Core Concepts#
This section introduces the core concepts of cuDNN.
cuDNN Handle#
The cuDNN library exposes a host API but assumes that for operations using the GPU, the necessary data is directly accessible from the device.
An application using cuDNN must initialize a handle to the library context.
Tensors and Layouts#
cuDNN operations take tensors as input and produce tensors as output.
Tensor Descriptor#
The cuDNN library describes data with a generic n-D tensor descriptor defined with the following parameters:
a number of dimensions from 3 to 8
a data type (32-bit floating-point, 64 bit-floating point, 16-bit floating-point…)
an integer array defining the size of each dimension
an integer array defining the stride of each dimension (for example, the number of elements to add to reach the next element from the same dimension)
This tensor definition allows, for example, to have some dimensions overlapping each other within the same tensor by having the stride of one dimension smaller than the product of the dimension and the stride of the next dimension. In cuDNN, unless specified otherwise, all routines will support tensors with overlapping dimensions for forward-pass input tensors, however, dimensions of the output tensors cannot overlap. Even though this tensor format supports negative strides (which can be useful for data mirroring), cuDNN routines do not support tensors with negative strides unless specified otherwise.
WXYZ Tensor Descriptor#
Tensor descriptor formats are identified using acronyms, with each letter referencing a corresponding dimension. In this document, the usage of this terminology implies:
all the strides are strictly positive
the dimensions referenced by the letters are sorted in decreasing order of their respective strides
3-D Tensor Descriptor#
A 3-D tensor is commonly used for matrix multiplications, with three letters: B, M, and N. B represents the batch size (for batch matmul), M represents the number of rows, and N represents the number of columns. Refer to the CUDNN_BACKEND_OPERATION_MATMUL_DESCRIPTOR operation for more information.
4-D Tensor Descriptor#
A 4-D tensor descriptor is used to define the format for batches of 2D images with 4 letters: N,C,H,W for respectively the batch size, the number of feature maps, the height and the width. The letters are sorted in decreasing order of the strides. The commonly used 4-D tensor formats are:
NCHW
NHWC
CHWN
5-D Tensor Descriptor#
A 5-D tensor descriptor is used to define the format of the batch of 3D images with 5 letters: N,C,D,H,W for respectively the batch size, the number of feature maps, the depth, the height, and the width. The letters are sorted in decreasing order of the strides. The commonly used 5-D tensor formats are called:
NCDHW
NDHWC
CDHWN
Fully-Packed Tensors#
A tensor is defined as XYZ-fully-packed if, and only if:
the number of tensor dimensions is equal to the number of letters preceding the
fully-packedsuffixthe stride of the i-th dimension is equal to the product of the (i+1)-th dimension by the (i+1)-th stride
the stride of the last dimension is 1
Partially-Packed Tensors#
The partially XYZ-packed terminology only applies in the context of a tensor format described with a superset of the letters used to define a partially-packed tensor. A WXYZ tensor is defined as XYZ-packed if, and only if:
the strides of all dimensions NOT referenced in the
-packedsuffix are greater or equal to the product of the next dimension by the next stride.the stride of each dimension referenced in the
-packedsuffix in position i is equal to the product of the (i+1)-st dimension by the (i+1)-st stride.if the last tensor’s dimension is present in the
-packedsuffix, its stride is 1.
For example, an NHWC tensor WC-packed means that the c_stride is equal to 1 and w_stride is equal to c_dim x c_stride. In practice, the -packed suffix is usually applied to the minor dimensions of a tensor but can be applied to only the major dimensions; for example, an NCHW tensor that is only N-packed.
Spatially Packed Tensors#
Spatially-packed tensors are defined as partially-packed in spatial dimensions. For example, a spatially-packed 4D tensor would mean that the tensor is either NCHW HW-packed or CNHW HW-packed.
Overlapping Tensors#
A tensor is defined to be overlapping if iterating over a full range of dimensions produces the same address more than once. In practice an overlapped tensor will have stride[i-1] < stride[i]*dim[i] for some of the i from [1,nbDims] interval.
Data Layout Formats#
This section describes how cuDNN tensors are arranged in memory according to several data layout formats.
The recommended way to specify the layout format of a tensor is by setting its strides accordingly. For compatibility with the v7 API, a subset of the layout formats can also be configured through the cudnnTensorFormat_t enum. The enum is only supplied for legacy reasons and is deprecated.
Example Tensor#
Consider a batch of images with the following dimensions:
N is the batch size; 1
C is the number of feature maps (that is, number of channels); 64
H is the image height; 5
W is the image width; 4
To keep the example simple, the image pixel elements are expressed as a sequence of integers, 0, 1, 2, 3, and so on.

In the following subsections, we’ll use the above example to demonstrate the different layout formats.
Convolution Layouts#
cuDNN supports several layouts for convolution, as described in the following sections.
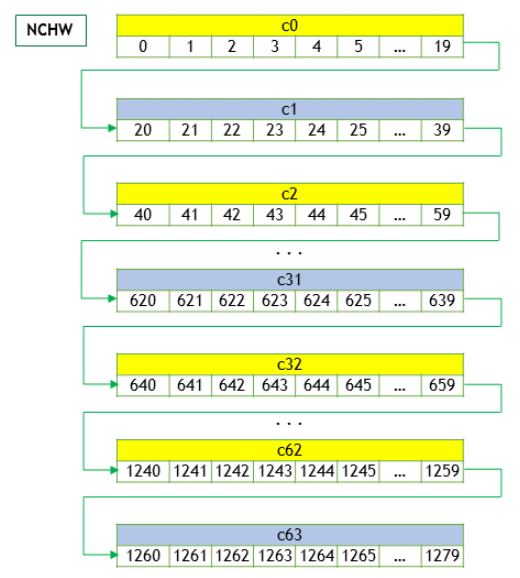
NCHW Memory Layout#
The above 4D tensor is laid out in the memory in the NCHW format as below:
Beginning with the first channel (c=0), the elements are arranged contiguously in row-major order.
Continue with second and subsequent channels until the elements of all the channels are laid out.
Proceed to the next batch (if N is > 1).
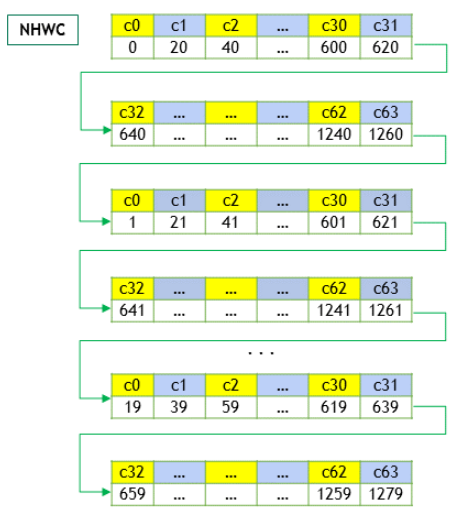
NHWC Memory Layout#
For the NHWC memory layout, the corresponding elements in all the C channels are laid out first, as below:
Begin with the first element of channel 0, then proceed to the first element of channel 1, and so on, until the first elements of all the C channels are laid out.
Next, select the second element of channel 0, then proceed to the second element of channel 1, and so on, until the second element of all the channels are laid out.
Follow the row-major order of channel 0 and complete all the elements.
Proceed to the next batch (if N is > 1).
NC/32HW32 Memory Layout#
The NC/32HW32 is similar to NHWC, with a key difference. For the NC/32HW32 memory layout, the 64 channels are grouped into two groups of 32 channels each - first group consisting of channels c0 through c31, and the second group consisting of channels c32 through c63. Then each group is laid out using the NHWC format.
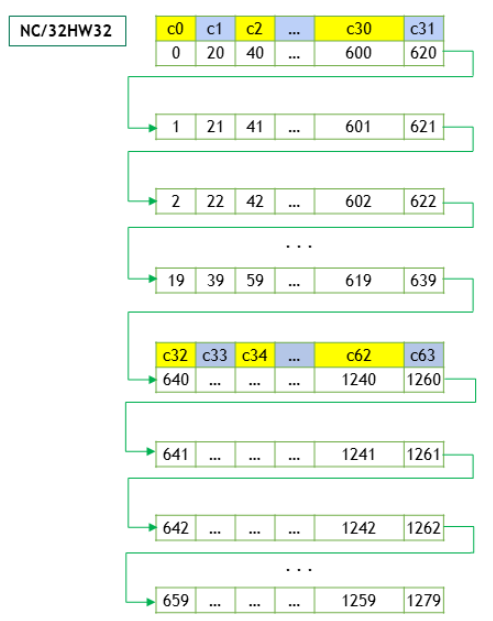
For the generalized NC/xHWx layout format, the following observations apply:
Only the channel dimension,
C, is grouped intoxchannels each.When
x = 1, each group has only one channel. Hence, the elements of one channel (that is, one group) are arranged contiguously (in the row-major order), before proceeding to the next group (that is, next channel). This is the same as the NCHW format.When
x = C, then NC/xHWx is identical to NHWC, that is, the entire channel depthCis considered as a single group. The casex = Ccan be thought of as vectorizing the entireCdimension as one big vector, laying out all theC, followed by the remaining dimensions, just like NHWC.The tensor format cudnnTensorFormat_t can also be interpreted in the following way - The NCHW INT8x32 format is really
N x (C/32) x H x W x 32(32C``s for every ``W), just as the NCHW INT8x4 format isN x (C/4) x H x W x 4(4Cfor everyW). Hence theVECT_Cname - eachWis a vector (4 or 32) ofC.
Matmul Layouts#
As discussed in 3-D Tensor Descriptor, matmul uses 3D tensors, described using BMN dimensions. The layout can be specified through the following strides. The following are two examples of recommended layouts:
Packed Row-major: dim [B,M,N] with stride [MN, N, 1], or
Packed Column-major: dim [B,M,N] with stride [MN, 1, M]
Unpacked layouts for 3-D tensors are supported as well, but their support surface is more ragged.