Legacy API#
The Graph API section can be thought of as a declarative API, in the sense that you declare a graph, and then build, and run it. Previously, cuDNN only had an imperative API, which is more convenient for basic use cases, but has turned out to be overly-restrictive as the deep learning field has evolved to require more operations and more complex fusions of operations. Over time, we are deprecating and removing parts of the legacy API, as the graph API grows to parity with its support surface. However, there is still a gap, and therefore there is still a legacy API.
Convolution Functions#
Prerequisites#
For the supported GPUs, the Tensor Core operations will be triggered for convolution functions only when cudnnSetConvolutionMathType() is called on the appropriate convolution descriptor by setting the mathType to CUDNN_TENSOR_OP_MATH or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION.
Supported Algorithms#
When the prerequisite is met, the below convolution functions can be run as Tensor Core operations:
Supported Convolution Function |
Supported Algorithm |
|---|---|
|
|
|
|
|
|
Data and Filter Formats#
The cuDNN library may use padding, folding, and NCHW-to-NHWC transformations to call the Tensor Core operations. For more information, refer to Tensor Transformations.
For algorithms other than *_ALGO_WINOGRAD_NONFUSED, when the following requirements are met, the cuDNN library will trigger the Tensor Core operations:
Input, filter, and output descriptors (
xDesc,yDesc,wDesc,dxDesc,dyDescanddwDescas applicable) are of thedataType = CUDNN_DATA_HALF(that is, FP16). For FP32 data type, refer to FP32-to-FP16 Conversion.The number of input and output feature maps (that is, channel dimension C) is a multiple of 8. When the channel dimension is not a multiple of 8, refer to Padding.
The filter is of type
CUDNN_TENSOR_NCHWorCUDNN_TENSOR_NHWC.If using a filter of type
CUDNN_TENSOR_NHWC, then the input, filter, and output data pointers (X,Y,W,dX,dY, anddWas applicable) are aligned to 128-bit boundaries.
RNN Functions#
Prerequisites#
Tensor Core operations may be used in RNN functions cudnnRNNForward(), cudnnRNNBackwardData_v8(), and cudnnRNNBackwardWeights_v8() when the mathType argument in cudnnSetRNNDescriptor_v8() is set to CUDNN_TENSOR_OP_MATH or CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION.
Supported Algorithms#
When the above prerequisites are met, the RNN functions below can be run as Tensor Core operations:
Supported RNN Function |
Supported Algorithm |
|---|---|
All RNN functions that support Tensor Core operations |
|
Data and Filter Formats#
When the following requirements are met, then the cuDNN library triggers the Tensor Core operations:
For
algo = CUDNN_RNN_ALGO_STANDARD:
The hidden state size, input size, and the batch size is a multiple of 8.
All user-provided tensors and the RNN weight buffer are aligned to 128-bit boundaries.
For FP16 input/output, the
CUDNN_TENSOR_OP_MATHorCUDNN_TENSOR_OP_MATH_ALLOW_CONVERSIONis selected.For FP32 input/output,
CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSIONis selected.For
algo = CUDNN_RNN_ALGO_PERSIST_STATIC:
The hidden state size and the input size is a multiple of 32.
The batch size is a multiple of 8.
If the batch size exceeds 96 (for forward training or inference) or 32 (for backward data), then the batch size constraints may be stricter, and large power-of-two batch sizes may be needed.
All user-provided tensors and the RNN weight buffer are aligned to 128-bit boundaries.
For FP16 input/output,
CUDNN_TENSOR_OP_MATHorCUDNN_TENSOR_OP_MATH_ALLOW_CONVERSIONis selected.For FP32 input/output,
CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSIONis selected.
For more information, refer to Features of RNN Functions.
Features of RNN Functions#
Refer to the following table for a list of features supported by each RNN function.
For each of these terms, the short-form versions shown in parentheses are used in the tables below for brevity: CUDNN_RNN_ALGO_STANDARD (_ALGO_STANDARD), CUDNN_RNN_ALGO_PERSIST_STATIC (_ALGO_PERSIST_STATIC), CUDNN_RNN_ALGO_PERSIST_DYNAMIC (_ALGO_PERSIST_DYNAMIC), CUDNN_RNN_ALGO_PERSIST_STATIC_SMALL_H (_ALGO_SMALL_H) and CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION (_ALLOW_CONVERSION).
Function |
I/O Layout Supported |
Supports Variable Sequence Length in Batch |
|---|---|---|
|
Sequence major unpacked. Batch major unpacked. Sequence major packed. |
Only with |
|
Sequence major unpacked. Batch major unpacked. Sequence major packed. |
Only with |
|
Sequence major unpacked. Batch major unpacked. Sequence major packed. |
Only with |
Note
To use an unpacked layout, set CUDNN_RNN_PADDED_IO_ENABLED through the auxFlags argument of cudnnSetRNNDescriptor_v8().
Commonly Supported
- Mode (cell type)
CUDNN_RNN_RELU,CUDNN_RNN_TANH,CUDNN_LSTM, andCUDNN_GRU.- Algo
_ALGO_STANDARD,_ALGO_PERSIST_STATIC,_ALGO_PERSIST_DYNAMIC,_ALGO_SMALL_H. Do not mix different algos incudnnRNNForward(),cudnnRNNBackwardData_v8(), andcudnnRNNBackwardWeights_v8()functions.- Math mode
CUDNN_DEFAULT_MATH,CUDNN_TENSOR_OP_MATH(will automatically fall back if run on pre-Volta or if algo doesn’t support Tensor Cores),_ALLOW_CONVERSION(may perform down conversion to utilize Tensor Cores).- Direction mode
CUDNN_UNIDIRECTIONAL,CUDNN_BIDIRECTIONAL- RNN input mode
CUDNN_LINEAR_INPUT,CUDNN_SKIP_INPUT
Feature |
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Not Supported |
Not Supported |
|
LSTM recurrent projection |
Supported |
Not Supported |
Not Supported |
Not Supported |
LSTM cell clipping |
Supported |
Supported |
Supported |
Supported |
Variable sequence length in batch |
Supported |
Not Supported |
Not Supported |
Not Supported |
Tensor Cores |
|
|
|
Not Supported, will execute normally ignoring |
Other limitations |
Max problem size is limited by GPU specifications. |
|
Requires real time compilation through NVRTC. |
Tensor Transformations#
A few functions in the cuDNN library will perform transformations such as folding, padding, and NCHW-to-NHWC conversion while performing the actual function operation.
Conversion Between FP32 and FP16#
The cuDNN API Reference allows you to specify that FP32 input data may be copied and converted to FP16 data internally to use Tensor Core operations for potentially improved performance. This can be achieved by selecting CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION enum for cudnnMathType_t. In this mode, the FP32 tensors are internally down-converted to FP16, the Tensor Op math is performed, and finally up-converted to FP32 as outputs.
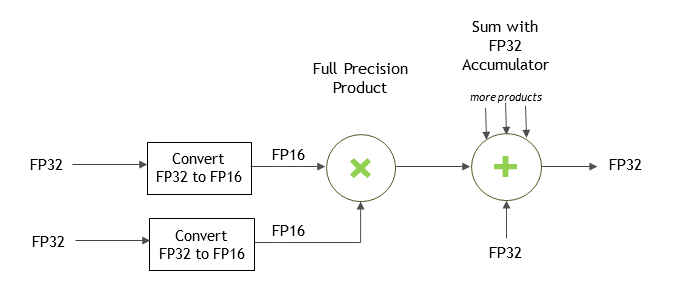
For Convolutions
For convolutions, the FP32-to-FP16 conversion can be achieved by passing the CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION enum value to the cudnnSetConvolutionMathType() call.
// Set the math type to allow cuDNN to use Tensor Cores: checkCudnnErr(cudnnSetConvolutionMathType(cudnnConvDesc, CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION));
For RNNs
For RNNs, the FP32-to-FP16 conversion can be achieved by assigning the CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION enum value to the mathType argument of the cudnnSetRNNDescriptor_v8() call to allow FP32 input data to be down-converted for use in RNNs.
Padding#
For packed NCHW data, when the channel dimension is not a multiple of 8, then the cuDNN library will pad the tensors as needed to enable Tensor Core operations. This padding is automatic for packed NCHW data in both the CUDNN_TENSOR_OP_MATH and the CUDNN_TENSOR_OP_MATH_ALLOW_CONVERSION cases.
Folding#
In the folding operation, the cuDNN library implicitly performs the formatting of input tensors and saves the input tensors in an internal workspace. This can lead to an acceleration of the call to Tensor Cores.
With folding or channel-folding, cuDNN can implicitly format the input tensors within an internal workspace to accelerate the overall calculation. Performing this transformation for the user often allows cuDNN to use kernels with restrictions on convolution stride to support a strided convolution problem.
Conversion Between NCHW And NHWC#
Tensor Cores require that the tensors be in the NHWC data layout. Conversion between NCHW and NHWC is performed when the user requests Tensor Op math. However, a request to use Tensor Cores is just that, a request and Tensor Cores may not be used in some cases. The cuDNN library converts between NCHW and NHWC if and only if Tensor Cores are requested and are actually used.
If your input (and output) are NCHW, then expect a layout change.
Non-Tensor Op convolutions will not perform conversions between NCHW and NHWC.
In very rare and difficult-to-qualify cases that are a complex function of padding and filter sizes, it is possible that Tensor Ops is not enabled. In such cases, users can pre-pad to enable the Tensor Ops path.
Mixed Precision Numerical Accuracy#
When the computation precision and the output precision are not the same, it is possible that the numerical accuracy will vary from one algorithm to the other.
For example, when the computation is performed in FP32 and the output is in FP16, the CUDNN_CONVOLUTION_BWD_FILTER_ALGO_0 (ALGO_0) has lower accuracy compared to the CUDNN_CONVOLUTION_BWD_FILTER_ALGO_1 (ALGO_1). This is because ALGO_0 does not use extra workspace, and is forced to accumulate the intermediate results in FP16, that is, half precision float, and this reduces the accuracy. The ALGO_1, on the other hand, uses additional workspace to accumulate the intermediate values in FP32, that is, full precision float.