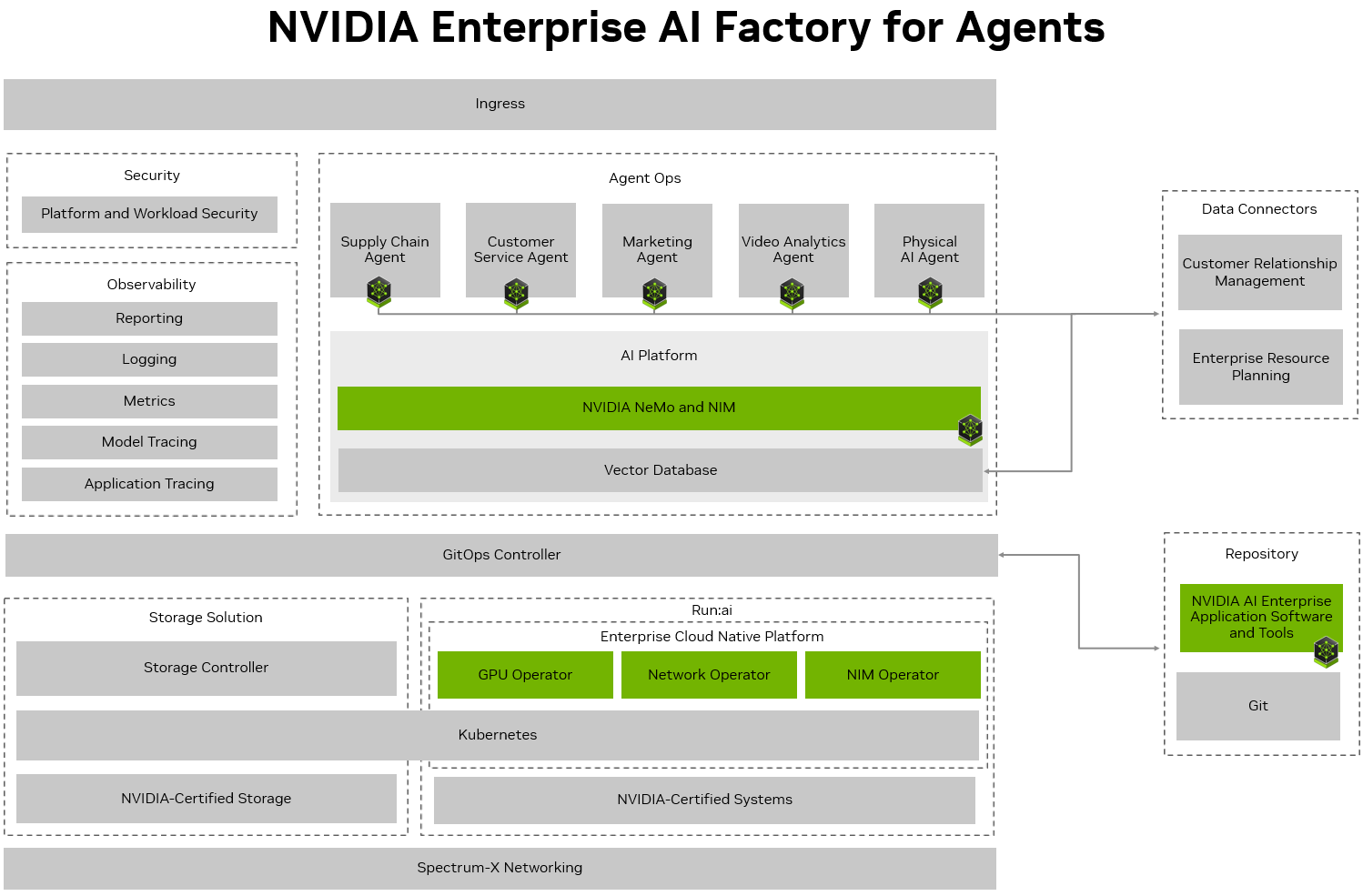
Agentic AI in the Factory#
The following sections describe the implementation of Agentic AI within an Enterprise AI Factory. Information is provided for each of the Enterprise AI Factory components (AI Platform, Data Connectors, Artifact Repository, Observability, Security, & Hardware) in relation to Agentic AI.
Agentic AI Workflows#
Agentic AI represents a shift from static pipelines to autonomous, stateful workflows. These systems are no longer limited to single-turn chat; they are long-running, multi-step agent graphs that coordinate tools, memory, and policies. This evolution transforms the AI Factory into a runtime for intelligent agents you own, allowing for full inspection and control of the reasoning process
From Deep Research to Business Insight#
Modern agents have evolved from stateless chat interfaces into comprehensive business partners. The AI-Q NVIDIA Blueprint defines this new standard through three technical characteristics:
Dynamic Routing: Agents automatically select the optimal model, workflow depth, and data sources for each request. This ensures that a “shallow” search doesn’t waste frontier model tokens, while “deep research” tasks receive the necessary multi-hop reasoning.
Persistent Context Management: Rather than being constrained by ephemeral memory, agents use virtual workspaces to store and recall datasets, code, and intermediate artifacts. This allows them to maintain long-term context across multiple interactions and planning cycles.
Integrated Evaluation: To deliver insights you can trust, the platform includes a built-in evaluation harness. This allows for transparent reasoning and benchmarking of agent stacks against real-world tasks, ensuring that every decision is auditable and grounded in enterprise data.
Long-Running Agents: Long-running Agents are engineered around three core primitives that make them suitable for production‑scale AI workflows:
File systems - Each Long-running Agent is provisioned with a structured, mountable workspace (for example /workspace/ backed by S3, SQLite, or local storage). Agents read and write intermediate artifacts—datasets, prompts, evaluation logs—through a unified filesystem interface. This decouples the agent graph from ephemeral memory limits and enables replayable, auditable workflows where inputs and outputs are versioned and addressable.
Skills - Skills are defined as modular, versioned units of behavior, specifically defined as directories containing an interface spec (e.g., SKILL.md), executable code (Python, Node.js, shell), and required dependencies. These are exposed as structured tools with input/output schemas, callable from agent planning loops. For instance, a “data‑analysis skill” can load a dataset, run statistical models, and emit structured JSON results, all invoked automatically as part of a larger workflow.
Sandboxes - Execution occurs inside sandboxed environments that enforce security and isolation: restricted network access, CPU/memory limits, and time‑bounded sessions (for example 30 seconds per step). Sandboxes can be implemented via Docker containers, VMs, or cloud‑native runtimes, depending on the AI Factory’s infrastructure. This design allows agents to run arbitrary code while preserving cluster integrity and multi‑tenant separation, which is essential for production AI workflows.
Together, these components enable long-running Agents to treat an AI workflow as a composable pipeline: files store state, skills define reusable actions, and sandboxes enforce safety and predictability.
NVIDIA AI-Q for Enterprise Research on the Enterprise AI Factory#
The NVIDIA AI-Q for Enterprise Research is an intelligence agent built on the NVIDIA NeMo Agent Toolkit in collaboration with LangChain as an implementation of a long-running agent. It is architected as a long‑running, multi‑step agent that orchestrates retrieval, reasoning, and tool use across enterprise data sources and APIs, all managed through a graph‑based control plane.
The Enterprise AI Factory validated design provides the runtime environment where AI‑Q‑style agent workflows can be extended, hardened, and evolved over time. Developers can:
Extend the agent blueprint by adding custom skills, data connectors, and evaluation hooks, while preserving the underlying graph structure and observability layer.
Mount enterprise file systems (e.g., data lakes, document stores, or feature repositories) to agent workspaces, enabling workflows that persist across multiple runs and services.
Configure sandbox policies (time limits, resource caps, network rules) to enforce security and cost controls for each agent or workflow class.
The Enterprise AI Factory treats long-running agents as first‑class services: they can be versioned, tested, monitored, and rolled back like traditional microservices, but with the added dimension of learned behavior and evolving skills. This allows the AI workflow architecture to evolve in lockstep with the business—new tools, data sources, and policies can be integrated without rebuilding the entire agent ecosystem.
In this model, Agentic AI becomes the new layer of orchestration above the core inference and data layers. The Enterprise AI Factory is no longer just a place to run models; it becomes the control plane for intelligent workflows that can plan, act, and improve over time.
AgentOps#
AgentOps represents a new operational discipline for managing agentic AI systems at scale. It extends the principles of traditional MLOps—which focus on deployment, observability, evaluation, and optimization—into a paradigm designed for the autonomous, stateful, and long-running processes of long-running agents. In this model, the Enterprise AI Factory is treated not just as a compute platform, but as a managed operating environment where agentic workflows are governed, monitored, and evolved as high-availability enterprise assets.
AgentOps provides a methodology for assembling agents from a library of reusable building blocks that accelerate software delivery in a manner that meets the requirements of an enterprise. By standardizing on foundational designs the AI Factory enables teams to rapidly prototype and deploy new agents while maintaining strict architectural consistency across the enterprise.
When effective, AgentOps is the ability to improve agents in real-time through a self-correcting intelligence loop. This is achieved via the evolution of policies, feedback loops from human or automated reviewers, and replay of agent traces. This ensures that agentic workflows continuously improve over time.
In practice, NVIDIA Blueprints serve as reference implementations of applications that are operated by AgentOps practices. They show how an agent‑centric workflow can be:
Versioned and reproducible, with clear separation between agent specs, configs, and runtime dependencies.
Secure by design, with sandboxed execution and tool‑server isolation baked into the architecture.
Observable by default, exposing telemetry and traces that plug into the AI Factory’s monitoring layer.
Extensible at runtime, allowing teams to add new skills, data sources, and policies without breaking existing workflows.
The Enterprise AI Factory becomes a unified control plane for operationalizing agentic AI: not just executing models, but orchestrating, governing, and evolving fleets of intelligent agents that empower human teams.
AI Platform#
An AI platform is an integrated suite of technologies providing the infrastructure and services needed to build, train, customize, and manage generative AI models, static data, and discrete inference pipelines to support autonomous agents at scale. Traditionally focused on data preparation, data processing, model training, and deployment, these platforms are now evolving from MLOps to support AgentOps. This shift addresses the unique operational requirements of long running, autonomous agentic workflows.
Enterprise software platforms are expanding their capabilities to orchestrate the end to end lifecycle of AI agents. This evolution includes providing dedicated interfaces for managing agentic skills, prompt tuning, and monitoring multi step decision chains. By natively integrating microservices from NVIDIA NeMo, these platforms allow organizations to customize large language models and deploy them as standardized microservices across cloud, on premises, or edge environments.
In an agentic context, the AI platform acts as the execution engine for complex reasoning loops. It must provide secure, robust, high performance APIs required for real time tool calling and context retrieval. The platform must be able to orchestrate horizontal and vertical scaling during spikes in processing demand, a common pattern from normal usage of an agentic system where a single prompt from a user can trigger complex executions.
Gateway#
As AI‑native workloads become foundational to modern infrastructure, the traditional Ingress Gateway is undergoing a significant transformation. The top most layer In the NVIDIA Enterprise AI Factory, the Gateway handles ingress traffic and serves not only as a traffic router, but also an inference gateway. Conventional HTTP‑centric routing models are no longer adequate for environments that must support LLM inference, agent‑to‑agent (A2A) communication, and Model Context Protocol (MCP) traffic. These emerging patterns introduce new requirements for secure, policy‑driven, and semantically aware traffic management. In response, the Ingress Gateway is evolving into a specialized Inference Gateway capable of orchestrating and governing interactions among agents, tools, and large language models.
Despite rapid progress in distributed inference and agentic architectures, the broader ecosystem still lacks standardized APIs for managing inference‑specific traffic flows. Current Ingress Gateways do not provide consistent mechanisms to extend routing logic, enforce identity at MCP and A2A layers, apply guardrails, or integrate inference‑aware telemetry and observability. This fragmentation creates operational complexity and limits the ability of platform teams to implement uniform governance across heterogeneous environments.
Given the absence of standardized interfaces, a common architectural pattern – reflected in NVIDIA’s reference designs – is to delegate inference‑specific traffic management to dedicated microservices. In this model, the Ingress Gateway performs initial request handling and forwards inference and agentic traffic to specialized control‑plane microservices responsible for managing these workloads.
As industry standards for inference and agentic traffic mature, these capabilities are expected to converge into the Ingress Gateway itself. NVIDIA’s roadmap anticipates transitioning the current microservice‑based logic into native gateway extensions once standardized APIs and interoperability frameworks become widely available. This evolution will streamline deployment architectures and enable more cohesive, gateway‑level governance for AI‑driven systems.
Data Connectors#
In the NVIDIA Enterprise AI factory, augmenting the running context means moving beyond static retrieval toward a dynamic exchange between agents and enterprise systems. To function as autonomous entities, agents require a platform that treats internal data, from CRM and ERP to point-of-sale systems, as a live, discoverable resource.
A key enabler for this is the Model Context Protocol (MCP), which provides a structured way for agents to discover and interact with external data and tools. Rather than using hard-coded connections, MCP allows agents to browse available resources and understand schemas to pull in the specific context needed for a task. This logic is managed by orchestration frameworks like LangGraph or CrewAI, which support long-running workflows where agents can self-correct or evolve their plans based on new information.
These agents rely on robust tool calling capabilities to bridge the gap between reasoning and action. By utilizing Anthropic-style skills and tool use definitions, agents can perform specific actions like executing code, querying databases, or updating records across the enterprise.
GitOps Controller#
A GitOps controller is a software component that continuously monitors the desired state of infrastructure and application configurations stored in a Git repository and ensures that the actual state of a system, such as a Kubernetes cluster, matches this declared state. Working in close collaboration with the artifact repository, it operates by regularly comparing the live state of resources in the environment with the version-controlled configurations in Git. If any differences are detected, the controller automatically reconciles them by applying the necessary changes to bring the system back in sync with what is defined in the repository. This approach leverages Git as the single source of truth, enabling automated, auditable, and reproducible deployments, and is typically implemented as a Kubernetes controller that runs a reconciliation loop to maintain consistency between Git and the cluster.
Artifact Repository#
The AI Factory incorporates a dedicated artifact repository designed to handle software components, especially for on-premises setups that follow GitOps principles. This repository serves as a secure, version-controlled local hub for essential NVIDIA AI Enterprise artifacts, such as containerized NVIDIA NIM microservices, AI models, libraries, and tools. In the GitOps workflow, git maintains the declarative state by linking to specific versions of these NVIDIA artifacts stored in the repository. Then, the GitOps Controller fetches these verified artifacts for deployment onto the Kubernetes platform. For on-premises environments, managing local artifacts enables essential operational practices such as scanning NVIDIA containers and other artifacts for security vulnerabilities, ensuring reliable and rapid access without relying on public registries, managing dependencies, and assuring reproducible deployments using specific, approved versions of NIMs and AI models.
Security#
Security in an agent based architecture extends beyond traditional network perimeter defense. It necessitates ensuring that each agent operates with the principle of least privilege possessing only the permissions strictly required for its designated function. AgentOps formalizes secure practices of the entire agent lifecycle including auditing and logging of all agent activities. This is achieved through rigorous isolation, the verification of signed skills, and controlled access to live production environments. As a result, even highly autonomous workflows maintain complete security and adherence to all corporate policies and regulatory mandates.
Network Security
The first line of defense is established at the network level through a multi-layered strategy that safeguards operations from the perimeter to individual data elements. This layer employs defense-in-depth strategies, primarily utilizing network policies native to the underlying container orchestration platform. These policies control traffic flow between services and pods, isolating workloads and restricting communication to only authorized pathways, thereby minimizing the attack surface. Modern AI Factory designs extend this by offloading and accelerating critical security tasks to DPUs(Data Processing Unit), which provide a hardware-isolated trust domain. To further bolster this, a service mesh enforces fine-grained traffic control policies at the application layer and automatically encrypts all traffic between services.
For detailed implementation of zero-trust and DPU offloading reference the NVIDIA Zero Trust Reference Architecture.
Identity Management
Building upon network controls, the identity layer focuses on verifying user and service identities and their entitlements. Authentication and authorization mechanisms are typically integrated directly with the platform’s own access systems. Crucially, these are seamlessly tied to broader enterprise Identity and Access Management (IAM) solutions, such as corporate directory services. This ensures consistent identity management and allows for centralized control over user access based on established enterprise credentials and policies.
Once identity is established, access to platform resources is governed by Role-Based Access Control (RBAC). This is implemented at multiple levels:
Orchestration Platform RBAC: The container orchestration platform itself employs RBAC to control permissions for managing and interacting with cluster resources (e.g., deploying applications, accessing logs, configuring services).
Integrated Platform RBAC: AI/ML platforms integrated within the ecosystem also commonly feature their own RBAC systems. These ensure that access to platform-specific functionalities and resources is restricted based on predefined user or service roles.
The most granular layer of security focuses on protecting the data itself within specialized data services, including various database systems. These services are often further protected by their internal RBAC mechanisms. These controls manage fine-grained access to data elements—such as specific data sets, tables, or collections—ensuring that read and write permissions are granted exclusively to authenticated and appropriately authorized applications and users, adhering to the principle of least privilege.
Clear roles and responsibilities are defined for effective management and operation of the complex on-premise, self-hosted AI/ML platform. This document outlines a consolidated mapping of key enterprise organizational roles to their typical access levels or administrative duties within logical groupings of platform tools. The goal is to provide a concise overview that facilitates understanding of how different teams interact with the various components of the technology stack, ensuring security, efficiency, and clear accountability in a self-managed environment.
IT Admin |
Network Administrator |
AI Developer |
MLOps |
|
|---|---|---|---|---|
Enterprise cloud native platform (e.g., Kubernetes/OpenShift, Base OS, Compute/GPU Management) |
Platform Admin & Provisioning: Manages OS, hardware, orchestration lifecycle, compute (GPUs). Ensures stability & resource availability. |
Network Infra Mgmt: Configures platform networking (SDN, ingress, egress), physical network. Collaborates with IT Admin on cluster networking. |
Platform User: Accesses platform for dev tools, logs, allocated compute (GPUs) for AI tasks. |
App Deployment & Ops: Admin/Operator in project namespaces for CI/CD agents, AI apps, services. Manages compute for inference. |
Storage Solution (Core & AI-specific storage, e.g., for datasets, models, VectorDBs) |
Core Storage Admin: Manages core storage infrastructure, backups, and base provisioning. Ensures availability for platform layers. |
Network for Storage: Ensures reliable network connectivity and segmentation for storage systems. Troubleshoots storage network issues. |
Data Consumer: Utilizes provisioned storage for datasets, model artifacts, and vector database access. |
Storage for AI Apps: Manages persistent storage claims for AI applications and models in production. Monitors storage performance for deployed agents. |
Artifact Repository (e.g., for container images, packages, models) |
Infra Support: Provides/maintains underlying infra (OS, VMs, K8s) for the repository. Core infra install/patch. |
Network Access: Ensures repository has necessary network access and is accessible by CI/CD tools and platform. |
Artifact User/Publisher: Manages and versions data/model artifacts, packages, and notebooks within the repository. Pulls base images. |
Artifact Lifecycle Mgmt: Manages CI/CD integration for publishing and consuming application/model artifacts and container images. |
GitOps Controller (e.g., ArgoCD) |
Infra Support: Maintains underlying infra (OS, VMs, K8s) for the GitOps controller. |
Network Access: Ensures GitOps controller can reach Git repositories and the Kubernetes API. |
User (Indirect): Benefits from GitOps for consistent environments defined by MLOps/Platform teams. |
GitOps Automation Lead: Defines/manages application and infrastructure configurations in Git. Manages GitOps controller for deployments. |
Observability (Monitoring, Logging, Tracing, Reporting) |
Infra Support: Provides/maintains underlying infra for the observability stack. Core infra install/patch. |
Network Support: Ensures monitoring tools reach targets & telemetry flows to central systems. |
Dev/Experiment Monitoring: Creates/views dashboards for experiments, data profiles, model dev metrics. Accesses logs for debugging. |
Prod AI Perf. Monitoring: Admin/Editor for dashboards/alerts on prod AI app performance, model drift, resource use, lifecycle quality. |
Security (Endpoint, Network, Identity, Data Security) |
Infra Security & IdP Support: Manages server security tools, IdP infra. Secures base platform. Collabs on infra firewall rules. |
Network Security Impl.: Manages firewalls, network security policies, IDS/IPS. Configures network aspects of IdP & security tools. Collabs on security posture. |
Authenticated User: Leverages federated identity for authorized access to tools, platforms, and data. Follows security best practices. |
Secure Deployment: Implements secure CI/CD practices. Manages secrets for deployed applications. Uses federated identity for tool/prod access. |
Data Connectors (e.g., to ERP, CRM, other enterprise systems) |
Infra & Network Support: Ensures underlying infrastructure and network paths are available for data connectors. |
Network Connectivity: Ensures secure and reliable network connectivity for data connectors to source/target systems. |
Data User: Utilizes configured data connectors to ingest data for AI model development and RAG. |
Operational Monitoring: Monitors the health and performance of data connectors used by production AI agents. |
AI Platform (e.g., AI/ML dev environments, Training/Fine-tuning services, Model Registries) |
Infra Support: Provides/maintains underlying infra (OS, K8s, GPU access) for the AI platform components. |
Network Connectivity: Ensures AI platform components have necessary network access for data, inter-service communication, and user access. |
Primary User: Creates projects, prepares data, builds, trains, tunes, and registers models. Uses platform tools for experimentation. |
Model Lifecycle Mgmt: Manages the CI/CD integration for models from the AI platform to production. Monitors resource usage of platform by MLOps tools. |
Agent Ops (Deployment, management, and operation of AI Agents) |
Resource Provisioning: Ensures sufficient compute, storage, and network resources are allocated for deployed AI agents. |
Network Services for Agents: Configures network routes, load balancing, and access policies for AI agents. |
Agent Logic Developer: Develops the core logic, AI model integration, and specific functionalities of the AI agents. Tests agent behavior. |
Agent Deployment & Production Mgmt: Deploys, scales, monitors, and manages the lifecycle of AI agents in production. Implements CI/CD for agents. |
Application Secrets
For secrets management, secure storage is provided using kubernetes secrets or specialized solutions that adhere to security procedures. Image security is reinforced by integrating container image scanning tools within artifact repositories, embedded within CI/CD pipelines. This process follows industry standard security gates to ensure the integrity of container images.
Endpoint Monitoring
Endpoint monitoring is critical in an AI Factory to secure the non-deterministic interactions of autonomous agents. While network policies isolate traffic, host-level visibility detects lateral movement, unauthorized model access, and credential theft within the Kubernetes cluster. By analyzing behavioral telemetry in real time, the platform identifies sophisticated fileless attacks and prompt injection escalations that bypass traditional signatures. This ensures the integrity of the reasoning loop and protects sensitive model weights from being compromised during complex execution
Auditing
Auditing is also a critical component, with comprehensive audit logging configured within associated applications. These logs are forwarded to Information and Event Management (SIEM) systems, following validated logging standards to ensure thorough and efficient monitoring of system activities. Together, these measures create a robust and secure environment to support AI workloads and platform services effectively.
Patch Management
A structured approach to patching and upgrades across the entire AI platform—including operating systems, container platforms, the AI software suite (e.g., NVIDIA AI Enterprise), and partner components—is crucial for security, stability, and performance. This requires rigorous testing, coordination with hardware and software vendors (leveraging the NVIDIA ecosystem and reference designs where applicable), and scheduled deployments to minimize operational disruption. Regular maintenance and updates ensure access to the latest features and security for AI agents.
Observability#
To understand the operation of long-running agents, extensive telemetry is necessary to observe the internal reasoning of the system. AgentOps addresses this requirement through a three-pronged monitoring strategy: traces detailing the workflow, logging user activity and responses of the models, and key performance metrics for the outcomes. This comprehensive set of signals provides a complete view, illustrating the entire execution path and quantifying the business value derived from these long-duration tasks.
Tracing
Application tracing is essential for managing the inherent non-determinism of LLM based systems. As agents evolve into complex, multi-step long-running agents, traditional logging—which assumes predictable, deterministic behavior—fails to capture why an agent reached a specific decision. Tracing bridges this gap by recording the full context of every model call, tool invocation, and retrieval step.
While various solutions exist for this requirement, the open source NeMo Agent Toolkit provides this critical profiling and observability by default. High fidelity tracing and optimization profiling provided by NeMo Agent Toolkit map the entire journey of a request across distributed services. This framework provides a coherent narrative of execution, which is vital when the same prompt may yield different outputs across planning cycles.
By consolidating these signals, an Enterprise AI Factory ensures that complex agentic workflows remain high performing and reliable. For organizations with existing observability stacks, NeMo Agent Toolkit supports OpenTelemetry standards, allowing these specialized agentic traces to integrate seamlessly with enterprise wide monitoring solutions.
Logging
Centralized logging forms a foundational aspect of this strategy, capturing detailed events from all layers of the platform. This includes logs from the underlying infrastructure, the container platform, core AI software components, and the AI agents themselves. These logs are invaluable, offering heuristics for debugging agent behavior, supporting security analysis by providing event records, and creating comprehensive audit trails. Such trails are essential for ensuring operational reliability, building trust in the AI system’s outputs, and meeting compliance requirements.
Metrics
Continuous monitoring of metrics is implemented to track both the health of the infrastructure and critical Key Performance Indicators (KPIs) specific to the AI agents. Key metrics, often collected using OpenTelemetry (OTEL) instrumentation, Application Performance Management (APM) tools, or directly from application endpoints and infrastructure tools or NVIDIA Data Center GPU Manager (DCGM), provide a real-time view of system performance and agent effectiveness. These metrics typically fall into the following categories:
Latency:
Time To First Token (TTFT): The delay before the agent produces its initial response token after receiving a request.
Tokens Per Second (TPS) / Output Throughput: The rate at which the agent generates response tokens over time.
End-to-End Latency: The total time elapsed from the user’s request to the completion of the agent’s full response.
Component Latency: The duration of individual processing steps, such as:
Plan Generation
Reasoning
Tool Calls
Database Queries (including vector database lookups)
Retriever Calls
Accuracy and Faithfulness:
Task Completion Rate: The percentage of assigned tasks that the agent successfully completes.
Accuracy/Relevance: The correctness and relevance of responses that rely on retrieved information (RAG), with specific metrics for retriever performance including precision, recall, and F1-score.
Faithfulness: How well the agent’s responses adhere to the provided source information, particularly in RAG scenarios.
Correctness: The validity of outputs from individual reasoning steps or executed tools.
Resource Utilization:
Consumption of GPU, CPU, and memory during agent operation.
Errors and Faults:
Fault Rate: The frequency of errors or failures within specific agent components or workflows (e.g., plan generation, tool calls, database access).
Timeout Rate: The number of operations that exceed their allocated time limit, categorized by component (e.g., tool call timeouts, retriever timeouts). To make the collected observability data useful, a consolidated reporting mechanism is beneficial. This involves presenting aggregated data from logging, metrics, and tracing in dashboards and reports. Such presentations offer a heuristic view of the systems health, performance, and accuracy, which can be tailored for different user roles, including IT operations, AI developers, and business stakeholders.
By extending the observability focus to these detailed aspects of operations—such as the specifics of planning and reasoning steps, the performance and accuracy of tool and data retrieval calls, and detailed fault and timeout analysis—enterprises can develop a more thorough understanding and improve control over their AI solutions. This increased visibility contributes to building and maintaining AI systems that are powerful, robust, efficient, and trustworthy.
Enterprise Cloud Native Platform#
The Enterprise Cloud Native Platform, with Kubernetes at its core, provides the agility, scalability, and resilience required for an NVIDIA Enterprise AI Factory capable of handling long running AI training jobs to developing and deploying autonomous agents. Kubernetes embodies cloud-native principles by orchestrating containers, managing microservice based agent architectures, and enabling dynamic automation. This includes the automated deployment of new agent versions, scaling inference based on demand, and self healing to support high availability and resource management for GPU clusters.
These capabilities are critical as AI workloads transition from static model serving to running agents. The ability to independently develop, update, and scale microservice based agents, coupled with automated CI/CD pipelines, allows for rapid iteration. Kubernetes handles the significant and often burstable compute demands for training models and scales NVIDIA NIM inference services for deployed agents based on real time needs. Through the NVIDIA NVIDIA GPU Operator and NVIDIA Network Operator, the platform automates the provisioning of drivers, runtimes, and monitoring, reducing the operational burden.
Kubernetes serves as the foundational control plane for the AI Factory, unifying a complex stack of storage, networking, and observability onto a single platform. Sophisticated schedulers such as KAI, Kueue, or Volcano can optionally extend the platform to create a highly efficient, multi-tenant environment capable of scaling diverse AI workloads with precision. This ecosystem allows the AI Factory to support a wide variety of workloads simultaneously, ranging from long running AI training to high priority inference tasks.