Enterprise AI Factory Overview#
The design for an Enterprise AI Factory integrates seamlessly with enterprise systems, data sources, and security infrastructure through NVIDIA’s partner solutions. It utilizes advanced NVIDIA hardware in conjunction with software tools and solutions from NVIDIA AI Enterprise to ensure optimal performance adhering to best practices. An ecosystem of partners is included, with specified versions and integrations, providing a comprehensive, high-performance solution for modern AI projects with a focus on Agentic AI workloads. It provides a standardized on-premises platform so that Enterprise IT stakeholders can work with their chosen vendors. The following is a high-level description of the design components.
Enterprise AI Factory Considerations#
An Enterprise AI Factory is engineered to industrialize AI deployment. Its requirements diverge sharply from a traditional enterprise data center built around generic CPU workloads and line-of-business apps. The most compelling considerations fall into the following areas to provide sufficient, reliable accelerator capacity, high‑speed networking, scalable storage, and power/cooling to sustain continuous AI workloads.
Dense GPU or accelerator nodes sized for large model training and large-scale inference.
High GPU memory capacity and fast local storage to keep large model weights and context in memory or swap model in model from storage as needed.
Low‑latency, high‑bandwidth fabrics (e.g., 100–400 GbE, RDMA-capable, or dedicated GPU interconnects) for distributed training and multi-node inference.
High-speed networking to sustain large volume east–west traffic for parameter synchronization, collective ops, and model sharding.
Parallel, scale‑out storage with high throughput and IOPS to stream massive datasets, checkpoints, and embeddings to accelerators at line rate.
Tiered storage to balance cost and performance (e.g., NVMe for hot training data and models, object storage for cold archives and historical datasets).
Racks designed for very high power density—multi‑kilowatt per node and tens of kilowatts per rack—far beyond typical power density of CPU racks.
Advanced cooling (liquid or high-efficiency air) to reliably dissipate heat from tightly packed accelerators and maintain performance under sustained training loads.
Infrastructure designed for scalability rather than static allocations. Agentic workloads are inherently bursty. Capacity planning and dynamic resource allocation around tokens per second / queries per second, with headroom for rapid model and traffic growth.
Together, these considerations explain why an Enterprise AI Factory is more than a traditional data center. It is a hardware and software co‑designed system, purpose‑built to run AI as a core production capability.
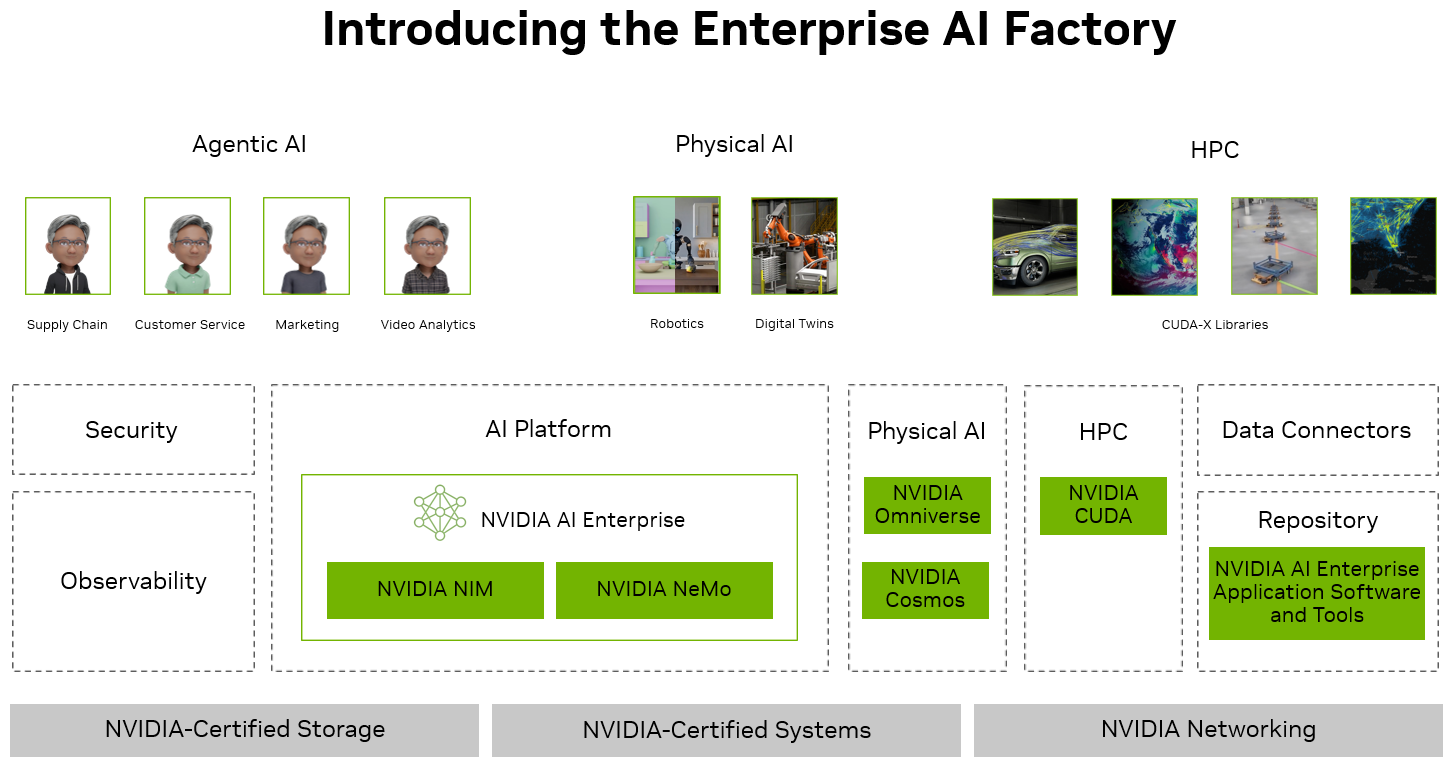
NVIDIA AI Enterprise#
NVIDIA AI Enterprise is a suite of software libraries, microservices, and frameworks,for building Enterprise AI workflows. Easy-to-use and performance optimized microservices with enterprise-grade security, stability and support ensure a smooth transition from prototype to production for enterprise AI development.
With broad adoption across industries and an extensive partner ecosystem, NVIDIA AI Enterprise enables organizations to build and deploy agentic AI systems anywhere—across clouds, data centers, or at the edge. By streamlining development and optimizing hardware utilization, NVIDIA AI Enterprise helps businesses accelerate time to market and reduce infrastructure cost while ensuring reliable, secure, and scalable AI operations.
Open Models
NVIDIA Nemotron™ is a family of open models, datasets, and technologies that empower you to build efficient, accurate, and specialized agentic AI systems. Designed for advanced reasoning, coding, visual understanding, agentic tasks, safety, speech, and information retrieval, Nemotron models are openly available and integrated across the AI ecosystem so they can be deployed anywhere—from edge to cloud. With transparent training data and broad platform support, Nemotron makes it easier to create and deploy trustworthy, high-performance AI agents.
The Nemotron 3™ family includes 3 sizes of LLMs for optimal accuracy, performance, and compute budget.
Nemotron 3 Nano, a lightweight, 30-billion-parameter model for targeted, highly efficient tasks
Nemotron 3 Super, a high-accuracy, approximately 100-billion-parameter reasoning model for multi-agent applications
Nemotron 3 Ultra, a large reasoning engine with about 500 billion parameters for complex AI applications.
NVIDIA Cosmos™ is a world foundation model (WFM) development platform to advance physical AI. At its core are Cosmos WFMs, openly available pretrained multimodal models that developers can use out-of-the-box for generating world states as videos and physical AI reasoning, or post-train to develop specialized physical AI models. NVIDIA Cosmos also includes advanced tokenizers, guardrails, accelerated data-processing pipeline, and post-training scripts.
NVIDIA NeMo
NVIDIA NeMo™ is a modular software suite for managing the AI agent lifecycle. It provides microservices and toolkits for data processing, model fine-tuning and evaluation, reinforcement learning, policy enforcement, and system observability. NeMo helps enterprises build, monitor, and optimize agentic AI systems at scale, on any GPU-accelerated infrastructure. An example of NeMo is NeMo Data Designer which is purpose-built for AI developers to design high-quality, domain-specific synthetic data at scale. You can start from scratch or from your own seed datasets to accelerate AI development with greater accuracy and performance.
NVIDIA Omniverse
NVIDIA Omniverse™ is a collection of libraries and microservices for developing physical AI such as industrial digital twins and robotics simulation. Leveraging NVIDIA’s deep expertise in accelerated computing and AI, Omniverse libraries enable software makers to integrate pre-built functionality into their solution, including open data interoperability (OpenUSD), real-time world-scale rendering (RTX), and advanced simulation (physics and runtime behavior).
NVIDIA Run:ai
NVIDIA Run:ai™ enables organizations to run AI workloads at scale by maximizing GPU efficiency, orchestrating shared infrastructure, and ensuring every compute resource delivers the highest possible value.
NVIDIA NIM
NVIDIA NIM™ is a set of easy-to-use microservices designed for secure, reliable deployment of high-performance AI model inferencing across clouds, data centers, and workstations. Supporting a wide range of AI models, including open-source community and NVIDIA AI foundation models, it ensures seamless, scalable AI inferencing on premises and in the cloud with industry-standard APIs. The recently released Nemotron 3 Super NIM is a cloud-native container featuring the latest Nemotron family of open models powered by NVIDIA Dynamo-Triton. It includes multiple backends automatically selecting the optimal performance profile for your underlying hardware.
NVIDIA CUDA-X AI
NVIDIA CUDA-X, built on top of CUDA®, is a collection of microservices, libraries, tools, and technologies for building applications that deliver dramatically higher performance than alternatives across data processing, AI, and high-performance computing (HPC). An example of CUDA-X is cuOPT, a GPU-accelerated optimization library that solves Mixed Integer Linear Programming (MILP), Linear Programming (LP), Quadratic Programming (QP), and Vehicle Routing Problems (VRP). It enables solutions for large-scale problems with millions of variables and constraints, offering seamless deployment across hybrid and multi-cloud environments.
Operators & Infrastructure Management Software
Kubernetes operators for managing GPU and networking in containers and the life cycle of microservices and AI pipelines
Cluster management software to provision and monitor servers at scale
Drivers to optimize utilization of NVIDIA GPUs and networking in bare-metal and containerized environments
Customers who build and maintain an AI infrastructure can use whatever parts of this collection they need. NVIDIA has partnered with leading companies to ensure integration with their orchestration platforms, hypervisors, operating systems, hardware systems, and cloud services.
Enterprise-Grade Features As AI rapidly evolves and expands, the complexity of the software stack and its dependencies grow. NVIDIA AI Enterprise addresses the challenges organizations face when building and maintaining a high-performance, secure, cloud-native AI software platform.
Security and Software Life Cycle Management: For NVIDIA AI Enterprise customers, NVIDIA commits to patch critical and high common vulnerabilities and exposures (CVEs) monthly for production branches and on quarterly for long-term support branches, while maintaining API compatibility up and down the stack.
Enterprise Support: Enterprise-grade support is provided for production deployments globally, with service-level agreement (SLA) response times, timely resolution by NVIDIA experts and engineers, and up to three years of long-term support.
End-to-End Manageability: Management software is included for workload and infrastructure utilization to scale development and deployment of AI across edge, data center, and cloud.
Portability to Deploy Everywhere: NVIDIA AI Enterprise software allows portability for enterprises who need a consistent environment wherever they choose to deploy AI. Available everywhere—including public clouds, NVIDIA-Certified™ Systems, networking and storage— NVIDIA AI Enterprise is optimized and certified to ensure reliable performance and reduce the risk associated with moving from pilot to production caused by infrastructure and architectural differences between environments.
Government-Ready: For the added needs of regulated industries we have the NVIDIA AI Factory for Government reference design
NVIDIA AI Data Platform#
Data fuels your AI factory, but most enterprise data is unstructured, fragmented, and rapidly changing. Traditional data platforms struggle to keep this data continuously AI‑ready, creating bottlenecks that limit how much of the organization’s knowledge the AI factory can actually use, and, therefore, how much intelligence it can manufacture. By embedding GPU acceleration directly into the data path, NVIDIA AI Data Platform handles the complexity and rapid changes of your data as a background operation. The AI data platform continuously ingests, indexes, and processes multimodal data from various sources, transforming it into a format that AI applications can readily consume. This ensures your enterprise data is always AI-ready, enabling your AI factory to generate actionable insights and drive intelligent decision-making in real-time.
To make enterprise data AI‑ready, heterogeneous unstructured assets—such as documents, images, audio, and video—must be transformed into machine‑understandable representations that are indexed, searchable, and retrievable by AI workloads. In‑place data processing brings compute power to the data itself, enabling accelerated data preparation workflows—including extraction, transformation, embedding generation, and vector indexing—using GPUs embedded within the data path. This architecture minimizes unnecessary data replication and long‑haul transfer, reducing data drift, I/O contention, and operational complexity across distributed pipelines. Continuous ingestion and transformation maintain real‑time data freshness, ensuring AI models operate on current and contextually relevant information without manual refresh cycles. Throughout the process, enterprise‑grade security and governance frameworks are preserved: existing access controls, compliance policies, and zero‑trust mechanisms remain enforced, while hardware‑accelerated encryption secures data in transit and at rest. Finally, GPU infrastructure can be elastically scaled to match evolving data characteristics—volume, variety, and velocity—optimizing utilization and maintaining predictable performance across enterprise environments.
The NVIDIA AI Data Platform reference design brings together NVIDIA RTX PRO Blackwell GPUs, NVIDIA BlueField-3 DPUs and integrated AI data processing pipelines based on NVIDIA Blueprints. This customizable reference design integrates NVIDIA-accelerated computing into enterprise storage to centralize intelligent data handling and deliver AI-ready data, while reducing latency, enhancing data security, and maximizing performance. In collaboration with NVIDIA, storage industry leaders are building out-of-the-box solutions, with designs that feature either the RTX PRO 6000 Blackwell Server Edition or RTX PRO 4500 Blackwell Server Edition GPU, that allow enterprises to unlock value from all their enterprise data while keeping data secure.
NVIDIA Blueprints#
NVIDIA Blueprints are comprehensive reference workflows designed to streamline AI application development across industries and accelerate deployment to production. Built with NVIDIA AI and Omniverse libraries, SDKs, and microservices, they provide a foundation for custom AI solutions. Each blueprint includes reference code for constructing workflows, tools, and documentation for deployment and customization, as well as a reference architecture outlining API definitions and microservice interoperability. By enabling rapid prototyping and accelerating time to deployment, these blueprints empower enterprises to operationalize AI-driven solutions like AI agents, digital twins, synthetic data generation, and more.
Benefits of NVIDIA Blueprints:
Comprehensive Reference Workflows: Everything you need to build AI solutions—reference code, best practices, and end-to-end workflows for AI agents, digital twins, and drug discovery—all in one place.
Powered by Leading NVIDIA Software: Tap into powerful, GPU-accelerated microservices, libraries and SDKs for faster prototyping, higher performance, and smoother deployment of advanced AI applications.
Flexible Deployment: Deploy on-premises, in the cloud, or in a hybrid setup—choose what works best for your business now and stay ready to pivot in the future.
Rapid Prototyping to Production: Move quickly from idea to live application using pre-tested code snippets and microservices that simplify integration, testing, and deployment.
Enterprise-Grade Support: Rely on professional services, documentation, and regular updates from NVIDIA to keep your AI solutions secure, reliable, and always up to speed.
Here are a few examples of NVIDIA blueprints:
NVIDIA AI-Q for Enterprise Research - an open reference architecture for building AI agents that connect to your enterprise data, reason with state-of-the-art models, and deliver trusted business insights. It combines Nemotron and frontier models for reasoning, Nemotron RAG for high-accuracy multimodal retrieval, and the NeMo Agent Toolkit for profiling, evaluation, and optimization, along with intent routing, a virtual file system for persistent context, and a built-in evaluation harness. Together, these components give enterprises a customizable, portable “recipe” for deep agents that can perceive, reason, and act on organizational knowledge—improving accuracy, transparency, and cost efficiency while ensuring they fully own, inspect, and control their AI systems.
Build an Enterprise RAG Pipeline - The NVIDIA AI Blueprint for Retrieval-Augmented Generation (RAG) is a production-ready, modular reference architecture for building high-accuracy, high-performance RAG systems that power enterprise search, knowledge assistants, copilots, and agentic workflows at scale. Optimized for GPU acceleration and enterprise throughput, the blueprint provides a complete foundation for ingestion, retrieval, reasoning, and generation across multimodal enterprise data.
Build a Video Search and Summarization (VSS) Agent - a reference blueprint for building and customizing video analytics AI agents. These insightful, accurate, and interactive agents are powered by generative AI, vision language models (VLMs), large language models (LLMs), and NVIDIA NIM™ Microservices—helping a variety of industries make better decisions, faster. They can be given tasks through natural language and perform complex operations like video summarization and visual question-answering, unlocking entirely new application possibilities.
Build Continuous Refining AI Agents with Data Flywheels - a self-reinforcing, automated loop that continuously improves models using real-world feedback. It collects production traffic logs, evaluates performance, fine-tunes models, and redeploys optimized versions—maintaining accuracy while reducing resource.
Multi-Agent Intelligent Warehouse - an AI-powered, multi-agent system designed to optimize warehouse operations through intelligent automation, real-time monitoring, and natural language interaction. The system provides comprehensive support for equipment management, operations coordination, safety compliance, and document processing.