Reference Build
CDP & AI Ready Systems
The following table outlines two recommended server configurations for deploying CDP Private Cloud Base for accelerated Apache Spark workloads. A cluster of “CDP Ready” servers is perfect for dedicated Apache Spark deployments, and a cluster of “AI Ready” servers is ideal for multi-purpose deployments that will include both Spark and other accelerated workloads (e.g., machine learning). NVIDIA and Cloudera recommend CDP Private Cloud Base users initially add (4) or (8) of these servers to begin experiencing the benefit of GPUs. Some server vendors have these bundles pre-configured and ready to buy; contact Cloudera or NVIDIA sales for details.
Parameter |
CDP-Ready Configuration |
AI-Ready Configuration |
|---|---|---|
GPU |
A30 |
A100 40GB |
GPU Configuration |
2x GPUs per server |
1 GPU ser server (option: 2x GPUs) |
CPU |
AMD EPYC (Rome or Milan) Intel Xeon (Skylake, Cascade Lake, Ice Lake) |
|
CPU Sockets |
2 per server |
|
CPU Speeds |
2.1 GHz minimum base clock |
|
CPU Cores |
20 physical cores minimum per socket |
|
System Memory |
512 GB |
|
Network Adapter (NIC) |
2 Mellanox ConnectX-6, ConnectX-6 DX, or BlueField-2 |
|
Storage |
40TB of SSDs or NVMe devices for HDFS |
|
These are recommended configurations. Additional hardware configurations are available.
Right-size Server Configurations
Cloudera recommends deploying three or four machine types into production:
Master Node Runs the Hadoop master daemons: NameNode, Standby NameNode, YARN Resource Manager and History Server, the HBase Master daemon, Sentry server, and the Impala StateStore Server and Catalog Server. Master nodes are also the location where Zookeeper and JournalNodes are installed. The daemons can often share single pool of servers. Depending on the cluster size, the roles can instead each be run on a dedicated server. Kudu Master Servers should also be deployed on master nodes.
Worker Node Runs the HDFS DataNode, YARN NodeManager, HBase RegionServer, Impala impalad, Search worker daemons and Kudu Tablet Servers. GPUs are installed in worker nodes.
Utility Node Runs Cloudera Manager and the Cloudera Management Services. It can also host a MySQL (or another supported) database instance, which is used by Cloudera Manager, Hive, Sentry and other Hadoop-related projects.
Edge Node Contains all client-facing configurations and services, including gateway configurations for HDFS, YARN, Impala, Hive, and HBase. The edge node is also a good place for Hue, Oozie, HiveServer2, and Impala HAProxy. HiveServer2 and Impala HAProxy serve as a gateway to external applications such as Business Intelligence (BI) tools
Deployment Topology
The graphic below depicts a cluster deployed across several racks (Rack 1, Rack 2, … Rack n)
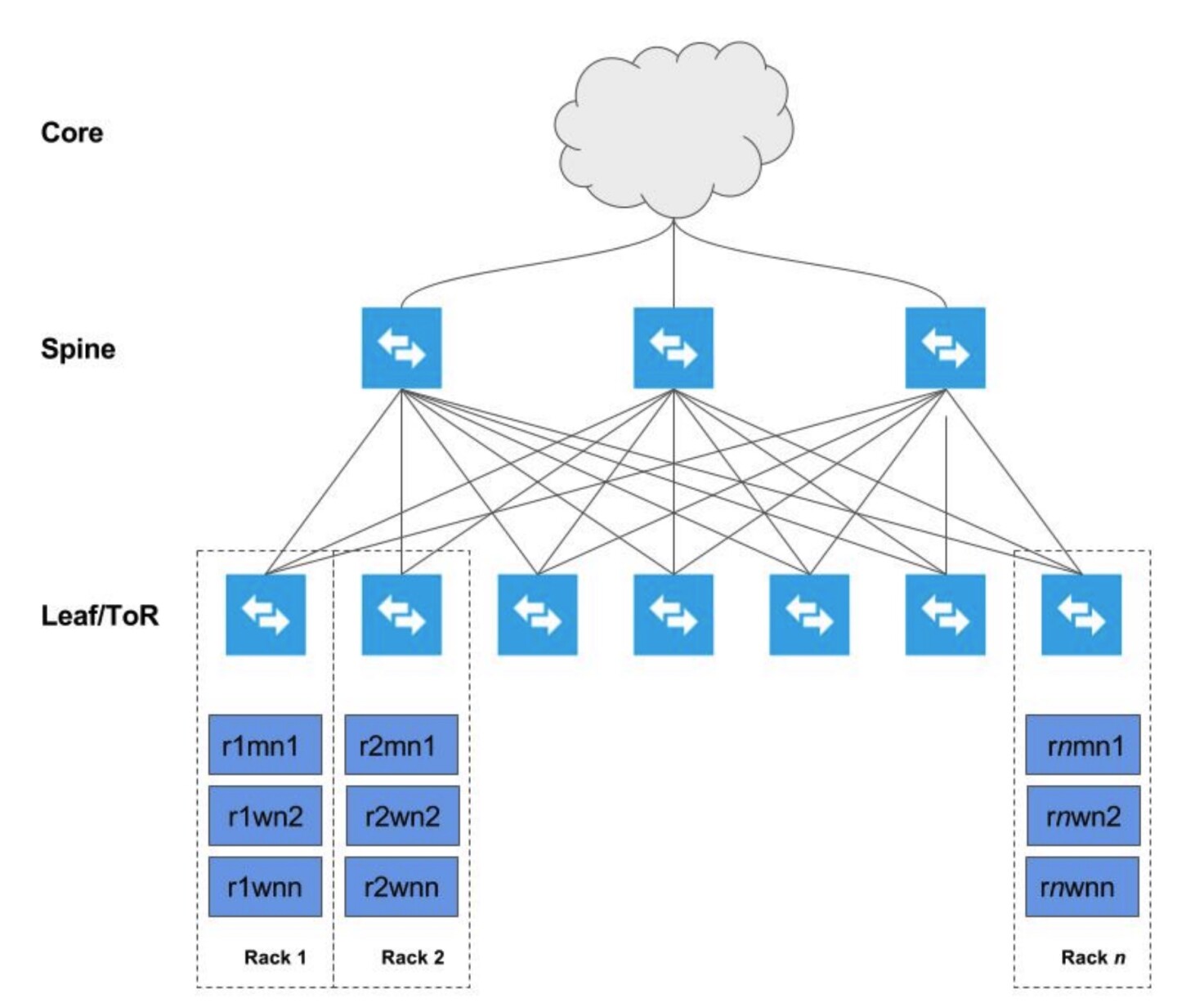
Each host is networked to two top-of-rack (TOR) switches which are in turn connected to a collection of spine switches which are then connected to the enterprise network. This deployment model allows each host maximum throughput, minimize of latency, while encouraging scalability.
Network Topology Considerations
The preferred network topology is spine-leaf with as close to 1:1 over subscription between leaf and spine switches, ideally aiming for no over subscription. This is so we can ensure full line-rate between any combination of storage and compute nodes. Since this architecture calls for disaggregation of compute and storage, the network design must be more aggressive in order to ensure best performance. GPUs worker nodes can be added to the network topology with the addition of new servers in racks with 100Gb+ TOR switching infrastructure
There are two aspects to the minimum network throughput required, which will also determine the compute to storage nodes ratio.
The network throughput and IO throughput capabilities of the storage backend.
The network throughput and network over subscription between compute and storage tiers (NS).
HDFS 1
Hadoop Distributed File system (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject.
NameNode and DataNodes
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
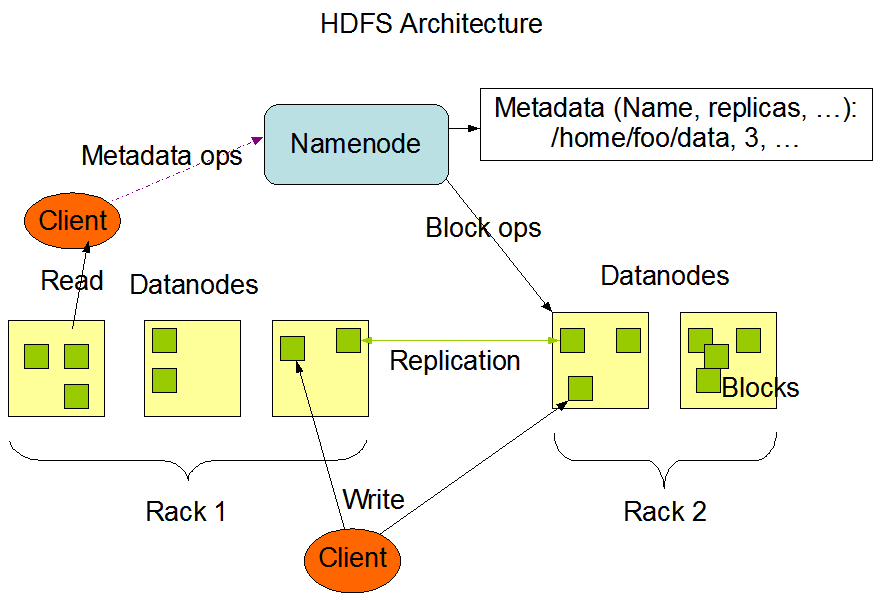
The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linux operating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
The existence of a single NameNode in a cluster greatly simplifies the architecture of the system. The NameNode is the arbitrator and repository for all HDFS metadata. The system is designed in such a way that user data never flows through the NameNode.
Data Replication
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time.
The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.

Disaggregated Storage 2
Disaggregated storage is a form of scale-out storage, built with some number of storage devices that function as a logical pool of storage that can be allocated to any server on the network over a very high performance network fabric. Disaggregated storage solves the limitations of storage area networks or direct-attached storage. Disaggregated storage is dynamically reconfigurable and optimally reconfigures physical resources to maximize performance and limit latency.[8] Disaggregated storage provides the performance of local storage with the flexibility of storage area networks.
Storage area networks (SAN)
A storage area network (SAN) or storage network is a computer network which provides access to consolidated, block-level data storage. SANs are primarily used to access data storage devices, such as disk arrays and tape libraries from servers so that the devices appear to the operating system as direct-attached storage. A SAN typically is a dedicated network of storage devices not accessible through the local area network (LAN).
Network-attached storage (NAS)
A NAS unit is a computer connected to a network that provides only file-based data storage services to other devices on the network. Although it may technically be possible to run other software on a NAS unit, it is usually not designed to be a general-purpose server. For example, NAS units usually do not have a keyboard or display, and are controlled and configured over the network, often using a browser.
A full-featured operating system is not needed on a NAS device, so often a stripped-down operating system is used. For example, FreeNAS or NAS4Free, both open source NAS solutions designed for commodity PC hardware, are implemented as a stripped-down version of FreeBSD.
NAS systems contain one or more hard disk drives, often arranged into logical, redundant storage containers or RAID.
NAS uses file-based protocols such as NFS (popular on UNIX systems), SMB (Server Message Block) (used with MS Windows systems), AFP (used with Apple Macintosh computers), or NCP (used with OES and Novell NetWare). NAS units rarely limit clients to a single protocol.
Object storage (Private Cloud)
Object storage (also known as object-based storage) is a computer data storage architecture that manages data as objects, as opposed to other storage architectures like file systems which manages data as a file hierarchy, and block storage which manages data as blocks within sectors and tracks. Each object typically includes the data itself, a variable amount of metadata, and a globally unique identifier. Object storage can be implemented at multiple levels, including the device level (object-storage device), the system level, and the interface level. In each case, object storage seeks to enable capabilities not addressed by other storage architectures, like interfaces that are directly programmable by the application, a namespace that can span multiple instances of physical hardware, and data-management functions like data replication and data distribution at object-level granularity.
Predicting Customer Churn
What is Churn?
Predicting customer churn is a common data science workflow in many enterprises. Customer churn is the percentage of customers that stopped using your company’s product or service during a certain time frame. It’s important because it costs more to acquire new customers than it does to retain existing customers.
Example of Churn in Telecoms
This benchmarks uses a synthetic dataset of a representative telco company’s customer data which contains 70M account level records including gender, monthly charges, departure date, and much more. This end-to-end example walks through analytic processing and ETL of raw data, integrating data engineering pipelines with machine learning, and continuing all the way to deploying the model in production.
Value of Predicting Churn
Predicting churn increases customer retention. A 5% reduction in churn translates to 25% increase in profit with less spent acquiring new customers.
Ebook - https://www.nvidia.com/en-us/ai-data-science/resources/churn-prediction-blueprint/
Demo - Predicting Customer Churn
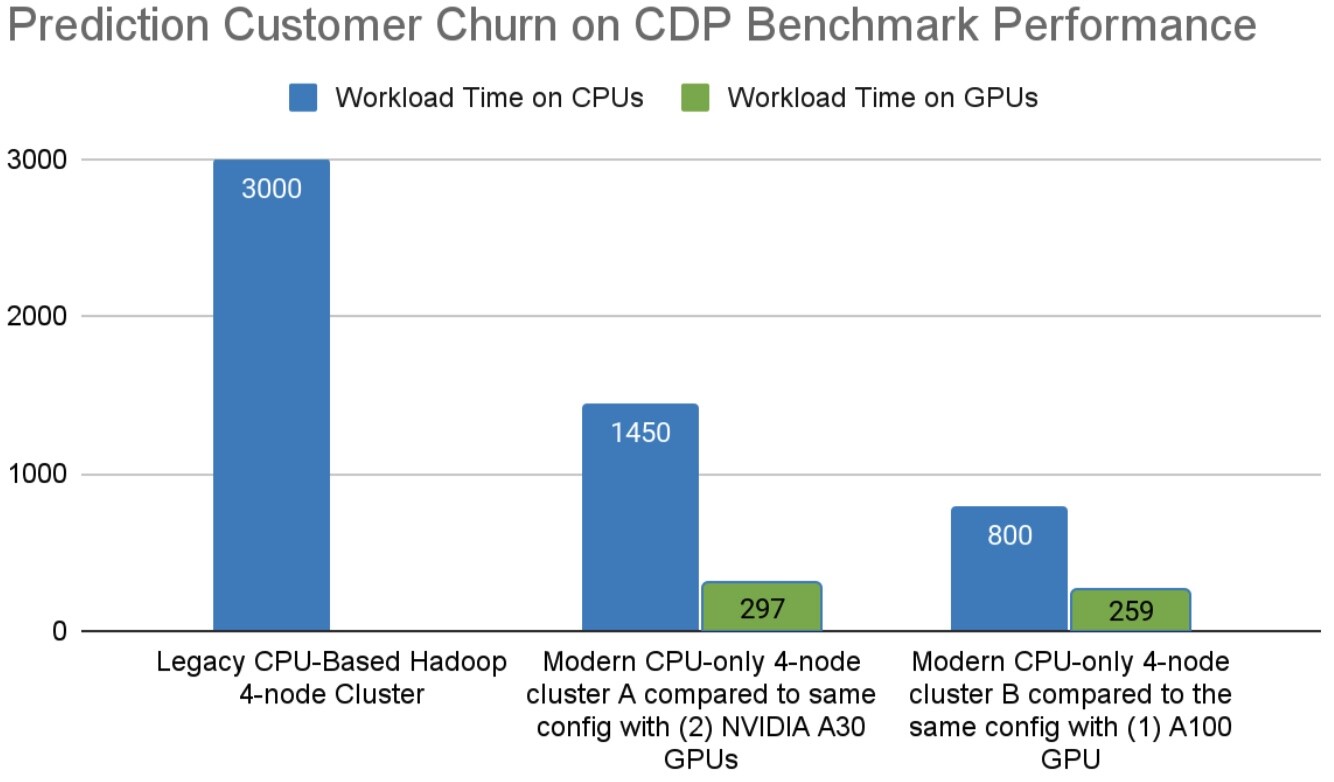
Download the Telco Churn Augmentation Benchmark
Benchmark |
Platform |
Speedup |
Cost Relative |
|---|---|---|---|
Data Preparation / Analytics (CPU vs GPU) |
Spark Batch Job / Cloudera Data Platform on NVIDIA Certified EGX Servers |
4.3x |
3.2x |
Performance results are subject to change and are improving regularly as joint development of this solution continues to expand. Speedup is measured by comparing the same workload tested on servers with and without GPUs, and Cost Relative speedup accounts for the incremental cost of including the GPUs in the server. The results above were obtained with 8x NVIDIA Certified EGX Dell r7525 Severs, 1x A100 GPU, 1x CX-6 NIC, 100GbE with RoCE
- <a class="fn-backref" href="#id1" target="_self">1</a>
The HDFS content was sourced from http://hadoop.apache.org
- <a class="fn-backref" href="#id2" target="_self">2</a>
The Dissagregated storage content was source from http://en.wikipedia.org