Deploying a NVIDIA NIM Inference Microservice on Brev#
Launch a NIM on Brev!#
First off, a short background on NVIDIA NIMs#
At their core, NIMs are an easy way to deploy AI on GPUs. Built on the NVIDIA software platform, they are containers that incorporate CUDA, TensorRT, TensorRT-LLM, and Triton Inference Server. NIMs are designed to be highly performant and can be used to accelerate a wide range of applications.
A NIM is a container that provides an interactive API for running blazing fast inference. Deploying a large language model NIM requires 2 key things – the NIM container (which holds the API, server, and runtime layers) and the model engine.
Let’s get started with deploying it on Brev!
1. Create an account#
Make an account on the Brev console.
2. Launch an instance#
To deploy a NIM, you’ll need to directly provision a VM on Brev first!
To begin, head over to the Instances tab in the Brev console and click on the blue New + button.
When creating your instance, select VM Mode.
To deploy a NIM, we recommend using L40S 48GB GPU or A100 80GB GPU! You can see the various hardware compatible with running different NIMs here.
Select a GPU type, enter a name for your instance, and click on the Deploy button. It’ll take a few minutes for the instance to deploy - once it says Running, you can access your instance with the Brev CLI.
3. Connect to and setup your instance#
Brev wraps SSH to make it easy to hop into your instance, so after installing the Brev CLI, run the following command in your terminal.
SSH into your VM and use default Docker:
brev shell <instance-name>
Verify that the VM setup is correct:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
You’ll need to get an NGC API Key to use NIMs.
Let’s create an environment variable for it:
export NGC_CLI_API_KEY=<value>
Run one of the following commands to make the key available at startup:
# If using bash
echo "export NGC_CLI_API_KEY=<value>" >> ~/.bashrc
# If using zsh
echo "export NGC_CLI_API_KEY=<value>" >> ~/.zshrc
Docker Login to NGC (to pull the NIM)
echo "$NGC_CLI_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
Set up the NGC CLI
This documentation uses the ngc CLI tool in a number of examples. See the NGC CLI documentation and follow the AMD64 documentation for downloading and configuring the tool.
4. Time to deploy your first NIM! We’ll be using the llama3-8b-instruct model. You should be able to follow these instructions to deploy any other NVIDIA NIM.#
List available NIMs
ngc registry image list --format_type csv nvcr.io/nim/meta/*
The following command launches a Docker container for the llama3-8b-instruct model.
# Choose a container name for bookkeeping
export CONTAINER_NAME=Llama3-8B-Instruct
# The container name from the previous ngc registry image list command
Repository=nim/meta/llama3-8b-instruct
Latest_Tag=1.0
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/nim/meta/${Repository}:${Latest_Tag}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-e $NGC_CLI_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
Note
If you face permission issues, re-try using sudo.
Let’s run the NIM!
NIMs are set to expose port 8000 by default (as specified in the above Docker command). In order to expose this port on the VM and provide public access, go to the Brev console and find your running GPU instance. In the Access tab in your instance details page, scroll down to Using Tunnels to expose Port 8000 in Deployments.
If you need to expose a port publicly, you can use Brev’s tunnel feature through the web console. This creates a public URL for your service, but note that:
The tunnel will be routed through Cloudflare for authentication
You’ll need to access the endpoint through a web browser for the initial authentication redirect
For direct API access without browser authentication, use port forwarding instead
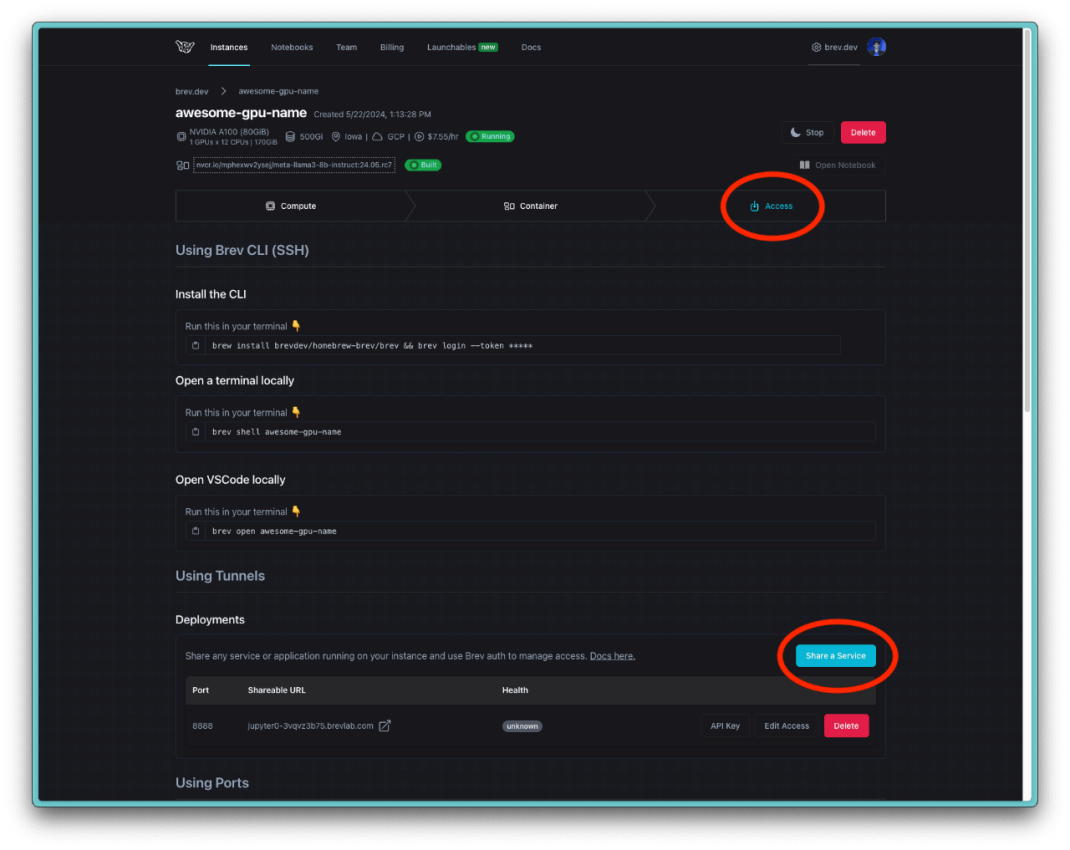
Click on the URL to copy the link to your clipboard - this URL is your <brev-tunnel-link>.
Run the following command to prompt Llama3-8b-instruct to generate a response to "Once upon a time":
curl -X 'POST' \
'<brev-tunnel-link>/v1/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta-llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 225
}'
You can replace /vi/completions with /v1/chat/completions, /v1/models, /v1/health/ready, or /v1/metrics!
You just deployed your first NIM! 🥳🤙🦙
Working with NIMs gives you a quick way to get production-grade performance out-of-the-box for your GenAI/LLM apps. 🥳🤙🦙