A2K43BB1-CTD 2666MHz |
Configured Memory Speed |
2666 MT/s |
RAM Size |
24x16GB (384GB Total) |
GPU |
|
|---|---|
NVIDIA L4 |
|
CPU |
|
Model |
AMD EPYC 7763 64-Core Processor |
Thread(s) per core |
1 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
8 |
Frequency boost |
enabled |
CPU max MHz |
3529 |
CPU min MHz |
1500 |
RAM |
|
Model |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
Configured Memory Speed |
3200 MT/s |
RAM Size |
16x32GB (512GB Total) |
GPU |
|
|---|---|
NVIDIA L40 |
|
CPU |
|
Model |
AMD EPYC 7763 64-Core Processor |
Thread(s) per core |
1 |
Socket(s) |
2 |
Core(s) per socket |
64 |
NUMA node(s) |
8 |
Frequency boost |
enabled |
CPU max MHz |
3529 |
CPU min MHz |
1500 |
RAM |
|
Model |
Samsung DDR4 M393A4K40DB3-CWE 3200MHz |
Configured Memory Speed |
3200 MT/s |
RAM Size |
16x32GB (512GB Total) |
Performance Considerations#
When the server is under high load, requests might time out, as the server will not start inference for a new request until a previous request is completely generated so that inference slot can be freed. This is done to maximize throughput for the TTS service and allow for real-time interaction.
Model Accuracy#
Riva evaluates TTS model accuracy using an automated approach that leverages Automatic Speech Recognition (ASR). The process works as follows:
The TTS model generates synthetic speech from input text
This generated audio is then passed through an ASR system
The ASR transcription is compared with the original input text using Character Error Rate (CER)
The Character Error Rate measures the percentage of characters that differ between the original text and the ASR transcription of the synthesized speech. A lower CER indicates better TTS quality, as it means the synthesized speech was clear enough for ASR to accurately transcribe it back to the original text.
The following table shows the Character Error Rate (CER) scores for the Multilingual Magpie model.
Model |
Language |
Dataset |
CER % ⬇️ |
ASR model used |
|---|---|---|---|---|
Multilingual |
English |
1.0 |
||
Spanish |
1.1 |
|||
French |
3.9 |
Note
We performed metrics calculations on a subset of the dev-clean split of LibriTTS for English, and the CML dataset for French and Spanish. For our analysis, we selected a subset of samples from the total available samples, ensuring that all speakers had at least 5 utterances of at least 5 seconds each. The reported metrics are the average values obtained from multiple iterations, ensuring a more efficient and reliable evaluation of the metrics.