AI Grid Hardware Reference Design#
Hardware Platforms#

Figure 2. NVIDIA AI Grid hardware platforms featuring HGX B300 and RTX PRO servers connected over a unified fabric to deliver optimized training, telco, and inference workloads across distributed AI infrastructure.
The AI Grid platform defines a set of standardized NVIDIA-certified systems delivered through a global ecosystem of OEM partners, each optimized for a distinct role in the AI lifecycle:
HGX B300 systems: Designed for large‑scale training and fine‑tuning of foundation and domain‑specific models.
RTX PRO Servers with RTX PRO 6000 Blackwell GPUs: Available in 4U and 2U configurations, optimized for high‑throughput, low‑latency inference and telco workloads at regional hubs and edge sites. The AI Grid offers flexible deployment profiles, ranging from a 2U configuration engineered for a balanced 50:50 AI-to-Telco workload split to a high-density 4U configuration optimized for an 80:20 ratio as an example that prioritizes heavy AI compute while maintaining essential telecommunications functions.
SN5400 leaf switches with optional SN5610‑based Spectrum‑X spine‑leaf fabrics: Provide the high‑performance, low‑latency networking required for distributed AI.
Together, these platforms give operators consistent, repeatable building blocks for AI factories, regional clusters, and edge nodes, with common management, networking, and software stacks, and support a range of power envelopes, including <15 kW and <25 kW per rack.
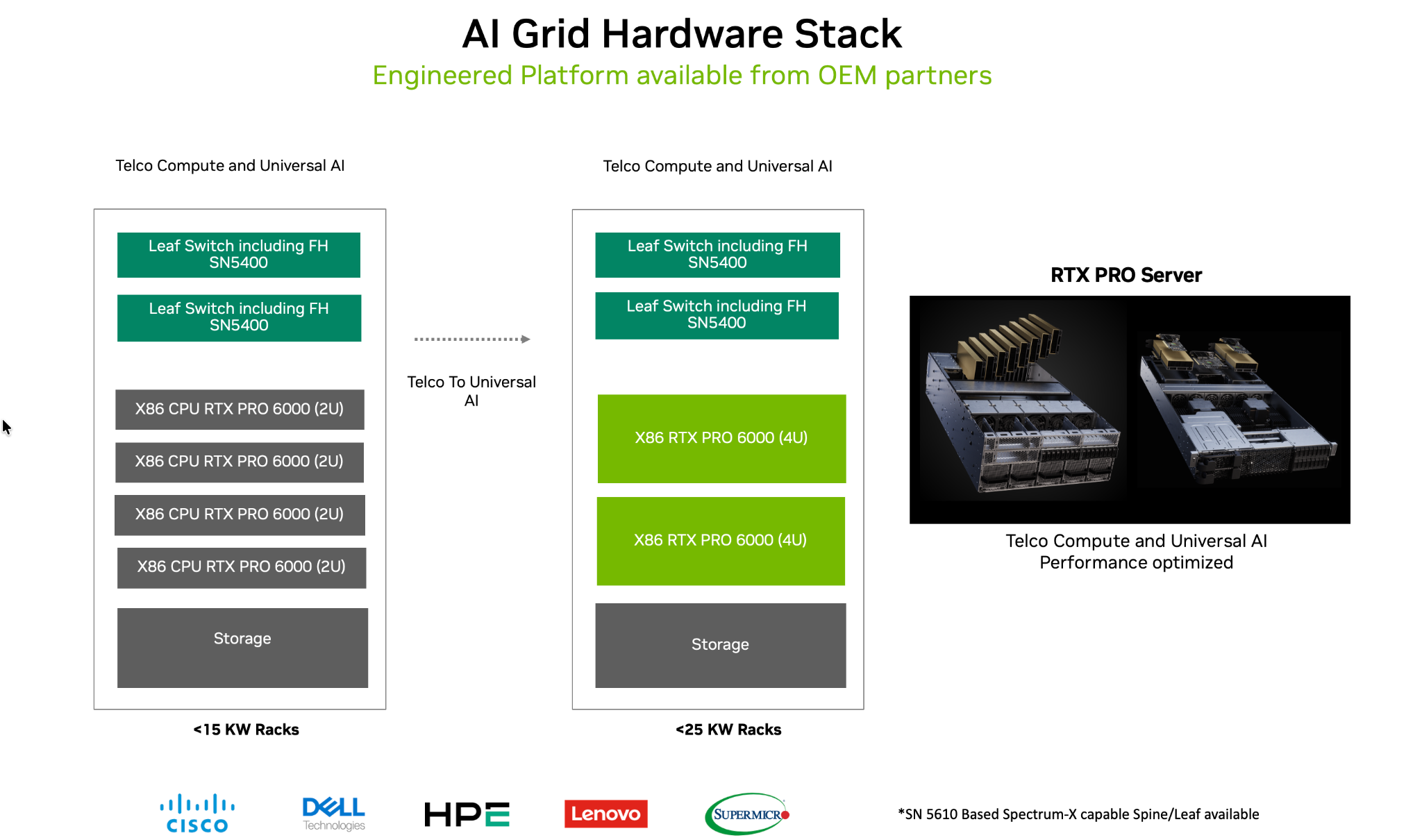
Figure 3. NVIDIA AI Grid hardware stack and example RTX PRO Server 2U and 4U system configurations, illustrating OEM‑delivered building blocks optimized for telco compute and universal AI workloads across diverse rack power envelopes.
Recommended 2U and 4U RTX PRO Server configurations are shown below.

Figure 4. NVIDIA RTX PRO Server 2U reference configuration featuring Blackwell‑based GPUs, high‑bandwidth networking, and balanced CPU, memory, and NVMe storage for telco and AI inference workloads.

Figure 5. NVIDIA RTX PRO Server 4U reference configuration with up to eight Blackwell‑based GPUs, expanded networking, and scalable CPU, memory, and NVMe capacity for high‑density AI and telco edge deployments.
Network Design#
To build a reliable AI Grid, service providers deploy an NVIDIA‑certified infrastructure stack from an NVIDIA partner that conforms to the NVIDIA Enterprise Reference Architecture (ERA) for RTX PRO Servers. Supported server configurations follow the ERA nomenclature of (number of CPUs)–(number of GPUs)–(number of network adapters), with an optional suffix indicating average bandwidth per GPU for GPU‑to‑GPU data movement. For example, the configurations shown above are 2‑2‑3 and 2‑8‑5 systems:
2‑8‑5: Designed for high-density compute, for example AI:Telco workload 80:20 ratio to prioritize heavy AI workloads while maintaining essential Telco functions.
2‑2‑3: Engineered for a 50:50 AI:Telco workload split, providing an equal distribution of resources between AI inference and Telco-specific processing.
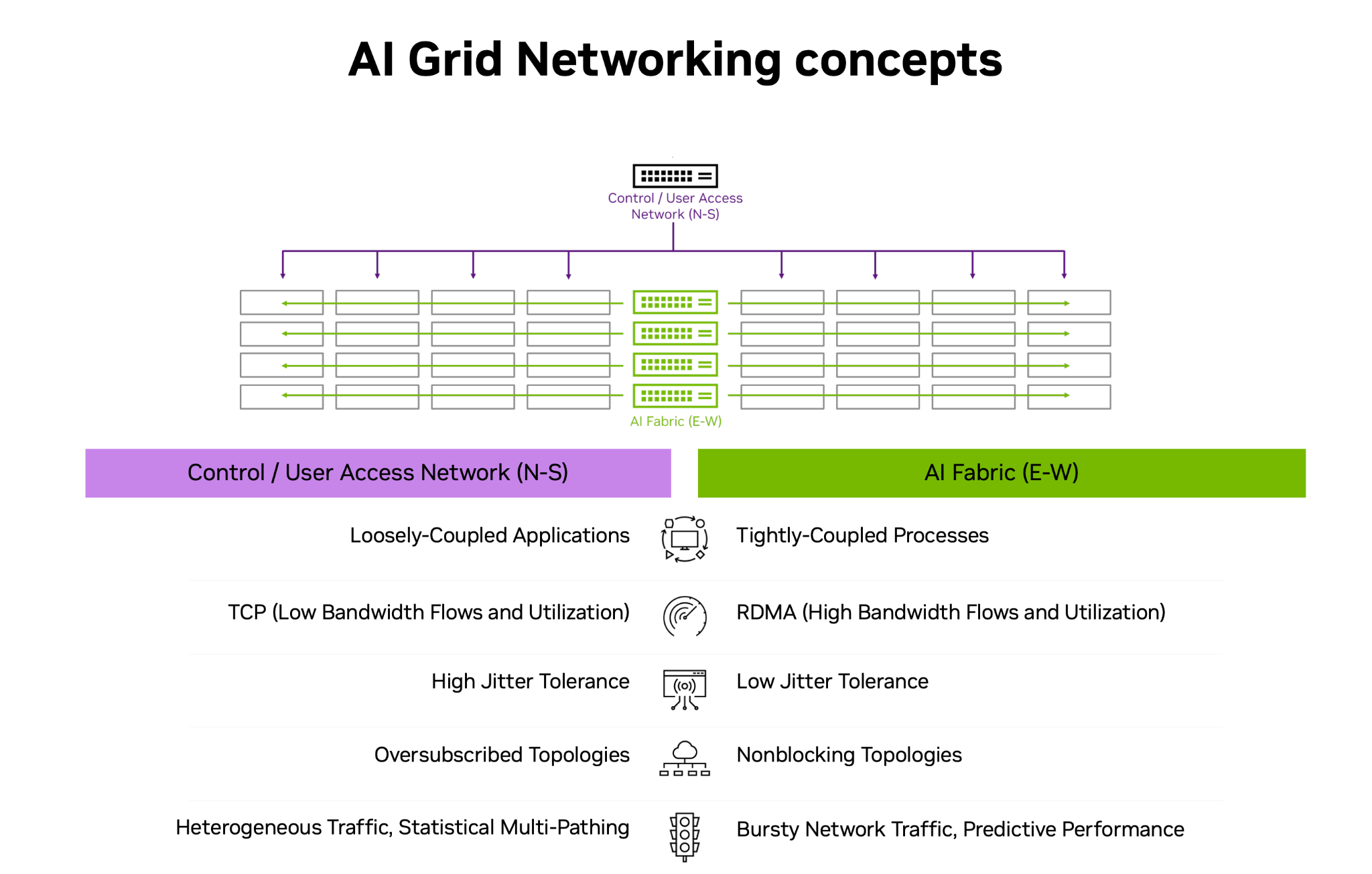
Figure 6. NVIDIA AI Grid networking concepts illustrating dual N‑S and E‑W fabrics that connect user access, control, and AI fabrics to meet the distinct latency and bandwidth requirements of telco and high‑performance AI workloads.
The AI Grid uses a dual‑fabric networking architecture to address the distinct requirements of user traffic,Telco traffic and high‑performance AI processing:
North-South (N-S) network: Provides control, storage, internet connectivity, and CPU/OS‑driven communication between cluster nodes for loosely coupled applications using standard TCP flows, with higher jitter tolerance and oversubscribed topologies for heterogeneous traffic.
East-West (E-W) network: Forms a high‑bandwidth, low‑latency fabric that connects tightly coupled processes via RDMA, using non‑blocking topologies to deliver predictable performance and low jitter for bursty AI and RAN workloads.
In the AI Grid design, the N‑S network is used for access, storage, administrative access, and CPU/OS‑level node communication, while the E‑W network is reserved for non‑blocking GPU‑to‑GPU traffic for multi‑GPU workloads and telco workloads such as vRAN that require PTP and SyncE support. For E-W Network recommended network cards are ConnectX-7, SuperNIC B3140H or ConnectX-8. For N-S Network BF3 B3220 card is recommended. Depending on the workload (e.g. RAN or multi-GPU inference) appropriate E-W cards can be selected.
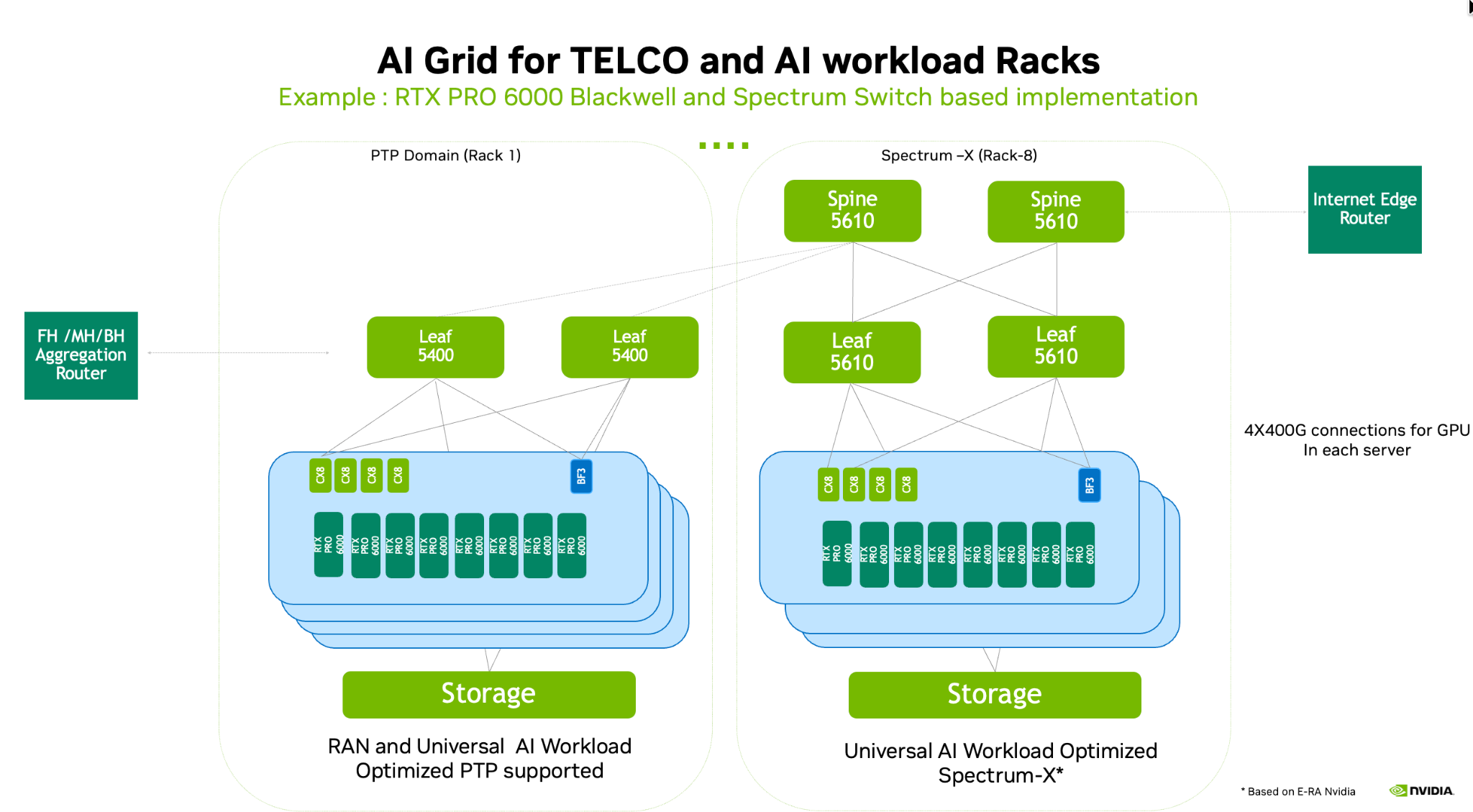
Figure 7. Example NVIDIA AI Grid rack implementation for telco and AI workloads using RTX PRO 6000 Blackwell servers and Spectrum switches to deliver a high‑bandwidth, low‑latency non‑blocking fabric for large‑scale multi‑GPU inference.
In the reference implementation shown, NVIDIA Spectrum‑4 SN5400 switches (with PTP/SyncE enabled) serve as leaf switches in the RAN‑ready PTP domain, while SN5610 switches, as part of the Spectrum‑X Ethernet networking platform, serve as spine switches in the AI‑optimized domain, together providing a high‑bandwidth, low‑latency, non‑blocking fabric for both telco (including vRAN) and AI workloads, including large‑scale multi‑GPU inference.
Example Switch and Compute Node Counts#
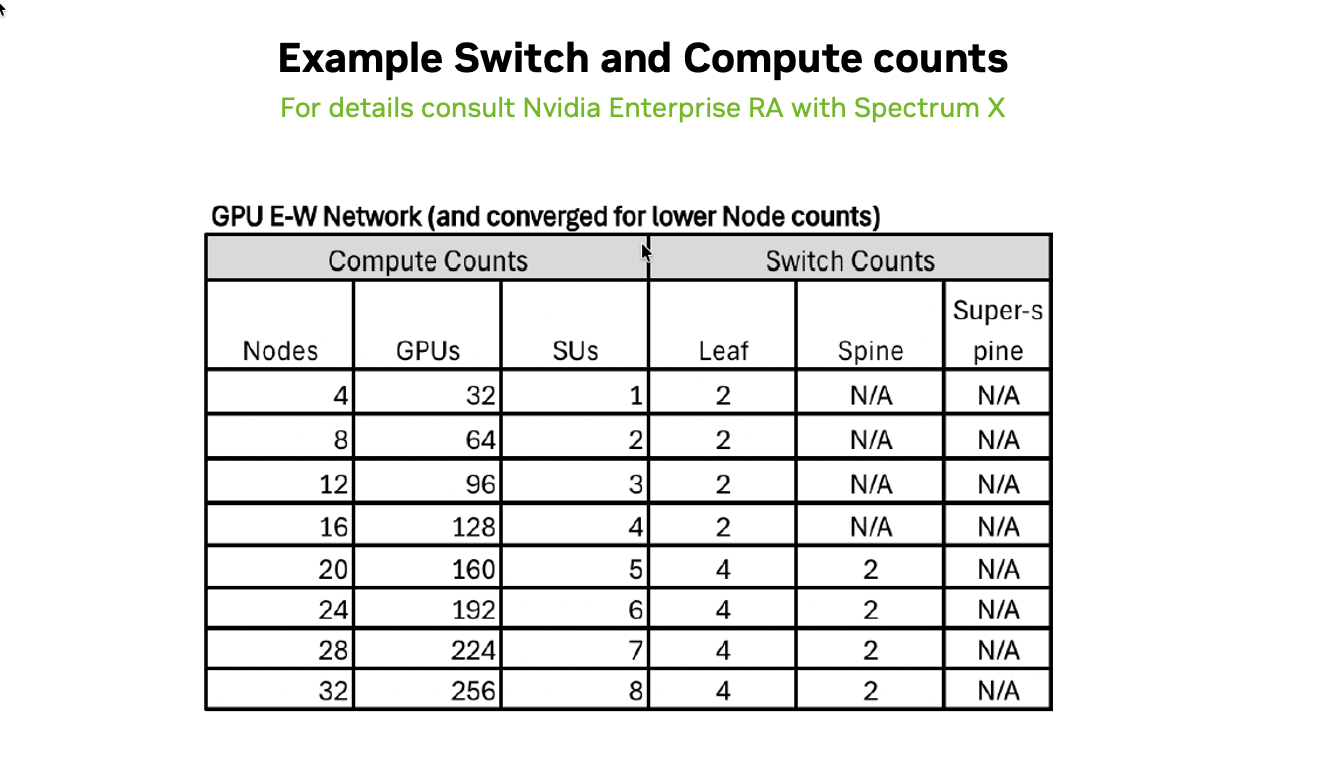
Figure 8. Example GPU E‑W network leaf‑spine sizing showing how SN5610 switch counts scale with node and GPU counts for AI workload‑optimized deployments.
The table above is an example of leaf-spine switch (SN5610) deployment sizes based on compute node counts for an AI workload-optimized scenario. For up to 96 GPUs (12 nodes), a single pair of SN5610 leaf switches is sufficient to serve both the E-W and N-S network. For larger deployments, the GPU E-W network evolves from a simple 2-leaf switch setup for small clusters (4–16 nodes) to a spine-leaf architecture once deployments exceed 16 nodes with 128+ GPUs.