Abstract
This is the API Reference documentation for the NVIDIA cuDNN version 8.9.0 library. This API Reference lists the datatyes and functions per library. Specifically, this reference consists of a cuDNN datatype reference section that describes the types of enums and a cuDNN API reference section that describes all routines in the cuDNN library API. The cuDNN API is a context-based API that allows for easy multithreading and (optional) interoperability with CUDA streams.
1. Introduction
NVIDIA® CUDA® Deep Neural Network (cuDNN) library offers a context-based API that allows for easy multithreading and (optional) interoperability with CUDA streams. This API Reference lists the datatyes and functions per library. Specifically, this reference consists of a cuDNN datatype reference section that describes the types of enums and a cuDNN API reference section that describes all routines in the cuDNN library API.
- cudnn_ops_infer
- This entity contains the routines related to cuDNN context creation and destruction, tensor descriptor management, tensor utility routines, and the inference portion of common machine learning algorithms such as batch normalization, softmax, dropout, and so on.
- cudnn_ops_train
- This entity contains common training routines and algorithms, such as batch normalization, softmax, dropout, and so on. The cudnn_ops_train library depends on cudnn_ops_infer.
- cudnn_cnn_infer
- This entity contains all routines related to convolutional neural networks needed at inference time. The cudnn_cnn_infer library depends on cudnn_ops_infer.
- cudnn_cnn_train
- This entity contains all routines related to convolutional neural networks needed during training time. The cudnn_cnn_train library depends on cudnn_ops_infer, cudnn_ops_train, and cudnn_cnn_infer.
- cudnn_adv_infer
- This entity contains all other features and algorithms. This includes RNNs, CTC loss, and multi-head attention. The cudnn_adv_infer library depends on cudnn_ops_infer.
- cudnn_adv_train
- This entity contains all the training counterparts of cudnn_adv_infer. The cudnn_adv_train library depends on cudnn_ops_infer, cudnn_ops_train, and cudnn_adv_infer.
- cudnnBackend*
- Introduced in cuDNN version 8.x, this entity contains a list of valid cuDNN backend descriptor types, a list of valid attributes, a subset of valid attribute values, and a full description of each backend descriptor type and their attributes.
- cudnn
- This is an optional shim layer between the application layer and the cuDNN code. This layer opportunistically opens the correct library for the API at runtime.
2. Added, Deprecated, and Removed API Functions
2.1. API Changes for cuDNN 8.7.0
| Backend descriptor types |
|---|
| cudnnRngDistribution_t |
| CUDNN_BACKEND_OPERATION_RNG_DESCRIPTOR |
| CUDNN_BACKEND_RNG_DESCRIPTOR |
2.2. API Changes for cuDNN 8.5.0
| Backend descriptor types |
|---|
| cudnnBackendNormFwdPhase_t |
| cudnnBackendNormMode_t |
| CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR |
| CUDNN_BACKEND_OPERATION_NORM_BACKWARD_DESCRIPTOR |
| CUDNN_BACKEND_OPERATION_NORM_FORWARD_DESCRIPTOR |
| CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR |
| cudnnFraction_t |
| cudnnSignalMode_t |
2.3. API Changes for cuDNN 8.4.0
| Backend descriptor types |
|---|
| cudnnBackendBehaviorNote_t |
| CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR |
| CUDNN_BACKEND_POINTWISE_DESCRIPTOR |
| CUDNN_BACKEND_REDUCTION_DESCRIPTOR |
| cudnnBackendTensorReordering_t |
| cudnnBnFinalizeStatsMode_t |
| cudnnPaddingMode_t |
| cudnnResampleMode_t |
2.4. API Changes for cuDNN 8.3.0
| Backend descriptor types |
|---|
| CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR |
| CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR |
| CUDNN_BACKEND_RESAMPLE_DESCRIPTOR |
2.5. API Changes for cuDNN 8.2.0
| New functions |
|---|
| cudnnGetActivationDescriptorSwishBeta() |
| cudnnSetActivationDescriptorSwishBeta() |
2.6. API Changes for cuDNN 8.1.0
| Backend descriptor types |
|---|
| CUDNN_BACKEND_MATMUL_DESCRIPTOR |
| CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR |
2.7. API Changes for cuDNN 8.0.3
2.8. API Changes for cuDNN 8.0.2
| New functions and data types |
|---|
| cudnnRNNBackwardData_v8() |
| cudnnRNNBackwardWeights_v8() |
2.9. API Changes for cuDNN 8.0.0 Preview
For our deprecation policy, refer to the Backward Compatibility And Deprecation Policy.
| Deprecated functions and data types | Replaced with |
|---|---|
| cudnnCopyAlgorithmDescriptor() | |
| cudnnCreateAlgorithmDescriptor() | |
| cudnnCreatePersistentRNNPlan() | cudnnBuildRNNDynamic() |
| cudnnDestroyAlgorithmDescriptor() | |
| cudnnDestroyPersistentRNNPlan() | |
| cudnnFindRNNBackwardDataAlgorithmEx() | |
| cudnnFindRNNBackwardWeightsAlgorithmEx() | |
| cudnnFindRNNForwardInferenceAlgorithmEx() | |
| cudnnFindRNNForwardTrainingAlgorithmEx() | |
| cudnnGetAlgorithmDescriptor() | |
| cudnnGetAlgorithmPerformance() | |
| cudnnGetAlgorithmSpaceSize() | |
| cudnnGetRNNBackwardDataAlgorithmMaxCount() | |
| cudnnGetRNNBackwardWeightsAlgorithmMaxCount() | |
|
cudnnGetRNNDescriptor_v8() |
| cudnnGetRNNForwardInferenceAlgorithmMaxCount() | |
| cudnnGetRNNForwardTrainingAlgorithmMaxCount() | |
|
cudnnGetRNNWeightParams() |
| cudnnGetRNNParamsSize() | cudnnGetRNNWeightSpaceSize() |
|
cudnnGetRNNTempSpaceSizes() |
| cudnnPersistentRNNPlan_t | |
| cudnnRestoreAlgorithm() | |
|
cudnnRNNBackwardData_v8() |
|
cudnnRNNBackwardWeights_v8() |
|
cudnnRNNForward() |
| cudnnRNNGetClip() | cudnnRNNGetClip_v8() |
| cudnnRNNSetClip() | cudnnRNNSetClip_v8() |
| cudnnSaveAlgorithm() | |
| cudnnSetAlgorithmDescriptor() | |
| cudnnSetAlgorithmPerformance() | |
| cudnnSetPersistentRNNPlan() | |
| cudnnSetRNNAlgorithmDescriptor() | |
|
cudnnSetRNNDescriptor_v8() |
| Removed functions and data types |
|---|
| cudnnConvolutionBwdDataPreference_t |
| cudnnConvolutionBwdFilterPreference_t |
| cudnnConvolutionFwdPreference_t |
| cudnnGetConvolutionBackwardDataAlgorithm() |
| cudnnGetConvolutionBackwardFilterAlgorithm() |
| cudnnGetConvolutionForwardAlgorithm() |
| cudnnGetRNNDescriptor() |
| cudnnSetRNNDescriptor() |
3. cudnn_ops_infer.so Library
3.1. Data Type References
3.1.1. Pointer To Opaque Struct Types
3.1.1.1. cudnnActivationDescriptor_t
3.1.1.2. cudnnCTCLossDescriptor_t
3.1.1.3. cudnnDropoutDescriptor_t
3.1.1.4. cudnnFilterDescriptor_t
3.1.1.5. cudnnHandle_t
3.1.1.6. cudnnLRNDescriptor_t
3.1.1.7. cudnnOpTensorDescriptor_t
3.1.1.8. cudnnPoolingDescriptor_t
3.1.1.9. cudnnReduceTensorDescriptor_t
3.1.1.10. cudnnSpatialTransformerDescriptor_t
3.1.1.11. cudnnTensorDescriptor_t
3.1.1.12. cudnnTensorTransformDescriptor_t
3.1.2. Enumeration Types
3.1.2.1. cudnnActivationMode_t
Values
- Selects the sigmoid function.
- Selects the rectified linear function.
- Selects the hyperbolic tangent function.
- Selects the clipped rectified linear function.
- Selects the exponential linear function.
- Selects the identity function, intended for bypassing the activation step in cudnnConvolutionBiasActivationForward(). (The cudnnConvolutionBiasActivationForward() function must use CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM.) Does not work with cudnnActivationForward() or cudnnActivationBackward().
- Selects the swish function.
3.1.2.3. cudnnBatchNormMode_t
Values
- Normalization is performed per-activation. This mode is intended to be used after the non-convolutional network layers. In this mode, the tensor dimensions of bnBias and bnScale and the parameters used in the cudnnBatchNormalization* functions are 1xCxHxW.
- Normalization is performed over N+spatial dimensions. This mode is intended for use after convolutional layers (where spatial invariance is desired). In this mode the bnBias and bnScale tensor dimensions are 1xCx1x1.
-
This mode is similar to CUDNN_BATCHNORM_SPATIAL but it can be faster for some tasks.
An optimized path may be selected for CUDNN_DATA_FLOAT and CUDNN_DATA_HALF types, compute capability 6.0 or higher for the following two batch normalization API calls: cudnnBatchNormalizationForwardTraining() and cudnnBatchNormalizationBackward(). In the case of cudnnBatchNormalizationBackward(), the savedMean and savedInvVariance arguments should not be NULL.
The rest of this section applies to NCHW mode only: This mode may use a scaled atomic integer reduction that is deterministic but imposes more restrictions on the input data range. When a numerical overflow occurs, the algorithm may produce NaN-s or Inf-s (infinity) in output buffers.
When Inf-s/NaN-s are present in the input data, the output in this mode is the same as from a pure floating-point implementation.
For finite but very large input values, the algorithm may encounter overflows more frequently due to a lower dynamic range and emit Inf-s/NaN-s while CUDNN_BATCHNORM_SPATIAL will produce finite results. The user can invoke cudnnQueryRuntimeError() to check if a numerical overflow occurred in this mode.
3.1.2.4. cudnnBatchNormOps_t
3.1.2.6. cudnnDataType_t
Values
- The data is a 32-bit single-precision floating-point (float).
- The data is a 64-bit double-precision floating-point (double).
- The data is a 16-bit floating-point.
- The data is an 8-bit signed integer.
- The data is a 32-bit signed integer.
- The data is 32-bit elements each composed of 4 8-bit signed integers. This data type is only supported with the tensor format CUDNN_TENSOR_NCHW_VECT_C.
- The data is an 8-bit unsigned integer.
- The data is 32-bit elements each composed of 4 8-bit unsigned integers. This data type is only supported with the tensor format CUDNN_TENSOR_NCHW_VECT_C.
- The data is 32-element vectors, each element being an 8-bit signed integer. This data type is only supported with the tensor format CUDNN_TENSOR_NCHW_VECT_C. Moreover, this data type can only be used with algo 1, meaning, CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM. For more information, refer to cudnnConvolutionFwdAlgo_t.
- The data is a 16-bit quantity, with 7 mantissa bits, 8 exponent bits, and 1 sign bit.
- The data is a 64-bit signed integer.
-
The data is a boolean (bool).
Note that for type CUDNN_TYPE_BOOLEAN, elements are expected to be "packed": that is, one byte contains 8 elements of type CUDNN_TYPE_BOOLEAN. Further, within each byte, elements are indexed from the least significant bit to the most significant bit. For example, a 1 dimensional tensor of 8 elements containing 01001111 has value 1 for elements 0 through 3, 0 for elements 4 and 5, 1 for element 6 and 0 for element 7.
Tensors with more than 8 elements simply use more bytes, where the order is also from least significant to most significant byte. Note, CUDA is little-endian, meaning that the least significant byte has the lower memory address address. For example, in the case of 16 elements, 01001111 11111100 has value 1 for elements 0 through 3, 0 for elements 4 and 5, 1 for element 6 and 0 for element 7, value 0 for elements 8 and 9, 1 for elements 10 through 15.
- The data is an 8-bit quantity, with 3 mantissa bits, 4 exponent bits, and 1 sign bit.
- The data is an 8-bit quantity, with 2 mantissa bits, 5 exponent bits, and 1 sign bit.
- The data type is a higher throughput but lower precision compute type (compared to CUDNN_DATA_FLOAT) used for FP8 tensor core operations
3.1.2.7. cudnnDeterminism_t
3.1.2.8. cudnnDivNormMode_t
Values
- The means tensor data pointer is expected to contain means or other
kernel convolution values precomputed by the user. The means pointer can
also be NULL, in that case, it's considered to be
filled with zeroes. This is equivalent to spatial LRN.
Note: In the backward pass, the means are treated as independent inputs and the gradient over means is computed independently. In this mode, to yield a net gradient over the entire LCN computational graph, the destDiffMeans result should be backpropagated through the user's means layer (which can be implemented using average pooling) and added to the destDiffData tensor produced by cudnnDivisiveNormalizationBackward().
3.1.2.9. cudnnErrQueryMode_t
Values
- Read the error storage location regardless of the kernel completion status.
- Report if all tasks in the user stream of the cuDNN handle were completed. If that is the case, report the remote kernel error code.
- Wait for all tasks to complete in the user stream before reporting the remote kernel error code.
3.1.2.10. cudnnFoldingDirection_t
3.1.2.11. cudnnIndicesType_t
3.1.2.12. cudnnLRNMode_t
3.1.2.13. cudnnMathType_t
Values
- Tensor Core operations are not used on pre-NVIDIA A100 GPU devices. On A100 GPU architecture devices, Tensor Core TF32 operation is permitted.
- The use of Tensor Core operations is permitted but will not actively perform datatype down conversion on tensors in order to utilize Tensor Cores.
- The use of Tensor Core operations is permitted and will actively perform datatype down conversion on tensors in order to utilize Tensor Cores.
- Restricted to only kernels that use FMA instructions.
On pre-NVIDIA A100 GPU devices, CUDNN_DEFAULT_MATH and CUDNN_FMA_MATH have the same behavior: Tensor Core kernels will not be selected. With NVIDIA Ampere architecture and CUDA toolkit 11, CUDNN_DEFAULT_MATH permits TF32 Tensor Core operation and CUDNN_FMA_MATH does not. The TF32 behavior for CUDNN_DEFAULT_MATH and the other Tensor Core math types can be explicitly disabled by the environment variable NVIDIA_TF32_OVERRIDE=0.
3.1.2.14. cudnnNanPropagation_t
3.1.2.15. cudnnNormAlgo_t
Values
- Standard normalization is performed.
-
This mode is similar to CUDNN_NORM_ALGO_STANDARD, however it only supports CUDNN_NORM_PER_CHANNEL and can be faster for some tasks.
An optimized path may be selected for CUDNN_DATA_FLOAT and CUDNN_DATA_HALF types, compute capability 6.0 or higher for the following two normalization API calls: cudnnNormalizationForwardTraining() and cudnnNormalizationBackward(). In the case of cudnnNormalizationBackward(), the savedMean and savedInvVariance arguments should not be NULL.
The rest of this section applies to NCHW mode only: This mode may use a scaled atomic integer reduction that is deterministic but imposes more restrictions on the input data range. When a numerical overflow occurs, the algorithm may produce NaN-s or Inf-s (infinity) in output buffers.
When Inf-s/NaN-s are present in the input data, the output in this mode is the same as from a pure floating-point implementation.
For finite but very large input values, the algorithm may encounter overflows more frequently due to a lower dynamic range and emit Inf-s/NaN-s while CUDNN_NORM_ALGO_STANDARD will produce finite results. The user can invoke cudnnQueryRuntimeError() to check if a numerical overflow occurred in this mode.
3.1.2.16. cudnnNormMode_t
Values
- Normalization is performed per-activation. This mode is intended to be used after the non-convolutional network layers. In this mode, the tensor dimensions of normBias and normScale and the parameters used in the cudnnNormalization* functions are 1xCxHxW.
- Normalization is performed per-channel over N+spatial dimensions. This mode is intended for use after convolutional layers (where spatial invariance is desired). In this mode, the normBias and normScale tensor dimensions are 1xCx1x1.
3.1.2.17. cudnnNormOps_t
3.1.2.18. cudnnOpTensorOp_t
Values
- The operation to be performed is addition.
- The operation to be performed is multiplication.
- The operation to be performed is a minimum comparison.
- The operation to be performed is a maximum comparison.
- The operation to be performed is square root, performed on only the A tensor.
- The operation to be performed is negation, performed on only the A tensor.
3.1.2.19. cudnnPoolingMode_t
Values
- The maximum value inside the pooling window is used.
- Values inside the pooling window are averaged. The number of elements used to calculate the average includes spatial locations falling in the padding region.
- Values inside the pooling window are averaged. The number of elements used to calculate the average excludes spatial locations falling in the padding region.
- The maximum value inside the pooling window is used. The algorithm used is deterministic.
3.1.2.20. cudnnReduceTensorIndices_t
3.1.2.21. cudnnReduceTensorOp_t
Values
- The operation to be performed is addition.
- The operation to be performed is multiplication.
- The operation to be performed is a minimum comparison.
- The operation to be performed is a maximum comparison.
- The operation to be performed is a maximum comparison of absolute values.
- The operation to be performed is averaging.
- The operation to be performed is addition of absolute values.
- The operation to be performed is a square root of the sum of squares.
- The operation to be performed is multiplication, not including elements of value zero.
3.1.2.22. cudnnRNNAlgo_t
Values
- Each RNN layer is executed as a sequence of operations. This algorithm is expected to have robust performance across a wide range of network parameters.
-
The recurrent parts of the network are executed using a persistent kernel approach. This method is expected to be fast when the first dimension of the input tensor is small (meaning, a small minibatch).
CUDNN_RNN_ALGO_PERSIST_STATIC is only supported on devices with compute capability >= 6.0.
-
The recurrent parts of the network are executed using a persistent kernel approach. This method is expected to be fast when the first dimension of the input tensor is small (meaning, a small minibatch). When using CUDNN_RNN_ALGO_PERSIST_DYNAMIC persistent kernels are prepared at runtime and are able to optimize using the specific parameters of the network and active GPU. As such, when using CUDNN_RNN_ALGO_PERSIST_DYNAMIC a one-time plan preparation stage must be executed. These plans can then be reused in repeated calls with the same model parameters.
The limits on the maximum number of hidden units supported when using CUDNN_RNN_ALGO_PERSIST_DYNAMIC are significantly higher than the limits when using CUDNN_RNN_ALGO_PERSIST_STATIC, however throughput is likely to significantly reduce when exceeding the maximums supported by CUDNN_RNN_ALGO_PERSIST_STATIC. In this regime, this method will still outperform CUDNN_RNN_ALGO_STANDARD for some cases.
CUDNN_RNN_ALGO_PERSIST_DYNAMIC is only supported on devices with compute capability >= 6.0 on Linux machines.
3.1.2.23. cudnnSamplerType_t
3.1.2.24. cudnnSeverity_t
3.1.2.25. cudnnSoftmaxAlgorithm_t
Values
- This implementation applies the straightforward softmax operation.
- This implementation scales each point of the softmax input domain by its maximum value to avoid potential floating point overflows in the softmax evaluation.
- This entry performs the log softmax operation, avoiding overflows by scaling each point in the input domain as in CUDNN_SOFTMAX_ACCURATE.
3.1.2.26. cudnnSoftmaxMode_t
3.1.2.27. cudnnStatus_t
Values
- The operation was completed successfully.
- The cuDNN library was not initialized properly. This error is usually returned when a call to cudnnCreate() fails or when cudnnCreate() has not been called prior to calling another cuDNN routine. In the former case, it is usually due to an error in the CUDA Runtime API called by cudnnCreate() or by an error in the hardware setup.
-
Resource allocation failed inside the cuDNN library. This is usually caused by an internal cudaMalloc() failure.
To correct, prior to the function call, deallocate previously allocated memory as much as possible.
-
An incorrect value or parameter was passed to the function.
To correct, ensure that all the parameters being passed have valid values.
-
The function requires a feature absent from the current GPU device. Note that cuDNN only supports devices with compute capabilities greater than or equal to 3.0.
To correct, compile and run the application on a device with appropriate compute capability.
-
An access to GPU memory space failed, which is usually caused by a failure to bind a texture.
To correct, prior to the function call, unbind any previously bound textures.
Otherwise, this may indicate an internal error/bug in the library.
-
The GPU program failed to execute. This is usually caused by a failure to launch some cuDNN kernel on the GPU, which can occur for multiple reasons.
To correct, check that the hardware, an appropriate version of the driver, and the cuDNN library are correctly installed.
Otherwise, this may indicate an internal error/bug in the library.
- An internal cuDNN operation failed.
- The functionality requested is not presently supported by cuDNN.
- The functionality requested requires some license and an error was detected when trying to check the current licensing. This error can happen if the license is not present or is expired or if the environment variable NVIDIA_LICENSE_FILE is not set properly.
- A runtime library required by cuDNN cannot be found in the predefined search paths. These libraries are libcuda.so (nvcuda.dll) and libnvrtc.so (nvrtc64_<Major Release Version><Minor Release Version>_0.dll and nvrtc-builtins64_<Major Release Version><Minor Release Version>.dll).
- Some tasks in the user stream are not completed.
- Numerical overflow occurred during the GPU kernel execution.
3.1.2.28. cudnnTensorFormat_t
Values
- This tensor format specifies that the data is laid out in the following order: batch size, feature maps, rows, columns. The strides are implicitly defined in such a way that the data are contiguous in memory with no padding between images, feature maps, rows, and columns; the columns are the inner dimension and the images are the outermost dimension.
- This tensor format specifies that the data is laid out in the following order: batch size, rows, columns, feature maps. The strides are implicitly defined in such a way that the data are contiguous in memory with no padding between images, rows, columns, and feature maps; the feature maps are the inner dimension and the images are the outermost dimension.
-
This tensor format specifies that the data is laid out in the following order: batch size, feature maps, rows, columns. However, each element of the tensor is a vector of multiple feature maps. The length of the vector is carried by the data type of the tensor. The strides are implicitly defined in such a way that the data are contiguous in memory with no padding between images, feature maps, rows, and columns; the columns are the inner dimension and the images are the outermost dimension. This format is only supported with tensor data types CUDNN_DATA_INT8x4, CUDNN_DATA_INT8x32, and CUDNN_DATA_UINT8x4.
The CUDNN_TENSOR_NCHW_VECT_C can also be interpreted in the following way: The NCHW INT8x32 format is really N x (C/32) x H x W x 32 (32 Cs for every W), just as the NCHW INT8x4 format is N x (C/4) x H x W x 4 (4 Cs for every W). Hence, the VECT_C name - each W is a vector (4 or 32) of Cs.
3.2. API Functions
3.2.1. cudnnActivationForward()
cudnnStatus_t cudnnActivationForward(
cudnnHandle_t handle,
cudnnActivationDescriptor_t activationDesc,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)In-place operation is allowed for this routine; meaning, xData and yData pointers may be equal. However, this requires xDesc and yDesc descriptors to be identical (particularly, the strides of the input and output must match for an in-place operation to be allowed).
All tensor formats are supported for 4 and 5 dimensions, however, the best performance is obtained when the strides of xDesc and yDesc are equal and HW-packed. For more than 5 dimensions the tensors must have their spatial dimensions packed.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. Activation descriptor. For more information, refer to cudnnActivationDescriptor_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to the previously initialized output tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
Returns
- CUDNN_STATUS_SUCCESS
- The function launched successfully.
- CUDNN_STATUS_NOT_SUPPORTED
- The function does not support the provided configuration.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- The parameter mode has an invalid enumerant value.
- The dimensions n, c, h, and w of the input tensor and output tensor differ.
- The datatype of the input tensor and output tensor differs.
- The strides nStride, cStride, hStride, and wStride of the input tensor and output tensor differ and in-place operation is used (meaning, x and y pointers are equal).
- CUDNN_STATUS_EXECUTION_FAILED
- The function failed to launch on the GPU.
3.2.2. cudnnAddTensor()
cudnnStatus_t cudnnAddTensor(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t aDesc,
const void *A,
const void *beta,
const cudnnTensorDescriptor_t cDesc,
void *C)Only 4D and 5D tensors are supported. Beyond these dimensions, this routine is not supported.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with the prior value in the destination tensor as follows:
dstValue = alpha[0]*srcValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointer to data of the tensor described by the aDesc descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Input/Output. Pointer to data of the tensor described by the cDesc descriptor.
Returns
- The function executed successfully.
- The function does not support the provided configuration.
- The dimensions of the bias tensor refer to an amount of data that is incompatible with the output tensor dimensions or the dataType of the two tensor descriptors are different.
- The function failed to launch on the GPU.
3.2.3. cudnnBatchNormalizationForwardInference()
cudnnStatus_t cudnnBatchNormalizationForwardInference(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
const void *alpha,
const void *beta,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t yDesc,
void *y,
const cudnnTensorDescriptor_t bnScaleBiasMeanVarDesc,
const void *bnScale,
const void *bnBias,
const void *estimatedMean,
const void *estimatedVariance,
double epsilon)Only 4D and 5D tensors are supported.
y = beta*y + alpha *[bnBias + (bnScale * (x-estimatedMean)/sqrt(epsilon + estimatedVariance)]
For the training phase, refer to cudnnBatchNormalizationForwardTraining().
Higher performance can be obtained when HW-packed tensors are used for all of x and dx.
For more information, refer to cudnnDeriveBNTensorDescriptor() for the secondary tensor descriptor generation for the parameters used in this function.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handles to the previously initialized tensor descriptors.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc, for the layer’s x input data.
- Input/Output. Data pointer to GPU memory associated with the tensor descriptor yDesc, for the youtput of the batch normalization layer.
- Inputs. Tensor descriptors and pointers in device memory for the batch normalization scale and bias parameters (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta and scale as gamma).
- Inputs. Mean and variance tensors (these have the same descriptor as the bias and scale). The resultRunningMean and resultRunningVariance, accumulated during the training phase from the cudnnBatchNormalizationForwardTraining() call, should be passed as inputs here.
- Input. Epsilon value used in the batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h.
Supported configurations
This function supports the following combinations of data types for various descriptors.
| Data Type Configurations | xDesc | bnScaleBiasMeanVarDesc | alpha, beta | yDesc |
|---|---|---|---|---|
| INT8_CONFIG | CUDNN_DATA_INT8 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_INT8 |
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the pointers alpha, beta, x, y, bnScale, bnBias, estimatedMean, and estimatedInvVariance is NULL.
- The number of xDesc or yDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported.)
- bnScaleBiasMeanVarDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- epsilon value is less than CUDNN_BN_MIN_EPSILON.
- Dimensions or data types mismatch for xDesc, yDesc.
3.2.5. cudnnCreate()
cudnnStatus_t cudnnCreate(cudnnHandle_t *handle)
The cuDNN library handle is tied to the current CUDA device (context). To use the library on multiple devices, one cuDNN handle needs to be created for each device.
For a given device, multiple cuDNN handles with different configurations (for example, different current CUDA streams) may be created. Because cudnnCreate() allocates some internal resources, the release of those resources by calling cudnnDestroy() will implicitly call cudaDeviceSynchronize(); therefore, the recommended best practice is to call cudnnCreate/cudnnDestroy outside of performance-critical code paths.
For multithreaded applications that use the same device from different threads, the recommended programming model is to create one (or a few, as is convenient) cuDNN handle(s) per thread and use that cuDNN handle for the entire life of the thread.
Parameters
- Output. Pointer to pointer where to store the address to the allocated cuDNN handle. For more information, refer to cudnnHandle_t.
Returns
- Invalid (NULL) input pointer supplied.
- No compatible GPU found, CUDA driver not installed or disabled, CUDA runtime API initialization failed.
- NVIDIA GPU architecture is too old.
- Host memory allocation failed.
- CUDA resource allocation failed.
- cuDNN license validation failed (only when the feature is enabled).
- cuDNN handle was created successfully.
3.2.6. cudnnCreateActivationDescriptor()
cudnnStatus_t cudnnCreateActivationDescriptor(
cudnnActivationDescriptor_t *activationDesc)
3.2.7. cudnnCreateAlgorithmDescriptor()
This function creates an algorithm descriptor object by allocating the memory needed to hold its opaque structure.
cudnnStatus_t cudnnCreateAlgorithmDescriptor(
cudnnAlgorithmDescriptor_t *algoDesc)
3.2.8. cudnnCreateAlgorithmPerformance()
cudnnStatus_t cudnnCreateAlgorithmPerformance(
cudnnAlgorithmPerformance_t *algoPerf,
int numberToCreate)
3.2.9. cudnnCreateDropoutDescriptor()
cudnnStatus_t cudnnCreateDropoutDescriptor(
cudnnDropoutDescriptor_t *dropoutDesc)
3.2.10. cudnnCreateFilterDescriptor()
cudnnStatus_t cudnnCreateFilterDescriptor(
cudnnFilterDescriptor_t *filterDesc)
3.2.11. cudnnCreateLRNDescriptor()
cudnnStatus_t cudnnCreateLRNDescriptor(
cudnnLRNDescriptor_t *poolingDesc)
cudnnCreateOpTensorDescriptor()
cudnnStatus_t cudnnCreateOpTensorDescriptor(
cudnnOpTensorDescriptor_t* opTensorDesc)
3.2.14. cudnnCreateReduceTensorDescriptor()
cudnnStatus_t cudnnCreateReduceTensorDescriptor( cudnnReduceTensorDescriptor_t* reduceTensorDesc)
3.2.15. cudnnCreateSpatialTransformerDescriptor()
cudnnStatus_t cudnnCreateSpatialTransformerDescriptor(
cudnnSpatialTransformerDescriptor_t *stDesc)
3.2.16. cudnnCreateTensorDescriptor()
cudnnStatus_t cudnnCreateTensorDescriptor(
cudnnTensorDescriptor_t *tensorDesc)
3.2.17. cudnnCreateTensorTransformDescriptor()
cudnnStatus_t cudnnCreateTensorTransformDescriptor( cudnnTensorTransformDescriptor_t *transformDesc);
3.2.18. cudnnDeriveBNTensorDescriptor()
cudnnStatus_t cudnnDeriveBNTensorDescriptor(
cudnnTensorDescriptor_t derivedBnDesc,
const cudnnTensorDescriptor_t xDesc,
cudnnBatchNormMode_t mode)Use the tensor descriptor produced by this function as the bnScaleBiasMeanVarDesc parameter for the cudnnBatchNormalizationForwardInference() and cudnnBatchNormalizationForwardTraining() functions, and as the bnScaleBiasDiffDesc parameter in the cudnnBatchNormalizationBackward() function.
- 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for BATCHNORM_MODE_SPATIAL
- 1xCxHxW for 4D and 1xCxDxHxW for 5D for BATCHNORM_MODE_PER_ACTIVATION mode
- Only 4D and 5D tensors are supported.
- The derivedBnDesc should be first created using cudnnCreateTensorDescriptor().
- xDesc is the descriptor for the layer's x data and has to be set up with proper dimensions prior to calling this function.
3.2.19. cudnnDeriveNormTensorDescriptor()
cudnnStatus_t CUDNNWINAPI
cudnnDeriveNormTensorDescriptor(cudnnTensorDescriptor_t derivedNormScaleBiasDesc,
cudnnTensorDescriptor_t derivedNormMeanVarDesc,
const cudnnTensorDescriptor_t xDesc,
cudnnNormMode_t mode,
int groupCnt)
Use the tensor descriptor produced by this function as the normScaleBiasDesc or normMeanVarDesc parameter for the cudnnNormalizationForwardInference() and cudnnNormalizationForwardTraining() functions, and as the dNormScaleBiasDesc and normMeanVarDesc parameters in the cudnnNormalizationBackward() function.
- 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for CUDNN_NORM_PER_ACTIVATION
- 1xCxHxW for 4D and 1xCxDxHxW for 5D for CUDNN_NORM_PER_CHANNEL mode
- Only 4D and 5D tensors are supported.
- The derivedNormScaleBiasDesc and derivedNormMeanVarDesc should be created first using cudnnCreateTensorDescriptor().
- xDesc is the descriptor for the layer's x data and has to be set up with proper dimensions prior to calling this function.
Parameters
- Output. Handle to a previously created tensor descriptor.
- Output. Handle to a previously created tensor descriptor.
- Input. Handle to a previously created and initialized layer's x data descriptor.
- Input. The normalization layer mode of operation.
- Input. The number of grouped convolutions. Currently, only 1 is supported.
3.2.20. cudnnDestroy()
cudnnStatus_t cudnnDestroy(cudnnHandle_t handle)
3.2.27. cudnnDestroyOpTensorDescriptor()
3.2.29. cudnnDestroyReduceTensorDescriptor()
cudnnStatus_t cudnnDestroyReduceTensorDescriptor(
cudnnReduceTensorDescriptor_t tensorDesc)
3.2.31. cudnnDestroyTensorDescriptor()
cudnnStatus_t cudnnDestroyTensorDescriptor(cudnnTensorDescriptor_t tensorDesc)
3.2.33. cudnnDivisiveNormalizationForward()
cudnnStatus_t cudnnDivisiveNormalizationForward(
cudnnHandle_t handle,
cudnnLRNDescriptor_t normDesc,
cudnnDivNormMode_t mode,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *means,
void *temp,
void *temp2,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)x_m = x-mean(x); y = x_m/max(c, sigma(x_m));
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Handle to a previously initialized LRN parameter descriptor. This descriptor is used for both LRN and DivisiveNormalization layers.
- Input. DivisiveNormalization layer mode of operation. Currently only CUDNN_DIVNORM_PRECOMPUTED_MEANS is implemented. Normalization is performed using the means input tensor that is expected to be precomputed by the user.
-
Input. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Tensor descriptor objects for the input and output tensors. Note that xDesc is shared between x, means, temp, and temp2 tensors.
- Input. Input tensor data pointer in device memory.
- Input. Input means tensor data pointer in device memory. Note that this tensor can be NULL (in that case its values are assumed to be zero during the computation). This tensor also doesn't have to contain means, these can be any values, a frequently used variation is a result of convolution with a normalized positive kernel (such as Gaussian).
- Workspace. Temporary tensors in device memory. These are used for computing intermediate values during the forward pass. These tensors do not have to be preserved as inputs from forward to the backward pass. Both use xDesc as their descriptor.
- Output. Pointer in device memory to a tensor for the result of the forward DivisiveNormalization computation.
Returns
- The computation was performed successfully.
- At least one of the following conditions are met:
- One of the tensor pointers x, y, temp, and temp2 is NULL.
- Number of input tensor or output tensor dimensions is outside of [4,5] range.
- A mismatch in dimensions between any two of the input or output tensors.
- For in-place computation when pointers x == y, a mismatch in strides between the input data and output data tensors.
- Alpha or beta pointer is NULL.
- LRN descriptor parameters are outside of their valid ranges.
- Any of the tensor strides are negative.
- The function does not support the provided configuration, for example, any of the input and output tensor strides mismatch (for the same dimension) is a non-supported configuration.
3.2.34. cudnnDropoutForward()
cudnnStatus_t cudnnDropoutForward(
cudnnHandle_t handle,
const cudnnDropoutDescriptor_t dropoutDesc,
const cudnnTensorDescriptor_t xdesc,
const void *x,
const cudnnTensorDescriptor_t ydesc,
void *y,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)- Better performance is obtained for fully packed tensors.
- This function should not be called during inference.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created dropout descriptor object.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Pointer to data of the tensor described by the xDesc descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Output. Pointer to data of the tensor described by the yDesc descriptor.
- Output. Pointer to user-allocated GPU memory used by this function. It is expected that the contents of reserveSpace does not change between cudnnDropoutForward() and cudnnDropoutBackward() calls.
- Input. Specifies the size in bytes of the provided memory for the reserve space.
Returns
- The call was successful.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The number of elements of input tensor and output tensors differ.
- The datatype of the input tensor and output tensors differs.
- The strides of the input tensor and output tensors differ and in-place operation is used (meaning, x and y pointers are equal).
- The provided reserveSpaceSizeInBytes is less than the value returned by cudnnDropoutGetReserveSpaceSize().
- cudnnSetDropoutDescriptor() has not been called on dropoutDesc with the non-NULLstates argument.
- The function failed to launch on the GPU.
3.2.35. cudnnDropoutGetReserveSpaceSize()
cudnnStatus_t cudnnDropoutGetReserveSpaceSize(
cudnnTensorDescriptor_t xDesc,
size_t *sizeInBytes)
3.2.36. cudnnDropoutGetStatesSize()
cudnnStatus_t cudnnDropoutGetStatesSize(
cudnnHandle_t handle,
size_t *sizeInBytes)
3.2.37. cudnnGetActivationDescriptor()
cudnnStatus_t cudnnGetActivationDescriptor(
const cudnnActivationDescriptor_t activationDesc,
cudnnActivationMode_t *mode,
cudnnNanPropagation_t *reluNanOpt,
double *coef)Parameters
- Input. Handle to a previously created activation descriptor.
- Output. Enumerant to specify the activation mode.
- Output. Enumerant to specify the Nan propagation mode.
- Output. Floating point number to specify the clipping threshold when the activation mode is set to CUDNN_ACTIVATION_CLIPPED_RELU or to specify the alpha coefficient when the activation mode is set to CUDNN_ACTIVATION_ELU.
3.2.38. cudnnGetActivationDescriptorSwishBeta()
cudnnStatus_t
cudnnGetActivationDescriptorSwishBeta(cudnnActivationDescriptor_t
activationDesc, double* swish_beta)
3.2.39. cudnnGetAlgorithmDescriptor()
This function queries a previously initialized generic algorithm descriptor object.
cudnnStatus_t cudnnGetAlgorithmDescriptor(
const cudnnAlgorithmDescriptor_t algoDesc,
cudnnAlgorithm_t *algorithm)
3.2.40. cudnnGetAlgorithmPerformance()
This function queries a previously initialized generic algorithm performance object.
cudnnStatus_t cudnnGetAlgorithmPerformance(
const cudnnAlgorithmPerformance_t algoPerf,
cudnnAlgorithmDescriptor_t* algoDesc,
cudnnStatus_t* status,
float* time,
size_t* memory)Parameters
- Input/Output. Handle to a previously created algorithm performance object.
- Output. The algorithm descriptor which the performance results describe.
- Output. The cuDNN status returned from running the algoDesc algorithm.
- Output. The GPU time spent running the algoDesc algorithm.
- Output. The GPU memory needed to run the algoDesc algorithm.
3.2.41. cudnnGetAlgorithmSpaceSize()
This function queries for the amount of host memory needed to call cudnnSaveAlgorithm(), much like the get workspace size function query for the amount of device memory needed.
cudnnStatus_t cudnnGetAlgorithmSpaceSize(
cudnnHandle_t handle,
cudnnAlgorithmDescriptor_t algoDesc,
size_t* algoSpaceSizeInBytes)
3.2.42. cudnnGetCallback()
cudnnStatus_t cudnnGetCallback(
unsigned mask,
void **udata,
cudnnCallback_t fptr)Parameters
- Output. Pointer to the address where the current internal error reporting message bit mask will be outputted.
- Output. Pointer to the address where the current internally stored udata address will be stored.
- Output. Pointer to the address where the current internally stored callback function pointer will be stored. When the built-in default callback function is used, NULL will be outputted.
3.2.43. cudnnGetCudartVersion()
size_t cudnnGetCudartVersion()
3.2.44. cudnnGetDropoutDescriptor()
cudnnStatus_t cudnnGetDropoutDescriptor(
cudnnDropoutDescriptor_t dropoutDesc,
cudnnHandle_t handle,
float *dropout,
void **states,
unsigned long long *seed)Parameters
- Input. Previously initialized dropout descriptor.
- Input. Handle to a previously created cuDNN context.
- Output. The probability with which the value from input is set to 0 during the dropout layer.
- Output. Pointer to user-allocated GPU memory that holds random number generator states.
- Output. Seed used to initialize random number generator states.
3.2.45. cudnnGetErrorString()
const char * cudnnGetErrorString(cudnnStatus_t status)
3.2.46. cudnnGetFilter4dDescriptor()
cudnnStatus_t cudnnGetFilter4dDescriptor(
const cudnnFilterDescriptor_t filterDesc,
cudnnDataType_t *dataType,
cudnnTensorFormat_t *format,
int *k,
int *c,
int *h,
int *w)
3.2.47. cudnnGetFilterNdDescriptor()
cudnnStatus_t cudnnGetFilterNdDescriptor(
const cudnnFilterDescriptor_t wDesc,
int nbDimsRequested,
cudnnDataType_t *dataType,
cudnnTensorFormat_t *format,
int *nbDims,
int filterDimA[])Parameters
- Input. Handle to a previously initialized filter descriptor.
- Input. Dimension of the expected filter descriptor. It is also the minimum size of the arrays filterDimA in order to be able to hold the results.
- Output. Data type.
- Output. Type of format.
- Output. Actual dimension of the filter.
- Output. Array of dimensions of at least nbDimsRequested that will be filled with the filter parameters from the provided filter descriptor.
3.2.48. cudnnGetFilterSizeInBytes()
cudnnStatus_t
cudnnGetFilterSizeInBytes(const cudnnFilterDescriptor_t filterDesc, size_t *size) ;
3.2.49. cudnnGetLRNDescriptor()
cudnnStatus_t cudnnGetLRNDescriptor(
cudnnLRNDescriptor_t normDesc,
unsigned *lrnN,
double *lrnAlpha,
double *lrnBeta,
double *lrnK)Parameters
- Input. Handle to a previously created LRN descriptor.
- Output. Pointers to receive values of parameters stored in the descriptor object. For more information, refer to cudnnSetLRNDescriptor(). Any of these pointers can be NULL (no value is returned for the corresponding parameter).
3.2.50. cudnnGetOpTensorDescriptor()
cudnnStatus_t cudnnGetOpTensorDescriptor(
const cudnnOpTensorDescriptor_t opTensorDesc,
cudnnOpTensorOp_t *opTensorOp,
cudnnDataType_t *opTensorCompType,
cudnnNanPropagation_t *opTensorNanOpt)Parameters
- Input. Tensor pointwise math descriptor passed to get the configuration from.
- Output. Pointer to the tensor pointwise math operation type, associated with this tensor pointwise math descriptor.
- Output. Pointer to the cuDNN data-type associated with this tensor pointwise math descriptor.
- Output. Pointer to the NAN propagation option associated with this tensor pointwise math descriptor.
3.2.51. cudnnGetPooling2dDescriptor()
cudnnStatus_t cudnnGetPooling2dDescriptor(
const cudnnPoolingDescriptor_t poolingDesc,
cudnnPoolingMode_t *mode,
cudnnNanPropagation_t *maxpoolingNanOpt,
int *windowHeight,
int *windowWidth,
int *verticalPadding,
int *horizontalPadding,
int *verticalStride,
int *horizontalStride)Parameters
- Input. Handle to a previously created pooling descriptor.
- Output. Enumerant to specify the pooling mode.
- Output. Enumerant to specify the Nan propagation mode.
- Output. Height of the pooling window.
- Output. Width of the pooling window.
- Output. Size of vertical padding.
- Output. Size of horizontal padding.
- Output. Pooling vertical stride.
- Output. Pooling horizontal stride.
3.2.52. cudnnGetPooling2dForwardOutputDim()
cudnnStatus_t cudnnGetPooling2dForwardOutputDim(
const cudnnPoolingDescriptor_t poolingDesc,
const cudnnTensorDescriptor_t inputDesc,
int *outN,
int *outC,
int *outH,
int *outW)
outputDim = 1 + (inputDim + 2*padding - windowDim)/poolingStride;
Parameters
- Input. Handle to a previously initialized pooling descriptor.
- Input. Handle to the previously initialized input tensor descriptor.
- Output. Number of images in the output.
- Output. Number of channels in the output.
- Output. Height of images in the output.
- Output. Width of images in the output.
3.2.53. cudnnGetPoolingNdDescriptor()
cudnnStatus_t cudnnGetPoolingNdDescriptor( const cudnnPoolingDescriptor_t poolingDesc, int nbDimsRequested, cudnnPoolingMode_t *mode, cudnnNanPropagation_t *maxpoolingNanOpt, int *nbDims, int windowDimA[], int paddingA[], int strideA[])
Parameters
- Input. Handle to a previously created pooling descriptor.
- Input. Dimension of the expected pooling descriptor. It is also the minimum size of the arrays windowDimA, paddingA, and strideA in order to be able to hold the results.
- Output. Enumerant to specify the pooling mode.
- Output. Enumerant to specify the Nan propagation mode.
- Output. Actual dimension of the pooling descriptor.
- Output. Array of dimension of at least nbDimsRequested that will be filled with the window parameters from the provided pooling descriptor.
- Output. Array of dimension of at least nbDimsRequested that will be filled with the padding parameters from the provided pooling descriptor.
- Output. Array of dimension at least nbDimsRequested that will be filled with the stride parameters from the provided pooling descriptor.
3.2.54. cudnnGetPoolingNdForwardOutputDim()
cudnnStatus_t cudnnGetPoolingNdForwardOutputDim(
const cudnnPoolingDescriptor_t poolingDesc,
const cudnnTensorDescriptor_t inputDesc,
int nbDims,
int outDimA[])
outputDim = 1 + (inputDim + 2*padding - windowDim)/poolingStride;
3.2.55. cudnnGetProperty()
cudnnStatus_t cudnnGetProperty(
libraryPropertyType type,
int *value)
3.2.56. cudnnGetReduceTensorDescriptor()
cudnnStatus_t cudnnGetReduceTensorDescriptor(
const cudnnReduceTensorDescriptor_t reduceTensorDesc,
cudnnReduceTensorOp_t *reduceTensorOp,
cudnnDataType_t *reduceTensorCompType,
cudnnNanPropagation_t *reduceTensorNanOpt,
cudnnReduceTensorIndices_t *reduceTensorIndices,
cudnnIndicesType_t *reduceTensorIndicesType)Parameters
- Input. Pointer to a previously initialized reduce tensor descriptor object.
- Output. Enumerant to specify the reduced tensor operation.
- Output. Enumerant to specify the computation datatype of the reduction.
- Output. Enumerant to specify the Nan propagation mode.
- Output. Enumerant to specify the reduced tensor indices.
- Output. Enumerant to specify the reduced tensor indices type.
3.2.57. cudnnGetReductionIndicesSize()
cudnnStatus_t cudnnGetReductionIndicesSize(
cudnnHandle_t handle,
const cudnnReduceTensorDescriptor_t reduceDesc,
const cudnnTensorDescriptor_t aDesc,
const cudnnTensorDescriptor_t cDesc,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Pointer to a previously initialized reduce tensor descriptor object.
- Input. Pointer to the input tensor descriptor.
- Input. Pointer to the output tensor descriptor.
- Output. Minimum size of the index space to be passed to the reduction.
3.2.58. cudnnGetReductionWorkspaceSize()
cudnnStatus_t cudnnGetReductionWorkspaceSize(
cudnnHandle_t handle,
const cudnnReduceTensorDescriptor_t reduceDesc,
const cudnnTensorDescriptor_t aDesc,
const cudnnTensorDescriptor_t cDesc,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Pointer to a previously initialized reduce tensor descriptor object.
- Input. Pointer to the input tensor descriptor.
- Input. Pointer to the output tensor descriptor.
- Output. Minimum size of the index space to be passed to the reduction.
3.2.59. cudnnGetStream()
cudnnStatus_t cudnnGetStream(
cudnnHandle_t handle,
cudaStream_t *streamId)
3.2.60. cudnnGetTensor4dDescriptor()
cudnnStatus_t cudnnGetTensor4dDescriptor(
const cudnnTensorDescriptor_t tensorDesc,
cudnnDataType_t *dataType,
int *n,
int *c,
int *h,
int *w,
int *nStride,
int *cStride,
int *hStride,
int *wStride)Parameters
- Input. Handle to a previously initialized tensor descriptor.
- Output. Data type.
- Output. Number of images.
- Output. Number of feature maps per image.
- Output. Height of each feature map.
- Output. Width of each feature map.
- Output. Stride between two consecutive images.
- Output. Stride between two consecutive feature maps.
- Output. Stride between two consecutive rows.
- Output. Stride between two consecutive columns.
3.2.61. cudnnGetTensorNdDescriptor()
cudnnStatus_t cudnnGetTensorNdDescriptor(
const cudnnTensorDescriptor_t tensorDesc,
int nbDimsRequested,
cudnnDataType_t *dataType,
int *nbDims,
int dimA[],
int strideA[])Parameters
- Input. Handle to a previously initialized tensor descriptor.
- Input. Number of dimensions to extract from a given tensor descriptor. It is also the minimum size of the arrays dimA and strideA. If this number is greater than the resulting nbDims[0], only nbDims[0] dimensions will be returned.
- Output. Data type.
- Output. Actual number of dimensions of the tensor will be returned in nbDims[0].
- Output. Array of dimensions of at least nbDimsRequested that will be filled with the dimensions from the provided tensor descriptor.
- Output. Array of dimensions of at least nbDimsRequested that will be filled with the strides from the provided tensor descriptor.
3.2.62. cudnnGetTensorSizeInBytes()
cudnnStatus_t cudnnGetTensorSizeInBytes(
const cudnnTensorDescriptor_t tensorDesc,
size_t *size)
3.2.63. cudnnGetTensorTransformDescriptor()
cudnnStatus_t cudnnGetTensorTransformDescriptor( cudnnTensorTransformDescriptor_t transformDesc, uint32_t nbDimsRequested, cudnnTensorFormat_t *destFormat, int32_t padBeforeA[], int32_t padAfterA[], uint32_t foldA[], cudnnFoldingDirection_t *direction);
Parameters
- Input. A previously initialized tensor transform descriptor.
- Input. The number of dimensions to consider. For more information, refer to Tensor Descriptor.
- Output. The transform format that will be returned.
- Output. An array filled with the amount of padding to add before each dimension. The dimension of this padBeforeA[] parameter is equal to nbDimsRequested.
- Output. An array filled with the amount of padding to add after each dimension. The dimension of this padBeforeA[] parameter is equal to nbDimsRequested.
- Output. An array that was filled with the folding parameters for each spatial dimension. The dimension of this foldA[] array is nbDimsRequested-2.
- Output. The setting that selects folding or unfolding. For more information, refer to cudnnFoldingDirection_t.
3.2.64. cudnnGetVersion()
size_t cudnnGetVersion()
3.2.65. cudnnInitTransformDest()
cudnnStatus_t cudnnInitTransformDest( const cudnnTensorTransformDescriptor_t transformDesc, const cudnnTensorDescriptor_t srcDesc, cudnnTensorDescriptor_t destDesc, size_t *destSizeInBytes);
Parameters
- Input. Handle to a previously initialized tensor transform descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Output. Handle of the tensor descriptor that will be initialized and returned.
- Output. A pointer to hold the size, in bytes, of the new tensor.
Returns
- The tensor descriptor was initialized successfully.
- If either srcDesc or destDesc is NULL, or if the tensor descriptor’s nbDims is incorrect. For more information, refer to Tensor Descriptor.
- If the provided configuration is not 4D.
- Function failed to launch on the GPU.
3.2.66. cudnnLRNCrossChannelForward()
cudnnStatus_t cudnnLRNCrossChannelForward(
cudnnHandle_t handle,
cudnnLRNDescriptor_t normDesc,
cudnnLRNMode_t lrnMode,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Handle to a previously initialized LRN parameter descriptor.
- Input. LRN layer mode of operation. Currently only CUDNN_LRN_CROSS_CHANNEL_DIM1 is implemented. Normalization is performed along the tensor's dimA[1].
-
Input. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Tensor descriptor objects for the input and output tensors.
- Input. Input tensor data pointer in device memory.
- Output. Output tensor data pointer in device memory.
Returns
- CUDNN_STATUS_SUCCESS
- The computation was performed successfully.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- One of the tensor pointers x, y is NULL.
- Number of input tensor dimensions is 2 or less.
- LRN descriptor parameters are outside of their valid ranges.
- One of the tensor parameters is 5D but is not in NCDHW DHW-packed format.
- CUDNN_STATUS_NOT_SUPPORTED
- The function does not support the provided configuration. Refer to the
following examples of non-supported configurations:
- Any of the input tensor datatypes is not the same as any of the output tensor datatype.
- x and y tensor dimensions mismatch.
- Any tensor parameters strides are negative.
3.2.67. cudnnNormalizationForwardInference()
cudnnStatus_t
cudnnNormalizationForwardInference(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const void *alpha,
const void *beta,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t normScaleBiasDesc,
const void *normScale,
const void *normBias,
const cudnnTensorDescriptor_t normMeanVarDesc,
const void *estimatedMean,
const void *estimatedVariance,
const cudnnTensorDescriptor_t zDesc,
const void *z,
cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t yDesc,
void *y,
double epsilon,
int groupCnt);
Only 4D and 5D tensors are supported.
y = beta*y + alpha *[normBias + (normScale * (x-estimatedMean)/sqrt(epsilon + estimatedVariance)]
The epsilon value has to be the same during training, backpropagation, and inference.
For the training phase, refer to cudnnNormalizationForwardTraining().
Higher performance can be obtained when HW-packed tensors are used for all of x and y.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
- Input. Mode of post-operative. Currently, CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are not supported.
- Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handles to the previously initialized tensor descriptors.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc, for the layer’s x input data.
- Output. Data pointer to GPU memory associated with the tensor descriptor yDesc, for the y output of the normalization layer.
-
Input. Tensor descriptors and pointers in device memory for residual addition to the result of the normalization operation, prior to the activation. zDesc and *z are optional and are only used when normOps is CUDNN_NORM_OPS_NORM_ADD_ACTIVATION, otherwise users may pass NULL. When in use, z should have exactly the same dimension as x and the final output y. For more information, refer to cudnnTensorDescriptor_t.
Since normOps is only supported for CUDNN_NORM_OPS_NORM, we can set these to NULL for now.
- Inputs. Tensor descriptors and pointers in device memory for the normalization scale and bias parameters (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta and scale as gamma).
- Inputs. Mean and variance tensors and their tensor descriptors. The estimatedMean and estimatedVariance inputs, accumulated during the training phase from the cudnnNormalizationForwardTraining() call, should be passed as inputs here.
- Input. Descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL. Since normOps is only supported for CUDNN_NORM_OPS_NORM, we can set these to NULL for now.
- Input. Epsilon value used in the normalization formula. Its value should be equal to or greater than zero.
- Input. The number of grouped convolutions. Currently, only 1 is supported.
Returns
- The computation was performed successfully.
- A compute or data type other than what is supported was chosen, or an unknown algorithm type was chosen.
- At least one of the following conditions are met:
- One of the pointers alpha, beta, x, y, normScale, normBias, estimatedMean, and estimatedInvVariance is NULL.
- The number of xDesc or yDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- normScaleBiasDesc and normMeanVarDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for per-channel, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- epsilon value is less than zero.
- Dimensions or data types mismatch for xDesc and yDesc.
- A compute or data type other than FLOAT was chosen, or an unknown algorithm type was chosen.
- The function failed to launch on the GPU.
3.2.68. cudnnOpsInferVersionCheck()
cudnnStatus_t cudnnOpsInferVersionCheck(void)
3.2.69. cudnnOpTensor()
cudnnStatus_t cudnnOpTensor(
cudnnHandle_t handle,
const cudnnOpTensorDescriptor_t opTensorDesc,
const void *alpha1,
const cudnnTensorDescriptor_t aDesc,
const void *A,
const void *alpha2,
const cudnnTensorDescriptor_t bDesc,
const void *B,
const void *beta,
const cudnnTensorDescriptor_t cDesc,
void *C)
| opTensorCompType in opTensorDesc | A | B | C (destination) |
|---|---|---|---|
| FLOAT | FLOAT | FLOAT | FLOAT |
| FLOAT | INT8 | INT8 | FLOAT |
| FLOAT | HALF | HALF | FLOAT |
| FLOAT | BFLOAT16 | BFLOAT16 | FLOAT |
| DOUBLE | DOUBLE | DOUBLE | DOUBLE |
| FLOAT | FLOAT | FLOAT | HALF |
| FLOAT | HALF | HALF | HALF |
| FLOAT | INT8 | INT8 | INT8 |
| FLOAT | FLOAT | FLOAT | INT8 |
| FLOAT | FLOAT | FLOAT | BFLOAT16 |
| FLOAT | BFLOAT16 | BFLOAT16 | BFLOAT16 |
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized op tensor descriptor.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Pointer to data of the tensors described by the aDesc and bDesc descriptors, respectively.
- Input/Output. Pointer to data of the tensor described by the cDesc descriptor.
Returns
- The function executed successfully.
- The function does not support the provided configuration. Refer to the
following examples of non-supported configurations:
- The dimensions of the bias tensor and the output tensor dimensions are above 5.
- opTensorCompType is not set as stated above.
- The data type of the destination tensor C is unrecognized, or the restrictions on the input and destination tensors, stated above, are not met.
- The function failed to launch on the GPU.
3.2.70. cudnnPoolingForward()
cudnnStatus_t cudnnPoolingForward(
cudnnHandle_t handle,
const cudnnPoolingDescriptor_t poolingDesc,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)All tensor formats are supported, best performance is expected when using HW-packed tensors. Only 2 and 3 spatial dimensions are allowed. Vectorized tensors are only supported if they have 2 spatial dimensions.
The dimensions of the output tensor yDesc can be smaller or bigger than the dimensions advised by the routine cudnnGetPooling2dForwardOutputDim() or cudnnGetPoolingNdForwardOutputDim().
For average pooling, the compute type is float even for integer input and output data type. Output round is nearest-even and clamp to the most negative or most positive value of type if out of range.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized pooling descriptor.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor. Must be of type FLOAT, DOUBLE, HALF, INT8, INT8x4, INT8x32, or BFLOAT16. For more information, refer to cudnnDataType_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to the previously initialized output tensor descriptor. Must be of type FLOAT, DOUBLE, HALF, INT8, INT8x4, INT8x32, or BFLOAT16. For more information, refer to cudnnDataType_t.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- The dimensions n, c of the input tensor and output tensors differ.
- The datatype of the input tensor and output tensors differs.
- The function does not support the provided configuration.
- The function failed to launch on the GPU.
3.2.71. cudnnQueryRuntimeError()
cudnnStatus_t cudnnQueryRuntimeError(
cudnnHandle_t handle,
cudnnStatus_t *rstatus,
cudnnErrQueryMode_t mode,
cudnnRuntimeTag_t *tag)When the CUDNN_BATCHNORM_SPATIAL_PERSISTENT mode is selected in cudnnBatchNormalizationForwardTraining() or cudnnBatchNormalizationBackward(), the algorithm may encounter numerical overflows where CUDNN_BATCHNORM_SPATIAL performs just fine albeit at a slower speed. The user can invoke cudnnQueryRuntimeError() to make sure numerical overflows did not occur during the kernel execution. Those issues are reported by the kernel that performs computations.
cudnnQueryRuntimeError() can be used in polling and blocking software control flows. There are two polling modes (CUDNN_ERRQUERY_RAWCODE and CUDNN_ERRQUERY_NONBLOCKING) and one blocking mode CUDNN_ERRQUERY_BLOCKING.
CUDNN_ERRQUERY_RAWCODE reads the error storage location regardless of the kernel completion status. The kernel might not even start and the error storage (allocated per cuDNN handle) might be used by an earlier call.
CUDNN_ERRQUERY_NONBLOCKING checks if all tasks in the user stream are completed. The cudnnQueryRuntimeError() function will return immediately and report CUDNN_STATUS_RUNTIME_IN_PROGRESS in rstatus if some tasks in the user stream are pending. Otherwise, the function will copy the remote kernel error code to rstatus.
In the blocking mode (CUDNN_ERRQUERY_BLOCKING), the function waits for all tasks to drain in the user stream before reporting the remote kernel error code. The blocking flavor can be further adjusted by calling cudaSetDeviceFlags with the cudaDeviceScheduleSpin, cudaDeviceScheduleYield, or cudaDeviceScheduleBlockingSync flag.
CUDNN_ERRQUERY_NONBLOCKING and CUDNN_ERRQUERY_BLOCKING modes should not be used when the user stream is changed in the cuDNN handle, meaning, cudnnSetStream() is invoked between functions that report runtime kernel errors and the cudnnQueryRuntimeError() function.
The remote error status reported in rstatus can be set to: CUDNN_STATUS_SUCCESS, CUDNN_STATUS_RUNTIME_IN_PROGRESS, or CUDNN_STATUS_RUNTIME_FP_OVERFLOW. The remote kernel error is automatically cleared by cudnnQueryRuntimeError().
3.2.72. cudnnReduceTensor()
cudnnStatus_t cudnnReduceTensor(
cudnnHandle_t handle,
const cudnnReduceTensorDescriptor_t reduceTensorDesc,
void *indices,
size_t indicesSizeInBytes,
void *workspace,
size_t workspaceSizeInBytes,
const void *alpha,
const cudnnTensorDescriptor_t aDesc,
const void *A,
const void *beta,
const cudnnTensorDescriptor_t cDesc,
void *C)Each dimension of the output tensor C must match the corresponding dimension of the input tensor A or must be equal to 1. The dimensions equal to 1 indicate the dimensions of A to be reduced.
The implementation will generate indices for the min and max ops only, as indicated by the cudnnReduceTensorIndices_t enum of the reduceTensorDesc. Requesting indices for the other reduction ops results in an error. The data type of the indices is indicated by the cudnnIndicesType_t enum; currently only the 32-bit (unsigned int) type is supported.
The indices returned by the implementation are not absolute indices but relative to the dimensions being reduced. The indices are also flattened, meaning, not coordinate tuples.
The data types of the tensors A and C must match if of type double. In this case, alpha and beta and the computation enum of reduceTensorDesc are all assumed to be of type double.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized reduce tensor descriptor.
- Output. Handle to a previously allocated space for writing indices.
- Input. Size of the above previously allocated space.
- Input. Handle to a previously allocated space for the reduction implementation.
- Input. Size of the above previously allocated space.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Pointer to data of the tensor described by the aDesc descriptor.
- Input/Output. Pointer to data of the tensor described by the cDesc descriptor.
Returns
- The function executed successfully.
- The function does not support the provided configuration. See the
following for some examples of non-supported configurations:
- The dimensions of the input tensor and the output tensor are above 8.
- reduceTensorCompType is not set as stated above.
- The corresponding dimensions of the input and output tensors all match, or the conditions in the above paragraphs are unmet.
- The allocations for the indices or workspace are insufficient.
- The function failed to launch on the GPU.
3.2.73. cudnnRestoreAlgorithm()
This function reads algorithm metadata from the host memory space provided by the user in algoSpace, allowing the user to use the results of RNN finds from previous cuDNN sessions.
cudnnStatus_t cudnnRestoreAlgorithm(
cudnnHandle_t handle,
void* algoSpace,
size_t algoSpaceSizeInBytes,
cudnnAlgorithmDescriptor_t algoDesc)
3.2.74. cudnnRestoreDropoutDescriptor()
cudnnStatus_t cudnnRestoreDropoutDescriptor(
cudnnDropoutDescriptor_t dropoutDesc,
cudnnHandle_t handle,
float dropout,
void *states,
size_t stateSizeInBytes,
unsigned long long seed)Parameters
- Input/Output. Previously created dropout descriptor.
- Input. Handle to a previously created cuDNN context.
- Input. Probability with which the value from an input tensor is set to 0 when performing dropout.
- Input. Pointer to GPU memory that holds random number generator states initialized by a prior call to cudnnSetDropoutDescriptor().
- Input. Size in bytes of buffer holding random number generator states.
- Input. Seed used in prior calls to cudnnSetDropoutDescriptor() that initialized states buffer. Using a different seed from this has no effect. A change of seed, and subsequent update to random number generator states can be achieved by calling cudnnSetDropoutDescriptor().
3.2.75. cudnnSaveAlgorithm()
This function writes algorithm metadata into the host memory space provided by the user in algoSpace, allowing the user to preserve the results of RNN finds after cuDNN exits.
cudnnStatus_t cudnnSaveAlgorithm(
cudnnHandle_t handle,
cudnnAlgorithmDescriptor_t algoDesc,
void* algoSpace
size_t algoSpaceSizeInBytes)
3.2.76. cudnnScaleTensor()
cudnnStatus_t cudnnScaleTensor(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t yDesc,
void *y,
const void *alpha)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized tensor descriptor.
- Input/Output. Pointer to data of the tensor described by the yDesc descriptor.
- Input. Pointer in the host memory to a single value that all elements of the tensor will be scaled with. For more information, refer to Scaling Parameters.
3.2.77. cudnnSetActivationDescriptor()
cudnnStatus_t cudnnSetActivationDescriptor(
cudnnActivationDescriptor_t activationDesc,
cudnnActivationMode_t mode,
cudnnNanPropagation_t reluNanOpt,
double coef)Parameters
- Input/Output. Handle to a previously created activation descriptor.
- Input. Enumerant to specify the activation mode.
- Input. Enumerant to specify the Nan propagation mode.
- Input. Floating point number. When the activation mode (refer to cudnnActivationMode_t) is set to CUDNN_ACTIVATION_CLIPPED_RELU, this input specifies the clipping threshold; and when the activation mode is set to CUDNN_ACTIVATION_RELU, this input specifies the upper bound.
3.2.78. cudnnSetActivationDescriptorSwishBeta()
cudnnStatus_t cudnnSetActivationDescriptorSwishBeta(cudnnActivationDescriptor_t activationDesc, double swish_beta)
3.2.79. cudnnSetAlgorithmDescriptor()
This function initializes a previously created generic algorithm descriptor object.
cudnnStatus_t cudnnSetAlgorithmDescriptor(
cudnnAlgorithmDescriptor_t algorithmDesc,
cudnnAlgorithm_t algorithm)
3.2.80. cudnnSetAlgorithmPerformance()
This function initializes a previously created generic algorithm performance object.
cudnnStatus_t cudnnSetAlgorithmPerformance(
cudnnAlgorithmPerformance_t algoPerf,
cudnnAlgorithmDescriptor_t algoDesc,
cudnnStatus_t status,
float time,
size_t memory)Parameters
- Input/Output. Handle to a previously created algorithm performance object.
- Input. The algorithm descriptor which the performance results describe.
- Input. The cuDNN status returned from running the algoDesc algorithm.
- Input. The GPU time spent running the algoDesc algorithm.
- Input. The GPU memory needed to run the algoDesc algorithm.
3.2.81. cudnnSetCallback()
cudnnStatus_t cudnnSetCallback(
unsigned mask,
void *udata,
cudnnCallback_t fptr)Parameters
-
Input. An unsigned integer. The four least significant bits (LSBs) of this unsigned integer are used for switching on and off the different levels of error reporting messages. This applies for both the default callbacks, and for the customized callbacks. The bit position is in correspondence with the enum of cudnnSeverity_t. The user may utilize the predefined macros CUDNN_SEV_ERROR_EN, CUDNN_SEV_WARNING_EN, and CUDNN_SEV_INFO_EN to form the bit mask. When a bit is set to 1, the corresponding message channel is enabled.
For example, when bit 3 is set to 1, the API logging is enabled. Currently, only the log output of level CUDNN_SEV_INFO is functional; the others are not yet implemented. When used for turning on and off the logging with the default callback, the user may pass NULL to udata and fptr. In addition, the environment variable CUDNN_LOGDEST_DBG must be set. For more information, refer to Deprecation Policy.- CUDNN_SEV_INFO_EN= 0b1000 (functional).
- CUDNN_SEV_ERROR_EN= 0b0010 (not yet functional).
- CUDNN_SEV_WARNING_EN= 0b0100 (not yet functional).
The output of CUDNN_SEV_FATAL is always enabled and cannot be disabled.
- Input. A pointer provided by the user. This pointer will be passed to the user’s custom logging callback function. The data it points to will not be read, nor be changed by cuDNN. This pointer may be used in many ways, such as in a mutex or in a communication socket for the user’s callback function for logging. If the user is utilizing the default callback function, or doesn’t want to use this input in the customized callback function, they may pass in NULL.
- Input. A pointer to a user-supplied callback function. When
NULL is passed to this pointer, then cuDNN switches
back to the built-in default callback function. The user-supplied
callback function prototype must be similar to the following (also
defined in the header file):
void customizedLoggingCallback (cudnnSeverity_t sev, void *udata, const cudnnDebug_t *dbg, const char *msg);
- The structure cudnnDebug_t is defined in the header file. It provides the metadata, such as time, time since start, stream ID, process and thread ID, that the user may choose to print or store in their customized callback.
- The variable msg is the logging message generated by cuDNN. Each line of this message is terminated by \0, and the end of the message is terminated by \0\0. Users may select what is necessary to show in the log, and may reformat the string.
3.2.82. cudnnSetDropoutDescriptor()
cudnnStatus_t cudnnSetDropoutDescriptor(
cudnnDropoutDescriptor_t dropoutDesc,
cudnnHandle_t handle,
float dropout,
void *states,
size_t stateSizeInBytes,
unsigned long long seed)When the states argument is not NULL, a cuRAND initialization kernel is invoked by cudnnSetDropoutDescriptor(). This kernel requires a substantial amount of GPU memory for the stack. Memory is released when the kernel finishes. The CUDNN_STATUS_ALLOC_FAILED status is returned when no sufficient free memory is available for the GPU stack.
Parameters
- Input/Output. Previously created dropout descriptor object.
- Input. Handle to a previously created cuDNN context.
- Input. The probability with which the value from input is set to zero during the dropout layer.
- Output. Pointer to user-allocated GPU memory that will hold random number generator states.
- Input. Specifies the size in bytes of the provided memory for the states.
- Input. Seed used to initialize random number generator states.
Returns
- The call was successful.
- The sizeInBytes argument is less than the value returned by cudnnDropoutGetStatesSize().
- The function failed to temporarily extend the GPU stack.
- The function failed to launch on the GPU.
- Internally used CUDA functions returned an error status.
3.2.83. cudnnSetFilter4dDescriptor()
cudnnStatus_t cudnnSetFilter4dDescriptor(
cudnnFilterDescriptor_t filterDesc,
cudnnDataType_t dataType,
cudnnTensorFormat_t format,
int k,
int c,
int h,
int w)Tensor format CUDNN_TENSOR_NHWC has limited support in cudnnConvolutionForward(), cudnnConvolutionBackwardData(), and cudnnConvolutionBackwardFilter().
Parameters
- Input/Output. Handle to a previously created filter descriptor.
- Input. Data type.
-
Input.Type of the filter layout format. If this input is set to CUDNN_TENSOR_NCHW, which is one of the enumerant values allowed by cudnnTensorFormat_t descriptor, then the layout of the filter is in the form of KCRS, where:
- K represents the number of output feature maps
- C is the number of input feature maps
- R is the number of rows per filter
- S is the number of columns per filter
If this input is set to CUDNN_TENSOR_NHWC, then the layout of the filter is in the form of KRSC. For more information, refer to cudnnTensorFormat_t.
- Input. Number of output feature maps.
- Input. Number of input feature maps.
- Input. Height of each filter.
- Input. Width of each filter.
3.2.84. cudnnSetFilterNdDescriptor()
cudnnStatus_t cudnnSetFilterNdDescriptor(
cudnnFilterDescriptor_t filterDesc,
cudnnDataType_t dataType,
cudnnTensorFormat_t format,
int nbDims,
const int filterDimA[])The tensor format CUDNN_TENSOR_NHWC has limited support in cudnnConvolutionForward(), cudnnConvolutionBackwardData(), and cudnnConvolutionBackwardFilter().
Parameters
- Input/Output. Handle to a previously created filter descriptor.
- Input. Data type.
-
Input.Type of the filter layout format. If this input is set to CUDNN_TENSOR_NCHW, which is one of the enumerant values allowed by cudnnTensorFormat_t descriptor, then the layout of the filter is as follows:
- For N=4, a 4D filter descriptor, the filter
layout is in the form of KCRS:
- K represents the number of output feature maps
- C is the number of input feature maps
- R is the number of rows per filter
- S is the number of columns per filter
- For N=3, a 3D filter descriptor, the number S (number of columns per filter) is omitted.
- For N=5 and greater, the layout of the higher dimensions immediately follows RS.
On the other hand, if this input is set to CUDNN_TENSOR_NHWC, then the layout of the filter is as follows:- For N=4, a 4D filter descriptor, the filter layout is in the form of KRSC.
- For N=3, a 3D filter descriptor, the number S (number of columns per filter) is omitted and the layout of C immediately follows R.
- For N=5 and greater, the layout of the higher dimensions are inserted between S and C. For more information, refer to cudnnTensorFormat_t.
- For N=4, a 4D filter descriptor, the filter
layout is in the form of KCRS:
- Input. Dimension of the filter.
- Input. Array of dimension nbDims containing the size of the filter for each dimension.
3.2.85. cudnnSetLRNDescriptor()
cudnnStatus_t cudnnSetLRNDescriptor(
cudnnLRNDescriptor_t normDesc,
unsigned lrnN,
double lrnAlpha,
double lrnBeta,
double lrnK)- Macros CUDNN_LRN_MIN_N, CUDNN_LRN_MAX_N, CUDNN_LRN_MIN_K, CUDNN_LRN_MIN_BETA defined in cudnn.h specify valid ranges for parameters.
- Values of double parameters will be cast down to the tensor datatype during computation.
Parameters
- Output. Handle to a previously created LRN descriptor.
- Input. Normalization window width in elements. The LRN layer uses a window [center-lookBehind, center+lookAhead], where lookBehind = floor( (lrnN-1)/2 ), lookAhead = lrnN-lookBehind-1. So for n=10, the window is [k-4...k...k+5] with a total of 10 samples. For the DivisiveNormalization layer, the window has the same extent as above in all spatial dimensions (dimA[2], dimA[3], dimA[4]). By default, lrnN is set to 5 in cudnnCreateLRNDescriptor().
- Input. Value of the alpha variance scaling parameter in the normalization formula. Inside the library code, this value is divided by the window width for LRN and by (window width)^#spatialDimensions for DivisiveNormalization. By default, this value is set to 1e-4 in cudnnCreateLRNDescriptor().
- Input. Value of the beta power parameter in the normalization formula. By default, this value is set to 0.75 in cudnnCreateLRNDescriptor().
- Input. Value of the k parameter in the normalization formula. By default, this value is set to 2.0.
3.2.86. cudnnSetOpTensorDescriptor()
cudnnStatus_t cudnnSetOpTensorDescriptor(
cudnnOpTensorDescriptor_t opTensorDesc,
cudnnOpTensorOp_t opTensorOp,
cudnnDataType_t opTensorCompType,
cudnnNanPropagation_t opTensorNanOpt)
3.2.87. cudnnSetPooling2dDescriptor()
cudnnStatus_t cudnnSetPooling2dDescriptor(
cudnnPoolingDescriptor_t poolingDesc,
cudnnPoolingMode_t mode,
cudnnNanPropagation_t maxpoolingNanOpt,
int windowHeight,
int windowWidth,
int verticalPadding,
int horizontalPadding,
int verticalStride,
int horizontalStride)Parameters
- Input/Output. Handle to a previously created pooling descriptor.
- Input. Enumerant to specify the pooling mode.
- Input. Enumerant to specify the Nan propagation mode.
- Input. Height of the pooling window.
- Input. Width of the pooling window.
- Input. Size of vertical padding.
- Input. Size of horizontal padding.
- Input. Pooling vertical stride.
- Input. Pooling horizontal stride.
3.2.88. cudnnSetPoolingNdDescriptor()
cudnnStatus_t cudnnSetPoolingNdDescriptor(
cudnnPoolingDescriptor_t poolingDesc,
const cudnnPoolingMode_t mode,
const cudnnNanPropagation_t maxpoolingNanOpt,
int nbDims,
const int windowDimA[],
const int paddingA[],
const int strideA[])Parameters
- Input/Output. Handle to a previously created pooling descriptor.
- Input. Enumerant to specify the pooling mode.
- Input. Enumerant to specify the Nan propagation mode.
- Input. Dimension of the pooling operation. Must be greater than zero.
- Input. Array of dimension nbDims containing the window size for each dimension. The value of array elements must be greater than zero.
- Input. Array of dimension nbDims containing the padding size for each dimension. Negative padding is allowed.
- Input. Array of dimension nbDims containing the striding size for each dimension. The value of array elements must be greater than zero (meaning, negative striding size is not allowed).
3.2.89. cudnnSetReduceTensorDescriptor()
cudnnStatus_t cudnnSetReduceTensorDescriptor(
cudnnReduceTensorDescriptor_t reduceTensorDesc,
cudnnReduceTensorOp_t reduceTensorOp,
cudnnDataType_t reduceTensorCompType,
cudnnNanPropagation_t reduceTensorNanOpt,
cudnnReduceTensorIndices_t reduceTensorIndices,
cudnnIndicesType_t reduceTensorIndicesType)Parameters
- Input/Output. Handle to a previously created reduce tensor descriptor.
- Input. Enumerant to specify the reduce tensor operation.
- Input. Enumerant to specify the computation datatype of the reduction.
- Input. Enumerant to specify the Nan propagation mode.
- Input. Enumerant to specify the reduced tensor indices.
- Input. Enumerant to specify the reduce tensor indices type.
3.2.90. cudnnSetSpatialTransformerNdDescriptor()
cudnnStatus_t cudnnSetSpatialTransformerNdDescriptor(
cudnnSpatialTransformerDescriptor_t stDesc,
cudnnSamplerType_t samplerType,
cudnnDataType_t dataType,
const int nbDims,
const int dimA[])
3.2.91. cudnnSetStream()
cudnnStatus_t cudnnSetStream(
cudnnHandle_t handle,
cudaStream_t streamId)With CUDA 11.x or later, internal streams have the same priority as the stream set by the last call to this function. In CUDA graph capture mode, CUDA 11.8 or later is required in order for the stream priorities to match.
3.2.92. cudnnSetTensor()
cudnnStatus_t cudnnSetTensor(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t yDesc,
void *y,
const void *valuePtr)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized tensor descriptor.
- Input/Output. Pointer to data of the tensor described by the yDesc descriptor.
- Input. Pointer in host memory to a single value. All elements of the y tensor will be set to value[0]. The data type of the element in value[0] has to match the data type of tensor y.
3.2.93. cudnnSetTensor4dDescriptor()
cudnnStatus_t cudnnSetTensor4dDescriptor(
cudnnTensorDescriptor_t tensorDesc,
cudnnTensorFormat_t format,
cudnnDataType_t dataType,
int n,
int c,
int h,
int w)The total size of a tensor including the potential padding between dimensions is limited to 2 Giga-elements of type datatype.
3.2.94. cudnnSetTensor4dDescriptorEx()
cudnnStatus_t cudnnSetTensor4dDescriptorEx(
cudnnTensorDescriptor_t tensorDesc,
cudnnDataType_t dataType,
int n,
int c,
int h,
int w,
int nStride,
int cStride,
int hStride,
int wStride)At present, some cuDNN routines have limited support for strides. Those routines will return CUDNN_STATUS_NOT_SUPPORTED if a 4D tensor object with an unsupported stride is used. cudnnTransformTensor() can be used to convert the data to a supported layout.
The total size of a tensor including the potential padding between dimensions is limited to 2 Giga-elements of type datatype.
Parameters
- Input/Output. Handle to a previously created tensor descriptor.
- Input. Data type.
- Input. Number of images.
- Input. Number of feature maps per image.
- Input. Height of each feature map.
- Input. Width of each feature map.
- Input. Stride between two consecutive images.
- Input. Stride between two consecutive feature maps.
- Input. Stride between two consecutive rows.
- Input. Stride between two consecutive columns.
3.2.95. cudnnSetTensorNdDescriptor()
cudnnStatus_t cudnnSetTensorNdDescriptor(
cudnnTensorDescriptor_t tensorDesc,
cudnnDataType_t dataType,
int nbDims,
const int dimA[],
const int strideA[])The total size of a tensor including the potential padding between dimensions is limited to 2 Giga-elements of type datatype. Tensors are restricted to having at least 4 dimensions, and at most CUDNN_DIM_MAX dimensions (defined in cudnn.h). When working with lower dimensional data, it is recommended that the user create a 4D tensor, and set the size along unused dimensions to 1.
Parameters
- Input/Output. Handle to a previously created tensor descriptor.
- Input. Data type.
- Input. Dimension of the tensor.
Note: Do not use 2 dimensions. Due to historical reasons, the minimum number of dimensions in the filter descriptor is three. For more information, refer to cudnnGetRNNLinLayerBiasParams().
- Input. Array of dimension nbDims that contain the size of the tensor for every dimension. The size along unused dimensions should be set to 1. By convention, the ordering of dimensions in the array follows the format - [N, C, D, H, W], with W occupying the smallest index in the array.
- Input. Array of dimension nbDims that contain the stride of the tensor for every dimension. By convention, the ordering of the strides in the array follows the format - [Nstride, Cstride, Dstride, Hstride, Wstride], with Wstride occupying the smallest index in the array.
Returns
- The object was set successfully.
- At least one of the elements of the array dimA was negative or zero, or dataType has an invalid enumerant value.
- The parameter nbDims is outside the range [4, CUDNN_DIM_MAX], or the total size of the tensor descriptor exceeds the maximum limit of 2 Giga-elements.
3.2.96. cudnnSetTensorNdDescriptorEx()
cudnnStatus_t cudnnSetTensorNdDescriptorEx(
cudnnTensorDescriptor_t tensorDesc,
cudnnTensorFormat_t format,
cudnnDataType_t dataType,
int nbDims,
const int dimA[])Parameters
- Output. Pointer to the tensor descriptor struct to be initialized.
- Input. Tensor format.
- Input. Tensor data type.
- Input. Dimension of the tensor.
Note: Do not use 2 dimensions. Due to historical reasons, the minimum number of dimensions in the filter descriptor is three. For more information, refer to cudnnGetRNNLinLayerBiasParams().
- Input. Array containing the size of each dimension.
3.2.97. cudnnSetTensorTransformDescriptor()
cudnnStatus_t cudnnSetTensorTransformDescriptor( cudnnTensorTransformDescriptor_t transformDesc, const uint32_t nbDims, const cudnnTensorFormat_t destFormat, const int32_t padBeforeA[], const int32_t padAfterA[], const uint32_t foldA[], const cudnnFoldingDirection_t direction);
Parameters
- Output. The tensor transform descriptor to be initialized.
- Input. The dimensionality of the transform operands. Must be greater than 2. For more information, refer to Tensor Descriptor.
- Input. The desired destination format.
- Input. An array that contains the amount of padding that should be added before each dimension. Set to NULL for no padding.
- Input. An array that contains the amount of padding that should be added after each dimension. Set to NULL for no padding.
- Input. An array that contains the folding parameters for each spatial dimension (dimensions 2 and up). Set to NULL for no folding.
- Input. Selects folding or unfolding. This input has no effect when folding parameters are all <= 1. For more information, refer to cudnnFoldingDirection_t.
Returns
- The function was launched successfully.
- The parameter transformDesc is NULL, or if direction is invalid, or nbDims is <= 2.
- If the dimension size requested is larger than maximum dimension size supported (meaning, one of the nbDims is larger than CUDNN_DIM_MAX), or if destFromat is something other than NCHW or NHWC.
3.2.98. cudnnSoftmaxForward()
cudnnStatus_t cudnnSoftmaxForward(
cudnnHandle_t handle,
cudnnSoftmaxAlgorithm_t algorithm,
cudnnSoftmaxMode_t mode,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)All tensor formats are supported for all modes and algorithms with 4 and 5D tensors. Performance is expected to be highest with NCHW fully-packed tensors. For more than 5 dimensions tensors must be packed in their spatial dimensions.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Enumerant to specify the softmax algorithm.
- Input. Enumerant to specify the softmax mode.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to the previously initialized output tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The dimensions n, c, h, w of the input tensor and output tensors differ.
- The datatype of the input tensor and output tensors differ.
- The parameters algorithm or mode have an invalid enumerant value.
- The function failed to launch on the GPU.
3.2.99. cudnnSpatialTfGridGeneratorForward()
cudnnStatus_t cudnnSpatialTfGridGeneratorForward(
cudnnHandle_t handle,
const cudnnSpatialTransformerDescriptor_t stDesc,
const void *theta,
void *grid)Only 2D transformation is supported.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created spatial transformer descriptor object.
- Input. Affine transformation matrix. It should be of size n*2*3 for a 2d transformation, where n is the number of images specified in stDesc.
- Output. A grid of coordinates. It is of size n*h*w*2 for a 2d transformation, where n, h, w is specified in stDesc. In the 4th dimension, the first coordinate is x, and the second coordinate is y.
Returns
- The call was successful.
- At least one of the following conditions are met:
- handle is NULL.
- One of the parameters grid or theta is NULL.
- The function does not support the provided configuration. Refer to the
following examples of non-supported configurations:
- The dimension of the transformed tensor specified in stDesc > 4.
- The function failed to launch on the GPU.
3.2.100. cudnnSpatialTfSamplerForward()
cudnnStatus_t cudnnSpatialTfSamplerForward(
cudnnHandle_t handle,
const cudnnSpatialTransformerDescriptor_t stDesc,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *grid,
const void *beta,
cudnnTensorDescriptor_t yDesc,
void *y)Only 2D transformation is supported.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created spatial transformer descriptor object.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with prior value in the destination tensor as follows:
dstValue = alpha[0]*srcValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. A grid of coordinates generated by cudnnSpatialTfGridGeneratorForward().
- Input. Handle to the previously initialized output tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
Returns
- The call was successful.
- At least one of the following conditions are met:
- handle is NULL.
- One of the parameters x, y or grid is NULL.
- The function does not support the provided configuration. Refer to the
following examples of non-supported configurations:
- The dimension of transformed tensor > 4.
- The function failed to launch on the GPU.
3.2.101. cudnnTransformFilter()
cudnnStatus_t cudnnTransformFilter( cudnnHandle_t handle, const cudnnTensorTransformDescriptor_t transDesc, const void *alpha, const cudnnFilterDescriptor_t srcDesc, const void *srcData, const void *beta, const cudnnFilterDescriptor_t destDesc, void *destData);
This function copies the scaled data from the input filter srcDesc to the output tensor destDesc with a different layout. If the filter descriptors of srcDesc and destDesc have different dimensions, they must be consistent with folding and padding amount and order specified in transDesc.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. A descriptor containing the details of the requested filter transformation. For more information, refer to cudnnTensorTransformDescriptor_t.
-
Input. Pointers, in the host memory, to the scaling factors used to scale the data in the input tensor srcDesc. beta is used to scale the destination tensor, while alpha is used to scale the source tensor. For more information, refer to Scaling Parameters.
The beta scaling value is not honored in the folding and zero-padding cases. Unfolding supports any (alpha, beta).
- Input. Handles to the previously initiated filter descriptors. srcDesc and destDesc must not overlap. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointers, in the host memory, to the data of the tensor described by srcDesc.
- Output. Pointers, in the host memory, to the data of the tensor described by destDesc.
Returns
- The function launched successfully.
- A parameter is uninitialized or initialized incorrectly, or the number of dimensions is different between srcDesc and destDesc.
- The function does not support the provided configuration. Also, in the folding and padding paths, any value other than A=1 and B=0 will result in a CUDNN_STATUS_NOT_SUPPORTED.
- The function failed to launch on the GPU.
3.2.102. cudnnTransformTensor()
cudnnStatus_t cudnnTransformTensor(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)Parameters
- Input. Handle to a previously created cuDNN context.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with prior value in the destination tensor as follows:
dstValue = alpha[0]*srcValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointer to data of the tensor described by the xDesc descriptor.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Output. Pointer to data of the tensor described by the yDesc descriptor.
3.2.103. cudnnTransformTensorEx()
cudnnStatus_t cudnnTransformTensorEx( cudnnHandle_t handle, const cudnnTensorTransformDescriptor_t transDesc, const void *alpha, const cudnnTensorDescriptor_t srcDesc, const void *srcData, const void *beta, const cudnnTensorDescriptor_t destDesc, void *destData);
This function copies the scaled data from the input tensor srcDesc to the output tensor destDesc with a different layout. The tensor descriptors of srcDesc and destDesc should have the same dimensions but need not have the same strides.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. A descriptor containing the details of the requested tensor transformation. For more information, refer to cudnnTensorTransformDescriptor_t.
-
Input. Pointers, in the host memory, to the scaling factors used to scale the data in the input tensor srcDesc. beta is used to scale the destination tensor, while alpha is used to scale the source tensor. For more information, refer to Scaling Parameters.
The beta scaling value is not honored in the folding and zero-padding cases. Unfolding supports any (alpha, beta).
- Input. Handles to the previously initiated tensor descriptors. srcDesc and destDesc must not overlap. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointers, in the host memory, to the data of the tensor described by srcDesc.
- Output. Pointers, in the host memory, to the data of the tensor described by destDesc.
Returns
- The function was launched successfully.
- A parameter is uninitialized or initialized incorrectly, or the number of dimensions is different between srcDesc and destDesc.
- Function does not support the provided configuration. Also, in the folding and padding paths, any value other than A=1 and B=0 will result in a CUDNN_STATUS_NOT_SUPPORTED.
- Function failed to launch on the GPU.
4. cudnn_ops_train.so Library
4.1. API Functions
4.1.1. cudnnActivationBackward()
cudnnStatus_t cudnnActivationBackward(
cudnnHandle_t handle,
cudnnActivationDescriptor_t activationDesc,
const void *alpha,
const cudnnTensorDescriptor_t yDesc,
const void *y,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)In-place operation is allowed for this routine; meaning dy and dx pointers may be equal. However, this requires the corresponding tensor descriptors to be identical (particularly, the strides of the input and output must match for an in-place operation to be allowed).
All tensor formats are supported for 4 and 5 dimensions, however, the best performance is obtained when the strides of yDesc and xDesc are equal and HW-packed. For more than 5 dimensions the tensors must have their spatial dimensions packed.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. Activation descriptor. For more information, refer to cudnnActivationDescriptor_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor yDesc.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyDesc.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. Data pointer to GPU memory associated with the output tensor descriptor xDesc.
- Input. Handle to the previously initialized output differential tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor dxDesc.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- The strides nStride, cStride, hStride and wStride of the input differential tensor and output differential tensor differ and in-place operation is used.
- The function does not support the provided configuration. Refer to the
following examples of non-supported configurations:
- The dimensions n, c, h, and w of the input tensor and output tensor differ.
- The datatype of the input tensor and output tensor differs.
- The strides nStride, cStride, hStride, and wStride of the input tensor and the input differential tensor differ.
- The strides nStride, cStride, hStride, and wStride of the output tensor and the output differential tensor differ.
- The function failed to launch on the GPU.
4.1.2. cudnnBatchNormalizationBackward()
cudnnStatus_t cudnnBatchNormalizationBackward(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
const void *alphaDataDiff,
const void *betaDataDiff,
const void *alphaParamDiff,
const void *betaParamDiff,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnTensorDescriptor_t dxDesc,
void *dx,
const cudnnTensorDescriptor_t bnScaleBiasDiffDesc,
const void *bnScale,
void *resultBnScaleDiff,
void *resultBnBiasDiff,
double epsilon,
const void *savedMean,
const void *savedInvVariance)Only 4D and 5D tensors are supported.
The epsilon value has to be the same during training, backpropagation, and inference.
Higher performance can be obtained when HW-packed tensors are used for all of x, dy, and dx.
For more information, refer to cudnnDeriveBNTensorDescriptor() for the secondary tensor descriptor generation for the parameters used in this function.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient output dx with a prior value in the destination tensor as follows:
dstValue = alphaDataDiff[0]*resultValue + betaDataDiff[0]*priorDstValue
For more information, refer to Scaling Parameters.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient outputs resultBnScaleDiff and resultBnBiasDiff with prior values in the destination tensor as follows:
dstValue = alphaParamDiff[0]*resultValue + betaParamDiff[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Inputs. Handles to the previously initialized tensor descriptors.
- Inputs. Data pointer to GPU memory associated with the tensor descriptor xDesc, for the layer’s x data.
- Inputs. Data pointer to GPU memory associated with the tensor descriptor dyDesc, for the backpropagated differential dy input.
- Inputs/Outputs. Data pointer to GPU memory associated with the tensor descriptor dxDesc, for the resulting differential output with respect to x.
- Input. Shared tensor descriptor for the following five tensors:
bnScale, resultBnScaleDiff,
resultBnBiasDiff, savedMean, and
savedInvVariance. The dimensions for this tensor
descriptor are dependent on normalization mode. For more information,
refer to cudnnDeriveBNTensorDescriptor().
Note: The data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Input. Pointer in the device memory for the batch normalization
scale parameter (in the original paper the quantity
scale is referred to as gamma).
Note: The bnBias parameter is not needed for this layer's computation.
- Outputs. Pointers in device memory for the resulting scale and bias differentials computed by this routine. Note that these scale and bias gradients are weight gradients specific to this batch normalization operation, and by definition are not backpropagated.
- Input. Epsilon value used in batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. The same epsilon value should be used in forward and backward functions.
- Inputs. Optional cache parameters containing saved intermediate
results that were computed during the forward pass. For this to work
correctly, the layer's x and bnScale
data have to remain unchanged until this backward function is called.
Note: Both these parameters can be NULL but only at the same time. It is recommended to use this cache since the memory overhead is relatively small.
Supported configurations
| Data Type Configurations | xDesc | bnScaleBiasMeanVarDesc | alpha, beta | yDesc |
|---|---|---|---|---|
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- Any of the pointers alpha, beta, x, dy, dx, bnScale, resultBnScaleDiff, and resultBnBiasDiff is NULL.
- The number of xDesc, yDesc or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- bnScaleBiasDiffDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of savedMean, savedInvVariance pointers is NULL.
- epsilon value is less than CUDNN_BN_MIN_EPSILON.
- Dimensions or data types mismatch for any pair of xDesc, dyDesc, and dxDesc.
4.1.3. cudnnBatchNormalizationBackwardEx()
cudnnStatus_t cudnnBatchNormalizationBackwardEx (
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
cudnnBatchNormOps_t bnOps,
const void *alphaDataDiff,
const void *betaDataDiff,
const void *alphaParamDiff,
const void *betaParamDiff,
const cudnnTensorDescriptor_t xDesc,
const void *xData,
const cudnnTensorDescriptor_t yDesc,
const void *yData,
const cudnnTensorDescriptor_t dyDesc,
const void *dyData,
const cudnnTensorDescriptor_t dzDesc,
void *dzData,
const cudnnTensorDescriptor_t dxDesc,
void *dxData,
const cudnnTensorDescriptor_t dBnScaleBiasDesc,
const void *bnScaleData,
const void *bnBiasData,
void *dBnScaleData,
void *dBnBiasData,
double epsilon,
const void *savedMean,
const void *savedInvVariance,
const cudnnActivationDescriptor_t activationDesc,
void *workspace,
size_t workSpaceSizeInBytes
void *reserveSpace
size_t reserveSpaceSizeInBytes);- All tensors, namely, x, y, dz, dy and dx must be NHWC-fully packed, and must be of the type CUDNN_DATA_HALF.
- The input parameter mode must be set to CUDNN_BATCHNORM_SPATIAL_PERSISTENT.
- workspace is not NULL.
- Before cuDNN version 8.2.0, the tensor C dimension should always be a multiple of 4. After 8.2.0, the tensor C dimension should be a multiple of 4 only when bnOps is CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION.
- workSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetBatchNormalizationBackwardExWorkspaceSize().
- reserveSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetBatchNormalizationTrainingExReserveSpaceSize().
- The content in reserveSpace stored by cudnnBatchNormalizationForwardTrainingEx() must be preserved.
If workspace is NULL and workSpaceSizeInBytes of zero is passed in, this API will function exactly like the non-extended function cudnnBatchNormalizationBackward.
This workspace is not required to be clean. Moreover, the workspace does not have to remain unchanged between the forward and backward pass, as it is not used for passing any information.
This extended function can accept a *workspace pointer to the GPU workspace, and workSpaceSizeInBytes, the size of the workspace, from the user.
The bnOps input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
Only 4D and 5D tensors are supported. The epsilon value has to be the same during the training, the backpropagation, and the inference.
When the tensor layout is NCHW, higher performance can be obtained when HW-packed tensors are used for x, dy, and dx.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- Input. Mode of operation. Currently, CUDNN_BATCHNORM_OPS_BN_ACTIVATION and CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnBatchNormOps_t. This input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient output dx with a prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient outputs dBnScaleData and dBnBiasData with prior values in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Inputs. Tensor descriptors and pointers in the device memory for the layer's x data, backpropagated gradient input dy, the original forward output y data. yDesc and yData are not needed if bnOps is set to CUDNN_BATCHNORM_OPS_BN, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Inputs. Tensor descriptors and pointers in the device memory for the computed gradient output dz, and dx. dzDesc is not needed when bnOps is CUDNN_BATCHNORM_OPS_BN or CUDNN_BATCHNORM_OPS_BN_ACTIVATION, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Outputs. Tensor descriptors and pointers in the device memory for the computed gradient output dz, and dx. *dzData is not needed when bnOps is CUDNN_BATCHNORM_OPS_BN or CUDNN_BATCHNORM_OPS_BN_ACTIVATION, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
-
Input. Shared tensor descriptor for the following six tensors: bnScaleData, bnBiasData, dBnScaleData, dBnBiasData, savedMean, and savedInvVariance. For more information, refer to cudnnDeriveBNTensorDescriptor().
The dimensions for this tensor descriptor are dependent on normalization mode.Note: The data type of this tensor descriptor must be float for FP16 and FP32 input tensors and double for FP64 input tensors.For more information, refer to cudnnTensorDescriptor_t. - Input. Pointer in the device memory for the batch normalization scale parameter (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, the quantity scale is referred to as gamma).
- Input. Pointers in the device memory for the batch normalization bias parameter (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta). This parameter is used only when activation should be performed.
- Outputs. Pointers in the device memory for the gradients of bnScaleData and bnBiasData, respectively.
- Input. Epsilon value used in batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. The same epsilon value should be used in forward and backward functions.
- Inputs. Optional cache parameters containing saved intermediate results computed during the forward pass. For this to work correctly, the layer's x and bnScaleData, bnBiasData data has to remain unchanged until this backward function is called. Note that both these parameters can be NULL but only at the same time. It is recommended to use this cache since the memory overhead is relatively small.
- Input. Descriptor for the activation operation. When the bnOps input is set to either CUDNN_BATCHNORM_OPS_BN_ACTIVATION or CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL.
- Input. Pointer to the GPU workspace. If workspace is NULL and workSpaceSizeInBytes of zero is passed in, then this API will function exactly like the non-extended function cudnnBatchNormalizationBackward().
- Input. The size of the workspace. It must be large enough to trigger the fast NHWC semi-persistent kernel by this function.
- Input. Pointer to the GPU workspace for the reserveSpace.
- Input. The size of the reserveSpace. It must be equal or larger than the amount required by cudnnGetBatchNormalizationTrainingExReserveSpaceSize().
Supported configurations
| Data Type Configurations | xDesc | bnScaleBiasMeanVarDesc | alpha, beta | yDesc |
|---|---|---|---|---|
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- Any of the pointers alphaDataDiff, betaDataDiff, alphaParamDiff, betaParamDiff, x, dy, dx, bnScale, resultBnScaleDiff, and resultBnBiasDiff is NULL.
- The number of xDesc, yDesc, or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- dBnScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of savedMean, savedInvVariance pointers is NULL.
- epsilon value is less than CUDNN_BN_MIN_EPSILON.
- Dimensions or data types mismatch for any pair of xDesc, dyDesc, or dxDesc.
4.1.4. cudnnBatchNormalizationForwardTraining()
cudnnStatus_t cudnnBatchNormalizationForwardTraining(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
const void *alpha,
const void *beta,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t yDesc,
void *y,
const cudnnTensorDescriptor_t bnScaleBiasMeanVarDesc,
const void *bnScale,
const void *bnBias,
double exponentialAverageFactor,
void *resultRunningMean,
void *resultRunningVariance,
double epsilon,
void *resultSaveMean,
void *resultSaveInvVariance)Only 4D and 5D tensors are supported.
The epsilon value has to be the same during training, backpropagation, and inference.
For the inference phase, use cudnnBatchNormalizationForwardInference.
Higher performance can be obtained when HW-packed tensors are used for both x and y.
Refer to cudnnDeriveBNTensorDescriptor() for the secondary tensor descriptor generation for the parameters used in this function.
Parameters
- handle
- Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- mode
- Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- alpha, beta
-
Inputs. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- xDesc, yDesc
- Tensor descriptors and pointers in device memory for the layer's x and y data. For more information, refer to cudnnTensorDescriptor_t.
- *x
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc, for the layer’s x input data.
- *y
- Input. Data pointer to GPU memory associated with the tensor descriptor yDesc, for the youtput of the batch normalization layer.
- bnScaleBiasMeanVarDesc
- Shared tensor descriptor desc for the secondary tensor that was derived by cudnnDeriveBNTensorDescriptor(). The dimensions for this tensor descriptor are dependent on the normalization mode.
- bnScale, bnBias
- Inputs. Pointers in device memory for the batch normalization scale and bias parameters (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta and scale as gamma). Note that bnBias parameter can replace the previous layer's bias parameter for improved efficiency.
- exponentialAverageFactor
-
Input. Factor used in the moving average computation as follows:
runningMean = runningMean*(1-factor) + newMean*factor
Use a factor=1/(1+n) at N-th call to the function to get the Cumulative Moving Average (CMA) behavior, for example:CMA[n] = (x[1]+...+x[n])/n
For example:CMA[n+1] = (n*CMA[n]+x[n+1])/(n+1) = ((n+1)*CMA[n]-CMA[n])/(n+1) + x[n+1]/(n+1) = CMA[n]*(1-1/(n+1))+x[n+1]*1/(n+1) = CMA[n]*(1-factor) + x(n+1)*factor
- resultRunningMean, resultRunningVariance
- Inputs/Outputs. Running mean and variance tensors (these have the same descriptor as the bias and scale). Both of these pointers can be NULL but only at the same time. The value stored in resultRunningVariance (or passed as an input in inference mode) is the sample variance and is the moving average of variance[x] where the variance is computed either over batch or spatial+batch dimensions depending on the mode. If these pointers are not NULL, the tensors should be initialized to some reasonable values or to 0.
- epsilon
- Input. Epsilon value used in the batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. The same epsilon value should be used in forward and backward functions.
- resultSaveMean, resultSaveInvVariance
- Outputs. Optional cache to save intermediate results computed during the forward pass. These buffers can be used to speed up the backward pass when supplied to the cudnnBatchNormalizationBackward() function. The intermediate results stored in resultSaveMean and resultSaveInvVariance buffers should not be used directly by the user. Depending on the batch normalization mode, the results stored in resultSaveInvVariance may vary. For the cache to work correctly, the input layer data must remain unchanged until the backward function is called. Note that both parameters can be NULL but only at the same time. In such a case, intermediate statistics will not be saved, and cudnnBatchNormalizationBackward() will have to re-compute them. It is recommended to use this cache as the memory overhead is relatively small because these tensors have a much lower product of dimensions than the data tensors.
Supported configurations
| Data Type Configurations | xDesc | bnScaleBiasMeanVarDesc | alpha, beta | yDesc |
|---|---|---|---|---|
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the pointers alpha, beta, x, y, bnScale, and bnBias is NULL.
- The number of xDesc or yDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- bnScaleBiasMeanVarDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of resultSaveMean, resultSaveInvVariance pointers are NULL.
- Exactly one of resultRunningMean, resultRunningInvVariance pointers are NULL.
- epsilon value is less than CUDNN_BN_MIN_EPSILON.
- Dimensions or data types mismatch for xDesc or yDesc.
4.1.5. cudnnBatchNormalizationForwardTrainingEx()
cudnnStatus_t cudnnBatchNormalizationForwardTrainingEx(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
cudnnBatchNormOps_t bnOps,
const void *alpha,
const void *beta,
const cudnnTensorDescriptor_t xDesc,
const void *xData,
const cudnnTensorDescriptor_t zDesc,
const void *zData,
const cudnnTensorDescriptor_t yDesc,
void *yData,
const cudnnTensorDescriptor_t bnScaleBiasMeanVarDesc,
const void *bnScaleData,
const void *bnBiasData,
double exponentialAverageFactor,
void *resultRunningMeanData,
void *resultRunningVarianceData,
double epsilon,
void *saveMean,
void *saveInvVariance,
const cudnnActivationDescriptor_t activationDesc,
void *workspace,
size_t workSpaceSizeInBytes
void *reserveSpace
size_t reserveSpaceSizeInBytes);- All tensors, namely, x, y, dz, dy and dx must be NHWC-fully packed and must be of the type CUDNN_DATA_HALF.
- The input parameter mode must be set to CUDNN_BATCHNORM_SPATIAL_PERSISTENT.
- workspace is not NULL.
- Before cuDNN version 8.2.0, the tensor C dimension should always be a multiple of 4. After 8.2.0, the tensor C dimension should be a multiple of 4 only when bnOps is CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION.
- workSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize().
- reserveSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetBatchNormalizationTrainingExReserveSpaceSize().
- The content in reserveSpace stored by cudnnBatchNormalizationForwardTrainingEx() must be preserved.
If workspace is NULL and workSpaceSizeInBytes of zero is passed in, this API will function exactly like the non-extended function cudnnBatchNormalizationForwardTraining().
This workspace is not required to be clean. Moreover, the workspace does not have to remain unchanged between the forward and backward pass, as it is not used for passing any information.
This extended function can accept a *workspace pointer to the GPU workspace, and workSpaceSizeInBytes, the size of the workspace, from the user.
The bnOps input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
Only 4D and 5D tensors are supported. The epsilon value has to be the same during the training, the backpropagation, and the inference.
When the tensor layout is NCHW, higher performance can be obtained when HW-packed tensors are used for x, dy, and dx.
Parameters
- Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- Input. Mode of operation for the fast NHWC kernel. For more information, refer to cudnnBatchNormOps_t. This input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Tensor descriptors and pointers in device memory for the layer's input x and output y, and for the optional z tensor input for residual addition to the result of the batch normalization operation, prior to the activation. The optional zDes and *zData descriptors are only used when bnOps is CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION, otherwise users may pass NULL. When in use, z should have exactly the same dimension as x and the final output y. For more information, refer to cudnnTensorDescriptor_t.
- Shared tensor descriptor desc for the secondary tensor that was derived by cudnnDeriveBNTensorDescriptor(). The dimensions for this tensor descriptor are dependent on the normalization mode.
- Inputs. Pointers in device memory for the batch normalization scale and bias parameters (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta and scale as gamma). Note that bnBiasData parameter can replace the previous layer's bias parameter for improved efficiency.
- Input. Factor used in the moving average computation as
follows:
runningMean = runningMean*(1-factor) + newMean*factor
Use a factor=1/(1+n) at N-th call to the function to get the Cumulative Moving Average (CMA) behavior, for example:CMA[n] = (x[1]+...+x[n])/n
For example:CMA[n+1] = (n*CMA[n]+x[n+1])/(n+1) = ((n+1)*CMA[n]-CMA[n])/(n+1) + x[n+1]/(n+1) = CMA[n]*(1-1/(n+1))+x[n+1]*1/(n+1) = CMA[n]*(1-factor) + x(n+1)*factor
- Inputs/Outputs. Pointers to the running mean and running variance data. Both these pointers can be NULL but only at the same time. The value stored in resultRunningVarianceData (or passed as an input in inference mode) is the sample variance and is the moving average of variance[x] where the variance is computed either over batch or spatial+batch dimensions depending on the mode. If these pointers are not NULL, the tensors should be initialized to some reasonable values or to 0.
- Input. Epsilon value used in the batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. The same epsilon value should be used in forward and backward functions.
- Outputs. Optional cache parameters containing saved intermediate results computed during the forward pass. For this to work correctly, the layer's x and bnScaleData, bnBiasData data has to remain unchanged until this backward function is called. Note that both these parameters can be NULL but only at the same time. It is recommended to use this cache since the memory overhead is relatively small.
- Input. The tensor descriptor for the activation operation. When the bnOps input is set to either CUDNN_BATCHNORM_OPS_BN_ACTIVATION or CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION then this activation is used, otherwise user may pass NULL.
- Inputs. *workspace is a pointer to the GPU workspace, and workSpaceSizeInBytes is the size of the workspace. When *workspace is not NULL and *workSpaceSizeInBytes is large enough, and the tensor layout is NHWC and the data type configuration is supported, then this function will trigger a new semi-persistent NHWC kernel for batch normalization. The workspace is not required to be clean. Also, the workspace does not need to remain unchanged between the forward and backward passes.
- Input. Pointer to the GPU workspace for the reserveSpace.
- Input. The size of the reserveSpace. Must be equal or larger than the amount required by cudnnGetBatchNormalizationTrainingExReserveSpaceSize().
Supported configurations
| Data Type Configurations | xDesc | bnScaleBiasMeanVarDesc | alpha, beta | yDesc |
|---|---|---|---|---|
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
Returns
- CUDNN_STATUS_SUCCESS
- The computation was performed successfully.
- CUDNN_STATUS_NOT_SUPPORTED
- The function does not support the provided configuration.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- One of the pointers alpha, beta, x, y, bnScaleData, and bnBiasData is NULL.
- The number of xDesc or yDesc tensor descriptor dimensions is not within the [4,5] range (only 4D and 5D tensors are supported).
- bnScaleBiasMeanVarDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of saveMean, saveInvVariance pointers are NULL.
- Exactly one of resultRunningMeanData, resultRunningInvVarianceData pointers are NULL.
- epsilon value is less than CUDNN_BN_MIN_EPSILON.
- Dimensions or data types mismatch for xDesc and yDesc.
4.1.6. cudnnDivisiveNormalizationBackward()
cudnnStatus_t cudnnDivisiveNormalizationBackward(
cudnnHandle_t handle,
cudnnLRNDescriptor_t normDesc,
cudnnDivNormMode_t mode,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *means,
const void *dy,
void *temp,
void *temp2,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx,
void *dMeans)Supported tensor formats are NCHW for 4D and NCDHW for 5D with any non-overlapping non-negative strides. Only 4D and 5D tensors are supported.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Handle to a previously initialized LRN parameter descriptor (this descriptor is used for both LRN and DivisiveNormalization layers).
- Input. DivisiveNormalization layer mode of operation. Currently only CUDNN_DIVNORM_PRECOMPUTED_MEANS is implemented. Normalization is performed using the means input tensor that is expected to be precomputed by the user.
-
Input. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Tensor descriptor and pointers in device memory for the layer's x and means data. Note that the means tensor is expected to be precomputed by the user. It can also contain any valid values (not required to be actual means, and can be for instance a result of a convolution with a Gaussian kernel).
- Input. Tensor pointer in device memory for the layer's dy cumulative loss differential data (error backpropagation).
- Workspace. Temporary tensors in device memory. These are used for computing intermediate values during the backward pass. These tensors do not have to be preserved from forward to backward pass. Both use xDesc as a descriptor.
- Input. Tensor descriptor for dx and dMeans.
- Output. Tensor pointers (in device memory) for the layers resulting in cumulative gradients dx and dMeans (dLoss/dx and dLoss/dMeans). Both share the same descriptor.
Returns
- The computation was performed successfully.
- At least one of the following conditions are met:
- One of the tensor pointers x, dx, temp, tmep2, and dy is NULL.
- Number of any of the input or output tensor dimensions is not within the [4,5] range.
- Either alpha or beta pointer is NULL.
- A mismatch in dimensions between xDesc and dxDesc.
- LRN descriptor parameters are outside of their valid ranges.
- Any of the tensor strides is negative.
- The function does not support the provided configuration, for example, any of the input and output tensor strides mismatch (for the same dimension) is a non-supported configuration.
4.1.7. cudnnDropoutBackward()
cudnnStatus_t cudnnDropoutBackward(
cudnnHandle_t handle,
const cudnnDropoutDescriptor_t dropoutDesc,
const cudnnTensorDescriptor_t dydesc,
const void *dy,
const cudnnTensorDescriptor_t dxdesc,
void *dx,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)Better performance is obtained for fully packed tensors.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created dropout descriptor object.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Pointer to data of the tensor described by the dyDesc descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Output. Pointer to data of the tensor described by the dxDesc descriptor.
- Input. Pointer to user-allocated GPU memory used by this function. It is expected that reserveSpace was populated during a call to cudnnDropoutForward and has not been changed.
- Input. Specifies the size in bytes of the provided memory for the reserve space.
Returns
- The call was successful.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The number of elements of input tensor and output tensors differ.
- The datatype of the input tensor and output tensors differs.
- The strides of the input tensor and output tensors differ and in-place operation is used (i.e., x and y pointers are equal).
- The provided reserveSpaceSizeInBytes is less than the value returned by cudnnDropoutGetReserveSpaceSize.
- cudnnSetDropoutDescriptor has not been called on dropoutDesc with the non-NULLstates argument.
- The function failed to launch on the GPU.
4.1.8. cudnnGetBatchNormalizationBackwardExWorkspaceSize()
cudnnStatus_t cudnnGetBatchNormalizationBackwardExWorkspaceSize(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
cudnnBatchNormOps_t bnOps,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t yDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnTensorDescriptor_t dzDesc,
const cudnnTensorDescriptor_t dxDesc,
const cudnnTensorDescriptor_t dBnScaleBiasDesc,
const cudnnActivationDescriptor_t activationDesc,
size_t *sizeInBytes);
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- Input. Mode of operation for the fast NHWC kernel. For more information, refer to cudnnBatchNormOps_t. This input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
- Tensor descriptors and pointers in the device memory for the layer's x data, back propagated differential dy (inputs), the optional y input data, the optional dz output, and the dx output, which is the resulting differential with respect to x. For more information, refer to cudnnTensorDescriptor_t.
- Input. Shared tensor descriptor for the following six tensors: bnScaleData, bnBiasData, dBnScaleData, dBnBiasData, savedMean, and savedInvVariance. This is the shared tensor descriptor desc for the secondary tensor that was derived by cudnnDeriveBNTensorDescriptor(). The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Input. Descriptor for the activation operation. When the bnOps input is set to either CUDNN_BATCHNORM_OPS_BN_ACTIVATION or CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION, then this activation is used, otherwise user may pass NULL.
- Output. Amount of GPU memory required for the workspace, as determined by this function, to be able to execute the cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize() function with the specified bnOps input setting.
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- Number of xDesc, yDesc or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- dBnScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Dimensions or data types mismatch for any pair of xDesc, dyDesc, or dxDesc.
4.1.9. cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize()
cudnnStatus_t cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
cudnnBatchNormOps_t bnOps,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t zDesc,
const cudnnTensorDescriptor_t yDesc,
const cudnnTensorDescriptor_t bnScaleBiasMeanVarDesc,
const cudnnActivationDescriptor_t activationDesc,
size_t *sizeInBytes);Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- Input. Mode of operation for the fast NHWC kernel. For more information, refer to cudnnBatchNormOps_t. This input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
- Tensor descriptors and pointers in the device memory for the layer's x data, the optional z input data, and the y output. zDesc is only needed when bnOps is CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION, otherwise the user may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Input. Shared tensor descriptor for the following six tensors: bnScaleData, bnBiasData, dBnScaleData, dBnBiasData, savedMean, and savedInvVariance. This is the shared tensor descriptor desc for the secondary tensor that was derived by cudnnDeriveBNTensorDescriptor(). The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Input. Descriptor for the activation operation. When the bnOps input is set to either CUDNN_BATCHNORM_OPS_BN_ACTIVATION or CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL.
- Output. Amount of GPU memory required for the workspace, as determined by this function, to be able to execute the cudnnGetBatchNormalizationForwardTrainingExWorkspaceSize() function with the specified bnOps input setting.
Returns
- CUDNN_STATUS_SUCCESS
- The computation was performed successfully.
- CUDNN_STATUS_NOT_SUPPORTED
- The function does not support the provided configuration.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- Number of xDesc, yDesc or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- dBnScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for spatial, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Dimensions or data types mismatch for xDesc or yDesc.
4.1.10. cudnnGetBatchNormalizationTrainingExReserveSpaceSize()
cudnnStatus_t cudnnGetBatchNormalizationTrainingExReserveSpaceSize(
cudnnHandle_t handle,
cudnnBatchNormMode_t mode,
cudnnBatchNormOps_t bnOps,
const cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t xDesc,
size_t *sizeInBytes);Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (spatial or per-activation). For more information, refer to cudnnBatchNormMode_t.
- Input. Mode of operation for the fast NHWC kernel. For more information, refer to cudnnBatchNormOps_t. This input can be used to set this function to perform either only the batch normalization, or batch normalization followed by activation, or batch normalization followed by element-wise addition and then activation.
- Tensor descriptors for the layer's x data. For more information, refer to cudnnTensorDescriptor_t.
- Input. Descriptor for the activation operation. When the bnOps input is set to either CUDNN_BATCHNORM_OPS_BN_ACTIVATION or CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION then this activation is used, otherwise user may pass NULL.
- Output. Amount of GPU memory reserved.
4.1.11. cudnnGetNormalizationBackwardWorkspaceSize()
cudnnStatus_t
cudnnGetNormalizationBackwardWorkspaceSize(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t yDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnTensorDescriptor_t dzDesc,
const cudnnTensorDescriptor_t dxDesc,
const cudnnTensorDescriptor_t dNormScaleBiasDesc,
const cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t normMeanVarDesc,
size_t *sizeInBytes,
int groupCnt);
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
- Input. Mode of post-operative. Currently CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnNormOps_t. This input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
- Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
- Tensor descriptors and pointers in the device memory for the layer's x data, back propagated differential dy (inputs), the optional y input data, the optional dz output, and the dx output, which is the resulting differential with respect to x. For more information, refer to cudnnTensorDescriptor_t.
- Input. Shared tensor descriptor for the following four tensors: normScaleData, normBiasData, dNormScaleData, dNormBiasData. The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Input. Descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION, then this activation is used, otherwise the user may pass NULL.
- Input. Shared tensor descriptor for the following tensors: savedMean and savedInvVariance. The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Output. Amount of GPU memory required for the workspace, as determined by this function, to be able to execute the cudnnGetNormalizationForwardTrainingWorkspaceSize() function with the specified normOps input setting.
- Input. The number of grouped convolutions. Currently, only 1 is supported.
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
-
At least one of the following conditions are met:
- Number of xDesc, yDesc or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- dNormScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for per-channel, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Dimensions or data types mismatch for any pair of xDesc, dyDesc, or dxDesc.
4.1.12. cudnnGetNormalizationForwardTrainingWorkspaceSize()
cudnnStatus_t
cudnnGetNormalizationForwardTrainingWorkspaceSize(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t zDesc,
const cudnnTensorDescriptor_t yDesc,
const cudnnTensorDescriptor_t normScaleBiasDesc,
const cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t normMeanVarDesc,
size_t *sizeInBytes,
int groupCnt);
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
- Input. Mode of post-operative. Currently CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnNormOps_t. This input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
- Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
- Tensor descriptors and pointers in the device memory for the layer's x data, the optional z input data, and the y output. zDesc is only needed when normOps is CUDNN_NORM_OPS_NORM_ADD_ACTIVATION, otherwise the user may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Input. Shared tensor descriptor for the following tensors: normScaleData and normBiasData. The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Input. Descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION, then this activation is used, otherwise the user may pass NULL.
- Input. Shared tensor descriptor for the following tensors: savedMean and savedInvVariance. The dimensions for this tensor descriptor are dependent on normalization mode. Note that the data type of this tensor descriptor must be float for FP16 and FP32 input tensors, and double for FP64 input tensors.
- Output. Amount of GPU memory required for the workspace, as determined by this function, to be able to execute the cudnnGetNormalizationForwardTrainingWorkspaceSize() function with the specified normOps input setting.
- Input. The number of grouped convolutions. Currently, only 1 is supported.
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
-
At least one of the following conditions are met:
- Number of xDesc, yDesc or zDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- normScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for per-channel, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Dimensions or data types mismatch for xDesc or yDesc.
4.1.13. cudnnGetNormalizationTrainingReserveSpaceSize()
cudnnStatus_t
cudnnGetNormalizationTrainingReserveSpaceSize(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t xDesc,
size_t *sizeInBytes,
int groupCnt);
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
- Input. Mode of post-operative. Currently CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnNormOps_t . This input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
- Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
- Tensor descriptors for the layer's x data. For more information, refer to cudnnTensorDescriptor_t.
- Input. Descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL.
- Output. Amount of GPU memory reserved.
- Input. The number of grouped convolutions. Currently, only 1 is supported.
4.1.14. cudnnLRNCrossChannelBackward()
cudnnStatus_t cudnnLRNCrossChannelBackward(
cudnnHandle_t handle,
cudnnLRNDescriptor_t normDesc,
cudnnLRNMode_t lrnMode,
const void *alpha,
const cudnnTensorDescriptor_t yDesc,
const void *y,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)Supported formats are: positive-strided, NCHW and NHWC for 4D x and y, and only NCDHW DHW-packed for 5D (for both x and y). Only non-overlapping 4D and 5D tensors are supported. NCHW layout is preferred for performance.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. Handle to a previously initialized LRN parameter descriptor.
- Input. LRN layer mode of operation. Currently, only CUDNN_LRN_CROSS_CHANNEL_DIM1 is implemented. Normalization is performed along the tensor's dimA[1].
-
Input. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Tensor descriptor and pointer in device memory for the layer's y data.
- Input. Tensor descriptor and pointer in device memory for the layer's input cumulative loss differential data dy (including error backpropagation).
- Input. Tensor descriptor and pointer in device memory for the layer's x data. Note that these values are not modified during backpropagation.
- Output. Tensor descriptor and pointer in device memory for the layer's resulting cumulative loss differential data dx (including error backpropagation).
Returns
- The computation was performed successfully.
- At least one of the following conditions are met:
- One of the tensor pointers x, y is NULL.
- Number of input tensor dimensions is 2 or less.
- LRN descriptor parameters are outside of their valid ranges.
- One of the tensor parameters is 5D but is not in NCDHW DHW-packed format.
- The function does not support the provided configuration. See the
following for some examples of non-supported configurations:
- Any of the input tensor datatypes is not the same as any of the output tensor datatype.
- Any pairwise tensor dimensions mismatch for x, y, dx, or dy.
- Any tensor parameters strides are negative.
4.1.15. cudnnNormalizationBackward()
cudnnStatus_t
cudnnNormalizationBackward(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const void *alphaDataDiff,
const void *betaDataDiff,
const void *alphaParamDiff,
const void *betaParamDiff,
const cudnnTensorDescriptor_t xDesc,
const void *xData,
const cudnnTensorDescriptor_t yDesc,
const void *yData,
const cudnnTensorDescriptor_t dyDesc,
const void *dyData,
const cudnnTensorDescriptor_t dzDesc,
void *dzData,
const cudnnTensorDescriptor_t dxDesc,
void *dxData,
const cudnnTensorDescriptor_t dNormScaleBiasDesc,
const void *normScaleData,
const void *normBiasData,
void *dNormScaleData,
void *dNormBiasData,
double epsilon,
const cudnnTensorDescriptor_t normMeanVarDesc,
const void *savedMean,
const void *savedInvVariance,
cudnnActivationDescriptor_t activationDesc,
void *workSpace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes,
int groupCnt)Only 4D and 5D tensors are supported.
The epsilon value has to be the same during training, backpropagation, and inference. This workspace is not required to be clean. Moreover, the workspace does not have to remain unchanged between the forward and backward pass, as it is not used for passing any information.
This function can accept a *workspace pointer to the GPU workspace, and workSpaceSizeInBytes, the size of the workspace, from the user.
The normOps input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
When the tensor layout is NCHW, higher performance can be obtained when HW-packed tensors are used for x, dy, or dx.
- All tensors, namely, x, y, dz, dy, and dx must be NHWC-fully packed, and must be of the type CUDNN_DATA_HALF.
- The tensor C dimension should be a multiple of 4.
- The input parameter mode must be set to CUDNN_NORM_PER_CHANNEL.
- The input parameter algo must be set to CUDNN_NORM_ALGO_PERSIST.
- Workspace is not NULL.
- workSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetNormalizationBackwardWorkspaceSize().
- reserveSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetNormalizationTrainingReserveSpaceSize().
- The content in reserveSpace stored by cudnnNormalizationForwardTraining() must be preserved.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
-
Input. Mode of post-operative. Currently CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnNormOps_t. This input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
-
Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient output dx with a prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the gradient outputs dNormScaleData and dNormBiasData with prior values in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Inputs. Tensor descriptors and pointers in the device memory for the layer's x data, backpropagated gradient input dy, the original forward output y data. yDesc and yData are not needed if normOps is set to CUDNN_NORM_OPS_NORM, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Inputs. Tensor descriptors and pointers in the device memory for the computed gradient output dz and dx. dzDesc is not needed when normOps is CUDNN_NORM_OPS_NORM or CUDNN_NORM_OPS_NORM_ACTIVATION, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
- Outputs. Tensor descriptors and pointers in the device memory for the computed gradient output dz and dx. *dzData is not needed when normOps is CUDNN_NORM_OPS_NORM or CUDNN_NORM_OPS_NORM_ACTIVATION, users may pass NULL. For more information, refer to cudnnTensorDescriptor_t.
-
Input. Shared tensor descriptor for the following six tensors: normScaleData, normBiasData, dNormScaleData, and dNormBiasData. The dimensions for this tensor descriptor are dependent on normalization mode.Note: The data type of this tensor descriptor must be float for FP16 and FP32 input tensors and double for FP64 input tensors.
For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointer in the device memory for the normalization scale parameter (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, the quantity scale is referred to as gamma).
- Input. Pointers in the device memory for the normalization bias parameter (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta). This parameter is used only when activation should be performed.
- Outputs. Pointers in the device memory for the gradients of normScaleData and normBiasData, respectively.
- Input. Epsilon value used in normalization formula. Its value should be equal to or greater than zero. The same epsilon value should be used in forward and backward functions.
-
Input. Shared tensor descriptor for the following tensors: savedMean and savedInvVariance. The dimensions for this tensor descriptor are dependent on normalization mode.Note: The data type of this tensor descriptor must be float for FP16 and FP32 input tensors and double for FP64 input tensors.
For more information, refer to cudnnTensorDescriptor_t.
- Inputs. Optional cache parameters containing saved intermediate results computed during the forward pass. For this to work correctly, the layer's x and normScaleData, normBiasData data has to remain unchanged until this backward function is called. Note that both these parameters can be NULL but only at the same time. It is recommended to use this cache since the memory overhead is relatively small.
- Input. Descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL.
- Input. Pointer to the GPU workspace.
- Input. The size of the workspace. It must be large enough to trigger the fast NHWC semi-persistent kernel by this function.
- Input. Pointer to the GPU workspace for the reserveSpace.
- Input. The size of the reserveSpace. It must be equal or larger than the amount required by cudnnGetNormalizationTrainingReserveSpaceSize().
- Input. The number of grouped convolutions. Currently, only 1 is supported.
Returns
- CUDNN_STATUS_SUCCESS
- The computation was performed successfully.
- CUDNN_STATUS_NOT_SUPPORTED
- The function does not support the provided configuration.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- Any of the pointers alphaDataDiff, betaDataDiff, alphaParamDiff, betaParamDiff, xData, dyData, dxData, normScaleData, dNormScaleData, and dNormBiasData is NULL.
- The number of xDesc, yDesc, or dxDesc tensor descriptor dimensions is not within the range of [4,5] (only 4D and 5D tensors are supported).
- dNormScaleBiasDesc dimensions not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for per-channel, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of savedMean, savedInvVariance pointers is NULL.
- epsilon value is less than zero.
- Dimensions or data types mismatch for any pair of xDesc, dyDesc, dxDesc, dNormScaleBiasDesc, or normMeanVarDesc.
4.1.16. cudnnNormalizationForwardTraining()
cudnnStatus_t
cudnnNormalizationForwardTraining(cudnnHandle_t handle,
cudnnNormMode_t mode,
cudnnNormOps_t normOps,
cudnnNormAlgo_t algo,
const void *alpha,
const void *beta,
const cudnnTensorDescriptor_t xDesc,
const void *xData,
const cudnnTensorDescriptor_t normScaleBiasDesc,
const void *normScale,
const void *normBias,
double exponentialAverageFactor,
const cudnnTensorDescriptor_t normMeanVarDesc,
void *resultRunningMean,
void *resultRunningVariance,
double epsilon,
void *resultSaveMean,
void *resultSaveInvVariance,
cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t zDesc,
const void *zData,
const cudnnTensorDescriptor_t yDesc,
void *yData,
void *workspace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes,
int groupCnt);Only 4D and 5D tensors are supported.
The epsilon value has to be the same during training, back propagation, and inference.
For the inference phase, refer to cudnnNormalizationForwardInference().
Higher performance can be obtained when HW-packed tensors are used for both x and y.
- All tensors, namely, xData, yData must be NHWC-fully packed and must be of the type CUDNN_DATA_HALF.
- The tensor C dimension should be a multiple of 4.
- The input parameter mode must be set to CUDNN_NORM_PER_CHANNEL.
- The input parameter algo must be set to CUDNN_NORM_ALGO_PERSIST.
- workspace is not NULL.
- workSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetNormalizationForwardTrainingWorkspaceSize().
- reserveSpaceSizeInBytes is equal to or larger than the amount required by cudnnGetNormalizationTrainingReserveSpaceSize().
- The content in reserveSpace stored by cudnnNormalizationForwardTraining() must be preserved.
This workspace is not required to be clean. Moreover, the workspace does not have to remain unchanged between the forward and backward pass, as it is not used for passing any information. This extended function can accept a *workspace pointer to the GPU workspace, and workSpaceSizeInBytes, the size of the workspace, from the user.
The normOps input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
Only 4D and 5D tensors are supported. The epsilon value has to be the same during the training, the backpropagation, and the inference.
When the tensor layout is NCHW, higher performance can be obtained when HW-packed tensors are used for xData, yData.
Parameters
- Input. Handle to a previously created cuDNN library descriptor. For more information, refer to cudnnHandle_t.
- Input. Mode of operation (per-channel or per-activation). For more information, refer to cudnnNormMode_t.
- Input. Mode of post-operative. Currently CUDNN_NORM_OPS_NORM_ACTIVATION and CUDNN_NORM_OPS_NORM_ADD_ACTIVATION are only supported in the NHWC layout. For more information, refer to cudnnNormOps_t. This input can be used to set this function to perform either only the normalization, or normalization followed by activation, or normalization followed by element-wise addition and then activation.
- Input. Algorithm to be performed. For more information, refer to cudnnNormAlgo_t.
-
Inputs. Pointers to scaling factors (in host memory) used to blend the layer output value with prior value in the destination tensor as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handles to the previously initialized tensor descriptors.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc, for the layer’s x input data.
- Output. Data pointer to GPU memory associated with the tensor descriptor yDesc, for the y output of the normalization layer.
- Input. Tensor descriptors and pointers in device memory for residual addition to the result of the normalization operation, prior to the activation. zDesc and *zData are optional and are only used when normOps is CUDNN_NORM_OPS_NORM_ADD_ACTIVATION, otherwise the user may pass NULL. When in use, z should have exactly the same dimension as xData and the final output yData. For more information, refer to cudnnTensorDescriptor_t.
- Inputs. Tensor descriptors and pointers in device memory for the normalization scale and bias parameters (in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper, bias is referred to as beta and scale as gamma). The dimensions for the tensor descriptor are dependent on the normalization mode.
-
Input. Factor used in the moving average computation as follows:
runningMean = runningMean*(1-factor) + newMean*factor
Use a factor=1/(1+n) at N-th call to the function to get the Cumulative Moving Average (CMA) behavior, for example:CMA[n] = (x[1]+...+x[n])/n
For example:CMA[n+1] = (n*CMA[n]+x[n+1])/(n+1) = ((n+1)*CMA[n]-CMA[n])/(n+1) + x[n+1]/(n+1) = CMA[n]*(1-1/(n+1))+x[n+1]*1/(n+1) = CMA[n]*(1-factor) + x(n+1)*factor
- Inputs. Tensor descriptor used for following tensors: resultRunningMean, resultRunningVariance, resultSaveMean, resultSaveInvVariance.
- Inputs/Outputs. Pointers to the running mean and running variance data. Both these pointers can be NULL but only at the same time. The value stored in resultRunningVariance (or passed as an input in inference mode) is the sample variance and is the moving average of variance[x] where the variance is computed either over batch or spatial+batch dimensions depending on the mode. If these pointers are not NULL, the tensors should be initialized to some reasonable values or to 0.
- Input. Epsilon value used in the normalization formula. Its value should be equal to or greater than zero.
- Outputs. Optional cache parameters containing saved intermediate results computed during the forward pass. For this to work correctly, the layer's x and normScale, normBias data has to remain unchanged until this backward function is called. Note that both these parameters can be NULL but only at the same time. It is recommended to use this cache since the memory overhead is relatively small.
- Input. The tensor descriptor for the activation operation. When the normOps input is set to either CUDNN_NORM_OPS_NORM_ACTIVATION or CUDNN_NORM_OPS_NORM_ADD_ACTIVATION then this activation is used, otherwise the user may pass NULL.
- Inputs. *workspace is a pointer to the GPU workspace, and workSpaceSizeInBytes is the size of the workspace. When *workspace is not NULL and *workSpaceSizeInBytes is large enough, and the tensor layout is NHWC and the data type configuration is supported, then this function will trigger a semi-persistent NHWC kernel for normalization. The workspace is not required to be clean. Also, the workspace does not need to remain unchanged between the forward and backward passes.
- Input. Pointer to the GPU workspace for the reserveSpace.
- Input. The size of the reserveSpace. Must be equal or larger than the amount required by cudnnGetNormalizationTrainingReserveSpaceSize().
- Input. The number of grouped convolutions. Currently, only 1 is supported.
Supported configurations
| Data Type Configurations | xDesc, yDesc, zDesc | normScaleBiasDesc, normMeanVarDesc |
|---|---|---|
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT |
Returns
- The computation was performed successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the pointers alpha, beta, xData, yData, normScale, and normBias is NULL.
- The number of xDesc or yDesc tensor descriptor dimensions is not within the [4,5] range (only 4D and 5D tensors are supported).
- normScaleBiasDesc dimensions are not 1xCx1x1 for 4D and 1xCx1x1x1 for 5D for per-channel mode, and are not 1xCxHxW for 4D and 1xCxDxHxW for 5D for per-activation mode.
- Exactly one of resultSaveMean, resultSaveInvVariance pointers are NULL.
- Exactly one of resultRunningMean, resultRunningInvVariance pointers are NULL.
- epsilon value is less than zero.
- Dimensions or data types mismatch for xDesc or yDesc.
4.1.17. cudnnOpsTrainVersionCheck()
cudnnStatus_t cudnnOpsTrainVersionCheck(void)
4.1.18. cudnnPoolingBackward()
cudnnStatus_t cudnnPoolingBackward(
cudnnHandle_t handle,
const cudnnPoolingDescriptor_t poolingDesc,
const void *alpha,
const cudnnTensorDescriptor_t yDesc,
const void *y,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnTensorDescriptor_t xDesc,
const void *xData,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)cudnnPoolingBackward() allows both x and y data pointers (together with the related tensor descriptor handles) to be NULL for avg-pooling. This could save memory footprint and bandwidth.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized pooling descriptor.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor. Can be NULL for average pooling.
- Input. Data pointer to GPU memory associated with the tensor descriptor yDesc. Can be NULL for average pooling.
- Input. Handle to the previously initialized input differential tensor descriptor. Must be of type FLOAT, DOUBLE, HALF, or BFLOAT16. For more information, refer to cudnnDataType_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyData.
- Input. Handle to the previously initialized output tensor descriptor. Can be NULL for average pooling.
- Input. Data pointer to GPU memory associated with the output tensor descriptor xDesc. Can be NULL for average pooling.
- Input. Handle to the previously initialized output differential tensor descriptor. Must be of type FLOAT, DOUBLE, HALF, or BFLOAT16. For more information, refer to cudnnDataType_t.
- Output. Data pointer to GPU memory associated with the output tensor descriptor dxDesc.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- The dimensions n, c, h, w of the yDesc and dyDesc tensors differ.
- The strides nStride, cStride, hStride, wStride of the yDesc and dyDesc tensors differ.
- The dimensions n, c, h, w of the dxDesc and dxDesc tensors differ.
- The strides nStride, cStride, hStride, wStride of the xDesc and dxDesc tensors differ.
- The datatype of the four tensors differ.
- The function does not support the provided configuration. See the
following for some examples of non-supported configurations:
- The wStride of input tensor or output tensor is not 1.
- The function failed to launch on the GPU.
4.1.19. cudnnSoftmaxBackward()
cudnnStatus_t cudnnSoftmaxBackward(
cudnnHandle_t handle,
cudnnSoftmaxAlgorithm_t algorithm,
cudnnSoftmaxMode_t mode,
const void *alpha,
const cudnnTensorDescriptor_t yDesc,
const void *yData,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)In-place operation is allowed for this routine; meaning, dy and dx pointers may be equal. However, this requires dyDesc and dxDesc descriptors to be identical (particularly, the strides of the input and output must match for in-place operation to be allowed).
All tensor formats are supported for all modes and algorithms with 4 and 5D tensors. Performance is expected to be highest with NCHW fully-packed tensors. For more than 5 dimensions tensors must be packed in their spatial dimensions.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Enumerant to specify the softmax algorithm.
- Input. Enumerant to specify the softmax mode.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor yDesc.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyData.
- Input. Handle to the previously initialized output differential tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor dxDesc.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The dimensions n, c, h, w of the yDesc, dyDesc and dxDesc tensors differ.
- The strides nStride, cStride, hStride, wStride of the yDesc and dyDesc tensors differ.
- The datatype of the three tensors differs.
- The function failed to launch on the GPU.
4.1.20. cudnnSpatialTfGridGeneratorBackward()
cudnnStatus_t cudnnSpatialTfGridGeneratorBackward(
cudnnHandle_t handle,
const cudnnSpatialTransformerDescriptor_t stDesc,
const void *dgrid,
void *dtheta)Only 2d transformation is supported.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created spatial transformer descriptor object.
- Input. Data pointer to GPU memory contains the input differential data.
- Output. Data pointer to GPU memory contains the output differential data.
Returns
- The call was successful.
- At least one of the following conditions are met:
- handle is NULL.
- One of the parameters dgrid or dtheta is NULL.
- The function does not support the provided configuration. See the
following for some examples of non-supported configurations:
- The dimension of the transformed tensor specified in stDesc > 4.
- The function failed to launch on the GPU.
4.1.21. cudnnSpatialTfSamplerBackward()
cudnnStatus_t cudnnSpatialTfSamplerBackward(
cudnnHandle_t handle,
const cudnnSpatialTransformerDescriptor_t stDesc,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx,
const void *alphaDgrid,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const void *grid,
const void *betaDgrid,
void *dgrid)Only 2d transformation is supported.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Previously created spatial transformer descriptor object.
-
Input. Pointers to scaling factors (in host memory) used to blend the source value with prior value in the destination tensor as follows:
dstValue = alpha[0]*srcValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to the previously initialized output differential tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor dxDesc.
-
Input. Pointers to scaling factors (in host memory) used to blend the gradient outputs dgrid with prior value in the destination pointer as follows:
dstValue = alpha[0]*srcValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyDesc.
- Input. A grid of coordinates generated by cudnnSpatialTfGridGeneratorForward().
- Output. Data pointer to GPU memory contains the output differential data.
Returns
- The call was successful.
- At least one of the following conditions are met:
- handle is NULL.
- One of the parameters x, dx, y, dy, grid, dgrid is NULL.
- The dimension of dy differs from those specified in stDesc.
- The function does not support the provided configuration. See the
following for some examples of non-supported configurations:
- The dimension of transformed tensor > 4.
- The function failed to launch on the GPU.
5. cudnn_cnn_infer.so Library
For the backend data and descriptor types, refer to the cuDNN Backend API section.
5.1. Data Type References
5.1.1. Pointer To Opaque Struct Types
5.1.1.1. cudnnConvolutionDescriptor_t
5.1.2. Struct Types
5.1.2.1. cudnnConvolutionBwdDataAlgoPerf_t
Data Members
- The algorithm runs to obtain the associated performance metrics.
- If any error occurs during the workspace allocation or timing of
cudnnConvolutionBackwardData(),
this status will represent that error. Otherwise, this status will be
the return status of cudnnConvolutionBackwardData().
- CUDNN_STATUS_ALLOC_FAILED if any error occurred during workspace allocation or if the provided workspace is insufficient.
- CUDNN_STATUS_INTERNAL_ERROR if any error occurred during timing calculations or workspace deallocation.
- Otherwise, this will be the return status of cudnnConvolutionBackwardData().
- The execution time of cudnnConvolutionBackwardData() (in milliseconds).
- The workspace size (in bytes).
- The determinism of the algorithm.
- The math type provided to the algorithm.
- Reserved space for future properties.
5.1.2.2. cudnnConvolutionFwdAlgoPerf_t
Data Members
- The algorithm runs to obtain the associated performance metrics.
- If any error occurs during the workspace allocation or timing of
cudnnConvolutionForward(), this
status will represent that error. Otherwise, this status will be the
return status of cudnnConvolutionForward().
- CUDNN_STATUS_ALLOC_FAILED if any error occurred during workspace allocation or if the provided workspace is insufficient.
- CUDNN_STATUS_INTERNAL_ERROR if any error occurred during timing calculations or workspace deallocation.
- Otherwise, this will be the return status of cudnnConvolutionForward().
- The execution time of cudnnConvolutionForward() (in milliseconds).
- The workspace size (in bytes).
- The determinism of the algorithm.
- The math type provided to the algorithm.
- Reserved space for future properties.
5.1.3. Enumeration Types
5.1.3.1. cudnnConvolutionBwdDataAlgo_t
Values
- This algorithm expresses the convolution as a sum of matrix products without actually explicitly forming the matrix that holds the input tensor data. The sum is done using the atomic add operation, thus the results are non-deterministic.
- This algorithm expresses the convolution as a matrix product without actually explicitly forming the matrix that holds the input tensor data. The results are deterministic.
- This algorithm uses a Fast-Fourier Transform approach to compute the convolution. A significant memory workspace is needed to store intermediate results. The results are deterministic.
- This algorithm uses the Fast-Fourier Transform approach but splits the inputs into tiles. A significant memory workspace is needed to store intermediate results but less than CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT for large size images. The results are deterministic.
- This algorithm uses the Winograd Transform approach to compute the convolution. A reasonably sized workspace is needed to store intermediate results. The results are deterministic.
- This algorithm uses the Winograd Transform approach to compute the convolution. A significant workspace may be needed to store intermediate results. The results are deterministic.
5.1.3.2. cudnnConvolutionBwdFilterAlgo_t
Values
- This algorithm expresses the convolution as a sum of matrix products without actually explicitly forming the matrix that holds the input tensor data. The sum is done using the atomic add operation, thus the results are non-deterministic.
- This algorithm expresses the convolution as a matrix product without actually explicitly forming the matrix that holds the input tensor data. The results are deterministic.
- This algorithm uses the Fast-Fourier Transform approach to compute the convolution. A significant workspace is needed to store intermediate results. The results are deterministic.
- This algorithm is similar to CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0 but uses some small workspace to precompute some indices. The results are also non-deterministic.
- This algorithm uses the Winograd Transform approach to compute the convolution. A significant workspace may be needed to store intermediate results. The results are deterministic.
- This algorithm uses the Fast-Fourier Transform approach to compute the convolution but splits the input tensor into tiles. A significant workspace may be needed to store intermediate results. The results are deterministic.
5.1.3.3. cudnnConvolutionFwdAlgo_t
Values
- CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM
- This algorithm expresses the convolution as a matrix product without actually explicitly forming the matrix that holds the input tensor data.
- CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM
- This algorithm expresses convolution as a matrix product without actually explicitly forming the matrix that holds the input tensor data, but still needs some memory workspace to precompute some indices in order to facilitate the implicit construction of the matrix that holds the input tensor data.
- CUDNN_CONVOLUTION_FWD_ALGO_GEMM
- This algorithm expresses the convolution as an explicit matrix product. A significant memory workspace is needed to store the matrix that holds the input tensor data.
- CUDNN_CONVOLUTION_FWD_ALGO_DIRECT
- This algorithm expresses the convolution as a direct convolution (for example, without implicitly or explicitly doing a matrix multiplication).
- CUDNN_CONVOLUTION_FWD_ALGO_FFT
- This algorithm uses the Fast-Fourier Transform approach to compute the convolution. A significant memory workspace is needed to store intermediate results.
- CUDNN_CONVOLUTION_FWD_ALGO_FFT_TILING
- This algorithm uses the Fast-Fourier Transform approach but splits the inputs into tiles. A significant memory workspace is needed to store intermediate results but less than CUDNN_CONVOLUTION_FWD_ALGO_FFT for large size images.
- CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD
- This algorithm uses the Winograd Transform approach to compute the convolution. A reasonably sized workspace is needed to store intermediate results.
- CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED
- This algorithm uses the Winograd Transform approach to compute the convolution. A significant workspace may be needed to store intermediate results.
5.1.3.4. cudnnConvolutionMode_t
5.1.3.5. cudnnReorderType_t
typedef enum { CUDNN_DEFAULT_REORDER = 0, CUDNN_NO_REORDER = 1, } cudnnReorderType_t;
5.2. API Functions
5.2.1. cudnnCnnInferVersionCheck()
cudnnStatus_t cudnnCnnInferVersionCheck(void)
5.2.2. cudnnConvolutionBackwardData()
cudnnStatus_t cudnnConvolutionBackwardData(
cudnnHandle_t handle,
const void *alpha,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionBwdDataAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnTensorDescriptor_t dxDesc,
void *dx)Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. Handle to the previously initialized input differential tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the input differential tensor descriptor dyDesc.
- Input. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
- Input. Enumerant that specifies which backward data convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionBwdDataAlgo_t.
- Input. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be NIL.
- Input. Specifies the size in bytes of the provided workSpace.
- Input. Handle to the previously initialized output tensor descriptor.
- Input/Output. Data pointer to GPU memory associated with the output tensor descriptor dxDesc that carries the result.
Supported configurations
| Data Type Configurations | wDesc, dyDesc and dxDesc Data Type | convDesc Data Type |
|---|---|---|
| TRUE_HALF_CONFIG (only supported on architectures with true FP16 support, meaning, compute capability 5.3 and later) | CUDNN_DATA_HALF | CUDNN_DATA_HALF |
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
Supported algorithms
The table below shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_0 (_ALGO_0)
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_1 (_ALGO_1)
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT (_FFT)
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_FFT_TILING (_FFT_TILING)
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD (_WINOGRAD)
- CUDNN_CONVOLUTION_BWD_DATA_ALGO_WINOGRAD_NONFUSED (_WINOGRAD_NONFUSED)
- CUDNN_TENSOR_NCHW (_NCHW)
- CUDNN_TENSOR_NHWC (_NHWC)
- CUDNN_TENSOR_NCHW_VECT_C (_NCHW_VECT_C)
| Filter descriptor wDesc: _NHWC (refer to cudnnTensorFormat_t) | |||||
|---|---|---|---|---|---|
| Algo Name | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
|
_ALGO_0 _ALGO_1 |
NHWC HWC-packed | NHWC HWC-packed | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
||
| Filter descriptor wDesc: _NCHW. | |||||
|---|---|---|---|---|---|
| Algo Name | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
|
_ALGO_0 |
No | NCHW CHW-packed | All except _NCHW_VECT_C. | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _ALGO_1 | Yes | NCHW CHW-packed | All except _NCHW_VECT_C. | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: greater than 0 for all dimensions
convDesc Group Count Support: Greater than 0 |
| _FFT | Yes | NCHW CHW-packed | NCHW HW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 dxDesc feature map height + 2 * convDesc zero-padding height must equal 256 or less dxDesc feature map width + 2 * convDesc zero-padding width must equal 256 or less convDesc vertical and horizontal filter stride must equal 1 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width |
| _FFT_TILING | Yes | NCHW CHW-packed | NCHW HW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG DOUBLE_CONFIG is also supported when the task can be handled by 1D FFT, meaning, one of the filter dimensions, width or height is 1. |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 When neither of wDesc filter dimension is 1, the filter width and height must not be larger than 32 When either of wDesc filter dimension is 1, the largest filter dimension should not exceed 256 convDesc vertical and horizontal filter stride must equal 1 when either the filter width or filter height is 1, otherwise, the stride can be 1 or 2 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width |
| _WINOGRAD | Yes | NCHW CHW-packed | All except _NCHW_VECT_C. | PSEUDO_HALF_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 convDesc vertical and horizontal filter stride must equal 1 wDesc filter height must be 3 wDesc filter width must be 3 |
| _WINOGRAD_NONFUSED | Yes | NCHW CHW-packed | All except _NCHW_VECT_C. | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 convDesc vertical and horizontal filter stride must equal 1 wDesc filter (height, width) must be (3,3) or (5,5) If wDesc filter (height, width) is (5,5) then the data type config TRUE_HALF_CONFIG is not supported |
| Filter descriptor wDesc: _NCHW. | |||||
|---|---|---|---|---|---|
| Algo Name | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
| _ALGO_0 | Yes | NCDHW CDHW-packed | All except _NCDHW_VECT_C. | PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _ALGO_1 | Yes | NCDHW
CDHW-packed |
NCDHW
CDHW-packed |
TRUE_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG PSEUDO_HALF_CONFIG FLOAT_CONFIGDOUBLE_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _FFT_TILING | Yes | NCDHW CDHW-packed | NCDHW DHW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 wDesc filter height must equal 16 or less wDesc filter width must equal 16 or less wDesc filter depth must equal 16 or less convDesc must have all filter strides equal to 1 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width wDesc filter depth must be greater than convDesc zero-padding width |
| Filter descriptor wDesc: _NHWC | |||||
|---|---|---|---|---|---|
| Algo Name (3D Convolutions) | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
| _ALGO_1 | Yes | NDHWC
DHWC-packed |
NDHWC
DHWC-packed |
TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PESUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
Dilation: Greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
Returns
- The operation was launched successfully.
- At least one of the following conditions are met:
- At least one of the following is NULL: handle, dyDesc, wDesc, convDesc, dxDesc, dy, w, dx, alpha, and beta
- wDesc and dyDesc have a non-matching number of dimensions
- wDesc and dxDesc have a non-matching number of dimensions
- wDesc has fewer than three number of dimensions
- wDesc, dxDesc, and dyDesc have a non-matching data type.
- wDesc and dxDesc have a non-matching number of input feature maps per image (or group in case of grouped convolutions).
- dyDesc spatial sizes do not match with the expected size as determined by cudnnGetConvolutionNdForwardOutputDim
- At least one of the following conditions are met:
- dyDesc or dxDesc have a negative tensor striding
- dyDesc, wDesc or dxDesc has a number of dimensions that is not 4 or 5
- The chosen algo does not support the parameters provided; see above for an exhaustive list of parameters that support each algo
- dyDesc or wDesc indicate an output channel count that isn't a multiple of group count (if group count has been set in convDesc).
- An error occurs during the texture binding of texture object creation associated with the filter data or the input differential tensor data.
- The function failed to launch on the GPU.
5.2.3. cudnnConvolutionBiasActivationForward()
cudnnStatus_t cudnnConvolutionBiasActivationForward(
cudnnHandle_t handle,
const void *alpha1,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionFwdAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *alpha2,
const cudnnTensorDescriptor_t zDesc,
const void *z,
const cudnnTensorDescriptor_t biasDesc,
const void *bias,
const cudnnActivationDescriptor_t activationDesc,
const cudnnTensorDescriptor_t yDesc,
void *y)The routine cudnnGetConvolution2dForwardOutputDim() or cudnnGetConvolutionNdForwardOutputDim() can be used to determine the proper dimensions of the output tensor descriptor yDesc with respect to xDesc, convDesc, and wDesc.
Only the CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM algo is enabled with CUDNN_ACTIVATION_IDENTITY. In other words, in the cudnnActivationDescriptor_t structure of the input activationDesc, if the mode of the cudnnActivationMode_t field is set to the enum value CUDNN_ACTIVATION_IDENTITY, then the input cudnnConvolutionFwdAlgo_t of this function cudnnConvolutionBiasActivationForward() must be set to the enum value CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM. For more information, refer to cudnnSetActivationDescriptor().
Device pointer z and y may be pointing to the same buffer, however, x cannot point to the same buffer as z or y.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result of convolution with z and bias as follows:
y = act ( alpha1 * conv(x) + alpha2 * z + bias )
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
- Input. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionFwdAlgo_t.
- Input. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be NIL.
- Input. Specifies the size in bytes of the provided workSpace.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor zDesc.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor biasDesc.
- Input. Handle to a previously initialized activation descriptor. For more information, refer to cudnnActivationDescriptor_t.
- Input. Handle to a previously initialized tensor descriptor.
- Input/Output. Data pointer to GPU memory associated with the tensor descriptor yDesc that carries the result of the convolution.
For the convolution step, this function supports the specific combinations of data types for xDesc, wDesc, convDesc, and yDesc as listed in the documentation of cudnnConvolutionForward(). The following table specifies the supported combinations of data types for x, y, z, bias, and alpha1/alpha2.
| x | w | convDesc | y and z | bias | alpha1/alpha2 |
|---|---|---|---|---|---|
| X_DOUBLE | X_DOUBLE | X_DOUBLE | X_DOUBLE | X_DOUBLE | X_DOUBLE |
| X_FLOAT | X_FLOAT | X_FLOAT | X_FLOAT | X_FLOAT | X_FLOAT |
| X_HALF | X_HALF | X_FLOAT | X_HALF | X_HALF | X_FLOAT |
| X_BFLOAT16 | X_BFLOAT16 | X_FLOAT | X_BFLOAT16 | X_BFLOAT16 | X_FLOAT |
| X_INT8 | X_INT8 | X_INT32 | X_INT8 | X_FLOAT | X_FLOAT |
| X_INT8 | X_INT8 | X_INT32 | X_FLOAT | X_FLOAT | X_FLOAT |
| X_INT8x4 | X_INT8x4 | X_INT32 | X_INT8x4 | X_FLOAT | X_FLOAT |
| X_INT8x4 | X_INT8x4 | X_INT32 | X_FLOAT | X_FLOAT | X_FLOAT |
| X_UINT8 | X_INT8 | X_INT32 | X_INT8 | X_FLOAT | X_FLOAT |
| X_UINT8 | X_INT8 | X_INT32 | X_FLOAT | X_FLOAT | X_FLOAT |
| X_UINT8x4 | X_INT8x4 | X_INT32 | X_INT8x4 | X_FLOAT | X_FLOAT |
| X_UINT8x4 | X_INT8x4 | X_INT32 | X_FLOAT | X_FLOAT | X_FLOAT |
| X_INT8x32 | X_INT8x32 | X_INT32 | X_INT8x32 | X_FLOAT | X_FLOAT |
Returns
- The operation was launched successfully.
- At least one of the following conditions are met:
- At least one of the following is NULL: handle, xDesc, wDesc, convDesc, yDesc, zDesc, biasDesc, activationDesc, xData, wData, yData, zData, bias, alpha1, and alpha2.
- The number of dimensions of xDesc, wDesc, yDesc, and zDesc is not equal to the array length of convDesc + 2.
- The function does not support the provided configuration. Some examples
of non-supported configurations are as follows:
- The mode of activationDesc is not CUDNN_ACTIVATION_RELU or CUDNN_ACTIVATION_IDENTITY.
- The reluNanOpt of activationDesc is not CUDNN_NOT_PROPAGATE_NAN.
- The second stride of biasDesc is not equal to one.
- The first dimension of biasDesc is not equal to one.
- The second dimension of biasDesc and the first dimension of filterDesc are not equal.
- The data type of biasDesc does not correspond to the data type of yDesc as listed in the above data types table.
- zDesc and destDesc do not match.
- The function failed to launch on the GPU.
5.2.4. cudnnConvolutionForward()
cudnnStatus_t cudnnConvolutionForward(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionFwdAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnTensorDescriptor_t yDesc,
void *y)The routine cudnnGetConvolution2dForwardOutputDim() or cudnnGetConvolutionNdForwardOutputDim() can be used to determine the proper dimensions of the output tensor descriptor yDesc with respect to xDesc, convDesc, and wDesc.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to a previously initialized filter descriptor. For more information, refer to cudnnFilterDescriptor_t.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
- Input. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionFwdAlgo_t.
- Input. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be NIL.
- Input. Specifies the size in bytes of the provided workSpace.
- Input. Handle to a previously initialized tensor descriptor.
- Input/Output. Data pointer to GPU memory associated with the tensor descriptor yDesc that carries the result of the convolution.
Supported configurations
This function supports the following combinations of data types for xDesc, wDesc, convDesc, and yDesc.
| Data Type Configurations | xDesc and wDesc | convDesc | yDesc |
|---|---|---|---|
| TRUE_HALF_CONFIG (only supported on architectures with true FP16 support, meaning, compute capability 5.3 and later) | CUDNN_DATA_HALF | CUDNN_DATA_HALF | CUDNN_DATA_HALF |
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT | CUDNN_DATA_HALF |
| PSEUDO_BFLOAT16_CONFIG (only support on architecture with bfloat16 support, meaning, compute capability 8.0 and later) | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT | CUDNN_DATA_BFLOAT16 |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
| INT8_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) | CUDNN_DATA_INT8 | CUDNN_DATA_INT32 | CUDNN_DATA_INT8 |
| INT8_EXT_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) | CUDNN_DATA_INT8 | CUDNN_DATA_INT32 | CUDNN_DATA_FLOAT |
| INT8x4_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) | CUDNN_DATA_INT8x4 | CUDNN_DATA_INT32 | CUDNN_DATA_INT8x4 |
| INT8x4_EXT_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) | CUDNN_DATA_INT8x4 | CUDNN_DATA_INT32 | CUDNN_DATA_FLOAT |
| UINT8_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) |
xDesc: CUDNN_DATA_UINT8 wDesc: CUDNN_DATA_INT8 |
CUDNN_DATA_INT32 | CUDNN_DATA_INT8 |
| UINT8x4_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) |
xDesc: CUDNN_DATA_UINT8x4 wDesc: CUDNN_DATA_INT8x4 |
CUDNN_DATA_INT32 | CUDNN_DATA_INT8x4 |
| UINT8_EXT_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) |
xDesc: CUDNN_DATA_UINT8 wDesc: CUDNN_DATA_INT8 |
CUDNN_DATA_INT32 | CUDNN_DATA_FLOAT |
| UINT8x4_EXT_CONFIG (only supported on architectures with DP4A support, meaning, compute capability 6.1 and later) |
xDesc: CUDNN_DATA_UINT8x4 wDesc: CUDNN_DATA_INT8x4 |
CUDNN_DATA_INT32 | CUDNN_DATA_FLOAT |
| INT8x32_CONFIG (only supported on architectures with IMMA support, meaning compute capability 7.5 and later) | CUDNN_DATA_INT8x32 | CUDNN_DATA_INT32 | CUDNN_DATA_INT8x32 |
Supported algorithms
The table below shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
- CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_GEMM (_IMPLICIT_GEMM)
- CUDNN_CONVOLUTION_FWD_ALGO_IMPLICIT_PRECOMP_GEMM (_IMPLICIT_PRECOMP_GEMM)
- CUDNN_CONVOLUTION_FWD_ALGO_GEMM (_GEMM)
- CUDNN_CONVOLUTION_FWD_ALGO_DIRECT (_DIRECT)
- CUDNN_CONVOLUTION_FWD_ALGO_FFT (_FFT)
- CUDNN_CONVOLUTION_FWD_ALGO_FFT_TILING (_FFT_TILING)
- CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD (_WINOGRAD)
- CUDNN_CONVOLUTION_FWD_ALGO_WINOGRAD_NONFUSED (_WINOGRAD_NONFUSED)
- CUDNN_TENSOR_NCHW (_NCHW)
- CUDNN_TENSOR_NHWC (_NHWC)
- CUDNN_TENSOR_NCHW_VECT_C (_NCHW_VECT_C)
| Filter descriptor wDesc: _NCHW (refer to
cudnnTensorFormat_t)
convDesc Group count support: Greater than 0, for all algos. |
||||
|---|---|---|---|---|
| Algo Name | Tensor Formats Supported for xDesc | Tensor Formats Supported for yDesc | Data Type Configurations Supported | Important |
| _IMPLICIT_GEMM | All except _NCHW_VECT_C. | All except _NCHW_VECT_C. | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: Greater than 0 for all dimensions |
| _IMPLICIT_PRECOMP_GEMM | All except _NCHW_VECT_C. | All except _NCHW_VECT_C. | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: 1 for all dimensions |
| _GEMM | All except _NCHW_VECT_C. | All except _NCHW_VECT_C. | PSEUDO_HALF_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: 1 for all dimensions |
| _FFT | NCHW HW-packed | NCHW HW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
xDesc feature map height + 2 * convDesc zero-padding height must equal 256 or less xDesc feature map width + 2 * convDesc zero-padding width must equal 256 or less convDesc vertical and horizontal filter stride must equal 1 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width |
| _FFT_TILING | PSEUDO_HALF_CONFIG FLOAT_CONFIG DOUBLE_CONFIG is also supported when the task can be handled by 1D FFT, meaning, one of the filter dimensions, width or height is 1. |
Dilation: 1 for all dimensions
When neither of wDesc filter dimension is 1, the filter width and height must not be larger than 32 When either of wDesc filter dimension is 1, the largest filter dimension should not exceed 256 convDesc vertical and horizontal filter stride must equal 1 when either the filter width or filter height is 1, otherwise the stride can be a 1 or 2 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width |
||
| _WINOGRAD | All except_NCHW_VECT_C. | All except_NCHW_VECT_C. | PSEUDO_HALF_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc vertical and horizontal filter stride must equal 1 wDesc filter height must be 3 wDesc filter width must be 3 |
| _WINOGRAD_NONFUSED | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc vertical and horizontal filter stride must equal 1 wDesc filter (height, width) must be (3,3) or (5,5) If wDesc filter (height, width) is (5,5), then data type config TRUE_HALF_CONFIG is not supported. |
||
| _DIRECT | Currently not implemented in cuDNN. | |||
| Filter descriptor wDesc: _NCHWC convDesc Group count support: Greater than 0. |
||||
|---|---|---|---|---|
| Algo Name | xDesc | yDesc | Data Type Configurations Supported | Important |
| _IMPLICIT_GEMM _IMPLICIT_PRECOMP_GEMM |
_NCHW_VECT_C | _NCHW_VECT_C |
INT8x4_CONFIG UINT8x4_CONFIG |
Dilation: 1 for all dimensions |
| _IMPLICIT_PRECOMP_GEMM | _NCHW_VECT_C | _NCHW_VECT_C | INT8x32_CONFIG | Dilation: 1 for all dimensions
Requires compute capability 7.2 or above. |
| Filter descriptor wDesc: _NHWC convDesc Group count support: Greater than 0. |
||||
|---|---|---|---|---|
| Algo Name | xDesc | yDesc | Data Type Configurations Supported | Important |
| _IMPLICIT_GEMM _IMPLICIT_PRECOMP_GEMM |
NHWC fully-packed | NHWC fully-packed | INT8_CONFIG INT8_EXT_CONFIG UINT8_CONFIG UINT8_EXT_CONFIG |
Dilation: 1 for all dimensions
Input and output feature maps must be a multiple of 4. Output features maps can be non-multiple in the case of INT8_EXT_CONFIG or UINT8_EXT_CONFIG. |
|
_IMPLICIT_GEMM _IMPLICIT_PRECOMP_GEMM |
NHWC HWC-packed. |
NHWC HWC-packed. NCHW CHW-packed |
TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
|
| Filter descriptor wDesc: _NCHW convDesc Group count support: Greater than 0, for all algos. |
||||
|---|---|---|---|---|
| Algo Name | xDesc | yDesc | Data Type Configurations Supported | Important |
| _IMPLICIT_GEMM | All except _NCHW_VECT_C. | All except _NCHW_VECT_C. | PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: Greater than 0 for all dimensions |
| _IMPLICIT_PRECOMP_GEMM | Dilation: Greater than 0 for all dimensions | |||
| _FFT_TILING | NCDHW DHW-packed | NCDHW DHW-packed | Dilation: 1 for all dimensions
wDesc filter height must equal 16 or less wDesc filter width must equal 16 or less wDesc filter depth must equal 16 or less convDesc must have all filter strides equal to 1 wDesc filter height must be greater than convDesc zero-padding height wDesc filter width must be greater than convDesc zero-padding width wDesc filter depth must be greater than convDesc zero-padding depth |
|
| Filter descriptor wDesc: _NHWC convDesc Group count support: Greater than 0, for all algos. |
||||
|---|---|---|---|---|
| Algo Name | xDesc | yDesc | Data Type Configurations Supported | Important |
| _IMPLICIT_PRECOMP_GEMM | NDHWC
DHWC-packed |
NDHWC
DHWC-packed |
PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
Dilation: Greater than 0 for all dimensions |
Returns
- The operation was launched successfully.
- At least one of the following conditions are met:
- At least one of the following is NULL: handle, xDesc, wDesc, convDesc, yDesc, xData, w, yData, alpha, and beta
- xDesc and yDesc have a non-matching number of dimensions
- xDesc and wDesc have a non-matching number of dimensions
- xDesc has fewer than three number of dimensions
- xDesc's number of dimensions is not equal to convDesc array length + 2
- xDesc and wDesc have a non-matching number of input feature maps per image (or group in case of grouped convolutions)
- yDesc or wDesc indicate an output channel count that isn't a multiple of group count (if group count has been set in convDesc).
- xDesc, wDesc, and yDesc have a non-matching data type
- For some spatial dimension, wDesc has a spatial size that is larger than the input spatial size (including zero-padding size)
- At least one of the following conditions are met:
- xDesc or yDesc have negative tensor striding
- xDesc, wDesc, or yDesc has a number of dimensions that is not 4 or 5
- yDesc spatial sizes do not match with the expected size as determined by cudnnGetConvolutionNdForwardOutputDim()
- The chosen algo does not support the parameters provided; see above for an exhaustive list of parameters supported for each algo
- An error occurs during the texture object creation associated with the filter data.
- The function failed to launch on the GPU.
5.2.5. cudnnCreateConvolutionDescriptor()
cudnnStatus_t cudnnCreateConvolutionDescriptor(
cudnnConvolutionDescriptor_t *convDesc)
5.2.7. cudnnFindConvolutionBackwardDataAlgorithm()
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithm(
cudnnHandle_t handle,
const cudnnFilterDescriptor_t wDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t dxDesc,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionBwdDataAlgoPerf_t *perfResults)Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdDataAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardDataAlgorithmMaxCount().
- This function is host blocking.
- It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized filter descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- wDesc, dyDesc, or dxDesc is not allocated properly.
- wDesc, dyDesc, or dxDesc has fewer than 1 dimension.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- This function was unable to allocate memory to store sample input, filters and output.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
5.2.8. cudnnFindConvolutionBackwardDataAlgorithmEx()
cudnnStatus_t cudnnFindConvolutionBackwardDataAlgorithmEx(
cudnnHandle_t handle,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t dxDesc,
void *dx,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionBwdDataAlgoPerf_t *perfResults,
void *workSpace,
size_t workSpaceSizeInBytes)Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdDataAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardDataAlgorithmMaxCount().
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized filter descriptor.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the filter descriptor dyDesc.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input/Output. Data pointer to GPU memory associated with the tensor descriptor dxDesc. The content of this tensor will be overwritten with arbitrary values.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A nil pointer is considered a workSpace of 0 bytes.
- Input. Specifies the size in bytes of the provided workSpace.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- wDesc, dyDesc, or dxDesc is not allocated properly.
- wDesc, dyDesc, or dxDesc has fewer than 1 dimension.
- w, dy, or dx is NIL.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
5.2.9. cudnnFindConvolutionForwardAlgorithm()
cudnnStatus_t cudnnFindConvolutionForwardAlgorithm(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const cudnnFilterDescriptor_t wDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t yDesc,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionFwdAlgoPerf_t *perfResults)
Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionFwdAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionForwardAlgorithmMaxCount().
- This function is host blocking.
- It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- xDesc, wDesc, or yDesc are not allocated properly.
- xDesc, wDesc, or yDesc has fewer than 1 dimension.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- This function was unable to allocate memory to store sample input, filters and output.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
5.2.10. cudnnFindConvolutionForwardAlgorithmEx()
cudnnStatus_t cudnnFindConvolutionForwardAlgorithmEx(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t yDesc,
void *y,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionFwdAlgoPerf_t *perfResults,
void *workSpace,
size_t workSpaceSizeInBytes)Algorithms without the CUDNN_TENSOR_OP_MATH availability will only be tried with CUDNN_DEFAULT_MATH, and returned as such.
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionFwdAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionForwardAlgorithmMaxCount().
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to a previously initialized filter descriptor.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input/Output. Data pointer to GPU memory associated with the tensor descriptor yDesc. The content of this tensor will be overwritten with arbitrary values.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A nil pointer is considered a workSpace of 0 bytes.
- Input. Specifies the size in bytes of the provided workSpace.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- xDesc, wDesc, or yDesc are not allocated properly.
- xDesc, wDesc, or yDesc has fewer than 1 dimension.
- x, w, or y is NIL.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
5.2.11. cudnnGetConvolution2dDescriptor()
cudnnStatus_t cudnnGetConvolution2dDescriptor(
const cudnnConvolutionDescriptor_t convDesc,
int *pad_h,
int *pad_w,
int *u,
int *v,
int *dilation_h,
int *dilation_w,
cudnnConvolutionMode_t *mode,
cudnnDataType_t *computeType)Parameters
- Input. Handle to a previously created convolution descriptor.
- Output. Zero-padding height: number of rows of zeros implicitly concatenated onto the top and onto the bottom of input images.
- Output. Zero-padding width: number of columns of zeros implicitly concatenated onto the left and onto the right of input images.
- Output. Vertical filter stride.
- Output. Horizontal filter stride.
- Output. Filter height dilation.
- Output. Filter width dilation.
- Output. Convolution mode.
- Output. Compute precision.
5.2.12. cudnnGetConvolution2dForwardOutputDim()
cudnnStatus_t cudnnGetConvolution2dForwardOutputDim(
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t inputTensorDesc,
const cudnnFilterDescriptor_t filterDesc,
int *n,
int *c,
int *h,
int *w)Each dimension h and w of the output images is computed as follows:
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;
Parameters
- Input. Handle to a previously created convolution descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Output. Number of output images.
- Output. Number of output feature maps per image.
- Output. Height of each output feature map.
- Output. Width of each output feature map.
5.2.13. cudnnGetConvolutionBackwardDataAlgorithmMaxCount()
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithmMaxCount(
cudnnHandle_t handle,
int *count)
5.2.14. cudnnGetConvolutionBackwardDataAlgorithm_v7()
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithm_v7(
cudnnHandle_t handle,
const cudnnFilterDescriptor_t wDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t dxDesc,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionBwdDataAlgoPerf_t *perfResults)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized filter descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- The query was successful.
- At least one of the following conditions are met:
- One of the parameters handle, wDesc, dyDesc, convDesc, dxDesc, perfResults, or returnedAlgoCount is NULL.
- The numbers of feature maps of the input tensor and output tensor differ.
- The dataType of the two tensor descriptors or the filters are different.
- requestedAlgoCount is less than or equal to 0.
5.2.15. cudnnGetConvolutionBackwardDataWorkspaceSize()
cudnnStatus_t cudnnGetConvolutionBackwardDataWorkspaceSize(
cudnnHandle_t handle,
const cudnnFilterDescriptor_t wDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t dxDesc,
cudnnConvolutionBwdDataAlgo_t algo,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized filter descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. Enumerant that specifies the chosen convolution algorithm.
- Output. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The numbers of feature maps of the input tensor and output tensor differ.
- The dataType of the two tensor descriptors or the filter are different.
- The combination of the tensor descriptors, filter descriptor and convolution descriptor is not supported for the specified algorithm.
5.2.16. cudnnGetConvolutionForwardAlgorithmMaxCount()
cudnnStatus_t cudnnGetConvolutionForwardAlgorithmMaxCount(
cudnnHandle_t handle,
int *count)
5.2.17. cudnnGetConvolutionForwardAlgorithm_v7()
cudnnStatus_t cudnnGetConvolutionForwardAlgorithm_v7(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const cudnnFilterDescriptor_t wDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t yDesc,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionFwdAlgoPerf_t *perfResults)
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Handle to a previously initialized convolution filter descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized output tensor descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- The query was successful.
- At least one of the following conditions are met:
- One of the parameters handle, xDesc, wDesc, convDesc, yDesc, perfResults, or returnedAlgoCount is NULL.
- Either yDesc or wDesc have different dimensions from xDesc.
- The data types of tensors xDesc, yDesc or wDesc are not all the same.
- The number of feature maps in xDesc and wDesc differs.
- The tensor xDesc has a dimension smaller than 3.
- requestedAlgoCount is less than or equal to 0.
5.2.18. cudnnGetConvolutionForwardWorkspaceSize()
cudnnStatus_t cudnnGetConvolutionForwardWorkspaceSize(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const cudnnFilterDescriptor_t wDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t yDesc,
cudnnConvolutionFwdAlgo_t algo,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized x tensor descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to the previously initialized y tensor descriptor.
- Input. Enumerant that specifies the chosen convolution algorithm.
- Output. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- One of the parameters handle, xDesc, wDesc, convDesc, or yDesc is NULL.
- The tensor yDesc or wDesc are not of the same dimension as xDesc.
- The tensor xDesc, yDesc or wDesc are not of the same data type.
- The numbers of feature maps of the tensor xDesc and wDesc differ.
- The tensor xDesc has a dimension smaller than 3.
- The combination of the tensor descriptors, filter descriptor and convolution descriptor is not supported for the specified algorithm.
5.2.21. cudnnGetConvolutionNdDescriptor()
cudnnStatus_t cudnnGetConvolutionNdDescriptor(
const cudnnConvolutionDescriptor_t convDesc,
int arrayLengthRequested,
int *arrayLength,
int padA[],
int filterStrideA[],
int dilationA[],
cudnnConvolutionMode_t *mode,
cudnnDataType_t *dataType)Parameters
- Input/Output. Handle to a previously created convolution descriptor.
- Input. Dimension of the expected convolution descriptor. It is also the minimum size of the arrays padA, filterStrideA, and dilationA in order to be able to hold the results.
- Output. Actual dimension of the convolution descriptor.
- Output. Array of dimension of at least arrayLengthRequested that will be filled with the padding parameters from the provided convolution descriptor.
- Output. Array of dimension of at least arrayLengthRequested that will be filled with the filter stride from the provided convolution descriptor.
- Output. Array of dimension of at least arrayLengthRequested that will be filled with the dilation parameters from the provided convolution descriptor.
- Output. Convolution mode of the provided descriptor.
- Output. Datatype of the provided descriptor.
5.2.22. cudnnGetConvolutionNdForwardOutputDim()
cudnnStatus_t cudnnGetConvolutionNdForwardOutputDim(
const cudnnConvolutionDescriptor_t convDesc,
const cudnnTensorDescriptor_t inputTensorDesc,
const cudnnFilterDescriptor_t filterDesc,
int nbDims,
int tensorOuputDimA[])
outputDim = 1 + ( inputDim + 2*pad - (((filterDim-1)*dilation)+1) )/convolutionStride;
Parameters
- Input. Handle to a previously created convolution descriptor.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. Dimension of the output tensor.
- Output. Array of dimensions nbDims that contains on exit of this routine the sizes of the output tensor.
Returns
- At least one of the following conditions are met:
- One of the parameters convDesc, inputTensorDesc, and filterDesc is nil.
- The dimension of the filter descriptor filterDesc is different from the dimension of input tensor descriptor inputTensorDesc.
- The dimension of the convolution descriptor is different from the dimension of input tensor descriptor inputTensorDesc-2.
- The features map of the filter descriptor filterDesc is different from the one of input tensor descriptor inputTensorDesc.
- The size of the dilated filter filterDesc is larger than the padded sizes of the input tensor.
- The dimension nbDims of the output array is negative or greater than the dimension of input tensor descriptor inputTensorDesc.
- The routine exited successfully.
5.2.23. cudnnGetConvolutionReorderType()
cudnnStatus_t cudnnGetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t *reorderType);
Parameters
- Input. The convolution descriptor from which the reorder type should be retrieved.
- Output. The retrieved reorder type. For more information, refer to cudnnReorderType_t.
5.2.24. cudnnGetFoldedConvBackwardDataDescriptors()
cudnnStatus_t cudnnGetFoldedConvBackwardDataDescriptors(const cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, const cudnnTensorDescriptor_t diffDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnTensorDescriptor_t gradDesc, const cudnnTensorFormat_t transformFormat, cudnnFilterDescriptor_t foldedFilterDesc, cudnnTensorDescriptor_t paddedDiffDesc, cudnnConvolutionDescriptor_t foldedConvDesc, cudnnTensorDescriptor_t foldedGradDesc, cudnnTensorTransformDescriptor_t filterFoldTransDesc, cudnnTensorTransformDescriptor_t diffPadTransDesc, cudnnTensorTransformDescriptor_t gradFoldTransDesc, cudnnTensorTransformDescriptor_t gradUnfoldTransDesc) ;
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Filter descriptor before folding.
- Input. Diff descriptor before folding.
- Input. Convolution descriptor before folding.
- Input. Gradient descriptor before folding.
- Input. Transform format for folding.
- Output. Folded filter descriptor.
- Output. Padded Diff descriptor.
- Output. Folded convolution descriptor.
- Output. Folded gradient descriptor.
- Output. Folding transform descriptor for filter.
- Output. Folding transform descriptor for Desc.
- Output. Folding transform descriptor for gradient.
- Output. Unfolding transform descriptor for folded gradient.
5.2.25. cudnnIm2Col()
cudnnStatus_t cudnnIm2Col(
cudnnHandle_t handle,
cudnnTensorDescriptor_t srcDesc,
const void *srcData,
cudnnFilterDescriptor_t filterDesc,
cudnnConvolutionDescriptor_t convDesc,
void *colBuffer)- batch_size is srcDesc first dimension
- y_height/y_width are computed from cudnnGetConvolutionNdForwardOutputDim()
- input_channels is srcDesc second dimension (when in NCHW layout)
- filter_height/filter_width are wDesc third and fourth dimension
The A matrix is stored in format HW fully-packed in GPU memory.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to a previously initialized tensor descriptor.
- Input. Data pointer to GPU memory associated with the input tensor descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. Handle to a previously initialized convolution descriptor.
- Output. Data pointer to GPU memory storing the output matrix.
5.2.26. cudnnReorderFilterAndBias()
cudnnStatus_t cudnnReorderFilterAndBias( cudnnHandle_t handle, const cudnnFilterDescriptor_t filterDesc, cudnnReorderType_t reorderType, const void *filterData, void *reorderedFilterData, int reorderBias, const void *biasData, void *reorderedBiasData);
Filter and bias tensors with data type CUDNN_DATA_INT8x32 (also implying tensor format CUDNN_TENSOR_NCHW_VECT_C) requires permutation of output channel axes in order to take advantage of the Tensor Core IMMA instruction. This is done in every cudnnConvolutionForward() and cudnnConvolutionBiasActivationForward() call when the reorder type attribute of the convolution descriptor is set to CUDNN_DEFAULT_REORDER. Users can avoid the repeated reordering kernel call by first using this call to reorder the filter and bias tensor and call the convolution forward APIs with reorder type set to CUDNN_NO_REORDER.
For example, convolutions in a neural network of multiple layers can require reordering of kernels at every layer, which can take up a significant fraction of the total inference time. Using this function, the reordering can be done one time on the filter and bias data. This is followed by the convolution operations at the multiple layers, which enhance the inference time.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Descriptor for the kernel dataset.
- Input. Setting to either perform reordering or not. For more information, refer to cudnnReorderType_t.
- Input. Pointer to the filter (kernel) data location in the device memory.
- Output. Pointer to the location in the device memory where the reordered filter data will be written to, by this function. This tensor has the same dimensions as filterData.
- Input. If > 0, then reorders the bias data also. If <= 0 then does not perform reordering operations on the bias data.
- Input. Pointer to the bias data location in the device memory.
- Output. Pointer to the location in the device memory where the reordered bias data will be written to, by this function. This tensor has the same dimensions as biasData.
Returns
- Reordering was successful.
- Either the reordering of the filter data or of the bias data failed.
- The handle, filter descriptor, filter data, or reordered data is NULL. Or, if the bias reordering is requested (reorderBias > 0), the bias data or reordered bias data is NULL. This status can also be returned if the filter dimension size is not 4.
- Filter descriptor data type is not CUDNN_DATA_INT8x32; the filter descriptor tensor is not in a vectorized layout (CUDNN_TENSOR_NCHW_VECT_C).
5.2.27. cudnnSetConvolution2dDescriptor()
cudnnStatus_t cudnnSetConvolution2dDescriptor(
cudnnConvolutionDescriptor_t convDesc,
int pad_h,
int pad_w,
int u,
int v,
int dilation_h,
int dilation_w,
cudnnConvolutionMode_t mode,
cudnnDataType_t computeType)Parameters
- Input/Output. Handle to a previously created convolution descriptor.
- Input. Zero-padding height: number of rows of zeros implicitly concatenated onto the top and onto the bottom of input images.
- Input. Zero-padding width: number of columns of zeros implicitly concatenated onto the left and onto the right of input images.
- Input. Vertical filter stride.
- Input. Horizontal filter stride.
- Input. Filter height dilation.
- Input. Filter width dilation.
- Input. Selects between CUDNN_CONVOLUTION and CUDNN_CROSS_CORRELATION.
- Input. Compute precision.
Returns
- The object was set successfully.
- At least one of the following conditions are met:
- The descriptor convDesc is NIL.
- One of the parameters pad_h, pad_w is strictly negative.
- One of the parameters u, v is negative or zero.
- One of the parameters dilation_h, dilation_w is negative or zero.
- The parameter mode has an invalid enumerant value.
5.2.29. cudnnSetConvolutionMathType()
cudnnStatus_t cudnnSetConvolutionMathType(
cudnnConvolutionDescriptor_t convDesc,
cudnnMathType_t mathType)
5.2.30. cudnnSetConvolutionNdDescriptor()
cudnnStatus_t cudnnSetConvolutionNdDescriptor(
cudnnConvolutionDescriptor_t convDesc,
int arrayLength,
const int padA[],
const int filterStrideA[],
const int dilationA[],
cudnnConvolutionMode_t mode,
cudnnDataType_t dataType)Parameters
- Input/Output. Handle to a previously created convolution descriptor.
- Input. Dimension of the convolution.
- Input. Array of dimension arrayLength containing the zero-padding size for each dimension. For every dimension, the padding represents the number of extra zeros implicitly concatenated at the start and at the end of every element of that dimension.
- Input. Array of dimension arrayLength containing the filter stride for each dimension. For every dimension, the filter stride represents the number of elements to slide to reach the next start of the filtering window of the next point.
- Input. Array of dimension arrayLength containing the dilation factor for each dimension.
- Input. Selects between CUDNN_CONVOLUTION and CUDNN_CROSS_CORRELATION.
- Input. Selects the data type in which the computation will be
done.
Note:CUDNN_DATA_HALF in cudnnSetConvolutionNdDescriptor() with HALF_CONVOLUTION_BWD_FILTER is not recommended as it is known to not be useful for any practical use case for training and will be considered to be blocked in a future cuDNN release. The use of CUDNN_DATA_HALF for input tensors in cudnnSetTensorNdDescriptor() and CUDNN_DATA_FLOAT in cudnnSetConvolutionNdDescriptor() with HALF_CONVOLUTION_BWD_FILTER is recommended and is used with the automatic mixed precision (AMP) training in many well known deep learning frameworks.
Returns
- The object was set successfully.
- At least one of the following conditions are met:
- The descriptor convDesc is NIL.
- The arrayLengthRequest is negative.
- The enumerant mode has an invalid value.
- The enumerant datatype has an invalid value.
- One of the elements of padA is strictly negative.
- One of the elements of strideA is negative or zero.
- One of the elements of dilationA is negative or zero.
- At least one of the following conditions are met:
- The arrayLengthRequest is greater than CUDNN_DIM_MAX.
5.2.31. cudnnSetConvolutionReorderType()
cudnnStatus_t cudnnSetConvolutionReorderType( cudnnConvolutionDescriptor_t convDesc, cudnnReorderType_t reorderType);
Parameters
- Input. The convolution descriptor for which the reorder type should be set.
- Input. Set the reorder type to this value. For more information, refer to cudnnReorderType_t.
6. cudnn_cnn_train.so Library
For the backend data and descriptor types, refer to the cuDNN Backend API section.
6.1. Data Type References
6.1.1. Pointer To Opaque Struct Types
6.1.1.1. cudnnFusedOpsConstParamPack_t
6.1.1.2. cudnnFusedOpsPlan_t
6.1.1.3. cudnnFusedOpsVariantParamPack_t
6.1.2. Struct Types
6.1.2.1. cudnnConvolutionBwdFilterAlgoPerf_t
Data Members
- The algorithm runs to obtain the associated performance metrics.
- If any error occurs during the workspace allocation or timing of
cudnnConvolutionBackwardFilter(), this status will represent that error. Otherwise, this
status will be the return status of cudnnConvolutionBackwardFilter().
- CUDNN_STATUS_ALLOC_FAILED if any error occurred during workspace allocation or if the provided workspace is insufficient.
- CUDNN_STATUS_INTERNAL_ERROR if any error occurred during timing calculations or workspace deallocation.
- Otherwise, this will be the return status of cudnnConvolutionBackwardFilter().
- The execution time of cudnnConvolutionBackwardFilter() (in milliseconds).
- The workspace size (in bytes).
- The determinism of the algorithm.
- The math type provided to the algorithm.
- Reserved space for future properties.
6.1.3. Enumeration Types
6.1.3.1. cudnnFusedOps_t
Members and Descriptions
-
On a per-channel basis, it performs these operations in this order: scale, add bias, activation, convolution, and generate batchnorm statistics.
-
On a per-channel basis, it performs these operations in this order: scale, add bias, activation, convolution backward weights, and generate batchnorm statistics.
- Computes the equivalent scale and bias from ySum, ySqSum and learned scale, bias. Optionally, update running statistics and generate saved stats.
- Computes the equivalent scale and bias from the learned running statistics and the learned scale, bias.
- On a per-channel basis, performs these operations in this order: convolution, scale, add bias, element-wise addition with another tensor, and activation.
- On a per-channel basis, performs these operations in this order: scale and bias on one tensor, scale and bias on a second tensor, element-wise addition of these two tensors, and on the resulting tensor performs activation and generates activation bit mask.
- On a per-channel basis, performs these operations in this order: backward activation, fork (meaning, write out gradient for the residual branch), and backward batch norm.
6.1.3.2. cudnnFusedOpsConstParamLabel_t
typedef enum { CUDNN_PARAM_XDESC = 0, CUDNN_PARAM_XDATA_PLACEHOLDER = 1, CUDNN_PARAM_BN_MODE = 2, CUDNN_PARAM_BN_EQSCALEBIAS_DESC = 3, CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER = 4, CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER = 5, CUDNN_PARAM_ACTIVATION_DESC = 6, CUDNN_PARAM_CONV_DESC = 7, CUDNN_PARAM_WDESC = 8, CUDNN_PARAM_WDATA_PLACEHOLDER = 9, CUDNN_PARAM_DWDESC = 10, CUDNN_PARAM_DWDATA_PLACEHOLDER = 11, CUDNN_PARAM_YDESC = 12, CUDNN_PARAM_YDATA_PLACEHOLDER = 13, CUDNN_PARAM_DYDESC = 14, CUDNN_PARAM_DYDATA_PLACEHOLDER = 15, CUDNN_PARAM_YSTATS_DESC = 16, CUDNN_PARAM_YSUM_PLACEHOLDER = 17, CUDNN_PARAM_YSQSUM_PLACEHOLDER = 18, CUDNN_PARAM_BN_SCALEBIAS_MEANVAR_DESC = 19, CUDNN_PARAM_BN_SCALE_PLACEHOLDER = 20, CUDNN_PARAM_BN_BIAS_PLACEHOLDER = 21, CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER = 22, CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER = 23, CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER = 24, CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER = 25, CUDNN_PARAM_ZDESC = 26, CUDNN_PARAM_ZDATA_PLACEHOLDER = 27, CUDNN_PARAM_BN_Z_EQSCALEBIAS_DESC = 28, CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER = 29, CUDNN_PARAM_BN_Z_EQBIAS_PLACEHOLDER = 30, CUDNN_PARAM_ACTIVATION_BITMASK_DESC = 31, CUDNN_PARAM_ACTIVATION_BITMASK_PLACEHOLDER = 32, CUDNN_PARAM_DXDESC = 33, CUDNN_PARAM_DXDATA_PLACEHOLDER = 34, CUDNN_PARAM_DZDESC = 35, CUDNN_PARAM_DZDATA_PLACEHOLDER = 36, CUDNN_PARAM_BN_DSCALE_PLACEHOLDER = 37, CUDNN_PARAM_BN_DBIAS_PLACEHOLDER = 38, } cudnnFusedOpsConstParamLabel_t;
| Short Form Used | Stands For |
|---|---|
| Setter | cudnnSetFusedOpsConstParamPackAttribute() |
| Getter | cudnnGetFusedOpsConstParamPackAttribute() |
| X_PointerPlaceHolder_t | cudnnFusedOpsPointerPlaceHolder_t |
| X_ prefix in the Attribute column | Stands for CUDNN_PARAM_ in the enumerator name |
| For the attribute CUDNN_FUSED_SCALE_BIAS_ACTIVATION_CONV_BNSTATS in cudnnFusedOpsConstParamLabel_t | |||
|---|---|---|---|
| Attribute | Expected Descriptor Type Passed in, in the Setter | Description | Default Value After Creation |
| X_XDESC | In the setter, the *param should be xDesc, a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout, and datatype of the x (input) tensor. | NULL |
| X_XDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether xData pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_MODE | In the setter, the *param should be a pointer to a previously initialized cudnnBatchNormMode_t*. | Describes the mode of operation for the scale, bias and the statistics.
As of cuDNN 7.6.0, only CUDNN_BATCHNORM_SPATIAL and CUDNN_BATCHNORM_SPATIAL_PERSISTENT are supported, meaning, scale, bias, and statistics are all per-channel. |
CUDNN_BATCHNORM_PER_ACTIVATION |
| X_BN_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout, and datatype of the batchNorm equivalent scale and bias tensors. The shapes must match the mode specified in CUDNN_PARAM_BN_MODE. If set to NULL, both scale and bias operation will become a NOP. | NULL |
| X_BN_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent scale pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the scale operation becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_EQBIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent bias pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the bias operation becomes a NOP. |
CUDNN_PTR_NULL |
| X_ACTIVATION_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnActivationDescriptor_t*. | Describes the activation operation.
As of cuDNN 7.6.0, only activation modes of CUDNN_ACTIVATION_RELU and CUDNN_ACTIVATION_IDENTITY are supported. If set to NULL or if the activation mode is set to CUDNN_ACTIVATION_IDENTITY, then the activation in the op sequence becomes a NOP. |
NULL |
| X_CONV_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnConvolutionDescriptor_t*. | Describes the convolution operation. | NULL |
| X_WDESC | In the setter, the *param should be a pointer to a previously initialized cudnnFilterDescriptor_t*. | Filter descriptor describing the size, layout and datatype of the w (filter) tensor. | NULL |
| X_WDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether w (filter) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_YDESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the y (output) tensor. | NULL |
| X_YDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether y (output) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_YSTATS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the sum of
y and sum of y square tensors.
The shapes need to match the mode specified in
CUDNN_PARAM_BN_MODE.
If set to NULL, the y statistics generation operation will become a NOP. |
NULL |
| X_YSUM_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether sum of y pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, the y statistics generation operation will become a NOP. |
CUDNN_PTR_NULL |
| X_YSQSUM_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether sum of y square pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, the y statistics generation operation will become a NOP. |
CUDNN_PTR_NULL |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and need to be at least element-aligned or 16 bytes-aligned, respectively.
| Parameter | Condition |
|---|---|
| Device compute capability | Need to be one of 7.0, 7.2 or 7.5. |
| CUDNN_PARAM_XDESC CUDNN_PARAM_XDATA_PLACEHOLDER |
Tensor is 4 dimensional
Datatype is CUDNN_DATA_HALF Layout is NHWC fully packed Alignment is CUDNN_PTR_16B_ALIGNED Tensor’s C dimension is a multiple of 8. |
| CUDNN_PARAM_BN_EQSCALEBIAS_DESC CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER |
If either one of scale and bias operation is not turned into a
NOP:
Tensor is 4 dimensional with shape 1xCx1x1 Datatype is CUDNN_DATA_HALF Layout is fully packed Alignment is CUDNN_PTR_16B_ALIGNED |
| CUDNN_PARAM_CONV_DESC CUDNN_PARAM_WDESC CUDNN_PARAM_WDATA_PLACEHOLDER |
Convolution descriptor’s mode needs to be
CUDNN_CROSS_CORRELATION.
Convolution descriptor’s dataType needs to be CUDNN_DATA_FLOAT. Convolution descriptor’s dilationA is (1,1). Convolution descriptor’s group count needs to be 1. Convolution descriptor’s mathType needs to be CUDNN_TENSOR_OP_MATH or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION. Filter is in NHWC layout Filter’s data type is CUDNN_DATA_HALF Filter’s K dimension is a multiple of 32 Filter size RxS is either 1x1 or 3x3 If filter size RxS is 1x1, convolution descriptor’s padA needs to be (0,0) and filterStrideA needs to be (1,1). Filter’s alignment is CUDNN_PTR_16B_ALIGNED |
| CUDNN_PARAM_YDESC CUDNN_PARAM_YDATA_PLACEHOLDER |
Tensor is 4 dimensional
Datatype is CUDNN_DATA_HALF Layout is NHWC fully packed Alignment is CUDNN_PTR_16B_ALIGNED |
| CUDNN_PARAM_YSTATS_DESC CUDNN_PARAM_YSUM_PLACEHOLDER CUDNN_PARAM_YSQSUM_PLACEHOLDER |
If the generate statistics operation is not turned into a
NOP:
Tensor is 4 dimensional with shape 1xKx1x1 Datatype is CUDNN_DATA_FLOAT Layout is fully packed Alignment is CUDNN_PTR_16B_ALIGNED |
| For the attribute CUDNN_FUSED_SCALE_BIAS_ACTIVATION_WGRAD in cudnnFusedOpsConstParamLabel_t | |||
|---|---|---|---|
| Attribute | Expected Descriptor Type Passed in, in the Setter | Description | Default Value After Creation |
| X_XDESC | In the setter, the *param should be xDesc, a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout and datatype of the x (input) tensor | NULL |
| X_XDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether xData pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_MODE | In the setter, the *param should be a pointer to a previously initialized cudnnBatchNormMode_t*. | Describes the mode of operation for the scale, bias and the statistics.
As of cuDNN 7.6.0, only CUDNN_BATCHNORM_SPATIAL and CUDNN_BATCHNORM_SPATIAL_PERSISTENT are supported, meaning, scale, bias, and statistics are all per-channel. |
CUDNN_BATCHNORM_PER_ACTIVATION |
| X_BN_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout and datatype of the batchNorm equivalent scale and bias tensors. The shapes must match the mode specified in CUDNN_PARAM_BN_MODE. If set to NULL, both scale and bias operation will become a NOP. | NULL |
| X_BN_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent scale pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the scale operation becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_EQBIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent bias pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the bias operation becomes a NOP. |
CUDNN_PTR_NULL |
| X_ACTIVATION_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnActivationDescriptor_t*. | Describes the activation operation.
As of cuDNN 7.6.0, only the activation mode of CUDNN_ACTIVATION_RELU and CUDNN_ACTIVATION_IDENTITY is supported. If set to NULL or if the activation mode is set to CUDNN_ACTIVATION_IDENTITY, then the activation in the op sequence becomes a NOP. |
NULL |
| X_CONV_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnConvolutionDescriptor_t*. | Describes the convolution operation. | NULL |
| X_DWDESC | In the setter, the *param should be a pointer to a previously initialized cudnnFilterDescriptor_t*. | Filter descriptor describing the size, layout and datatype of the dw (filter gradient output) tensor. | NULL |
| X_DWDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether dw (filter gradient output) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_DYDESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the dy (gradient input) tensor. | NULL |
| X_DYDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether dy (gradient input) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
| Parameter | Condition |
|---|---|
| Device compute capability | Needs to be one of 7.0, 7.2 or 7.5. |
| CUDNN_PARAM_XDESC CUDNN_PARAM_XDATA_PLACEHOLDER |
Tensor is 4 dimensional
Datatype is CUDNN_DATA_HALF Layout is NHWC fully packed Alignment is CUDNN_PTR_16B_ALIGNED Tensor’s C dimension is a multiple of 8. |
| CUDNN_PARAM_BN_EQSCALEBIAS_DESC CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER |
If either one of scale and bias operation is not turned into a
NOP:
Tensor is 4 dimensional with shape 1xCx1x1 Datatype is CUDNN_DATA_HALF Layout is fully packed Alignment is CUDNN_PTR_16B_ALIGNED |
| CUDNN_PARAM_CONV_DESC CUDNN_PARAM_DWDESC CUDNN_PARAM_DWDATA_PLACEHOLDER |
Convolution descriptor’s mode needs to be
CUDNN_CROSS_CORRELATION.
Convolution descriptor’s dataType needs to be CUDNN_DATA_FLOAT. Convolution descriptor’s dilationA is (1,1) Convolution descriptor’s group count needs to be 1. Convolution descriptor’s mathType needs to be CUDNN_TENSOR_OP_MATH or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION. Filter gradient is in NHWC layout Filter gradient’s data type is CUDNN_DATA_HALF Filter gradient’s K dimension is a multiple of 32. Filter gradient size RxS is either 1x1 or 3x3 If filter gradient size RxS is 1x1, convolution descriptor’s padA needs to be (0,0) and filterStrideA needs to be (1,1). Filter gradient’s alignment is CUDNN_PTR_16B_ALIGNED |
| CUDNN_PARAM_DYDESC CUDNN_PARAM_DYDATA_PLACEHOLDER |
Tensor is 4 dimensional
Datatype is CUDNN_DATA_HALF Layout is NHWC fully packed Alignment is CUDNN_PTR_16B_ALIGNED |
| For the attribute CUDNN_FUSED_BN_FINALIZE_STATISTICS_TRAINING in cudnnFusedOpsConstParamLabel_t | |||
|---|---|---|---|
| Attribute | Expected Descriptor Type Passed in, in the Setter | Description | Default Value After Creation |
| X_BN_MODE | In the setter, the *param should be a pointer to a previously initialized cudnnBatchNormMode_t*. | Describes the mode of operation for the scale, bias and the statistics.
As of cuDNN 7.6.0, only CUDNN_BATCHNORM_SPATIAL and CUDNN_BATCHNORM_SPATIAL_PERSISTENT are supported, meaning, scale, bias and statistics are all per-channel. |
CUDNN_BATCHNORM_PER_ACTIVATION |
| X_YSTATS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the sum of y and sum of y square tensors. The shapes need to match the mode specified in CUDNN_PARAM_BN_MODE. | NULL |
| X_YSUM_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether sum of y pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_YSQSUM_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether sum of y square pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_SCALEBIAS_MEANVAR_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t. | A common tensor descriptor describing the size, layout and datatype of the batchNorm trained scale, bias and statistics tensors. The shapes need to match the mode specified in CUDNN_PARAM_BN_MODE (similar to the bnScaleBiasMeanVarDesc field in the cudnnBatchNormalization* API). | NULL |
| X_BN_SCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm trained scale pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If the output of BN_EQSCALE is not needed, then this is not needed and may be NULL. |
CUDNN_PTR_NULL |
| X_BN_BIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm trained bias pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If neither output of BN_EQSCALE or BN_EQBIAS is needed, then this is not needed and may be NULL. |
CUDNN_PTR_NULL |
| X_BN_SAVED_MEAN_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm saved mean pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_SAVED_INVSTD_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm saved inverse standard deviation pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_RUNNING_MEAN_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm running mean pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_RUNNING_VAR_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm running variance pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the batchNorm equivalent
scale and bias tensors. The shapes need to match the mode specified
in CUDNN_PARAM_BN_MODE.
If neither output of BN_EQSCALE or BN_EQBIAS is needed, then this is not needed and may be NULL. |
NULL |
| X_BN_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent scale pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_EQBIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent bias pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| For the attribute CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE in cudnnFusedOpsConstParamLabel_t | |||
|---|---|---|---|
| Attribute | Expected Descriptor Type Passed in, in the Setter | Description | Default Value After Creation |
| X_BN_MODE | In the setter, the *param should be a pointer to a previously initialized cudnnBatchNormMode_t*. | Describes the mode of operation for the scale, bias and the statistics.
As of cuDNN 7.6.0, only CUDNN_BATCHNORM_SPATIAL and CUDNN_BATCHNORM_SPATIAL_PERSISTENT are supported, meaning, scale, bias and statistics are all per-channel. |
CUDNN_BATCHNORM_PER_ACTIVATION |
| X_BN_SCALEBIAS_MEANVAR_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t. | A common tensor descriptor describing the size, layout and datatype of the batchNorm trained scale, bias and statistics tensors. The shapes need to match the mode specified in CUDNN_PARAM_BN_MODE (similar to the bnScaleBiasMeanVarDesc field in the cudnnBatchNormalization* API). | NULL |
| X_BN_SCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm trained scale pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_BIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm trained bias pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_RUNNING_MEAN_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm running mean pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_RUNNING_VAR_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether the batchNorm running variance pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the batchNorm equivalent scale and bias tensors. The shapes need to match the mode specified in CUDNN_PARAM_BN_MODE. | NULL |
| X_BN_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent scale pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| X_BN_EQBIAS_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent bias pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the computation for this output becomes a NOP. |
CUDNN_PTR_NULL |
| For the attribute
CUDNN_FUSED_CONVOLUTION_SCALE_BIAS_ADD_RELU in
cudnnFusedOpsConstParamLabel_t This operation performs the following computation, where * denotes convolution operator: y=1(w*x)+2 z+b |
|||
|---|---|---|---|
| Attribute | Expected Descriptor Type Passed in, in the Setter | Description | Default Value After Creation |
| X_XDESC | In the setter, the *param should be xDesc, a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout and datatype of the x (input) tensor. | NULL |
| X_XDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether xData pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_CONV_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnConvolutionDescriptor_t*. | Describes the convolution operation. | NULL |
| X_WDESC | In the setter, the *param should be a pointer to a previously initialized cudnnFilterDescriptor_t*. | Filter descriptor describing the size, layout and datatype of the w (filter) tensor. | NULL |
| X_WDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether w (filter) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
| X_BN_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the α1 scale and bias tensors. The tensor should have shape (1,K,1,1), K is the number of output features. | NULL |
| X_BN_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm equivalent scale or α1 tensor pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then α1 scaling becomes an NOP. |
CUDNN_PTR_NULL |
| X_ZDESC | In the setter, the *param should be xDesc, a pointer to a previously initialized cudnnTensorDescriptor_t. | Tensor descriptor describing the size, layout and datatype of the z
tensor.
If unset, then z scale-add term becomes a NOP. |
NULL |
| CUDNN_PARAM_ZDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether z tensor pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then z scale-add term becomes a NOP. |
CUDNN_PTR_NULL |
| CUDNN_PARAM_BN_Z_EQSCALEBIAS_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the α2
tensor.
If set to NULL then scaling for input z becomes a NOP. |
NULLPTR |
| CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether batchnorm z-equivalent scaling pointer in the
VariantParamPack will be NULL,
or if not, user promised pointer alignment *.
If set to CUDNN_PTR_NULL, then the scaling for input z becomes a NOP. |
CUDNN_PTR_NULL |
| X_ACTIVATION_DESC | In the setter, the *param should be a pointer to a previously initialized cudnnActivationDescriptor_t*. | Describes the activation operation.
As of 7.6.0, only activation modes of CUDNN_ACTIVATION_RELU and CUDNN_ACTIVATION_IDENTITY are supported. If set to NULL or if the activation mode is set to CUDNN_ACTIVATION_IDENTITY, then the activation in the op sequence becomes a NOP. |
NULL |
| X_YDESC | In the setter, the *param should be a pointer to a previously initialized cudnnTensorDescriptor_t*. | Tensor descriptor describing the size, layout and datatype of the y (output) tensor. | NULL |
| X_YDATA_PLACEHOLDER | In the setter, the *param should be a pointer to a previously initialized X_PointerPlaceHolder_t*. | Describes whether y (output) tensor pointer in the VariantParamPack will be NULL, or if not, user promised pointer alignment *. | CUDNN_PTR_NULL |
6.1.3.3. cudnnFusedOpsPointerPlaceHolder_t
| Member | Description |
|---|---|
| CUDNN_PTR_NULL = 0 | Indicates that the pointer to the tensor in the variantPack will be NULL. |
| CUDNN_PTR_ELEM_ALIGNED = 1 | Indicates that the pointer to the tensor in the variantPack will not be NULL, and will have element alignment. |
| CUDNN_PTR_16B_ALIGNED = 2 | Indicates that the pointer to the tensor in the variantPack will not be NULL, and will have 16 byte alignment. |
6.1.3.4. cudnnFusedOpsVariantParamLabel_t
typedef enum { CUDNN_PTR_XDATA = 0, CUDNN_PTR_BN_EQSCALE = 1, CUDNN_PTR_BN_EQBIAS = 2, CUDNN_PTR_WDATA = 3, CUDNN_PTR_DWDATA = 4, CUDNN_PTR_YDATA = 5, CUDNN_PTR_DYDATA = 6, CUDNN_PTR_YSUM = 7, CUDNN_PTR_YSQSUM = 8, CUDNN_PTR_WORKSPACE = 9, CUDNN_PTR_BN_SCALE = 10, CUDNN_PTR_BN_BIAS = 11, CUDNN_PTR_BN_SAVED_MEAN = 12, CUDNN_PTR_BN_SAVED_INVSTD = 13, CUDNN_PTR_BN_RUNNING_MEAN = 14, CUDNN_PTR_BN_RUNNING_VAR = 15, CUDNN_PTR_ZDATA = 16, CUDNN_PTR_BN_Z_EQSCALE = 17, CUDNN_PTR_BN_Z_EQBIAS = 18, CUDNN_PTR_ACTIVATION_BITMASK = 19, CUDNN_PTR_DXDATA = 20, CUDNN_PTR_DZDATA = 21, CUDNN_PTR_BN_DSCALE = 22, CUDNN_PTR_BN_DBIAS = 23, CUDNN_SCALAR_SIZE_T_WORKSPACE_SIZE_IN_BYTES = 100, CUDNN_SCALAR_INT64_T_BN_ACCUMULATION_COUNT = 101, CUDNN_SCALAR_DOUBLE_BN_EXP_AVG_FACTOR = 102, CUDNN_SCALAR_DOUBLE_BN_EPSILON = 103, } cudnnFusedOpsVariantParamLabel_t;
| Short-Form Used | Stands For |
|---|---|
| Setter | cudnnSetFusedOpsVariantParamPackAttribute() |
| Getter | cudnnGetFusedOpsVariantParamPackAttribute() |
| X_ prefix in the Attribute key column | Stands for CUDNN_PTR_ or CUDNN_SCALAR_ in the enumerator name. |
| For the attribute CUDNN_FUSED_SCALE_BIAS_ACTIVATION_CONV_BNSTATS in cudnnFusedOpsVariantParamLabel_t | ||||
|---|---|---|---|---|
| Attribute key | Expected Descriptor Type Passed in, in the Setter | I/O Type | Description | Default Value |
| X_XDATA | void * | input | Pointer to x (input) tensor on device, need to agree with previously set CUDNN_PARAM_XDATA_PLACEHOLDER attribute *. | NULL |
| X_BN_EQSCALE | void * | input | Pointer to batchnorm equivalent scale tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_EQBIAS | void * | input | Pointer to batchnorm equivalent bias tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER attribute *. | NULL |
| X_WDATA | void * | input | Pointer to w (filter) tensor on device, need to agree with previously set CUDNN_PARAM_WDATA_PLACEHOLDER attribute *. | NULL |
| X_YDATA | void * | output | Pointer to y (output) tensor on device, need to agree with previously set CUDNN_PARAM_YDATA_PLACEHOLDER attribute *. | NULL |
| X_YSUM | void * | output | Pointer to sum of y tensor on device, need to agree with previously set CUDNN_PARAM_YSUM_PLACEHOLDER attribute *. | NULL |
| X_YSQSUM | void * | output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_YSQSUM_PLACEHOLDER attribute *. | NULL |
| X_WORKSPACE | void * | input | Pointer to user allocated workspace on device. Can be NULL if the workspace size requested is 0. | NULL |
| X_SIZE_T_WORKSPACE_SIZE_IN_BYTES | size_t * | input | Pointer to a size_t value in host memory describing the user allocated workspace size in bytes. The amount needs to be equal or larger than the amount requested in cudnnMakeFusedOpsPlan. | 0 |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
| For the attribute CUDNN_FUSED_SCALE_BIAS_ACTIVATION_WGRAD in cudnnFusedOpsVariantParamLabel_t | ||||
|---|---|---|---|---|
| Attribute key | Expected Descriptor Type Passed in, in the Setter | I/O Type | Description | Default Value |
| X_XDATA | void * | input | Pointer to x (input) tensor on device, need to agree with previously set CUDNN_PARAM_XDATA_PLACEHOLDER attribute *. | NULL |
| X_BN_EQSCALE | void * | input | Pointer to batchnorm equivalent scale tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_EQBIAS | void * | input | Pointer to batchnorm equivalent bias tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER attribute *. | NULL |
| X_DWDATA | void * | output | Pointer to dw (filter gradient output) tensor on device, need to agree with previously set CUDNN_PARAM_WDATA_PLACEHOLDER attribute *. | NULL |
| X_DYDATA | void * | input | Pointer to dy (gradient input) tensor on device, need to agree with previously set CUDNN_PARAM_YDATA_PLACEHOLDER attribute *. | NULL |
| X_WORKSPACE | void * | input | Pointer to user allocated workspace on device. Can be NULL if the workspace size requested is 0. | NULL |
| X_SIZE_T_WORKSPACE_SIZE_IN_BYTES | size_t * | input | Pointer to a size_t value in host memory describing the user allocated workspace size in bytes. The amount needs to be equal or larger than the amount requested in cudnnMakeFusedOpsPlan. | 0 |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
| For the attribute CUDNN_FUSED_BN_FINALIZE_STATISTICS_TRAINING in cudnnFusedOpsVariantParamLabel_t | ||||
|---|---|---|---|---|
| Attribute key | Expected Descriptor Type Passed in, in the Setter | I/O Type | Description | Default Value |
| X_YSUM | void * | input | Pointer to sum of y tensor on device, need to agree with previously set CUDNN_PARAM_YSUM_PLACEHOLDER attribute *. | NULL |
| X_YSQSUM | void * | input | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_YSQSUM_PLACEHOLDER attribute *. | NULL |
| X_BN_SCALE | void * | input | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_SCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_BIAS | void * | input | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_BIAS_PLACEHOLDER attribute *. | NULL |
| X_BN_SAVED_MEAN | void * | output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_SAVED_MEAN_PLACEHOLDER attribute *. | NULL |
| X_BN_SAVED_INVSTD | void * | output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_SAVED_INVSTD_PLACEHOLDER attribute *. | NULL |
| X_BN_RUNNING_MEAN | void * | input/output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER attribute *. | NULL |
| X_BN_RUNNING_VAR | void * | input/output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER attribute *. | NULL |
| X_BN_EQSCALE | void * | output | Pointer to batchnorm equivalent scale tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_EQBIAS | void * | output | Pointer to batchnorm equivalent bias tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER attribute *. | NULL |
| X_INT64_T_BN_ACCUMULATION_COUNT | int64_t * | input | Pointer to a scalar value in int64_t on host memory.
This value should describe the number of tensor elements accumulated in the sum of y and sum of y square tensors. For example, in the single GPU use case, if the mode is CUDNN_BATCHNORM_SPATIAL or CUDNN_BATCHNORM_SPATIAL_PERSISTENT, the value should be equal to N*H*W of the tensor from which the statistics are calculated. In multi-GPU use case, if all-reduce has been performed on the sum of y and sum of y square tensors, this value should be the sum of the single GPU accumulation count on each of the GPUs. |
0 |
| X_DOUBLE_BN_EXP_AVG_FACTOR | double * | input | Pointer to a scalar value in double on host memory.
Factor used in the moving average computation. See exponentialAverageFactor in cudnnBatchNormalization* APIs. |
0.0 |
| X_DOUBLE_BN_EPSILON | double * | input | Pointer to a scalar value in double on host memory.
A conditioning constant used in the batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. See exponentialAverageFactor in cudnnBatchNormalization* APIs. |
0.0 |
| X_WORKSPACE | void * | input | Pointer to user allocated workspace on device. Can be NULL if the workspace size requested is 0. | NULL |
| X_SIZE_T_WORKSPACE_SIZE_IN_BYTES | size_t * | input | Pointer to a size_t value in host memory describing the user allocated workspace size in bytes. The amount needs to be equal or larger than the amount requested in cudnnMakeFusedOpsPlan. | 0 |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
| For the attribute CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE in cudnnFusedOpsVariantParamLabel_t | ||||
|---|---|---|---|---|
| Attribute key | Expected Descriptor Type Passed in, in the Setter | I/O Type | Description | Default Value |
| X_BN_SCALE | void * | input | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_SCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_BIAS | void * | input | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_BIAS_PLACEHOLDER attribute *. | NULL |
| X_BN_RUNNING_MEAN | void * | input/output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_RUNNING_MEAN_PLACEHOLDER attribute *. | NULL |
| X_BN_RUNNING_VAR | void * | input/output | Pointer to sum of y square tensor on device, need to agree with previously set CUDNN_PARAM_BN_RUNNING_VAR_PLACEHOLDER attribute *. | NULL |
| X_BN_EQSCALE | void * | output | Pointer to batchnorm equivalent scale tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_EQBIAS | void * | output | Pointer to batchnorm equivalent bias tensor on device, need to agree with previously set CUDNN_PARAM_BN_EQBIAS_PLACEHOLDER attribute *. | NULL |
| X_DOUBLE_BN_EPSILON | double * | input | Pointer to a scalar value in double on host memory.
A conditioning constant used in the batch normalization formula. Its value should be equal to or greater than the value defined for CUDNN_BN_MIN_EPSILON in cudnn.h. See exponentialAverageFactor in cudnnBatchNormalization* APIs. |
0.0 |
| X_WORKSPACE | void * | input | Pointer to user allocated workspace on device. Can be NULL if the workspace size requested is 0. | NULL |
| X_SIZE_T_WORKSPACE_SIZE_IN_BYTES | size_t * | input | Pointer to a size_t value in host memory describing the user allocated workspace size in bytes. The amount needs to be equal or larger than the amount requested in cudnnMakeFusedOpsPlan. | 0 |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
| For the attribute CUDNN_FUSED_BN_FINALIZE_STATISTICS_INFERENCE in cudnnFusedOpsVariantParamLabel_t | ||||
|---|---|---|---|---|
| Attribute key | Expected Descriptor Type Passed in, in the Setter | I/O Type | Description | Default Value |
| X_XDATA | void * | input | Pointer to x (image) tensor on device, need to agree with previously set CUDNN_PARAM_XDATA_PLACEHOLDER attribute *. | NULL |
| X_WDATA | void * | input | Pointer to w (filter) tensor on device, need to agree with previously set CUDNN_PARAM_WDATA_PLACEHOLDER attribute *. | NULL |
| X_BN_EQSCALE | void * | input | Pointer to alpha1 or batchnorm equivalent scale tensor on device; need to agree with previously set CUDNN_PARAM_BN_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_ZDATA | void * | input | Pointer to z ( tensor on device; Need to agree with previously set CUDNN_PARAM_YDATA_PLACEHOLDER attribute *. | NULL |
| X_BN_Z_EQSCALE | void * | input | Pointer to alpha2, equivalent scale tensor for z; Need to agree with previously set CUDNN_PARAM_BN_Z_EQSCALE_PLACEHOLDER attribute *. | NULL |
| X_BN_Z_EQBIAS | void * | input | Pointer to batchnorm equivalent bias tensor on device, need to agree with previously set CUDNN_PARAM_BN_Z_EQBIAS_PLACEHOLDER attribute *. | NULL |
| X_YDATA | void * | output | Pointer to y (output) tensor on device, need to agree with previously set CUDNN_PARAM_YDATA_PLACEHOLDER attribute *. | NULL |
| X_WORKSPACE | void * | input | Pointer to user allocated workspace on device. Can be NULL if the workspace size requested is 0. | NULL |
| X_SIZE_T_WORKSPACE_SIZE_IN_BYTES | size_t * | input | Pointer to a size_t value in host memory describing the user allocated workspace size in bytes. The amount needs to be equal or larger than the amount requested in cudnnMakeFusedOpsPlan. | 0 |
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_NULL, then the device pointer in the VariantParamPack needs to be NULL as well.
- If the corresponding pointer placeholder in ConstParamPack is set to CUDNN_PTR_ELEM_ALIGNED or CUDNN_PTR_16B_ALIGNED, then the device pointer in the VariantParamPack may not be NULL and needs to be at least element-aligned or 16 bytes-aligned, respectively.
6.2. API Functions
6.2.1. cudnnCnnTrainVersionCheck()
cudnnStatus_t cudnnCnnTrainVersionCheck(void)
6.2.2. cudnnConvolutionBackwardBias()
cudnnStatus_t cudnnConvolutionBackwardBias(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const void *beta,
const cudnnTensorDescriptor_t dbDesc,
void *db)Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*resultValue + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to the previously initialized input tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyDesc.
- Input. Handle to the previously initialized output tensor descriptor.
- Output. Data pointer to GPU memory associated with the output tensor descriptor dbDesc.
Returns
- The operation was launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the parameters n, height, or width of the output tensor is not 1.
- The numbers of feature maps of the input tensor and output tensor differ.
- The dataType of the two tensor descriptors is different.
6.2.3. cudnnConvolutionBackwardFilter()
cudnnStatus_t cudnnConvolutionBackwardFilter(
cudnnHandle_t handle,
const void *alpha,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
cudnnConvolutionBwdFilterAlgo_t algo,
void *workSpace,
size_t workSpaceSizeInBytes,
const void *beta,
const cudnnFilterDescriptor_t dwDesc,
void *dw)Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
-
Input. Pointers to scaling factors (in host memory) used to blend the computation result with prior value in the output layer as follows:
dstValue = alpha[0]*result + beta[0]*priorDstValue
For more information, refer to Scaling Parameters.
- Input. Handle to a previously initialized tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Data pointer to GPU memory associated with the tensor descriptor xDesc.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the backpropagation gradient tensor descriptor dyDesc.
- Input. Previously initialized convolution descriptor. For more information, refer to cudnnConvolutionDescriptor_t.
- Input. Enumerant that specifies which convolution algorithm should be used to compute the results. For more information, refer to cudnnConvolutionBwdFilterAlgo_t.
- Input. Data pointer to GPU memory to a workspace needed to be able to execute the specified algorithm. If no workspace is needed for a particular algorithm, that pointer can be NIL.
- Input. Specifies the size in bytes of the provided workSpace.
- Input. Handle to a previously initialized filter gradient descriptor. For more information, refer to cudnnFilterDescriptor_t.
- Input/Output. Data pointer to GPU memory associated with the filter gradient descriptor dwDesc that carries the result.
Supported configurations
This function supports the following combinations of data types for xDesc, dyDesc, convDesc, and dwDesc.
| Data Type Configurations | xDesc, dyDesc, and dwDesc Data Type | convDesc Data Type |
|---|---|---|
| TRUE_HALF_CONFIG (only supported on architectures with true FP16 support, meaning, compute capability 5.3 and later) | CUDNN_DATA_HALF | CUDNN_DATA_HALF |
| PSEUDO_HALF_CONFIG | CUDNN_DATA_HALF | CUDNN_DATA_FLOAT |
| PSEUDO_BFLOAT16_CONFIG | CUDNN_DATA_BFLOAT16 | CUDNN_DATA_FLOAT |
| FLOAT_CONFIG | CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT |
| DOUBLE_CONFIG | CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE |
Supported algorithms
The table below shows the list of the supported 2D and 3D convolutions. The 2D convolutions are described first, followed by the 3D convolutions.
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0 (_ALGO_0)
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1 (_ALGO_1)
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_3 (_ALGO_3)
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT (_FFT)
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFT_TILING (_FFT_TILING)
- CUDNN_CONVOLUTION_BWD_FILTER_ALGO_WINOGRAD_NONFUSED (_WINOGRAD_NONFUSED)
- CUDNN_TENSOR_NCHW (_NCHW)
- CUDNN_TENSOR_NHWC (_NHWC)
- CUDNN_TENSOR_NCHW_VECT_C (_NCHW_VECT_C)
| Filter descriptor dwDesc: _NHWC (refer to cudnnTensorFormat_t) | |||||
|---|---|---|---|---|---|
| Algo Name | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
| _ALGO_0 and _ALGO_1 | NHWC HWC-packed. | NHWC HWC-packed | PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
||
| Filter descriptor dwDesc: _NCHW | |||||
|---|---|---|---|---|---|
| Algo Name | Deterministic (Yes or No) | Tensor Formats Supported for dyDesc | Tensor Formats Supported for dxDesc | Data Type Configurations Supported | Important |
| _ALGO_0 | No | All except _NCHW_VECT_C | NCHW CHW-packed | PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _ALGO_1 | Yes | All except _NCHW_VECT_C | NCHW CHW-packed | PSEUDO_HALF_CONFIG TRUE_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _FFT | Yes | NCHW CHW-packed | NCHW CHW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 xDesc feature map height + 2 * convDesc zero-padding height must equal 256 or less xDesc feature map width + 2 * convDesc zero-padding width must equal 256 or less convDesc vertical and horizontal filter stride must equal 1 dwDesc filter height must be greater than convDesc zero-padding height dwDesc filter width must be greater than convDesc zero-padding width |
| _ALGO_3 | No | All except _NCHW_VECT_C | NCHW CHW-packed | PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 |
| _WINOGRAD_NONFUSED | Yes | All except _NCHW_VECT_C | NCHW CHW-packed | TRUE_HALF_CONFIG PSEUDO_HALF_CONFIG PSEUDO_BFLOAT16_CONFIG FLOAT_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 convDesc vertical and horizontal filter stride must equal 1 dwDesc filter (height, width) must be (3,3) or (5,5) If dwDesc filter (height, width) is (5,5), then the data type config TRUE_HALF_CONFIG is not supported. |
| _FFT_TILING | Yes | NCHW CHW-packed | NCHW CHW-packed | PSEUDO_HALF_CONFIG FLOAT_CONFIG DOUBLE_CONFIG |
Dilation: 1 for all
dimensions
convDesc Group Count Support: Greater than 0 dyDesc width or height must equal 1 (the same dimension as in xDesc). The other dimension must be less than or equal to 256, meaning, the largest 1D tile size currently supported. convDesc vertical and horizontal filter stride must equal 1 dwDesc filter height must be greater than convDesc zero-padding height dwDesc filter width must be greater than convDesc zero-padding width |
| Filter descriptor dwDesc: _NHWC | |||||
|---|---|---|---|---|---|
| Algo Name (3D Convolutions) | Deterministic (Yes or No) | Tensor Formats Supported for xDesc | Tensor Formats Supported for dyDesc | Data Type Configurations Supported | Important |
| _ALGO_1 | Yes | NDHWC HWC-packed | NDHWC HWC-packed | PSEUDO_HALF_CONFIG PSEUDO_BFLOT16_CONFIG FLOAT_CONFIG TRUE_HALF_CONFIG |
Dilation: greater than 0 for all
dimensions
convDesc Group Count Support: Greater than 0 |
Returns
- The operation was launched successfully.
- At least one of the following conditions are met:
- At least one of the following is NULL: handle, xDesc, dyDesc, convDesc, dwDesc, xData, dyData, dwData, alpha, or beta
- xDesc and dyDesc have a non-matching number of dimensions
- xDesc and dwDesc have a non-matching number of dimensions
- xDesc has fewer than three number of dimensions
- xDesc, dyDesc, and dwDesc have a non-matching data type.
- xDesc and dwDesc have a non-matching number of input feature maps per image (or group in case of grouped convolutions).
- yDesc or dwDesc indicate an output channel count that isn't a multiple of group count (if group count has been set in convDesc).
- At least one of the following conditions are met:
- xDesc or dyDesc have negative tensor striding
- xDesc, dyDesc or dwDesc has a number of dimensions that is not 4 or 5
- The chosen algo does not support the parameters provided; see above for exhaustive list of parameter support for each algo
- An error occurs during the texture object creation associated with the filter data.
- The function failed to launch on the GPU.
6.2.4. cudnnCreateFusedOpsConstParamPack()
cudnnStatus_t cudnnCreateFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t *constPack, cudnnFusedOps_t ops);
Parameters
- Input. The opaque structure that is created by this function. For more information, refer to cudnnFusedOpsConstParamPack_t.
- Input. The specific sequence of computations to perform in the cudnnFusedOps computations, as defined in the enumerant type cudnnFusedOps_t.
6.2.5. cudnnCreateFusedOpsPlan()
cudnnStatus_t cudnnCreateFusedOpsPlan( cudnnFusedOpsPlan_t *plan, cudnnFusedOps_t ops);
Parameters
- Input. A pointer to the instance of the descriptor created by this function.
- Input. The specific sequence of fused operations computations for which this plan descriptor should be created. For more information, refer to cudnnFusedOps_t.
6.2.6. cudnnCreateFusedOpsVariantParamPack()
cudnnStatus_t cudnnCreateFusedOpsVariantParamPack( cudnnFusedOpsVariantParamPack_t *varPack, cudnnFusedOps_t ops);
Parameters
- Input. Pointer to the descriptor created by this function. For more information, refer to cudnnFusedOpsVariantParamPack_t.
- Input. The specific sequence of fused operations computations for which this descriptor should be created.
6.2.7. cudnnDestroyFusedOpsConstParamPack()
cudnnStatus_t cudnnDestroyFusedOpsConstParamPack( cudnnFusedOpsConstParamPack_t constPack);
6.2.10. cudnnFindConvolutionBackwardFilterAlgorithm()
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithm( cudnnHandle_t handle, const cudnnTensorDescriptor_t xDesc, const cudnnTensorDescriptor_t dyDesc, const cudnnConvolutionDescriptor_t convDesc, const cudnnFilterDescriptor_t dwDesc, const int requestedAlgoCount, int *returnedAlgoCount, cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)
Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdFilterAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount().
- This function is host blocking.
- It is recommended to run this function prior to allocating layer data; doing otherwise may needlessly inhibit some algorithm options due to resource usage.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- xDesc, dyDesc, or dwDesc are not allocated properly.
- xDesc, dyDesc, or dwDesc has fewer than 1 dimension.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- This function was unable to allocate memory to store sample input, filters and output.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
6.2.11. cudnnFindConvolutionBackwardFilterAlgorithmEx()
cudnnStatus_t cudnnFindConvolutionBackwardFilterAlgorithmEx(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t dyDesc,
const void *dy,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnFilterDescriptor_t dwDesc,
void *dw,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionBwdFilterAlgoPerf_t *perfResults,
void *workSpace,
size_t workSpaceSizeInBytes)Memory is allocated via cudaMalloc(). The performance metrics are returned in the user-allocated array of cudnnConvolutionBwdFilterAlgoPerf_t. These metrics are written in a sorted fashion where the first element has the lowest compute time. The total number of resulting algorithms can be queried through the API cudnnGetConvolutionBackwardFilterAlgorithmMaxCount().
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Data pointer to GPU memory associated with the filter descriptor xDesc.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Data pointer to GPU memory associated with the tensor descriptor dyDesc.
- Input. Previously initialized convolution descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input/Output. Data pointer to GPU memory associated with the filter descriptor dwDesc. The content of this tensor will be overwritten with arbitrary values.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory is a necessary workspace for some algorithms. The size of this workspace will determine the availability of algorithms. A NIL pointer is considered a workSpace of 0 bytes.
- Input. Specifies the size in bytes of the provided workSpace.
Returns
- The query was successful.
- At least one of the following conditions are met:
- handle is not allocated properly.
- xDesc, dyDesc, or dwDesc are not allocated properly.
- xDesc, dyDesc, or dwDesc has fewer than 1 dimension.
- x, dy, or dw is NIL.
- Either returnedCount or perfResults is NIL.
- requestedCount is less than 1.
- At least one of the following conditions are met:
- The function was unable to allocate necessary timing objects.
- The function was unable to deallocate necessary timing objects.
- The function was unable to deallocate sample input, filters and output.
6.2.12. cudnnFusedOpsExecute()
cudnnStatus_t cudnnFusedOpsExecute(
cudnnHandle_t handle,
const cudnnFusedOpsPlan_t plan,
cudnnFusedOpsVariantParamPack_t varPack);
6.2.13. cudnnGetConvolutionBackwardFilterAlgorithmMaxCount()
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithmMaxCount(
cudnnHandle_t handle,
int *count)
6.2.14. cudnnGetConvolutionBackwardFilterAlgorithm_v7()
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithm_v7(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnFilterDescriptor_t dwDesc,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnConvolutionBwdFilterAlgoPerf_t *perfResults)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
Returns
- CUDNN_STATUS_SUCCESS
- The query was successful.
- CUDNN_STATUS_BAD_PARAM
- At least one of the following conditions are met:
- One of the parameters handle, xDesc, dyDesc, convDesc, dwDesc, perfResults, or returnedAlgoCount is NULL.
- The numbers of feature maps of the input tensor and output tensor differ.
- The dataType of the two tensor descriptors or the filter are different.
- requestedAlgoCount is less than or equal to 0.
6.2.15. cudnnGetConvolutionBackwardFilterWorkspaceSize()
cudnnStatus_t cudnnGetConvolutionBackwardFilterWorkspaceSize(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t xDesc,
const cudnnTensorDescriptor_t dyDesc,
const cudnnConvolutionDescriptor_t convDesc,
const cudnnFilterDescriptor_t dwDesc,
cudnnConvolutionBwdFilterAlgo_t algo,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized input tensor descriptor.
- Input. Handle to the previously initialized input differential tensor descriptor.
- Input. Previously initialized convolution descriptor.
- Input. Handle to a previously initialized filter descriptor.
- Input. Enumerant that specifies the chosen convolution algorithm.
- Output. Amount of GPU memory needed as workspace to be able to execute a forward convolution with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The numbers of feature maps of the input tensor and output tensor differ.
- The dataType of the two tensor descriptors or the filter are different.
- The combination of the tensor descriptors, filter descriptor and convolution descriptor is not supported for the specified algorithm.
6.2.16. cudnnGetFusedOpsConstParamPackAttribute()
cudnnStatus_t cudnnGetFusedOpsConstParamPackAttribute( const cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, void *param, int *isNULL);
Parameters
- Input. The opaque cudnnFusedOpsConstParamPack_t structure that contains the various problem size information, such as the shape, layout and the type of tensors, and the descriptors for convolution and activation, for the selected sequence of cudnnFusedOps_t computations.
- Input. Several types of descriptors can be retrieved by this getter function. The param input points to the descriptor itself, and this input indicates the type of the descriptor pointed to by the param input. The cudnnFusedOpsConstParamLabel_t enumerant type enables the selection of the type of the descriptor. Refer to the param description below.
- Input. Data pointer to the host memory associated with the descriptor that should be retrieved. The type of this descriptor depends on the value of paramLabel. For the given paramLabel, if the associated value inside the constPack is set to NULL or by default NULL, then cuDNN will copy the value or the opaque structure in the constPack to the host memory buffer pointed to by param. For more information, see the table in cudnnFusedOpsConstParamLabel_t.
- Input/Output. Users must pass a pointer to an integer in the host memory in this field. If the value in the constPack associated with the given paramLabel is by default NULL or previously set by the user to NULL, then cuDNN will write a non-zero value to the location pointed by is isNULL.
6.2.17. cudnnGetFusedOpsVariantParamPackAttribute()
cudnnStatus_t cudnnGetFusedOpsVariantParamPackAttribute( const cudnnFusedOpsVariantParamPack_t varPack, cudnnFusedOpsVariantParamLabel_t paramLabel, void *ptr);
Parameters
- Input. Pointer to the cudnnFusedOps variant parameter pack (varPack) descriptor.
- Input. Type of the buffer pointer parameter (in the varPack descriptor). For more information, refer to cudnnFusedOpsConstParamLabel_t. The retrieved descriptor values vary according to this type.
- Output. Pointer to the host or device memory where the retrieved value is written by this function. The data type of the pointer, and the host/device memory location, depend on the paramLabel input selection. For more information, refer to cudnnFusedOpsVariantParamLabel_t.
6.2.18. cudnnMakeFusedOpsPlan()
cudnnStatus_t cudnnMakeFusedOpsPlan(
cudnnHandle_t handle,
cudnnFusedOpsPlan_t plan,
const cudnnFusedOpsConstParamPack_t constPack,
size_t *workspaceSizeInBytes); Parameters
- Input. Pointer to the cuDNN library context.
- Input. Pointer to a previously-created and initialized plan descriptor.
- Input. Pointer to the descriptor to the const parameters pack.
- Output. The amount of workspace size the user should allocate for the execution of this plan.
Returns
- If any of the inputs is NULL, or if the type of cudnnFusedOps_t in the constPack descriptor is unsupported.
- The function executed successfully.
6.2.19. cudnnSetFusedOpsConstParamPackAttribute()
cudnnStatus_t cudnnSetFusedOpsConstParamPackAttribute( cudnnFusedOpsConstParamPack_t constPack, cudnnFusedOpsConstParamLabel_t paramLabel, const void *param);
Parameters
- Input. The opaque cudnnFusedOpsConstParamPack_t structure that contains the various problem size information, such as the shape, layout and the type of tensors, the descriptors for convolution and activation, and settings for operations such as convolution and activation.
- Input. Several types of descriptors can be set by this setter function. The param input points to the descriptor itself, and this input indicates the type of the descriptor pointed to by the param input. The cudnnFusedOpsConstParamLabel_t enumerant type enables the selection of the type of the descriptor.
- Input. Data pointer to the host memory, associated with the specific descriptor.
The type of the descriptor depends on the value of
paramLabel. For more information, refer to the
table in cudnnFusedOpsConstParamLabel_t.
If this pointer is set to NULL, then the cuDNN library will record as such. If not, then the values pointed to by this pointer (meaning, the value or the opaque structure underneath) will be copied into the constPack during cudnnSetFusedOpsConstParamPackAttribute() operation.
6.2.20. cudnnSetFusedOpsVariantParamPackAttribute()
cudnnStatus_t cudnnSetFusedOpsVariantParamPackAttribute(
cudnnFusedOpsVariantParamPack_t varPack,
cudnnFusedOpsVariantParamLabel_t paramLabel,
void *ptr); Parameters
- Input. Pointer to the cudnnFusedOps variant parameter pack (varPack) descriptor.
- Input. Type to which the buffer pointer parameter (in the varPack descriptor) is set by this function. For more information, refer to cudnnFusedOpsConstParamLabel_t.
- Input. Pointer, to the host or device memory, to the value to which the descriptor parameter is set. The data type of the pointer, and the host/device memory location, depend on the paramLabel input selection. For more information, refer to cudnnFusedOpsVariantParamLabel_t.
7. cudnn_adv_infer.so Library
7.1. Data Type References
7.1.1. Pointer To Opaque Struct Types
7.1.1.1. cudnnAttnDescriptor_t
- weight and bias tensor shapes (vector lengths before and after linear projections)
- parameters that can be set in advance and do not change when invoking functions to evaluate forward responses and gradients (number of attention heads, softmax smoothing/sharpening coefficient)
- other settings that are necessary to compute temporary buffer sizes.
Use the cudnnCreateAttnDescriptor() function to create an instance of the attention descriptor object and cudnnDestroyAttnDescriptor() to delete the previously created descriptor. Use the cudnnSetAttnDescriptor() function to configure the descriptor.
7.1.1.2. cudnnPersistentRNNPlan_t
cudnnPersistentRNNPlan_t is a pointer to an opaque structure holding a plan to execute a dynamic persistent RNN. cudnnCreatePersistentRNNPlan() is used to create and initialize one instance.
7.1.1.3. cudnnRNNDataDescriptor_t
7.1.1.4. cudnnRNNDescriptor_t
7.1.1.5. cudnnSeqDataDescriptor_t
The TIME dimension is used to bundle vectors into sequences of vectors. The actual sequences can be shorter than the TIME dimension, therefore, additional information is needed about each sequence length and how unused (padding) vectors should be saved.
It is assumed that the sequence data container is fully packed. The TIME, BATCH and BEAM dimensions can be in any order when vectors are traversed in the ascending order of addresses. Six data layouts (permutation of TIME, BATCH and BEAM) are possible.
- data type used by vectors
- TIME, BATCH, BEAM and VECT dimensions
- data layout
- the length of each sequence along the TIME dimension
- an optional value to be copied to output padding vectors
Use the cudnnCreateSeqDataDescriptor() function to create one instance of the sequence data descriptor object and cudnnDestroySeqDataDescriptor() to delete a previously created descriptor. Use the cudnnSetSeqDataDescriptor() function to configure the descriptor.
This descriptor is used by multi-head attention API functions.
7.1.2. Enumeration Types
7.1.2.1. cudnnDirectionMode_t
7.1.2.2. cudnnForwardMode_t
7.1.2.3. cudnnMultiHeadAttnWeightKind_t
Values
- Selects the input projection weights for queries.
- Selects the input projection weights for keys.
- Selects the input projection weights for values.
- Selects the output projection weights.
- Selects the input projection biases for queries.
- Selects the input projection biases for keys.
- Selects the input projection biases for values.
- Selects the output projection biases.
7.1.2.4. cudnnRNNBiasMode_t
7.1.2.5. cudnnRNNClipMode_t
7.1.2.6. cudnnRNNDataLayout_t
7.1.2.7. cudnnRNNInputMode_t
7.1.2.8. cudnnRNNMode_t
Values
-
A single-gate recurrent neural network with a ReLU activation function.
In the forward pass, the output for a given iteration can be computed from the recurrent input and the previous layer input , given the matrices W, R and the bias vectors, where .
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS (default mode), then the following equation with biases and applies:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_SINGLE_REC_BIAS, then the following equation with bias applies:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_NO_BIAS, then the following equation applies:
-
A single-gate recurrent neural network with a tanh activation function.
In the forward pass, the output for a given iteration can be computed from the recurrent input and the previous layer input , given the matrices W, R and the bias vectors, and where tanh is the hyperbolic tangent function.
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS (default mode), then the following equation with biases and applies:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_SINGLE_REC_BIAS, then the following equation with bias applies:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_NO_BIAS, then the following equation applies:
-
A four-gate Long Short-Term Memory (LSTM) network with no peephole connections.
In the forward pass, the output and cell output for a given iteration can be computed from the recurrent input , the cell input and the previous layer input , given the matrices W, R and the bias vectors.
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS (default mode), then the following equations with biases and apply:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_SINGLE_REC_BIAS, then the following equations with bias apply:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_NO_BIAS, then the following equations apply:
-
A three-gate network consisting of Gated Recurrent Units.
In the forward pass, the output for a given iteration can be computed from the recurrent input and the previous layer input given matrices W, R and the bias vectors.
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS (default mode), then the following equations with biases and apply:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS, then the following equations with bias apply:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_SINGLE_REC_BIAS, then the following equations with bias apply:
If cudnnRNNBiasMode_t biasMode in rnnDesc is CUDNN_RNN_NO_BIAS, then the following equations apply:
7.1.2.10. cudnnSeqDataAxis_t
cudnnSeqDataAxis_t constants are also used in the axis[] argument of the cudnnSetSeqDataDescriptor() call to define the layout of the sequence data buffer in memory.
Refer to cudnnSetSeqDataDescriptor() for a detailed description on how to use the cudnnSeqDataAxis_t enumerated type.
The CUDNN_SEQDATA_DIM_COUNT macro defines the number of constants in the cudnnSeqDataAxis_t enumerated type. This value is currently set to 4.
Values
- Identifies the TIME (sequence length) dimension or specifies the TIME in the data layout.
- Identifies the BATCH dimension or specifies the BATCH in the data layout.
- Identifies the BEAM dimension or specifies the BEAM in the data layout.
- Identifies the VECT (vector) dimension or specifies the VECT in the data layout.
7.2. API Functions
7.2.1. cudnnAdvInferVersionCheck()
cudnnStatus_t cudnnAdvInferVersionCheck(void)
7.2.2. cudnnBuildRNNDynamic()
cudnnStatus_t cudnnBuildRNNDynamic( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t miniBatch);
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. The exact number of sequences in a batch.
Returns
- The code was built and linked successfully.
-
A GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If CUDNN_STATUS_MAPPING_ERROR is returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.
- The resources could not be allocated.
- The prerequisite runtime library could not be found.
- The current hyper-parameters are invalid.
7.2.3. cudnnCreateAttnDescriptor()
cudnnStatus_t cudnnCreateAttnDescriptor(cudnnAttnDescriptor_t *attnDesc);
Use the cudnnSetAttnDescriptor() function to configure the attention descriptor and cudnnDestroyAttnDescriptor() to destroy it and release the allocated memory.
7.2.4. cudnnCreatePersistentRNNPlan()
cudnnStatus_t cudnnCreatePersistentRNNPlan(
cudnnRNNDescriptor_t rnnDesc,
const int minibatch,
const cudnnDataType_t dataType,
cudnnPersistentRNNPlan_t *plan)This function creates a plan to execute persistent RNNs when using the CUDNN_RNN_ALGO_PERSIST_DYNAMIC algo. This plan is tailored to the current GPU and RNN model hyperparameters. This function call is expected to be expensive in terms of runtime and should be used infrequently. However, the user must invoke cudnnCreatePersistentRNNPlan() every time the number of input vectors changes in a minibatch. For more information, refer to cudnnRNNDescriptor_t, cudnnDataType_t, and cudnnPersistentRNNPlan_t.
Parameters
- rnnDesc
- Input. A previously initialized RNN descriptor.
- minibatch
- Input. The exact number of vectors in a batch.
- dataType
- Input. Specifies data type for RNN weights/biases and input and output data.
- plan
- Output. Pointer to where the address to the newly created RNN persistent plan should be written.
Returns
- The object was created successfully.
-
A GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If CUDNN_STATUS_MAPPING_ERROR is returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.
- The resources could not be allocated.
- A prerequisite runtime library cannot be found.
- The current hyperparameters are invalid.
7.2.5. cudnnCreateRNNDataDescriptor()
cudnnStatus_t cudnnCreateRNNDataDescriptor(
cudnnRNNDataDescriptor_t *RNNDataDesc)
7.2.6. cudnnCreateRNNDescriptor()
7.2.7. cudnnCreateSeqDataDescriptor()
cudnnStatus_t cudnnCreateSeqDataDescriptor(cudnnSeqDataDescriptor_t *seqDataDesc);
Use the cudnnSetSeqDataDescriptor() function to configure the sequence data descriptor and cudnnDestroySeqDataDescriptor() to destroy it and release the allocated memory.
7.2.8. cudnnDestroyAttnDescriptor()
cudnnStatus_t cudnnDestroyAttnDescriptor(cudnnAttnDescriptor_t attnDesc);
The cudnnDestroyAttnDescriptor() function is not able to detect if the attnDesc argument holds a valid address. Undefined behavior will occur in case of passing an invalid pointer, not returned by the cudnnCreateAttnDescriptor() function, or in the double deletion scenario of a valid address.
7.2.9. cudnnDestroyPersistentRNNPlan()
This function destroys a previously created persistent RNN plan object. Invoking cudnnDestroyPersistentRNNPlan() with the NULL argument is a no operation (NOP).
cudnnStatus_t cudnnDestroyPersistentRNNPlan(
cudnnPersistentRNNPlan_t plan)The cudnnDestroyPersistentRNNPlan() function is not able to detect if the plan argument holds a valid address. Undefined behavior will occur in cases of passing an invalid pointer, not returned by the cudnnCreatePersistentRNNPlan() function, or in the double deletion scenario of a valid address.
7.2.10. cudnnDestroyRNNDataDescriptor()
cudnnStatus_t cudnnDestroyRNNDataDescriptor(
cudnnRNNDataDescriptor_t RNNDataDesc)
The cudnnDestroyRNNDataDescriptor() function is not able to detect if the RNNDataDesc argument holds a valid address. Undefined behavior will occur in cases of passing an invalid pointer, not returned by the cudnnCreateRNNDataDescriptor() function, or in the double deletion scenario of a valid address.
7.2.11. cudnnDestroyRNNDescriptor()
cudnnStatus_t cudnnDestroyRNNDescriptor(
cudnnRNNDescriptor_t rnnDesc)The cudnnDestroyRNNDescriptor() function is not able to detect if the rnnDesc argument holds a valid address. Undefined behavior will occur in cases of passing an invalid pointer, not returned by the cudnnCreateRNNDescriptor() function, or in the double deletion scenario of a valid address.
7.2.12. cudnnDestroySeqDataDescriptor()
cudnnStatus_t cudnnDestroySeqDataDescriptor(cudnnSeqDataDescriptor_t seqDataDesc);
The cudnnDestroySeqDataDescriptor() function is not able to detect if the seqDataDesc argument holds a valid address. Undefined behavior will occur in case of passing an invalid pointer, not returned by the cudnnCreateSeqDataDescriptor() function, or in the double deletion scenario of a valid address.
7.2.13. cudnnFindRNNForwardInferenceAlgorithmEx()
This function attempts all available cuDNN algorithms for cudnnRNNForwardInference(), using user-allocated GPU memory. It outputs the parameters that influence the performance of the algorithm to a user-allocated array of cudnnAlgorithmPerformance_t. These parameter metrics are written in sorted fashion where the first element has the lowest compute time.
cudnnStatus_t cudnnFindRNNForwardInferenceAlgorithmEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t *yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
const float findIntensity,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnAlgorithmPerformance_t *perfResults,
void *workspace,
size_t workSpaceSizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of fully packed tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array xDesc. The data are expected to be packed contiguously with the first element of iteration n+1 following directly from the last element of iteration n.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in xDesc.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc. The data are expected to be packed contiguously with the first element of iteration n+1 following directly from the last element of iteration n.
-
Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
-
Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
-
Input.This input was previously unused in versions prior to 7.2.0. It is used in cuDNN 7.2.0 and later versions to control the overall runtime of the RNN find algorithms, by selecting the percentage of a large Cartesian product space to be searched.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, cxDesc, wDesc, hyDesc or cyDesc, or one of the descriptors in xDesc or yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, cxDesc, wDesc, yDesc, hyDesc or cyDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
7.2.14. cudnnGetAttnDescriptor()
cudnnStatus_t cudnnGetAttnDescriptor(
cudnnAttnDescriptor_t attnDesc,
unsigned *attnMode,
int *nHeads,
double *smScaler,
cudnnDataType_t *dataType,
cudnnDataType_t *computePrec,
cudnnMathType_t *mathType,
cudnnDropoutDescriptor_t *attnDropoutDesc,
cudnnDropoutDescriptor_t *postDropoutDesc,
int *qSize,
int *kSize,
int *vSize,
int *qProjSize,
int *kProjSize,
int *vProjSize,
int *oProjSize,
int *qoMaxSeqLength,
int *kvMaxSeqLength,
int *maxBatchSize,
int *maxBeamSize);
Parameters
- Input. Attention descriptor.
- Output. Pointer to the storage for binary attention flags.
- Output. Pointer to the storage for the number of attention heads.
- Output. Pointer to the storage for the softmax smoothing/sharpening coefficient.
- Output. Data type for attention weights, sequence data inputs, and outputs.
- Output. Pointer to the storage for the compute precision.
- Output. NVIDIA Tensor Core settings.
- Output. Descriptor of the dropout operation applied to the softmax output.
- Output. Descriptor of the dropout operation applied to the multi-head attention output.
- Output. Q, K, and V embedding vector lengths.
- Output. Q, K, and V embedding vector lengths after input projections.
- Output. Pointer to store the output vector length after projection.
- Output. Largest sequence length expected in sequence data descriptors related to Q, O, dQ, dO inputs and outputs.
- Output. Largest sequence length expected in sequence data descriptors related to K, V, dK, dV inputs and outputs.
- Output. Largest batch size expected in the cudnnSeqDataDescriptor_t container.
- Output. Largest beam size expected in the cudnnSeqDataDescriptor_t container.
7.2.15. cudnnGetMultiHeadAttnBuffers()
cudnnStatus_t cudnnGetMultiHeadAttnBuffers(
cudnnHandle_t handle,
const cudnnAttnDescriptor_t attnDesc,
size_t *weightSizeInBytes,
size_t *workSpaceSizeInBytes,
size_t *reserveSpaceSizeInBytes);
The user must allocate weight, work, and reserve space buffer sizes in the GPU memory using cudaMalloc() with the reported buffer sizes. The buffers can be also carved out from a larger chunk of allocated memory but the buffer addresses must be at least 16B aligned.
The work-space buffer is used for temporary storage. Its content can be discarded or modified after all GPU kernels launched by the corresponding API complete. The reserve-space buffer is used to transfer intermediate results from cudnnMultiHeadAttnForward() to cudnnMultiHeadAttnBackwardData(), and from cudnnMultiHeadAttnBackwardData() to cudnnMultiHeadAttnBackwardWeights(). The content of the reserve-space buffer cannot be modified until all GPU kernels launched by the above three multi-head attention API functions finish.
All multi-head attention weight and bias tensors are stored in a single weight buffer. For speed optimizations, the cuDNN API may change tensor layouts and their relative locations in the weight buffer based on the provided attention parameters. Use the cudnnGetMultiHeadAttnWeights() function to obtain the start address and the shape of each weight or bias tensor.
Parameters
- Input. The current cuDNN context handle.
- Input. Pointer to a previously initialized attention descriptor.
- Output. Minimum buffer size required to store all multi-head attention trainable parameters.
- Output. Minimum buffer size required to hold all temporary surfaces used by the forward and gradient multi-head attention API calls.
- Output. Minimum buffer size required to store all intermediate data exchanged between forward and backward (gradient) multi-head attention functions. Set this parameter to NULL in the inference mode indicating that gradient API calls will not be invoked.
7.2.16. cudnnGetMultiHeadAttnWeights()
cudnnStatus_t cudnnGetMultiHeadAttnWeights(
cudnnHandle_t handle,
const cudnnAttnDescriptor_t attnDesc,
cudnnMultiHeadAttnWeightKind_t wKind,
size_t weightSizeInBytes,
const void *weights,
cudnnTensorDescriptor_t wDesc,
void **wAddr);
Biases are used in the input and output projections when the CUDNN_ATTN_ENABLE_PROJ_BIASES flag is set in the attention descriptor. Refer to cudnnSetAttnDescriptor() for the description of flags to control projection biases.
When the corresponding weight or bias tensor does not exist, the function writes NULL to the storage location pointed by wAddr and returns zeros in the wDesc tensor descriptor. The return status of the cudnnGetMultiHeadAttnWeights() function is CUDNN_STATUS_SUCCESS in this case.
The cuDNN multiHeadAttention sample code demonstrates how to access multi-head attention weights. Although the buffer with weights and biases should be allocated in the GPU memory, the user can copy it to the host memory and invoke the cudnnGetMultiHeadAttnWeights() function with the host weights address to obtain tensor pointers in the host memory. This scheme allows the user to inspect trainable parameters directly in the CPU memory.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously configured attention descriptor.
- Input. Enumerant type to specify which weight or bias tensor should be retrieved.
- Input. Buffer size that stores all multi-head attention weights and biases.
- Input. Pointer to the weight buffer in the host or device memory.
- Output. The descriptor specifying weight or bias tensor shape. For weights, the wDesc.dimA[] array has three elements: [nHeads, projected size, original size]. For biases, the wDesc.dimA[] array also has three elements: [nHeads, projected size, 1]. The wDesc.strideA[] array describes how tensor elements are arranged in memory.
- Output. Pointer to a location where the start address of the requested tensor should be written. When the corresponding projection is disabled, the address written to wAddr is NULL.
7.2.17. cudnnGetRNNBackwardWeightsAlgorithmMaxCount()
7.2.18. cudnnGetRNNBiasMode()
cudnnStatus_t cudnnGetRNNBiasMode( cudnnRNNDescriptor_t rnnDesc, cudnnRNNBiasMode_t *biasMode)
This function retrieves the RNN bias mode that was configured by cudnnSetRNNBiasMode(). The default value of biasMode in rnnDesc after cudnnCreateRNNDescriptor() is CUDNN_RNN_DOUBLE_BIAS.
7.2.19. cudnnGetRNNDataDescriptor()
cudnnStatus_t cudnnGetRNNDataDescriptor(
cudnnRNNDataDescriptor_t RNNDataDesc,
cudnnDataType_t *dataType,
cudnnRNNDataLayout_t *layout,
int *maxSeqLength,
int *batchSize,
int *vectorSize,
int arrayLengthRequested,
int seqLengthArray[],
void *paddingFill);
Parameters
- Input. A previously created and initialized RNN descriptor.
- Output. Pointer to the host memory location to store the datatype of the RNN data tensor.
- Output. Pointer to the host memory location to store the memory layout of the RNN data tensor.
- Output. The maximum sequence length within this RNN data tensor, including the padding vectors.
- Output. The number of sequences within the mini-batch.
- Output. The vector length (meaning, embedding size) of the input or output tensor at each time-step.
- Input. The number of elements that the user requested for seqLengthArray.
- Output. Pointer to the host memory location to store the integer array describing the length (meaning, number of time-steps) of each sequence. This is allowed to be a NULL pointer if arrayLengthRequested is 0.
- Output. Pointer to the host memory location to store the user defined symbol. The symbol should be interpreted as the same data type as the RNN data tensor.
7.2.20. cudnnGetRNNDescriptor_v6()
cudnnStatus_t cudnnGetRNNDescriptor_v6( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int *hiddenSize, int *numLayers, cudnnDropoutDescriptor_t *dropoutDesc, cudnnRNNInputMode_t *inputMode, cudnnDirectionMode_t *direction, cudnnRNNMode_t *cellMode, cudnnRNNAlgo_t *algo, cudnnDataType_t *mathPrec) {
This function retrieves RNN network parameters that were configured by cudnnSetRNNDescriptor_v6(). All pointers passed to the function should be not-NULL or CUDNN_STATUS_BAD_PARAM is reported. The function does not check the validity of retrieved parameters.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously created and initialized RNN descriptor.
- Output. Pointer to where the size of the hidden state should be stored (the same value is used in every RNN layer).
- Output. Pointer to where the number of RNN layers should be stored.
- Output. Pointer to where the handle to a previously configured dropout descriptor should be stored.
- Output. Pointer to where the mode of the first RNN layer should be saved.
- Output. Pointer to where RNN unidirectional/bidirectional mode should be saved.
- Output. Pointer to where RNN cell type should be saved.
- Output. Pointer to where RNN algorithm type should be stored.
- Output. Pointer to where the math precision type should be stored.
7.2.21. cudnnGetRNNDescriptor_v8()
cudnnStatus_t cudnnGetRNNDescriptor_v8(
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNAlgo_t *algo,
cudnnRNNMode_t *cellMode,
cudnnRNNBiasMode_t *biasMode,
cudnnDirectionMode_t *dirMode,
cudnnRNNInputMode_t *inputMode,
cudnnDataType_t *dataType,
cudnnDataType_t *mathPrec,
cudnnMathType_t *mathType,
int32_t *inputSize,
int32_t *hiddenSize,
int32_t *projSize,
int32_t *numLayers,
cudnnDropoutDescriptor_t *dropoutDesc,
uint32_t *auxFlags);
Parameters
- Input. A previously created and initialized RNN descriptor.
- Output. Pointer to where RNN algorithm type should be stored.
- Output. Pointer to where RNN cell type should be saved.
- Output. Pointer to where RNN bias mode cudnnRNNBiasMode_t should be saved.
- Output. Pointer to where RNN unidirectional/bidirectional mode should be saved.
- Output. Pointer to where the mode of the first RNN layer should be saved.
- Output. Pointer to where the data type of RNN weights/biases should be stored.
- Output. Pointer to where the math precision type should be stored.
- Output. Pointer to where the preferred option for Tensor Cores are saved.
- Output. Pointer to where the RNN input vector size is stored.
- Output. Pointer to where the size of the hidden state should be stored (the same value is used in every RNN layer).
- Output. Pointer to where the LSTM cell output size after the recurrent projection is stored.
- Output. Pointer to where the number of RNN layers should be stored.
- Output. Pointer to where the handle to a previously configured dropout descriptor should be stored.
- Output. Pointer to miscellaneous RNN options (flags) that do not require passing additional numerical values to configure.
Returns
- RNN parameters were successfully retrieved from the RNN descriptor.
- An invalid input argument was found (rnnDesc was NULL).
- The RNN descriptor was configured with the legacy cudnnSetRNNDescriptor_v6() call.
7.2.22. cudnnGetRNNForwardInferenceAlgorithmMaxCount()
7.2.23. cudnnGetRNNLinLayerBiasParams()
cudnnStatus_t cudnnGetRNNLinLayerBiasParams(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int pseudoLayer,
const cudnnTensorDescriptor_t xDesc,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const int linLayerID,
cudnnFilterDescriptor_t linLayerBiasDesc,
void **linLayerBias)This function is used to obtain a pointer and a descriptor of every RNN bias column vector in each pseudo-layer within the recurrent network defined by rnnDesc and its input width specified in xDesc.
The cudnnGetRNNLinLayerBiasParams() function returns the RNN bias vector size in two dimensions: rows and columns.
filterDimA[0]=total_size, filterDimA[1]=1, filterDimA[2]=1For more information, see the description of the cudnnGetFilterNdDescriptor() function.
filterDimA[0]=1, filterDimA[1]=rows, filterDimA[2]=1 (number of columns)In both cases, the format field of the filter descriptor should be ignored when retrieved by cudnnGetFilterNdDescriptor().
filterDimA[0]=0, filterDimA[1]=0, and filterDimA[2]=2and sets linLayerBias to NULL. Refer to the details for the function parameter linLayerID to determine the relevant values of linLayerID based on biasMode.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. The pseudo-layer to query. In unidirectional RNNs, a
pseudo-layer is the same as a physical layer
(pseudoLayer=0 is the RNN input layer,
pseudoLayer=1 is the first hidden layer). In
bidirectional RNNs, there are twice as many pseudo-layers in comparison
to physical layers.
- pseudoLayer=0 refers to the forward part of the physical input layer
- pseudoLayer=1 refers to the backward part of the physical input layer
- pseudoLayer=2 is the forward part of the first hidden layer, and so on
- Input. A fully packed tensor descriptor describing the input to one recurrent iteration (to retrieve the RNN input width).
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. Linear ID index of the weight matrix.
If cellMode in rnnDesc was set to CUDNN_RNN_RELU or CUDNN_RNN_TANH:- Value 0 references the weight matrix used in conjunction with the input from the previous layer or input to the RNN model.
- Value 1 references the weight matrix used in conjunction with the hidden state from the previous time step or the initial hidden state.
If cellMode in rnnDesc was set to CUDNN_LSTM:- Values 0, 1, 2, and 3 reference weight matrices used in conjunction with the input from the previous layer or input to the RNN model.
- Values 4, 5, 6, and 7 reference weight matrices used in conjunction with the hidden state from the previous time step or the initial hidden state.
- Value 8 corresponds to the projection matrix, if enabled.
Values and their LSTM gates:- linLayerID0 and 4 correspond to the input gate.
- linLayerID1 and 5 correspond to the forget gate.
- linLayerID2 and 6 correspond to the new cell state calculations with a hyperbolic tangent.
- linLayerID3 and 7 correspond to the output gate.
If cellMode in rnnDesc was set to CUDNN_GRU:- Values 0, 1, and 2 reference weight matrices used in conjunction with the input from the previous layer or input to the RNN model.
- Values 3, 4, and 5 reference weight matrices used in conjunction with the hidden state from the previous time step or the initial hidden state.
- Output. Handle to a previously created filter descriptor.
- Output. Data pointer to GPU memory associated with the filter descriptor linLayerBiasDesc.
Returns
- The query was successful.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the following arguments is NULL: handle, rnnDesc, xDesc, wDesc, linLayerBiasDesc, or linLayerBias.
- A data type mismatch was detected between rnnDesc and other descriptors.
- Minimum requirement for the w pointer alignment is not satisfied.
- The value of pseudoLayer or linLayerID is out of range.
- Some elements of the linLayerBias vector are outside the w buffer boundaries as specified by the wDesc descriptor.
7.2.24. cudnnGetRNNLinLayerMatrixParams()
cudnnStatus_t cudnnGetRNNLinLayerMatrixParams( cudnnHandle_t handle, const cudnnRNNDescriptor_t rnnDesc, const int pseudoLayer, const cudnnTensorDescriptor_t xDesc, const cudnnFilterDescriptor_t wDesc, const void *w, const int linLayerID, cudnnFilterDescriptor_t linLayerMatDesc, void **linLayerMat)
This function is used to obtain a pointer and a descriptor of every RNN weight matrix in each pseudo-layer within the recurrent network defined by rnnDesc and its input width specified in xDesc.
The cudnnGetRNNLinLayerMatrixParams() function returns the RNN matrix size in two dimensions: rows and columns. This allows the user to easily print and initialize RNN weight matrices. Elements in each weight matrix are arranged in the row-major order. Due to historical reasons, the minimum number of dimensions in the filter descriptor is three. In previous versions of the cuDNN library, the function returned the total number of weights in linLayerMatDesc as follows: filterDimA[0]=total_size, filterDimA[1]=1, filterDimA[2]=1 (see the description of the cudnnGetFilterNdDescriptor() function). In cuDNN 7.1.1, the format was changed to: filterDimA[0]=1, filterDimA[1]=rows, filterDimA[2]=columns. In both cases, the "format" field of the filter descriptor should be ignored when retrieved by cudnnGetFilterNdDescriptor().
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. The pseudo-layer to query. In unidirectional RNNs, a
pseudo-layer is the same as a physical layer
(pseudoLayer=0 is the RNN input layer,
pseudoLayer=1 is the first hidden layer). In
bidirectional RNNs, there are twice as many pseudo-layers in comparison
to physical layers.
- pseudoLayer=0 refers to the forward part of the physical input layer
- pseudoLayer=1 refers to the backward part of the physical input layer
- pseudoLayer=2 is the forward part of the first hidden layer, and so on
- Input. A fully packed tensor descriptor describing the input to one recurrent iteration (to retrieve the RNN input width).
-
Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. The linear layer to obtain information about:
- If mode in rnnDesc was set
to CUDNN_RNN_RELU or
CUDNN_RNN_TANH:
- Value 0 references the bias applied to the input from the previous layer (relevant if biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_DOUBLE_BIAS).
- Value 1 references the bias applied to the recurrent input (relevant if biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS or CUDNN_RNN_SINGLE_REC_BIAS).
- If mode in rnnDesc was set
to CUDNN_LSTM:
- Values of 0, 1, 2 and 3 reference bias applied to the input from the previous layer (relevant if biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_DOUBLE_BIAS).
- Values of 4, 5, 6 and 7 reference bias applied to the recurrent input (relevant if biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS or CUDNN_RNN_SINGLE_REC_BIAS).
- Values and their associated gates:
- Values 0 and 4 reference the input gate.
- Values 1 and 5 reference the forget gate.
- Values 2 and 6 reference the new memory gate.
- Values 3 and 7 reference the output gate.
- If mode in rnnDesc was set
to CUDNN_GRU:
- Values of 0, 1 and 2 reference bias applied to the input from the previous layer (relevant if biasMode in rnnDesc is CUDNN_RNN_SINGLE_INP_BIAS or CUDNN_RNN_DOUBLE_BIAS).
- Values of 3, 4 and 5 reference bias applied to the recurrent input (relevant if biasMode in rnnDesc is CUDNN_RNN_DOUBLE_BIAS or CUDNN_RNN_SINGLE_REC_BIAS).
- Values and their associated gates:
- Values 0 and 3 reference the reset gate.
- Values 1 and 4 reference the update gate.
- Values 2 and 5 reference the new memory gate.
For more information on modes and bias modes, refer to cudnnRNNMode_t.
- If mode in rnnDesc was set
to CUDNN_RNN_RELU or
CUDNN_RNN_TANH:
- Output. Handle to a previously created filter descriptor. When the weight matrix does not exist, the returned filer descriptor has all fields set to zero.
- Output. Data pointer to GPU memory associated with the filter descriptor linLayerMatDesc. When the weight matrix does not exist, the returned pointer is NULL.
Returns
- The query was successful.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- One of the following arguments is NULL: handle, rnnDesc, xDesc, wDesc, linLayerMatDesc, or linLayerMat.
- A data type mismatch was detected between rnnDesc and other descriptors.
- Minimum requirement for the w pointer alignment is not satisfied.
- The value of pseudoLayer or linLayerID is out of range.
- Some elements of the linLayerMat vector are outside the w buffer boundaries as specified by the wDesc descriptor.
7.2.25. cudnnGetRNNMatrixMathType()
cudnnStatus_t cudnnGetRNNMatrixMathType( cudnnRNNDescriptor_t rnnDesc, cudnnMathType_t *mType);
This function retrieves the preferred settings for NVIDIA Tensor Cores on NVIDIA Volta™ (SM 7.0) or higher GPUs. Refer to the cudnnMathType_t description for more details.
7.2.26. cudnnGetRNNPaddingMode()
cudnnStatus_t cudnnGetRNNPaddingMode(
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNPaddingMode_t *paddingMode)This function retrieves the RNN padding mode from the RNN descriptor.
7.2.27. cudnnGetRNNParamsSize()
cudnnStatus_t cudnnGetRNNParamsSize(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const cudnnTensorDescriptor_t xDesc,
size_t *sizeInBytes,
cudnnDataType_t dataType)This function is used to query the amount of parameter space required to execute the RNN described by rnnDesc with input dimensions defined by xDesc.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. A fully packed tensor descriptor describing the input to one recurrent iteration.
- Output. Minimum amount of GPU memory needed as parameter space to be able to execute an RNN with the specified descriptor and input tensors.
- Input. The data type of the parameters.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- The descriptor xDesc is invalid.
- The descriptor xDesc is not fully packed.
- The combination of dataType and tensor descriptor data type is invalid.
- The combination of the RNN descriptor and tensor descriptors is not supported.
7.2.28. cudnnGetRNNProjectionLayers()
cudnnStatus_t cudnnGetRNNProjectionLayers(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
int *recProjSize,
int *outProjSize)This function retrieves the current RNN projection parameters. By default, the projection feature is disabled so invoking this function will yield recProjSize equal to hiddenSize and outProjSize set to zero. The cudnnSetRNNProjectionLayers() method enables the RNN projection.
7.2.29. cudnnGetRNNTempSpaceSizes()
cudnnStatus_t cudnnGetRNNTempSpaceSizes(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnForwardMode_t fMode,
cudnnRNNDataDescriptor_t xDesc,
size_t *workSpaceSize,
size_t *reserveSpaceSize);
The user can assign NULL to workSpaceSize or reserveSpaceSize pointers when the corresponding value is not needed.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized RNN descriptor.
- Input. Specifies whether temporary buffers are used in inference or training modes. The reserve-space buffer is not used during inference. Therefore, the returned size of the reserve space buffer will be zero when the fMode argument is CUDNN_FWD_MODE_INFERENCE.
- Input. A single RNN data descriptor that specifies current RNN data dimensions: maxSeqLength and batchSize.
- Output. Minimum amount of GPU memory in bytes needed as a workspace buffer. The workspace buffer is not used to pass intermediate results between APIs but as a temporary read/write buffer.
- Output. Minimum amount of GPU memory in bytes needed as the reserve-space buffer. The reserve space buffer is used to pass intermediate results from cudnnRNNForward() to RNN BackwardData and BackwardWeights routines that compute first order derivatives with respect to RNN inputs or trainable weight and biases.
7.2.30. cudnnGetRNNTrainingReserveSize()
cudnnStatus_t cudnnGetRNNTrainingReserveSize(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
size_t *sizeInBytes)This function is used to query the amount of reserved space required for training the RNN described by rnnDesc with input dimensions defined by xDesc. The same reserved space buffer must be passed to cudnnRNNForwardTraining(), cudnnRNNBackwardData(), and cudnnRNNBackwardWeights(). Each of these calls overwrites the contents of the reserved space, however it can safely be backed up and restored between calls if reuse of the memory is desired.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Output. Minimum amount of GPU memory needed as reserve space to be able to train an RNN with the specified descriptor and input tensors.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors in xDesc is invalid.
- The descriptors in xDesc have inconsistent second dimensions, strides or data types.
- The descriptors in xDesc have increasing first dimensions.
- The descriptors in xDesc are not fully packed.
- The data types in tensors described by xDesc are not supported.
7.2.31. cudnnGetRNNWeightParams()
cudnnStatus_t cudnnGetRNNWeightParams( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, int32_t pseudoLayer, size_t weightSpaceSize, const void *weightSpace, int32_t linLayerID, cudnnTensorDescriptor_t mDesc, void **mAddr, cudnnTensorDescriptor_t bDesc, void **bAddr);
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. The pseudo-layer to query. In unidirectional RNNs, a
pseudo-layer is the same as a physical layer
(pseudoLayer=0 is the RNN input layer,
pseudoLayer=1 is the first hidden layer). In
bidirectional RNNs, there are twice as many pseudo-layers in comparison
to physical layers:
- pseudoLayer=0 refers to the forward direction sub-layer of the physical input layer
- pseudoLayer=1 refers to the backward direction sub-layer of the physical input layer
- pseudoLayer=2 is the forward direction sub-layer of the first hidden layer, and so on
- Input. Size of the weight space buffer in bytes.
- Input. Pointer to the weight space buffer.
-
Input. Weight matrix or bias vector linear ID index.
If cellMode in rnnDesc was set to CUDNN_RNN_RELU or CUDNN_RNN_TANH:- Value 0 references the weight matrix or bias vector used in conjunction with the input from the previous layer or input to the RNN model.
- Value 1 references the weight matrix or bias vector used in conjunction with the hidden state from the previous time step or the initial hidden state.
If cellMode in rnnDesc was set to CUDNN_LSTM:- Values 0, 1, 2 and 3 reference weight matrices or bias vectors used in conjunction with the input from the previous layer or input to the RNN model.
- Values 4, 5, 6 and 7 reference weight matrices or bias vectors used in conjunction with the hidden state from the previous time step or the initial hidden state.
- Value 8 corresponds to the projection matrix, if enabled (there is no bias in this operation).
Values and their LSTM gates:- linLayerID0 and 4 correspond to the input gate.
- linLayerID1 and 5 correspond to the forget gate.
- linLayerID2 and 6 correspond to the new cell state calculations with hyperbolic tangent.
- linLayerID3 and 7 correspond to the output gate.
If cellMode in rnnDesc was set to CUDNN_GRU:- Values 0, 1 and 2 reference weight matrices or bias vectors used in conjunction with the input from the previous layer or input to the RNN model.
- Values 3, 4 and 5 reference weight matrices or bias vectors used in conjunction with the hidden state from the previous time step or the initial hidden state.
Values and their GRU gates:- linLayerID0 and 3 correspond to the reset gate.
- linLayerID1 and 4 reference to the update gate.
- linLayerID2 and 5 correspond to the new hidden state calculations with hyperbolic tangent.
For more information on modes and bias modes, refer to cudnnRNNMode_t.
- Output. Handle to a previously created tensor descriptor. The shape of the corresponding weight matrix is returned in this descriptor in the following format: dimA[3] = {1, rows, cols}. The reported number of tensor dimensions is zero when the weight matrix does not exist. This situation occurs for input GEMM matrices of the first layer when CUDNN_SKIP_INPUT is selected or for the LSTM projection matrix when the feature is disabled.
- Output. Pointer to the beginning of the weight matrix within the weight space buffer. When the weight matrix does not exist, the returned address is NULL.
- Output. Handle to a previously created tensor descriptor. The shape of the corresponding bias vector is returned in this descriptor in the following format: dimA[3] = {1, rows, 1}. The reported number of tensor dimensions is zero when the bias vector does not exist.
- Output. Pointer to the beginning of the bias vector within the weight space buffer. When the bias vector does not exist, the returned address is NULL.
Returns
- The query was completed successfully.
- An invalid input argument was encountered. For example, the value of pseudoLayer is out of range or linLayerID is negative or larger than 8.
- Some weight/bias elements are outside the weight space buffer boundaries.
- The RNN descriptor was configured with the legacy cudnnSetRNNDescriptor_v6() call.
7.2.32. cudnnGetRNNWeightSpaceSize()
cudnnStatus_t cudnnGetRNNWeightSpaceSize( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, size_t *weightSpaceSize);
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized RNN descriptor.
- Output. Minimum size in bytes of GPU memory needed for all RNN trainable parameters.
Returns
- The query was successful.
- An invalid input argument was encountered. For example, any input argument was NULL.
- The RNN descriptor was configured with the legacy cudnnSetRNNDescriptor_v6() call.
7.2.33. cudnnGetRNNWorkspaceSize()
cudnnStatus_t cudnnGetRNNWorkspaceSize(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
size_t *sizeInBytes)This function is used to query the amount of work space required to execute the RNN described by rnnDesc with input dimensions defined by xDesc.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. Workspace that is allocated, based on the size that this function provides, cannot be used for sequences longer than seqLength.
-
Input. An array of tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. For example, if you have multiple time series in a batch, they can be different lengths. This dimension is the batch size for the particular iteration of the sequence, and so it should decrease when a sequence in the batch has been terminated.
Each tensor descriptor must have the same second dimension (vector length).
- Output. Minimum amount of GPU memory needed as workspace to be able to execute an RNN with the specified descriptor and input tensors.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors in xDesc is invalid.
- The descriptors in xDesc have inconsistent second dimensions, strides or data types.
- The descriptors in xDesc have increasing first dimensions.
- The descriptors in xDesc are not fully packed.
- The data types in tensors described by xDesc are not supported.
7.2.34. cudnnGetSeqDataDescriptor()
cudnnStatus_t cudnnGetSeqDataDescriptor( const cudnnSeqDataDescriptor_t seqDataDesc, cudnnDataType_t *dataType, int *nbDims, int nbDimsRequested, int dimA[], cudnnSeqDataAxis_t axes[], size_t *seqLengthArraySize, size_t seqLengthSizeRequested, int seqLengthArray[], void *paddingFill);
// Array holding sequence data strides.
size_t strA[CUDNN_SEQDATA_DIM_COUNT] = {0};
// Compute strides from dimension and order arrays.
size_t stride = 1;
for (int i = nbDims - 1; i >= 0; i--) {
int j = int(axes[i]);
if (unsigned(j) < CUDNN_SEQDATA_DIM_COUNT-1 && strA[j] == 0) {
strA[j] = stride;
stride *= dimA[j];
} else {
fprintf(stderr, "ERROR: invalid axes[%d]=%d\n\n", i, j);
abort();
}
}
// Using four indices (batch, beam, time, vect) with ranges already checked.
size_t base = strA[CUDNN_SEQDATA_BATCH_DIM] * batch
+ strA[CUDNN_SEQDATA_BEAM_DIM] * beam
+ strA[CUDNN_SEQDATA_TIME_DIM] * time;
val = seqDataPtr[base + vect];
The above code assumes that all four indices (batch, beam, time, vect) are less than the corresponding value in the dimA[] array. The sample code also omits the strA[CUDNN_SEQDATA_VECT_DIM] stride because its value is always 1, meaning, elements of one vector occupy a contiguous block of memory.
Parameters
- Input. Sequence data descriptor.
- Output. Data type used in the sequence data buffer.
- Output. The number of active dimensions in the dimA[] and axes[] arrays.
- Input. The maximum number of consecutive elements that can be written to dimA[] and axes[] arrays starting from index zero. The recommended value for this argument is CUDNN_SEQDATA_DIM_COUNT.
- Output. Integer array holding sequence data dimensions.
- Output. Array of cudnnSeqDataAxis_t that defines the layout of sequence data in memory.
- Output. The number of required elements in seqLengthArray[] to save all sequence lengths.
- Input. The maximum number of consecutive elements that can be written to the seqLengthArray[] array starting from index zero.
- Output. Integer array holding sequence lengths.
- Output. Pointer to a storage location of dataType with the fill value that should be written to all padding vectors. Use NULL when an explicit initialization of output padding vectors was not requested.
7.2.35. cudnnMultiHeadAttnForward()
cudnnStatus_t cudnnMultiHeadAttnForward( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, int currIdx, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsQO[], const int devSeqLengthsKV[], const cudnnSeqDataDescriptor_t qDesc, const void *queries, const void *residuals, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t oDesc, void *out, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
In the inference mode, the currIdx specifies the time-step or sequence index of the embedding vectors to be processed. In this mode, the user can perform one iteration for time-step zero (currIdx=0), then update Q, K, V vectors and the attention window, and execute the next step (currIdx=1). The iterative process can be repeated for all time-steps.
When all Q time-steps are available (for example, in the training mode or in the inference mode on the encoder side in self-attention),the user can assign a negative value to currIdx and the cudnnMultiHeadAttnForward() API will automatically sweep through all Q time-steps.
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=0; // initial time-step, no attention window currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=1; // attention window spans one vector currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=2; // attention window spans two vectors (...)
When currIdx is negative in cudnnMultiHeadAttnForward(), the loWinIdx[] and hiWinIdx[] arrays must be fully initialized for all time-steps. When cudnnMultiHeadAttnForward() is invoked with currIdx=0, currIdx=1, currIdx=2, etc., then the user can update loWinIdx[currIdx] and hiWinIdx[currIdx] elements only before invoking the forward response function. All other elements in the loWinIdx[] and hiWinIdx[] arrays will not be accessed. Any adaptive attention window scheme can be implemented that way.
currIdx=0: loWinIdx[0]=0; hiWinIdx[0]=maxSeqLenK; currIdx=1: loWinIdx[1]=0; hiWinIdx[1]=maxSeqLenK; currIdx=2: loWinIdx[2]=0; hiWinIdx[2]=maxSeqLenK; (...)
devSeqLengthsQO[] and devSeqLengthsKV[] are pointers to device (not host) arrays with Q, O, and K, V sequence lengths. Note that the same information is also passed in the corresponding descriptors of type cudnnSeqDataDescriptor_t on the host side. The need for extra device arrays comes from the asynchronous nature of cuDNN calls and limited size of the constant memory dedicated to GPU kernel arguments. When the cudnnMultiHeadAttnForward() API returns, the sequence length arrays stored in the descriptors can be immediately modified for the next iteration. However, the GPU kernels launched by the forward call may not have started at this point. For this reason, copies of sequence arrays are needed on the device side to be accessed directly by GPU kernels. Those copies cannot be created inside the cudnnMultiHeadAttnForward() function for very large K, V inputs without the device memory allocation and CUDA stream synchronization.
To reduce the cudnnMultiHeadAttnForward() API overhead, devSeqLengthsQO[] and devSeqLengthsKV[] device arrays are not validated to contain the same settings as seqLengthArray[] in the sequence data descriptors.
Sequence lengths in the kDesc and vDesc descriptors should be the same. Similarly, sequence lengths in the qDesc and oDesc descriptors should match. The user can define six different data layouts in the qDesc, kDesc, vDesc and oDesc descriptors. Refer to the cudnnSetSeqDataDescriptor() function for the discussion of those layouts. All multi-head attention API calls require that the same layout is used in all sequence data descriptors.
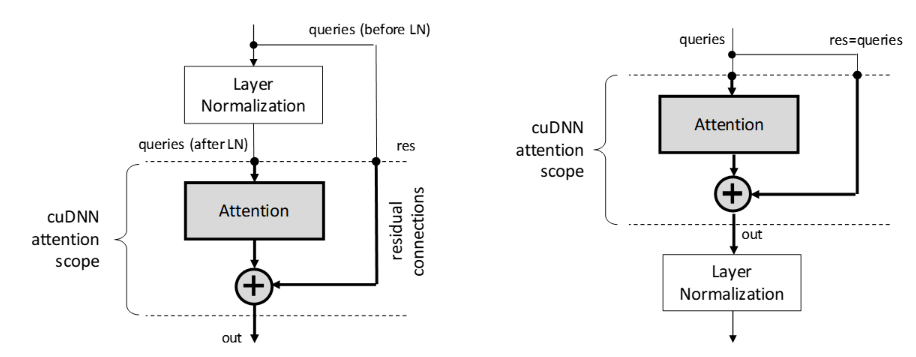
Queries and residuals share the same qDesc descriptor in cudnnMultiHeadAttnForward(). When residual connections are disabled, the residuals pointer should be NULL. When residual connections are enabled, the vector length in qDesc should match the vector length specified in the oDesc descriptor, so that a vector addition is feasible.
The queries, keys, and values pointers are not allowed to be NULL, even when K and V are the same inputs or Q, K, V are the same inputs.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized attention descriptor.
- Input. Time-step in queries to process. When the currIdx argument is negative, all Q time-steps are processed. When currIdx is zero or positive, the forward response is computed for the selected time-step only. The latter input can be used in inference mode only, to process one time-step while updating the next attention window and Q, R, K, V inputs in-between calls.
- Input. Two host integer arrays specifying the start and end indices of the attention window for each Q time-step. The start index in K, V sets is inclusive, and the end index is exclusive.
- Input. Device array specifying sequence lengths of query, residual, and output sequence data.
- Input. Device array specifying sequence lengths of key and value input data.
- Input. Descriptor for the query and residual sequence data.
- Input. Pointer to queries data in the device memory.
- Input. Pointer to residual data in device memory. Set this argument to NULL if no residual connections are required.
- Input. Descriptor for the keys sequence data.
- Input. Pointer to keys data in device memory.
- Input. Descriptor for the values sequence data.
- Input. Pointer to values data in device memory.
- Input. Descriptor for the multi-head attention output sequence data.
- Output. Pointer to device memory where the output response should be written.
- Input. Size of the weight buffer in bytes where all multi-head attention trainable parameters are stored.
- Input. Pointer to the weight buffer in device memory.
- Input. Size of the work-space buffer in bytes used for temporary API storage.
- Input/Output. Pointer to the work-space buffer in device memory.
- Input. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls. This parameter should be zero in the inference mode and non-zero in the training mode.
- Input/Output. Pointer to the reserve-space buffer in device memory. This argument should be NULL in inference mode and non-NULL in the training mode.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- An invalid or incompatible input argument was encountered. Some examples
include:
- a required input pointer was NULL
- currIdx was out of bound
- the descriptor value for attention, query, key, value, and output were incompatible with one another
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- An inconsistent internal state was encountered.
- A requested option or a combination of input arguments is not supported.
- Insufficient amount of shared memory to launch a GPU kernel.
7.2.36. cudnnRNNForward()
cudnnStatus_t cudnnRNNForward(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnForwardMode_t fwdMode,
const int32_t devSeqLengths[],
cudnnRNNDataDescriptor_t xDesc,
const void *x,
cudnnRNNDataDescriptor_t yDesc,
void *y,
cudnnTensorDescriptor_t hDesc,
const void *hx,
void *hy,
cudnnTensorDescriptor_t cDesc,
const void *cx,
void *cy,
size_t weightSpaceSize,
const void *weightSpace,
size_t workSpaceSize,
void *workSpace,
size_t reserveSpaceSize,
void *reserveSpace);
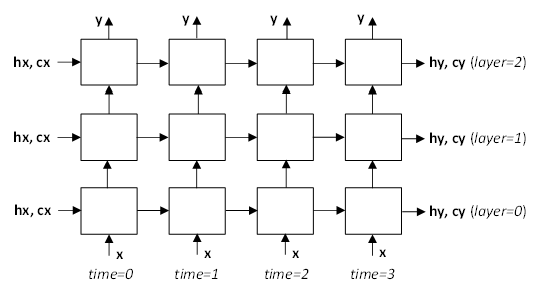
The next figure depicts data flow when the RNN model is bidirectional. In this mode each RNN physical layer consists of two consecutive pseudo-layers, each with its own weights, biases, the initial hidden state hx, and for LSTM, also the initial cell state cx. Even pseudo-layers 0, 2, 4 process input vectors from left to right or in the forward (F) direction. Odd pseudo-layers 1, 3, 5 process input vectors from right to left or in the reverse (R) direction. Two successive pseudo-layers operate on the same input vectors, just in a different order. Pseudo-layers 0 and 1 access the original sequences stored in the x buffer. Outputs of F and R cells are concatenated so vectors fed to the next two pseudo-layers have lengths of 2x hiddenSize or 2x projSize. Input GEMMs in subsequent pseudo-layers adjust vector lengths to 1x hiddenSize.
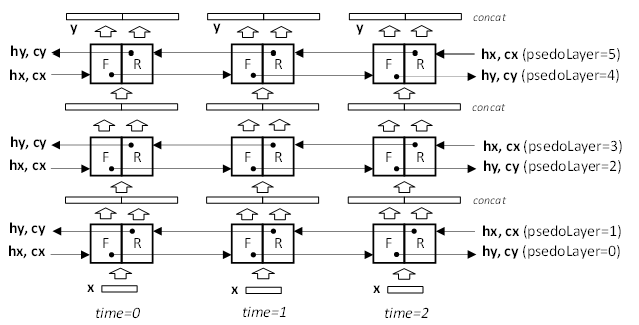
When the fwdMode parameter is set to CUDNN_FWD_MODE_TRAINING, the cudnnRNNForward() function stores intermediate data required to compute first order derivatives in the reserve space buffer. Work and reserve space buffer sizes should be computed by the cudnnGetRNNTempSpaceSizes() function with the same fwdMode setting as used in the cudnnRNNForward() call.
The same layout type must be specified in xDesc and yDesc descriptors. The same sequence lengths must be configured in xDesc, yDesc and in the device array devSeqLengths. The cudnnRNNForward() function does not verify that sequence lengths stored in devSeqLengths in GPU memory are the same as in xDesc and yDesc descriptors in CPU memory. Sequence length arrays from xDesc and yDesc descriptors are checked for consistency, however.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized RNN descriptor.
- Input. Specifies inference or training mode (CUDNN_FWD_MODE_INFERENCE and CUDNN_FWD_MODE_TRAINING). In the training mode, additional data is stored in the reserve space buffer. This information is used in the backward pass to compute derivatives.
- Input. A copy of seqLengthArray from xDesc or yDesc RNN data descriptor. The devSeqLengths array must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after the cudnnRNNForward() function exists. This argument cannot be NULL.
- Input. A previously initialized descriptor corresponding to the RNN model primary input. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray must match that of yDesc. The parameter vectorSize must match the inputSize argument passed to the cudnnSetRNNDescriptor_v8() function.
- Input. Data pointer to the GPU memory associated with the RNN data descriptor xDesc. The vectors are expected to be arranged in memory according to the layout specified by xDesc. The elements in the tensor (including padding vectors) must be densely packed.
- Input. A previously initialized RNN data descriptor. The
dataType, layout,
maxSeqLength, batchSize, and
seqLengthArray must match that of
xDesc. The parameter vectorSize
depends on whether LSTM projection is enabled and whether the network is
bi-directional. Specifically:
- For uni-directional models, the parameter vectorSize must match the hiddenSize argument passed to cudnnSetRNNDescriptor_v8(). If the LSTM projection is enabled, the vectorSize must be the same as the projSize argument passed to cudnnSetRNNDescriptor_v8().
- For bi-directional models, if the RNN cellMode is CUDNN_LSTM and the projection feature is enabled, the parameter vectorSize must be 2x the projSize argument passed to cudnnSetRNNDescriptor_v8(). Otherwise, it should be 2x the hiddenSize value.
- Output. Data pointer to the GPU memory associated with the RNN data descriptor yDesc. The vectors are expected to be laid out in memory according to the layout specified by yDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
-
Input. A tensor descriptor describing the initial or final hidden state of RNN. Hidden state data are fully packed. The first dimension of the tensor depends on the dirMode argument passed to the cudnnSetRNNDescriptor_v8() function.
- If dirMode is CUDNN_UNIDIRECTIONAL, then the first dimension should match the numLayers argument passed to cudnnSetRNNDescriptor_v8().
- If dirMode is CUDNN_BIDIRECTIONAL, then the first dimension should be double the numLayers argument passed to cudnnSetRNNDescriptor_v8().
The second dimension must match the batchSize parameter described in xDesc. The third dimension depends on whether RNN mode is CUDNN_LSTM and whether the LSTM projection is enabled. Specifically:- If RNN mode is CUDNN_LSTM and LSTM projection is enabled, the third dimension must match the projSize argument passed to the cudnnSetRNNProjectionLayers() call.
- Otherwise, the third dimension must match the hiddenSize argument passed to the cudnnSetRNNDescriptor_v8() call used to initialize rnnDesc.
- Input. Pointer to the GPU buffer with the RNN initial hidden state. Data dimensions are described by the hDesc tensor descriptor. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
- Output. Pointer to the GPU buffer where the final RNN hidden state should be stored. Data dimensions are described by the hDesc tensor descriptor. If a NULL pointer is passed, the final hidden state of the network will not be saved.
-
Input. For LSTM networks only. A tensor descriptor describing the initial or final cell state for LSTM networks only. Cell state data are fully packed. The first dimension of the tensor depends on the dirMode argument passed to the cudnnSetRNNDescriptor_v8() call.
- If dirMode is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument passed to cudnnSetRNNDescriptor_v8().
- If dirMode is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument passed to cudnnSetRNNDescriptor_v8().
The second tensor dimension must match the batchSize parameter in xDesc. The third dimension must match the hiddenSize argument passed to the cudnnSetRNNDescriptor_v8() call.
- Input. For LSTM networks only. Pointer to the GPU buffer with the initial LSTM state data. Data dimensions are described by the cDesc tensor descriptor. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Output. For LSTM networks only. Pointer to the GPU buffer where final LSTM state data should be stored. Data dimensions are described by the cDesc tensor descriptor. If a NULL pointer is passed, the final LSTM cell state will not be saved.
- Input. Specifies the size in bytes of the provided weight-space buffer.
- Input. Address of the weight space buffer in GPU memory.
- Input. Specifies the size in bytes of the provided workspace buffer.
- Input/Output. Address of the workspace buffer in GPU memory to store temporary data.
- Input. Specifies the size in bytes of the reserve-space buffer.
- Input/Output. Address of the reserve-space buffer in GPU memory.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- At least one of the following conditions are met:
- variable sequence length input is passed while CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is specified
- CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is requested on pre-Pascal devices
- the 'double' floating point type is used for input/output and the CUDNN_RNN_ALGO_PERSIST_STATIC algo
- An invalid or incompatible input argument was encountered. For
example:
- some input descriptors are NULL
- at least one of the settings in rnnDesc, xDesc, yDesc, hDesc, or cDesc descriptors is invalid
- weightSpaceSize, workSpaceSize, or reserveSpaceSize is too small
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- The function was unable to allocate CPU memory.
7.2.37. cudnnRNNForwardInference()
cudnnStatus_t cudnnRNNForwardInference(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t *yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
void *workspace,
size_t workSpaceSizeInBytes)This routine executes the recurrent neural network described by rnnDesc with inputs x, hx, and cx, weights w and outputs y, hy, and cy. workspace is required for intermediate storage. This function does not store intermediate data required for training; cudnnRNNForwardTraining() should be used for that purpose.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of seqLength fully packed tensor
descriptors. Each descriptor in the array should have three dimensions
that describe the input data format to one recurrent iteration (one
descriptor per RNN time-step). The first dimension (batch size) of the
tensors may decrease from iteration n to iteration
n+1 but may not increase. Each tensor descriptor
must have the same second dimension (RNN input vector length,
inputSize). The third dimension of each tensor
should be 1. Input data are expected to be arranged in the column-major
order so strides in xDesc should be set as follows:
strideA[0]=inputSize, strideA[1]=1, strideA[2]=1
- Input. Data pointer to GPU memory associated with the array of tensor descriptors xDesc. The input vectors are expected to be packed contiguously with the first vector of iteration (time-step) n+1 following directly from the last vector of iteration n. In other words, input vectors for all RNN time-steps should be packed in the contiguous block of GPU memory with no gaps between the vectors.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in xDesc.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc. The data are expected to be packed contiguously with the first element of iteration n+1 following directly from the last element of iteration n.
-
Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
-
Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, cxDesc, wDesc, hyDesc, cyDesc or one of the descriptors in xDesc, or yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, cxDesc, wDesc, yDesc, hyDesc, or cyDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
7.2.38. cudnnRNNForwardInferenceEx()
cudnnStatus_t cudnnRNNForwardInferenceEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const cudnnRNNDataDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnRNNDataDescriptor_t yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
const cudnnRNNDataDescriptor_t kDesc,
const void *keys,
const cudnnRNNDataDescriptor_t cDesc,
void *cAttn,
const cudnnRNNDataDescriptor_t iDesc,
void *iAttn,
const cudnnRNNDataDescriptor_t qDesc,
void *queries,
void *workSpace,
size_t workSpaceSizeInBytes)
This routine is the extended version of the cudnnRNNForwardInference() function. The cudnnRNNForwardTrainingEx() function allows the user to use an unpacked (padded) layout for input x and output y. In the unpacked layout, each sequence in the mini-batch is considered to be of fixed length, specified by maxSeqLength in its corresponding RNNDataDescriptor. Each fixed-length sequence, for example, the nth sequence in the mini-batch, is composed of a valid segment, specified by the seqLengthArray[n] in its corresponding RNNDataDescriptor, and a padding segment to make the combined sequence length equal to maxSeqLength.
With an unpacked layout, both sequence major (meaning, time major) and batch major are supported. For backward compatibility, the packed sequence major layout is supported. However, similar to the non-extended function cudnnRNNForwardInference(), the sequences in the mini-batch need to be sorted in descending order according to length.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. A previously initialized RNN Data descriptor. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray need to match that of yDesc.
- Input. Data pointer to the GPU memory associated with the RNN data descriptor xDesc. The vectors are expected to be laid out in memory according to the layout specified by xDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the batchSize parameter described in xDesc. The third dimension depends on whether RNN mode is CUDNN_LSTM and whether LSTM projection is enabled. Specifically:- If RNN mode is CUDNN_LSTM and LSTM projection is enabled, the third dimension must match the recProjSize argument passed to cudnnSetRNNProjectionLayers() call used to set rnnDesc.
- Otherwise, the third dimension must match the hiddenSize argument used to initialize rnnDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the batchSize parameter in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. A previously initialized RNN data descriptor. The dataType, layout, maxSeqLength , batchSize, and seqLengthArray must match that of dyDesc and dxDesc. The parameter vectorSize depends on whether RNN mode is CUDNN_LSTM and whether LSTM projection is enabled and whether the network is bidirectional. Specifically:
- For uni-directional network, if the RNN mode is CUDNN_LSTM and LSTM projection is enabled, the parameter vectorSize must match the recProjSize argument passed to cudnnSetRNNProjectionLayers() call used to set rnnDesc. If the network is bidirectional, then multiply the value by 2.
- Otherwise, for a uni-directional network, the parameter vectorSize must match the hiddenSize argument used to initialize rnnDesc. If the network is bidirectional, then multiply the value by 2.
- Output. Data pointer to the GPU memory associated with the RNN data descriptor yDesc. The vectors are expected to be laid out in memory according to the layout specified by yDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
- Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The descriptor must be set exactly the same way as hxDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
- Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The descriptor must be set exactly the same way as cxDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
- Reserved. User may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- Variable sequence length input is passed in while CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used.
- CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used on pre-Pascal devices.
- Double input/output is used for CUDNN_RNN_ALGO_PERSIST_STATIC.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors in xDesc, yDesc, hxDesc, cxDesc, wDesc, hyDesc, or cyDesc is invalid, or has incorrect strides or dimensions.
- reserveSpaceSizeInBytes is too small.
- workSpaceSizeInBytes is too small.
- cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
7.2.39. cudnnRNNGetClip()
cudnnStatus_t cudnnRNNGetClip(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNClipMode_t *clipMode,
cudnnNanPropagation_t *clipNanOpt,
double *lclip,
double *rclip);
Retrieves the current LSTM cell clipping parameters, and stores them in the arguments provided.
Parameters
- Output. Pointer to the location where the retrieved clipMode is stored. The clipMode can be CUDNN_RNN_CLIP_NONE in which case no LSTM cell state clipping is being performed; or CUDNN_RNN_CLIP_MINMAX, in which case the cell state activation to other units are being clipped.
- Output. Pointers to the location where the retrieved LSTM cell clipping range [lclip, rclip] is stored.
- Output. Pointer to the location where the retrieved clipNanOpt is stored.
7.2.40. cudnnRNNGetClip_v8()
cudnnStatus_t cudnnRNNGetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t *clipMode, cudnnNanPropagation_t *clipNanOpt, double *lclip, double *rclip);
Parameters
- Input. A previously initialized RNN descriptor.
- Output. Pointer to the location where the retrieved cudnnRNNClipMode_t value is stored. The clipMode can be CUDNN_RNN_CLIP_NONE in which case no LSTM cell state clipping is being performed; or CUDNN_RNN_CLIP_MINMAX, in which case the cell state activation to other units are being clipped.
- Output. Pointer to the location where the retrieved cudnnNanPropagation_t value is stored.
- Output. Pointers to the location where the retrieved LSTM cell clipping range [lclip, rclip] is stored.
7.2.41. cudnnRNNSetClip()
cudnnStatus_t cudnnRNNSetClip(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNClipMode_t clipMode,
cudnnNanPropagation_t clipNanOpt,
double lclip,
double rclip);
Sets the LSTM cell clipping mode. The LSTM clipping is disabled by default. When enabled, clipping is applied to all layers. This cudnnRNNSetClip() function may be called multiple times.
Parameters
- Input. Enables or disables the LSTM cell clipping. When clipMode is set to CUDNN_RNN_CLIP_NONE no LSTM cell state clipping is performed. When clipMode is CUDNN_RNN_CLIP_MINMAX the cell state activation to other units is clipped.
- Input. The range [lclip, rclip] to which the LSTM cell clipping should be set.
- Input. When set to CUDNN_PROPAGATE_NAN (see the description for cudnnNanPropagation_t), NaN is propagated from the LSTM cell, or it can be set to one of the clipping range boundary values, instead of propagating.
7.2.42. cudnnRNNSetClip_v8()
cudnnStatus_t cudnnRNNSetClip_v8( cudnnRNNDescriptor_t rnnDesc, cudnnRNNClipMode_t clipMode, cudnnNanPropagation_t clipNanOpt, double lclip, double rclip);
Parameters
- Input. A previously initialized RNN descriptor.
- Input. Enables or disables the LSTM cell clipping. When clipMode is set to CUDNN_RNN_CLIP_NONE no LSTM cell state clipping is performed. When clipMode is CUDNN_RNN_CLIP_MINMAX the cell state activation to other units is clipped.
- Input. When set to CUDNN_PROPAGATE_NAN (see the description for cudnnNanPropagation_t), NaN is propagated from the LSTM cell, or it can be set to one of the clipping range boundary values, instead of propagating.
- Input. The range [lclip, rclip] to which the LSTM cell clipping should be set.
7.2.43. cudnnSetAttnDescriptor()
cudnnStatus_t cudnnSetAttnDescriptor( cudnnAttnDescriptor_t attnDesc, unsigned attnMode, int nHeads, double smScaler, cudnnDataType_t dataType, cudnnDataType_t computePrec, cudnnMathType_t mathType, cudnnDropoutDescriptor_t attnDropoutDesc, cudnnDropoutDescriptor_t postDropoutDesc, int qSize, int kSize, int vSize, int qProjSize, int kProjSize, int vProjSize, int oProjSize, int qoMaxSeqLength, int kvMaxSeqLength, int maxBatchSize, int maxBeamSize);
Input sequence data descriptors in cudnnMultiHeadAttnForward(), cudnnMultiHeadAttnBackwardData() and cudnnMultiHeadAttnBackwardWeights() functions are checked against the configuration parameters stored in the attention descriptor. Some parameters must match exactly while max arguments such as maxBatchSize or qoMaxSeqLength establish upper limits for the corresponding dimensions.
The multi-head attention model can be described by the following equations:
- is the number of independent attention heads that evaluate vectors.
- is a primary input, a single query column vector.
- are two matrices of key and value column vectors.
For simplicity, the above equations are presented using a single embedding vector but the cuDNN API can handle multiple candidates in the beam search scheme, process vectors from multiple sequences bundled into a batch, or automatically iterate through all embedding vectors (time-steps) of a sequence. Thus, in general, , inputs are tensors with additional pieces of information such as the active length of each sequence or how unused padding vectors should be saved.
In some publications, matrices are combined into one output projection matrix and vectors are merged explicitly into a single vector. This is an equivalent notation. In the cuDNN library, matrices are conceptually treated the same way as , or input projection weights. See the description of the cudnnGetMultiHeadAttnWeights() function for more details.
Weight matrices , , and play similar roles, adjusting vector lengths in , inputs and in the multi-head attention final output. The user can disable any or all projections by setting , , or arguments to zero.
Embedding vector sizes in , and the vector lengths after projections need to be selected in such a way that matrix multiplications described above are feasible. Otherwise, CUDNN_STATUS_BAD_PARAM is returned by the cudnnSetAttnDescriptor() function. All four weight matrices are used when it is desirable to maintain rank deficiency of or matrices to eliminate one or more dimensions during linear transformations in each head. This is a form of feature extraction. In such cases, the projected sizes are smaller than the original vector lengths.
When the output projection is disabled , the output vector length is , meaning, the output is a concatenation of all vectors. In the alternative interpretation, a concatenated matrix forms the identity matrix.
Softmax is a normalized, exponential vector function that takes and outputs vectors of the same size. The multi-head attention API utilizes softmax of the CUDNN_SOFTMAX_ACCURATE type to reduce the likelihood of the floating-point overflow.
The smScaler parameter is the softmax sharpening/smoothing coefficient. When smScaler=1.0, softmax uses the natural exponential function exp(x) or 2.7183*. When smScaler<1.0, for example smScaler=0.2, the function used by the softmax block will not grow as fast because exp(0.2*x) ≈ 1.2214*.
The smScaler parameter can be adjusted to process larger ranges of values fed to softmax. When the range is too large (or smScaler is not sufficiently small for the given range), the output vector of the softmax block becomes categorical, meaning, one vector element is close to 1.0 and other outputs are zero or very close to zero. When this occurs, the Jacobian matrix of the softmax block is also close to zero so deltas are not back-propagated during training from output to input except through residual connections, if these connections are enabled. The user can set smScaler to any positive floating-point value or even zero. The smScaler parameter is not trainable.
The qoMaxSeqLength, kvMaxSeqLength, maxBatchSize, and maxBeamSize arguments declare the maximum sequence lengths, maximum batch size, and maximum beam size respectively, in the cudnnSeqDataDescriptor_t containers. The actual dimensions supplied to forward and backward (gradient) API functions should not exceed the max limits. The max arguments should be set carefully because too large values will result in excessive memory usage due to oversized work and reserve space buffers.
The attnMode argument is treated as a binary mask where various on/off options are set. These options can affect the internal buffer sizes, enforce certain argument checks, select optimized code execution paths, or enable attention variants that do not require additional numerical arguments. An example of such options is the inclusion of biases in input and output projections.
Parameters
- Output. Attention descriptor to be configured.
- Input. Enables various attention options that do not require additional numerical values. See the table below for the list of supported flags. The user should assign a preferred set of bitwise OR-ed flags to this argument.
- Input. Number of attention heads.
- Input. Softmax smoothing (1.0 >= smScaler >= 0.0) or sharpening (smScaler > 1.0) coefficient. Negative values are not accepted.
- Input. Data type used to represent attention inputs, attention weights and attention outputs.
- Input. Compute precision.
- Input. NVIDIA Tensor Core settings.
- Input. Descriptor of the dropout operation applied to the softmax output. See the table below for a list of unsupported features.
- Input. Descriptor of the dropout operation applied to the multi-head attention output, just before the point where residual connections are added. See the table below for a list of unsupported features.
- Input. , embedding vector lengths.
- Input. , embedding vector lengths after input projections. Use zero to disable the corresponding projection.
- Input. The vector length after the output projection. Use zero to disable this projection.
- Input. Largest sequence length expected in sequence data descriptors related to , , and inputs and outputs.
- Input. Largest sequence length expected in sequence data descriptors related to , and inputs and outputs.
- Input. Largest batch size expected in any cudnnSeqDataDescriptor_t container.
- Input. Largest beam size expected in any cudnnSeqDataDescriptor_t container.
Supported attnMode flags
- Forward declaration of mapping between and vectors when the beam size is greater than one in the input. Multiple vectors from the same beam bundle map to the same vectors. This means that beam sizes in the sets are equal to one.
- Forward declaration of mapping between and vectors when the beam size is greater than one in the input. Multiple vectors from the same beam bundle map to different vectors. This requires beam sizes in sets to be the same as in the input.
- Use no biases in the attention input and output projections.
- Use extra biases in the attention input and output projections. In this case the projected vectors are computed as , where is the number of columns in the matrix. In other words, the same column vector is added to all columns of after the weight matrix multiplication.
Supported combinations of dataType, computePrec, and mathType
| dataType | computePrec | mathType |
|---|---|---|
| CUDNN_DATA_DOUBLE | CUDNN_DATA_DOUBLE | CUDNN_DEFAULT_MATH |
| CUDNN_DATA_FLOAT | CUDNN_DATA_FLOAT | CUDNN_DEFAULT_MATH, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION |
| CUDNN_DATA_HALF | CUDNN_DATA_HALF, CUDNN_DATA_FLOAT | CUDNN_DEFAULT_MATH, CUDNN_TENSOR_OP_MATH, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION |
Unsupported features
- The paddingFill argument in cudnnSeqDataDescriptor_t is currently ignored by all multi-head attention functions.
7.2.44. cudnnSetPersistentRNNPlan()
This function sets the persistent RNN plan to be executed when using rnnDesc and CUDNN_RNN_ALGO_PERSIST_DYNAMIC algo.
cudnnStatus_t cudnnSetPersistentRNNPlan(
cudnnRNNDescriptor_t rnnDesc,
cudnnPersistentRNNPlan_t plan)
7.2.46. cudnnSetRNNBiasMode()
cudnnStatus_t cudnnSetRNNBiasMode( cudnnRNNDescriptor_t rnnDesc, cudnnRNNBiasMode_t biasMode)
The cudnnSetRNNBiasMode() function sets the number of bias vectors for a previously created and initialized RNN descriptor. This function should be called to enable the specified bias mode in an RNN. The default value of biasMode in rnnDesc after cudnnCreateRNNDescriptor() is CUDNN_RNN_DOUBLE_BIAS.
Parameters
- Input/Output. A previously created RNN descriptor.
- Input. Sets the number of bias vectors. For more information, refer to cudnnRNNBiasMode_t.
7.2.47. cudnnSetRNNDataDescriptor()
cudnnStatus_t cudnnSetRNNDataDescriptor(
cudnnRNNDataDescriptor_t RNNDataDesc,
cudnnDataType_t dataType,
cudnnRNNDataLayout_t layout,
int maxSeqLength,
int batchSize,
int vectorSize,
const int seqLengthArray[],
void *paddingFill);Parameters
- Input/Output. A previously created RNN descriptor. For more information, refer to cudnnRNNDataDescriptor_t.
- Input. The datatype of the RNN data tensor. For more information, refer to cudnnDataType_t.
- Input. The memory layout of the RNN data tensor.
- Input. The maximum sequence length within this RNN data tensor. In the unpacked (padded) layout, this should include the padding vectors in each sequence. In the packed (unpadded) layout, this should be equal to the greatest element in seqLengthArray.
- Input. The number of sequences within the mini-batch.
- Input. The vector length (embedding size) of the input or output tensor at each time-step.
- Input. An integer array with batchSize number of elements. Describes the length (number of time-steps) of each sequence. Each element in seqLengthArray must be greater than or equal to 0 but less than or equal to maxSeqLength. In the packed layout, the elements should be sorted in descending order, similar to the layout required by the non-extended RNN compute functions.
- Input. A user-defined symbol for filling the padding position in RNN output. This is only effective when the descriptor is describing the RNN output, and the unpacked layout is specified. The symbol should be in the host memory, and is interpreted as the same data type as that of the RNN data tensor. If a NULL pointer is passed in, then the padding position in the output will be undefined.
Returns
- The object was set successfully.
- dataType is not one of CUDNN_DATA_HALF, CUDNN_DATA_FLOAT or CUDNN_DATA_DOUBLE.
- Any one of these have occurred:
- RNNDataDesc is NULL.
- Any one of maxSeqLength, batchSize or vectorSize is less than or equal to zero.
- An element of seqLengthArray is less than zero or greater than maxSeqLength.
- Layout is not one of CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED, CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED or CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED.
- The allocation of internal array storage has failed.
7.2.48. cudnnSetRNNDescriptor_v6()
cudnnStatus_t cudnnSetRNNDescriptor_v6( cudnnHandle_t handle, cudnnRNNDescriptor_t rnnDesc, const int hiddenSize, const int numLayers, cudnnDropoutDescriptor_t dropoutDesc, cudnnRNNInputMode_t inputMode, cudnnDirectionMode_t direction, cudnnRNNMode_t mode, cudnnRNNAlgo_t algo, cudnnDataType_t mathPrec)
This function initializes a previously created RNN descriptor object.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input/Output. A previously created RNN descriptor.
- Input. Size of the internal hidden state for each layer.
- Input. Number of stacked layers.
- Input. Handle to a previously created and initialized dropout descriptor. Dropout will be applied between layers, for example, a single layer network will have no dropout applied.
- Input. Specifies the behavior at the input to the first layer.
- Input. Specifies the recurrence pattern, for example, bidirectional.
- Input. Specifies the type of RNN to compute.
- Input. Specifies which RNN algorithm should be used to compute the results.
- Input. Math precision. This parameter is used for controlling the
math precision in RNN. The following applies:
- For the input/output in FP16, the parameter mathPrec can be CUDNN_DATA_HALF or CUDNN_DATA_FLOAT.
- For the input/output in FP32, the parameter mathPrec can only be CUDNN_DATA_FLOAT.
- For the input/output in FP64, double type, the parameter mathPrec can only be CUDNN_DATA_DOUBLE.
7.2.49. cudnnSetRNNDescriptor_v8()
cudnnStatus_t cudnnSetRNNDescriptor_v8(
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNAlgo_t algo,
cudnnRNNMode_t cellMode,
cudnnRNNBiasMode_t biasMode,
cudnnDirectionMode_t dirMode,
cudnnRNNInputMode_t inputMode,
cudnnDataType_t dataType,
cudnnDataType_t mathPrec,
cudnnMathType_t mathType,
int32_t inputSize,
int32_t hiddenSize,
int32_t projSize,
int32_t numLayers,
cudnnDropoutDescriptor_t dropoutDesc,
uint32_t auxFlags);
Parameters
- Input. A previously initialized RNN descriptor.
- Input. RNN algo (CUDNN_RNN_ALGO_STANDARD, CUDNN_RNN_ALGO_PERSIST_STATIC, or CUDNN_RNN_ALGO_PERSIST_DYNAMIC).
- Input. Specifies the RNN cell type in the entire model (CUDNN_RNN_RELU, CUDNN_RNN_TANH, CUDNN_RNN_LSTM, CUDNN_RNN_GRU).
- Input. Sets the number of bias vectors (CUDNN_RNN_NO_BIAS, CUDNN_RNN_SINGLE_INP_BIAS, CUDNN_RNN_SINGLE_REC_BIAS, CUDNN_RNN_DOUBLE_BIAS). The two single bias settings are functionally the same for RELU, TANH and LSTM cell types. For differences in GRU cells, see the description of CUDNN_GRU in the cudnnRNNMode_t enumerated type.
- Input. Specifies the recurrence pattern: CUDNN_UNIDIRECTIONAL or CUDNN_BIDIRECTIONAL. In bidirectional RNNs, the hidden states passed between physical layers are concatenations of forward and backward hidden states.
- Input. Specifies how the input to the RNN model is processed by the first layer. When inputMode is CUDNN_LINEAR_INPUT, original input vectors of size inputSize are multiplied by the weight matrix to obtain vectors of hiddenSize. When inputMode is CUDNN_SKIP_INPUT, the original input vectors to the first layer are used as is without multiplying them by the weight matrix.
- Input. Specifies data type for RNN weights/biases and input and output data.
- Input. This parameter is used to control the compute math
precision in the RNN model. The following applies:
- For the input/output in FP16, the parameter mathPrec can be CUDNN_DATA_HALF or CUDNN_DATA_FLOAT.
- For the input/output in FP32, the parameter mathPrec can only be CUDNN_DATA_FLOAT.
- For the input/output in FP64, double type, the parameter mathPrec can only be CUDNN_DATA_DOUBLE.
-
Input. Sets the preferred option to use NVIDIA Tensor Cores accelerators on Volta (SM 7.0) or higher GPU-s).
- When dataType is CUDNN_DATA_HALF, the mathType parameter can be CUDNN_DEFAULT_MATH or CUDNN_TENSOR_OP_MATH. The ALLOW_CONVERSION setting is treated the same as CUDNN_TENSOR_OP_MATH for this data type.
- When dataType is CUDNN_DATA_FLOAT, the mathType parameter can be CUDNN_DEFAULT_MATH or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION. When the latter settings are used, original weights and intermediate results will be down-converted to CUDNN_DATA_HALF before they are used in another recursive iteration.
- When dataType is CUDNN_DATA_DOUBLE, the mathType parameter can be CUDNN_DEFAULT_MATH.
This option has an advisory status meaning Tensor Cores may not be always utilized, for example, due to specific GEMM dimensions restrictions.
- Input. Size of the input vector in the RNN model. When the inputMode=CUDNN_SKIP_INPUT, the inputSize should match the hiddenSize value.
- Input. Size of the hidden state vector in the RNN model. The same hidden size is used in all RNN layers.
- Input. The size of the LSTM cell output after the recurrent projection. This value should not be larger than hiddenSize. It is legal to set projSize equal to hiddenSize, however, in this case, the recurrent projection feature is disabled. The recurrent projection is an additional matrix multiplication in the LSTM cell to project hidden state vectors ht into smaller vectors rt = Wrht, where Wr is a rectangular matrix with projSize rows and hiddenSize columns. When the recurrent projection is enabled, the output of the LSTM cell (both to the next layer and unrolled in-time) is rt instead of ht. The recurrent projection can be enabled for LSTM cells and CUDNN_RNN_ALGO_STANDARD only.
- Input. Number of stacked, physical layers in the deep RNN model. When dirMode= CUDNN_BIDIRECTIONAL, the physical layer consists of two pseudo-layers corresponding to forward and backward directions.
- Input. Handle to a previously created and initialized dropout descriptor. Dropout operation will be applied between physical layers. A single layer network will have no dropout applied. Dropout is used in the training mode only.
- Input. This argument is used to pass miscellaneous switches that do not require additional numerical values to configure the corresponding feature. In future cuDNN releases, this parameter will be used to extend the RNN functionality without adding new API functions (applicable options should be bitwise OR-ed). Currently, this parameter is used to enable or disable padded input/output (CUDNN_RNN_PADDED_IO_DISABLED, CUDNN_RNN_PADDED_IO_ENABLED). When the padded I/O is enabled, layouts CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED and CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED are permitted in RNN data descriptors.
Returns
- The RNN descriptor was configured successfully.
- An invalid input argument was detected.
- The dimensions of the bias tensor refer to an amount of data that is incompatible with the output tensor dimensions or the dataType of the two tensor descriptors are different.
- An incompatible or unsupported combination of input arguments was detected.
7.2.50. cudnnSetRNNMatrixMathType()
cudnnStatus_t cudnnSetRNNMatrixMathType(
cudnnRNNDescriptor_t rnnDesc,
cudnnMathType_t mType)This function sets the preferred option to use NVIDIA Tensor Cores accelerators on Volta GPUs (SM 7.0 or higher). When the mType parameter is CUDNN_TENSOR_OP_MATH, inference and training RNN APIs will attempt use Tensor Cores when weights/biases are of type CUDNN_DATA_HALF or CUDNN_DATA_FLOAT. When RNN weights/biases are stored in the CUDNN_DATA_FLOAT format, the original weights and intermediate results will be down-converted to CUDNN_DATA_HALF before they are used in another recursive iteration.
7.2.51. cudnnSetRNNPaddingMode()
cudnnStatus_t cudnnSetRNNPaddingMode(
cudnnRNNDescriptor_t rnnDesc,
cudnnRNNPaddingMode_t paddingMode)This function enables or disables the padded RNN input/output for a previously created and initialized RNN descriptor. This information is required before calling the cudnnGetRNNWorkspaceSize() and cudnnGetRNNTrainingReserveSize() functions, to determine whether additional workspace and training reserve space is needed. By default, the padded RNN input/output is not enabled.
Parameters
- Input/Output. A previously created RNN descriptor.
- Input. Enables or disables the padded input/output. For more information, refer to cudnnRNNPaddingMode_t.
7.2.52. cudnnSetRNNProjectionLayers()
cudnnStatus_t cudnnSetRNNProjectionLayers(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
int recProjSize,
int outProjSize)The cudnnSetRNNProjectionLayers() function should be called to enable the recurrent and/or output projection in a recursive neural network. The recurrent projection is an additional matrix multiplication in the LSTM cell to project hidden state vectors into smaller vectors , where is a rectangular matrix with recProjSize rows and hiddenSize columns. When the recurrent projection is enabled, the output of the LSTM cell (both to the next layer and unrolled in-time) is instead of . The dimensionality of , , , and vectors used in conjunction with non-linear functions remains the same as in the canonical LSTM cell. To make this possible, the shapes of matrices in the LSTM formulas (refer to cudnnRNNMode_t type), such as in hidden RNN layers or in the entire network, become rectangular versus square in the canonical LSTM mode. Obviously, the result of is a square matrix but it is rank deficient, reflecting the compression of LSTM output. The recurrent projection is typically employed when the number of independent (adjustable) weights in the RNN network with projection is smaller in comparison to canonical LSTM for the same hiddenSize value.
The recurrent projection can be enabled for LSTM cells and CUDNN_RNN_ALGO_STANDARD only. The recProjSize parameter should be smaller than the hiddenSize value. It is legal to set recProjSize equal to hiddenSize but in that case the recurrent projection feature is disabled.
The output projection is currently not implemented.
For more information on the recurrent and output RNN projections, refer to the paper by Hasim Sak, et al.: Long Short-Term Memory Based Recurrent Neural Network Architectures For Large Vocabulary Speech Recognition.
Parameters
- Input. Handle to a previously created cuDNN library descriptor.
- Input. A previously created and initialized RNN descriptor.
- Input. The size of the LSTM cell output after the recurrent projection. This value should not be larger than hiddenSize.
- Input. This parameter should be zero.
Returns
- RNN projection parameters were set successfully.
- An invalid input argument was detected (for example, NULL handles, negative values for projection parameters).
- Projection applied to RNN algo other than CUDNN_RNN_ALGO_STANDARD, cell type other than CUDNN_LSTM, recProjSize larger than hiddenSize.
7.2.53. cudnnSetSeqDataDescriptor()
cudnnStatus_t cudnnSetSeqDataDescriptor(
cudnnSeqDataDescriptor_t seqDataDesc,
cudnnDataType_t dataType,
int nbDims,
const int dimA[],
const cudnnSeqDataAxis_t axes[],
size_t seqLengthArraySize,
const int seqLengthArray[],
void *paddingFill);
CUDNN_SEQDATA_TIME_DIM CUDNN_SEQDATA_BATCH_DIM CUDNN_SEQDATA_BEAM_DIM CUDNN_SEQDATA_VECT_DIM
For example, to express information that vectors in our sequence data buffer are five elements long, we need to assign dimA[CUDNN_SEQDATA_VECT_DIM]=5 in the dimA[] array.
The number of active dimensions in the dimA[] and axes[] arrays is defined by the nbDims argument. Currently, the value of this argument should be four. The actual size of the dimA[] and axes[] arrays should be declared using the CUDNN_SEQDATA_DIM_COUNT macro.
The cudnnSeqDataDescriptor_t container is treated as a collection of fixed length vectors that form sequences, similarly to words (vectors of characters) constructing sentences. The TIME dimension spans the sequence length. Different sequences are bundled together in a batch. A BATCH may be a group of individual sequences or beams. A BEAM is a cluster of alternative sequences or candidates. When thinking about the beam, consider a translation task from one language to another. You may want to keep around and experiment with several translated versions of the original sentence before selecting the best one. The number of candidates kept around is the BEAM size.
Every sequence can have a different length, even within the same beam, so vectors toward the end of the sequence can be just padding. The paddingFill argument specifies how the padding vectors should be written in output sequence data buffers. The paddingFill argument points to one value of type dataType that should be copied to all elements in padding vectors. Currently, the only supported value for paddingFill is NULL which means this option should be ignored. In this case, elements of the padding vectors in output buffers will have undefined values.
{batch_idx=0, beam_idx=0}
{batch_idx=0, beam_idx=1}
{batch_idx=1, beam_idx=0}
{batch_idx=1, beam_idx=1}
{batch_idx=2, beam_idx=0}
{batch_idx=2, beam_idx=1}
when
dimA[CUDNN_SEQDATA_BATCH_DIM]=3 and
dimA[CUDNN_SEQDATA_BEAM_DIM]=2.
- All data is fully packed. There are no unused spaces or gaps between individual vector elements or consecutive vectors.
- The most inner dimension of the container is the vector. In other words, the first contiguous group of dimA[CUDNN_SEQDATA_VECT_DIM] elements belongs to the first vector, followed by elements of the second vector, and so on.
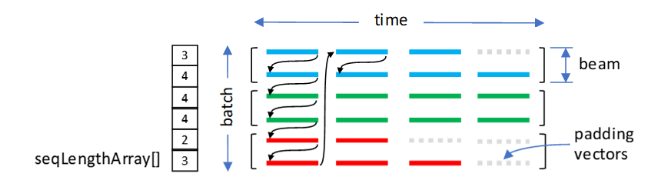
int dimA[CUDNN_SEQDATA_DIM_COUNT]; dimA[CUDNN_SEQDATA_TIME_DIM] = 4; dimA[CUDNN_SEQDATA_BATCH_DIM] = 3; dimA[CUDNN_SEQDATA_BEAM_DIM] = 2; dimA[CUDNN_SEQDATA_VECT_DIM] = 5;
cudnnSeqDataAxis_t axes[CUDNN_SEQDATA_DIM_COUNT]; axes[3] = CUDNN_SEQDATA_VECT_DIM; // 3 = nbDims-1
axes[2] = CUDNN_SEQDATA_BEAM_DIM;
axes[1] = CUDNN_SEQDATA_BATCH_DIM;
axes[0] = CUDNN_SEQDATA_TIME_DIM;
The four values of the axes[] array fully describe the data layout depicted in the figure.
The sequence data descriptor allows the user to select 3! = 6 different data layouts or permutations of BEAM, BATCH and TIME dimensions. The multi-head attention API supports all six layouts.
Parameters
- Output. Pointer to a previously created sequence data descriptor.
- Input. Data type of the sequence data buffer (CUDNN_DATA_HALF, CUDNN_DATA_FLOAT or CUDNN_DATA_DOUBLE).
- Input. Must be 4. The number of active dimensions in dimA[] and axes[] arrays. Both arrays should be declared to contain at least CUDNN_SEQDATA_DIM_COUNT elements.
- Input. Integer array specifying sequence data dimensions. Use the cudnnSeqDataAxis_t enumerated type to index all active dimA[] elements.
- Input. Array of cudnnSeqDataAxis_t that defines the layout of sequence data in memory. The first nbDims elements of axes[] should be initialized with the outermost dimension in axes[0] and the innermost dimension in axes[nbDims-1].
- Input. Number of elements in the sequence length array, seqLengthArray[].
- Input. An integer array that defines all sequence lengths of the container.
- Input. Must be NULL. Pointer to a value of dataType that is used to fill up output vectors beyond the valid length of each sequence or NULL to ignore this setting.
Returns
- All input arguments were validated and the sequence data descriptor was successfully updated.
- An invalid input argument was found. Some examples include:
- seqDataDesc=NULL
- dateType was not a valid type of cudnnDataType_t
- nbDims was negative or zero
- seqLengthArraySize did not match the expected length
- some elements of seqLengthArray[] were invalid
- An unsupported input argument was encountered. Some examples include:
- nbDims is not equal to 4
- paddingFill is not NULL
- Failed to allocate storage for the sequence data descriptor object.
8. cudnn_adv_train.so Library
8.1. Data Type References
8.1.1. Enumeration Types
8.1.1.1. cudnnLossNormalizationMode_t
Values
- The input probs of the cudnnCTCLoss() function is expected to be the normalized probability, and the output gradients is the gradient of loss with respect to the unnormalized probability.
- The input probs of the cudnnCTCLoss() function is expected to be the unnormalized activation from the previous layer, and the output gradients is the gradient with respect to the activation. Internally the probability is computed by softmax normalization.
8.1.1.2. cudnnWgradMode_t
Values
- A weight gradient component corresponding to a new batch of inputs is added to previously evaluated weight gradients. Before using this mode, the buffer holding weight gradients should be initialized to zero. Alternatively, the first API call outputting to an uninitialized buffer should use the CUDNN_WGRAD_MODE_SET option.
- A weight gradient component, corresponding to a new batch of inputs, overwrites previously stored weight gradients in the output buffer.
8.2. API Functions
8.2.1. cudnnAdvTrainVersionCheck()
cudnnStatus_t cudnnAdvTrainVersionCheck(void)
8.2.2. cudnnCreateCTCLossDescriptor()
cudnnStatus_t cudnnCreateCTCLossDescriptor(
cudnnCTCLossDescriptor_t* ctcLossDesc)Parameters
- Output. CTC loss descriptor to be set. For more information, refer to cudnnCTCLossDescriptor_t.
8.2.3. cudnnCTCLoss()
cudnnStatus_t cudnnCTCLoss(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t probsDesc,
const void *probs,
const int hostLabels[],
const int hostLabelLengths[],
const int hostInputLengths[],
void *costs,
const cudnnTensorDescriptor_t gradientsDesc,
const void *gradients,
cudnnCTCLossAlgo_t algo,
const cudnnCTCLossDescriptor_t ctcLossDesc,
void *workspace,
size_t *workSpaceSizeInBytes)
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. Handle to the previously initialized probabilities tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointer to a previously initialized probabilities tensor. These input probabilities are normalized by softmax.
- Input. Pointer to a previously initialized labels list, in CPU memory.
- Input. Pointer to a previously initialized lengths list in CPU memory, to walk the above labels list.
- Input. Pointer to a previously initialized list of the lengths of the timing steps in each batch, in CPU memory.
- Output. Pointer to the computed costs of CTC.
- Input. Handle to a previously initialized gradient tensor descriptor.
- Output. Pointer to the computed gradients of CTC. These computed gradient outputs are with respect to the unnormalized activation.
- Input. Enumerant that specifies the chosen CTC loss algorithm. For more information, refer to cudnnCTCLossAlgo_t.
- Input. Handle to the previously initialized CTC loss descriptor. For more information, refer to cudnnCTCLossDescriptor_t.
- Input. Pointer to GPU memory of a workspace needed to be able to execute the specified algorithm.
- Input. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The dimensions of probsDesc do not match the dimensions of gradientsDesc.
- The inputLengths do not agree with the first dimension of probsDesc.
- The workSpaceSizeInBytes is not sufficient.
- The labelLengths is greater than 255.
- A compute or data type other than FLOAT was chosen, or an unknown algorithm type was chosen.
- The function failed to launch on the GPU.
8.2.4. cudnnCTCLoss_v8()
cudnnStatus_t cudnnCTCLoss_v8(
cudnnHandle_t handle,
cudnnCTCLossAlgo_t algo,
const cudnnCTCLossDescriptor_t ctcLossDesc,
const cudnnTensorDescriptor_t probsDesc,
const void *probs,
const int labels[],
const int labelLengths[],
const int inputLengths[],
void *costs,
const cudnnTensorDescriptor_t gradientsDesc,
const void *gradients,
size_t *workSpaceSizeInBytes,
void *workspace)Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. Enumerant that specifies the chosen CTC loss algorithm. For more information, refer to cudnnCTCLossAlgo_t.
- Input. Handle to the previously initialized CTC loss descriptor. To use this _v8 function, this descriptor must be set using cudnnSetCTCLossDescriptor_v8(). For more information, refer to cudnnCTCLossDescriptor_t.
- Input. Handle to the previously initialized probabilities tensor descriptor. For more information, refer to cudnnTensorDescriptor_t.
- Input. Pointer to a previously initialized probabilities tensor. These input probabilities are normalized by softmax.
- Input. Pointer to a previously initialized labels list, in GPU memory.
- Input. Pointer to a previously initialized lengths list in GPU memory, to walk the above labels list.
- Input. Pointer to a previously initialized list of the lengths of the timing steps in each batch, in GPU memory.
- Output. Pointer to the computed costs of CTC.
- Input. Handle to a previously initialized gradient tensor descriptor.
- Output. Pointer to the computed gradients of CTC. These computed gradient outputs are with respect to the unnormalized activation.
- Input. Pointer to GPU memory of a workspace needed to be able to execute the specified algorithm.
- Input. Amount of GPU memory needed as a workspace to be able to execute the CTC loss computation with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The dimensions of probsDesc do not match the dimensions of gradientsDesc.
- The inputLengths do not agree with the first dimension of probsDesc.
- The workSpaceSizeInBytes is not sufficient.
- The labelLengths is greater than 256.
- A compute or data type other than FLOAT was chosen, or an unknown algorithm type was chosen.
- The function failed to launch on the GPU.
8.2.6. cudnnFindRNNBackwardDataAlgorithmEx()
This function attempts all available cuDNN algorithms for cudnnRNNBackwardData(), using user-allocated GPU memory. It outputs the parameters that influence the performance of the algorithm to a user-allocated array of cudnnAlgorithmPerformance_t. These parameter metrics are written in sorted fashion where the first element has the lowest compute time.
cudnnStatus_t cudnnFindRNNBackwardDataAlgorithmEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *yDesc,
const void *y,
const cudnnTensorDescriptor_t *dyDesc,
const void *dy,
const cudnnTensorDescriptor_t dhyDesc,
const void *dhy,
const cudnnTensorDescriptor_t dcyDesc,
const void *dcy,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnTensorDescriptor_t *dxDesc,
void *dx,
const cudnnTensorDescriptor_t dhxDesc,
void *dhx,
const cudnnTensorDescriptor_t dcxDesc,
void *dcx,
const float findIntensity,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnAlgorithmPerformance_t *perfResults,
void *workspace,
size_t workSpaceSizeInBytes,
const void *reserveSpace,
size_t reserveSpaceSizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in dyDesc.
- Input. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
-
Input. An array of fully packed tensor descriptors describing the gradient at the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the second dimension of the tensor n in dxDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array dyDesc.
-
Input. A fully packed tensor descriptor describing the gradients at the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor dhyDesc. If a NULL pointer is passed, the gradients at the final hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the gradients at the final cell state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor dcyDesc. If a NULL pointer is passed, the gradients at the final cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. An array of fully packed tensor descriptors describing the gradient at the input of each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Output. Data pointer to GPU memory associated with the tensor descriptors in the array dxDesc.
-
Input. A fully packed tensor descriptor describing the gradient at the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor dhxDesc. If a NULL pointer is passed, the gradient at the hidden input of the network will not be set.
-
Input. A fully packed tensor descriptor describing the gradient at the initial cell state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in dxDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor dcxDesc. If a NULL pointer is passed, the gradient at the cell input of the network will not be set.
- Input.This input was previously unused in versions prior to cuDNN
7.2.0. It is used in cuDNN 7.2.0 and later versions to control the
overall runtime of the RNN find algorithms, by selecting the percentage
of a large Cartesian product space to be searched.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors dhxDesc, wDesc, hxDesc, cxDesc, dcxDesc, dhyDesc, or dcyDesc or one of the descriptors in yDesc, dxdesc, dydesc is invalid.
- The descriptors in one of yDesc, dxDesc, dyDesc, dhxDesc, wDesc, hxDesc, cxDesc, dcxDesc, dhyDesc, or dcyDesc has incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.7. cudnnFindRNNBackwardWeightsAlgorithmEx()
This function attempts all available cuDNN algorithms for cudnnRNNBackwardWeights(), using user-allocated GPU memory. It outputs the parameters that influence the performance of the algorithm to a user-allocated array of cudnnAlgorithmPerformance_t. These parameter metrics are written in sorted fashion where the first element has the lowest compute time.
cudnnStatus_t cudnnFindRNNBackwardWeightsAlgorithmEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t *yDesc,
const void *y,
const float findIntensity,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnAlgorithmPerformance_t *perfResults,
const void *workspace,
size_t workSpaceSizeInBytes,
const cudnnFilterDescriptor_t dwDesc,
void *dw,
const void *reserveSpace,
size_t reserveSpaceSizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of fully packed tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array xDesc.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in dyDesc.
- Input. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
- Input.This input was previously unused in versions prior to cuDNN
7.2.0. It is used in cuDNN 7.2.0 and later versions to control the
overall runtime of the RNN find algorithms, by selecting the percentage
of a large Cartesian product space to be searched.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input. Handle to a previously initialized filter descriptor describing the gradients of the weights for the RNN.
- Input/Output. Data pointer to GPU memory associated with the filter descriptor dwDesc.
- Input. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, dwDesc or one of the descriptors in xDesc, yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, yDesc, or dwDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.8. cudnnFindRNNForwardTrainingAlgorithmEx()
This function attempts all available cuDNN algorithms for cudnnRNNForwardTraining(), using user-allocated GPU memory. It outputs the parameters that influence the performance of the algorithm to a user-allocated array of cudnnAlgorithmPerformance_t. These parameter metrics are written in sorted fashion where the first element has the lowest compute time.
cudnnStatus_t cudnnFindRNNForwardTrainingAlgorithmEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t *yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
const float findIntensity,
const int requestedAlgoCount,
int *returnedAlgoCount,
cudnnAlgorithmPerformance_t *perfResults,
void *workspace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. An array of fully packed tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array xDesc.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in xDesc.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
-
Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
-
Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
- Input.This input was previously unused in versions prior to cuDNN
7.2.0. It is used in cuDNN 7.2.0 and later versions to control the
overall runtime of the RNN find algorithms, by selecting the percentage
of a large Cartesian product space to be searched.
- Input. The maximum number of elements to be stored in perfResults.
- Output. The number of output elements stored in perfResults.
- Output. A user-allocated array to store performance metrics sorted ascending by compute time.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, cxDesc, wDesc, hyDesc, or cyDesc or one of the descriptors in xDesc, yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, cxDesc, wDesc, yDesc, hyDesc, or cyDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.9. cudnnGetCTCLossDescriptor()
cudnnStatus_t cudnnGetCTCLossDescriptor(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t* compType)
8.2.10. cudnnGetCTCLossDescriptorEx()
cudnnStatus_t cudnnGetCTCLossDescriptorEx(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t *compType,
cudnnLossNormalizationMode_t *normMode,
cudnnNanPropagation_t *gradMode)
Parameters
- Input. CTC loss function descriptor passed, from which to retrieve the configuration.
- Output. Compute type associated with this CTC loss function descriptor.
- Output. Input normalization type for this CTC loss function descriptor. For more information, see cudnnLossNormalizationMode_t.
- Output. NaN propagation type for this CTC loss function descriptor.
8.2.11. cudnnGetCTCLossDescriptor_v8()
cudnnStatus_t cudnnGetCTCLossDescriptor_v8(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t *compType,
cudnnLossNormalizationMode_t *normMode,
cudnnNanPropagation_t *gradMode,
int *maxLabelLength)
Parameters
- Input. CTC loss function descriptor passed, from which to retrieve the configuration.
- Output. Compute type associated with this CTC loss function descriptor.
- Output. Input normalization type for this CTC loss function descriptor. For more information, see cudnnLossNormalizationMode_t.
- Output. NaN propagation type for this CTC loss function descriptor.
- Output. The max label length for this CTC loss function descriptor.
8.2.12. cudnnGetCTCLossWorkspaceSize()
cudnnStatus_t cudnnGetCTCLossWorkspaceSize(
cudnnHandle_t handle,
const cudnnTensorDescriptor_t probsDesc,
const cudnnTensorDescriptor_t gradientsDesc,
const int *labels,
const int *labelLengths,
const int *inputLengths,
cudnnCTCLossAlgo_t algo,
const cudnnCTCLossDescriptor_t ctcLossDesc,
size_t *sizeInBytes)Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Handle to the previously initialized probabilities tensor descriptor.
- Input. Handle to a previously initialized gradient tensor descriptor.
- Input. Pointer to a previously initialized labels list.
- Input. Pointer to a previously initialized lengths list, to walk the above labels list.
- Input. Pointer to a previously initialized list of the lengths of the timing steps in each batch.
- Input. Enumerant that specifies the chosen CTC loss algorithm.
- Input. Handle to the previously initialized CTC loss descriptor.
- Output. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified algo.
Returns
- The query was successful.
- At least one of the following conditions are met:
- The dimensions of probsDesc do not match the dimensions of gradientsDesc.
- The inputLengths do not agree with the first dimension of probsDesc.
- The workSpaceSizeInBytes is not sufficient.
- The labelLengths is greater than 256.
- A compute or data type other than FLOAT was chosen, or an unknown algorithm type was chosen.
8.2.13. cudnnGetCTCLossWorkspaceSize_v8()
cudnnStatus_t cudnnGetCTCLossWorkspaceSize_v8(
cudnnHandle_t handle,
cudnnCTCLossAlgo_t algo,
const cudnnCTCLossDescriptor_t ctcLossDesc,
const cudnnTensorDescriptor_t probsDesc,
const cudnnTensorDescriptor_t gradientsDesc,
size_t *sizeInBytes
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. Enumerant that specifies the chosen CTC loss algorithm.
- Input. Handle to the previously initialized CTC loss descriptor.
- Input. Handle to the previously initialized probabilities tensor descriptor.
- Input. Handle to a previously initialized gradient tensor descriptor.
- Output. Amount of GPU memory needed as workspace to be able to execute the CTC loss computation with the specified algo.
8.2.15. cudnnGetRNNForwardTrainingAlgorithmMaxCount()
8.2.16. cudnnMultiHeadAttnBackwardData()
cudnnStatus_t cudnnMultiHeadAttnBackwardData( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, const int loWinIdx[], const int hiWinIdx[], const int devSeqLengthsDQDO[], const int devSeqLengthsDKDV[], const cudnnSeqDataDescriptor_t doDesc, const void *dout, const cudnnSeqDataDescriptor_t dqDesc, void *dqueries, const void *queries, const cudnnSeqDataDescriptor_t dkDesc, void *dkeys, const void *keys, const cudnnSeqDataDescriptor_t dvDesc, void *dvalues, const void *values, size_t weightSizeInBytes, const void *weights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
The cudnnMultiHeadAttnBackwardData() function does not output partial derivatives for residual connections because this result is equal to . If the multi-head attention model enables residual connections sourced directly from Q, then the dout tensor needs to be added to dqueries to obtain the correct result of the latter. This operation is demonstrated in the cuDNN multiHeadAttention sample code.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized attention descriptor.
- Input. Two host integer arrays specifying the start and end indices of the attention window for each Q time-step. The start index in K, V sets is inclusive, and the end index is exclusive.
- Input. Device array containing a copy of the sequence length array from the dqDesc or doDesc sequence data descriptor.
- Input. Device array containing a copy of the sequence length array from the dkDesc or dvDesc sequence data descriptor.
- Input. Descriptor for the gradients (vectors of partial derivatives of the loss function with respect to the multi-head attention outputs).
- Pointer to gradient data in the device memory.
- Input. Descriptor for queries and dqueries sequence data.
- Output. Device pointer to gradients of the loss function computed with respect to queries vectors.
- Input. Pointer to queries data in the device memory. This is the same input as in cudnnMultiHeadAttnForward().
- Input. Descriptor for keys and dkeys sequence data.
- Output. Device pointer to gradients of the loss function computed with respect to keys vectors.
- Input. Pointer to keys data in the device memory. This is the same input as in cudnnMultiHeadAttnForward().
- Input. Descriptor for values and dvalues sequence data.
- Output. Device pointer to gradients of the loss function computed with respect to values vectors.
- Input. Pointer to values data in the device memory. This is the same input as in cudnnMultiHeadAttnForward().
- Input. Size of the weight buffer in bytes where all multi-head attention trainable parameters are stored.
- Input. Address of the weight buffer in the device memory.
- Input. Size of the work-space buffer in bytes used for temporary API storage.
- Input/Output. Address of the work-space buffer in the device memory.
- Input. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls.
- Input/Output. Address to the reserve-space buffer in the device memory.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- An invalid or incompatible input argument was encountered.
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- An inconsistent internal state was encountered.
- A requested option or a combination of input arguments is not supported.
- Insufficient amount of shared memory to launch a GPU kernel.
8.2.17. cudnnMultiHeadAttnBackwardWeights()
cudnnStatus_t cudnnMultiHeadAttnBackwardWeights( cudnnHandle_t handle, const cudnnAttnDescriptor_t attnDesc, cudnnWgradMode_t addGrad, const cudnnSeqDataDescriptor_t qDesc, const void *queries, const cudnnSeqDataDescriptor_t kDesc, const void *keys, const cudnnSeqDataDescriptor_t vDesc, const void *values, const cudnnSeqDataDescriptor_t doDesc, const void *dout, size_t weightSizeInBytes, const void *weights, void *dweights, size_t workSpaceSizeInBytes, void *workSpace, size_t reserveSpaceSizeInBytes, void *reserveSpace);
All gradient results with respect to weights and biases are written to the dweights buffer. The size and the organization of the dweights buffer is the same as the weights buffer that holds multi-head attention weights and biases. The cuDNN multiHeadAttention sample code demonstrates how to access those weights.
Gradient of the loss function with respect to weights or biases is typically computed over multiple batches. In such a case, partial results computed for each batch should be summed together. The addGrad argument specifies if the gradients from the current batch should be added to previously computed results or the dweights buffer should be overwritten with the new results.
The cudnnMultiHeadAttnBackwardWeights() function should be invoked after cudnnMultiHeadAttnBackwardData(). The queries, keys, values, weights, and reserveSpace arguments should be the same as in cudnnMultiHeadAttnForward() and cudnnMultiHeadAttnBackwardData() calls. The dout argument should be the same as in cudnnMultiHeadAttnBackwardData().
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized attention descriptor.
- Input. Weight gradient output mode.
- Input. Descriptor for the query sequence data.
- Input. Pointer to queries sequence data in the device memory.
- Input. Descriptor for the keys sequence data.
- Input. Pointer to keys sequence data in the device memory.
- Input. Descriptor for the values sequence data.
- Input. Pointer to values sequence data in the device memory.
- Input. Descriptor for the gradients (vectors of partial derivatives of the loss function with respect to the multi-head attention outputs).
- Input. Pointer to gradient data in the device memory.
- Input. Size of the weights and dweights buffers in bytes.
- Input. Address of the weight buffer in the device memory.
- Output. Address of the weight gradient buffer in the device memory.
- Input. Size of the work-space buffer in bytes used for temporary API storage.
- Input/Output. Address of the work-space buffer in the device memory.
- Input. Size of the reserve-space buffer in bytes used for data exchange between forward and backward (gradient) API calls.
- Input/Output. Address to the reserve-space buffer in the device memory.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- An invalid or incompatible input argument was encountered.
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- An inconsistent internal state was encountered.
- A requested option or a combination of input arguments is not supported.
8.2.18. cudnnRNNBackwardData()
cudnnStatus_t cudnnRNNBackwardData(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *yDesc,
const void *y,
const cudnnTensorDescriptor_t *dyDesc,
const void *dy,
const cudnnTensorDescriptor_t dhyDesc,
const void *dhy,
const cudnnTensorDescriptor_t dcyDesc,
const void *dcy,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnTensorDescriptor_t *dxDesc,
void *dx,
const cudnnTensorDescriptor_t dhxDesc,
void *dhx,
const cudnnTensorDescriptor_t dcxDesc,
void *dcx,
void *workspace,
size_t workSpaceSizeInBytes,
const void *reserveSpace,
size_t reserveSpaceSizeInBytes)This routine executes the recurrent neural network described by rnnDesc with output gradients dy, dhy, and dhc, weights w and input gradients dx, dhx, and dcx. workspace is required for intermediate storage. The data in reserveSpace must have previously been generated by cudnnRNNForwardTraining(). The same reserveSpace data must be used for future calls to cudnnRNNBackwardWeights() if they execute on the same input data.
Parameters
- Input. Handle to a previously created cuDNN context. For more information, refer to cudnnHandle_t.
- Input. A previously initialized RNN descriptor. For more information, refer to cudnnRNNDescriptor_t.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). For more information, refer to cudnnTensorDescriptor_t. The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in dyDesc.
- Input. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
-
Input. An array of fully packed tensor descriptors describing the gradient at the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in dxDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array dyDesc.
-
Input. A fully packed tensor descriptor describing the gradients at the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor dhyDesc. If a NULL pointer is passed, the gradients at the final hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the gradients at the final cell state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor dcyDesc. If a NULL pointer is passed, the gradients at the final cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN. For more information, refer to cudnnFilterDescriptor_t.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the second dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the second dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. An array of fully packed tensor descriptors describing the gradient at the input of each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Output. Data pointer to GPU memory associated with the tensor descriptors in the array dxDesc.
-
Input. A fully packed tensor descriptor describing the gradient at the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor dhxDesc. If a NULL pointer is passed, the gradient at the hidden input of the network will not be set.
-
Input. A fully packed tensor descriptor describing the gradient at the initial cell state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor dcxDesc. If a NULL pointer is passed, the gradient at the cell input of the network will not be set.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors dhxDesc, wDesc, hxDesc, cxDesc, dcxDesc, dhyDesc, or dcyDesc or one of the descriptors in yDesc, dxdesc, dydesc is invalid.
- The descriptors in one of yDesc, dxDesc, dyDesc, dhxDesc, wDesc, hxDesc, cxDesc, dcxDesc, dhyDesc, or dcyDesc has incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
-
A GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If CUDNN_STATUS_MAPPING_ERROR is returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.19. cudnnRNNBackwardData_v8()
cudnnStatus_t cudnnRNNBackwardData_v8(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
const int32_t devSeqLengths[],
cudnnRNNDataDescriptor_t yDesc,
const void *y,
const void *dy,
cudnnRNNDataDescriptor_t xDesc,
void *dx,
cudnnTensorDescriptor_t hDesc,
const void *hx,
const void *dhy,
void *dhx,
cudnnTensorDescriptor_t cDesc,
const void *cx,
const void *dcy,
void *dcx,
size_t weightSpaceSize,
const void *weightSpace,
size_t workSpaceSize,
void *workSpace,
size_t reserveSpaceSize,
void *reserveSpace);
Locations of x, y, hx, cx, hy, cy, dx, dy, dhx, dcx, dhy, and dcy signals a multi-layer RNN model are shown in the following figure. Note that internal RNN signals (between time-steps and between layers) are not exposed by the cudnnRNNBackwardData_v8() function.
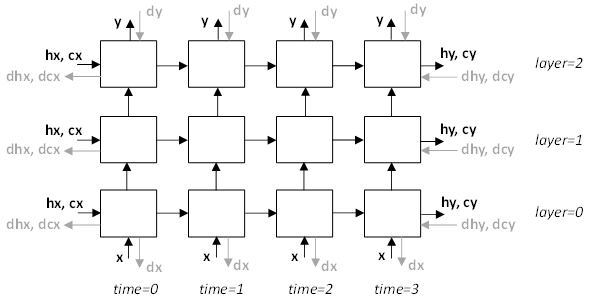
Memory addresses to the primary RNN output y, the initial hidden state hx, and the initial cell state cx (for LSTM only) should point to the same data as in the preceding cudnnRNNForward() call. The dy and dx pointers cannot be NULL.
The cudnnRNNBackwardData_v8() function accepts any combination of dhy, dhx, dcy, dcx buffer addresses being NULL. When dhy or dcy are NULL, it is assumed that those inputs are zero. When dhx or dcx pointers are NULL then the corresponding results are not written by cudnnRNNBackwardData_v8().
When all hx, dhy, dhx pointers are NULL, then the corresponding tensor descriptor hDesc can be NULL too. The same rule applies to the cx, dcy, dcx pointers and the cDesc tensor descriptor.
The cudnnRNNBackwardData_v8() function allows the user to use padded layouts for inputs y, dy, and output dx. In padded or unpacked layouts (CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_UNPACKED, CUDNN_RNN_DATA_LAYOUT_BATCH_MAJOR_UNPACKED) each sequence of vectors in a mini-batch has a fixed length defined by the maxSeqLength argument in the cudnnSetRNNDataDescriptor() function. The term "unpacked" refers here to the presence of padding vectors, and not unused address ranges between contiguous vectors.
Each padded, fixed-length sequence starts from a segment of valid vectors. The valid vector count is stored in seqLengthArray passed to cudnnSetRNNDataDescriptor(), such that 0 < seqLengthArray[i] <= maxSeqLength for all sequences in a mini-batch, that is, for i=0..batchSize-1. The remaining padding vectors make the combined sequence length equal to maxSeqLength. Both sequence-major and batch-major padded layouts are supported.
In addition, a packed sequence-major layout: CUDNN_RNN_DATA_LAYOUT_SEQ_MAJOR_PACKED can be selected by the user. In the latter layout, sequences of vectors in a mini-batch are sorted in the descending order according to the sequence lengths. First, all vectors for time step zero are stored. They are followed by vectors for time step one, and so on. This layout uses no padding vectors.
The same layout type must be specified in xDesc and yDesc descriptors.
Two host arrays named seqLengthArray in xDesc and yDesc RNN data descriptors must be the same. In addition, a copy of seqLengthArray in the device memory must be passed via the devSeqLengths argument. This array is supplied directly to GPU kernels. The cudnnRNNBackwardData_v8() function does not verify that sequence lengths stored in devSeqLengths in GPU memory are the same as in xDesc and yDesc descriptors in CPU memory. Sequence length arrays from xDesc and yDesc descriptors are checked for consistency, however.
The cudnnRNNBackwardData_v8() function must be called after cudnnRNNForward(). The cudnnRNNForward() function should be invoked with the fwdMode argument of type cudnnRNNForward() set to CUDNN_FWD_MODE_TRAINING.
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized RNN descriptor.
- Input. A copy of seqLengthArray from xDesc or yDesc RNN data descriptors. The devSeqLengths array must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after the cudnnRNNBackwardData_v8() function exists. This argument cannot be NULL.
- Input. A previously initialized descriptor corresponding to the RNN model primary output. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray need to match that of xDesc.
- Input. Data pointers to GPU buffers holding the RNN model primary output and gradient deltas (gradient of the loss function with respect to y). The y output should be produced by the preceding cudnnRNNForward() call. The y and dy vectors are expected to be laid out in memory according to the layout specified by yDesc. The elements in the tensor (including elements in padding vectors) must be densely packed. The y and dy arguments cannot be NULL.
- Input. A previously initialized RNN data descriptor corresponding to the gradient of the loss function with respect to the RNN primary model input. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray must match that of yDesc. The parameter vectorSize must match the inputSize argument passed to the cudnnSetRNNDescriptor_v8() function.
- Output. Data pointer to GPU memory where back-propagated gradients of the loss function with respect to the RNN primary input x should be stored. The vectors are expected to be arranged in memory according to the layout specified by xDesc. The elements in the tensor (including padding vectors) must be densely packed. This argument cannot be NULL.
-
Input. A tensor descriptor describing the initial RNN hidden state hx and gradients of the loss function with respect to the initial of the final hidden state. Hidden state data and the corresponding gradients are fully packed. The first dimension of the tensor depends on the dirMode argument passed to the cudnnSetRNNDescriptor_v8() function.
- If dirMode is CUDNN_UNIDIRECTIONAL, then the first dimension should match the numLayers argument passed to cudnnSetRNNDescriptor_v8().
- If dirMode is CUDNN_BIDIRECTIONAL, then the first dimension should be double the numLayers argument passed to cudnnSetRNNDescriptor_v8().
The second dimension must match the batchSize parameter described in xDesc. The third dimension depends on whether RNN mode is CUDNN_LSTM and whether the LSTM projection is enabled. Specifically:- If RNN mode is CUDNN_LSTM and LSTM projection is enabled, the third dimension must match the projSize argument passed to the cudnnSetRNNDescriptor_v8() call.
- Otherwise, the third dimension must match the hiddenSize argument passed to the cudnnSetRNNDescriptor_v8() call used to initialize rnnDesc.
- Input. Addresses of GPU buffers with the RNN initial hidden state hx and gradient deltas dhy. Data dimensions are described by the hDesc tensor descriptor. If a NULL pointer is passed in hx or dhy arguments, the corresponding buffer is assumed to contain all zeros.
- Output. Pointer to the GPU buffer where first-order derivatives corresponding to initial hidden state variables should be stored. Data dimensions are described by the hDesc tensor descriptor. If a NULL pointer is assigned to dhx, the back-propagated derivatives are not saved.
-
Input. For LSTM networks only. A tensor descriptor describing the initial cell state cx and gradients of the loss function with respect to the initial of the final cell state. Cell state data are fully packed. The first dimension of the tensor depends on the dirMode argument passed to the cudnnSetRNNDescriptor_v8() call.
- If dirMode is CUDNN_UNIDIRECTIONAL, then the first dimension should match the numLayers argument passed to cudnnSetRNNDescriptor_v8().
- If dirMode is CUDNN_BIDIRECTIONAL, then the first dimension should be double the numLayers argument passed to cudnnSetRNNDescriptor_v8().
The second tensor dimension must match the batchSize parameter in xDesc. The third dimension must match the hiddenSize argument passed to the cudnnSetRNNDescriptor_v8() call.
- Input. For LSTM networks only. Addresses of GPU buffers with the initial LSTM state data and gradient deltas dcy. Data dimensions are described by the cDesc tensor descriptor. If a NULL pointer is passed in cx or dcy arguments, the corresponding buffer is assumed to contain all zeros.
- Output. For LSTM networks only. Pointer to the GPU buffer where first-order derivatives corresponding to initial LSTM state variables should be stored. Data dimensions are described by the cDesc tensor descriptor. If a NULL pointer is assigned to dcx, the back-propagated derivatives are not saved.
- Input. Specifies the size in bytes of the provided weight-space buffer.
- Input. Address of the weight space buffer in GPU memory.
- Input. Specifies the size in bytes of the provided workspace buffer.
- Input/Output. Address of the workspace buffer in GPU memory to store temporary data.
- Input. Specifies the size in bytes of the reserve-space buffer.
- Input/Output. Address of the reserve-space buffer in GPU memory.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- At least one of the following conditions are met:
- variable sequence length input is passed while CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is specified
- CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is requested on pre-Pascal devices
- the 'double' floating point type is used for input/output and the CUDNN_RNN_ALGO_PERSIST_STATIC algo
- An invalid or incompatible input argument was encountered. For
example:
- some input descriptors are NULL
- settings in rnnDesc, xDesc, yDesc, hDesc, or cDesc descriptors are invalid
- weightSpaceSize, workSpaceSize, or reserveSpaceSize is too small
-
A GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If CUDNN_STATUS_MAPPING_ERROR is returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- The function was unable to allocate CPU memory.
8.2.20. cudnnRNNBackwardDataEx()
cudnnStatus_t cudnnRNNBackwardDataEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const cudnnRNNDataDescriptor_t yDesc,
const void *y,
const cudnnRNNDataDescriptor_t dyDesc,
const void *dy,
const cudnnRNNDataDescriptor_t dcDesc,
const void *dcAttn,
const cudnnTensorDescriptor_t dhyDesc,
const void *dhy,
const cudnnTensorDescriptor_t dcyDesc,
const void *dcy,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnRNNDataDescriptor_t dxDesc,
void *dx,
const cudnnTensorDescriptor_t dhxDesc,
void *dhx,
const cudnnTensorDescriptor_t dcxDesc,
void *dcx,
const cudnnRNNDataDescriptor_t dkDesc,
void *dkeys,
void *workSpace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)
This routine is the extended version of the function cudnnRNNBackwardData(). This function cudnnRNNBackwardDataEx() allows the user to use an unpacked (padded) layout for input y and output dx.
In the unpacked layout, each sequence in the mini-batch is considered to be of fixed length, specified by maxSeqLength in its corresponding RNNDataDescriptor. Each fixed-length sequence, for example, the nth sequence in the mini-batch, is composed of a valid segment specified by the seqLengthArray[n] in its corresponding RNNDataDescriptor; and a padding segment to make the combined sequence length equal to maxSeqLength.
With the unpacked layout, both sequence major (meaning, time major) and batch major are supported. For backward compatibility, the packed sequence major layout is supported. However, similar to the non-extended function cudnnRNNBackwardData(), the sequences in the mini-batch need to be sorted in descending order according to length.
Parameters
- Input. Handle to a previously created This function is deprecated starting in cuDNN 8.0.0. context.
- Input. A previously initialized RNN descriptor.
- Input. A previously initialized RNN data descriptor. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to the GPU memory associated with the RNN data descriptor yDesc. The vectors are expected to be laid out in memory according to the layout specified by yDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported. Must contain the exact same data previously produced by cudnnRNNForwardTrainingEx().
- Input. A previously initialized RNN data descriptor. The dataType, layout, maxSeqLength, batchSize, vectorSize, and seqLengthArray need to match the yDesc previously passed to cudnnRNNForwardTrainingEx().
- Input. Data pointer to the GPU memory associated with the RNN data descriptor dyDesc. The vectors are expected to be laid out in memory according to the layout specified by dyDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
-
Input. A fully packed tensor descriptor describing the gradients at the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc. Additionally:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the batchSize parameter in xDesc. The third dimension depends on whether the RNN mode is CUDNN_LSTM and whether LSTM projection is enabled. Additionally:
- If the RNN mode is CUDNN_LSTM and LSTM projection is enabled, the third dimension must match the recProjSize argument passed to cudnnSetRNNProjectionLayers() call used to set rnnDesc.
- Otherwise, the third dimension must match the hiddenSize argument used to initialize rnnDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptor dhyDesc. If a NULL pointer is passed, the gradients at the final hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the gradients at the final cell state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc. Additionally:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor dcyDesc. If a NULL pointer is passed, the gradients at the final cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
- Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero. Must contain the exact same data previously passed into cudnnRNNForwardTrainingEx(), or be NULL if NULL was previously passed to cudnnRNNForwardTrainingEx().
- Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero. Must contain the exact same data previously passed into cudnnRNNForwardTrainingEx(), or be NULL if NULL was previously passed to cudnnRNNForwardTrainingEx().
- Input. A previously initialized RNN data descriptor. The dataType, layout, maxSeqLength, batchSize, vectorSize and seqLengthArray need to match that of xDesc previously passed to cudnnRNNForwardTrainingEx().
- Output. Data pointer to the GPU memory associated with the RNN data descriptor dxDesc. The vectors are expected to be laid out in memory according to the layout specified by dxDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
- Input. A fully packed tensor descriptor describing the gradient at the initial hidden state of the RNN. The descriptor must be set exactly the same way as dhyDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor dhxDesc. If a NULL pointer is passed, the gradient at the hidden input of the network will not be set.
- Input. A fully packed tensor descriptor describing the gradient at the initial cell state of the RNN. The descriptor must be set exactly the same way as dcyDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor dcxDesc. If a NULL pointer is passed, the gradient at the cell input of the network will not be set.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- Variable sequence length input is passed in while CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used.
- CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used on pre-Pascal devices.
- Double input/output is used for CUDNN_RNN_ALGO_PERSIST_STATIC.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors yDesc, dxdesc, dydesc, dhxDesc, wDesc, hxDesc, cxDesc, dcxDesc, dhyDesc, or dcyDesc is invalid or has incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
-
A GPU/CUDA resource, such as a texture object, shared memory, or zero-copy memory is not available in the required size or there is a mismatch between the user resource and cuDNN internal resources. A resource mismatch may occur, for example, when calling cudnnSetStream(). There could be a mismatch between the user provided CUDA stream and the internal CUDA events instantiated in the cuDNN handle when cudnnCreate() was invoked.
This error status may not be correctable when it is related to texture dimensions, shared memory size, or zero-copy memory availability. If CUDNN_STATUS_MAPPING_ERROR is returned by cudnnSetStream(), then it is typically correctable, however, it means that the cuDNN handle was created on one GPU and the user stream passed to this function is associated with another GPU.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.21. cudnnRNNBackwardWeights()
cudnnStatus_t cudnnRNNBackwardWeights(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t *yDesc,
const void *y,
const void *workspace,
size_t workSpaceSizeInBytes,
const cudnnFilterDescriptor_t dwDesc,
void *dw,
const void *reserveSpace,
size_t reserveSpaceSizeInBytes)This routine accumulates weight gradients dw from the recurrent neural network described by rnnDesc with inputs x, hx and outputs y. The mode of operation in this case is additive, the weight gradients calculated will be added to those already existing in dw. workspace is required for intermediate storage. The data in reserveSpace must have previously been generated by cudnnRNNBackwardData().
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of fully packed tensor descriptors describing the input to each recurrent iteration (one descriptor per iteration). The first dimension (batch size) of the tensors may decrease from element n to element n+1 but may not increase. Each tensor descriptor must have the same second dimension (vector length).
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array xDesc.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in dyDesc.
- Input. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input. Handle to a previously initialized filter descriptor describing the gradients of the weights for the RNN.
- Input/Output. Data pointer to GPU memory associated with the filter descriptor dwDesc.
- Input. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, dwDesc or one of the descriptors in xDesc, yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, yDesc, dwDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.22. cudnnRNNBackwardWeights_v8()
cudnnStatus_t cudnnRNNBackwardWeights_v8(
cudnnHandle_t handle,
cudnnRNNDescriptor_t rnnDesc,
cudnnWgradMode_t addGrad,
const int32_t devSeqLengths[],
cudnnRNNDataDescriptor_t xDesc,
const void *x,
cudnnTensorDescriptor_t hDesc,
const void *hx,
cudnnRNNDataDescriptor_t yDesc,
const void *y,
size_t weightSpaceSize,
void *dweightSpace,
size_t workSpaceSize,
void *workSpace,
size_t reserveSpaceSize,
void *reserveSpace);
All gradient results with respect to weights and biases are written to the dweightSpace buffer. The size and the organization of the dweightSpace buffer is the same as the weightSpace buffer that holds RNN weights and biases.
Gradient of the loss function with respect to weights and biases is typically computed over multiple mini-batches. In such a case, partial results computed for each mini-batch should be aggregated. The addGrad argument specifies if gradients from the current mini-batch should be added to previously computed results (CUDNN_WGRAD_MODE_ADD) or the dweightSpace buffer should be overwritten with the new results (CUDNN_WGRAD_MODE_SET). Currently, the cudnnRNNBackwardWeights_v8() function supports the CUDNN_WGRAD_MODE_ADD mode only so the dweightSpace buffer should be zeroed by the user before invoking the routine for the first time.
The same sequence lengths must be specified in the xDesc descriptor and in the device array devSeqLengths. The cudnnRNNBackwardWeights_v8() function should be invoked after cudnnRNNBackwardData().
Parameters
- Input. The current cuDNN context handle.
- Input. A previously initialized RNN descriptor.
- Input. Weight gradient output mode. For more details, see the description of the cudnnWgradMode_t enumerated type. Currently, only the CUDNN_WGRAD_MODE_ADD mode is supported by the cudnnRNNBackwardWeights_v8() function.
- Input. A copy of seqLengthArray from the xDesc RNN data descriptor. The devSeqLengths array must be stored in GPU memory as it is accessed asynchronously by GPU kernels, possibly after the cudnnRNNBackwardWeights_v8() function exists.
- Input. A previously initialized descriptor corresponding to the RNN model input data. This is the same RNN data descriptor as used in the preceding cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
- Input. Pointer to the GPU buffer with the primary RNN input. The same buffer address x should be provided in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
- Input. A tensor descriptor describing the initial RNN hidden state. Hidden state data are fully packed. This is the same tensor descriptor as used in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
- Input. Pointer to the GPU buffer with the RNN initial hidden state. The same buffer address hx should be provided in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
- Input. A previously initialized descriptor corresponding to the RNN model output data. This is the same RNN data descriptor as used in prior cudnnRNNForward() and cudnnRNNBackwardData_v8() calls.
- Output. Pointer to the GPU buffer with the primary RNN output as generated by the prior cudnnRNNForward() call. Data in the y buffer are described by the yDesc descriptor. Elements in the y tensor (including elements in padding vectors) must be densely packed.
- Input. Specifies the size in bytes of the provided weight-space buffer.
- Output. Address of the weight space buffer in GPU memory.
- Input. Specifies the size in bytes of the provided workspace buffer.
- Input/Output. Address of the workspace buffer in GPU memory to store temporary data.
- Input. Specifies the size in bytes of the reserve-space buffer.
- Input/Output. Address of the reserve-space buffer in GPU memory.
Returns
- No errors were detected while processing API input arguments and launching GPU kernels.
- The function does not support the provided configuration.
- An invalid or incompatible input argument was encountered. For
example:
- some input descriptors are NULL
- settings in rnnDesc, xDesc, yDesc, or hDesc descriptors are invalid
- weightSpaceSize, workSpaceSize, or reserveSpaceSize values are too small
- the addGrad argument is not equal to CUDNN_WGRAD_MODE_ADD
- The process of launching a GPU kernel returned an error, or an earlier kernel did not complete successfully.
- The function was unable to allocate CPU memory.
8.2.23. cudnnRNNBackwardWeightsEx()
cudnnStatus_t cudnnRNNBackwardWeightsEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const cudnnRNNDataDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnRNNDataDescriptor_t yDesc,
const void *y,
void *workSpace,
size_t workSpaceSizeInBytes,
const cudnnFilterDescriptor_t dwDesc,
void *dw,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)
This routine is the extended version of the function cudnnRNNBackwardWeights(). This function cudnnRNNBackwardWeightsEx() allows the user to use an unpacked (padded) layout for input x and output dw.
In the unpacked layout, each sequence in the mini-batch is considered to be of fixed length, specified by maxSeqLength in its corresponding RNNDataDescriptor. Each fixed-length sequence, for example, the nth sequence in the mini-batch, is composed of a valid segment specified by the seqLengthArray[n] in its corresponding RNNDataDescriptor; and a padding segment to make the combined sequence length equal to maxSeqLength.
With the unpacked layout, both sequence major (meaning, time major) and batch major are supported. For backward compatibility, the packed sequence major layout is supported. However, similar to the non-extended function cudnnRNNBackwardWeights(), the sequences in the mini-batch need to be sorted in descending order according to length.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. A previously initialized RNN data descriptor. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory associated with the tensor descriptors in the array xDesc. Must contain the exact same data previously passed into cudnnRNNForwardTrainingEx().
- Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero. Must contain the exact same data previously passed into cudnnRNNForwardTrainingEx(), or be NULL if NULL was previously passed to cudnnRNNForwardTrainingEx().
- Input. A previously initialized RNN data descriptor. Must match or be the exact same descriptor previously passed into cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory associated with the output tensor descriptor yDesc. Must contain the exact same data previously produced by cudnnRNNForwardTrainingEx().
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input. Handle to a previously initialized filter descriptor describing the gradients of the weights for the RNN.
- Input/Output. Data pointer to GPU memory associated with the filter descriptor dwDesc.
- Input. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- The function does not support the provided configuration.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors xDesc, yDesc, hxDesc, dwDesc is invalid, or has incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.24. cudnnRNNForwardTraining()
cudnnStatus_t cudnnRNNForwardTraining(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const int seqLength,
const cudnnTensorDescriptor_t *xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnTensorDescriptor_t *yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
void *workspace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes)This routine executes the recurrent neural network described by rnnDesc with inputs x, hx, and cx, weights w and outputs y, hy, and cy. workspace is required for intermediate storage. reserveSpace stores data required for training. The same reserveSpace data must be used for future calls to cudnnRNNBackwardData() and cudnnRNNBackwardWeights() if these execute on the same input data.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. Number of iterations to unroll over. The value of this seqLength must not exceed the value that was used in the cudnnGetRNNWorkspaceSize() function for querying the workspace size required to execute the RNN.
- Input. An array of seqLength fully packed tensor
descriptors. Each descriptor in the array should have three dimensions
that describe the input data format to one recurrent iteration (one
descriptor per RNN time-step). The first dimension (batch size) of the
tensors may decrease from iteration element n to iteration element
n+1 but may not increase. Each tensor descriptor
must have the same second dimension (RNN input vector length,
inputSize). The third dimension of each tensor
should be 1. Input vectors are expected to be arranged in the
column-major order so strides in xDesc should be set as
follows:
strideA[0]=inputSize, strideA[1]=1, strideA[2]=1
- Input. Data pointer to GPU memory associated with the array of tensor descriptors xDesc. The input vectors are expected to be packed contiguously with the first vector of iterations (time-step) n+1 following directly the last vector of iteration n. In other words, input vectors for all RNN time-steps should be packed in the contiguous block of GPU memory with no gaps between the vectors.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. An array of fully packed tensor descriptors describing the output from each recurrent iteration (one descriptor per iteration). The second dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the second dimension should match the hiddenSize argument.
- If direction is CUDNN_BIDIRECTIONAL the second dimension should match double the hiddenSize argument.
The first dimension of the tensor n must match the first dimension of the tensor n in xDesc.
- Output. Data pointer to GPU memory associated with the output tensor descriptor yDesc.
-
Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
-
Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The first dimension of the tensor depends on the direction argument used to initialize rnnDesc:
- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
-
The function launched successfully.
-
At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors hxDesc, cxDesc, wDesc, hyDesc, cyDesc or one of the descriptors in xDesc, yDesc is invalid.
- The descriptors in one of xDesc, hxDesc, cxDesc, wDesc, yDesc, hyDesc, cyDesc have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
-
cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.25. cudnnRNNForwardTrainingEx()
cudnnStatus_t cudnnRNNForwardTrainingEx(
cudnnHandle_t handle,
const cudnnRNNDescriptor_t rnnDesc,
const cudnnRNNDataDescriptor_t xDesc,
const void *x,
const cudnnTensorDescriptor_t hxDesc,
const void *hx,
const cudnnTensorDescriptor_t cxDesc,
const void *cx,
const cudnnFilterDescriptor_t wDesc,
const void *w,
const cudnnRNNDataDescriptor_t yDesc,
void *y,
const cudnnTensorDescriptor_t hyDesc,
void *hy,
const cudnnTensorDescriptor_t cyDesc,
void *cy,
const cudnnRNNDataDescriptor_t kDesc,
const void *keys,
const cudnnRNNDataDescriptor_t cDesc,
void *cAttn,
const cudnnRNNDataDescriptor_t iDesc,
void *iAttn,
const cudnnRNNDataDescriptor_t qDesc,
void *queries,
void *workSpace,
size_t workSpaceSizeInBytes,
void *reserveSpace,
size_t reserveSpaceSizeInBytes);
This routine is the extended version of the cudnnRNNForwardTraining() function. The cudnnRNNForwardTrainingEx() allows the user to use unpacked (padded) layout for input x and output y.
In the unpacked layout, each sequence in the mini-batch is considered to be of fixed length, specified by maxSeqLength in its corresponding RNNDataDescriptor. Each fixed-length sequence, for example, the nth sequence in the mini-batch, is composed of a valid segment specified by the seqLengthArray[n] in its corresponding RNNDataDescriptor; and a padding segment to make the combined sequence length equal to maxSeqLength.
With the unpacked layout, both sequence major (meaning, time major) and batch major are supported. For backward compatibility, the packed sequence major layout is supported. However, similar to the non-extended function cudnnRNNForwardTraining(), the sequences in the mini-batch need to be sorted in descending order according to length.
Parameters
- Input. Handle to a previously created cuDNN context.
- Input. A previously initialized RNN descriptor.
- Input. A previously initialized RNN Data descriptor. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray need to match that of yDesc.
- Input. Data pointer to the GPU memory associated with the RNN data descriptor xDesc. The input vectors are expected to be laid out in memory according to the layout specified by xDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
-
Input. A fully packed tensor descriptor describing the initial hidden state of the RNN.
The first dimension of the tensor depends on the direction argument used to initialize rnnDesc. Moreover:- If direction is CUDNN_UNIDIRECTIONAL then the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL then the first dimension should match double the numLayers argument.
The second dimension must match the batchSize parameter in xDesc. The third dimension depends on whether RNN mode is CUDNN_LSTM and whether LSTM projection is enabled. Additionally:- If RNN mode is CUDNN_LSTM and LSTM projection is enabled, the third dimension must match the recProjSize argument passed to cudnnSetRNNProjectionLayers() call used to set rnnDesc.
- Otherwise, the third dimension must match the hiddenSize argument used to initialize rnnDesc.
- Input. Data pointer to GPU memory associated with the tensor descriptor hxDesc. If a NULL pointer is passed, the initial hidden state of the network will be initialized to zero.
-
Input. A fully packed tensor descriptor describing the initial cell state for LSTM networks.
The first dimension of the tensor depends on the direction argument used to initialize rnnDesc. Additionally:- If direction is CUDNN_UNIDIRECTIONAL the first dimension should match the numLayers argument.
- If direction is CUDNN_BIDIRECTIONAL the first dimension should match double the numLayers argument.
The second dimension must match the first dimension of the tensors described in xDesc. The third dimension must match the hiddenSize argument used to initialize rnnDesc. The tensor must be fully packed.
- Input. Data pointer to GPU memory associated with the tensor descriptor cxDesc. If a NULL pointer is passed, the initial cell state of the network will be initialized to zero.
- Input. Handle to a previously initialized filter descriptor describing the weights for the RNN.
- Input. Data pointer to GPU memory associated with the filter descriptor wDesc.
-
Input. A previously initialized RNN data descriptor. The dataType, layout, maxSeqLength, batchSize, and seqLengthArray need to match that of dyDesc and dxDesc. The parameter vectorSize depends on whether the RNN mode is CUDNN_LSTM and whether LSTM projection is enabled and whether the network is bidirectional. Specifically:
- For a unidirectional network, if the RNN mode is CUDNN_LSTM and LSTM projection is enabled, the parameter vectorSize must match the recProjSize argument passed to cudnnSetRNNProjectionLayers() call used to set rnnDesc. If the network is bidirectional, then multiply the value by 2.
- Otherwise, for unidirectional network, the parameter vectorSize must match the hiddenSize argument used to initialize rnnDesc. If the network is bidirectional, then multiply the value by 2.
- Output. Data pointer to GPU memory associated with the RNN data descriptor yDesc. The input vectors are expected to be laid out in memory according to the layout specified by yDesc. The elements in the tensor (including elements in the padding vector) must be densely packed, and no strides are supported.
- Input. A fully packed tensor descriptor describing the final hidden state of the RNN. The descriptor must be set exactly the same as hxDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor hyDesc. If a NULL pointer is passed, the final hidden state of the network will not be saved.
- Input. A fully packed tensor descriptor describing the final cell state for LSTM networks. The descriptor must be set exactly the same as cxDesc.
- Output. Data pointer to GPU memory associated with the tensor descriptor cyDesc. If a NULL pointer is passed, the final cell state of the network will not be saved.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Reserved. Users may pass in NULL.
- Input. Data pointer to GPU memory to be used as a workspace for this call.
- Input. Specifies the size in bytes of the provided workspace.
- Input/Output. Data pointer to GPU memory to be used as a reserve space for this call.
- Input. Specifies the size in bytes of the provided reserveSpace.
Returns
- The function launched successfully.
- At least one of the following conditions are met:
- Variable sequence length input is passed in while CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used.
- CUDNN_RNN_ALGO_PERSIST_STATIC or CUDNN_RNN_ALGO_PERSIST_DYNAMIC is used on pre-Pascal devices.
- Double input/output is used for CUDNN_RNN_ALGO_PERSIST_STATIC.
- At least one of the following conditions are met:
- The descriptor rnnDesc is invalid.
- At least one of the descriptors xDesc, yDesc, hxDesc, cxDesc, wDesc, hyDesc, and cyDesc is invalid, or have incorrect strides or dimensions.
- workSpaceSizeInBytes is too small.
- reserveSpaceSizeInBytes is too small.
- cudnnSetPersistentRNNPlan() was not called prior to the current function when CUDNN_RNN_ALGO_PERSIST_DYNAMIC was selected in the RNN descriptor.
- The function failed to launch on the GPU.
- The function was unable to allocate memory.
8.2.26. cudnnSetCTCLossDescriptor()
cudnnStatus_t cudnnSetCTCLossDescriptor(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t compType)cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
8.2.27. cudnnSetCTCLossDescriptorEx()
cudnnStatus_t cudnnSetCTCLossDescriptorEx(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t compType,
cudnnLossNormalizationMode_t normMode,
cudnnNanPropagation_t gradMode)cudnnSetCtcLossDescriptor(*) = cudnnSetCtcLossDescriptorEx(*, normMode=CUDNN_LOSS_NORMALIZATION_NONE, gradMode=CUDNN_NOT_PROPAGATE_NAN)
Parameters
- Output. CTC loss descriptor to be set.
- Input. Compute type for this CTC loss function.
- Input. Input normalization type for this CTC loss function. For more information, refer to cudnnLossNormalizationMode_t.
- Input. NaN propagation type for this CTC loss function. For L the sequence length, R the number of repeated letters in the sequence, and T the length of sequential data, the following applies: when a sample with L+R > T is encountered during the gradient calculation, if gradMode is set to CUDNN_PROPAGATE_NAN (refer to cudnnNanPropagation_t), then the CTC loss function does not write to the gradient buffer for that sample. Instead, the current values, even not finite, are retained. If gradMode is set to CUDNN_NOT_PROPAGATE_NAN, then the gradient for that sample is set to zero. This guarantees a finite gradient.
8.2.28. cudnnSetCTCLossDescriptor_v8()
cudnnStatus_t cudnnSetCTCLossDescriptorEx(
cudnnCTCLossDescriptor_t ctcLossDesc,
cudnnDataType_t compType,
cudnnLossNormalizationMode_t normMode,
cudnnNanPropagation_t gradMode,
int maxLabelLength)
Parameters
- Output. CTC loss descriptor to be set.
- Input. Compute type for this CTC loss function.
- Input. Input normalization type for this CTC loss function. For more information, refer to cudnnLossNormalizationMode_t.
- Input. NaN propagation type for this CTC loss function. For L the sequence length, R the number of repeated letters in the sequence, and T the length of sequential data, the following applies: when a sample with L+R > T is encountered during the gradient calculation, if gradMode is set to CUDNN_PROPAGATE_NAN (refer to cudnnNanPropagation_t), then the CTC loss function does not write to the gradient buffer for that sample. Instead, the current values, even not finite, are retained. If gradMode is set to CUDNN_NOT_PROPAGATE_NAN, then the gradient for that sample is set to zero. This guarantees a finite gradient.
- Input. The maximum label length from the labels data.
9. cuDNN Backend API
- cudnnBackendCreateDescriptor() creates a descriptor of a specified type.
- cudnnBackendSetAttribute() sets the values of a settable attribute for the descriptor. All required attributes must be set before the next step.
- cudnnBackendFinalize() finalizes the descriptor.
- cudnnBackendGetAttribute() gets the values of an attribute from a finalized descriptor.
The enumeration type cudnnBackendDescriptorType_t enumerates the list of valid cuDNN backend descriptor types. The enumeration type cudnnBackendAttributeName_t enumerates the list of valid attributes. Each descriptor type in cudnnBackendDescriptorType_t has a disjoint subset of valid attribute values of cudnnBackendAttributeName_t. The full description of each descriptor type and their attributes are specified in the Backend Descriptor Types section.
9.1. Data Type References
9.1.1. Enumeration Types
9.1.1.1. cudnnBackendAttributeName_t
typedef enum { CUDNN_ATTR_POINTWISE_MODE = 0, CUDNN_ATTR_POINTWISE_MATH_PREC = 1, CUDNN_ATTR_POINTWISE_NAN_PROPAGATION = 2, CUDNN_ATTR_POINTWISE_RELU_LOWER_CLIP = 3, CUDNN_ATTR_POINTWISE_RELU_UPPER_CLIP = 4, CUDNN_ATTR_POINTWISE_RELU_LOWER_CLIP_SLOPE = 5, CUDNN_ATTR_POINTWISE_ELU_ALPHA = 6, CUDNN_ATTR_POINTWISE_SOFTPLUS_BETA = 7, CUDNN_ATTR_POINTWISE_SWISH_BETA = 8, CUDNN_ATTR_POINTWISE_AXIS = 9, CUDNN_ATTR_CONVOLUTION_COMP_TYPE = 100, CUDNN_ATTR_CONVOLUTION_CONV_MODE = 101, CUDNN_ATTR_CONVOLUTION_DILATIONS = 102, CUDNN_ATTR_CONVOLUTION_FILTER_STRIDES = 103, CUDNN_ATTR_CONVOLUTION_POST_PADDINGS = 104, CUDNN_ATTR_CONVOLUTION_PRE_PADDINGS = 105, CUDNN_ATTR_CONVOLUTION_SPATIAL_DIMS = 106, CUDNN_ATTR_ENGINEHEUR_MODE = 200, CUDNN_ATTR_ENGINEHEUR_OPERATION_GRAPH = 201, CUDNN_ATTR_ENGINEHEUR_RESULTS = 202, CUDNN_ATTR_ENGINECFG_ENGINE = 300, CUDNN_ATTR_ENGINECFG_INTERMEDIATE_INFO = 301, CUDNN_ATTR_ENGINECFG_KNOB_CHOICES = 302, CUDNN_ATTR_EXECUTION_PLAN_HANDLE = 400, CUDNN_ATTR_EXECUTION_PLAN_ENGINE_CONFIG = 401, CUDNN_ATTR_EXECUTION_PLAN_WORKSPACE_SIZE = 402, CUDNN_ATTR_EXECUTION_PLAN_COMPUTED_INTERMEDIATE_UIDS = 403, CUDNN_ATTR_EXECUTION_PLAN_RUN_ONLY_INTERMEDIATE_UIDS = 404, CUDNN_ATTR_INTERMEDIATE_INFO_UNIQUE_ID = 500, CUDNN_ATTR_INTERMEDIATE_INFO_SIZE = 501, CUDNN_ATTR_INTERMEDIATE_INFO_DEPENDENT_DATA_UIDS = 502, CUDNN_ATTR_INTERMEDIATE_INFO_DEPENDENT_ATTRIBUTES = 503, CUDNN_ATTR_KNOB_CHOICE_KNOB_TYPE = 600, CUDNN_ATTR_KNOB_CHOICE_KNOB_VALUE = 601, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_ALPHA = 700, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_BETA = 701, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_CONV_DESC = 702, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_W = 703, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_X = 704, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_Y = 705, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_ALPHA = 706, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_BETA = 707, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_CONV_DESC = 708, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_W = 709, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DX = 710, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_DATA_DY = 711, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_ALPHA = 712, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_BETA = 713, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_CONV_DESC = 714, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DW = 715, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_X = 716, CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DY = 717, CUDNN_ATTR_OPERATION_POINTWISE_PW_DESCRIPTOR = 750, CUDNN_ATTR_OPERATION_POINTWISE_XDESC = 751, CUDNN_ATTR_OPERATION_POINTWISE_BDESC = 752, CUDNN_ATTR_OPERATION_POINTWISE_YDESC = 753, CUDNN_ATTR_OPERATION_POINTWISE_ALPHA1 = 754, CUDNN_ATTR_OPERATION_POINTWISE_ALPHA2 = 755, CUDNN_ATTR_OPERATION_POINTWISE_DXDESC = 756, CUDNN_ATTR_OPERATION_POINTWISE_DYDESC = 757, CUDNN_ATTR_OPERATION_POINTWISE_TDESC = 758, CUDNN_ATTR_OPERATION_GENSTATS_MODE = 770, CUDNN_ATTR_OPERATION_GENSTATS_MATH_PREC = 771, CUDNN_ATTR_OPERATION_GENSTATS_XDESC = 772, CUDNN_ATTR_OPERATION_GENSTATS_SUMDESC = 773, CUDNN_ATTR_OPERATION_GENSTATS_SQSUMDESC = 774, CUDNN_ATTR_OPERATION_BN_FINALIZE_STATS_MODE = 780, CUDNN_ATTR_OPERATION_BN_FINALIZE_MATH_PREC = 781, CUDNN_ATTR_OPERATION_BN_FINALIZE_Y_SUM_DESC = 782, CUDNN_ATTR_OPERATION_BN_FINALIZE_Y_SQ_SUM_DESC = 783, CUDNN_ATTR_OPERATION_BN_FINALIZE_SCALE_DESC = 784, CUDNN_ATTR_OPERATION_BN_FINALIZE_BIAS_DESC = 785, CUDNN_ATTR_OPERATION_BN_FINALIZE_PREV_RUNNING_MEAN_DESC = 786, CUDNN_ATTR_OPERATION_BN_FINALIZE_PREV_RUNNING_VAR_DESC = 787, CUDNN_ATTR_OPERATION_BN_FINALIZE_UPDATED_RUNNING_MEAN_DESC = 788, CUDNN_ATTR_OPERATION_BN_FINALIZE_UPDATED_RUNNING_VAR_DESC = 789, CUDNN_ATTR_OPERATION_BN_FINALIZE_SAVED_MEAN_DESC = 790, CUDNN_ATTR_OPERATION_BN_FINALIZE_SAVED_INV_STD_DESC = 791, CUDNN_ATTR_OPERATION_BN_FINALIZE_EQ_SCALE_DESC = 792, CUDNN_ATTR_OPERATION_BN_FINALIZE_EQ_BIAS_DESC = 793, CUDNN_ATTR_OPERATION_BN_FINALIZE_ACCUM_COUNT_DESC = 794, CUDNN_ATTR_OPERATION_BN_FINALIZE_EPSILON_DESC = 795, CUDNN_ATTR_OPERATION_BN_FINALIZE_EXP_AVERATE_FACTOR_DESC = 796, CUDNN_ATTR_OPERATIONGRAPH_HANDLE = 800, CUDNN_ATTR_OPERATIONGRAPH_OPS = 801, CUDNN_ATTR_OPERATIONGRAPH_ENGINE_GLOBAL_COUNT = 802, CUDNN_ATTR_TENSOR_BYTE_ALIGNMENT = 900, CUDNN_ATTR_TENSOR_DATA_TYPE = 901, CUDNN_ATTR_TENSOR_DIMENSIONS = 902, CUDNN_ATTR_TENSOR_STRIDES = 903, CUDNN_ATTR_TENSOR_VECTOR_COUNT = 904, CUDNN_ATTR_TENSOR_VECTORIZED_DIMENSION = 905, CUDNN_ATTR_TENSOR_UNIQUE_ID = 906, CUDNN_ATTR_TENSOR_IS_VIRTUAL = 907, CUDNN_ATTR_TENSOR_IS_BY_VALUE = 908, CUDNN_ATTR_TENSOR_REORDERING_MODE = 909, CUDNN_ATTR_TENSOR_RAGGED_OFFSET_DESC = 910, CUDNN_ATTR_VARIANT_PACK_UNIQUE_IDS = 1000, CUDNN_ATTR_VARIANT_PACK_DATA_POINTERS = 1001, CUDNN_ATTR_VARIANT_PACK_INTERMEDIATES = 1002, CUDNN_ATTR_VARIANT_PACK_WORKSPACE = 1003, CUDNN_ATTR_LAYOUT_INFO_TENSOR_UID = 1100, CUDNN_ATTR_LAYOUT_INFO_TYPES = 1101, CUDNN_ATTR_KNOB_INFO_TYPE = 1200, CUDNN_ATTR_KNOB_INFO_MAXIMUM_VALUE = 1201, CUDNN_ATTR_KNOB_INFO_MINIMUM_VALUE = 1202, CUDNN_ATTR_KNOB_INFO_STRIDE = 1203, CUDNN_ATTR_ENGINE_OPERATION_GRAPH = 1300, CUDNN_ATTR_ENGINE_GLOBAL_INDEX = 1301, CUDNN_ATTR_ENGINE_KNOB_INFO = 1302, CUDNN_ATTR_ENGINE_NUMERICAL_NOTE = 1303, CUDNN_ATTR_ENGINE_LAYOUT_INFO = 1304, CUDNN_ATTR_ENGINE_BEHAVIOR_NOTE = 1305, CUDNN_ATTR_MATMUL_COMP_TYPE = 1500, CUDNN_ATTR_MATMUL_PADDING_VALUE = 1501, CUDNN_ATTR_OPERATION_MATMUL_ADESC = 1520, CUDNN_ATTR_OPERATION_MATMUL_BDESC = 1521, CUDNN_ATTR_OPERATION_MATMUL_CDESC = 1522, CUDNN_ATTR_OPERATION_MATMUL_DESC = 1523, CUDNN_ATTR_OPERATION_MATMUL_IRREGULARLY_STRIDED_BATCH_COUNT = 1524, CUDNN_ATTR_OPERATION_MATMUL_GEMM_M_OVERRIDE_DESC = 1525, CUDNN_ATTR_OPERATION_MATMUL_GEMM_N_OVERRIDE_DESC = 1526, CUDNN_ATTR_OPERATION_MATMUL_GEMM_K_OVERRIDE_DESC = 1527, CUDNN_ATTR_REDUCTION_OPERATOR = 1600, CUDNN_ATTR_REDUCTION_COMP_TYPE = 1601, CUDNN_ATTR_OPERATION_REDUCTION_XDESC = 1610, CUDNN_ATTR_OPERATION_REDUCTION_YDESC = 1611, CUDNN_ATTR_OPERATION_REDUCTION_DESC = 1612, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_MATH_PREC = 1620, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_MEAN_DESC = 1621, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_INVSTD_DESC = 1622, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_BN_SCALE_DESC = 1623, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_X_DESC = 1624, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DY_DESC = 1625, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DBN_SCALE_DESC = 1626, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_DBN_BIAS_DESC = 1627, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_DY_SCALE_DESC = 1628, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_X_SCALE_DESC = 1629, CUDNN_ATTR_OPERATION_BN_BWD_WEIGHTS_EQ_BIAS = 1630, CUDNN_ATTR_RESAMPLE_MODE = 1700, CUDNN_ATTR_RESAMPLE_COMP_TYPE = 1701, CUDNN_ATTR_RESAMPLE_SPATIAL_DIMS = 1702, CUDNN_ATTR_RESAMPLE_POST_PADDINGS = 1703, CUDNN_ATTR_RESAMPLE_PRE_PADDINGS = 1704, CUDNN_ATTR_RESAMPLE_STRIDES = 1705, CUDNN_ATTR_RESAMPLE_WINDOW_DIMS = 1706, CUDNN_ATTR_RESAMPLE_NAN_PROPAGATION = 1707, CUDNN_ATTR_RESAMPLE_PADDING_MODE = 1708, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_XDESC = 1710, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_YDESC = 1711, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_IDXDESC = 1712, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_ALPHA = 1713, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_BETA = 1714, CUDNN_ATTR_OPERATION_RESAMPLE_FWD_DESC = 1716, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DXDESC = 1720, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DYDESC = 1721, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_IDXDESC = 1722, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_ALPHA = 1723, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_BETA = 1724, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_DESC = 1725, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_XDESC = 1726, CUDNN_ATTR_OPERATION_RESAMPLE_BWD_YDESC = 1727, CUDNN_ATTR_OPERATION_CONCAT_AXIS = 1800, CUDNN_ATTR_OPERATION_CONCAT_INPUT_DESCS = 1801, CUDNN_ATTR_OPERATION_CONCAT_INPLACE_INDEX = 1802, CUDNN_ATTR_OPERATION_CONCAT_OUTPUT_DESC = 1803, CUDNN_ATTR_OPERATION_SIGNAL_MODE = 1900, CUDNN_ATTR_OPERATION_SIGNAL_FLAGDESC = 1901, CUDNN_ATTR_OPERATION_SIGNAL_VALUE = 1902, CUDNN_ATTR_OPERATION_SIGNAL_XDESC = 1903, CUDNN_ATTR_OPERATION_SIGNAL_YDESC = 1904, CUDNN_ATTR_OPERATION_NORM_FWD_MODE = 2000, CUDNN_ATTR_OPERATION_NORM_FWD_PHASE = 2001, CUDNN_ATTR_OPERATION_NORM_FWD_XDESC = 2002, CUDNN_ATTR_OPERATION_NORM_FWD_MEAN_DESC = 2003, CUDNN_ATTR_OPERATION_NORM_FWD_INV_VARIANCE_DESC = 2004, CUDNN_ATTR_OPERATION_NORM_FWD_SCALE_DESC = 2005, CUDNN_ATTR_OPERATION_NORM_FWD_BIAS_DESC = 2006, CUDNN_ATTR_OPERATION_NORM_FWD_EPSILON_DESC = 2007, CUDNN_ATTR_OPERATION_NORM_FWD_EXP_AVG_FACTOR_DESC = 2008, CUDNN_ATTR_OPERATION_NORM_FWD_INPUT_RUNNING_MEAN_DESC = 2009, CUDNN_ATTR_OPERATION_NORM_FWD_INPUT_RUNNING_VAR_DESC = 2010, CUDNN_ATTR_OPERATION_NORM_FWD_OUTPUT_RUNNING_MEAN_DESC = 2011, CUDNN_ATTR_OPERATION_NORM_FWD_OUTPUT_RUNNING_VAR_DESC = 2012, CUDNN_ATTR_OPERATION_NORM_FWD_YDESC = 2013, CUDNN_ATTR_OPERATION_NORM_FWD_PEER_STAT_DESCS = 2014, CUDNN_ATTR_OPERATION_NORM_BWD_MODE = 2100, CUDNN_ATTR_OPERATION_NORM_BWD_XDESC = 2101, CUDNN_ATTR_OPERATION_NORM_BWD_MEAN_DESC = 2102, CUDNN_ATTR_OPERATION_NORM_BWD_INV_VARIANCE_DESC = 2103, CUDNN_ATTR_OPERATION_NORM_BWD_DYDESC = 2104, CUDNN_ATTR_OPERATION_NORM_BWD_SCALE_DESC = 2105, CUDNN_ATTR_OPERATION_NORM_BWD_EPSILON_DESC = 2106, CUDNN_ATTR_OPERATION_NORM_BWD_DSCALE_DESC = 2107, CUDNN_ATTR_OPERATION_NORM_BWD_DBIAS_DESC = 2108, CUDNN_ATTR_OPERATION_NORM_BWD_DXDESC = 2109, CUDNN_ATTR_OPERATION_NORM_BWD_PEER_STAT_DESCS = 2110, CUDNN_ATTR_OPERATION_RESHAPE_XDESC = 2200, CUDNN_ATTR_OPERATION_RESHAPE_YDESC = 2201, CUDNN_ATTR_RNG_DISTRIBUTION = 2300, CUDNN_ATTR_RNG_NORMAL_DIST_MEAN = 2301, CUDNN_ATTR_RNG_NORMAL_DIST_STANDARD_DEVIATION = 2302, CUDNN_ATTR_RNG_UNIFORM_DIST_MAXIMUM = 2303, CUDNN_ATTR_RNG_UNIFORM_DIST_MINIMUM = 2304, CUDNN_ATTR_RNG_BERNOULLI_DIST_PROBABILITY = 2305, CUDNN_ATTR_OPERATION_RNG_YDESC = 2310, CUDNN_ATTR_OPERATION_RNG_SEED = 2311, CUDNN_ATTR_OPERATION_RNG_DESC = 2312, CUDNN_ATTR_OPERATION_RNG_OFFSET_DESC = 2313, } cudnnBackendAttributeName_t;
9.1.1.2. cudnnBackendAttributeType_t
typedef enum { CUDNN_TYPE_HANDLE = 0, CUDNN_TYPE_DATA_TYPE, CUDNN_TYPE_BOOLEAN, CUDNN_TYPE_INT64, CUDNN_TYPE_FLOAT, CUDNN_TYPE_DOUBLE, CUDNN_TYPE_VOID_PTR, CUDNN_TYPE_CONVOLUTION_MODE, CUDNN_TYPE_HEUR_MODE, CUDNN_TYPE_KNOB_TYPE, CUDNN_TYPE_NAN_PROPOGATION, CUDNN_TYPE_NUMERICAL_NOTE, CUDNN_TYPE_LAYOUT_TYPE, CUDNN_TYPE_ATTRIB_NAME, CUDNN_TYPE_POINTWISE_MODE, CUDNN_TYPE_BACKEND_DESCRIPTOR, CUDNN_TYPE_GENSTATS_MODE, CUDNN_TYPE_BN_FINALIZE_STATS_MODE, CUDNN_TYPE_REDUCTION_OPERATOR_TYPE, CUDNN_TYPE_BEHAVIOR_NOTE, CUDNN_TYPE_TENSOR_REORDERING_MODE, CUDNN_TYPE_RESAMPLE_MODE, CUDNN_TYPE_PADDING_MODE, CUDNN_TYPE_INT32, CUDNN_TYPE_CHAR, CUDNN_TYPE_SIGNAL_MODE, CUDNN_TYPE_FRACTION, CUDNN_TYPE_NORM_MODE, CUDNN_TYPE_NORM_FWD_PHASE, CUDNN_TYPE_RNG_DISTRIBUTION } cudnnBackendAttributeType_t;
| cudnnBackendAttributeType_t | Attribute type |
|---|---|
| CUDNN_TYPE_HANDLE | cudnnHandle_t |
| CUDNN_TYPE_DATA_TYPE | cudnnDataType_t |
| CUDNN_TYPE_BOOLEAN | bool |
| CUDNN_TYPE_INT64 | int64_t |
| CUDNN_TYPE_FLOAT | float |
| CUDNN_TYPE_DOUBLE | double |
| CUDNN_TYPE_VOID_PTR | void * |
| CUDNN_TYPE_CONVOLUTION_MODE | cudnnConvolutionMode_t |
| CUDNN_TYPE_HEUR_MODE | cudnnBackendHeurMode_t |
| CUDNN_TYPE_KNOB_TYPE | cudnnBackendKnobType_t |
| CUDNN_TYPE_NAN_PROPOGATION | cudnnNanPropagation_t |
| CUDNN_TYPE_NUMERICAL_NOTE | cudnnBackendNumericalNote_t |
| CUDNN_TYPE_LAYOUT_TYPE | cudnnBackendLayoutType_t |
| CUDNN_TYPE_ATTRIB_NAME | cudnnBackendAttributeName_t |
| CUDNN_TYPE_POINTWISE_MODE | cudnnPointwiseMode_t |
| CUDNN_TYPE_BACKEND_DESCRIPTOR | cudnnBackendDescriptor_t |
| CUDNN_TYPE_GENSTATS_MODE | cudnnGenStatsMode_t |
| CUDNN_TYPE_BN_FINALIZE_STATS_MODE | cudnnBnFinalizeStatsMode_t |
| CUDNN_TYPE_REDUCTION_OPERATOR_TYPE | cudnnReduceTensorOp_t |
| CUDNN_TYPE_BEHAVIOR_NOTE | cudnnBackendBehaviorNote_t |
| CUDNN_TYPE_TENSOR_REORDERING_MODE | cudnnBackendTensorReordering_t |
| CUDNN_TYPE_RESAMPLE_MODE | cudnnResampleMode_t |
| CUDNN_TYPE_PADDING_MODE | cudnnPaddingMode_t |
| CUDNN_TYPE_INT32 | int32_t |
| CUDNN_TYPE_CHAR | char |
| CUDNN_TYPE_SIGNAL_MODE | cudnnSignalMode_t |
| CUDNN_TYPE_FRACTION | cudnnFraction_t |
| CUDNN_TYPE_NORM_MODE | cudnnBackendNormMode_t |
| CUDNN_TYPE_NORM_FWD_PHASE | cudnnBackendNormFwdPhase_t |
| CUDNN_TYPE_RNG_DISTRIBUTION | cudnnRngDistribution_t |
9.1.1.3. cudnnBackendBehaviorNote_t
typedef enum { CUDNN_BEHAVIOR_NOTE_RUNTIME_COMPILATION = 0, CUDNN_BEHAVIOR_NOTE_REQUIRES_FILTER_INT8x32_REORDER = 1, CUDNN_BEHAVIOR_NOTE_REQUIRES_BIAS_INT8x32_REORDER = 2, CUDNN_BEHAVIOR_NOTE_TYPE_COUNT, } cudnnBackendBehaviorNote_t;
9.1.1.4. cudnnBackendDescriptorType_t
typedef enum { CUDNN_BACKEND_POINTWISE_DESCRIPTOR = 0, CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR, CUDNN_BACKEND_ENGINE_DESCRIPTOR, CUDNN_BACKEND_ENGINECFG_DESCRIPTOR, CUDNN_BACKEND_ENGINEHEUR_DESCRIPTOR, CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR, CUDNN_BACKEND_INTERMEDIATE_INFO_DESCRIPTOR, CUDNN_BACKEND_KNOB_CHOICE_DESCRIPTOR, CUDNN_BACKEND_KNOB_INFO_DESCRIPTOR, CUDNN_BACKEND_LAYOUT_INFO_DESCRIPTOR, CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR, CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR, CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR, CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR, CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR, CUDNN_BACKEND_OPERATIONGRAPH_DESCRIPTOR, CUDNN_BACKEND_VARIANT_PACK_DESCRIPTOR, CUDNN_BACKEND_TENSOR_DESCRIPTOR, CUDNN_BACKEND_MATMUL_DESCRIPTOR, CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR, CUDNN_BACKEND_OPERATION_BN_FINALIZE_STATISTICS_DESCRIPTOR, CUDNN_BACKEND_REDUCTION_DESCRIPTOR, CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR, CUDNN_BACKEND_OPERATION_BN_BWD_WEIGHTS_DESCRIPTOR, CUDNN_BACKEND_RESAMPLE_DESCRIPTOR, CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR, CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR, CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR, CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR, CUDNN_BACKEND_OPERATION_NORM_FORWARD_DESCRIPTOR, CUDNN_BACKEND_OPERATION_NORM_BACKWARD_DESCRIPTOR, } cudnnBackendDescriptorType_t;
9.1.1.5. cudnnBackendHeurMode_t
typedef enum { CUDNN_HEUR_MODE_INSTANT = 0, CUDNN_HEUR_MODE_B = 1, CUDNN_HEUR_MODE_FALLBACK = 2, CUDNN_HEUR_MODE_A = 3 }
Values
-
CUDNN_HEUR_MODE_A provides the exact same functionality as CUDNN_HEUR_MODE_INSTANT. The purpose of this renaming is to better match the naming of CUDNN_HEUR_MODE_B. Consider the use of CUDNN_HEUR_MODE_INSTANT as deprecated; instead, use CUDNN_HEUR_MODE_A.
CUDNN_HEUR_MODE_A utilizes a decision tree heuristic which provides optimal inference time on the CPU in comparison to CUDNN_HEUR_MODE_B.
-
Can utilize the neural net based heuristics to improve generalization performance compared to CUDNN_HEUR_MODE_INSTANT. In cases where the neural net is utilized, inference time on the CPU will be increased by 10-100x compared to CUDNN_HEUR_MODE_INSTANT. These neural net heuristics are not supported for any of the following cases:
- 3-D convolutions
- Grouped convolutions (groupCount larger than 1)
- Dilated convolutions (any dilation for any spatial dimension larger than 1)
Further, the neural net is only enabled on x86 platforms when cuDNN is run on an A100 GPU. In cases where the neural net is not supported, CUDNN_HEUR_MODE_B will also fall back to CUDNN_HEUR_MODE_INSTANT. CUDNN_HEUR_MODE_B will fall back to CUDNN_HEUR_MODE_INSTANT in cases where the overhead of CUDNN_HEUR_MODE_B is projected to reduce overall network performance.
- This heuristic mode is intended to be used for finding fallback options which provide functional support (without any expectation of providing optimal GPU performance).
9.1.1.6. cudnnBackendKnobType_t
typedef enum { CUDNN_KNOB_TYPE_SPLIT_K = 0, CUDNN_KNOB_TYPE_SWIZZLE = 1, CUDNN_KNOB_TYPE_TILE_SIZE = 2, CUDNN_KNOB_TYPE_USE_TEX = 3, CUDNN_KNOB_TYPE_EDGE = 4, CUDNN_KNOB_TYPE_KBLOCK = 5, CUDNN_KNOB_TYPE_LDGA = 6, CUDNN_KNOB_TYPE_LDGB = 7, CUDNN_KNOB_TYPE_CHUNK_K = 8, CUDNN_KNOB_TYPE_SPLIT_H = 9, CUDNN_KNOB_TYPE_WINO_TILE = 10, CUDNN_KNOB_TYPE_MULTIPLY = 11, CUDNN_KNOB_TYPE_SPLIT_K_BUF = 12, CUDNN_KNOB_TYPE_TILEK = 13, CUDNN_KNOB_TYPE_STAGES = 14, CUDNN_KNOB_TYPE_REDUCTION_MODE = 15, CUDNN_KNOB_TYPE_CTA_SPLIT_K_MODE = 16, CUDNN_KNOB_TYPE_SPLIT_K_SLC = 17, CUDNN_KNOB_TYPE_IDX_MODE = 18, CUDNN_KNOB_TYPE_SLICED = 19, CUDNN_KNOB_TYPE_SPLIT_RS = 20, CUDNN_KNOB_TYPE_SINGLEBUFFER = 21, CUDNN_KNOB_TYPE_LDGC = 22, CUDNN_KNOB_TYPE_SPECFILT = 23, CUDNN_KNOB_TYPE_KERNEL_CFG = 24, CUDNN_KNOB_TYPE_WORKSPACE = 25, CUDNN_KNOB_TYPE_COUNTS = 26, } cudnnBackendKnobType_t;
9.1.1.7. cudnnBackendLayoutType_t
typedef enum { CUDNN_LAYOUT_TYPE_PREFERRED_NCHW = 0, CUDNN_LAYOUT_TYPE_PREFERRED_NHWC = 1, CUDNN_LAYOUT_TYPE_PREFERRED_PAD4CK = 2, CUDNN_LAYOUT_TYPE_PREFERRED_PAD8CK = 3, CUDNN_LAYOUT_TYPE_COUNT = 4, } cudnnBackendLayoutType_t;
9.1.1.8. cudnnBackendNormFwdPhase_t
typedef enum { CUDNN_NORM_FWD_INFERENCE = 0, CUDNN_NORM_FWD_TRAINING = 1, } cudnnBackendNormFwdPhase_t;
9.1.1.9. cudnnBackendNormMode_t
- The definition of layer normalization can be found in the Layer Normalization paper.
- The definition of instance normalization can be found in the Instance Normalization: The Missing Ingredient for Fast Stylization paper.
- The definition of batch normalization can be found in the Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift paper.
CUDNN_GROUP_NORM is not yet supported. If you try to use it, cuDNN returns a CUDNN_STATUS_INTERNAL_ERROR error.
typedef enum { CUDNN_LAYER_NORM = 0, CUDNN_INSTANCE_NORM = 1, CUDNN_BATCH_NORM = 2, CUDNN_GROUP_NORM = 3, } cudnnBackendNormMode_t;
9.1.1.10. cudnnBackendNumericalNote_t
typedef enum { CUDNN_NUMERICAL_NOTE_TENSOR_CORE = 0, CUDNN_NUMERICAL_NOTE_DOWN_CONVERT_INPUTS, CUDNN_NUMERICAL_NOTE_REDUCED_PRECISION_REDUCTION, CUDNN_NUMERICAL_NOTE_FFT, CUDNN_NUMERICAL_NOTE_NONDETERMINISTIC, CUDNN_NUMERICAL_NOTE_WINOGRAD, CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_4x4, CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_6x6, CUDNN_NUMERICAL_NOTE_WINOGRAD_TILE_13x13, CUDNN_NUMERICAL_NOTE_TYPE_COUNT, } cudnnBackendNumericalNote_t;
9.1.1.11. cudnnBackendTensorReordering_t
typedef enum { CUDNN_TENSOR_REORDERING_NONE = 0, CUDNN_TENSOR_REORDERING_INT8x32 = 1, CUDNN_TENSOR_REORDERING_F16x16 = 2, } cudnnBackendTensorReordering_t;
9.1.1.12. cudnnBnFinalizeStatsMode_t
typedef enum { CUDNN_BN_FINALIZE_STATISTICS_TRAINING = 0, CUDNN_BN_FINALIZE_STATISTICS_INFERENCE = 1, } cudnnBnFinalizeStatsMode_t;
| BN Statistics Mode | Description |
|---|---|
| CUDNN_BN_FINALIZE_STATISTICS_TRAINING |
Computes the equivalent scale and bias from ySum, ySqSum and learned scale, bias. Optionally, update running statistics and generate saved stats for interoperability with cudnnBatchNormalizationBackward(), cudnnBatchNormalizationBackwardEx(), or cudnnNormalizationBackward(). |
| CUDNN_BN_FINALIZE_STATISTICS_INFERENCE | Computes the equivalent scale and bias from the learned running statistics and the learned scale, bias. |
9.1.1.13. cudnnFraction_t
typedef struct cudnnFractionStruct { int64_t numerator; int64_t denominator; } cudnnFraction_t;
9.1.1.14. cudnnGenStatsMode_t
9.1.1.15. cudnnPaddingMode_t
typedef enum { CUDNN_ZERO_PAD = 0, CUDNN_NEG_INF_PAD = 1, CUDNN_EDGE_VAL_PAD = 2, } cudnnPaddingMode_t;
9.1.1.16. cudnnPointwiseMode_t
Values
- In this mode, a pointwise addition between two tensors is computed.
- In this mode, a pointwise addition between the first tensor and the square of the second tensor is computed.
- In this mode, a pointwise true division of the first tensor by second tensor is computed.
- In this mode, a pointwise maximum is taken between two tensors.
- In this mode, a pointwise minimum is taken between two tensors.
- In this mode, a pointwise floating-point remainder of the first tensor's division by the second tensor is computed.
- In this mode, a pointwise multiplication between two tensors is computed.
- In this mode, a pointwise value from the first tensor to the power of the second tensor is computed.
- In this mode, a pointwise subtraction between two tensors is computed.
- In this mode, a pointwise absolute value of the input tensor is computed.
- In this mode, a pointwise ceiling of the input tensor is computed.
- In this mode, a pointwise trigonometric cosine of the input tensor is computed.
- In this mode, a pointwise exponential of the input tensor is computed.
- In this mode, a pointwise floor of the input tensor is computed.
- In this mode, a pointwise natural logarithm of the input tensor is computed.
- In this mode, a pointwise numerical negative of the input tensor is computed.
- In this mode, a pointwise reciprocal of the square root of the input tensor is computed.
- In this mode, a pointwise trigonometric sine of the input tensor is computed.
- In this mode, a pointwise square root of the input tensor is computed.
- In this mode, a pointwise trigonometric tangent of the input tensor is computed.
- In this mode, a pointwise Error Function is computed.
- In this mode, no computation is performed. As with other pointwise modes, this mode provides implicit conversions by specifying the data type of the input tensor as one type, and the data type of the output tensor as another.
- In this mode, a pointwise rectified linear activation function of the input tensor is computed.
- In this mode, a pointwise tanh activation function of the input tensor is computed.
- In this mode, a pointwise sigmoid activation function of the input tensor is computed.
- In this mode, a pointwise Exponential Linear Unit activation function of the input tensor is computed.
- In this mode, a pointwise Gaussian Error Linear Unit activation function of the input tensor is computed.
- In this mode, a pointwise softplus activation function of the input tensor is computed.
- In this mode, a pointwise swish activation function of the input tensor is computed.
- In this mode, a pointwise tanh approximation of the Gaussian Error Linear Unit activation
function of the input tensor is computed. The tanh GELU approximation is
computed as
For more information, refer to the GAUSSIAN ERROR LINEAR UNIT (GELUS) paper.
- In this mode, a pointwise first derivative of rectified linear activation of the input tensor is computed.
- In this mode, a pointwise first derivative of tanh activation of the input tensor is computed.
- In this mode, a pointwise first derivative of sigmoid activation of the input tensor is computed.
- In this mode, a pointwise first derivative of Exponential Linear Unit activation of the input tensor is computed.
- In this mode, a pointwise first derivative of Gaussian Error Linear Unit activation of the input tensor is computed.
- In this mode, a pointwise first derivative of softplus activation of the input tensor is computed.
- In this mode, a pointwise first derivative of swish activation of the input tensor is computed.
- In this mode, a pointwise first derivative of the tanh approximation of the Gaussian Error Linear Unit activation of the input tensor is computed. This is computed as where is and is .
- In this mode, a pointwise truth value of the first tensor equal to the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor not equal to the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor greater than the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor greater than equal to the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor less than the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor less than equal to the second tensor is computed.
- In this mode, a pointwise truth value of the first tensor logical AND second tensor is computed.
- In this mode, a pointwise truth value of the first tensor logical OR second tensor is computed.
- In this mode, a pointwise truth value of input tensor's logical NOT is computed.
- In this mode, a pointwise index value of the input tensor is generated along a given axis.
- In this mode, a pointwise value is selected amongst two input tensors based on a given predicate tensor.
- In this mode, a pointwise reciprocal of the input tensor is computed. In other words, for every element x in the input tensor, 1/x is computed.
9.1.1.17. cudnnResampleMode_t
typedef enum { CUDNN_RESAMPLE_NEAREST = 0, CUDNN_RESAMPLE_BILINEAR = 1, CUDNN_RESAMPLE_AVGPOOL = 2, CUDNN_RESAMPLE_AVGPOOL_INCLUDE_PADDING = 2, CUDNN_RESAMPLE_AVGPOOL_EXCLUDE_PADDING = 4, CUDNN_RESAMPLE_MAXPOOL = 3, } cudnnResampleMode_t;
9.1.1.18. cudnnRngDistribution_t
typedef enum { CUDNN_RNG_DISTRIBUTION_BERNOULLI, CUDNN_RNG_DISTRIBUTION_UNIFORM, CUDNN_RNG_DISTRIBUTION_NORMAL, } cudnnRngDistribution_t;
Values
- In this mode, the bernoulli distribution is used for the random number generation. The attribute CUDNN_ATTR_RNG_BERNOULLI_DIST_PROBABILITY can be used to specify the probability of generating 1’s.
- In this mode, the normal distribution is used for the random number generation. The attribute CUDNN_ATTR_RNG_NORMAL_DIST_MEAN and CUDNN_ATTR_RNG_NORMAL_DIST_STANDARD_DEVIATION can be used to specify the mean and standard deviation of the random number generator.
9.1.1.19. cudnnSignalMode_t
typedef enum { CUDNN_SIGNAL_SET = 0, CUDNN_SIGNAL_WAIT = 1, } cudnnSignalMode_t;
9.1.2. Data Types Found In cudnn_backend.h
9.1.2.1. cudnnBackendDescriptor_t
Attributes of a descriptor can be set using cudnnBackendSetAttribute(). After all required attributes of a descriptor are set, the descriptor can be finalized by cudnnBackendFinalize(). From a finalized descriptor, one can query its queryable attributes using cudnnBackendGetAttribute(). Finally, the memory allocated for a descriptor can be freed using cudnnBackendDestroyDescriptor().
9.2. API Functions
9.2.1. cudnnBackendCreateDescriptor()
cudnnStatus_t cudnnBackendCreateDescriptor(cudnnBackendDescriptorType_t descriptorType, cudnnBackendDescriptor_t *descriptor)
Parameters
- Input. One among the enumerated cudnnBackendDescriptorType_t.
- Input. Pointer to an instance of cudnnBackendDescriptor_t to be created.
Returns
- The creation was successful.
- Creating a descriptor of a given type is not supported.
- The memory allocation failed.
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.2. cudnnBackendDestroyDescriptor()
cudnnStatus_t cudnnBackendDestroyDescriptor(cudnnBackendDescriptor_tdescriptor)
Parameters
- Input. Instance of cudnnBackendDescriptor_t previously created by cudnnBackendCreateDescriptor().
Returns
- The memory was destroyed successfully.
- The destruction of memory failed.
- The descriptor was altered between the Create and Destroy Descriptor.
- The value pointed by the descriptor will be Undefined after the memory is free and done.
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.3. cudnnBackendExecute()
cudnnStatus_ cudnnBackendExecute(cudnnHandle_t handle, cudnnBackendDescriptor_t executionPlan, cudnnBackendDescriptor_t varianPack)
Parameters
- Input. Pointer to the cuDNN handle to be destroyed.
- Input. Pointer to the finalized VariantPack
consisting of:
- Data pointer for each non-virtual pointer of the operation set in the execution plan.
- Pointer to user-allocated workspace in global memory at least as large as the size queried from CUDNN_BACKEND_.
Returns
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.4. cudnnBackendFinalize()
cudnnStatus_t cudnnbBackendFinalize(cudnnBackendDescriptor descriptor)
cudnnBackendFinalize() also checks all the attributes set between the create/initialization and finalize phase. If successful, cudnnBackendFinalize() returns CUDNN_STATUS_SUCCESS and the finalized state of the descriptor is set to true. In this state, setting attributes using cudnnBackendSetAttribute() is not allowed. Getting attributes using cudnnBackendGetAttribute() is only allowed when the finalized state of the descriptor is true.
Returns
- The descriptor was finalized successfully.
- Invalid descriptor attribute values or combination thereof is encountered.
- Descriptor attribute values or combinations therefore not supported by the current version of cuDNN are encountered.
- Some internal errors are encountered.
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.5. cudnnBackendGetAttribute()
cudnnStatus_t cudnnBackendGetAttribute(
cudnnBackendDescriptor_t descriptor,
cudnnBackendAttributeName_t attributeName,
cudnnBackendAttributeType_t attributeType,
int64_t requestedElementCount,
int64_t *elementCount,
void *arrayOfElements);
Parameters
- Input. Instance of cudnnBackendDescriptor_t whose attribute the user wants to retrieve.
- Input. The name of the attribute being get from the on the descriptor.
- Input. The type of attribute.
- Input. Number of elements to output to arrayOfElements.
- Input. Output pointer for the number of elements the descriptor attribute has. Note that cudnnBackendGetAttribute() will only write the least of this and requestedElementCount elements to arrayOfElements.
- Input. Array of elements of the datatype of the attributeType. The datatype of the attributeType is listed in the mapping table of cudnnBackendAttributeType_t.
Returns
- The attributeName was given to the descriptor successfully.
- One or more invalid or inconsistent argument values were encountered.
Some examples:
- attributeName is not a valid attribute for the descriptor.
- attributeType is not one of the valid types for the attribute.
- The descriptor has not been successfully finalized using cudnnBackendFinalize().
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.6. cudnnBackendInitialize()
cudnnStatus_t cudnnBackendInitialize(cudnnBackendDescriptor_t descriptor, cudnnBackendDescriptorType_t descriptorType, size_t sizeInBytes)
Parameters
- Input. Instance of cudnnBackendDescriptor_t to be initialized.
- Input. Enumerated value for the type of cuDNN backend descriptor.
- Input. Size of memory pointed to by descriptor.
Returns
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.2.7. cudnnBackendSetAttribute()
cudnnStatus_t cudnnBackendSetAttribute(
cudnnBackendDescriptor_t descriptor,
cudnnBackendAttributeName_t attributeName,
cudnnBackendAttributeType_t attributeType,
int64_t elementCount,
void *arrayOfElements);
Parameters
- Input. Instance of cudnnBackendDescriptor_t whose attribute is being set.
- Input. The name of the attribute being set on the descriptor.
- Input. The type of attribute.
- Input. Number of elements being set.
- Input. The starting location for an array from where to read the values from. The elements of the array are expected to be of the datatype of the attributeType. The datatype of the attributeType is listed in the mapping table of cudnnBackendAttributeType_t.
Returns
- The attributeName was set to the descriptor.
- The backend descriptor pointed to by the descriptor is already in the finalized state.
- The function is called with arguments that correspond to invalid values.
Some possible causes are:
- attributeName is not a settable attribute of descriptor
- attributeType is incorrect for this attributeName.
- elemCount value is unexpected.
- arrayOfElements contains values invalid for the attributeType.
- The value(s) to which the attributes are being set is not supported by the current version of cuDNN.
Additional return values depend on the arguments used as explained in the cuDNN Backend API.
9.3. Backend Descriptor Types
9.3.1. CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR
Attributes
- The compute type of the convolution operator.
- CUDNN_TYPE_DATA_TYPE; one element.
- Required attribute.
- Convolution or cross-correlation mode.
- CUDNN_TYPE_CONVOLUTION_MODE; one element.
- Required attribute.
- Filter dilation.
- CUDNN_TYPE_INT64; one or more, but at most CUDNN_MAX_DIMS elements.
- Required attribute.
- Filter stride.
- CUDNN_TYPE_INT64; one or more, but at most CUDNN_MAX_DIMS elements.
- Required attribute.
- Padding at the beginning of each spatial dimension.
- CUDNN_TYPE_INT64; one or more, but at most CUDNN_MAX_DIMS elements.
- Required attribute.
- Padding at the end of each spatial dimension.
- CUDNN_TYPE_INT64; one or more, but at most CUDNN_MAX_DIMS elements.
- Required attribute.
- The number of spatial dimensions in the convolution.
- CUDNN_TYPE_INT64, one element.
- Required attribute.
Finalization
- An elemCount argument for setting CUDNN_ATTR_CONVOLUTION_DILATIONS, CUDNN_ATTR_CONVOLUTION_FILTER_STRIDES, CUDNN_ATTR_CONVOLUTION_PRE_PADDINGS, and CUDNN_ATTR_CONVOLUTION_POST_PADDINGS is not equal to the value set for CUDNN_ATTR_CONVOLUTION_SPATIAL_DIMS.
- The descriptor was finalized successfully.
9.3.2. CUDNN_BACKEND_ENGINE_DESCRIPTOR
Attributes
- The operation graph to compute.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_OPERATIONGRAPH_DESCRIPTOR.
- Required attribute.
- The index for the engine.
- CUDNN_TYPE_INT64; one element.
- Valid values are between 0 and CUDNN_ATTR_OPERATIONGRAPH_ENGINE_GLOBAL_COUNT-1.
- Required attribute.
- The descriptors of performance knobs of the engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_KNOB_INFO_DESCRIPTOR.
- Read-only attribute.
- The numerical attributes of the engine.
- CUDNN_TYPE_NUMERICAL_NOTE; zero or more elements.
- Read-only attribute.
- The preferred tensor layouts of the engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_LAYOUT_INFO_DESCRIPTOR.
- Read-only attribute.
Finalization
- The descriptor was finalized successfully.
- The descriptor attribute set is not supported by the current version of
cuDNN. Some examples include:
- The value of CUDNN_ATTR_ENGINE_GLOBAL_INDEX is not in a valid range.
- The descriptor attribute set is inconsistent or in an unexpected state.
Some examples include:
- The operation graph descriptor set is not already finalized.
9.3.3. CUDNN_BACKEND_ENGINECFG_DESCRIPTOR
Attributes
- The backend engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR: one element, a backend descriptor of type CUDNN_BACKEND_ENGINE_DESCRIPTOR.
- Required attribute.
- The engine tuning knobs and choices.
- CUDNN_TYPE_BACKEND_DESCRIPTOR: zero or more elements, backend descriptors of type CUDNN_BACKEND_KNOB_CHOICE_DESCRIPTOR.
- Information of the computational intermediate of this engine config.
- CUDNN_TYPE_BACKEND_DESCRIPTOR: one element, a backend descriptor of type CUDNN_BACKEND_INTERMEDIATE_INFO_DESCRIPTOR.
- Read-only attribute.
- Currently unsupported. Placeholder for future implementation.
9.3.4. CUDNN_BACKEND_ENGINEHEUR_DESCRIPTOR
Attributes
- The operation graph for which heuristics result in a query.
- One element.
- Required attribute.
- The heuristic mode to query the result.
- CUDNN_TYPE_HEUR_MODE; one element.
- Required attribute.
- The result of the heuristics query.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; zero or more elements of descriptor type CUDNN_BACKEND_ENGINECFG_DESCRIPTOR.
- Get-only attribute.
9.3.5. CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR
Attributes
- A cuDNN handle.
- CUDNN_TYPE_HANDLE; one element.
- Required attribute.
- An engine configuration to execute.
- CUDNN_BACKEND_ENGINECFG_DESCRIPTOR; one element.
- Required attribute.
- Unique identifiers of intermediates to compute.
- CUDNN_TYPE_INT64; zero or more elements.
- Optional attribute. If set, the execution plan will only compute the specified intermediate and not any of the output tensors on the operation graph in the engine configuration.
- Unique identifiers of precomputed intermediates.
- CUDNN_TYPE_INT64; zero or more elements.
- Optional attribute. If set, the plan will expect and use pointers for each intermediate in the variant pack descriptor during execution.
- Not supported currently: placeholder for future implementation.
- The size of the workspace buffer required to execute this plan.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute.
- The JSON representation of the serialized execution plan. Serialization
and deserialization can be done by getting and setting this attribute,
respectively.
- CUDNN_TYPE_CHAR; many elements, the same amount as the size of a null-terminated string of the json representation of the execution plan.
9.3.6. CUDNN_BACKEND_INTERMEDIATE_INFO_DESCRIPTOR
This is a read-only descriptor. Users cannot set the descriptor attributes or finalize the descriptor. User query for a finalized descriptor from an engine config descriptor.
Attributes
- A unique identifier of the intermediate.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute.
- The required device memory size for the intermediate.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute.
- UID of tensors on which the intermediate depends.
- CUDNN_TYPE_INT64; zero or more elements.
- Read-only attribute.
- Placeholder for future implementation.
9.3.7. CUDNN_BACKEND_KNOB_CHOICE_DESCRIPTOR
9.3.8. CUDNN_BACKEND_KNOB_INFO_DESCRIPTOR
Attributes
- The type of the performance knob.
- CUDNN_TYPE_KNOB_TYPE: one element.
- Read-only attribute.
- The smallest valid value choice value for this knob.
- CUDNN_TYPE_INT64: one element.
- Read-only attribute.
- The largest valid choice value for this knob.
- CUDNN_TYPE_INT64: one element.
- Read-only attribute.
- The stride of valid choice values for this knob.
- CUDNN_TYPE_INT64: one element.
- Read-only attribute.
9.3.9. CUDNN_BACKEND_LAYOUT_INFO_DESCRIPTOR
Attributes
- The UID of the tensor.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute.
- The preferred layout of the tensor.
- CUDNN_TYPE_LAYOUT_TYPE: zero or more element cudnnBackendLayoutType_t.
- Read-only attribute.
9.3.10. CUDNN_BACKEND_MATMUL_DESCRIPTOR
9.3.11. CUDNN_BACKEND_OPERATION_CONCAT_DESCRIPTOR
This operation also supports an in-place mode, where one of the input tensors is already assumed to be at the correct location in the output tensor, that is, they share the same device buffer.
Attributes
- The dimension which tensors are being concatenated over.
- Type: CUDNN_TYPE_INT64
- Required attribute.
- A vector of input tensor descriptors, which are concatenated in the same
order as provided in this vector.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one or more elements of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The index of input tensor in the vector of input tensor descriptors that
is already present in-place in the output tensor.
- Type: CUDNN_TYPE_INT64
- Optional attribute.
- The output tensor descriptor for the result from concatenation of input
tensors.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
Finalization
- Invalid or inconsistent attribute values are encountered. Some possible
causes:
- The tensors involved in the operation should have the same shape in all dimensions except the dimension that they are being concatenated over.
- The output tensor shape in the concatenating dimension should equal the sum of tensor shape of all input tensors in that same dimension.
- Concatenation axis should be a valid tensor dimension.
- If provided, the in-place input tensor index should be a valid index in the vector of input tensor descriptors.
- The descriptor was finalized successfully.
9.3.12. CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_DATA_DESCRIPTOR
Attributes
- The alpha value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required attribute.
- The beta value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required attribute.
- The convolution operator descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR.
- Required attribute.
- The convolution filter tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The image gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The response gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
Finalization
In finalizing the convolution operation, the tensor dimensions of the tensor DX, W, and DY are bound based on the same interpretations as the X, W, and Y tensor dimensions described in the CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR section.
9.3.13. CUDNN_BACKEND_OPERATION_CONVOLUTION_BACKWARD_FILTER_DESCRIPTOR
Attributes
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_ALPHA
- The alpha value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required attribute. Required to be set before finalization.
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_BETA
- The beta value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required attribute. Required to be set before finalization.
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_CONV_DESC
- The convolution operator descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR.
- Required attribute. Required to be set before finalization.
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DW
- The convolution filter tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute. Required to be set before finalization.
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_X
- The image gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute. Required to be set before finalization.
- CUDNN_ATTR_OPERATION_CONVOLUTION_BWD_FILTER_DY
- The response gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute. Required to be set before finalization.
Finalization
In finalizing the convolution operation, the tensor dimensions of the tensor X, DW, and DY are bound based on the same interpretations as the X, W, and Y tensor dimensions described in the CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR section.
9.3.14. CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR
Attributes
- The alpha value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required to be set before finalization.
- The beta value.
- CUDNN_TYPE_FLOAT or CUDNN_TYPE_DOUBLE; one or more elements.
- Required attribute.
- The convolution operator descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR.
- Required attribute.
- The convolution filter tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The image tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The response tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The number of spatial dimensions in the convolution.
- CUDNN_TYPE_INT64, one element.
- Required attribute.
Finalization
In finalizing the convolution operation, the tensor dimensions of the tensor X, W, and Y are bound based on the following interpretations:
The CUDNN_ATTR_CONVOLUTION_SPATIAL_DIMS attribute of CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_CONV_DESC is the number of spatial dimension of the convolution. The number of dimensions for tensor X, W, and Y must be larger than the number of spatial dimensions by 2 or 3 depending on how users choose to specify the convolution tensors.
- X tensor dimension and stride arrays are [N, GC, …]
- W tensor dimension and stride arrays are [KG, C, …]
- Y tensor dimension and stride arrays are [N, GK, …]
- X tensor dimension and stride arrays are [N, G, C, …]
- W tensor dimension and stride arrays are [G, K, C, …]
- Y tensor dimension and stride arrays are [N, G, K, …]
9.3.15. CUDNN_BACKEND_OPERATION_GEN_STATS_DESCRIPTOR
Attributes
- Sets the CUDNN_TYPE_GENSTATS_MODEof the operation. This attribute is required.
- The math precision of the computation. This attribute is required.
- Sets the descriptor for the input tensor X. This attribute is required.
- Sets the descriptor for the output tensor sum. This attribute is required.
- Sets the descriptor for the output tensor quadraticsum. This attribute is required.
9.3.16. CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR
- B indicates the batch size
- M is the number of rows of the matrix A
- K is the number or columns of the input matrix A (which is the same as the number of rows as the input matrix B)
- N is the number of columns of the input matrix B
If either the batch size of matrix A or B is set to 1, this indicates that the matrix will be broadcasted in the batch matmul. The resulting output matrix C will be a tensor of B x M x N.
The functionality of having multiple batch dimensions allows you to have layouts where the batch is not packed at a single stride. This case is especially seen in multi-head attention.
The addressing of the matrix elements from a given tensor can be specified using strides in the tensor descriptor. The strides represent the spacing between elements for each tensor dimension. Considering a matrix tensor A (B x M x N) with strides [BS, MS, NS], it indicates that the actual matrix element A[x, y, z] is found at (A_base_address + x * BS + y * MS + z * NS) from the linear memory space allocated for tensor A. With our current support, the innermost dimension must be packed, which requires either MS=1 or NS=1. Otherwise, there are no other technical constraints with regard to how the strides can be specified in a tensor descriptor as it should follow the aforementioned addressing formula and the strides as specified by the user.
- The most basic case is a fully packed row-major batch matrix, without any consideration of leading dimension or transpose. In this case, BS = M*N, MS = N and NS = 1.
- Matrix transpose can be achieved by exchanging the inner and outer dimensions
using strides. Namely:
- To specify a non-transposed matrix: BS = M*N, MS = N and NS = 1.
- To specify matrix transpose: BS = M*N, MS = 1 and NS = M.
- Leading dimension, a widely used concept in BLAS-like APIs, describes the inner dimension of the 2D array memory allocation (as opposed to the conceptual matrix dimension). It resembles the stride in a way that it defines the spacing between elements in the outer dimension. The most typical use cases where it shows difference from the matrix inner dimension is when the matrix is only part of the data in the allocated memory, addressing submatrices, or addressing matrices from an aligned memory allocation. Therefore, the leading dimension LDA in a column-major matrix A must satisfy LDA >= M, whereas in a row-major matrix A, it must satisfy LDA >= N. To transition from the leading dimension concept to using strides, this entails MS >= N and NS = 1 or MS = 1 and NS >= M. Keep in mind that, while these are some practical use cases, these inequalities do not impose technical constraints with respect to an acceptable specification of the strides.
Other commonly used GEMM features, such as alpha/beta output blending, can also be achieved using this matmul operation along with other pointwise operations.
Attributes
The commonly used GEMM operation can also be achieved using this matmul operation along with other pointwise operations for output blending.
- CUDNN_ATTR_OPERATION_MATMUL_ADESC
- The matrix A descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- CUDNN_ATTR_OPERATION_MATMUL_BDESC
- The matrix B descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- CUDNN_ATTR_OPERATION_MATMUL_CDESC
- The matrix C descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- CUDNN_ATTR_OPERATION_MATMUL_IRREGULARLY_STRIDED_BATCH_COUNT
- Number of matmul operations to perform in the batch on
matrix. Default = 1.
- CUDNN_TYPE_INT64; one element.
- Default value is 1.
- CUDNN_ATTR_OPERATION_MATMUL_GEMM_M_OVERRIDE_DESC
- The tensor gemm_m_override descriptor. Allows you to
override the M dimension of a batch matrix multiplication through this
tensor. It is only supported in pattern 6 in the runtime fusion engine
documented in Runtime Fusion Engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- CUDNN_ATTR_OPERATION_MATMUL_GEMM_N_OVERRIDE_DESC
- The tensor gemm_n_override descriptor. Allows you to
override the N dimension of a batch matrix multiplication through this
tensor. It is only supported in pattern 6 in the runtime fusion engine
documented in Runtime Fusion Engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- CUDNN_ATTR_OPERATION_MATMUL_GEMM_K_OVERRIDE_DESC
- The tensor gemm_k_override descriptor. Allows you to
override the K dimension of a batch matrix multiplication through this
tensor. It is only supported in pattern 6 in the runtime fusion engine
documented in Runtime Fusion Engine.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- CUDNN_ATTR_OPERATION_MATMUL_DESC
- The matmul operation descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_MATMUL_DESCRIPTOR.
- Required attribute.
Finalization
In the finalization of the matmul operation, the tensor dimensions of the matrices A, B and C will be checked to ensure that they satisfy the requirements of matrix multiplication:
- An unsupported attribute value was encountered. Some possible cause:
- If not all of the matrices A, B and C are at least rank-2 tensors.
- Invalid or inconsistent attribute values are encountered. Some possible
causes:
- The CUDNN_ATTR_OPERATION_MATMUL_IRREGULARLY_STRIDED_BATCH_COUNT specified is a negative value.
- The CUDNN_ATTR_OPERATION_MATMUL_IRREGULARLY_STRIDED_BATCH_COUNT and one or more of the batch sizes of the matrices A, B and C are not equal to one. That is to say there is a conflict where both irregularly and regularly strided batched matrix multiplication are specified, which is not a valid use case.
- The dimensions of the matrices A, B and C do not satisfy the requirements of matrix multiplication.
- The descriptor was finalized successfully.
9.3.17. CUDNN_BACKEND_OPERATION_NORM_BACKWARD_DESCRIPTOR
Limitations
- Does not support CUDNN_GROUP_NORM mode.
| CUDNN_ATTR_OPERATION_NORM_BWD_MODE | |||
|---|---|---|---|
| CUDNN_LAYER_NORM | CUDNN_INSTANCE_NORM | CUDNN_BATCH_NORM | CUDNN_GROUP_NORM |
| Yes | Yes | Yes | No |
Attributes
- Chooses the normalization mode for the norm backward operation.
- CUDNN_TYPE_NORM_MODE; one element.
- Required attribute.
- Input tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Saved mean input tensor descriptor for reusing the mean computed during
the forward computation of the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Saved inverse variance input tensor descriptor for reusing the mean
computed during the forward computation of the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Normalization scale descriptor. Note that the bias descriptor is not
necessary for the backward pass.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Scalar input tensor descriptor for the epsilon value. The epsilon values
are needed only if the saved mean and variances are not passed as inputs
to the operation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Scale gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Bias gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Input gradient tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Vector of tensor descriptors for the communication buffers used in
multi-GPU normalization. Typically, one buffer is provided for every GPU
in the node. This is an optional attribute only used for multi-GPU
tensor stats reduction.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one or more elements of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
9.3.18. CUDNN_BACKEND_OPERATION_NORM_FORWARD_DESCRIPTOR
Limitations
- Does not support CUDNN_GROUP_NORM mode.
- Batch norm only supports forward training and not forward inference.
| CUDNN_ATTR_OPERATION_NORM_FWD_PHASE | CUDNN_ATTR_OPERATION_NORM_FWD_MODE | |||
|---|---|---|---|---|
| CUDNN_LAYER_NORM | CUDNN_INSTANCE_NORM | CUDNN_BATCH_NORM | CUDNN_GROUP_NORM | |
| CUDNN_NORM_FWD_TRAINING | Yes | Yes | Yes | No |
| CUDNN_NORM_FWD_INFERENCE | Yes | Yes | No | No |
Attributes
- Chooses the normalization mode for the norm forward operation.
- CUDNN_TYPE_NORM_MODE; one element.
- Required attribute.
- Selects the training or inference phase for the norm forward
operation.
- CUDNN_TYPE_NORM_FWD_PHASE; one element.
- Required attribute.
- Input tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Estimated mean input tensor descriptor for the inference phase and the
computed mean output tensor descriptor for the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Estimated inverse variance input tensor descriptor for the inference
phase and the computed inverse variance output tensor descriptor for the
training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Normalization scale input tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Normalization bias input tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Scalar input tensor descriptor for the epsilon value used in
normalization calculation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Scalar input tensor descriptor for the exponential average factor value
used in running stats computation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Input running mean tensor descriptor for the running stats computation
in the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Input running variance tensor descriptor for the running stats
computation in the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Output running mean tensor descriptor for the running stats computation
in the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Output running variance tensor descriptor for the running stats
computation in the training phase.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Tensor descriptor for the output of the normalization operation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Vector of tensor descriptors for the communication buffers used in
multi-GPU normalization. Typically, one buffer is provided for every GPU
in the node. This is an optional attribute only used for multi-GPU
tensor stats reduction.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one or more elements of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
9.3.19. CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR
For a list of supported operations, refer to the cudnnPointwiseMode_t section.
For dual-input pointwise operations, broadcasting is assumed when a tensor dimension in one of the tensors is 1 while the other tensors corresponding dimension is not 1.
For three-input single-output pointwise operations, we do not support broadcasting in any tensor.
This opaque struct can be created with cudnnBackendCreateDescriptor() (CUDNN_BACKEND_OPERATION_POINTWISE_DESCRIPTOR).
Attributes
- Sets the descriptor containing the mathematical settings of the pointwise operation. This attribute is required.
- Sets the descriptor for the input tensor . This attribute is required for pointwise mathematical functions or activation forward propagation computations.
- If the operation requires 2 inputs, such as add or multiply, this attribute sets the second input tensor β. If the operation requires only 1 input, this field is not used and should not be set.
- Sets the descriptor for the output tensor . This attribute is required for pointwise mathematical functions or activation forward propagation computations.
- Sets the descriptor for the tensor T. This attribute is required for CUDNN_ATTR_POINTWISE_MODE set to CUDNN_POINTWISE_BINARY_SELECT and acts as the mask based on which the selection is done.
- Sets the scalar value in the equation. Can be in float or half. This attribute is optional, if not set, the default value is 1.0.
- If the operation requires two inputs, such as add or multiply, this attribute sets the scalar value in the equation. Can be in float or half. This attribute is optional, if not set, the default value is 1.0. If the operation requires only 1 input, this field is not used and should not be set.
- Sets the descriptor for the output tensor . This attribute is required for pointwise activation back propagation computations.
- Sets the descriptor for the input tensor . This attribute is required for pointwise activation back propagation computations.
Finalization
- Invalid or inconsistent attribute values are encountered. Some possible
causes are:
- The number of dimensions do not match between the input and output tensors.
- The input/output tensor dimensions do not agree with the above described automatic broadcasting rules.
- The descriptor was finalized successfully.
9.3.20. CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR
cudnnBackendCreateDescriptor(CUDNN_BACKEND_OPERATION_REDUCTION_DESCRIPTOR,
&desc);The output tensor Y should be the size as that of input tensor X, except dimension(s) where its size is 1.
Attributes
- The matrix X descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The matrix Y descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The reduction operation descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR one element of descriptor type CUDNN_BACKEND_REDUCTION_DESCRIPTOR.
- Required attribute.
Finalization
In the finalization of the reduction operation, the dimensions of tensors X and Y are checked to ensure that they satisfy the requirements of the reduction operation.
9.3.21. CUDNN_BACKEND_OPERATION_RESAMPLE_BWD_DESCRIPTOR
Attributes
- Resample operation descriptor
(CUDNN_BACKEND_RESAMPLE_DESCRIPTOR) instance
containing metadata about the operation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_RESAMPLE_DESCRIPTOR.
- Required attribute.
- Input tensor gradient descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Output tensor gradient descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Tensor containing maxpool or nearest neighbor resampling indices to be
used in backprop.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Sets the alpha parameter used in blending.
- CUDNN_TYPE_DOUBLE or CUDNN_TYPE_FLOAT; one element.
- Optional attribute.
- Default value is 1.0.
- Sets the beta parameter used in blending.
- CUDNN_TYPE_DOUBLE or CUDNN_TYPE_FLOAT; one element.
- Optional attribute.
- Default value is 0.0.
- Input tensor X descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Required for NCHW layout.
- Input tensor Y descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Required for NCHW layout
9.3.22. CUDNN_BACKEND_OPERATION_RESAMPLE_FWD_DESCRIPTOR
The resampling mode acts independently on each spatial dimension. For spatial dimension , the output spatial dimension size can be calculated by combining input image’s spatial dimension size , post padding , pre padding , stride , window size as: y_i = 1+(x_i + post_i + pre_i - w_i) / s_i
Attributes
- Resample operation descriptor
(CUDNN_BACKEND_RESAMPLE_DESCRIPTOR) instance
containing metadata about the operation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_RESAMPLE_DESCRIPTOR.
- Required attribute.
- Input tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Output tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Tensor containing maxpool or nearest neighbor resampling indices to be
used in backprop.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute (primarily used for use cases involving training).
- Sets the alpha parameter used in blending.
- CUDNN_TYPE_DOUBLE or CUDNN_TYPE_FLOAT; one element.
- Optional attribute.
- Default value is 1.0.
- Sets the beta parameter used in blending.
- CUDNN_TYPE_DOUBLE or CUDNN_TYPE_FLOAT; one element.
- Optional attribute.
- Default value is 0.0.
9.3.23. CUDNN_BACKEND_OPERATION_RNG_DESCRIPTOR
The random numbers are generated using a Philox random number generator (RNG) as described in Pytorch. The Philox object takes a seed value, a subsequence for starting the generation, and an offset for the subsequence. Seed and offset can be set by using the attributes. The subsequence is internally set, to ensure independent random numbers.
Attributes
- Rng descriptor
(CUDNN_BACKEND_RNG_DESCRIPTOR) instance containing
metadata about the operation.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_RNG_DESCRIPTOR.
- Required attribute.
- Output tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- Sets the seed for the random number generator which creates the
Y tensor. It can be a host INT64 value or a backend
descriptor binded to a value on the device. Only supports a tensor with
all dimensions set to 1 and all strides set to 1.
- CUDNN_TYPE_INT64; one element or CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
- Default value is 0.
- Tensor descriptor for the offset used in the RNG Philox object. Only
supports a tensor with all dimensions set to 1 and all strides set to
1.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
Finalization
- CUDNN_ATTR_OPERATION_RNG_OFFSET_DESC or CUDNN_ATTR_OPERATION_RNG_SEED do not have all dimensions and strides set to 1.
- The descriptor was finalized successfully.
9.3.24. CUDNN_BACKEND_OPERATION_SIGNAL_DESCRIPTOR
This operation, to connect to other nodes in the graph, also has a pass-through input tensor, which is not operated on and is just passed along to the output tensor. This mandatory pass-through input tensor helps in determining the predecessor node after which the signal operation should be executed. The optional output tensor helps in determining the successor node before which the signal execution should have completed. It is also guaranteed that for a non-virtual tensor as the output tensor, all writes for the tensor will have taken place before the signal value is updated by the operation.
Attributes
- The signaling mode to use.
- CUDNN_TYPE_SIGNAL_MODE;
- Required attribute.
- Flag tensor descriptor.
- Output tensor descriptor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The scalar value to compare or update the flag variable with.
- CUDNN_TYPE_INT64
- Required attribute.
- A pass-through input tensor to enable connecting this signal operation
to other nodes in the graph.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Required attribute.
- The output tensor for the pass-through input tensor.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element of descriptor type CUDNN_BACKEND_TENSOR_DESCRIPTOR.
- Optional attribute.
9.3.25. CUDNN_BACKEND_OPERATIONGRAPH_DESCRIPTOR
Attributes
- A cuDNN handle.
- CUDNN_TYPE_HANDLE; one element.
- Required attribute.
- Operation nodes to form the operation graph.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one or more elements of descriptor type CUDNN_BACKEND_OPERATION_*_DESCRIPTOR().
- Required attribute.
- The number of engines to support the operation graph.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute.
- The number of engines that support the operation graph.
- CUDNN_TYPE_INT64; one element.
- Read-only attribute; placeholder only: currently not supported.
Finalization
- An invalid attribute value was encountered. For example:
- One of the backend descriptors in CUDNN_ATTR_OPERATIONGRAPH_OPS is not finalized.
- The value CUDNN_ATTR_OPERATIONGRAPH_HANDLE is not a valid cuDNN handle.
- An unsupported attribute value was encountered. For example:
- The combination of operations of attribute CUDNN_ATTR_OPERATIONGRAPH_OPS is not supported.
- The descriptor was finalized successfully.
9.3.26. CUDNN_BACKEND_POINTWISE_DESCRIPTOR
Attributes
- Mode of the pointwise operation.
- CUDNN_TYPE_POINTWISE_MODE; one element.
- Required attribute.
- The math precision of the computation.
- CUDNN_TYPE_DATA_TYPE; one element.
- Required attribute.
- Specifies a method by which to propagate NaNs.
- CUDNN_TYPE_NAN_PROPOGATION; one element.
- Required only for comparison based pointwise modes, like ReLU.
- Current support only includes enum value CUDNN_PROPAGATE_NAN.
- Default value: CUDNN_NOT_PROPAGATE_NAN.
- Sets the lower clip value for ReLU. If (value < lower_clip)
value = lower_clip + lower_clip_slope * (value -
lower_clip);
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: 0.0f.
- Sets the upper clip value for ReLU. If (value > upper_clip)
value = upper_clip;
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: Numeric limit max.
- Sets the lower clip slope value for ReLU. If (value <
lower_clip) value = lower_clip + lower_clip_slope * (value -
lower_clip);
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: 0.0f.
- Sets the alpha value for ELU. If (value < 0.0) value = alpha
* (e^value - 1.0);
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: 1.0f.
- Sets the beta value for softplus. value = log (1 + e^(beta *
value)) / beta
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: 1.0f
- Sets the beta value for swish. value = value / (1 + e^(-beta *
value))
- CUDNN_TYPE_DOUBLE / CUDNN_TYPE_FLOAT; one element.
- Default value: 1.0f.
- Sets the axis value for GEN_INDEX. The index will be
generated for this axis.
- CUDNN_TYPE_INT64; one element.
- Default value: -1.
- Needs to lie between [0,input_dim_size-1]. For example, if your input has dimensions [N,C,H,W], the axis can be set to anything in [0,3].
Finalization
- The descriptor was finalized successfully.
9.3.27. CUDNN_BACKEND_REDUCTION_DESCRIPTOR
9.3.28. CUDNN_BACKEND_RESAMPLE_DESCRIPTOR
Attributes
- Specifies mode of resampling, for example, average pool,
nearest-neighbor, etc.
- CUDNN_TYPE_RESAMPLE_MODE; one element.
- Default value is CUDNN_RESAMPLE_NEAREST.
- Compute data type for the resampling operator.
- CUDNN_TYPE_DATA_TYPE; one element.
- Default value is CUDNN_DATA_FLOAT.
- Specifies a method by which to propagate NaNs.
- CUDNN_TYPE_NAN_PROPAGATION; one element.
- Default value is CUDNN_NOT_PROPAGATE_NAN.
- Specifies the number of spatial dimensions to perform the resampling
over.
- CUDNN_TYPE_INT64; one element.
- Required attribute.
- Specifies which values to use for padding.
- CUDNN_TYPE_PADDING_MODE; one element.
- Default value is CUDNN_ZERO_PAD.
- Stride in each dimension for the kernel/filter.
- CUDNN_TYPE_INT64 or CUDNN_TYPE_FRACTION; at most CUDNN_MAX_DIMS - 2.
- Required attribute.
- Padding added to the beginning of the input tensor in each dimension.
- CUDNN_TYPE_INT64 or CUDNN_TYPE_FRACTION; at most CUDNN_MAX_DIMS - 2.
- Required attribute.
- Padding added to the end of the input tensor in each dimension.
- CUDNN_TYPE_INT64 or CUDNN_TYPE_FRACTION; at most CUDNN_MAX_DIMS - 2.
- Required attribute.
- Spatial dimensions of filter.
- CUDNN_TYPE_INT64 or CUDNN_TYPE_FRACTION; at most CUDNN_MAX_DIMS - 2.
- Required attribute.
Finalization
- An unsupported attribute value was encountered. Some possible causes
are:
- An elemCount argument for setting CUDNN_ATTR_RESAMPLE_WINDOW_DIMS, CUDNN_ATTR_RESAMPLE_STRIDES, CUDNN_ATTR_RESAMPLE_PRE_PADDINGS, and CUDNN_ATTR_RESAMPLE_POST_PADDINGS is not equal to the value set for CUDNN_ATTR_RESAMPLE_SPATIAL_DIMS.
- CUDNN_ATTR_RESAMPLE_MODE is set to CUDNN_RESAMPLE_BILINEAR and any of the CUDNN_ATTR_RESAMPLE_WINDOW_DIMS are not set to 2.
- The descriptor was finalized successfully.
9.3.29. CUDNN_BACKEND_RNG_DESCRIPTOR
Attributes
- The probability distribution used for the rng
operation.
- CUDNN_TYPE_RNG_DISTRIBUTION; one element.
- Default value is CUDNN_RNG_DISTRIBUTION_BERNOULLI.
- The mean value for the normal distribution, used if
CUDNN_ATTR_RNG_DISTRIBUTION =
CUDNN_RNG_DISTRIBUTION_NORMAL.
- CUDNN_TYPE_DOUBLE ; one element.
- Default value is -1.
- The standard deviation value for the normal distribution, used if
CUDNN_ATTR_RNG_DISTRIBUTION =
CUDNN_RNG_DISTRIBUTION_NORMAL.
- CUDNN_TYPE_DOUBLE ; one element.
- Default value is -1.
- The maximum value for the range used in uniform distribution, used if
CUDNN_ATTR_RNG_DISTRIBUTION =
CUDNN_RNG_DISTRIBUTION_UNIFORM.
- CUDNN_TYPE_DOUBLE ; one element.
- Default value is -1.
- The minimum value for the range used in uniform distribution, used if
CUDNN_ATTR_RNG_DISTRIBUTION =
CUDNN_RNG_DISTRIBUTION_UNIFORM.
- CUDNN_TYPE_DOUBLE ; one element.
- Default value is -1.
- The probability of generating 1’s in the tensor, used if
CUDNN_ATTR_RNG_DISTRIBUTION =
CUDNN_RNG_DISTRIBUTION_BERNOULLI.
- CUDNN_TYPE_DOUBLE ; one element.
- Default value is -1.
Finalization
- An invalid attribute value was encountered. For example:
- If CUDNN_ATTR_RNG_DISTRIBUTION = CUDNN_RNG_DISTRIBUTION_NORMAL and the standard deviation supplied is negative.
- If CUDNN_ATTR_RNG_DISTRIBUTION = CUDNN_RNG_DISTRIBUTION_UNIFORM and the maximum value of the range is lower than minimum value.
- If CUDNN_ATTR_RNG_DISTRIBUTION = CUDNN_RNG_DISTRIBUTION_BERNOULLI and the probability supplied is negative.
- The descriptor was finalized successfully.
9.3.30. CUDNN_BACKEND_TENSOR_DESCRIPTOR
Attributes
- An integer that uniquely identifies the tensor.
- CUDNN_TYPE_INT64; one element.
- Required attribute.
- Data type of tensor.
- CUDNN_TYPE_DATA_TYPE; one element.
- Required attribute.
- Byte alignment of pointers for this tensor.
- CUDNN_TYPE_INT64; one element.
- Required attribute.
- Tensor dimensions.
- CUDNN_TYPE_INT64; at most CUDNN_MAX_DIMS elements.
- Required attribute.
- Tensor strides.
- CUDNN_TYPE_INT64; at most CUDNN_MAX_DIMS elements.
- Required attribute.
- Size of vectorization.
- CUDNN_TYPE_INT64; one element.
- Default value: 1
- Index of the vectorized dimension.
- CUDNN_TYPE_INT64; one element.
- Required to be set before finalization if CUDNN_ATTR_TENSOR_VECTOR_COUNT is set to a value different than its default; otherwise it’s ignored.
- Indicates whether the tensor is virtual. A virtual tensor is an
intermediate tensor in the operation graph that exists in transient and
not read from or written to in global device memory.
- CUDNN_TYPE_BOOL; one element.
- Default value: false
- A ragged tensor, that is, a tensor with nested variable length lists as
inner dimensions, will have another tensor called the ragged offset
descriptor that contains offsets in memory to the next variable length
list.
- CUDNN_TYPE_BACKEND_DESCRIPTOR; one element.
- Default value: None
Finalization
- An invalid attribute value was encountered. For example:
- Any of the tensor dimensions or strides is not positive.
- The value of the tensor alignment attribute is not divisible by the size of the data type.
- An unsupported attribute value was encountered. For example:
- The data type attribute is CUDNN_DATA_INT8x4, CUDNN_DATA_UINT8x4, or CUDNN_DATA_INT8x32.
- The data type attribute is CUDNN_DATA_INT8 and CUDNN_ATTR_TENSOR_VECTOR_COUNT value is not 1, 4, or 32.
- The descriptor was finalized successfully.
9.3.31. CUDNN_BACKEND_VARIANT_PACK_DESCRIPTOR
Attributes
- A unique identifier of tensor for each data pointer.
- CUDNN_TYPE_INT64; zero of more elements.
- Required attribute.
- Tensor data device pointers.
- CUDNN_TYPE_VOID_PTR; zero or more elements.
- Required attribute.
- Intermediate device pointers.
- CUDNN_TYPE_VOID_PTR; zero or more elements.
- Setting attribute unsupported. Placeholder for support to be added in a future version.
- Workspace to device pointer.
- CUDNN_TYPE_VOID_PTR; one element.
- Required attribute.
Finalization
- The descriptor was finalized successfully.
9.4. Use Cases
9.4.1. Setting Up An Operation Graph For A Grouped Convolution
- Create tensor descriptors.
cudnnBackendDescriptor_t xDesc; cudnnBackendCreateDescriptor(CUDNN_BACKEND_TENSOR_DESCRIPTOR, &xDesc); cudnnDataType_t dtype = CUDNN_DATA_FLOAT; cudnnBackendSetAttribute(xDesc, CUDNN_ATTR_TENSOR_DATA_TYPE, CUDNN_TYPE_DATA_TYPE, 1, &dtype); int64_t xDim[] = {n, g, c, d, h, w}; int64_t xStr[] = {g * c * d * h * w, c *d *h *w, d *h *w, h *w, w, 1}; int64_t xUi = 'x'; int64_t alignment = 4; cudnnBackendSetAttribute(xDesc, CUDNN_ATTR_TENSOR_DIMENSIONS, CUDNN_TYPE_INT64, 6, xDim); cudnnBackendSetAttribute(xDesc, CUDNN_ATTR_TENSOR_STRIDES, CUDNN_TYPE_INT64, 6, xStr); cudnnBackendSetAttribute(xDesc, CUDNN_ATTR_TENSOR_UNIQUE_ID, CUDNN_TYPE_INT64, 1, &xUi); cudnnBackendSetAttribute(xDesc, CUDNN_ATTR_TENSOR_BYTE_ALIGNMENT, CUDNN_TYPE_INT64, 1, &alignment); cudnnBackendFinalize(xDesc); - Repeat the above step for the convolution filter and output tensor descriptor.
The six filter tensor dimensions are [g, k, c, t, r, s] and the
six output tensor dimensions are [n, g, k, o, p, q],
respectively. Below, when finalizing a convolution operator to which the tensors
are bound, dimension consistency is checked, meaning all n,
g, c, k values shared
among the three tensors are required to be the same. Otherwise,
CUDNN_STATUS_BAD_PARAM status is returned.For backward compatibility with how tensors are specified in cudnnTensorDescriptor_t and used in convolution API, it is also possible to specify a 5D tensor with the following dimension:
- image: [n, g*c, d, h, w]
- filter: [g*k, c, t, r, s]
- response: [n, g*k, o, p, q]
In this format, a similar consistency check is performed when finalizing a convolution operator descriptor to which the tensors are bound.
- Create, set, and finalize a convolution operator descriptor.
cudnnBackendDescriptor_t cDesc; int64_t nbDims = 3; cudnnDataType_t compType = CUDNN_DATA_FLOAT; cudnnConvolutionMode_t mode = CUDNN_CONVOLUTION; int64_t pad[] = {0, 0, 0}; int64_t filterStr[] = {1, 1, 1}; int64_t dilation[] = {1, 1, 1}; cudnnBackendCreateDescriptor(CUDNN_BACKEND_CONVOLUTION_DESCRIPTOR, &cDesc); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_SPATIAL_DIMS, CUDNN_TYPE_INT64, 1, &nbDims); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_COMP_TYPE, CUDNN_TYPE_DATA_TYPE, 1, &compType); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_CONV_MODE, CUDNN_TYPE_CONVOLUTION_MODE, 1, &mode); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_PRE_PADDINGS, CUDNN_TYPE_INT64, nbDims, pad); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_POST_PADDINGS, CUDNN_TYPE_INT64, nbDims, pad); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_DILATIONS, CUDNN_TYPE_INT64, nbDims, dilation); cudnnBackendSetAttribute(cDesc, CUDNN_ATTR_CONVOLUTION_FILTER_STRIDES, CUDNN_TYPE_INT64, nbDims, filterStr); cudnnBackendFinalize(cDesc); - Create, set, and finalize a convolution forward operation descriptor.
cudnnBackendDescriptor_t fprop; float alpha = 1.0; float beta = 0.5; cudnnBackendCreateDescriptor(CUDNN_BACKEND_OPERATION_CONVOLUTION_FORWARD_DESCRIPTOR, &fprop); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_X, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &xDesc); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_W, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &wDesc); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_Y, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &yDesc); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_CONV_DESC, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &cDesc); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_ALPHA, dtype, 1, alpha); cudnnBackendSetAttribute(fprop, CUDNN_ATTR_OPERATION_CONVOLUTION_FORWARD_BETA, dtype, 1, beta); cudnnBackendFinalize(fprop); - Create, set, and finalize an operation graph descriptor.
cudnnBackendDescriptor_t op_graph; cudnnBackendCreateDescriptor(CUDNN_BACKEND_OPERATIONGRAPH_DESCRIPTOR, op_graph); cudnnBackendSetAttribute(op_graph, CUDNN_ATTR_OPERATIONGRAPH_OPS, CUDNN_TYPE_BACKEND_DESCRIPTOR, len, ops); cudnnBackendSetAttribute(op_graph, CUDNN_ATTR_OPERATIONGRAPH_HANDLE, CUDNN_TYPE_HANDLE, 1, &handle); cudnnBackendFinalize(op_graph);
9.4.2. Setting Up An Engine Configuration
- Create, set, and finalize an engine descriptor.
cudnnBackendDescriptor_t engine; cudnnBackendCreateDescriptor(CUDNN_BACKEND_ENGINE_DESCRIPTOR, &engine); cudnnBackendSetAttribute(engine, CUDNN_ATTR_ENGINE_OPERATION_GRAPH, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &opset); Int64_t gidx = 0; cudnnBackendSetAttribute(engine, CUDNN_ATTR_ENGINE_GLOBAL_INDEX, CUDNN_TYPE_INT64, 1, &gidx); cudnnBackendFinalize(engine);The user can query a finalized engine descriptor with cudnnBackendGetAttribute() API call for its attributes, including the performance knobs that it has. For simplicity, this use case skips this step and assumes the user is setting up an engine config descriptor below without making any changes to performance knobs.
- Create, set, and finalize an engine config descriptor.
cudnnBackendDescriptor_t engcfg; cudnnBackendSetAttribute(engcfg, CUDNN_ATTR_ENGINECFG_ENGINE, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &engine); cudnnBackendFinalize(engcfg);
9.4.3. Setting Up And Executing A Plan
- Create, set, and finalize an execution plan descriptor. Obtain workspace size
to allocate.
cudnnBackendDescriptor_t plan; cudnnBackendCreateDescriptor(CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR, &plan); cudnnBackendSetAttribute(plan, CUDNN_ATTR_EXECUTION_PLAN_ENGINE_CONFIG, CUDNN_TYPE_BACKEND_DESCRIPTOR, 1, &engcfg); cudnnBackendFinalize(plan); int64_t workspaceSize; cudnnBackendGetAttribute(plan, CUDNN_ATTR_EXECUTION_PLAN_WORKSPACE_SIZE, CUDNN_TYPE_INT64, 1, NULL, &workspaceSize) - Create, set and finalize a variant pack descriptor.
void *dev_ptrs[3] = {xData, wData, yData}; // device pointer int64_t uids[3] = {‘x’, ‘w’, ‘y’}; Void *workspace; cudnnBackendDescriptor_t varpack; cudnnBackendCreateDescriptor(CUDNN_BACKEND_VARIANT_PACK_DESCRIPTOR, &varpack); cudnnBackendSetAttribute(varpack, CUDNN_ATTR_VARIANT_PACK_DATA_POINTERS, CUDNN_TYPE_VOID_PTR, 3, dev_ptrs); cudnnBackendSetAttribute(varpack, CUDNN_ATTR_VARIANT_PACK_UNIQUE_IDS, CUDNN_TYPE_INT64, 3, uids); cudnnBackendSetAttribute(varpack, CUDNN_ATTR_VARIANT_PACK_WORKSPACE, CUDNN_TYPE_VOID_PTR, 1, &workspace); cudnnBackendFinalize(varPack); - Execute the plan with a variant pack.
cudnnBackendExecute(handle, plan, varpack);
Notices
Notice
This document is provided for information purposes only and shall not be regarded as a warranty of a certain functionality, condition, or quality of a product. NVIDIA Corporation (“NVIDIA”) makes no representations or warranties, expressed or implied, as to the accuracy or completeness of the information contained in this document and assumes no responsibility for any errors contained herein. NVIDIA shall have no liability for the consequences or use of such information or for any infringement of patents or other rights of third parties that may result from its use. This document is not a commitment to develop, release, or deliver any Material (defined below), code, or functionality.
NVIDIA reserves the right to make corrections, modifications, enhancements, improvements, and any other changes to this document, at any time without notice.
Customer should obtain the latest relevant information before placing orders and should verify that such information is current and complete.
NVIDIA products are sold subject to the NVIDIA standard terms and conditions of sale supplied at the time of order acknowledgement, unless otherwise agreed in an individual sales agreement signed by authorized representatives of NVIDIA and customer (“Terms of Sale”). NVIDIA hereby expressly objects to applying any customer general terms and conditions with regards to the purchase of the NVIDIA product referenced in this document. No contractual obligations are formed either directly or indirectly by this document.
NVIDIA products are not designed, authorized, or warranted to be suitable for use in medical, military, aircraft, space, or life support equipment, nor in applications where failure or malfunction of the NVIDIA product can reasonably be expected to result in personal injury, death, or property or environmental damage. NVIDIA accepts no liability for inclusion and/or use of NVIDIA products in such equipment or applications and therefore such inclusion and/or use is at customer’s own risk.
NVIDIA makes no representation or warranty that products based on this document will be suitable for any specified use. Testing of all parameters of each product is not necessarily performed by NVIDIA. It is customer’s sole responsibility to evaluate and determine the applicability of any information contained in this document, ensure the product is suitable and fit for the application planned by customer, and perform the necessary testing for the application in order to avoid a default of the application or the product. Weaknesses in customer’s product designs may affect the quality and reliability of the NVIDIA product and may result in additional or different conditions and/or requirements beyond those contained in this document. NVIDIA accepts no liability related to any default, damage, costs, or problem which may be based on or attributable to: (i) the use of the NVIDIA product in any manner that is contrary to this document or (ii) customer product designs.
No license, either expressed or implied, is granted under any NVIDIA patent right, copyright, or other NVIDIA intellectual property right under this document. Information published by NVIDIA regarding third-party products or services does not constitute a license from NVIDIA to use such products or services or a warranty or endorsement thereof. Use of such information may require a license from a third party under the patents or other intellectual property rights of the third party, or a license from NVIDIA under the patents or other intellectual property rights of NVIDIA.
Reproduction of information in this document is permissible only if approved in advance by NVIDIA in writing, reproduced without alteration and in full compliance with all applicable export laws and regulations, and accompanied by all associated conditions, limitations, and notices.
THIS DOCUMENT AND ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND SEPARATELY, “MATERIALS”) ARE BEING PROVIDED “AS IS.” NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS FOR A PARTICULAR PURPOSE. TO THE EXTENT NOT PROHIBITED BY LAW, IN NO EVENT WILL NVIDIA BE LIABLE FOR ANY DAMAGES, INCLUDING WITHOUT LIMITATION ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, PUNITIVE, OR CONSEQUENTIAL DAMAGES, HOWEVER CAUSED AND REGARDLESS OF THE THEORY OF LIABILITY, ARISING OUT OF ANY USE OF THIS DOCUMENT, EVEN IF NVIDIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. Notwithstanding any damages that customer might incur for any reason whatsoever, NVIDIA’s aggregate and cumulative liability towards customer for the products described herein shall be limited in accordance with the Terms of Sale for the product.
Arm
Arm, AMBA and Arm Powered are registered trademarks of Arm Limited. Cortex, MPCore and Mali are trademarks of Arm Limited. "Arm" is used to represent Arm Holdings plc; its operating company Arm Limited; and the regional subsidiaries Arm Inc.; Arm KK; Arm Korea Limited.; Arm Taiwan Limited; Arm France SAS; Arm Consulting (Shanghai) Co. Ltd.; Arm Germany GmbH; Arm Embedded Technologies Pvt. Ltd.; Arm Norway, AS and Arm Sweden AB.
HDMI
HDMI, the HDMI logo, and High-Definition Multimedia Interface are trademarks or registered trademarks of HDMI Licensing LLC.
Blackberry/QNX
Copyright © 2020 BlackBerry Limited. All rights reserved.
Trademarks, including but not limited to BLACKBERRY, EMBLEM Design, QNX, AVIAGE, MOMENTICS, NEUTRINO and QNX CAR are the trademarks or registered trademarks of BlackBerry Limited, used under license, and the exclusive rights to such trademarks are expressly reserved.
Trademarks
NVIDIA, the NVIDIA logo, and BlueField, CUDA, DALI, DRIVE, Hopper, JetPack, Jetson AGX Xavier, Jetson Nano, Maxwell, NGC, Nsight, Orin, Pascal, Quadro, Tegra, TensorRT, Triton, Turing and Volta are trademarks and/or registered trademarks of NVIDIA Corporation in the United States and other countries. Other company and product names may be trademarks of the respective companies with which they are associated.