AI Grid Control Plane Design#
The AI grid control plane introduces a deterministic, SLA-aware AI workload routing layer that treats model endpoints as a distributed systems fabric rather than a set of isolated clusters. Instead of simply sending each request to the nearest or least‑loaded region, the orchestrator evaluates latency, cost, model capabilities, health signals, and capacity in real time to decide exactly where a request should execute, making SLA‑aware routing a first‑class primitive. At the same time, it optimizes model placement and reuse through KV‑cache‑aware model routing for LLM prompts, steering compatible requests to instances with high cache‑hit probability to reduce token latency and GPU consumption. This combination of deterministic policy enforcement and cache‑savvy routing enables operators to deliver predictable performance under strict SLAs while significantly improving the efficiency of their global AI inference infrastructure.
The AI Grid Control Plane acts as a high-performance nervous system. The AI Grid Orchestrator provides node health and resource quotas, Load Balancers distribute SLA aware network traffic, and LLM Routers provide “semantic intelligence” by directing prompts based on cost, complexity, and context. Together, they ensure scalable, cost-effective, and resilient distributed model inference.
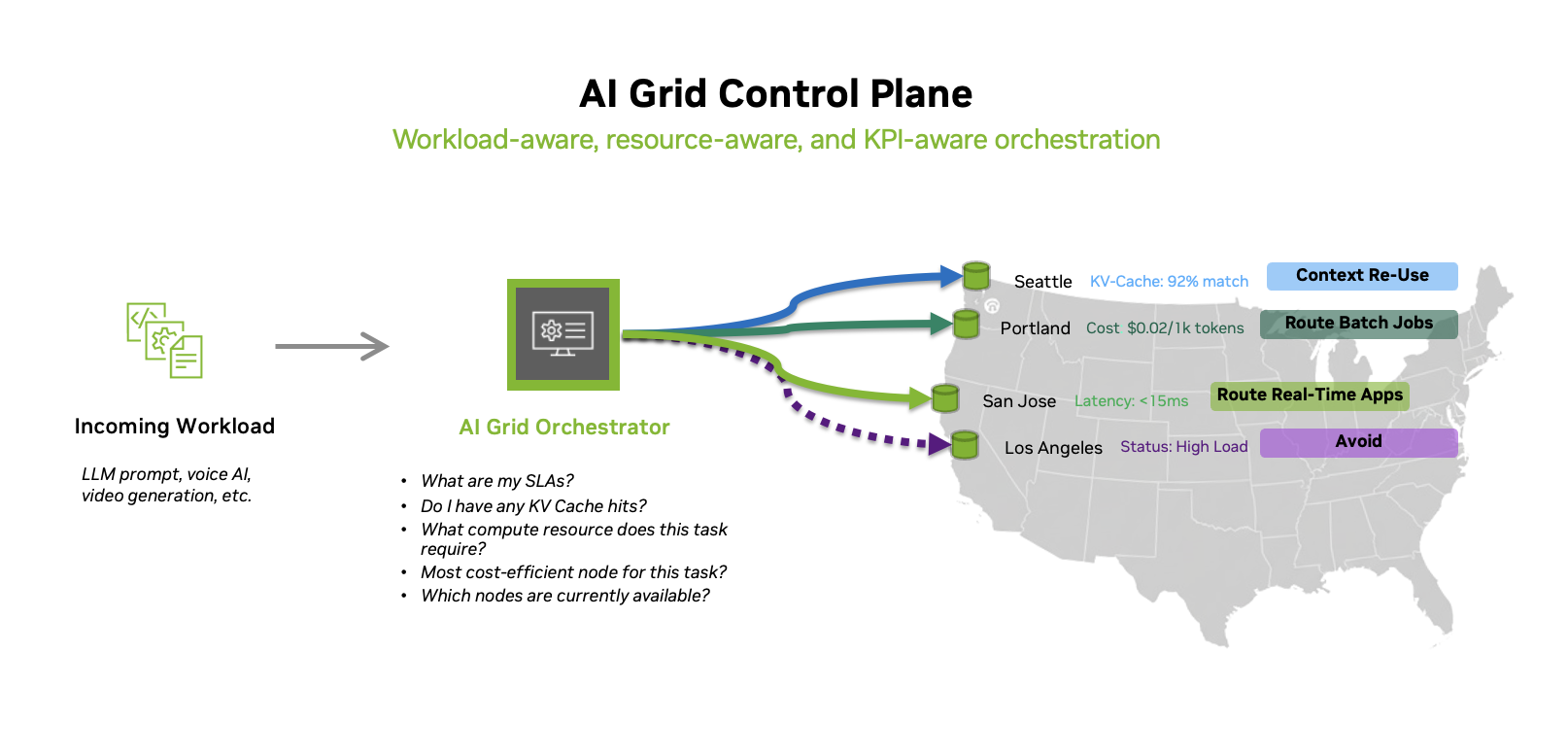
Figure 10. AI grid control plane treating distributed endpoints as a single logical platform for workload- and resource-aware routing.
Unlike traditional load balancers, the AI grid control plane routes traffic based on:
Prompt Awareness: It analyzes the complexity and intent of each request so that simple interactions are steered to lighter‑tier nodes, while complex reasoning tasks are routed to high‑density RTX PRO 6000 clusters.
Resource and Utilization Awareness: It balances compute and network utilization in real-time to avoid hotspots and prevent any single node from becoming a bottleneck.
Multi-tenancy: It supports “slicing” of the grid, enabling guaranteed performance for high-priority tenants while keeping other tenants hard-isolated on a shared fabric.
Data governance: The AI Grid Control Plane embeds data governance as a first-class routing constraint, enforcing tenant-specific data residency, sovereignty, and compliance policies at request time.
Security: It treats security as a first-class design principle, enforcing role-based access controls and hardened multi-tenancy. Deterministic routing decisions are fully auditable, providing traceability, attack-surface minimization, and consistent security posture under strict SLAs.
AI Grid Control Plane Service Flow#
The AI grid service flow diagram below illustrates a multi‑tier architecture that bridges enterprise‑level AI configuration with high‑performance end‑user service delivery. Service providers or telcos manage tenant creation, and deployment requests originate from each tenant. These requests are handled by the AI grid control plane through a centralized Resource and Intent Engine, which translates high‑level requirements into infrastructure actions. The Decision and Policy Engine then can coordinate with an SDN controller for network creation and with NVCF (NVIDIA Cloud Functions) for optional serverless deployment, before provisioning workloads onto AI grid resources.
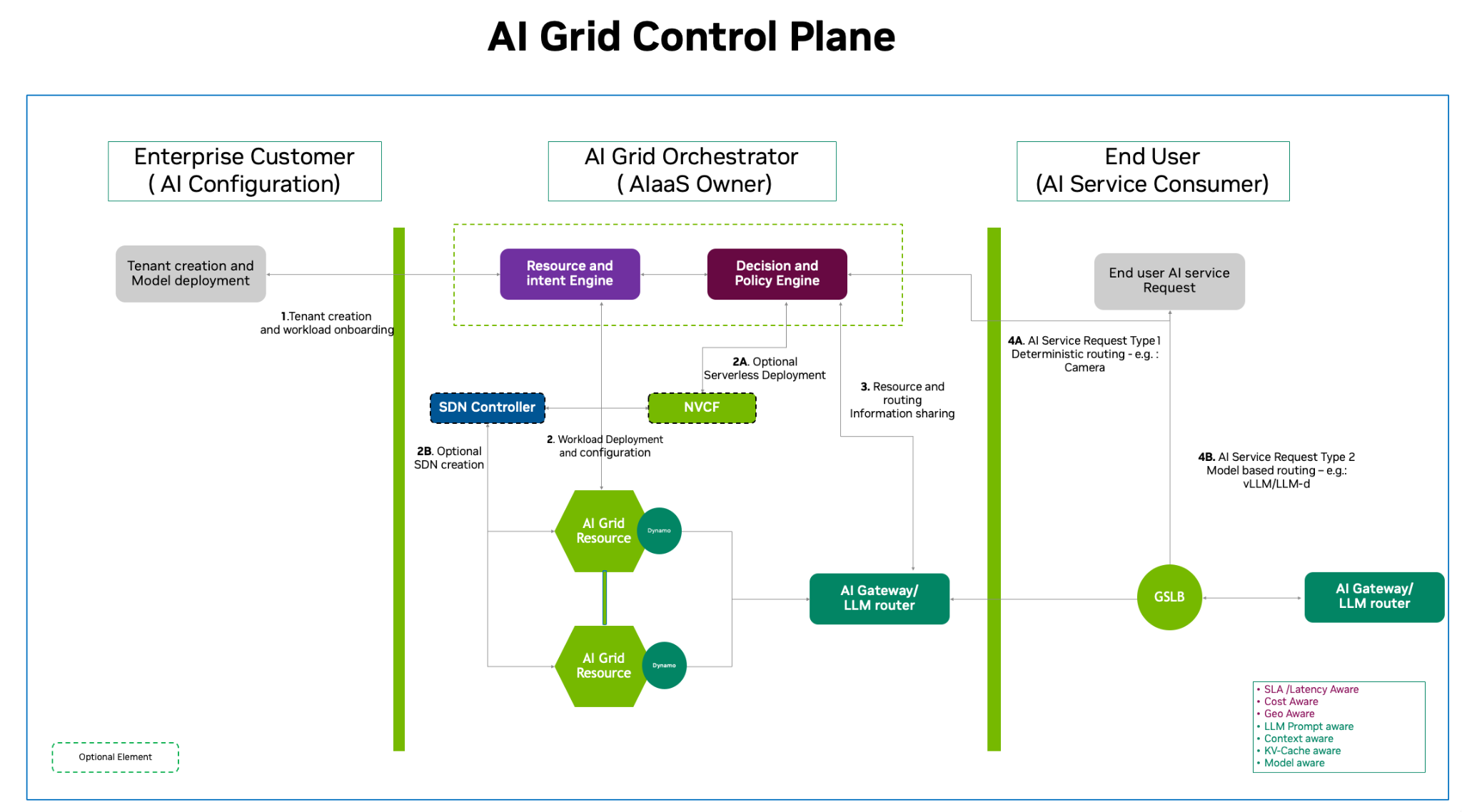
Figure 11. NVIDIA AI Grid control plane service flow showing how enterprise tenants, the AI Grid Orchestrator, and end‑user services interact through resource and policy engines to provision workloads across the grid.
1. The AI Grid Orchestrator
The AI Grid Orchestrator maintains the state knowing which clusters are healthy and where capacity is available. Through resource and intent engine It manages the lifecycle of pod, cluster, and model deployments. If a node fails, the Orchestrator detects the heartbeat loss and re-provisions the model elsewhere to maintain the desired state.
Often built on Kubernetes or specialized AI scheduling frameworks, the AI Grid Orchestrator includes a sophisticated decision and policy engine to govern distributed resources, dynamically enforcing governance rules, optimizing cost-efficiency through predictive analytics. The Orchestrator ensures that workload placement adheres to strict security protocols while maintaining high-performance service level agreements across complex, heterogeneous hardware environments for seamless and resilient model inference and workload placement. Below is a conceptual view of the AI Grid Orchestrator dashboard.
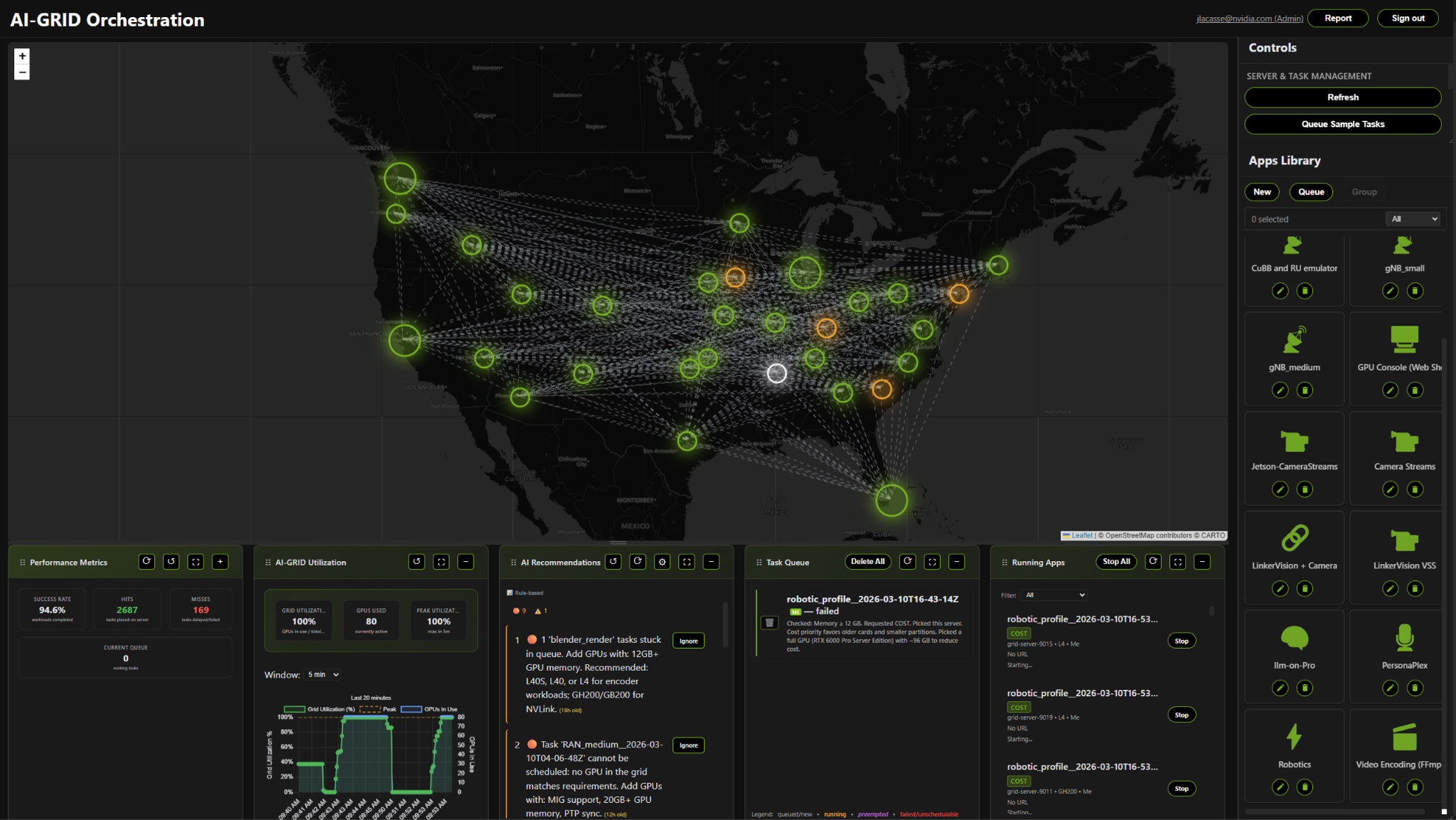
Figure 12. Conceptual AI Grid Orchestrator dashboard providing a global view of cluster health, workload placement, and real‑time telemetry across geographically distributed AI infrastructure.
2. Global Load Balancers
While the Orchestrator handles the placement of resources, the Global Server Load Balancer (GSLB) handles the flow of incoming data (Ingress) and determines where the request should be sent for processing. It distributes incoming requests across multiple active instances and may maintain a ranking list based on several criteria set by the service providers. It ensures that no single GPU becomes a bottleneck while others sit idle. The Load Balancer usually looks at hardware-level health, like connection counts or CPU/GPU utilization and may connect to the AI Grid Orchestrator directly or through an AI Gateway or LLM router for periodic updates for resources, utilization, policy, etc.
3. LLM Routers
An LLM Router is focused on intelligent request routing. Its primary function is to analyze incoming queries, evaluate context, complexity, and metadata, and then direct each request to the most suitable model. Unlike a standard Load Balancer, a Router is context-aware. It analyzes the incoming prompt to decide the most efficient path. It may also do Semantic Caching: If the same question was just asked, the router can serve a cached response instead of hitting the GPU again.
4. Dynamo
Nvidia Dynamo simplifies and automates the complexities of distributed serving by disaggregating the various phases of inference across different GPUs, intelligently routing requests to the appropriate GPU to avoid redundant computation, and extending GPU memory through data caching to cost-effective storage tiers.
This architectural overview reflects current best practices, but expect these tools to evolve as capabilities mature.