Overview
Contents
Overview#
Riva handles deployments of full pipelines, which can be composed of one or more supported NVIDIA NeMo models and other pre-/post-processing components. These pipelines have to be exported to an efficient inference engine and optimized for the target platform. Therefore, the Riva server cannot use unsupported NVIDIA NeMo models directly because they represent only a single model.
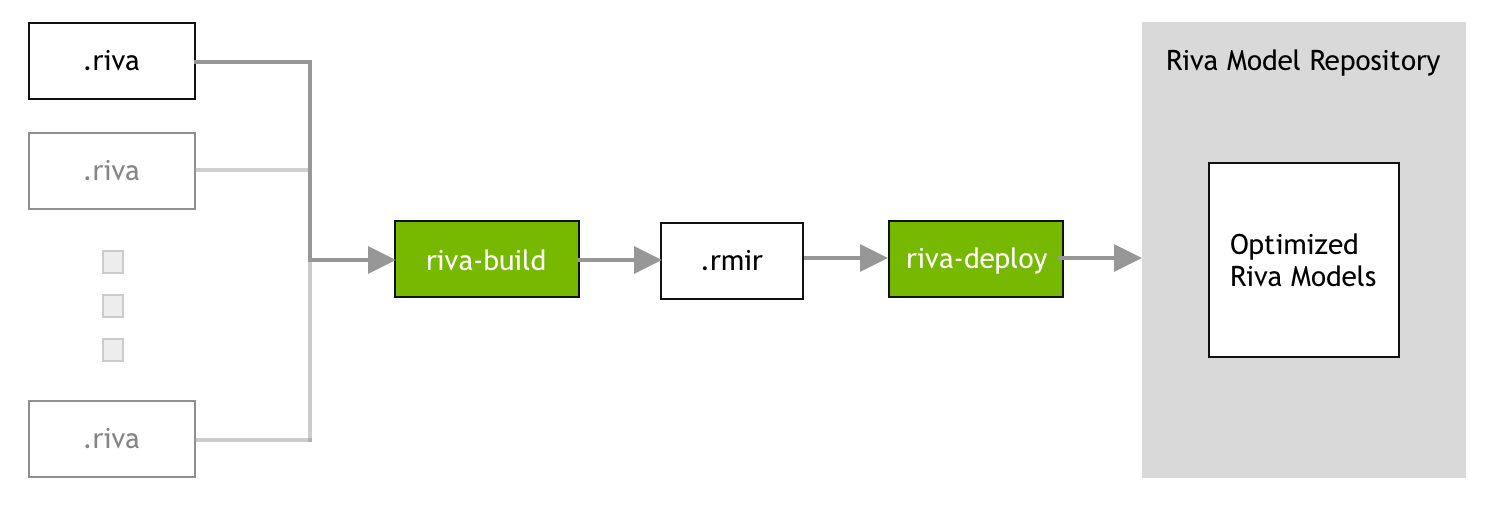
The process of gathering all the required artifacts (for example, models, files, configurations, and user settings) and generating the inference engines, will be referred to as the Riva model repository generation. The Riva Docker image has all the tools necessary to generate the Riva model repository and can be pulled from NGC as follows:
Data center
docker pull nvcr.io/nvidia/riva/riva-speech:2.24.0
Embedded
docker pull nvcr.io/nvidia/riva/riva-speech:2.24.0-l4t-aarch64
The Riva model repository generation is done in three phases:
Phase 1: The development phase. To create a model in Riva, the model checkpoints must be converted to .riva format. You
can further develop these .riva models using NeMo. For more information, refer to the Model Development with NeMo sections.
Note
For embedded, Phase 1 must be performed on the Linux x86_64 workstation itself, and not on the NVIDIA Jetson platform.
After the .riva files are generated, Phase 2 and Phase 3 must be performed on the Jetson platform.
Phase 2: The build phase. During the build phase, all the necessary artifacts (models, files, configurations, and user settings) required to deploy a Riva service are gathered into an intermediate file called RMIR (Riva Model Intermediate Representation). For more information, refer to the Riva Build section.
Phase 3: The deploy phase. During the deploy phase, the RMIR file is converted into the Riva model repository and the neural networks in the NeMo format is exported and optimized to run on the target platform. The deploy phase should be executed on the physical cluster on which the Riva server is deployed. For more information, refer to the Riva Deploy section.
Using Your Own Data#
Many use cases require training new models or fine-tuning existing ones with new data. In these cases, there are a few guidelines to follow. Many of these guidelines also apply to inputs at inference time.
Use lossless audio formats if possible. The use of lossy codecs such as MP3 can reduce quality.
Augment training data. Adding background noise to audio training data can initially decrease accuracy, but increase robustness.
Limit vocabulary size if using scraped text. Many online sources contain typos or ancillary pronouns and uncommon words. Removing these can improve the language model.
Use a minimum sampling rate of 16kHz if possible, but do not resample.
If using NeMo to fine-tune ASR models, consult this tutorial. We recommend fine-tuning ASR models only with sufficient data approximately on the order of several hundred hours of speech. If such data is not available, it may be more useful to simply adapt the LM on in-domain text corpus rather than to train the ASR model.
There is no guarantee that the ASR model will or will not be stream-able after training. We see that with more training (thousands of hours of speech, 100-200 epochs), models generally obtain better offline scores and online scores do not degrade as severely (but still degrade to some extent due to differences between online and offline evaluation).
Model Development with NeMo#
NeMo is an open source PyTorch-based toolkit for research in conversational AI that exposes more of the model and PyTorch internals. Riva supports the ability to import supported models trained in NeMo.
For more information, refer to the NeMo project page.
Export Models with NeMo2Riva#
Models trained in NVIDIA NeMo have the format .nemo. To use these models in Riva, convert the model checkpoints to .riva format for building and deploying with Riva using the nemo2riva tool. The nemo2riva tool is currently packaged and available via the Riva Quick Start scripts.
Refer to this nemo2riva README for detailed instructions on exporting different model architectures from .nemo to .riva format.
Riva Build#
The riva-build tool is responsible for deployment preparation. It is only output is an
intermediate format (called an RMIR) of an end-to-end pipeline for the supported
services within Riva. This tool can take multiple different types
of models as inputs. Currently, the following pipelines are supported:
speech_recognition(for ASR)speech_synthesis(for TTS)punctuation(for NLP)translation(for NMT)
Launch an interactive session inside the Riva image.
Data center
docker run --gpus all -it --rm \ -v <artifact_dir>:/servicemaker-dev \ -v <riva_repo_dir>:/data \ --entrypoint="/bin/bash" \ nvcr.io/nvidia/riva/riva-speech:2.24.0
Embedded
docker run --gpus all -it --rm \ -v <artifact_dir>:/servicemaker-dev \ -v <riva_repo_dir>:/data \ --entrypoint="/bin/bash" \ nvcr.io/nvidia/riva/riva-speech:2.24.0-l4t-aarch64
where:
<artifact_dir>is the folder or Docker volume that contains the.rivafile and other artifacts required to prepare the Riva model repository.<riva_repo_dir>is the folder or Docker volume where the Riva model repository is generated.
Run the
riva-buildcommand from within the container.riva-build <pipeline> \ /servicemaker-dev/<rmir_filename>:<encryption_key> \ /servicemaker-dev/<riva_filename>:<encryption_key> \ <optional_args>
where:
<pipeline>must be one of the following:speech_recognitionspeech_synthesisqatoken_classificationintent_slottext_classificationpunctuationtranslation
<rmir_filename>is the name of the RMIR file that is generated.<riva_filename>is the name of therivafile(s) to use as input.<args>are optional arguments to configure the Riva service. The following section discusses the different ways the ASR, NLP, and TTS services can be configured.<encryption_key>is optional. If the.rivafile is generated without an encryption key, the input/output files are specified with<riva_filename>instead of<riva_filename>:<encryption_key>.
By default, if a file named <rmir_filename> already exists, it will not be overwritten. To force the <rmir_filename> to be overwritten, use the -f or --force argument. For example, riva-build <pipeline> -f ...
For details about the optional parameters that can be passed to riva-build to customize the Riva pipeline, run:
riva-build <pipeline> -h
Riva Deploy#
The riva-deploy tool takes as input one or more RMIR files and a target model repository directory. It is
responsible for performing the following functions:
Model Optimization: Optimize the frozen checkpoints for inference on the target GPU.
Configuration Generation: Generate configuration files for backend components including ensembles of models.
The Riva model repository can be generated from the Riva .rmir file(s) with the following command:
riva-deploy /servicemaker-dev/<rmir_filename>:<encryption_key> /data/models
By default, if the destination folder (that is, /data/models/ in the above example) already exists, it will not be overwritten.
To force the destination folder to be overwritten, use the -f or --force parameter. For example, riva-deploy -f ...
Deploying Your Custom Model into Riva#
This section provides a brief overview on the two main tools used in the deployment process:
The build phase using
riva-build.The deploy phase using
riva-deploy.
Build Process#
For your custom trained model, refer to the riva-build phase (ASR, NLP, NMT, TTS) for your model type. At the end of this phase, you will have the RMIR archive for your custom model.
Deploy Process#
At this point, you already have your RMIR archive. Now, you have two options for deploying this RMIR.
Option 1: Use the Quick Start scripts (riva_init.sh and riva_start.sh) with the appropriate parameters in
config.sh.
Option 2: Manually run riva-deploy and then start riva-server with the target model repository.
Using Quick Start Scripts to Deploy (Recommended)#
The Quick Start scripts (riva_init.sh and riva_start.sh) use a particular directory for its operations. This directory
is defined by the variable $riva_model_loc specified in config.sh.
For data center, by default, this is set to use a Docker volume, however, you can specify any local directory to this variable.
For embedded platforms, this is set to a local directory called
model_repository which gets created at the same location where the Quick Start scripts are present.
By default, the riva_init.sh Quick Start script performs the following:
Downloads the RMIRs defined and enabled in
config.shfrom NGC into a subdirectory at$riva_model_loc, specifically$riva_model_loc/rmir.Executes
riva-deployfor each of the RMIRs at$riva_model_loc/rmirto generate their corresponding Riva model repository at$riva_model_loc/models.
When you execute riva_start.sh, it starts with the riva-speech container by mounting this $riva_model_loc directory
to /data inside the container.
To deploy your own custom RMIR, or set of RMIRs, place them inside the $riva_model_loc/rmir
directory. Ensure you have defined a directory (that you have access to) in the $riva_model_loc variable in config.sh,
since you will need to copy over your RMIRs in its subdirectory. If the subdirectory $riva_model_loc/rmir does not exist,
create it, and then copy your custom RMIRs there.
If you want to skip the downloading of the default RMIRs from NGC, set the $use_existing_rmirs variable to
true. After your custom RMIRs are inside this $riva_model_loc/rmir directory, run riva_init.sh to
execute riva-deploy on your custom RMIRs along with any other RMIRs that are present on that directory and generate the Riva
model repository at $riva_model_loc/models.
Next, run riva_start.sh to start the riva-speech container
and load your custom models along with any other models that are present at $riva_model_loc/models. If you only want to load your
specific models, ensure that $riva_model_loc/models is empty or the /models directory is not present before you run
riva_init.sh. The riva_init.sh script creates the /rmir and /models subdirectories if they are not already there.
For more information about seeing logs and using client containers for testing your models, refer to the Local (Docker) section.
Using riva-deploy and Riva Speech Container (Advanced)#
Execute
riva-deploy. Refer to the Riva Deploy section for a brief overview onriva-deploy.riva-deploy -f <rmir_filename>:<encryption_key> /data/models
If your
.rmirarchives are encrypted, you need to include:<encryption_key>at the end of the RMIR filename. Otherwise, this is unnecessary.The above command creates the Riva model repository at
/data/models. If you want to write to any other location other than/data/models, this will require additional manual changes in the embedded artifact directories within the configuration files within some of the model repositories that has model-specific artifacts such as class labels. Therefore, stick with/data/modelsunless you are familiar with Triton Inference Server model repository configurations.Manually start the
riva-serverDocker container usingdocker run. After the Riva model repository for your custom model is generated, start the Riva server on that target repository. The following command assumes you generated the model repository at/data/models.docker run -d --gpus 1 --init --shm-size=1G --ulimit memlock=-1 --ulimit stack=67108864 \ -v /data:/data \ -p 50051:50051 \ -e "CUDA_VISIBLE_DEVICES=0" \ --name riva-speech \ nvcr.io/nvidia/riva/riva-speech:2.24.0 \ start-riva --riva-uri=0.0.0.0:50051 --nlp_service=true --asr_service=true --tts_service=true
This command launches the Riva Speech Service API server similar to the Quick Start script
riva_start.sh. For example:Starting Riva Speech Services > Waiting for Riva server to load all models...retrying in 10 seconds > Waiting for Riva server to load all models...retrying in 10 seconds > Waiting for Riva server to load all models...retrying in 10 seconds > Riva server is ready…
Verify that the servers have started correctly and check that the output of
docker logs riva-speechshows:I0428 03:14:50.440955 1 riva_server.cc:71] Riva Conversational AI Server listening on 0.0.0.0:50051