Technical Brief#
Overview#
Fraudulent emails designed to manipulate people into downloading malware, sharing sensitive information, or sending money to criminals are becoming more and more common. Historically, spear phishing focused on high-value targets at individual companies due to the personalized nature of the attack. As generative AI techniques are becoming more popular (especially those aimed at text generation), it is becoming easier for cyber criminals to harness this power to create large-scale spear phishing campaigns. To defend against spear phishing, companies need to invest in using this same base layer of technology for protection against such attacks. Traditional approaches to leverage AI to solve the spear phishing problem have struggled with sourcing enough training data to create an effective model. This data gap has made using AI an uneasy path to cross since each Enterprise only sees a small fraction of the attacks.
With NVIDIA NeMo and Morpheus, this lack of available training data to create such spear phishing detectors is now an issue of the past. The NVIDIA Morpheus cybersecurity AI framework provides a Natural Language Processing (NLP) model that has been trained using synthetic emails generated by NeMo to identify spear phishing attempts. Morpheus is able to infer whether an email is spear phishing or not by first determining the intent of the email: whether it is seeking financial information, requesting cryptocurrency, or asking for personal financial information, such as account and routing numbers. Morpheus then combines the intent of the message with anonymized historical data of the sender, including syntactic analysis, message timing, and previous intentions. The spear phishing model incorporates all of this data into an actionable result.
To reduce the time to develop a phishing detection solution, NVIDIA has developed the Spear Phishing AI Workflow. This workflow leverages NVIDIA Morpheus, the open-source Postfix mail server, a PostgreSQL database, as well as a series of pre-trained models using generative AI techniques. Model inference occurs within the Morpheus pipeline, where a score is generated, correlating the classification of the message’s intent based upon its content. The end-user is then notified to verify the safety of the email, which was flagged by the AI model, for intent confirmation. This feedback can then be used to re-train the model and generate additional training emails.
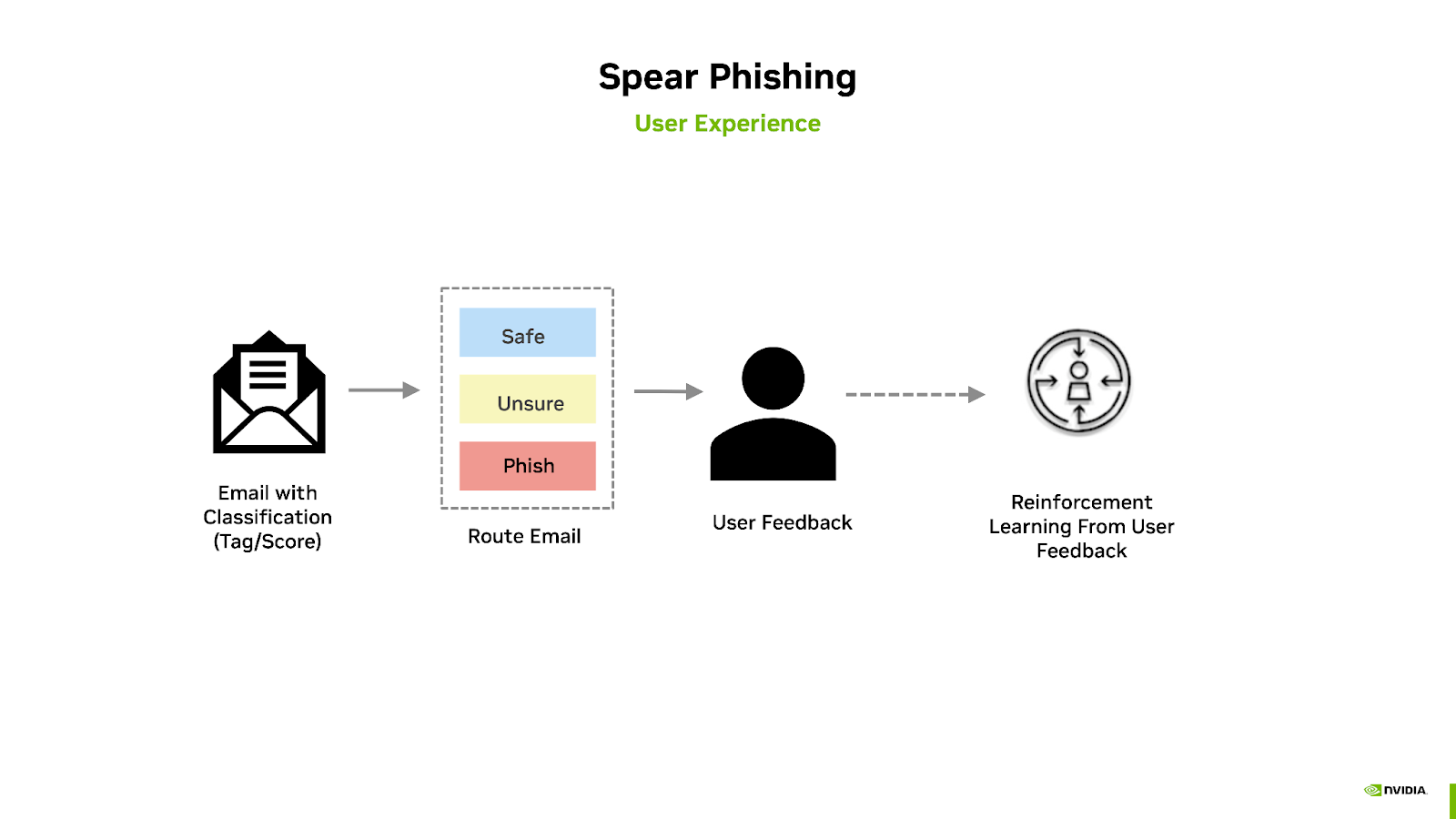
This NVIDIA AI Workflow contains:
Natural Language Processing (NLP) pre-trained models to analyze and classify emails for identifying spear phishing attempts
Inference pipeline for spear phishing detection
A reference for solution deployment in production, including components like logging and monitoring the workflow.
Cloud-native deployable bundle packaged as a single helm chart
Using the above assets, this NVIDIA AI Workflow provides a reference for you to get started and build your own AI solution with minimal preparation, and includes enterprise-ready implementation best practices helping you achieve the desired AI outcome more quickly while still allowing a path for you to deviate. NVIDIA AI Workflows are designed as microservices, which means they can be deployed on Kubernetes alone or with other microservices to create a production-ready application for seamless scaling in your enterprise environment.
The following cloud-native Kubernetes services are used with this workflow:
NVIDIA Morpheus
Postfix Mail Server
MLflow
Prometheus
Grafana
PostgreSQL
These components are packaged together into a deployable solution described in the diagram below:
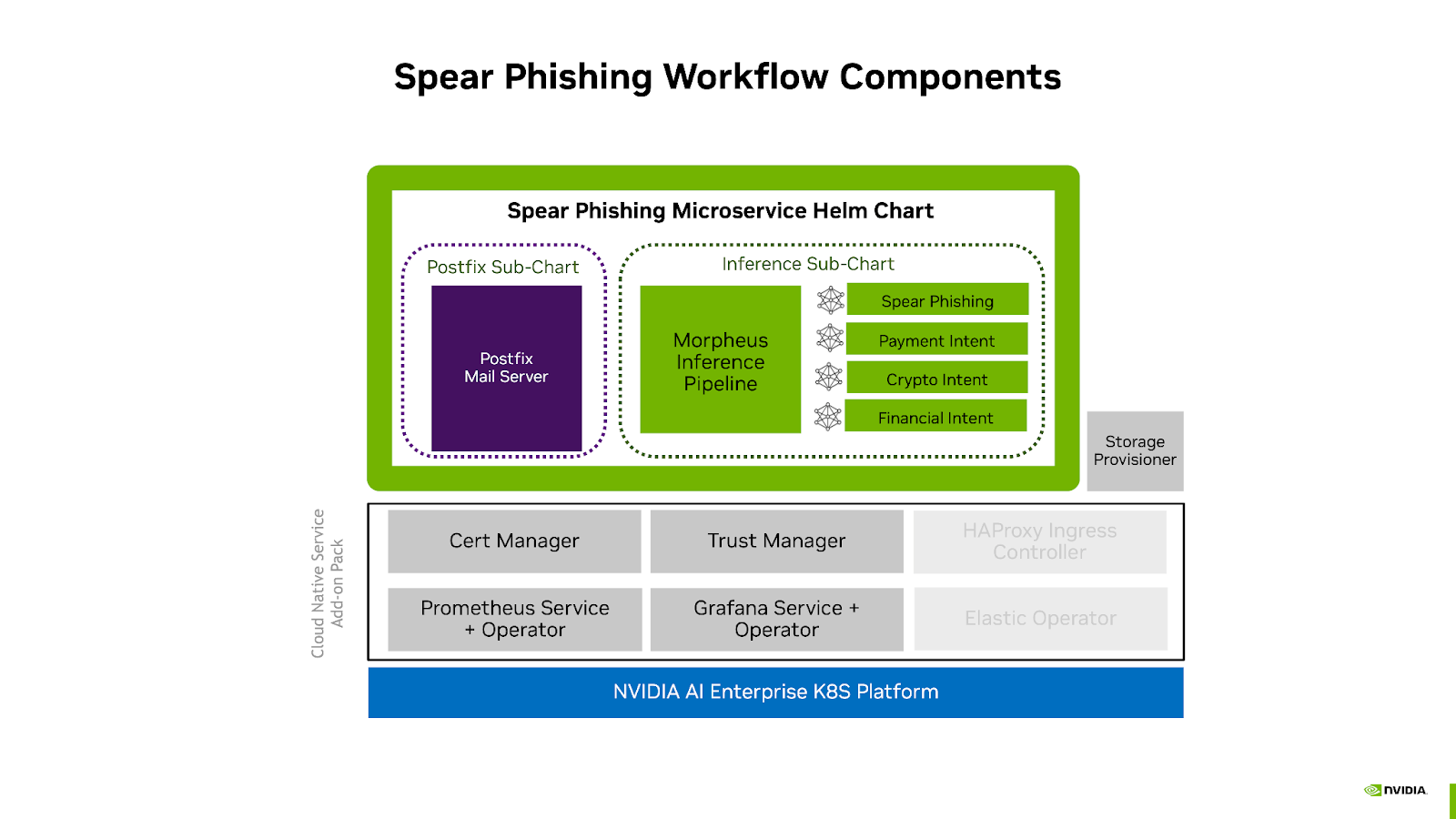
More information about the components used can be found in the Spear Phishing Workflow Guide and the NVIDIA Cloud Native Service Add-on Pack Deployment Guide.
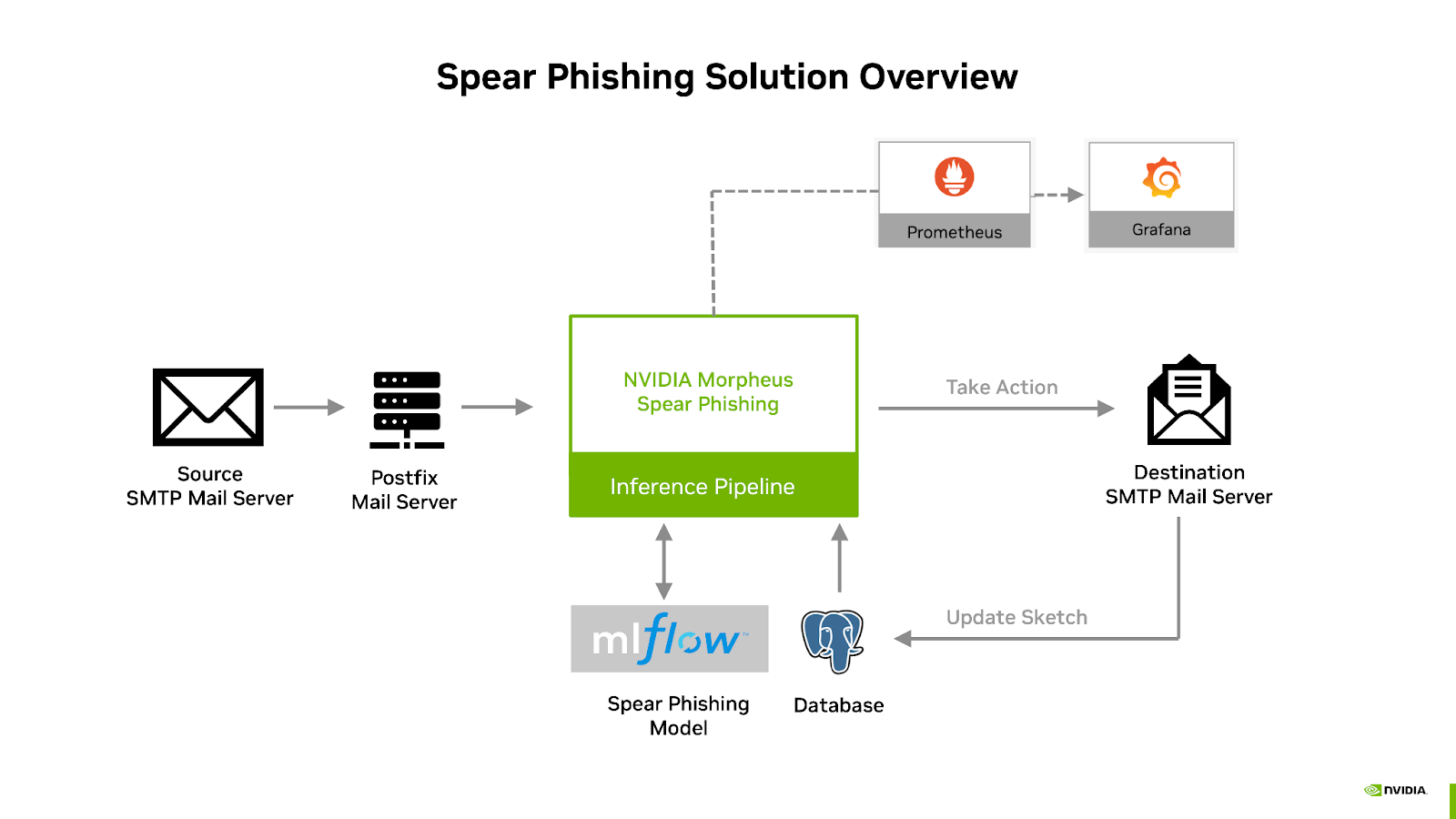
These components are used to build and deploy the spear phishing inference pipeline and are integrated together with the additional components as indicated in the below diagram:
Pre-Trained Models#
Email intentions play a crucial role in deciding whether the sender’s email is benign or spear phishing. To tap into this signal, Large Language Models (LLMs) were trained to infer intents using samples of Enterprise email content. The NVIDIA Spear Phishing AI Workflow includes three intention models: whether the email is asking for a payment, discussing cryptocurrency, or requesting personal financial information such as account and routing numbers. These become features of the spear phishing detection pre-trained model which is included in this Phishing Detection AI Workflow.
Note
The pre-trained models were trained in such a way to include no PII or sensitive information from the originating institution/enterprise.
Inference Pipeline#
The Spear Phishing AI Workflow inference pipeline includes sender behavior feature generation, intent classification, scoring, and header manipulation. The following diagram illustrates an overview of the the Morpheus Spear Phishing inference pipeline:
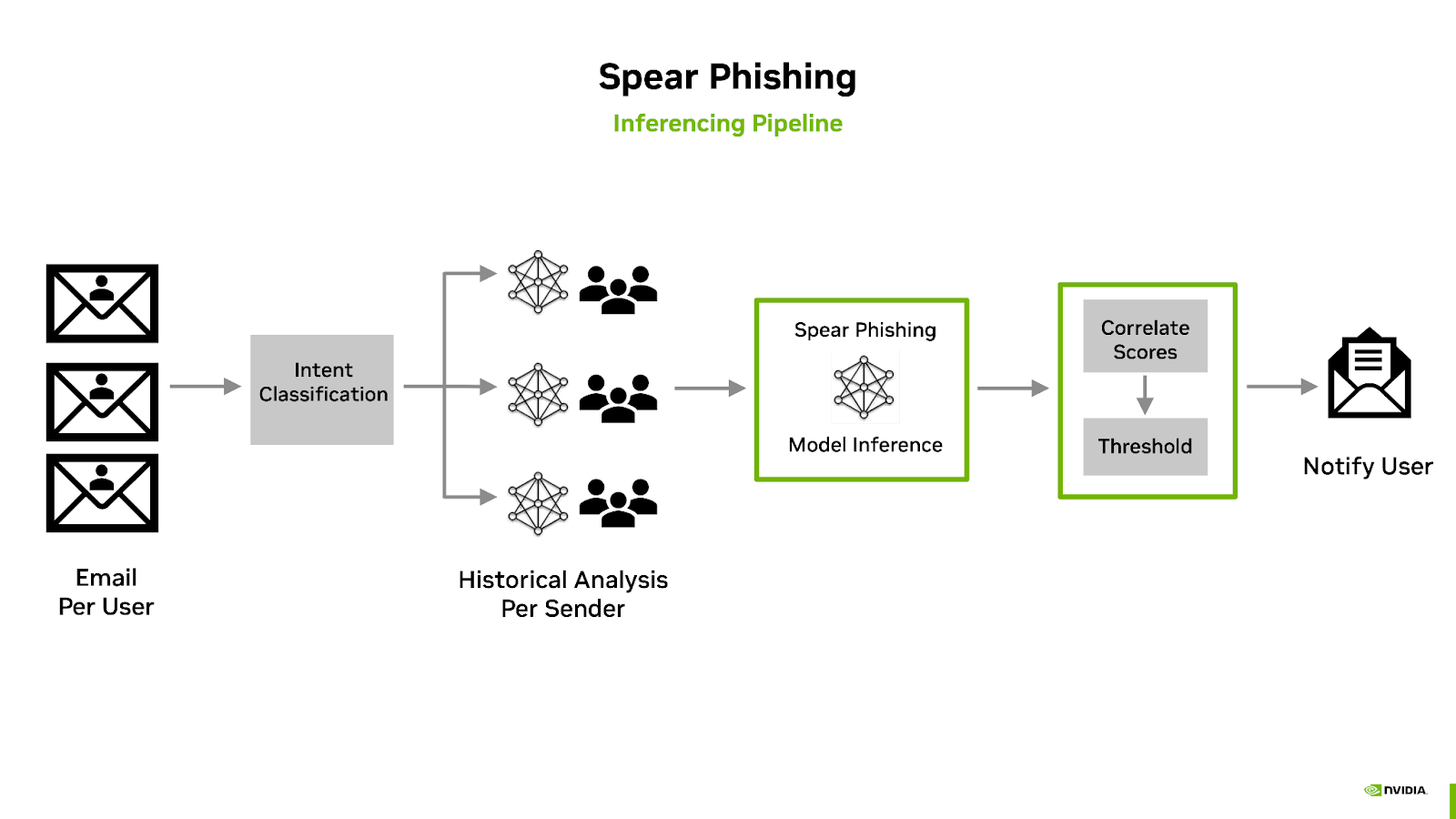
The classification of email takes place during a preprocess stage which first leverages three pre-trained sentiment analysis models for predicting the emails intent.
Is the email requesting financial information?
Is email requesting personal information?
Is the email mentioning cryptocurrency?
Note
Additional sentiment analysis models can be added for email intent predictions.
The results of the intents are then combined with historical information into what is known as the sender’s sketch. This includes anonymized statistical information regarding the sender of the email, such as the timing of the mail, syntactic analysis, and previous intentions. For example, does Bob normally ask Alice for a Bitcoin payment at 2AM with poor grammar?
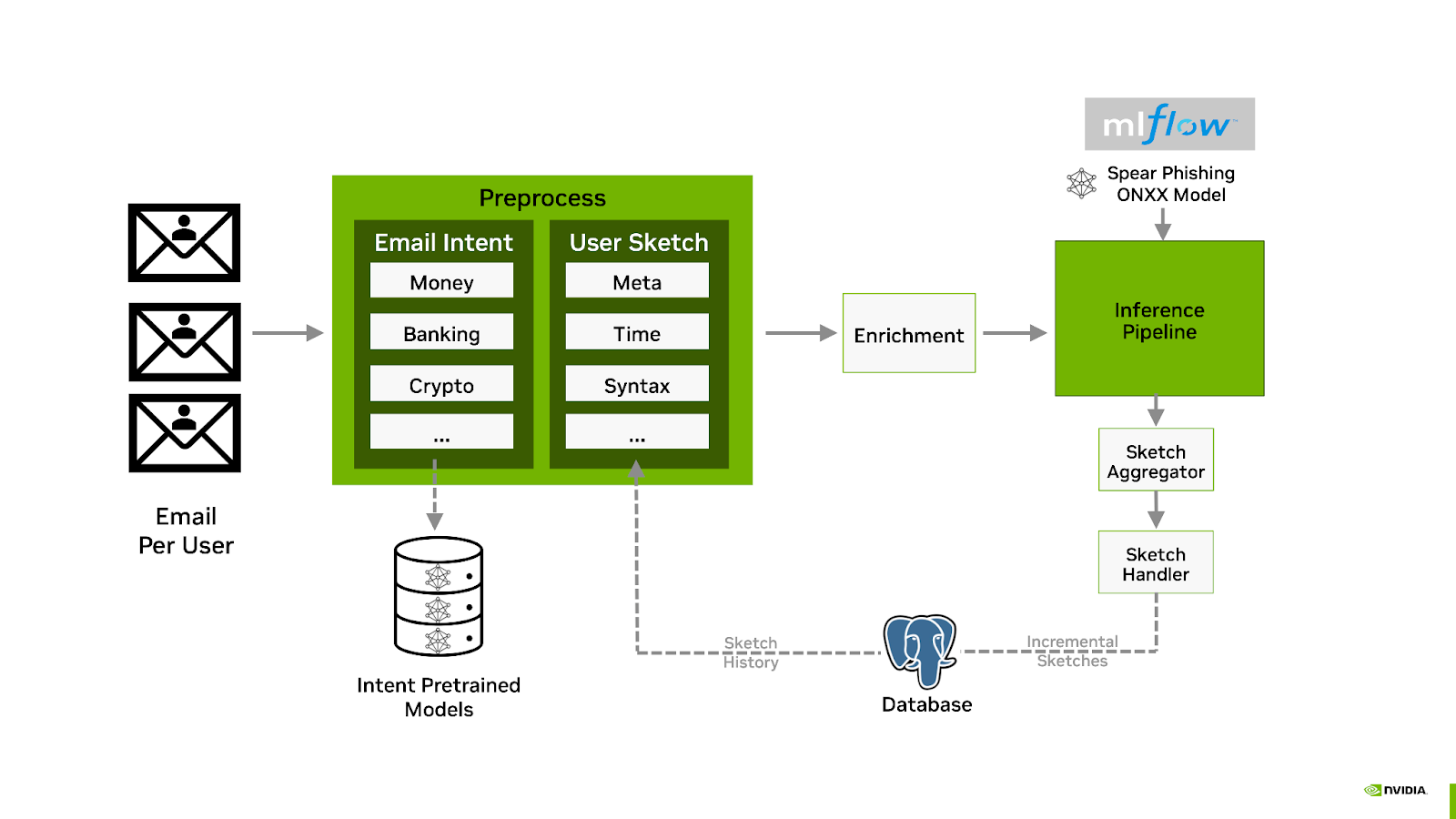
The intention analysis, sender sketch profile, and email are combined and then used for inference using the Spear Phishing model. The resulting score is also added as an email header, and if the score is above a specified threshold, the subject is then modified to include a warning. Administrators can customize the workflow to take other actions, such as delivering the mail to a dedicated quarantine mailbox.
Additional Components#
The following components are deployed and integrated as a part of the workflow solution:
Postfix Mail Server
The open-source Postfix mail server is used to source and sink email in and out of the inference pipeline. Administrators can configure their DNS MX record to point to the Postfix SMTP server. The Postfix server will accept the mail and route it to the Morpheus content filter. The inference pipeline then re-injects the mail, with Spear Phishing analysis score, into the Postfix queue, where it is delivered to the next-hop mail server, such as Office 365 or Gmail.
PostGreSQL
The NVIDIA Spear Phishing AI Workflow uses the open source object-relational database system PostGreSQL to store both MLflow models and sender sketches.
MLflow
The MLflow open-source platform is a key element to managing the included AI models. The MLOps platform enables organizations to easily manage their end-to-end machine learning lifecycle. MLflow uses a centralized model store and has its own set of APIs and user interface for manageability. In this workflow, MLflow’s tracking database is backed by a PostgreSQL database. At the beginning of the pipeline, the Morpheus spear phishing pre-trained model is loaded into MLflow and will be used for inference. Storing the model in MLflow allows administrators to update the model without having to stop and start the pipeline.
Monitoring
The Spear Phishing AI workflow outputs statistical information using Prometheus. Pipeline throughput statistics; active health and status of the pipeline; and spear phishing frequency metrics can be viewed via the Grafana dashboard.