Product Description#
Aerial Testbed is an AI/ML enabled end-to-end, real-time Over-The-Air (OTA) testbed for AI-RAN research. As shown in the figure below, ATB is an on-prem edge-cloud datacenter that is built on the NVIDIA Aerial CUDA-Accelerated RAN in-line accelerated L1, integrated with the OpenAirInterface (OAI) Software Alliance L2, and Core Network (CN). The Aerial CUDA-Accelerated RAN L1 runs on the Hopper GPU and the OAI L2 runs on the Grace CPU. The default L2 configuration assumes the CN is run on the same host as the L1 and L2, but the L2 also supports running the CN on a separate x86 or ARM server. An NVIDIA NIC connects via a fronthaul switch to one or more O-RUs using O-RAN 7.2x for single or multi-cell operation.
NVIDIA Aerial CUDA-Accelerated RAN L1 and OAI L2 stacks are open source. Researchers can bring their innovations to reality through customization of the modulation, coding and signal processing algorithms in the data and control channels of the air interface. With source for L2 machine learning (ML) algorithms, deep reinforcement learning (DRL) can be implemented in the MAC and scheduler.
With an ATB testbed you can test ML algorithms at all layers of the stack. You can bring ML to the physical layer, to layer 2, and benchmark them in a live network. As real O-RUs are used in the testbed, your algorithms can be verified and benchmarked in the context of real-world wireless channels, in addition to all the non-idealities present in a physical gNB such as power amplifier non-linearities, RF gain and phase mismatch, and other imperfections in the analog electronics. ATB can be used in conjunction with real-time channel emulators and UE emulators to test algorithms with traditional 3GPP stochastic channel models in addition to using site-specific models generated by RF ray tracing in a digital twin, such as NVIDIA Aerial Omniverse Digital Twin.
ATB is built with an eye to enabling AI/ML research. It supports the capture of OTA data for use in training pipelines. Data collection is facilitated using NVIDIA Aerial Data Lake, which collects uplink I/Q samples from O-RU(s) over the 7.2x fronthaul interface and writes them to a database. FAPI meta information exchanged between L1 and L2 is also collected and populated in the database and can be used for indexing into and extracting data from the Data Lake database.
While the uplink I/Q samples and L2 meta information are useful for some types of algorithm development, each type of ML, or for that matter non-ML, algorithm design requires a data set tailored to the use case at hand. This is where NVIDIA pyAerial helps. While there are multiple uses for pyAerial, one application is for generating data sets corresponding to any node in the cuPHY PUSCH pipeline. pyAerial brings cuPHY CUDA kernels to Python. It is a library of cuPHY L1 kernels that have been provisioned with Python APIs. It is straightforward for a researcher to, for example, assemble a complete PUSCH pipeline using pyAerial blocks. Since under the pyAerial API the blocks are invoking the same CUDA code that is employed in the real-time cuPHY L1, the pyAerial pipeline is bit-equivalent to the pure CUDA cuPHY pipeline. You might want access to, for example, the input and output samples of cuPHY minimum mean square error (MMSE) channel estimator. You can simply instrument your pyAerial Python code with file I/O operations for each node of interest in the pyAerial graph.
The figure below shows the E2E architecture and software stack for Aerial Testbed.
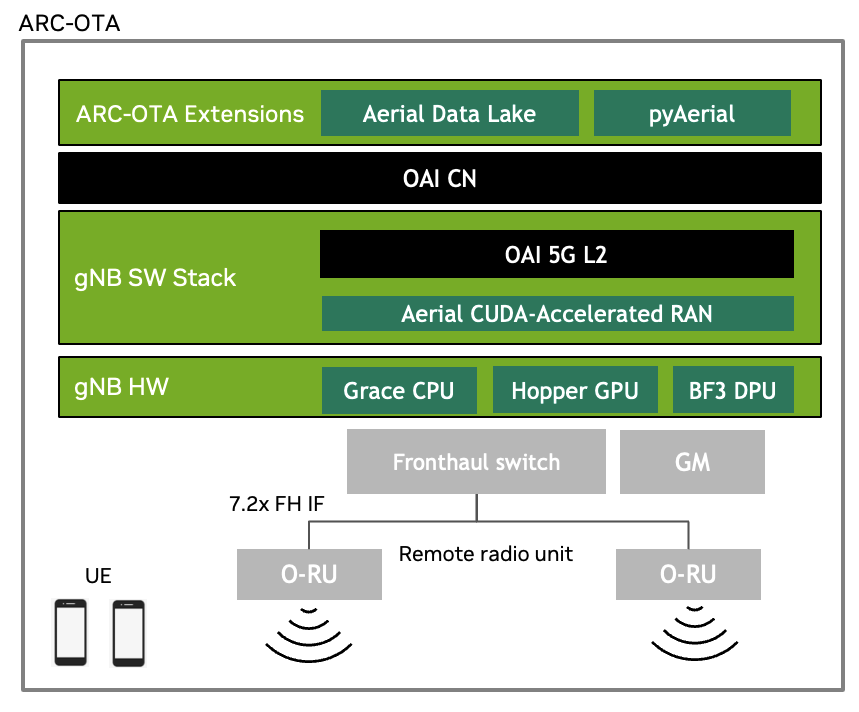
Key Features and Specifications#
The configuration and capabilities of ATB 1.0 are outlined in the following sections.
Feature |
Value |
|---|---|
Number Antennas |
4T4R |
Number of Component Carriers |
1x 100MHz carrier |
Subcarrier Spacing (PDxCH; PUxCH, SSB) |
30 kHz |
FFT Size |
4096 |
MIMO layers |
DL: 4 layers; UL: 1 layer |
Duplex Mode |
Release 15 SA TDD |
Number of RRC connected UEs |
Up to 100 |
Number of UEs/TTI |
16 |
Frame structure and slot format |
DDDDDDSUUU |
DSUUU |
|
User plane latency (RRC connected) |
< 10ms one way for DL and UL mode |
Synchronization and Timing |
IEEE 1588v2 PTP; SyncE; LLS-C3 |
Frequency Band |
n78, n48 (CBRS) |
Max Transmit Power |
22 dBm at RF connector |
Peak throughput |
Refer to the Release Notes for the latest peak throughput values. |
Bi-directional UDP Traffic |
> 10+ hours exercised (SMC-GH) |
Tip
To learn how KPIs have changed from last release, refer to the Release Notes.
5G NR gNB Features#
Component |
Capabilities |
|---|---|
gNB PHY |
Refer to the Aerial CUDA-Accelerated RAN cuBB documentation |
gNB MAC |
Refer to the Aerial CUDA-Accelerated RAN cuBB documentation |
5G Core Features#
AMF |
Features |
NGAP AMF status indication (3GPP TS 38.413) |
Add UE Retention Information support (3GPP TS 38.413) |
||
Support of Location services with LMF and AMF (3GPP TS 29.518, 3GPP TS 38.413, 3GPP TS 23.502) |
||
Update NAS with Rel 16.14.0 IEs: Refactor code for Encode/Decode functions; cleanup NAS library (3GPP TS 24.501) |
||
Fixes |
Fix typo for N1N2MessageSubscribe (3GPP TS 29.518) |
|
Fix issue when receiving PDU session reject from SMF (3GPP TS 29.518, 3GPP TS 23.502) |
||
Technical Debt |
Reformatting of the SCTP code |
|
Refactor promise handling |
||
Removing dependencies to libconfig++ (Only YAML file can be read as configuration) |
||
SMF |
Features |
Add N1/N2 info in the message response to AMF if available (3GPP TS 29.502) |
Fixes |
Add connection handling mechanism between NRF and SMF |
|
Technical Debt |
Refactor SMF PFCP associations to use UPF profile |
|
UDM |
Fixes |
Add connection handling mechanism between NRF and UDM |
UDR |
Technical Debt |
Fixed builds |
Add connection handling mechanism between NRF and UDR |
||
Improve MongoDB support |
||
Common |
New HTTP Client library (CPR) for all the NFs |
|
Support mobility registration update procedure (3GPP TS 23.502) |
5G Fronthaul Features#
RU Category |
Category A |
|---|---|
FH Split Compliance |
7.2x with DL low-PHY to include Precoding, Digital BF, iFFT+CP and UL low-PHY to include FFT-CP, Digital BF |
FH Ethernet Link |
25Gbps x 1 lane |
Transport encapsulation |
Ethernet |
Transport header |
eCPRI |
C Plane |
Conformant to O-RAN-WG4.CUS.0-v02.00 7.2x split |
U Plane |
Conformant to O-RAN-WG4.CUS.0-v02.00 7.2x split |
S Plane |
Conformant to O-RAN-WG4.CUS.0-v02.00 7.2x split |
M Plane |
Conformant to O-RAN-WG4.CUS.0-v02.00 7.2x split |
RU Beamforming Type |
Code book based |
Data Collection on Aerial Testbed with Data Lake#
Aerial CUDA-Accelerated RAN supports data capture for offline processing using logging, which is useful for debugging and performance analysis. It also captures richer control and data plane data in real time in Data Lake for offline and real-time usage to enhance debugging and performance analysis, to train AI/ML models, and to be used by dApps, written by 3rd parties to achieve new RAN functionality.
Data Lake is a real-time component of ACAR running on the O-DU that captures L1 and L2 data from O-RUs and the O-DU.
It consists of three parts (refer to figure below):
The Data Collection App (DCA) running on the CPU
The Data Lake Database (DLDB)
DLDB APIs used for retrieving data from the DLDB

Data Lake components for offline and real-time data access#
Key Features#
Data Lake has the following features:
Real-time capture of Fronthaul I/Q samples
The data passed to L2 via RX_Data.Indication and UL_TTI.Request are exported to the database.
API access to the database
Scalable and time coherent over arbitrary number of BSs
The data collection app runs on the same CPU that supports the DU. It runs on a single core, and the database runs on free cores. Because each gNB is responsible for collecting its own uplink data, the collection process scales as more gNBs are added to the network testbed. Database entries are time-stamped so data collected over multiple gNBs can be used in a training flow in a time-coherent manner.
Use in conjunction with `pyAerial`_ to generate training data for neural network physical layer designs
Data Lake can be used in conjunction with pyAerial. Using the Data Lake database APIs, pyAerial can access RF samples in a Data Lake database and transform those samples into training data for all the signal processing functions in an uplink or downlink pipeline.
Use by dApps
dApps can use real-time data from the database to analyze system performance and/or to trigger real-time actions on the gNB based on the analysis.
Example: Training Data Generation Using pyAerial#
Uplink I/Q data from one or more O-RAN Radio Units (O-RUs) is delivered to GPU memory where it is both processed by the L1 PUSCH baseband pipeline and delivered to host CPU memory. The Data Lake collector process writes the I/Q samples to the Data Lake database in the fh table.

Data Lake data capture and usage by pyAerial for model training#
The fh table has columns for SFN, Slot, IQ samples as fhData, and the start time of that SFN.slot as TsTaiNs.
The collector app saves data that the L2 sent to L1 to describe UL OTA transmissions in UL_TTI.Request messages as well as data returned to the L2 via RX_Data.Indication and CRC.Indication. This data is then written to the fapi database table. These messages and the fields within them are described in SCF 5G FAPI PHY Spec version 10.02, sections 3.4.3, 3.4.7, and 3.4.8.
Each gNB in a network testbed collects data from all O-RUs associated with it. That is, data collection over the span of a network is performed in a distributed manner, each gNB is building its own local database. Training can be performed locally at each gNB, and site-specific optimizations can be realized with this approach. Since the data in a database is time-stamped, the local databases can be consolidated at a centralized compute resource and training performed using the time aligned aggregated data.
In cases where the PUSCH pipeline was unable to decode due to channel conditions, retransmissions can be used as ground truth as long as one of the retransmissions succeeds, allowing the user to test algorithms with better performance than the originals.
The Data Lake database storage requirements depend on the number of O-RUs, the antenna configuration of the O-RU, the carrier bandwidth, the TDD pattern and the number of samples to be collected. Collecting IQ samples of 1 million transmissions from a single RU 4T4R O-RU employing a single 100MHz carrier will consume approximately 660 GB of storage.
The Data Lake database comprises the fronthaul RF data. However, for many training applications access to data at other nodes in the receive pipeline is required. A pyAerial pipeline, together with the Data Lake database APIs, can access samples from an Data Lake database and transform that data into training data for any function in the pipeline.
The figure below illustrates data ingress from a Data Lake database into a pyAerial pipeline and using standard Python file I/O to generate training data for a soft de-mapper.

pyAerial and Data Lake data flow for building training datasets for a neural network soft de-mapper#
Information about installing and using Data Lake and pyAerial can be found in the Aerial CUDA-Accelerated RAN documentation.
Extending RAN functionality with dApps#
dApps are real-time, 3rd party applications that can analyze L1/L2 data from the RAN and use it to control RAN functionality. ACAR captures data using Data Lake and implements a dApp Framework through which dApps can register/deregister themselves, subscribe to and access Data Lake data, and send commands to control ACAR behavior (refer to figure below). dApps communicate with the dApp Framework using a pre-standard version of the E3 interface and E3 Application Protocol (E3AP).

dApp: High level operation#
dApps run on the O-DU and extend its functionality. On GPUs that support MIG (Multi-Instance GPU), dApps and ACAR run in different MIG instances, providing process and memory isolation while maintaining low latency data exchange via CPU shared memory. Running on the same GPU-based HW as ACAR enables dApps to run low latency AI/ML inference to analyze data from Data Lake and to determine actions to be sent to control the RAN.

dApp hardware and software architecture#
Software components#
dApp functionality is split among 4 main components in the O-DU, as shown in figure below.
DU-Low, which runs L1 pipelines, Data Lake and an E3 Agent
DU-High, which runs L2 and higher layer components. OpenAirInterface is used as an example L2+ stack
CPU Shared Memory (CPU SHM)
One or more co-located dApps

dApp components#
DU-Low#
DU-Low functionality is provided by Aerail CUDA-Accelerated RAN (ACAR). The figure above shows three main components:
CUDA Pipeline: The figure shows a single PUSCH L1 pipeline for simplicity, which receives FH (Fronthaul) data from an RU and processes it into CRC-checked data blocks
Data Lake: Captures FH I/Q samples and other L1/L2 data from intermediate processing blocks and metadata. The data is captured in real time to memory. Data writes alternate between 2 buffers (ping and pong). When one buffer is full, writes begin to the other buffer and data from the full buffer is read out to a ClickHouse database configured in RAM tables or in SSD storage.
E3 Agent: Interfaces ACAR functionality with one or more dApps. It runs alongside the real-time data path in DU-Low, receives notifications when new uplink data is available, and exposes that data to subscribed dApps through the E3 interface. For small data items, it can send values directly in E3 indication messages; for larger data objects such as I/Q samples or channel estimates, it sends metadata and shared-memory references so the dApp can read the data efficiently. It also handles E3AP procedures such as setup, subscription, indication, and control, enabling dApps to discover data, receive real-time updates, and optionally send control commands back to the RAN.
DU-High#
DU-High can interact with dApps through the E3 interface for data consumption and control actions similar to how they interact with DU-Low as long as it supports E3.
dApp sub-components#
A dApp itself consists of 3 main sub-components (refer to the figure below):
E3 Manager: The core engine that handles E3AP protocol, multi-agent communication, shared memory, and application dispatch.
dApp Client: An external control interface for managing the dApp lifecycle: listing agents, subscribing to telemetry, unsubscribing, and querying status.
dApp Logic: The application-specific processing logic (e.g., PRB power calculation) including inference engine. Each app has its own config, Dockerfile, models, and build system. Different inference engines are supported, such as Triton Inference Server, Python and TensorRT, and multiple models can be used, hosted in a model repository.

dApp reference implementation#
E3 Agent-Manager relationships#
The figure below shows how multiple Agents can connect to multiple Managers.

Multiple Agent-Manager connections#
It shows how a single E3 Agent can connect to multiple dApps (i.e., E3 Managers), each of which may subscribe to different data from the Agent and control different aspects of its behavior, likely based on different dApp logic.
Similarly, a single dApp (i.e., E3 Manager) may connect to different E3 Agents, accessing different data and controlling different behaviors, potentially based on different dApp logic.
Available Data Streams#
The E3 Agent exposes the following uplink data streams through the NVIDIA KPM Service Model. dApps can subscribe to any combination of these to receive real-time RAN data for inference, analytics, or custom processing.
Category |
Data |
Description |
|---|---|---|
IQ & Channel |
IQ samples, DMRS |
Raw fronthaul IQ, DMRS channel estimates, PUSCH estimates, decoded PUSCH data (shared memory) |
Frame info |
SFN, Slot, Timestamp |
System Frame Number, slot index, agent-side nanosecond timestamp |
Cell & Antenna |
Cell ID, RX antennas, BS antennas, Cells |
Physical cell ID, antenna counts, Cells |
Channel quality |
RSRP, RSSI, CQI, MCS index, QAM order |
PHY-layer measurements and modulation parameters |
PUSCH |
TB CRC fail, CB errors, CB count |
Transport/code block error indicators |
Resource allocation |
RB start, RB size, Symbols, Subcarriers, MIMO layers |
Frequency/time resource assignment |
This list reflects the currently supported telemetry streams. Additional data streams and service models may be added in future releases. Refer to the NVIDIA Sample Apps repository for the full per-field telemetry ID table and shared memory layout details.
Future releases of E3 Agents may also expose other Service Models with different RAN Function IDs, providing additional telemetry IDs and/or control IDs.
References#
NVIDIA Sample Apps repository, containing sample dApps to show how to build, install, configure, test and run low-latency, inference-capable dApps to collect and consume data in real-time from ACAR. NVIDIA/aerial-sample-apps
[1] D. Villa, M. Belgiovine, N. Hedberg, M. Polese, C. Dick, and T. Melodia, “Programmable and GPU-Accelerated Edge Inference for Real-Time ISAC on NVIDIA Aerial Testbed,” arXiv:2512.06493 [cs.NI], 2026. [pdf](https://arxiv.org/pdf/2512.06493)
[2] S. D’Oro, M. Polese, L. Bonati, H. Cheng, and T. Melodia, “dApps: Distributed Applications for Real-time Inference and Control in O-RAN,” IEEE Communications Magazine, 2022. [pdf](https://arxiv.org/pdf/2203.02370.pdf)
[3] Northeastern University, NVIDIA, and Mavenir, “dApps Architecture and Interfaces,” O-RAN next Generation Research Group (nGRG), Research Report, 2025, report ID: RR-2025-05, v2.0. [pdf](https://mediastorage.o-ran.org/ngrg-rr/nGRG-RR-2025-05-dApps%20Architecture%20and%20Interfaces-v2.0.pdf)
[4] Northeastern University, NVIDIA, Mavenir, MITRE, and Qualcomm, “dApps for Real-Time RAN Control: Use Cases and Requirement,” O-RAN next Generation Research Group (nGRG), Research Report, Oct 2024, report ID: RR-2024-10. [pdf](https://mediastorage.o-ran.org/ngrg-rr/nGRG-RR-2024-10-dApp%20use%20cases%20and%20requirements.pdf)
[5] A. Lacava, L. Bonati, N. Mohamadi, R. Gangula, F. Kaltenberger, P. Johari, S. D’Oro, F. Cuomo, M. Polese, and T. Melodia, “dApps: Enabling Real-Time AI-Based Open RAN Control,” Computer Networks, vol.269, pp. 111342, 2025. [pdf](https://www.sciencedirect.com/science/article/pii/S1389128625003093)
Product Blueprints#
To ease developer onboarding, this section provides reference blueprints with key ingredients for creating a full-stack tested product prototype.
ATB with AI-RAN integration offers several advantages:
Real-world validation: Many assumptions made for analytical and simulation studies can be rigorously tested in a real OTA network environment, now including AI-enhanced RAN functionality.
Comprehensive experience sharing: Our extensive experience in innovation labs, including design, setup, deployment, and integration of tools and frameworks, is made available to all developers, incorporating insights from AI-RAN implementations
Qualified components: Hardware components and software configurations have undergone rigorous qualification processes, addressing potential difficulties and pitfalls, now including AI-RAN accelerated computing platform
Controlled experimentation: Developer variations in lab experimental networks are limited to environment variability, transmission power, attenuation, and a select set of variables
Full-stack programmability: ATB provides complete access to source code, allowing developers to onboard any experiments with quick-turnaround validation and benchmarking results, now extended to AI-RAN applications
Cutting-edge technology: Built on principles of disaggregation, virtualization, software-defined systems, adaptability, and O-RAN specifications, ATB serves as a true advanced wireless developer launchpad
AI-RAN integration: The platform now supports concurrent AI and RAN processing, enabling developers to explore multi-tenancy and orchestration capabilities, maximizing capacity utilization
Energy efficiency: AI-RAN integration allows for optimized energy consumption without compromising performance, enabling developers to test and validate energy-efficient network designs
Enhanced performance: Developers can leverage AI-enhanced functionalities such as improved throughput, handover speed, and network anomaly detection
As we look to leverage, extend, and innovate, the key guiding attributes for these blueprints focus on creating a reliable, stable, performant, and scalable experimental radio network that empowers developers to push the boundaries of wireless technology.
Full-Stack Innovation#
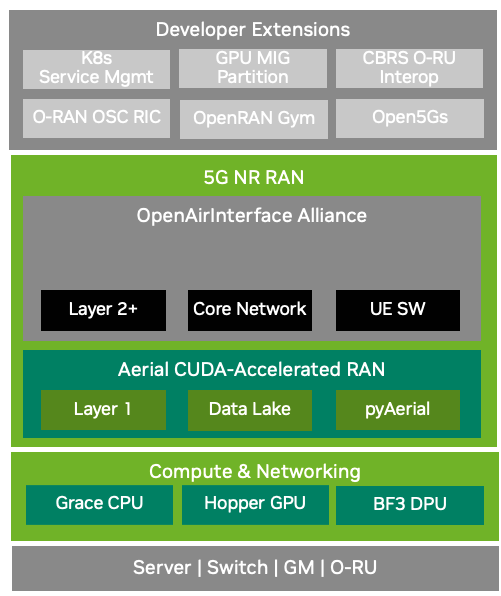
Components |
Feature |
|---|---|
COTS hardware |
COTS infrastructure composed of accelerated compute, virtualization, radios, fronthaul networking, and precision timing. |
Virtualization |
vRAN workloads from NVIDIA and OAI |
AI/ML Frameworks |
Data Lake + pyAerial for AI/ML frameworks: RF / IQ data + FAPI |
Standards |
3GPP Release 15 + O-RAN 7.2 split P5G on-prem lab network |
Developer Extensions |
For more information on developer contributions, refer to the Developer Zone section |
Note
We welcome developer contributions through extensions and plugins–for community benefits and to accelerate pace of innovations!
Aerial Testbed and O-RAN#
The O-RAN framework is designed to foster openness, programmability, automation, intelligence, and the decoupling of hardware and software through standardized, interoperable interfaces. It champions a multi-vendor and multi-stakeholder ecosystem within a cloud-native and virtualized wireless infrastructure, enhancing the efficiency of RAN deployment, operation, and maintenance.
The O-RAN split-RAN concept disaggregates the RAN into multiple functional components: O-RAN Central Unit (O-CU), O-RAN Distributed Unit (O-DU) and O-RAN Radio Unit (O-RU), as shown in the figure below. These components can be deployed on different hardware and software platforms and can be interconnected using open interfaces.
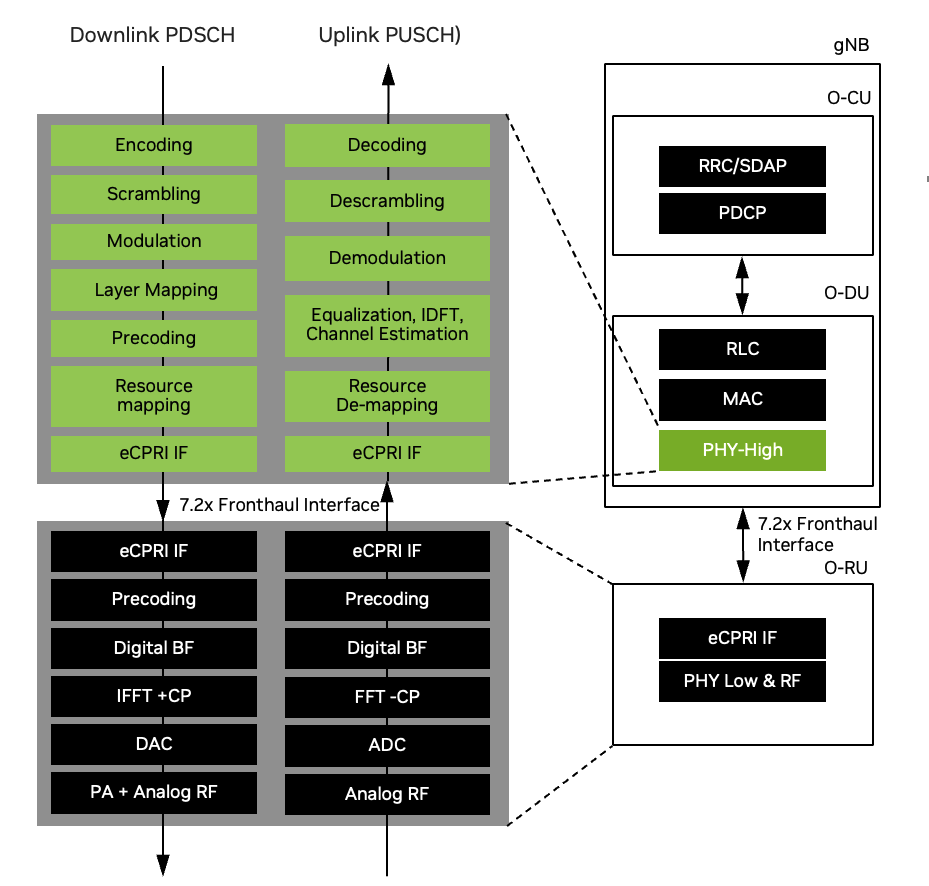
ATB conforms to an O-RAN blueprint as shown in the figure and table below. The figure highlights the multi-vendor aspect of O-RAN, with O-RUs supplied from NVIDIA O-RU ecosystem partners, Layer-1 from NVIDIA Aerial-CUDA Accelerated RAN, and O-DU (high), O-CU, and 5G Core from OAI.
The developer extension from Northeastern University (NEU) has the following highlights:
OpenRAN Gym, an open toolbox for data collection and experimentation with AI in O-RAN architectures
Integration of the OSC (O-RAN Software Community) near real-time RIC (RAN Intelligent Controller)
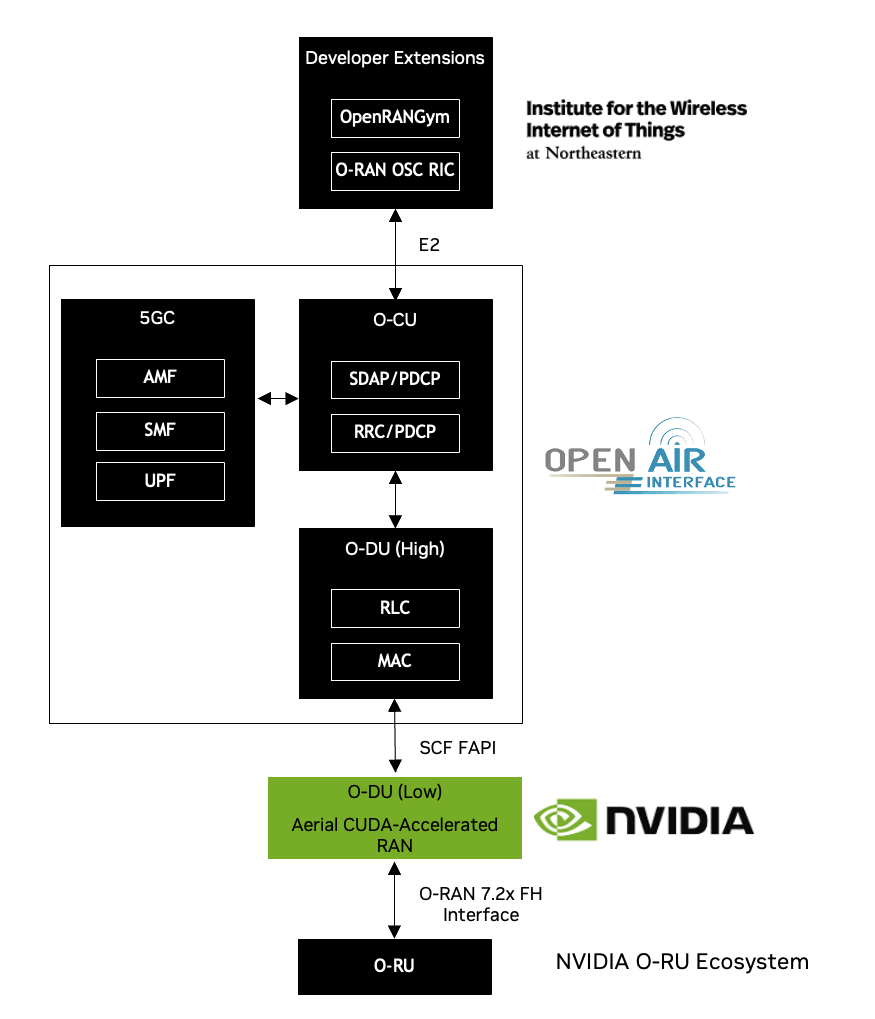
Organization |
Components |
|---|---|
Northeastern |
E2 interface plugin leveraging O-RAN OSC RIC and template xApps |
OAI |
O-DU-High (Layer 2), O-CU and 5GC |
NVIDIA |
O-DU Low / High PHY |
Others |
Handsets (Apple iPhone 14, Samsung S23), Viavi Qualsar Grandmaster, Dell FH switch, Supermicro GH200 server. |