Getting Started#
In this section, we show how to implement a sparse matrix-matrix multiplication using cuSPARSELt. We first introduce an overview of the workflow by showing the main steps to set up the computation. Then, we describe how to install the library and how to compile it. Lastly, we present a step by step code example with additional comments.
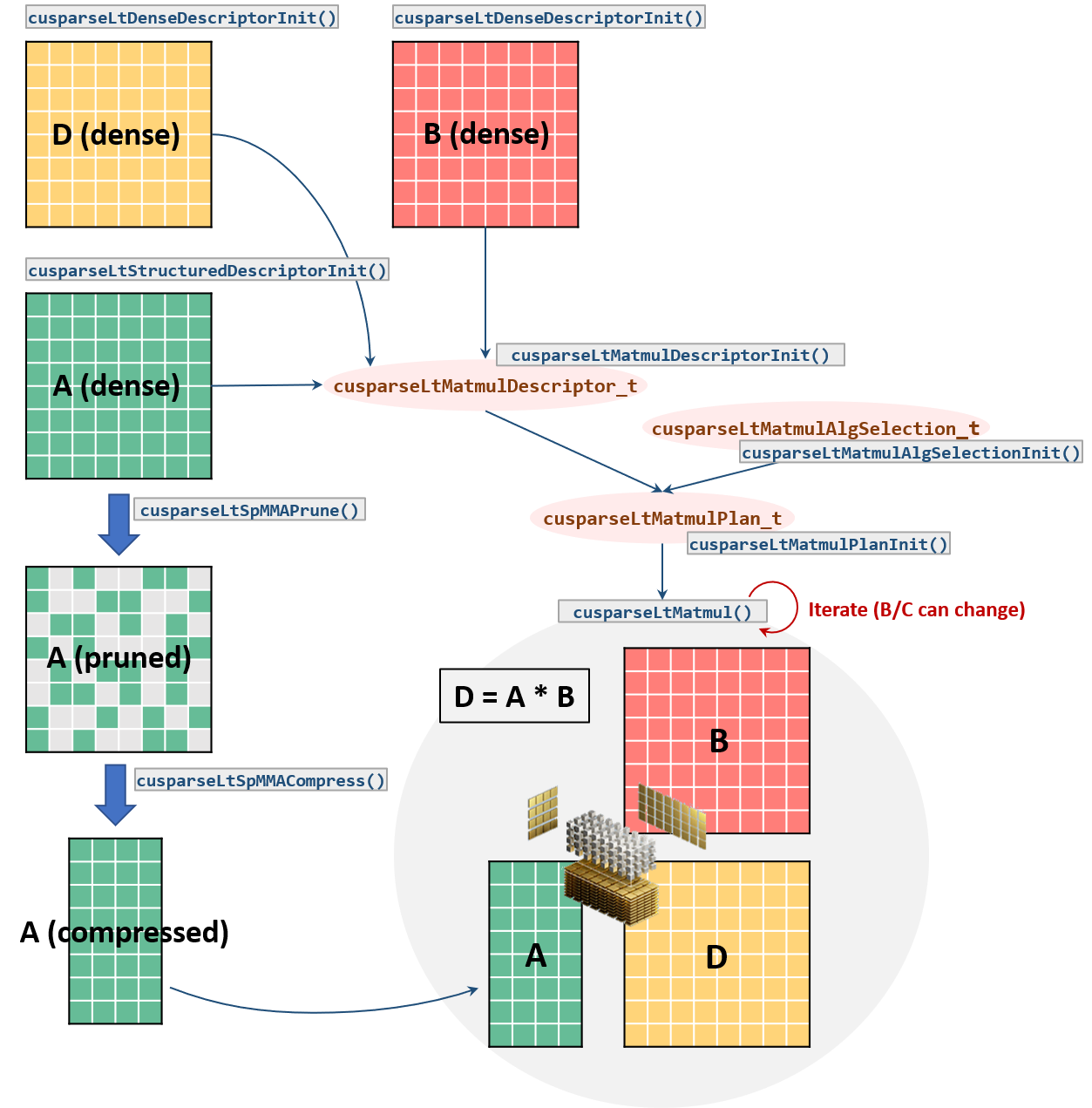
cuSPARSELt Workflow#
A. Problem definition: Specify matrices shapes, data types, operations, etc.B. User preferences/constraints: User algorithm selection or limit search space of viable implementations (candidates)C. Plan: Gather descriptors for the execution and “find” the best implementation if neededD. Execution: Perform the actual computation
More in detail, the common workflow consists in the following steps:
1. Initialize the library handle:cusparseLtInit().2. Specify the input/output matrix characteristics:cusparseLtDenseDescriptorInit(),cusparseLtStructuredDescriptorInit().3. Initialize the matrix multiplication descriptor and its properties (e.g. operations, compute type, etc.):cusparseLtMatmulDescriptorInit().4. Initialize the algorithm selection descriptor:cusparseLtMatmulAlgSelectionInit().5. Initialize the matrix multiplication plan:cusparseLtMatmulPlanInit().6. Prune theAmatrix:cusparseLtSpMMAPrune(). This step is not needed if the user provides a customized matrix pruning.7. Compress the pruned matrix:cusparseLtSpMMACompress().8. Compute the required size of workspace:cusparseLtMatmulGetWorkspace. Allocate a device buffer of this size.9. Execute the matrix multiplication:cusparseLtMatmul(). This step can be repeated multiple times with different input values.10. Destroy the matrix descriptors, matrix multiplication plan and the library handle:cusparseLtMatDescriptorDestroy(),cusparseLtMatmulPlanDestroy()cusparseLtDestroy().
Installation and Compilation#
Download the cuSPARSELt package from developer.nvidia.com/cusparselt/downloads
Prerequisites#
Hardware requirements#
GPU with minimum supported Compute Capability 8.0
See Compute Capability list for NVIDIA GPUs here: https://developer.nvidia.com/cuda-gpus
For detailed list of functionality support based on GPU Compute Capability see Key Features.
Software requirements#
CUDA 12.9 toolkit or newer and CUDA compatible driver (see CUDA Driver Release Notes).
Linux#
Assuming cuSPARSELt has been extracted in CUSPARSELT_DIR, we update the library path accordingly:
export LD_LIBRARY_PATH=${CUSPARSELT_DIR}/lib64:${LD_LIBRARY_PATH}
To compile the sample code we will discuss below (matmul_example.cpp),
nvcc matmul_example.cpp -I {CUSPARSELT_PATH}/include/ -l cusparse -l cusparseLt -L ${CUSPARSELT_PATH}/lib/
Note that the previous command links cusparseLt as a shared library. Linking the code with the static version of the library requires additional flags:
nvcc matmul_example.cpp -I${CUSPARSELT_DIR}/include \
-Xlinker=${CUSPARSELT_DIR}/lib64/libcusparseLt_static.a \
-o matmul_static -ldl -lcuda
Windows#
Assuming cuSPARSELt has been extracted in CUSPARSELT_DIR, we update the library path accordingly:
setx PATH "%CUSPARSELT_DIR%\lib:%PATH%"
To compile the sample code we will discuss below (matmul_example.cpp),
nvcc.exe matmul_example.cpp -I "%CUSPARSELT_DIR%\include" -lcusparseLt -lcuda -o matmul.exe
Note that the previous command links cusparseLt as a shared library. Linking the code with the static version of the library requires additional flags:
nvcc.exe matmul_example.cpp -I %CUSPARSELT_DIR%\include \
-Xlinker=/WHOLEARCHIVE:"%CUSPARSELT_DIR%\lib\cusparseLt_static.lib" \
-Xlinker=/FORCE -lcuda -o matmul.exe
Code Example#
#include <cusparseLt.h> // cusparseLt header
// Device pointers and coefficient definitions
float alpha = 1.0f;
float beta = 0.0f;
__half* dA = ...
__half* dB = ...
__half* dC = ...
//--------------------------------------------------------------------------
// cusparseLt data structures and handle initialization
cusparseLtHandle_t handle;
cusparseLtMatDescriptor_t matA, matB, matC;
cusparseLtMatmulDescriptor_t matmul;
cusparseLtMatmulAlgSelection_t alg_sel;
cusparseLtMatmulPlan_t plan;
cudaStream_t stream = nullptr;
cusparseLtInit(&handle);
//--------------------------------------------------------------------------
// matrix descriptor initialization
cusparseLtStructuredDescriptorInit(&handle, &matA, num_A_rows, num_A_cols,
lda, alignment, type, order,
CUSPARSELT_SPARSITY_50_PERCENT);
cusparseLtDenseDescriptorInit(&handle, &matB, num_B_rows, num_B_cols, ldb,
alignment, type, order);
cusparseLtDenseDescriptorInit(&handle, &matC, num_C_rows, num_C_cols, ldc,
alignment, type, order);
//--------------------------------------------------------------------------
// matmul, algorithm selection, and plan initialization
cusparseLtMatmulDescriptorInit(&handle, &matmul, opA, opB, &matA, &matB,
&matC, &matC, compute_type);
cusparseLtMatmulAlgSelectionInit(&handle, &alg_sel, &matmul,
CUSPARSELT_MATMUL_ALG_DEFAULT);
cusparseLtMatmulPlanInit(&handle, &plan, &matmul, &alg_sel);
//--------------------------------------------------------------------------
// Prune the A matrix (in-place) and check the correctness
cusparseLtSpMMAPrune(&handle, &matmul, dA, dA, CUSPARSELT_PRUNE_SPMMA_TILE,
stream);
int *d_valid;
cudaMalloc((void**) &d_valid, sizeof(d_valid));
cusparseLtSpMMAPruneCheck(&handle, &matmul, dA, &d_valid, stream);
int is_valid;
cudaMemcpyAsync(&is_valid, d_valid, sizeof(d_valid), cudaMemcpyDeviceToHost,
stream);
cudaStreamSynchronize(stream);
if (is_valid != 0) {
std::printf("!!!! The matrix has been pruned in a wrong way. "
"cusparseLtMatmul will not provided correct results\n");
return EXIT_FAILURE;
}
//--------------------------------------------------------------------------
// Matrix A compression
size_t compressed_size;
cusparseLtSpMMACompressedSize(&handle, &plan, &compressed_size);
cudaMalloc((void**) &dA_compressed, compressed_size);
cusparseLtSpMMACompress(&handle, &plan, dA, dA_compressed, stream);
//--------------------------------------------------------------------------
// Allocate workspace
size_t workspace_size;
void* d_workspace = nullptr;
cusparseLtMatmulGetWorkspace(&handle, &plan, &workspace_size);
cudaMalloc((void**) &d_workspace, workspace_size);
//--------------------------------------------------------------------------
// Perform the matrix multiplication
int num_streams = 0;
cudaStream_t* streams = nullptr;
cusparseLtMatmul(&handle, &plan, &alpha, dA_compressed, dB, &beta, dC, dD,
d_workspace, streams, num_streams);
//--------------------------------------------------------------------------
// Destroy descriptors, plan and handle
cusparseLtMatDescriptorDestroy(&matA);
cusparseLtMatDescriptorDestroy(&matB);
cusparseLtMatDescriptorDestroy(&matC);
cusparseLtMatmulPlanDestroy(&plan);
cusparseLtMatmulAlgSelectionDestroy(&alg_sel);
cusparseLtDestroy(&handle);